 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive residual learning for single image dehazing
Mar 14, 2021
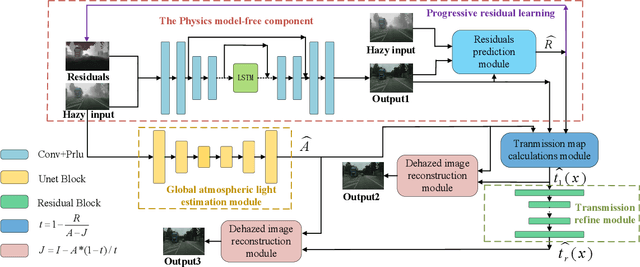



The recent physical model-free dehazing methods have achieved state-of-the-art performances. However, without the guidance of physical models, the performances degrade rapidly when applied to real scenarios due to the unavailable or insufficient data problems. On the other hand, the physical model-based methods have better interpretability but suffer from multi-objective optimizations of parameters, which may lead to sub-optimal dehazing results. In this paper, a progressive residual learning strategy has been proposed to combine the physical model-free dehazing process with reformulated scattering model-based dehazing operations, which enjoys the merits of dehazing methods in both categories. Specifically, the global atmosphere light and transmission maps are interactively optimized with the aid of accurate residual information and preliminary dehazed restorations from the initial physical model-free dehazing process. The proposed method performs favorably against the state-of-the-art methods on public dehazing benchmarks with better model interpretability and adaptivity for complex hazy data.
Blind Universal Bayesian Image Denoising with Gaussian Noise Level Learning
Jul 05, 2019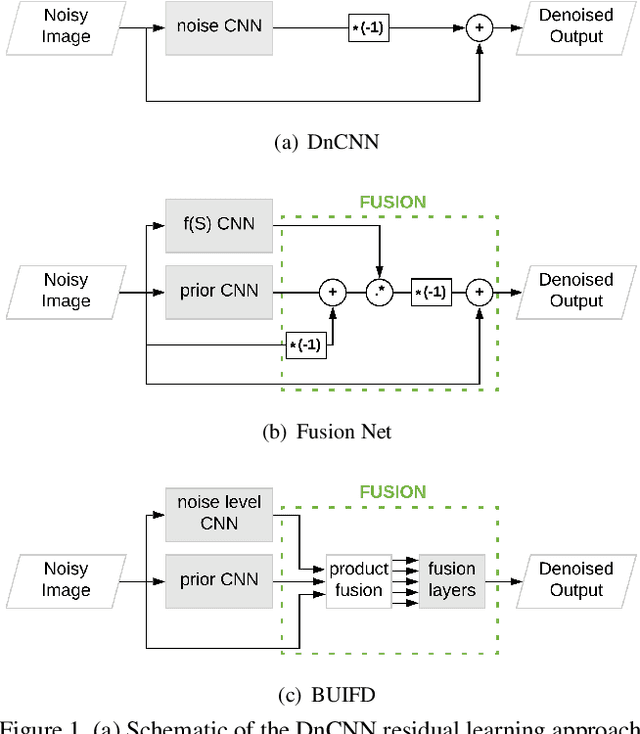

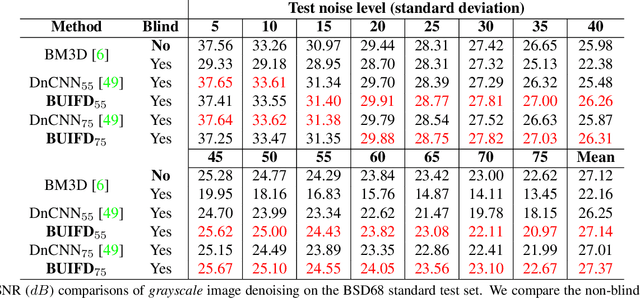

Blind and universal image denoising consists of a unique model that denoises images with any level of noise. It is especially practical as noise levels do not need to be known when the model is developed or at test time. We propose a theoretically-grounded blind and universal deep learning image denoiser for Gaussian noise. Our network is based on an optimal denoising solution, which we call fusion denoising. It is derived theoretically with a Gaussian image prior assumption. Synthetic experiments show our network's generalization strength to unseen noise levels. We also adapt the fusion denoising network architecture for real image denoising. Our approach improves real-world grayscale image denoising PSNR results by up to $0.7dB$ for training noise levels and by up to $2.82dB$ on noise levels not seen during training. It also improves state-of-the-art color image denoising performance on every single noise level, by an average of $0.1dB$, whether trained on or not.
Deep Learning Strategies for Industrial Surface Defect Detection Systems
Sep 23, 2021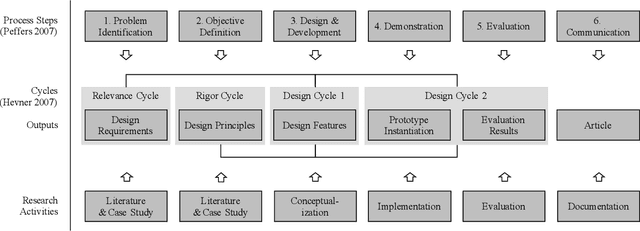

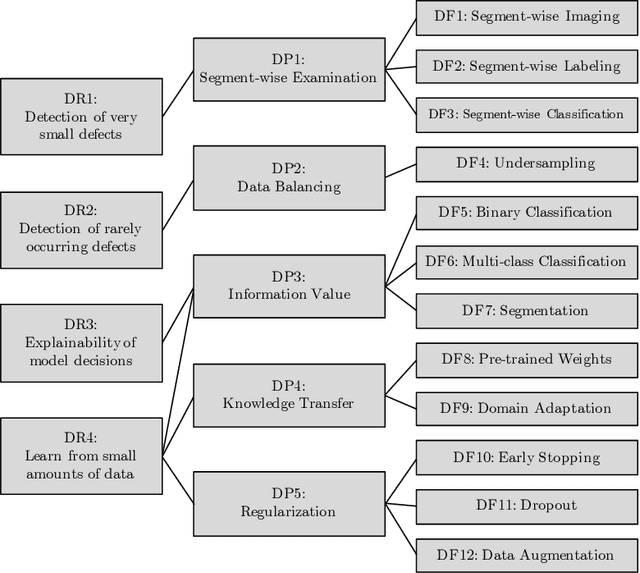
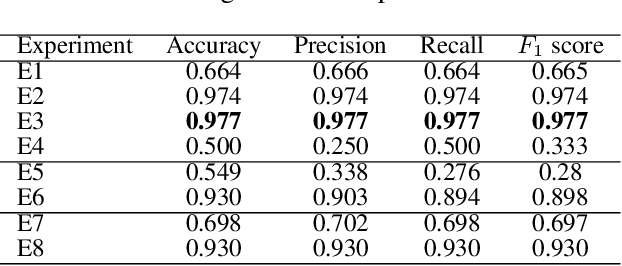
Deep learning methods have proven to outperform traditional computer vision methods in various areas of image processing. However, the application of deep learning in industrial surface defect detection systems is challenging due to the insufficient amount of training data, the expensive data generation process, the small size, and the rare occurrence of surface defects. From literature and a polymer products manufacturing use case, we identify design requirements which reflect the aforementioned challenges. Addressing these, we conceptualize design principles and features informed by deep learning research. Finally, we instantiate and evaluate the gained design knowledge in the form of actionable guidelines and strategies based on an industrial surface defect detection use case. This article, therefore, contributes to academia as well as practice by (1) systematically identifying challenges for the industrial application of deep learning-based surface defect detection, (2) strategies to overcome these, and (3) an experimental case study assessing the strategies' applicability and usefulness.
HUMBI: A Large Multiview Dataset of Human Body Expressions and Benchmark Challenge
Sep 30, 2021
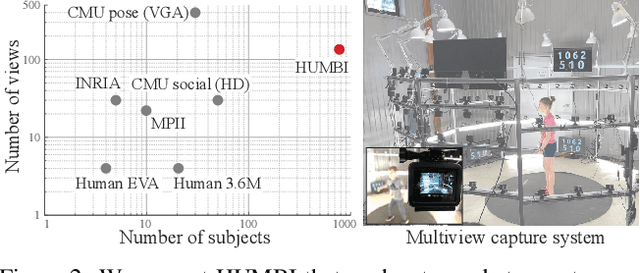
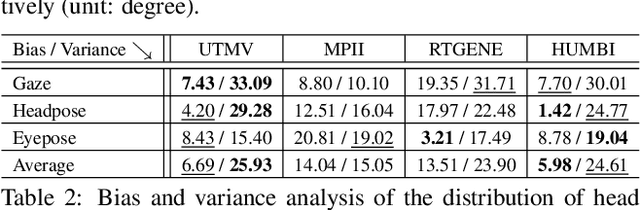
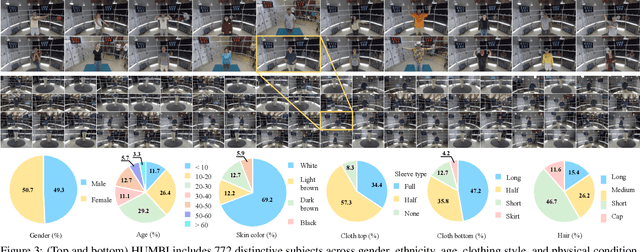
This paper presents a new large multiview dataset called HUMBI for human body expressions with natural clothing. The goal of HUMBI is to facilitate modeling view-specific appearance and geometry of five primary body signals including gaze, face, hand, body, and garment from assorted people. 107 synchronized HD cameras are used to capture 772 distinctive subjects across gender, ethnicity, age, and style. With the multiview image streams, we reconstruct high fidelity body expressions using 3D mesh models, which allows representing view-specific appearance. We demonstrate that HUMBI is highly effective in learning and reconstructing a complete human model and is complementary to the existing datasets of human body expressions with limited views and subjects such as MPII-Gaze, Multi-PIE, Human3.6M, and Panoptic Studio datasets. Based on HUMBI, we formulate a new benchmark challenge of a pose-guided appearance rendering task that aims to substantially extend photorealism in modeling diverse human expressions in 3D, which is the key enabling factor of authentic social tele-presence. HUMBI is publicly available at http://humbi-data.net
Segmentation-Aware Hyperspectral Image Classification
May 22, 2019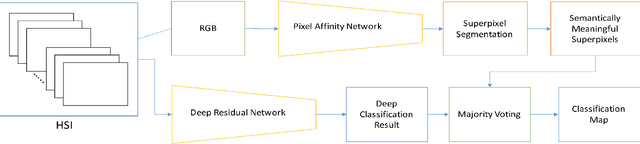


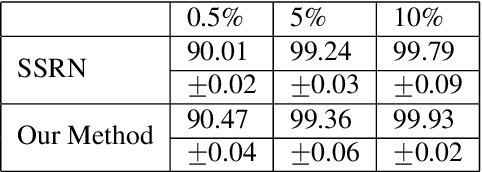
In this paper, we propose an unified hyperspectral image classification method which takes three-dimensional hyperspectral data cube as an input and produces a classification map. In the proposed method, a deep neural network which uses spectral and spatial information together with residual connections, and pixel affinity network based segmentation-aware superpixels are used together. In the architecture, segmentation-aware superpixels run on the initial classification map of deep residual network, and apply majority voting on obtained results. Experimental results show that our propoped method yields state-of-the-art results in two benchmark datasets. Moreover, we also show that the segmentation-aware superpixels have great contribution to the success of hyperspectral image classification methods in cases where training data is insufficient.
Seeing Glass: Joint Point Cloud and Depth Completion for Transparent Objects
Sep 30, 2021
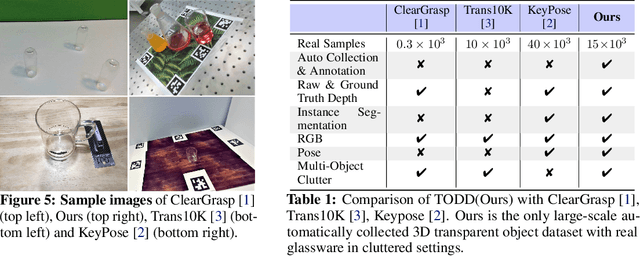
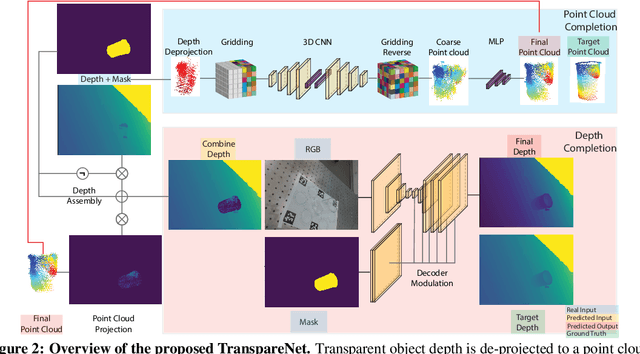
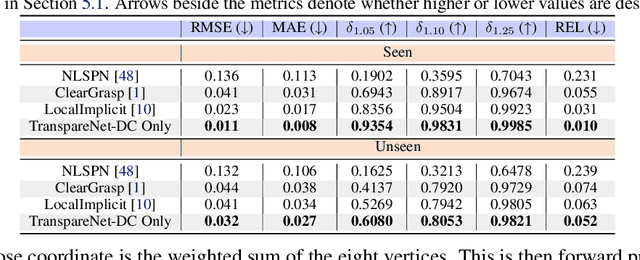
The basis of many object manipulation algorithms is RGB-D input. Yet, commodity RGB-D sensors can only provide distorted depth maps for a wide range of transparent objects due light refraction and absorption. To tackle the perception challenges posed by transparent objects, we propose TranspareNet, a joint point cloud and depth completion method, with the ability to complete the depth of transparent objects in cluttered and complex scenes, even with partially filled fluid contents within the vessels. To address the shortcomings of existing transparent object data collection schemes in literature, we also propose an automated dataset creation workflow that consists of robot-controlled image collection and vision-based automatic annotation. Through this automated workflow, we created Toronto Transparent Objects Depth Dataset (TODD), which consists of nearly 15000 RGB-D images. Our experimental evaluation demonstrates that TranspareNet outperforms existing state-of-the-art depth completion methods on multiple datasets, including ClearGrasp, and that it also handles cluttered scenes when trained on TODD. Code and dataset will be released at https://www.pair.toronto.edu/TranspareNet/
Directional GAN: A Novel Conditioning Strategy for Generative Networks
May 13, 2021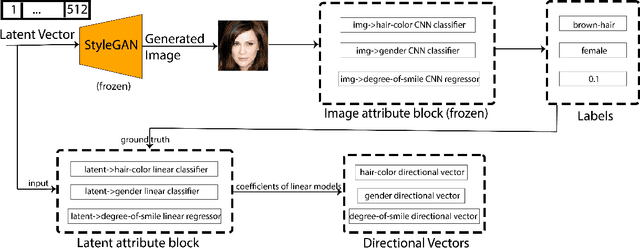

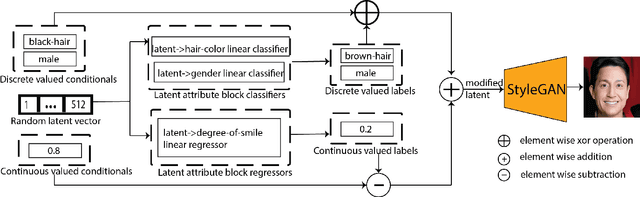
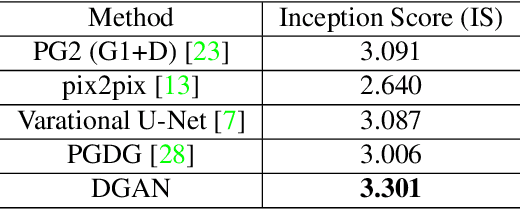
Image content is a predominant factor in marketing campaigns, websites and banners. Today, marketers and designers spend considerable time and money in generating such professional quality content. We take a step towards simplifying this process using Generative Adversarial Networks (GANs). We propose a simple and novel conditioning strategy which allows generation of images conditioned on given semantic attributes using a generator trained for an unconditional image generation task. Our approach is based on modifying latent vectors, using directional vectors of relevant semantic attributes in latent space. Our method is designed to work with both discrete (binary and multi-class) and continuous image attributes. We show the applicability of our proposed approach, named Directional GAN, on multiple public datasets, with an average accuracy of 86.4% across different attributes.
Direct Neural Network 3D Image Reconstruction of Radon Encoded Data
Aug 19, 2019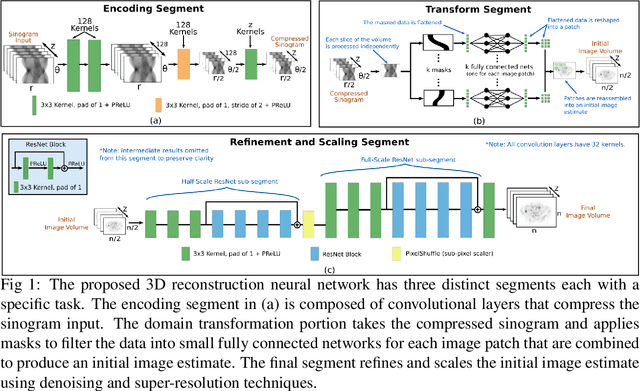
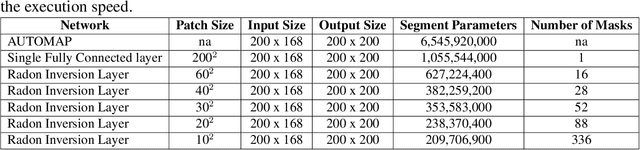
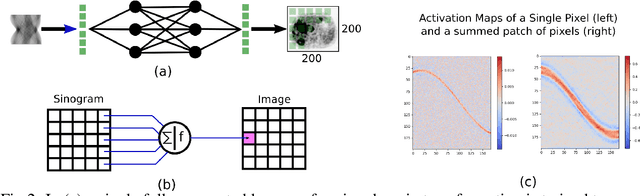

Neural network image reconstruction directly from measurement data is a growing field of research, but until now has been limited to producing small (e.g. 128x128) 2D images by the large memory requirements of the previously suggested networks. In order to facilitate further research with direct reconstruction, we developed a more efficient network capable of 3D reconstruction of Radon encoded data with a relatively large image matrix (e.g. 400x400). Our proposed network is able to produce image quality comparable to the benchmark Ordered Subsets Expectation Maximization (OSEM) algorithm. We address the most memory intensive aspect of transforming the data from sinogram space to image space through a specially designed Radon inversion layer. We insert this layer between an initial network segment designed to encode the sinogram input and an output segment designed to refine and scale the initial image estimate to produce the final image. We demonstrate 3D reconstructions comparable to OSEM for 1, 4, 8 and 16 slices with no modifications to the network's architecture, capacity or hyper-parameters on a data set of simulated PET whole-body scans. When batch operations are considered, this network can reconstruct an entire PET whole-body volume in a single pass or about one second. Although results in this paper are on PET data, the proposed methods would be equally applicable to X-ray CT or any other Radon encoded measurement data.
Deep Convolutional Neural Network for Low Projection SPECT Imaging Reconstruction
Aug 09, 2021



In this paper, we present a novel method for tomographic image reconstruction in SPECT imaging with a low number of projections. Deep convolutional neural networks (CNN) are employed in the new reconstruction method. Projection data from software phantoms were used to train the CNN network. For evaluation of the efficacy of the proposed method, software phantoms and hardware phantoms based on the FOV SPECT system were used. The resulting tomographic images are compared to those produced by the "Maximum Likelihood Expectation Maximisation" (MLEM).
Cross-View Image Synthesis with Deformable Convolution and Attention Mechanism
Jul 20, 2020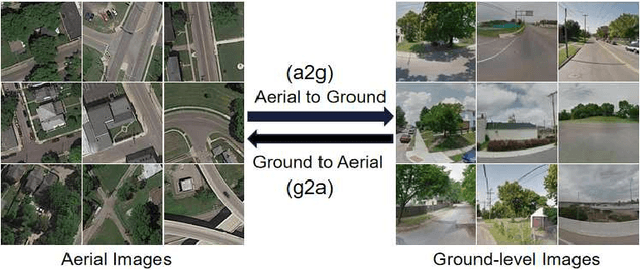
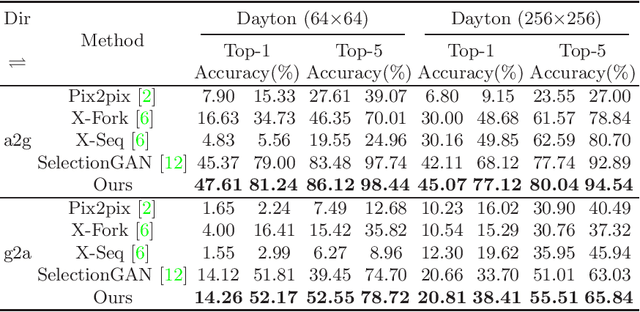
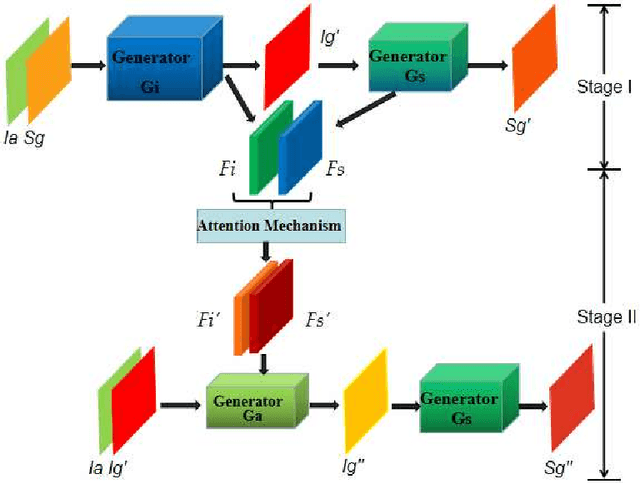
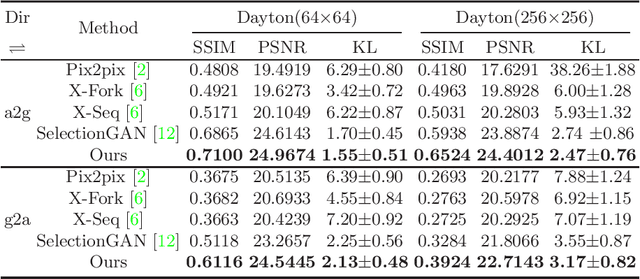
Learning to generate natural scenes has always been a daunting task in computer vision. This is even more laborious when generating images with very different views. When the views are very different, the view fields have little overlap or objects are occluded, leading the task very challenging. In this paper, we propose to use Generative Adversarial Networks(GANs) based on a deformable convolution and attention mechanism to solve the problem of cross-view image synthesis (see Fig.1). It is difficult to understand and transform scenes appearance and semantic information from another view, thus we use deformed convolution in the U-net network to improve the network's ability to extract features of objects at different scales. Moreover, to better learn the correspondence between images from different views, we apply an attention mechanism to refine the intermediate feature map thus generating more realistic images. A large number of experiments on different size images on the Dayton dataset[1] show that our model can produce better results than state-of-the-art methods.