 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Check It Again: Progressive Visual Question Answering via Visual Entailment
Jun 08, 2021
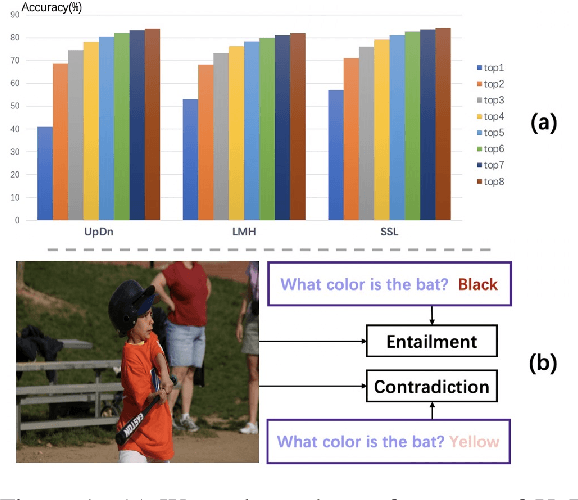
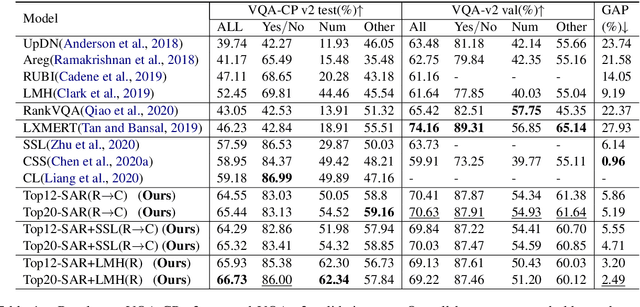
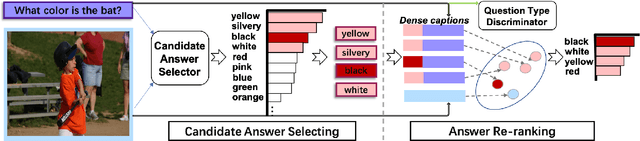
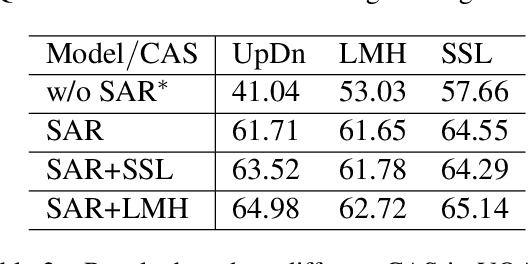
While sophisticated Visual Question Answering models have achieved remarkable success, they tend to answer questions only according to superficial correlations between question and answer. Several recent approaches have been developed to address this language priors problem. However, most of them predict the correct answer according to one best output without checking the authenticity of answers. Besides, they only explore the interaction between image and question, ignoring the semantics of candidate answers. In this paper, we propose a select-and-rerank (SAR) progressive framework based on Visual Entailment. Specifically, we first select the candidate answers relevant to the question or the image, then we rerank the candidate answers by a visual entailment task, which verifies whether the image semantically entails the synthetic statement of the question and each candidate answer. Experimental results show the effectiveness of our proposed framework, which establishes a new state-of-the-art accuracy on VQA-CP v2 with a 7.55% improvement.
Convolutional Deep Denoising Autoencoders for Radio Astronomical Images
Oct 16, 2021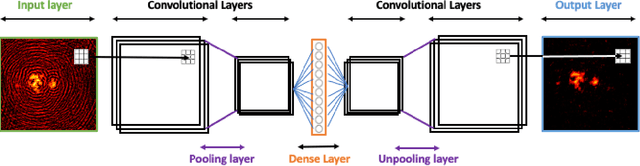
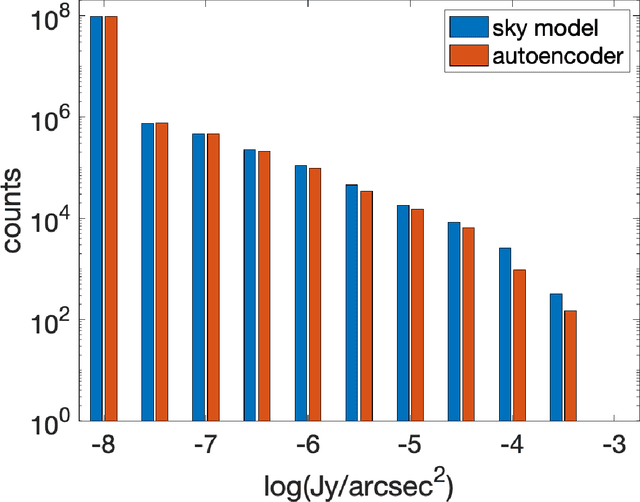
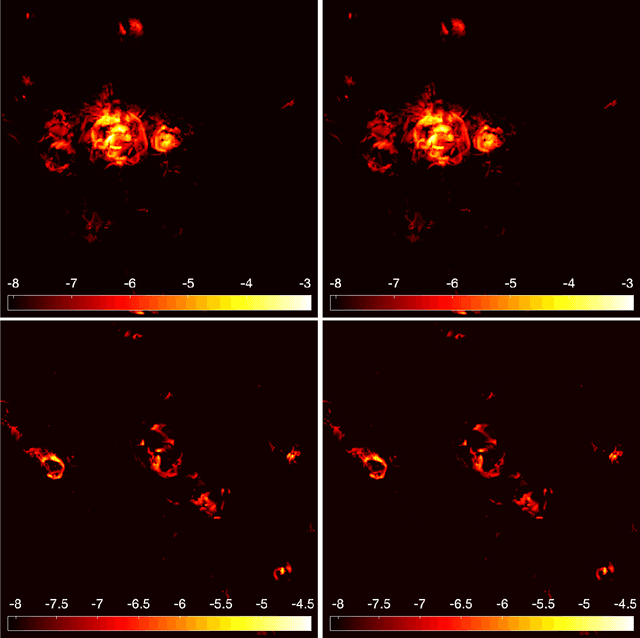
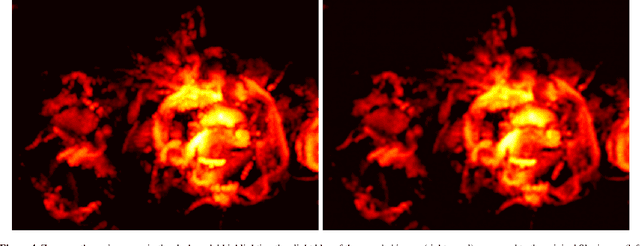
We apply a Machine Learning technique known as Convolutional Denoising Autoencoder to denoise synthetic images of state-of-the-art radio telescopes, with the goal of detecting the faint, diffused radio sources predicted to characterise the radio cosmic web. In our application, denoising is intended to address both the reduction of random instrumental noise and the minimisation of additional spurious artefacts like the sidelobes, resulting from the aperture synthesis technique. The effectiveness and the accuracy of the method are analysed for different kinds of corrupted input images, together with its computational performance. Specific attention has been devoted to create realistic mock observations for the training, exploiting the outcomes of cosmological numerical simulations, to generate images corresponding to LOFAR HBA 8 hours observations at 150 MHz. Our autoencoder can effectively denoise complex images identifying and extracting faint objects at the limits of the instrumental sensitivity. The method can efficiently scale on large datasets, exploiting high performance computing solutions, in a fully automated way (i.e. no human supervision is required after training). It can accurately perform image segmentation, identifying low brightness outskirts of diffused sources, proving to be a viable solution for detecting challenging extended objects hidden in noisy radio observations.
Object Disparity
Aug 18, 2021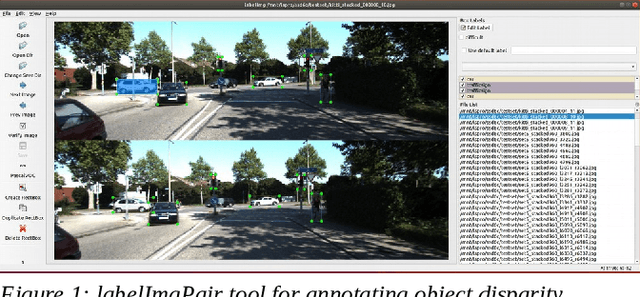
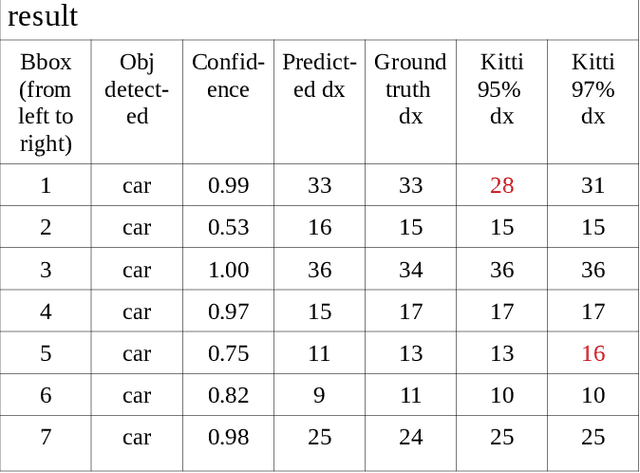
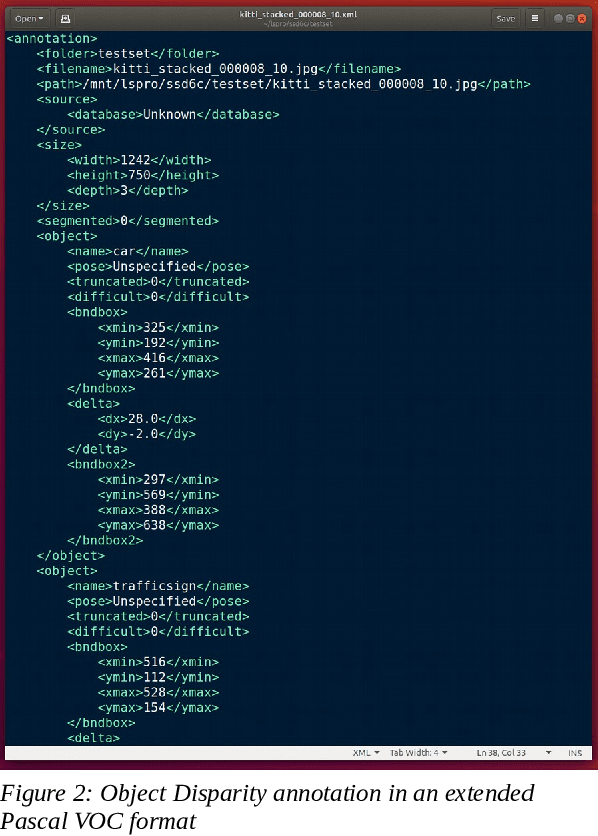
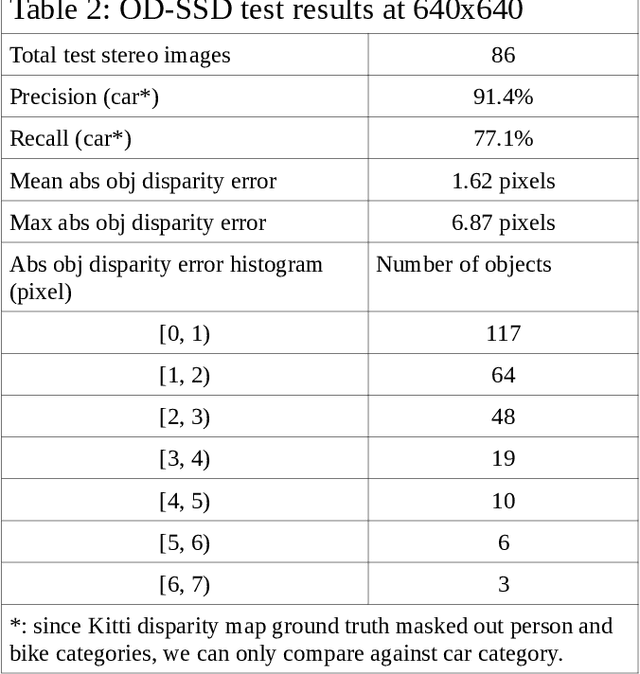
Most of stereo vision works are focusing on computing the dense pixel disparity of a given pair of left and right images. A camera pair usually required lens undistortion and stereo calibration to provide an undistorted epipolar line calibrated image pair for accurate dense pixel disparity computation. Due to noise, object occlusion, repetitive or lack of texture and limitation of matching algorithms, the pixel disparity accuracy usually suffers the most at those object boundary areas. Although statistically the total number of pixel disparity errors might be low (under 2% according to the Kitti Vision Benchmark of current top ranking algorithms), the percentage of these disparity errors at object boundaries are very high. This renders the subsequence 3D object distance detection with much lower accuracy than desired. This paper proposed a different approach for solving a 3D object distance detection by detecting object disparity directly without going through a dense pixel disparity computation. An example squeezenet Object Disparity-SSD (OD-SSD) was constructed to demonstrate an efficient object disparity detection with comparable accuracy compared with Kitti dataset pixel disparity ground truth. Further training and testing results with mixed image dataset captured by several different stereo systems may suggest that an OD-SSD might be agnostic to stereo system parameters such as a baseline, FOV, lens distortion, even left/right camera epipolar line misalignment.
New SAR target recognition based on YOLO and very deep multi-canonical correlation analysis
Oct 28, 2021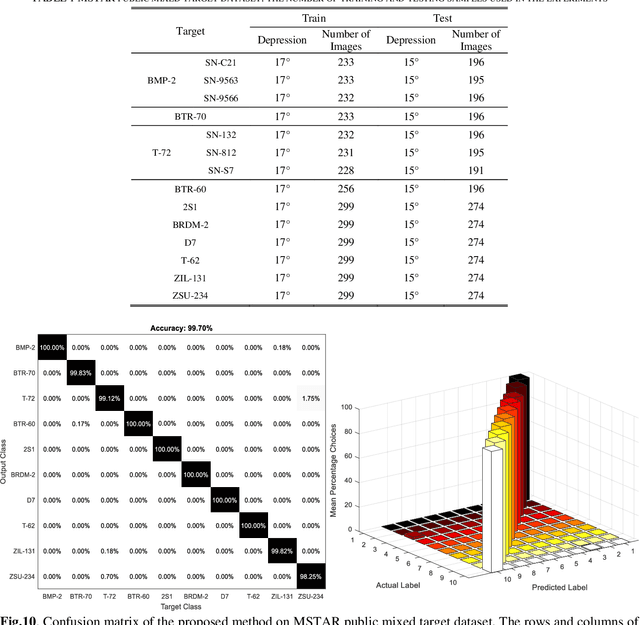
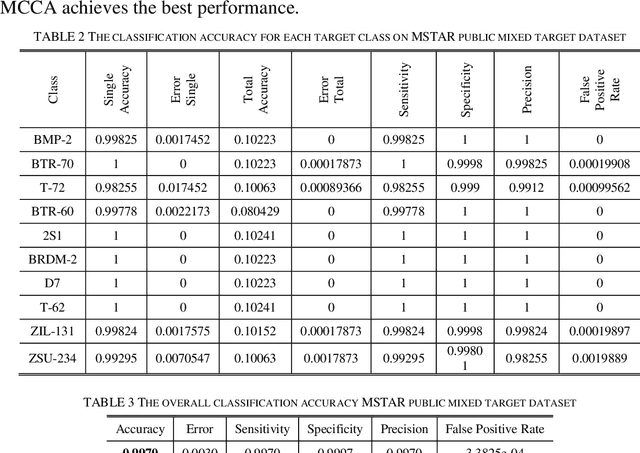
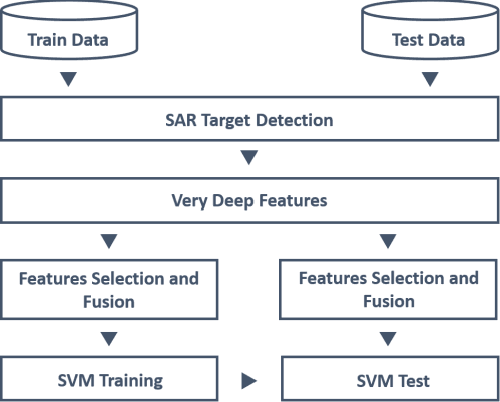
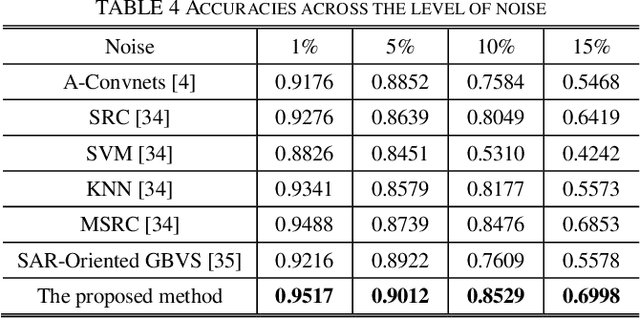
Synthetic Aperture Radar (SAR) images are prone to be contaminated by noise, which makes it very difficult to perform target recognition in SAR images. Inspired by great success of very deep convolutional neural networks (CNNs), this paper proposes a robust feature extraction method for SAR image target classification by adaptively fusing effective features from different CNN layers. First, YOLOv4 network is fine-tuned to detect the targets from the respective MF SAR target images. Second, a very deep CNN is trained from scratch on the moving and stationary target acquisition and recognition (MSTAR) database by using small filters throughout the whole net to reduce the speckle noise. Besides, using small-size convolution filters decreases the number of parameters in each layer and, therefore, reduces computation cost as the CNN goes deeper. The resulting CNN model is capable of extracting very deep features from the target images without performing any noise filtering or pre-processing techniques. Third, our approach proposes to use the multi-canonical correlation analysis (MCCA) to adaptively learn CNN features from different layers such that the resulting representations are highly linearly correlated and therefore can achieve better classification accuracy even if a simple linear support vector machine is used. Experimental results on the MSTAR dataset demonstrate that the proposed method outperforms the state-of-the-art methods.
MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning
Oct 28, 2021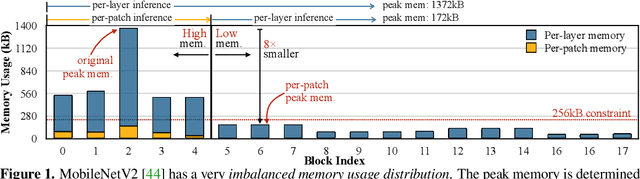

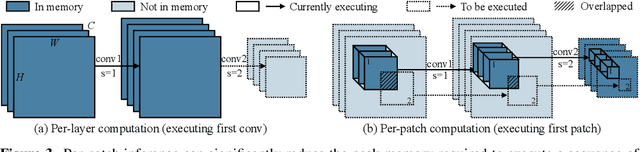

Tiny deep learning on microcontroller units (MCUs) is challenging due to the limited memory size. We find that the memory bottleneck is due to the imbalanced memory distribution in convolutional neural network (CNN) designs: the first several blocks have an order of magnitude larger memory usage than the rest of the network. To alleviate this issue, we propose a generic patch-by-patch inference scheduling, which operates only on a small spatial region of the feature map and significantly cuts down the peak memory. However, naive implementation brings overlapping patches and computation overhead. We further propose network redistribution to shift the receptive field and FLOPs to the later stage and reduce the computation overhead. Manually redistributing the receptive field is difficult. We automate the process with neural architecture search to jointly optimize the neural architecture and inference scheduling, leading to MCUNetV2. Patch-based inference effectively reduces the peak memory usage of existing networks by 4-8x. Co-designed with neural networks, MCUNetV2 sets a record ImageNet accuracy on MCU (71.8%), and achieves >90% accuracy on the visual wake words dataset under only 32kB SRAM. MCUNetV2 also unblocks object detection on tiny devices, achieving 16.9% higher mAP on Pascal VOC compared to the state-of-the-art result. Our study largely addressed the memory bottleneck in tinyML and paved the way for various vision applications beyond image classification.
Scatterbrain: Unifying Sparse and Low-rank Attention Approximation
Oct 28, 2021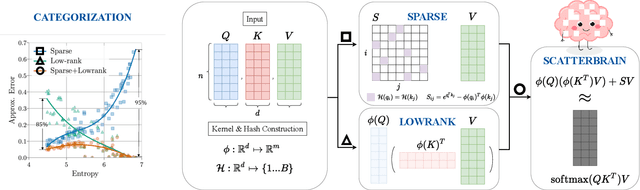


Recent advances in efficient Transformers have exploited either the sparsity or low-rank properties of attention matrices to reduce the computational and memory bottlenecks of modeling long sequences. However, it is still challenging to balance the trade-off between model quality and efficiency to perform a one-size-fits-all approximation for different tasks. To better understand this trade-off, we observe that sparse and low-rank approximations excel in different regimes, determined by the softmax temperature in attention, and sparse + low-rank can outperform each individually. Inspired by the classical robust-PCA algorithm for sparse and low-rank decomposition, we propose Scatterbrain, a novel way to unify sparse (via locality sensitive hashing) and low-rank (via kernel feature map) attention for accurate and efficient approximation. The estimation is unbiased with provably low error. We empirically show that Scatterbrain can achieve 2.1x lower error than baselines when serving as a drop-in replacement in BigGAN image generation and pre-trained T2T-ViT. On a pre-trained T2T Vision transformer, even without fine-tuning, Scatterbrain can reduce 98% of attention memory at the cost of only 1% drop in accuracy. We demonstrate Scatterbrain for end-to-end training with up to 4 points better perplexity and 5 points better average accuracy than sparse or low-rank efficient transformers on language modeling and long-range-arena tasks.
Improving Object Detection by Label Assignment Distillation
Aug 24, 2021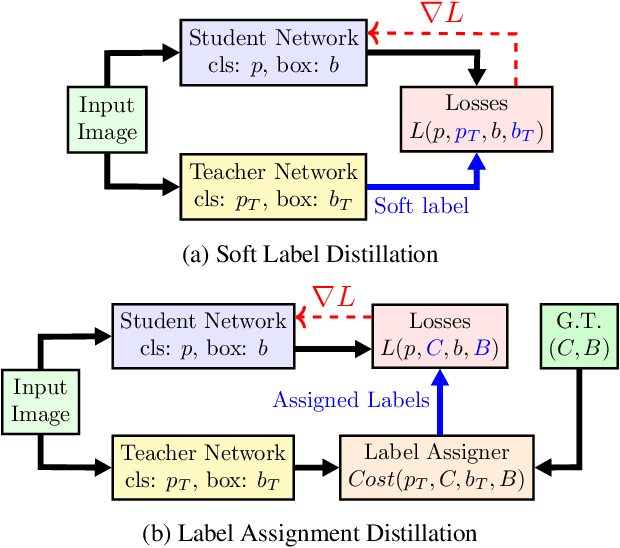
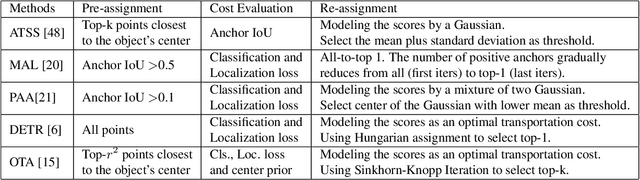
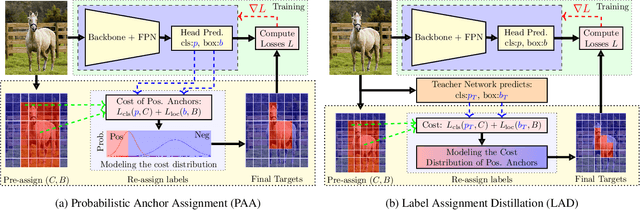
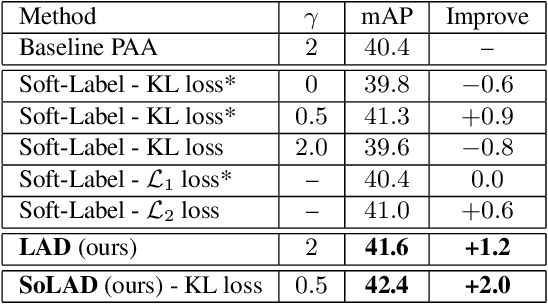
Label assignment in object detection aims to assign targets, foreground or background, to sampled regions in an image. Unlike labeling for image classification, this problem is not well defined due to the object's bounding box. In this paper, we investigate the problem from a perspective of distillation, hence we call Label Assignment Distillation (LAD). Our initial motivation is very simple, we use a teacher network to generate labels for the student. This can be achieved in two ways: either using the teacher's prediction as the direct targets (soft label), or through the hard labels dynamically assigned by the teacher (LAD). Our experiments reveal that: (i) LAD is more effective than soft-label, but they are complementary. (ii) Using LAD, a smaller teacher can also improve a larger student significantly, while soft-label can't. We then introduce Co-learning LAD, in which two networks simultaneously learn from scratch and the role of teacher and student are dynamically interchanged. Using PAA-ResNet50 as a teacher, our LAD techniques can improve detectors PAA-ResNet101 and PAA-ResNeXt101 to $46 \rm AP$ and $47.5\rm AP$ on the COCO test-dev set. With a strong teacher PAA-SwinB, we improve the PAA-ResNet50 to $43.9\rm AP$ with only \1x schedule training, and PAA-ResNet101 to $47.9\rm AP$, significantly surpassing the current methods. Our source code and checkpoints will be released at https://github.com/cybercore-co-ltd/CoLAD_paper.
Image-to-Image Translation with Multi-Path Consistency Regularization
May 29, 2019

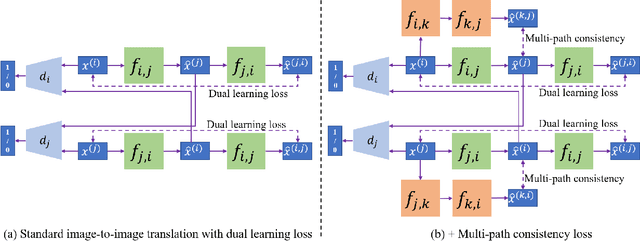

Image translation across different domains has attracted much attention in both machine learning and computer vision communities. Taking the translation from source domain $\mathcal{D}_s$ to target domain $\mathcal{D}_t$ as an example, existing algorithms mainly rely on two kinds of loss for training: One is the discrimination loss, which is used to differentiate images generated by the models and natural images; the other is the reconstruction loss, which measures the difference between an original image and the reconstructed version through $\mathcal{D}_s\to\mathcal{D}_t\to\mathcal{D}_s$ translation. In this work, we introduce a new kind of loss, multi-path consistency loss, which evaluates the differences between direct translation $\mathcal{D}_s\to\mathcal{D}_t$ and indirect translation $\mathcal{D}_s\to\mathcal{D}_a\to\mathcal{D}_t$ with $\mathcal{D}_a$ as an auxiliary domain, to regularize training. For multi-domain translation (at least, three) which focuses on building translation models between any two domains, at each training iteration, we randomly select three domains, set them respectively as the source, auxiliary and target domains, build the multi-path consistency loss and optimize the network. For two-domain translation, we need to introduce an additional auxiliary domain and construct the multi-path consistency loss. We conduct various experiments to demonstrate the effectiveness of our proposed methods, including face-to-face translation, paint-to-photo translation, and de-raining/de-noising translation.
Cell Detection from Imperfect Annotation by Pseudo Label Selection Using P-classification
Jul 20, 2021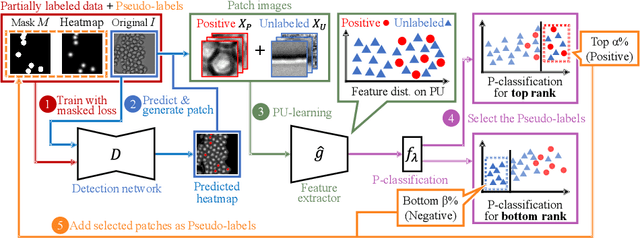
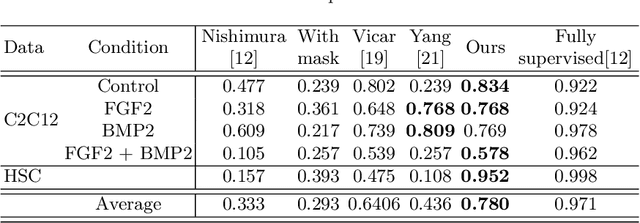
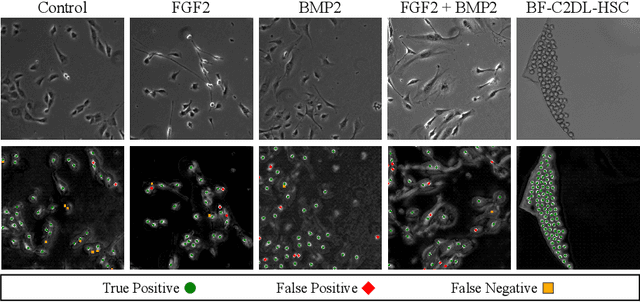
Cell detection is an essential task in cell image analysis. Recent deep learning-based detection methods have achieved very promising results. In general, these methods require exhaustively annotating the cells in an entire image. If some of the cells are not annotated (imperfect annotation), the detection performance significantly degrades due to noisy labels. This often occurs in real collaborations with biologists and even in public data-sets. Our proposed method takes a pseudo labeling approach for cell detection from imperfect annotated data. A detection convolutional neural network (CNN) trained using such missing labeled data often produces over-detection. We treat partially labeled cells as positive samples and the detected positions except for the labeled cell as unlabeled samples. Then we select reliable pseudo labels from unlabeled data using recent machine learning techniques; positive-and-unlabeled (PU) learning and P-classification. Experiments using microscopy images for five different conditions demonstrate the effectiveness of the proposed method.
PlaneTR: Structure-Guided Transformers for 3D Plane Recovery
Jul 27, 2021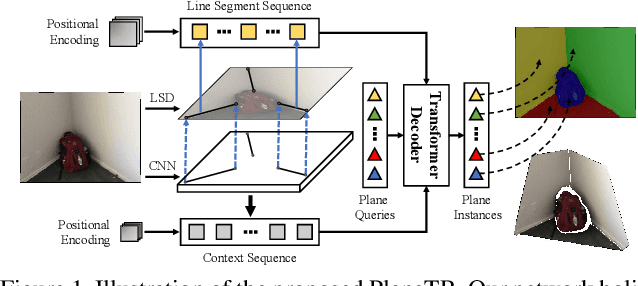
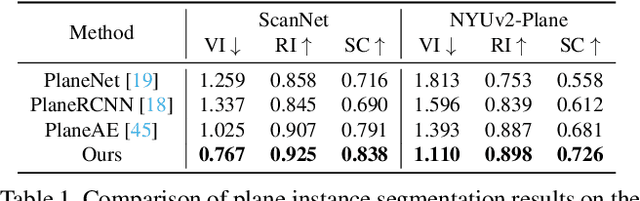
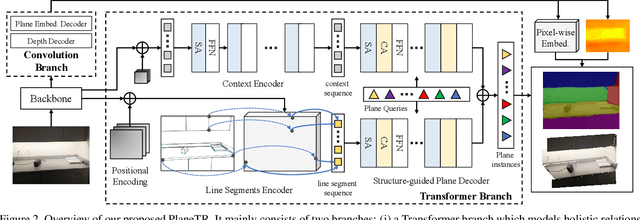
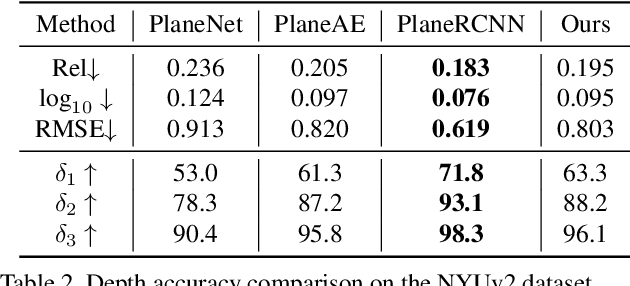
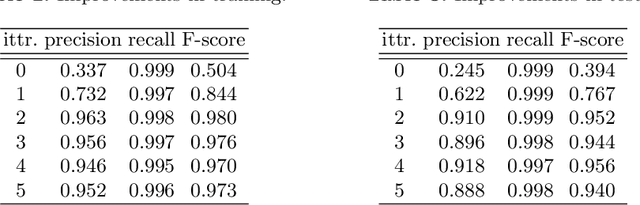
This paper presents a neural network built upon Transformers, namely PlaneTR, to simultaneously detect and reconstruct planes from a single image. Different from previous methods, PlaneTR jointly leverages the context information and the geometric structures in a sequence-to-sequence way to holistically detect plane instances in one forward pass. Specifically, we represent the geometric structures as line segments and conduct the network with three main components: (i) context and line segments encoders, (ii) a structure-guided plane decoder, (iii) a pixel-wise plane embedding decoder. Given an image and its detected line segments, PlaneTR generates the context and line segment sequences via two specially designed encoders and then feeds them into a Transformers-based decoder to directly predict a sequence of plane instances by simultaneously considering the context and global structure cues. Finally, the pixel-wise embeddings are computed to assign each pixel to one predicted plane instance which is nearest to it in embedding space. Comprehensive experiments demonstrate that PlaneTR achieves a state-of-the-art performance on the ScanNet and NYUv2 datasets.