 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-View Image Synthesis with Deformable Convolution and Attention Mechanism
Jul 20, 2020
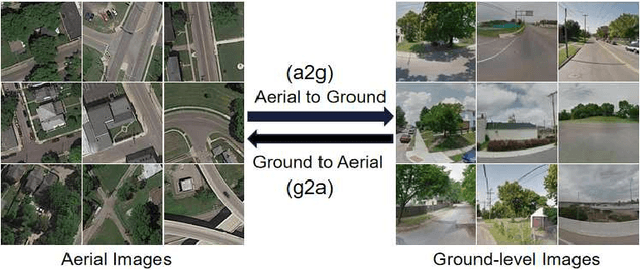
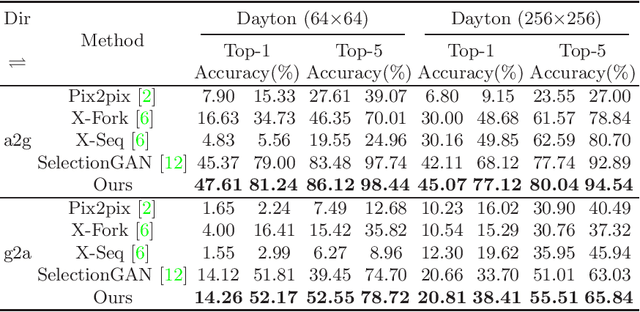
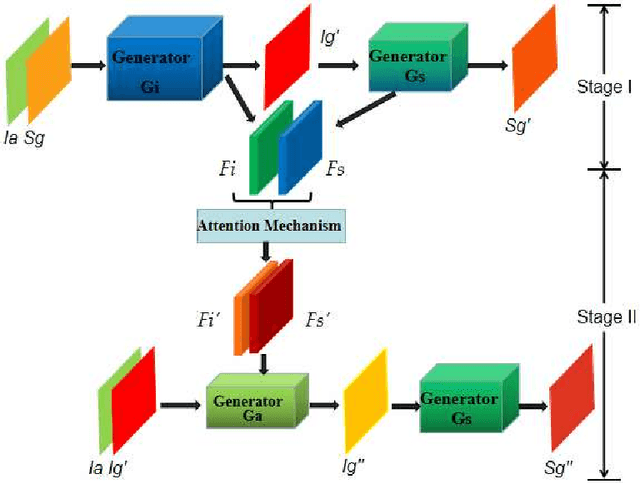
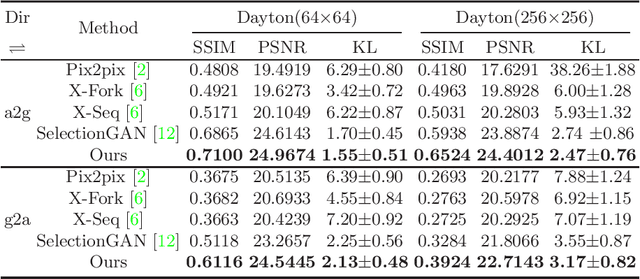
Learning to generate natural scenes has always been a daunting task in computer vision. This is even more laborious when generating images with very different views. When the views are very different, the view fields have little overlap or objects are occluded, leading the task very challenging. In this paper, we propose to use Generative Adversarial Networks(GANs) based on a deformable convolution and attention mechanism to solve the problem of cross-view image synthesis (see Fig.1). It is difficult to understand and transform scenes appearance and semantic information from another view, thus we use deformed convolution in the U-net network to improve the network's ability to extract features of objects at different scales. Moreover, to better learn the correspondence between images from different views, we apply an attention mechanism to refine the intermediate feature map thus generating more realistic images. A large number of experiments on different size images on the Dayton dataset[1] show that our model can produce better results than state-of-the-art methods.
Model-based Behavioral Cloning with Future Image Similarity Learning
Oct 08, 2019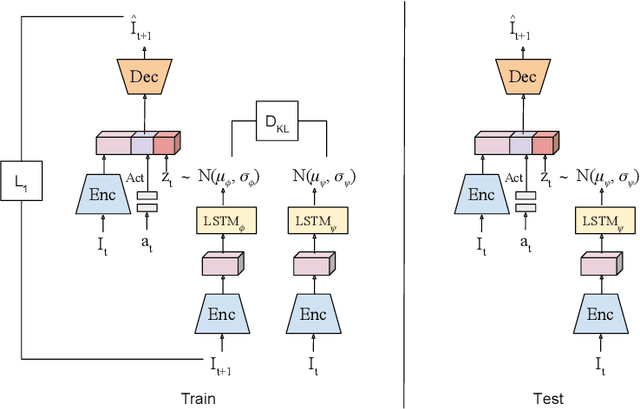


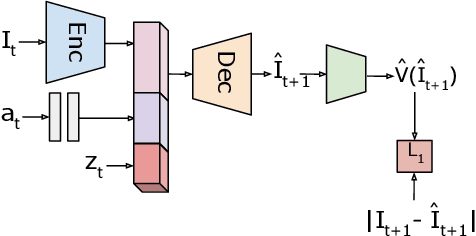
We present a visual imitation learning framework that enables learning of robot action policies solely based on expert samples without any robot trials. Robot exploration and on-policy trials in a real-world environment could often be expensive/dangerous. We present a new approach to address this problem by learning a future scene prediction model solely on a collection of expert trajectories consisting of unlabeled example videos and actions, and by enabling generalized action cloning using future image similarity. The robot learns to visually predict the consequences of taking an action, and obtains the policy by evaluating how similar the predicted future image is to an expert image. We develop a stochastic action-conditioned convolutional autoencoder, and present how we take advantage of future images for robot learning. We conduct experiments in simulated and real-life environments using a ground mobility robot with and without obstacles, and compare our models to multiple baseline methods.
Full-color photon-counting single-pixel imaging
Sep 06, 2021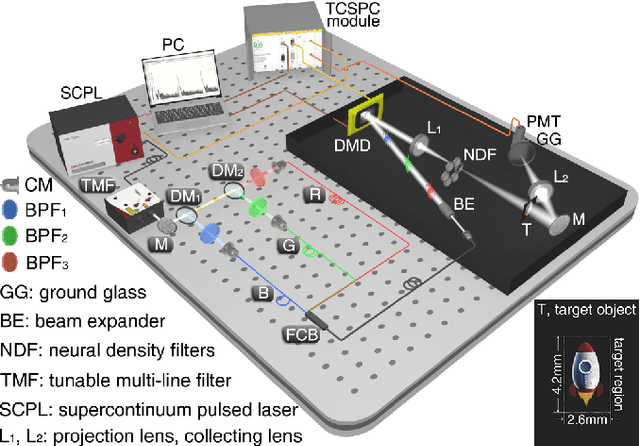
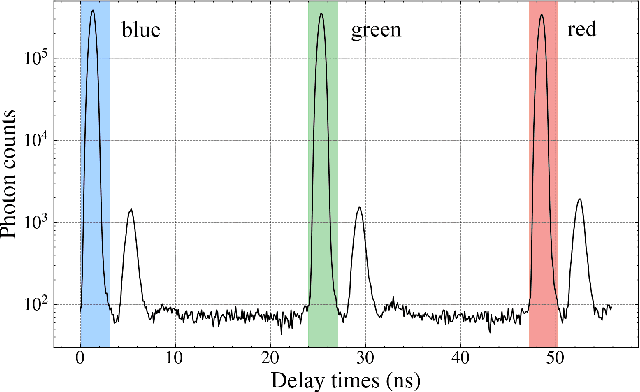

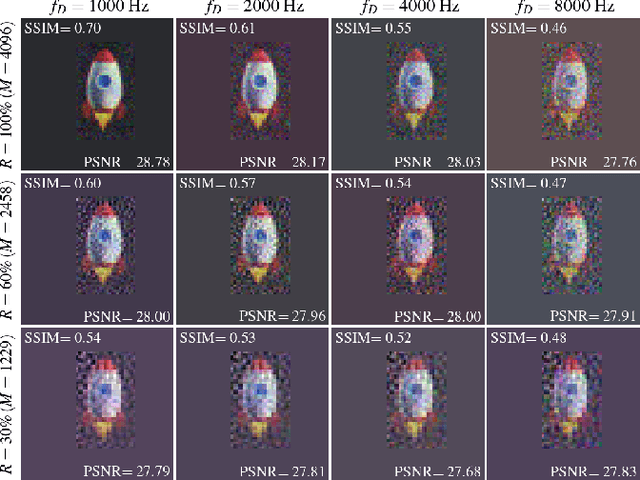
We propose and experimentally demonstrate a high-efficiency single-pixel imaging (SPI) scheme by integrating time-correlated single-photon counting (TCSPC) with time-division multiplexing to acquire full-color images at extremely low light level. This SPI scheme uses a digital micromirror device to modulate a sequence of laser pulses with preset delays to achieve three-color structured illumination, then employs a photomultiplier tube into the TCSPC module to achieve photon-counting detection. By exploiting the time-resolved capabilities of TCSPC, we demodulate the spectrum-image-encoded signals, and then reconstruct high-quality full-color images in a single-round of measurement. Based on this scheme, the strategies such as single-step measurement, high-speed projection, and undersampling can further improve the imaging efficiency.
Constructing Multi-Modal Dialogue Dataset by Replacing Text with Semantically Relevant Images
Jul 19, 2021
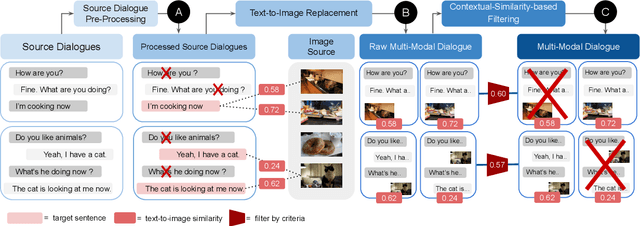
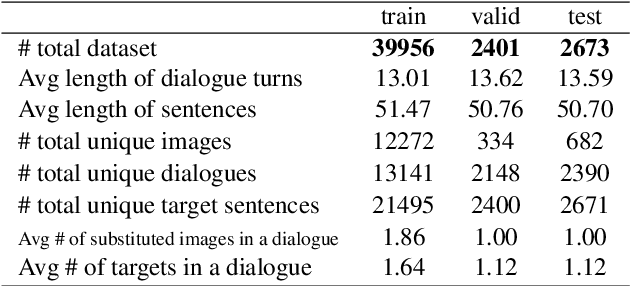
In multi-modal dialogue systems, it is important to allow the use of images as part of a multi-turn conversation. Training such dialogue systems generally requires a large-scale dataset consisting of multi-turn dialogues that involve images, but such datasets rarely exist. In response, this paper proposes a 45k multi-modal dialogue dataset created with minimal human intervention. Our method to create such a dataset consists of (1) preparing and pre-processing text dialogue datasets, (2) creating image-mixed dialogues by using a text-to-image replacement technique, and (3) employing a contextual-similarity-based filtering step to ensure the contextual coherence of the dataset. To evaluate the validity of our dataset, we devise a simple retrieval model for dialogue sentence prediction tasks. Automatic metrics and human evaluation results on such tasks show that our dataset can be effectively used as training data for multi-modal dialogue systems which require an understanding of images and text in a context-aware manner. Our dataset and generation code is available at https://github.com/shh1574/multi-modal-dialogue-dataset.
Semi-supervised Cell Detection in Time-lapse Images Using Temporal Consistency
Jul 19, 2021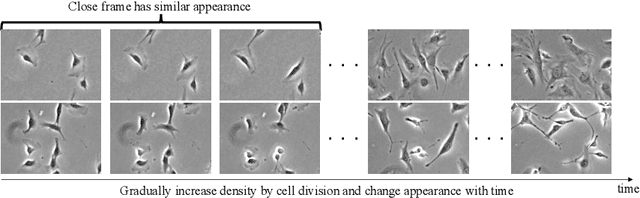
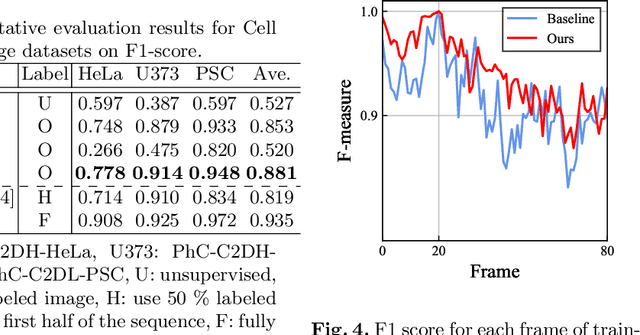
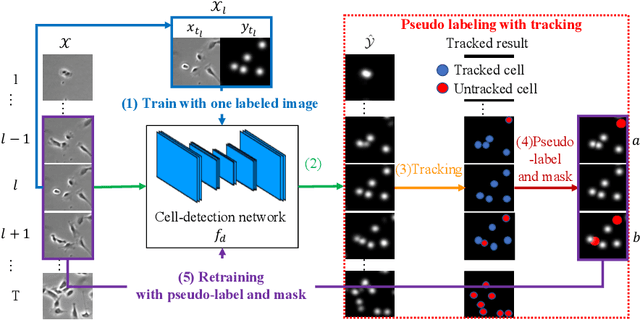
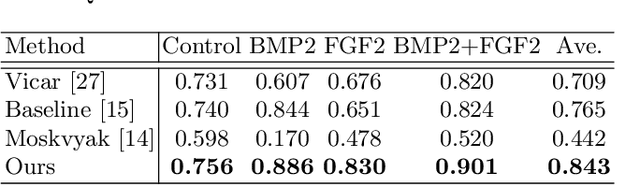
Cell detection is the task of detecting the approximate positions of cell centroids from microscopy images. Recently, convolutional neural network-based approaches have achieved promising performance. However, these methods require a certain amount of annotation for each imaging condition. This annotation is a time-consuming and labor-intensive task. To overcome this problem, we propose a semi-supervised cell-detection method that effectively uses a time-lapse sequence with one labeled image and the other images unlabeled. First, we train a cell-detection network with a one-labeled image and estimate the unlabeled images with the trained network. We then select high-confidence positions from the estimations by tracking the detected cells from the labeled frame to those far from it. Next, we generate pseudo-labels from the tracking results and train the network by using pseudo-labels. We evaluated our method for seven conditions of public datasets, and we achieved the best results relative to other semi-supervised methods. Our code is available at https://github.com/naivete5656/SCDTC
Multi-Feature Fusion-based Scene Classification Framework for HSR Images
May 22, 2021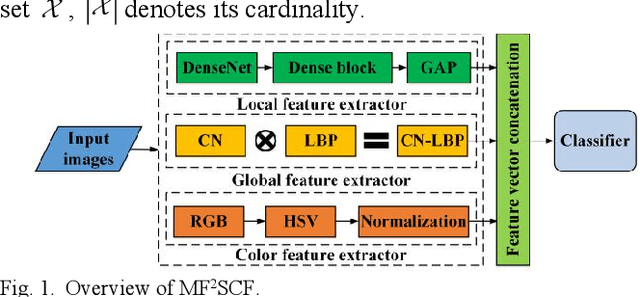
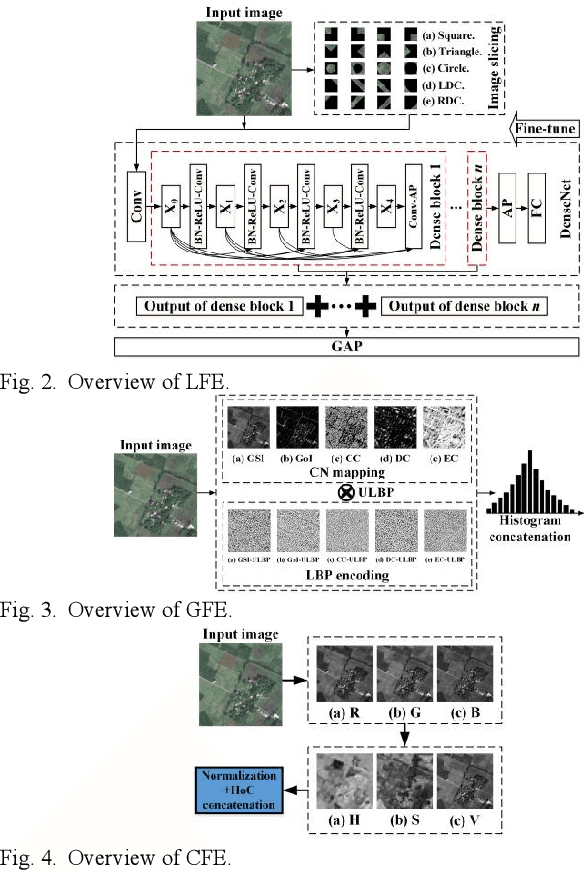
To realize high-accuracy classification of high spatial resolution (HSR) images, this letter proposes a new multi-feature fusion-based scene classification framework (MF2SCF) by fusing local, global, and color features of HSR images. Specifically, we first extract the local features with the help of image slicing and densely connected convolutional networks (DenseNet), where the outputs of dense blocks in the fine-tuned DenseNet-121 model are jointly averaged and concatenated to describe local features. Second, from the perspective of complex networks (CN), we model a HSR image as an undirected graph based on pixel distance, intensity, and gradient, and obtain a gray-scale image (GSI), a gradient of image (GoI), and three CN-based feature images to delineate global features. To make the global feature descriptor resist to the impact of rotation and illumination, we apply uniform local binary patterns (LBP) on GSI, GoI, and feature images, respectively, and generate the final global feature representation by concatenating spatial histograms. Third, the color features are determined based on the normalized HSV histogram, where HSV stands for hue, saturation, and value, respectively. Finally, three feature vectors are jointly concatenated for scene classification. Experiment results show that MF2SCF significantly improves the classification accuracy compared with state-of-the-art LBP-based methods and deep learning-based methods.
Grid Anchor based Image Cropping: A New Benchmark and An Efficient Model
Sep 18, 2019
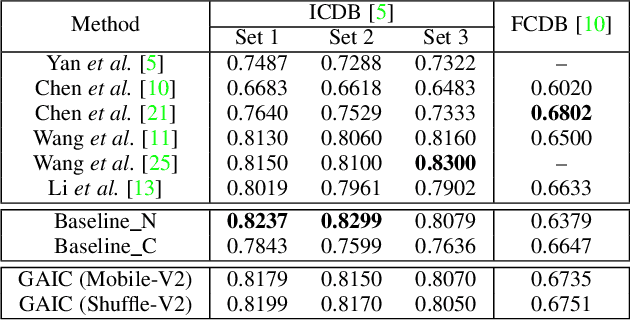

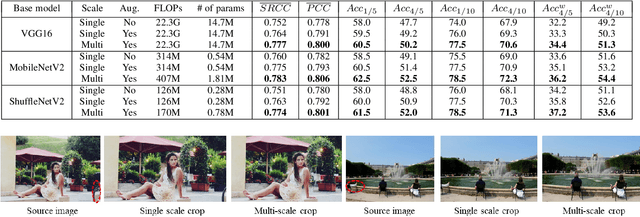
Image cropping aims to improve the composition as well as aesthetic quality of an image by removing extraneous content from it. Most of the existing image cropping databases provide only one or several human-annotated bounding boxes as the groundtruths, which can hardly reflect the non-uniqueness and flexibility of image cropping in practice. The employed evaluation metrics such as intersection-over-union cannot reliably reflect the real performance of a cropping model, either. This work revisits the problem of image cropping, and presents a grid anchor based formulation by considering the special properties and requirements (e.g., local redundancy, content preservation, aspect ratio) of image cropping. Our formulation reduces the searching space of candidate crops from millions to no more than ninety. Consequently, a grid anchor based cropping benchmark is constructed, where all crops of each image are annotated and more reliable evaluation metrics are defined. To meet the practical demands of robust performance and high efficiency, we also design an effective and lightweight cropping model. By simultaneously considering the region of interest and region of discard, and leveraging multi-scale information, our model can robustly output visually pleasing crops for images of different scenes. With less than 2.5M parameters, our model runs at a speed of 200 FPS on one single GTX 1080Ti GPU and 12 FPS on one i7-6800K CPU. The code is available at: \url{https://github.com/HuiZeng/Grid-Anchor-based-Image-Cropping-Pytorch}.
HUMBI: A Large Multiview Dataset of Human Body Expressions and Benchmark Challenge
Sep 30, 2021
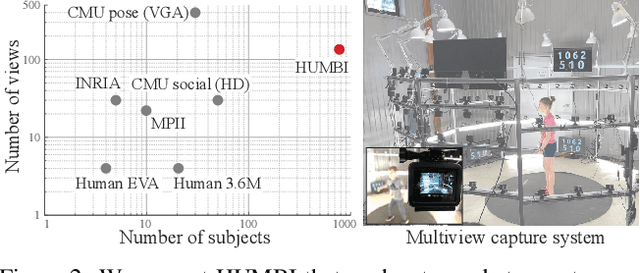
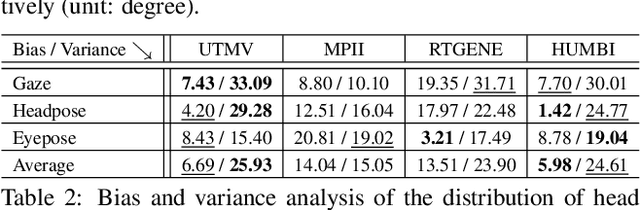
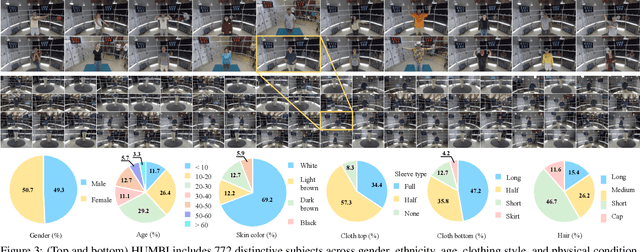
This paper presents a new large multiview dataset called HUMBI for human body expressions with natural clothing. The goal of HUMBI is to facilitate modeling view-specific appearance and geometry of five primary body signals including gaze, face, hand, body, and garment from assorted people. 107 synchronized HD cameras are used to capture 772 distinctive subjects across gender, ethnicity, age, and style. With the multiview image streams, we reconstruct high fidelity body expressions using 3D mesh models, which allows representing view-specific appearance. We demonstrate that HUMBI is highly effective in learning and reconstructing a complete human model and is complementary to the existing datasets of human body expressions with limited views and subjects such as MPII-Gaze, Multi-PIE, Human3.6M, and Panoptic Studio datasets. Based on HUMBI, we formulate a new benchmark challenge of a pose-guided appearance rendering task that aims to substantially extend photorealism in modeling diverse human expressions in 3D, which is the key enabling factor of authentic social tele-presence. HUMBI is publicly available at http://humbi-data.net
Deep Learning Strategies for Industrial Surface Defect Detection Systems
Sep 23, 2021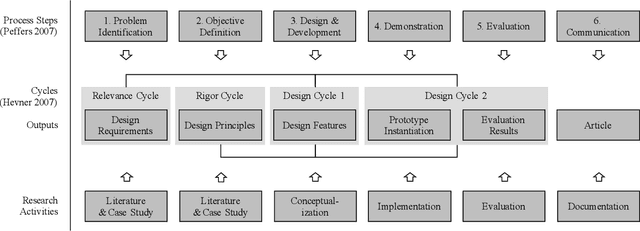

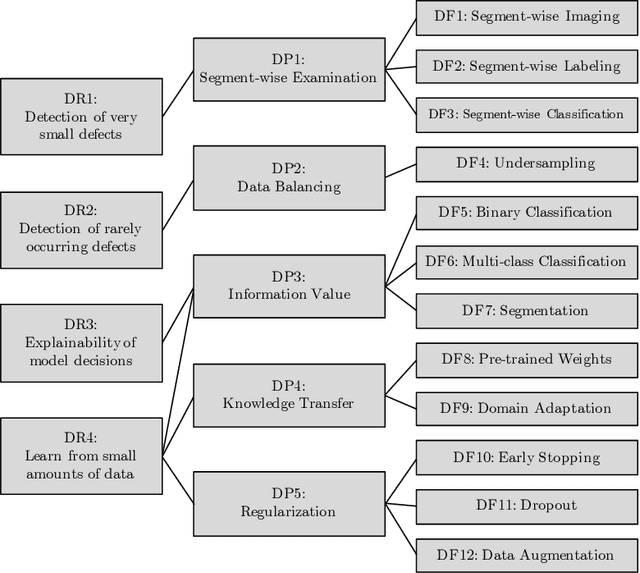
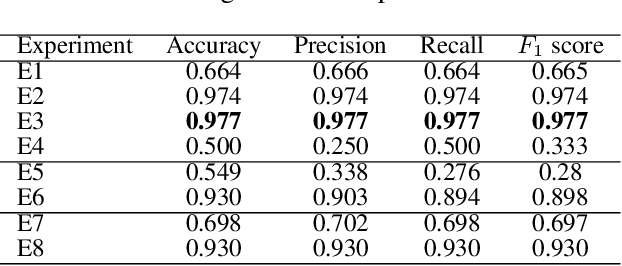
Deep learning methods have proven to outperform traditional computer vision methods in various areas of image processing. However, the application of deep learning in industrial surface defect detection systems is challenging due to the insufficient amount of training data, the expensive data generation process, the small size, and the rare occurrence of surface defects. From literature and a polymer products manufacturing use case, we identify design requirements which reflect the aforementioned challenges. Addressing these, we conceptualize design principles and features informed by deep learning research. Finally, we instantiate and evaluate the gained design knowledge in the form of actionable guidelines and strategies based on an industrial surface defect detection use case. This article, therefore, contributes to academia as well as practice by (1) systematically identifying challenges for the industrial application of deep learning-based surface defect detection, (2) strategies to overcome these, and (3) an experimental case study assessing the strategies' applicability and usefulness.
Segmentation-Aware Hyperspectral Image Classification
May 22, 2019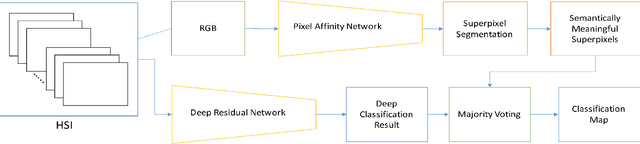


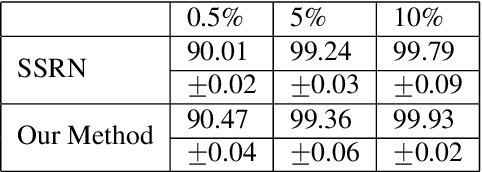
In this paper, we propose an unified hyperspectral image classification method which takes three-dimensional hyperspectral data cube as an input and produces a classification map. In the proposed method, a deep neural network which uses spectral and spatial information together with residual connections, and pixel affinity network based segmentation-aware superpixels are used together. In the architecture, segmentation-aware superpixels run on the initial classification map of deep residual network, and apply majority voting on obtained results. Experimental results show that our propoped method yields state-of-the-art results in two benchmark datasets. Moreover, we also show that the segmentation-aware superpixels have great contribution to the success of hyperspectral image classification methods in cases where training data is insufficient.