 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dispensed Transformer Network for Unsupervised Domain Adaptation
Oct 28, 2021
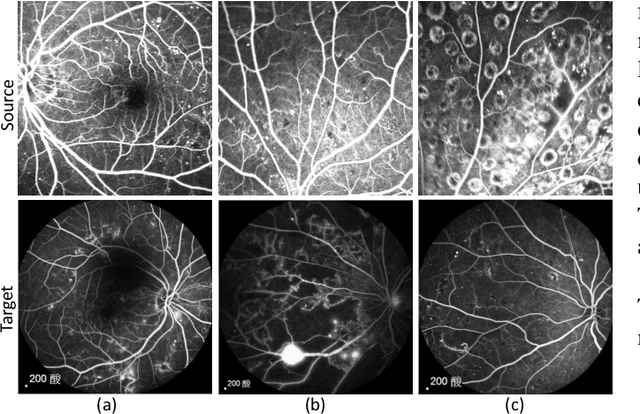
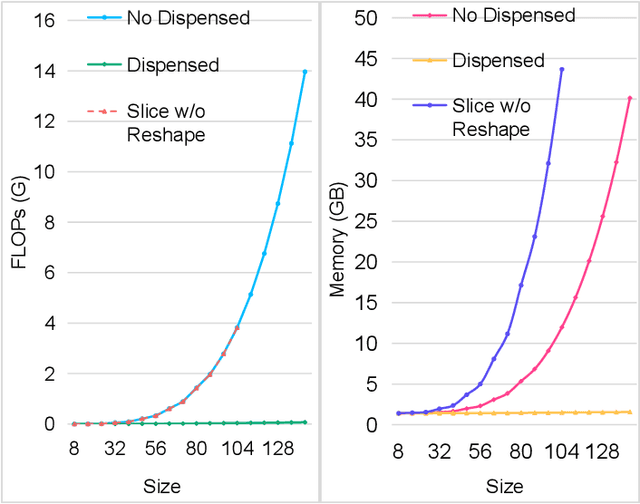
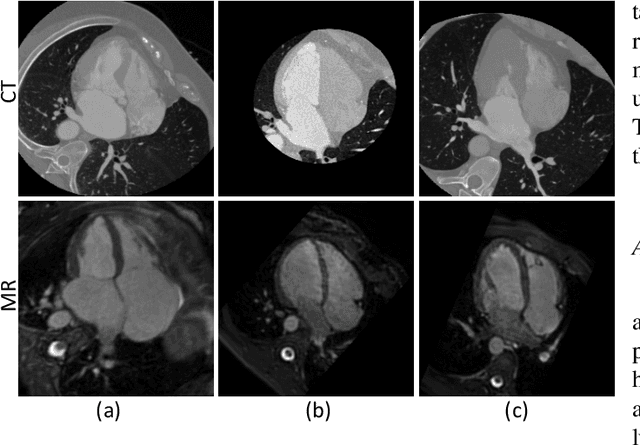
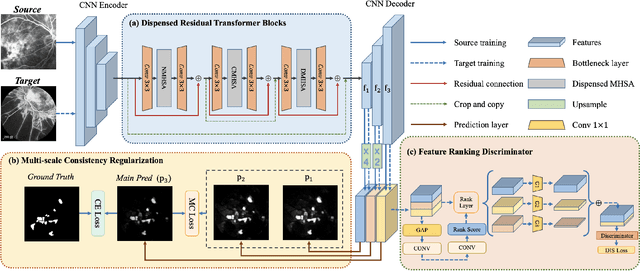
Accurate segmentation is a crucial step in medical image analysis and applying supervised machine learning to segment the organs or lesions has been substantiated effective. However, it is costly to perform data annotation that provides ground truth labels for training the supervised algorithms, and the high variance of data that comes from different domains tends to severely degrade system performance over cross-site or cross-modality datasets. To mitigate this problem, a novel unsupervised domain adaptation (UDA) method named dispensed Transformer network (DTNet) is introduced in this paper. Our novel DTNet contains three modules. First, a dispensed residual transformer block is designed, which realizes global attention by dispensed interleaving operation and deals with the excessive computational cost and GPU memory usage of the Transformer. Second, a multi-scale consistency regularization is proposed to alleviate the loss of details in the low-resolution output for better feature alignment. Finally, a feature ranking discriminator is introduced to automatically assign different weights to domain-gap features to lessen the feature distribution distance, reducing the performance shift of two domains. The proposed method is evaluated on large fluorescein angiography (FA) retinal nonperfusion (RNP) cross-site dataset with 676 images and a wide used cross-modality dataset from the MM-WHS challenge. Extensive results demonstrate that our proposed network achieves the best performance in comparison with several state-of-the-art techniques.
Contrastive Active Inference
Oct 22, 2021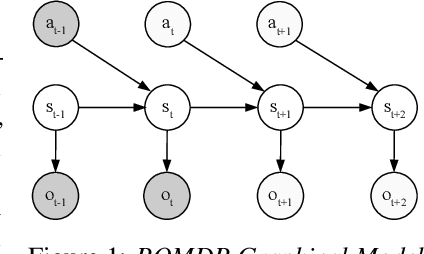
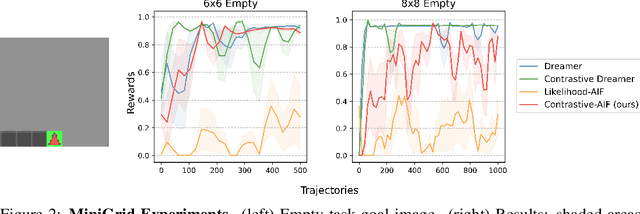

Active inference is a unifying theory for perception and action resting upon the idea that the brain maintains an internal model of the world by minimizing free energy. From a behavioral perspective, active inference agents can be seen as self-evidencing beings that act to fulfill their optimistic predictions, namely preferred outcomes or goals. In contrast, reinforcement learning requires human-designed rewards to accomplish any desired outcome. Although active inference could provide a more natural self-supervised objective for control, its applicability has been limited because of the shortcomings in scaling the approach to complex environments. In this work, we propose a contrastive objective for active inference that strongly reduces the computational burden in learning the agent's generative model and planning future actions. Our method performs notably better than likelihood-based active inference in image-based tasks, while also being computationally cheaper and easier to train. We compare to reinforcement learning agents that have access to human-designed reward functions, showing that our approach closely matches their performance. Finally, we also show that contrastive methods perform significantly better in the case of distractors in the environment and that our method is able to generalize goals to variations in the background.
Unpaired cross-modality educed distillation (CMEDL) applied to CT lung tumor segmentation
Jul 16, 2021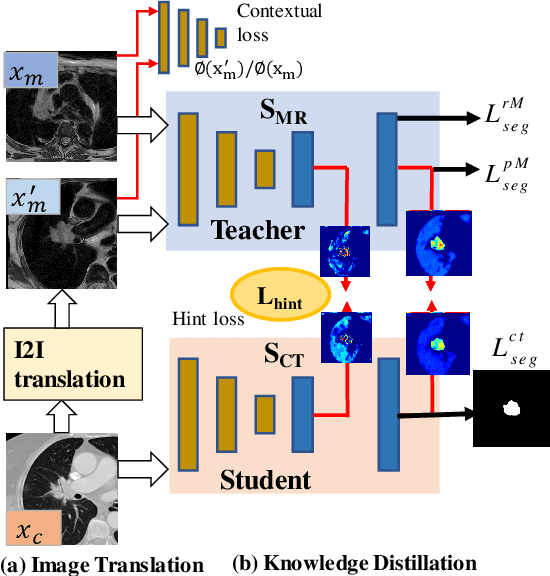
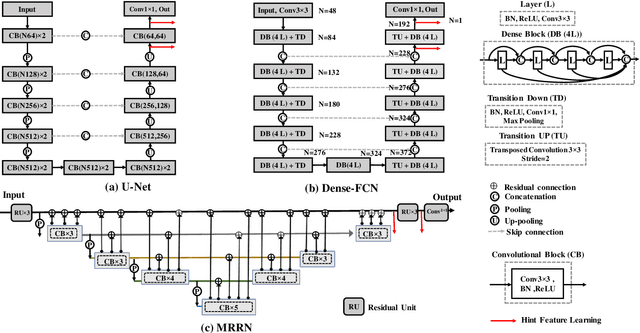
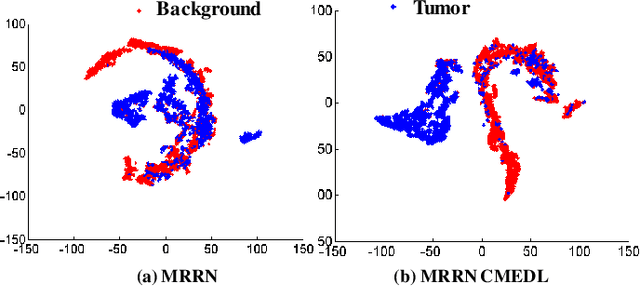
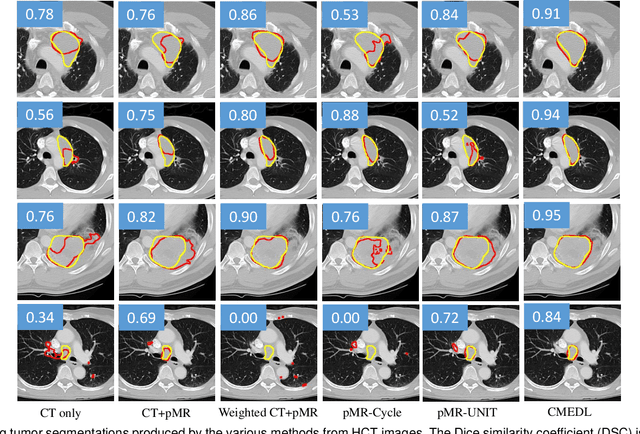
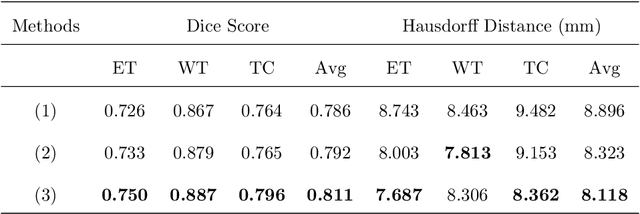
Accurate and robust segmentation of lung cancers from CTs is needed to more accurately plan and deliver radiotherapy and to measure treatment response. This is particularly difficult for tumors located close to mediastium, due to low soft-tissue contrast. Therefore, we developed a new cross-modality educed distillation (CMEDL) approach, using unpaired CT and MRI scans, whereby a teacher MRI network guides a student CT network to extract features that signal the difference between foreground and background. Our contribution eliminates two requirements of distillation methods: (i) paired image sets by using an image to image (I2I) translation and (ii) pre-training of the teacher network with a large training set by using concurrent training of all networks. Our framework uses an end-to-end trained unpaired I2I translation, teacher, and student segmentation networks. Our framework can be combined with any I2I and segmentation network. We demonstrate our framework's feasibility using 3 segmentation and 2 I2I methods. All networks were trained with 377 CT and 82 T2w MRI from different sets of patients. Ablation tests and different strategies for incorporating MRI information into CT were performed. Accuracy was measured using Dice similarity (DSC), surface Dice (sDSC), and Hausdorff distance at the 95$^{th}$ percentile (HD95). The CMEDL approach was significantly (p $<$ 0.001) more accurate than non-CMEDL methods, quantitatively and visually. It produced the highest segmentation accuracy (sDSC of 0.83 $\pm$ 0.16 and HD95 of 5.20 $\pm$ 6.86mm). CMEDL was also more accurate than using either pMRI's or the combination of CT's with pMRI's for segmentation.
A Tri-attention Fusion Guided Multi-modal Segmentation Network
Nov 02, 2021
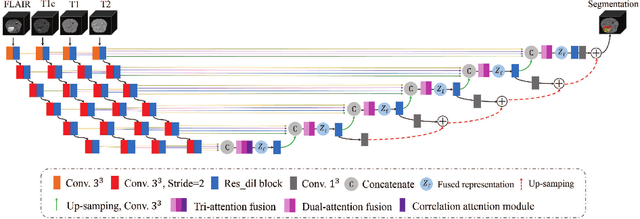
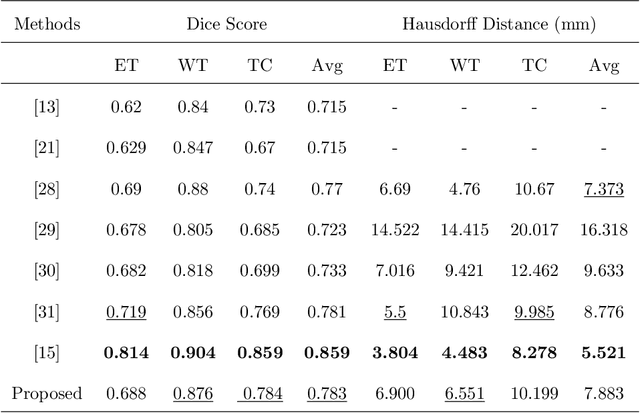
In the field of multimodal segmentation, the correlation between different modalities can be considered for improving the segmentation results. Considering the correlation between different MR modalities, in this paper, we propose a multi-modality segmentation network guided by a novel tri-attention fusion. Our network includes N model-independent encoding paths with N image sources, a tri-attention fusion block, a dual-attention fusion block, and a decoding path. The model independent encoding paths can capture modality-specific features from the N modalities. Considering that not all the features extracted from the encoders are useful for segmentation, we propose to use dual attention based fusion to re-weight the features along the modality and space paths, which can suppress less informative features and emphasize the useful ones for each modality at different positions. Since there exists a strong correlation between different modalities, based on the dual attention fusion block, we propose a correlation attention module to form the tri-attention fusion block. In the correlation attention module, a correlation description block is first used to learn the correlation between modalities and then a constraint based on the correlation is used to guide the network to learn the latent correlated features which are more relevant for segmentation. Finally, the obtained fused feature representation is projected by the decoder to obtain the segmentation results. Our experiment results tested on BraTS 2018 dataset for brain tumor segmentation demonstrate the effectiveness of our proposed method.
Learn-Morph-Infer: a new way of solving the inverse problem for brain tumor modeling
Nov 07, 2021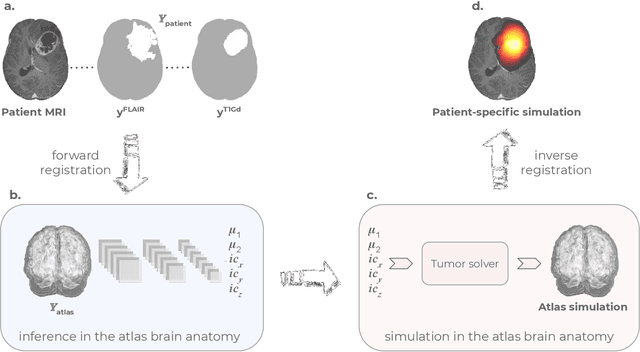
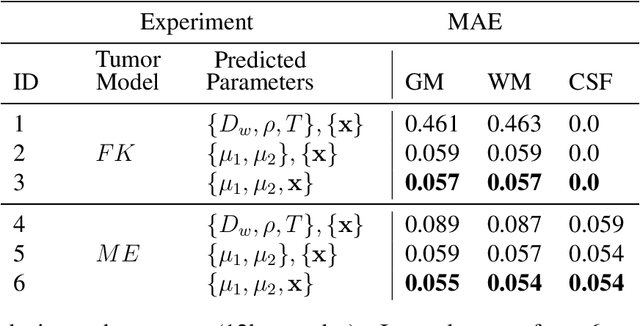
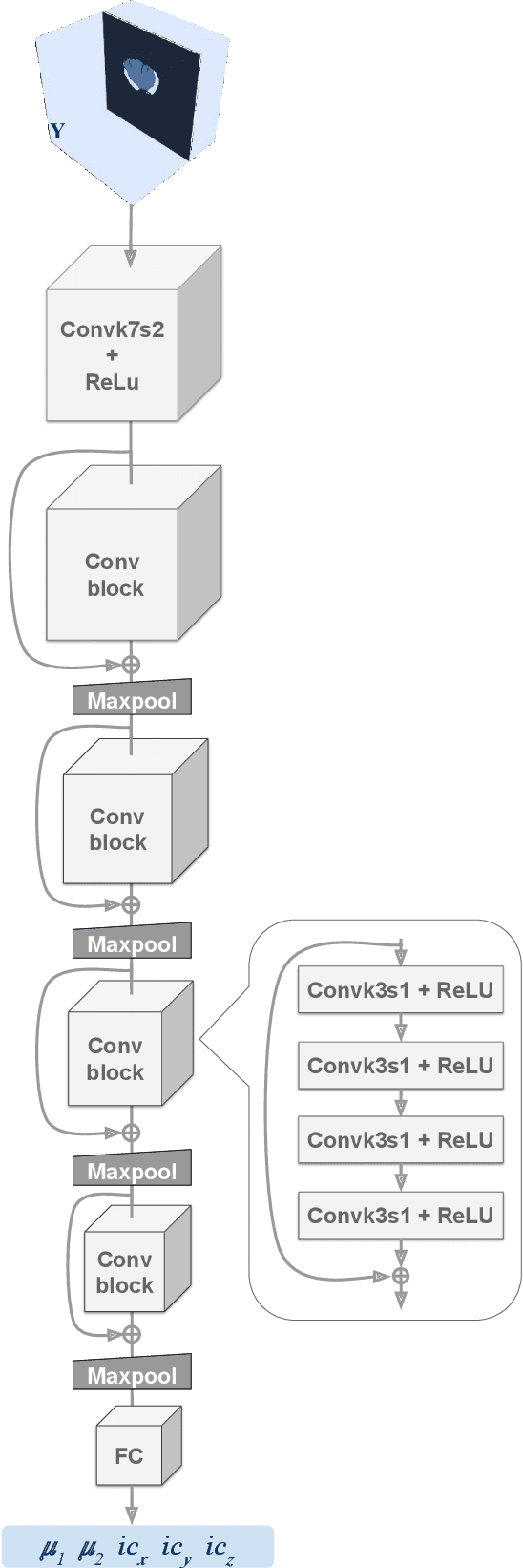

Current treatment planning of patients diagnosed with brain tumor could significantly benefit by accessing the spatial distribution of tumor cell concentration. Existing diagnostic modalities, such as magnetic-resonance imaging (MRI), contrast sufficiently well areas of high cell density. However, they do not portray areas of low concentration, which can often serve as a source for the secondary appearance of the tumor after treatment. Numerical simulations of tumor growth could complement imaging information by providing estimates of full spatial distributions of tumor cells. Over recent years a corpus of literature on medical image-based tumor modeling was published. It includes different mathematical formalisms describing the forward tumor growth model. Alongside, various parametric inference schemes were developed to perform an efficient tumor model personalization, i.e. solving the inverse problem. However, the unifying drawback of all existing approaches is the time complexity of the model personalization that prohibits a potential integration of the modeling into clinical settings. In this work, we introduce a methodology for inferring patient-specific spatial distribution of brain tumor from T1Gd and FLAIR MRI medical scans. Coined as \textit{Learn-Morph-Infer} the method achieves real-time performance in the order of minutes on widely available hardware and the compute time is stable across tumor models of different complexity, such as reaction-diffusion and reaction-advection-diffusion models. We believe the proposed inverse solution approach not only bridges the way for clinical translation of brain tumor personalization but can also be adopted to other scientific and engineering domains.
One-to-many Approach for Improving Super-Resolution
Jun 22, 2021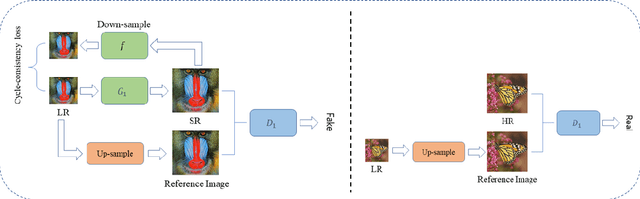
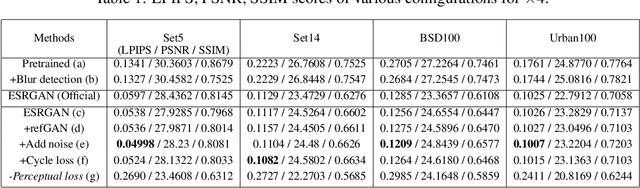
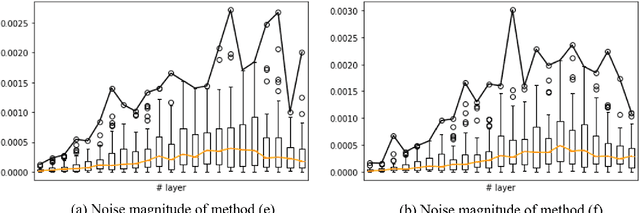
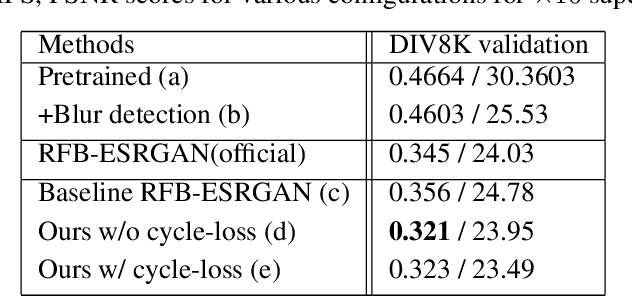
Super-resolution (SR) is a one-to-many task with multiple possible solutions. However, previous works were not concerned about this characteristic. For a one-to-many pipeline, the generator should be able to generate multiple estimates of the reconstruction, and not be penalized for generating similar and equally realistic images. To achieve this, we propose adding weighted pixel-wise noise after every Residual-in-Residual Dense Block (RRDB) to enable the generator to generate various images. We modify the strict content loss to not penalize the stochastic variation in reconstructed images as long as it has consistent content. Additionally, we observe that there are out-of-focus regions in the DIV2K, DIV8K datasets that provide unhelpful guidelines. We filter blurry regions in the training data using the method of [10]. Finally, we modify the discriminator to receive the low-resolution image as a reference image along with the target image to provide better feedback to the generator. Using our proposed methods, we were able to improve the performance of ESRGAN in x4 perceptual SR and achieve the state-of-the-art LPIPS score in x16 perceptual extreme SR.
Towards Generating Stylized Image Captions via Adversarial Training
Aug 08, 2019
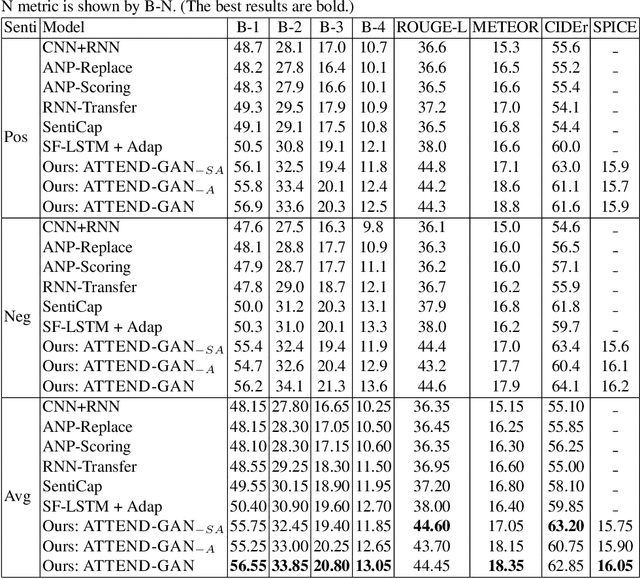
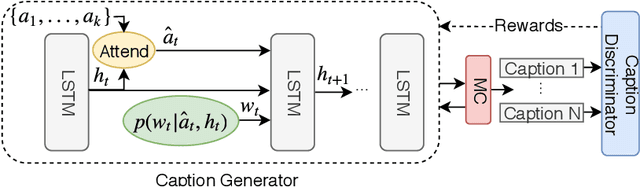
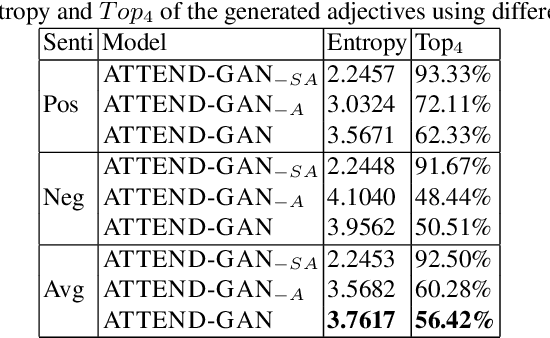
While most image captioning aims to generate objective descriptions of images, the last few years have seen work on generating visually grounded image captions which have a specific style (e.g., incorporating positive or negative sentiment). However, because the stylistic component is typically the last part of training, current models usually pay more attention to the style at the expense of accurate content description. In addition, there is a lack of variability in terms of the stylistic aspects. To address these issues, we propose an image captioning model called ATTEND-GAN which has two core components: first, an attention-based caption generator to strongly correlate different parts of an image with different parts of a caption; and second, an adversarial training mechanism to assist the caption generator to add diverse stylistic components to the generated captions. Because of these components, ATTEND-GAN can generate correlated captions as well as more human-like variability of stylistic patterns. Our system outperforms the state-of-the-art as well as a collection of our baseline models. A linguistic analysis of the generated captions demonstrates that captions generated using ATTEND-GAN have a wider range of stylistic adjectives and adjective-noun pairs.
Tracing Halpha Fibrils through Bayesian Deep Learning
Jul 16, 2021
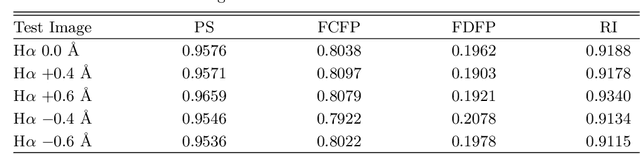
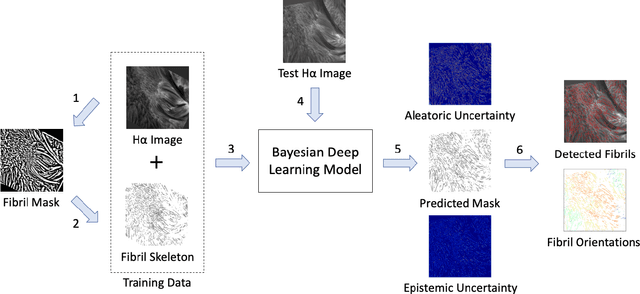
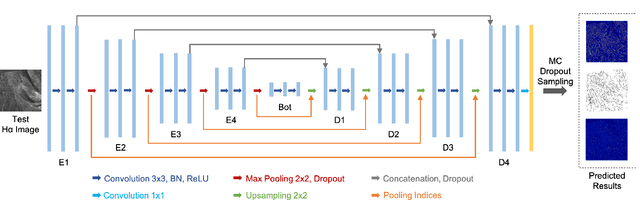
We present a new deep learning method, dubbed FibrilNet, for tracing chromospheric fibrils in Halpha images of solar observations. Our method consists of a data pre-processing component that prepares training data from a threshold-based tool, a deep learning model implemented as a Bayesian convolutional neural network for probabilistic image segmentation with uncertainty quantification to predict fibrils, and a post-processing component containing a fibril-fitting algorithm to determine fibril orientations. The FibrilNet tool is applied to high-resolution Halpha images from an active region (AR 12665) collected by the 1.6 m Goode Solar Telescope (GST) equipped with high-order adaptive optics at the Big Bear Solar Observatory (BBSO). We quantitatively assess the FibrilNet tool, comparing its image segmentation algorithm and fibril-fitting algorithm with those employed by the threshold-based tool. Our experimental results and major findings are summarized as follows. First, the image segmentation results (i.e., detected fibrils) of the two tools are quite similar, demonstrating the good learning capability of FibrilNet. Second, FibrilNet finds more accurate and smoother fibril orientation angles than the threshold-based tool. Third, FibrilNet is faster than the threshold-based tool and the uncertainty maps produced by FibrilNet not only provide a quantitative way to measure the confidence on each detected fibril, but also help identify fibril structures that are not detected by the threshold-based tool but are inferred through machine learning. Finally, we apply FibrilNet to full-disk Halpha images from other solar observatories and additional high-resolution Halpha images collected by BBSO/GST, demonstrating the tool's usability in diverse datasets.
Real-Time Activity Recognition and Intention Recognition Using a Vision-based Embedded System
Jul 27, 2021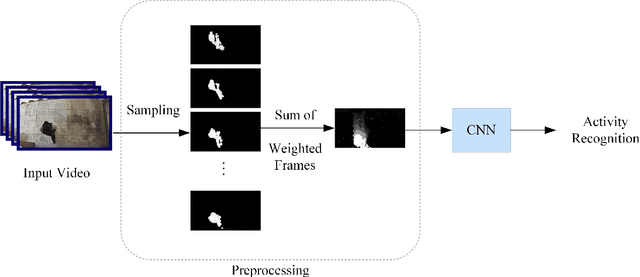
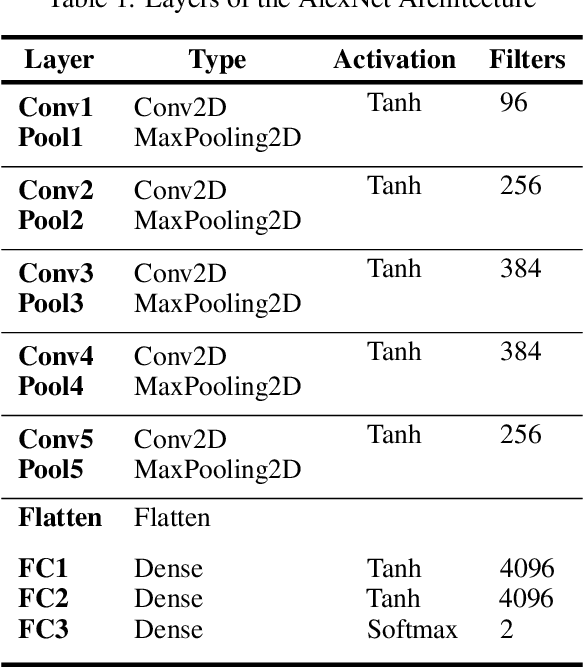
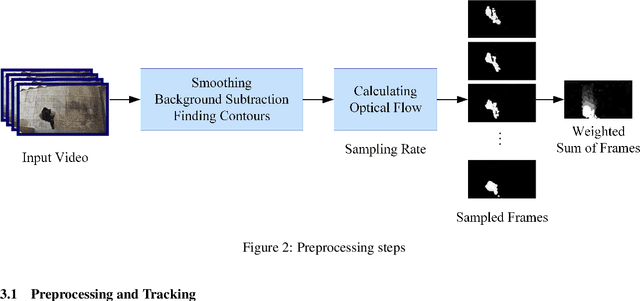
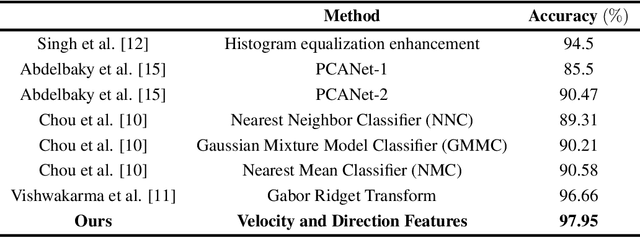
With the rapid increase in digital technologies, most fields of study include recognition of human activity and intention recognition, which are important in smart environments. In this research, we introduce a real-time activity recognition to recognize people's intentions to pass or not pass a door. This system, if applied in elevators and automatic doors will save energy and increase efficiency. For this study, data preparation is applied to combine the spatial and temporal features with the help of digital image processing principles. Nevertheless, unlike previous studies, only one AlexNet neural network is used instead of two-stream convolutional neural networks. Our embedded system was implemented with an accuracy of 98.78% on our Intention Recognition dataset. We also examined our data representation approach on other datasets, including HMDB-51, KTH, and Weizmann, and obtained accuracy of 78.48%, 97.95%, and 100%, respectively. The image recognition and neural network models were simulated and implemented using Xilinx simulators for ZCU102 board. The operating frequency of this embedded system is 333 MHz, and it works in real-time with 120 frames per second (fps).
SiWa: See into Walls via Deep UWB Radar
Oct 28, 2021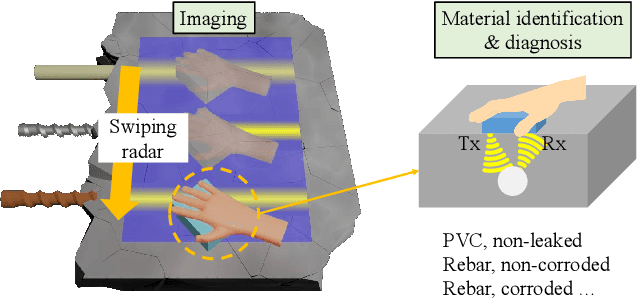


Being able to see into walls is crucial for diagnostics of building health; it enables inspections of wall structure without undermining the structural integrity. However, existing sensing devices do not seem to offer a full capability in mapping the in-wall structure while identifying their status (e.g., seepage and corrosion). In this paper, we design and implement SiWa as a low-cost and portable system for wall inspections. Built upon a customized IR-UWB radar, SiWa scans a wall as a user swipes its probe along the wall surface; it then analyzes the reflected signals to synthesize an image and also to identify the material status. Although conventional schemes exist to handle these problems individually, they require troublesome calibrations that largely prevent them from practical adoptions. To this end, we equip SiWa with a deep learning pipeline to parse the rich sensory data. With an ingenious construction and innovative training, the deep learning modules perform structural imaging and the subsequent analysis on material status, without the need for parameter tuning and calibrations. We build SiWa as a prototype and evaluate its performance via extensive experiments and field studies; results confirm that SiWa accurately maps in-wall structures, identifies their materials, and detects possible failures, suggesting a promising solution for diagnosing building health with lower effort and cost.
* 14 pages