 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Public Ground-Truth Dataset for Handwritten Circuit Diagram Images
Jul 21, 2021
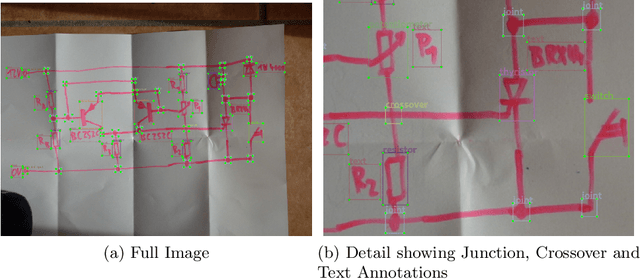
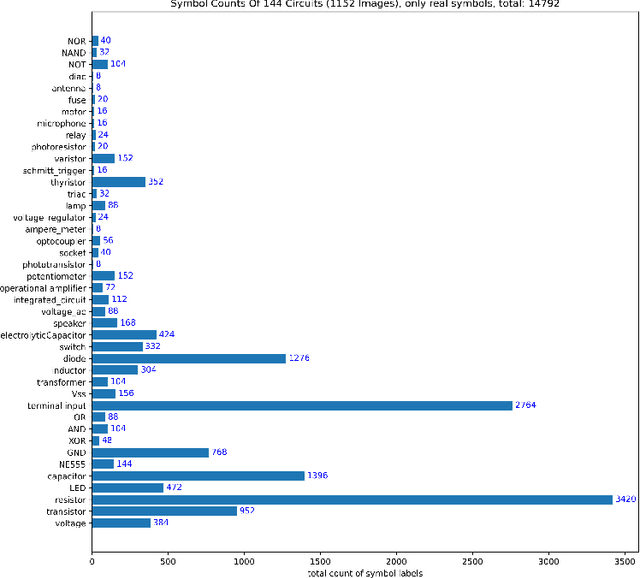
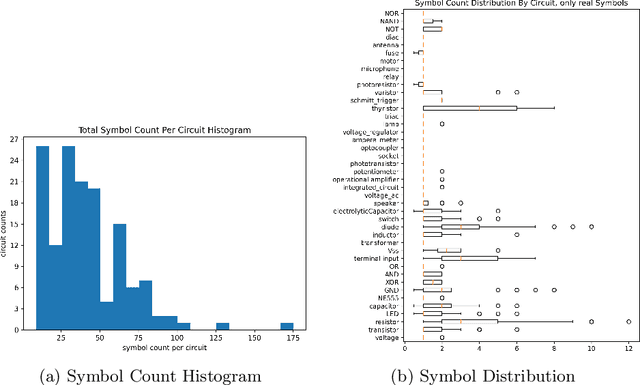
The development of digitization methods for line drawings (especially in the area of electrical engineering) relies on the availability of publicly available training and evaluation data. This paper presents such an image set along with annotations. The dataset consists of 1152 images of 144 circuits by 12 drafters and 48 563 annotations. Each of these images depicts an electrical circuit diagram, taken by consumer grade cameras under varying lighting conditions and perspectives. A variety of different pencil types and surface materials has been used. For each image, all individual electrical components are annotated with bounding boxes and one out of 45 class labels. In order to simplify a graph extraction process, different helper symbols like junction points and crossovers are introduced, while texts are annotated as well. The geometric and taxonomic problems arising from this task as well as the classes themselves and statistics of their appearances are stated. The performance of a standard Faster RCNN on the dataset is provided as an object detection baseline.
Controllable List-wise Ranking for Universal No-reference Image Quality Assessment
Jan 06, 2020
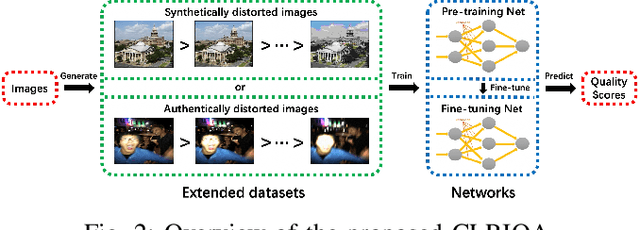

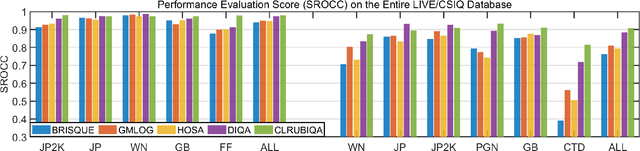
No-reference image quality assessment (NR-IQA) has received increasing attention in the IQA community since reference image is not always available. Real-world images generally suffer from various types of distortion. Unfortunately, existing NR-IQA methods do not work with all types of distortion. It is a challenging task to develop universal NR-IQA that has the ability of evaluating all types of distorted images. In this paper, we propose a universal NR-IQA method based on controllable list-wise ranking (CLRIQA). First, to extend the authentically distorted image dataset, we present an imaging-heuristic approach, in which the over-underexposure is formulated as an inverse of Weber-Fechner law, and fusion strategy and probabilistic compression are adopted, to generate the degraded real-world images. These degraded images are label-free yet associated with quality ranking information. We then design a controllable list-wise ranking function by limiting rank range and introducing an adaptive margin to tune rank interval. Finally, the extended dataset and controllable list-wise ranking function are used to pre-train a CNN. Moreover, in order to obtain an accurate prediction model, we take advantage of the original dataset to further fine-tune the pre-trained network. Experiments evaluated on four benchmark datasets (i.e. LIVE, CSIQ, TID2013, and LIVE-C) show that the proposed CLRIQA improves the state of the art by over 9% in terms of overall performance. The code and model are publicly available at https://github.com/GZHU-Image-Lab/CLRIQA.
Alpha Matte Generation from Single Input for Portrait Matting
Jun 06, 2021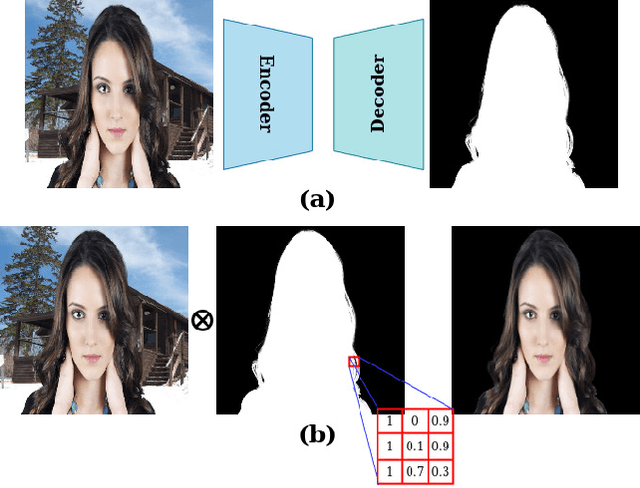
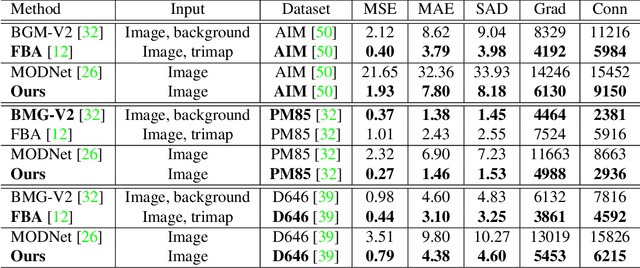
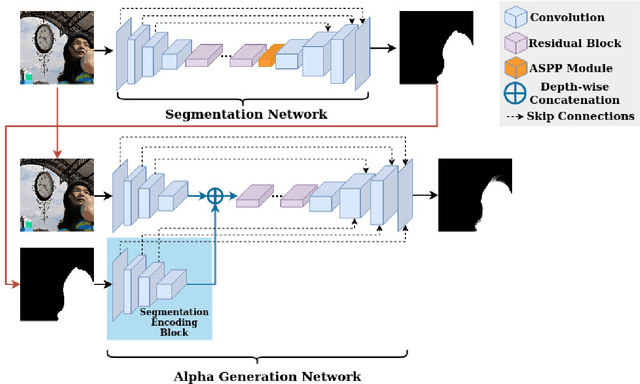
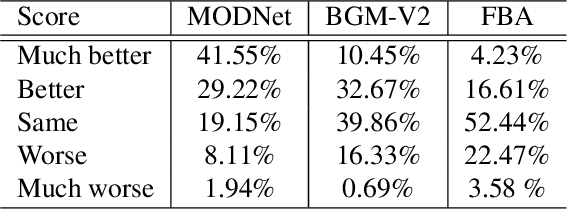
Portrait matting is an important research problem with a wide range of applications, such as video conference app, image/video editing, and post-production. The goal is to predict an alpha matte that identifies the effect of each pixel on the foreground subject. Traditional approaches and most of the existing works utilized an additional input, e.g., trimap, background image, to predict alpha matte. However, providing additional input is not always practical. Besides, models are too sensitive to these additional inputs. In this paper, we introduce an additional input-free approach to perform portrait matting using Generative Adversarial Nets (GANs). We divide the main task into two subtasks. For this, we propose a segmentation network for the person segmentation and the alpha generation network for alpha matte prediction. While the segmentation network takes an input image and produces a coarse segmentation map, the alpha generation network utilizes the same input image as well as a coarse segmentation map that is produced by the segmentation network to predict the alpha matte. Besides, we present a segmentation encoding block to downsample the coarse segmentation map and provide feature representation to the residual block. Furthermore, we propose border loss to penalize only the borders of the subject separately which is more likely to be challenging and we also adapt perceptual loss for portrait matting. To train the proposed system, we combine two different popular training datasets to improve the amount of data as well as diversity to address domain shift problems in the inference time. We tested our model on three different benchmark datasets, namely Adobe Image Matting dataset, Portrait Matting dataset, and Distinctions dataset. The proposed method outperformed the MODNet method that also takes a single input.
Fiducial marker recovery and detection from severely truncated data in navigation assisted spine surgery
Aug 25, 2021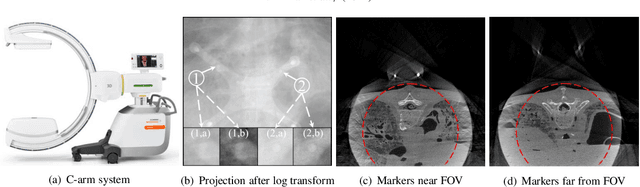
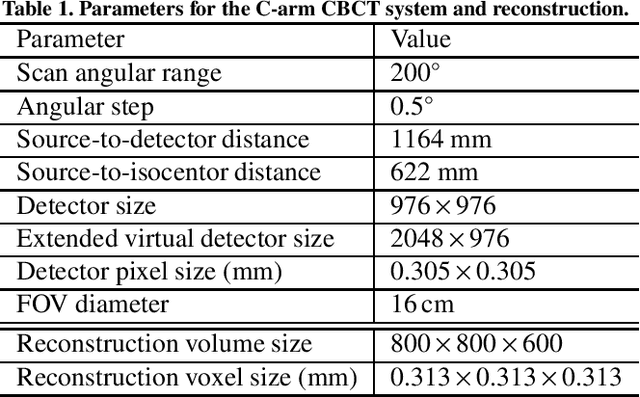
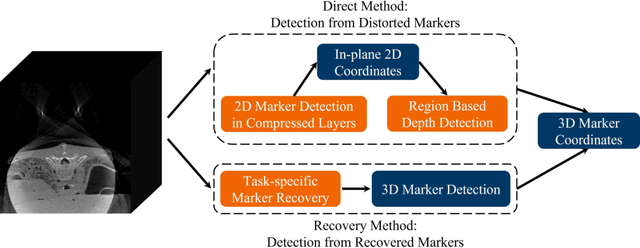

Fiducial markers are commonly used in navigation assisted minimally invasive spine surgery (MISS) and they help transfer image coordinates into real world coordinates. In practice, these markers might be located outside the field-of-view (FOV), due to the limited detector sizes of C-arm cone-beam computed tomography (CBCT) systems used in intraoperative surgeries. As a consequence, reconstructed markers in CBCT volumes suffer from artifacts and have distorted shapes, which sets an obstacle for navigation. In this work, we propose two fiducial marker detection methods: direct detection from distorted markers (direct method) and detection after marker recovery (recovery method). For direct detection from distorted markers in reconstructed volumes, an efficient automatic marker detection method using two neural networks and a conventional circle detection algorithm is proposed. For marker recovery, a task-specific learning strategy is proposed to recover markers from severely truncated data. Afterwards, a conventional marker detection algorithm is applied for position detection. The two methods are evaluated on simulated data and real data, both achieving a marker registration error smaller than 0.2 mm. Our experiments demonstrate that the direct method is capable of detecting distorted markers accurately and the recovery method with task-specific learning has high robustness and generalizability on various data sets. In addition, the task-specific learning is able to reconstruct other structures of interest accurately, e.g. ribs for image-guided needle biopsy, from severely truncated data, which empowers CBCT systems with new potential applications.
Bilinear pooling and metric learning network for early Alzheimer's disease identification with FDG-PET images
Nov 09, 2021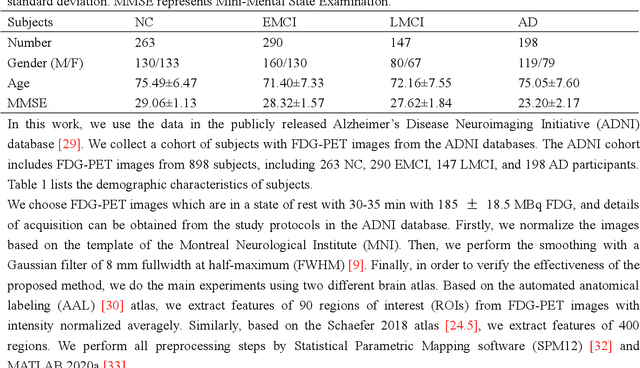
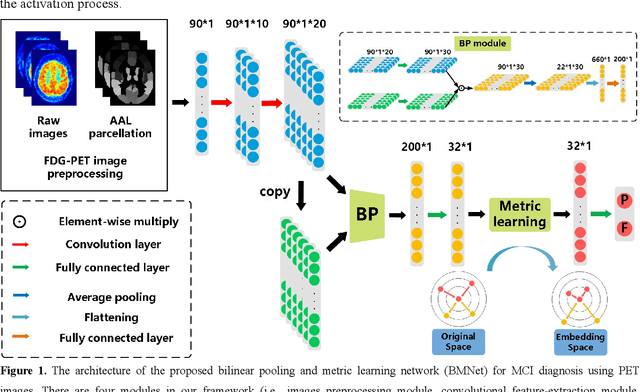
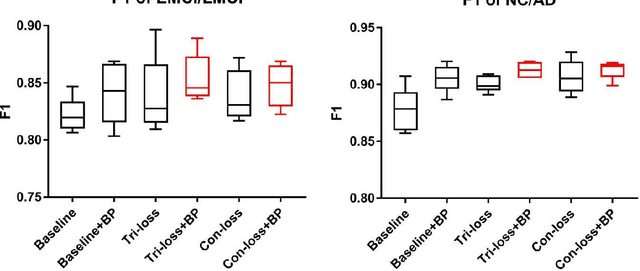
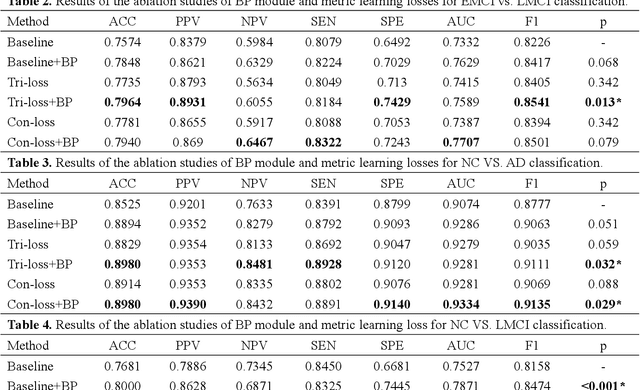
FDG-PET reveals altered brain metabolism in individuals with mild cognitive impairment (MCI) and Alzheimer's disease (AD). Some biomarkers derived from FDG-PET by computer-aided-diagnosis (CAD) technologies have been proved that they can accurately diagnosis normal control (NC), MCI, and AD. However, the studies of identification of early MCI (EMCI) and late MCI (LMCI) with FDG-PET images are still insufficient. Compared with studies based on fMRI and DTI images, the researches of the inter-region representation features in FDG-PET images are insufficient. Moreover, considering the variability in different individuals, some hard samples which are very similar with both two classes limit the classification performance. To tackle these problems, in this paper, we propose a novel bilinear pooling and metric learning network (BMNet), which can extract the inter-region representation features and distinguish hard samples by constructing embedding space. To validate the proposed method, we collect 998 FDG-PET images from ADNI. Following the common preprocessing steps, 90 features are extracted from each FDG-PET image according to the automatic anatomical landmark (AAL) template and then sent into the proposed network. Extensive 5-fold cross-validation experiments are performed for multiple two-class classifications. Experiments show that most metrics are improved after adding the bilinear pooling module and metric losses to the Baseline model respectively. Specifically, in the classification task between EMCI and LMCI, the specificity improves 6.38% after adding the triple metric loss, and the negative predictive value (NPV) improves 3.45% after using the bilinear pooling module.
Multi-scale PIIFD for Registration of Multi-source Remote Sensing Images
Apr 26, 2021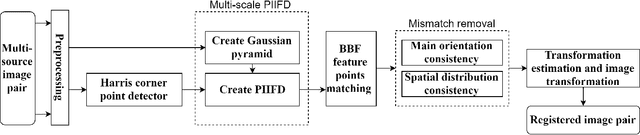


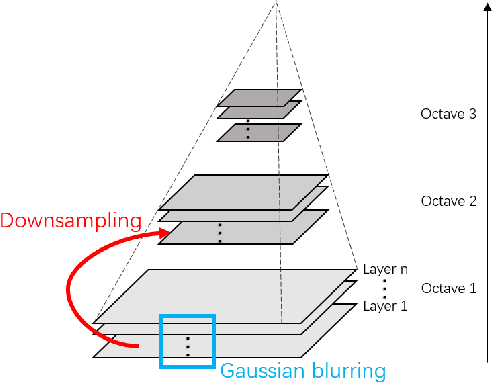
This paper aims at providing multi-source remote sensing images registered in geometric space for image fusion. Focusing on the characteristics and differences of multi-source remote sensing images, a feature-based registration algorithm is implemented. The key technologies include image scale-space for implementing multi-scale properties, Harris corner detection for keypoints extraction, and partial intensity invariant feature descriptor (PIIFD) for keypoints description. Eventually, a multi-scale Harris-PIIFD image registration algorithm framework is proposed. The experimental results of four sets of representative real data show that the algorithm has excellent, stable performance in multi-source remote sensing image registration, and can achieve accurate spatial alignment, which has strong practical application value and certain generalization ability.
Programmable Spectral Filter Arrays for Hyperspectral Imaging
Sep 29, 2021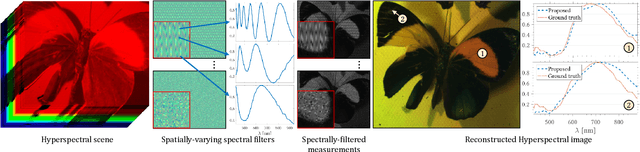
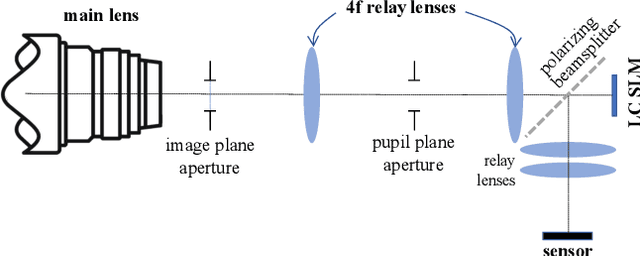
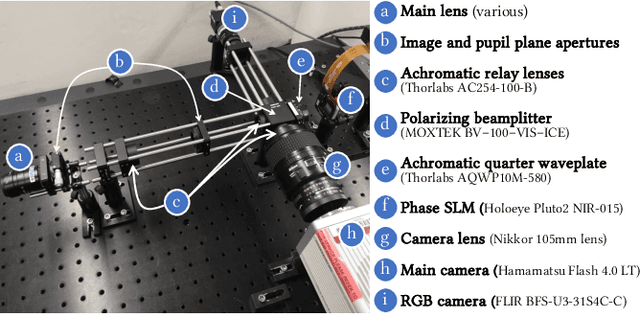
Modulating the spectral dimension of light has numerous applications in computational imaging. While there are many techniques for achieving this, there are few, if any, for implementing a spatially-varying and programmable spectral filter. This paper provides an optical design for implementing such a capability. Our key insight is that spatially-varying spectral modulation can be implemented using a liquid crystal spatial light modulator since it provides an array of liquid crystal cells, each of which can be purposed to act as a programmable spectral filter array. Relying on this insight, we provide an optical schematic and an associated lab prototype for realizing the capability, as well as address the associated challenges at implementation using optical and computational innovations. We show a number of unique operating points with our prototype including single- and multi-image hyperspectral imaging, as well as its application in material identification.
AnaXNet: Anatomy Aware Multi-label Finding Classification in Chest X-ray
May 20, 2021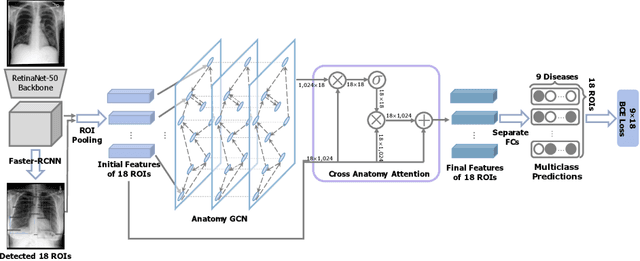
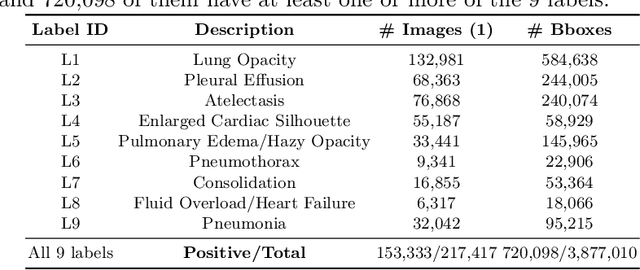
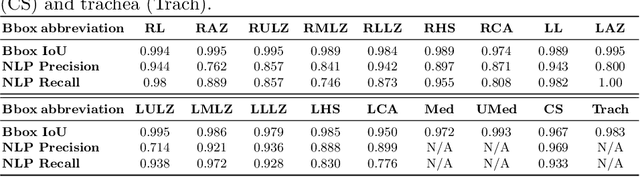
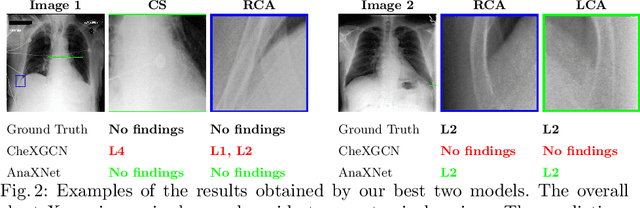
Radiologists usually observe anatomical regions of chest X-ray images as well as the overall image before making a decision. However, most existing deep learning models only look at the entire X-ray image for classification, failing to utilize important anatomical information. In this paper, we propose a novel multi-label chest X-ray classification model that accurately classifies the image finding and also localizes the findings to their correct anatomical regions. Specifically, our model consists of two modules, the detection module and the anatomical dependency module. The latter utilizes graph convolutional networks, which enable our model to learn not only the label dependency but also the relationship between the anatomical regions in the chest X-ray. We further utilize a method to efficiently create an adjacency matrix for the anatomical regions using the correlation of the label across the different regions. Detailed experiments and analysis of our results show the effectiveness of our method when compared to the current state-of-the-art multi-label chest X-ray image classification methods while also providing accurate location information.
XCI-Sketch: Extraction of Color Information from Images for Generation of Colored Outlines and Sketches
Aug 26, 2021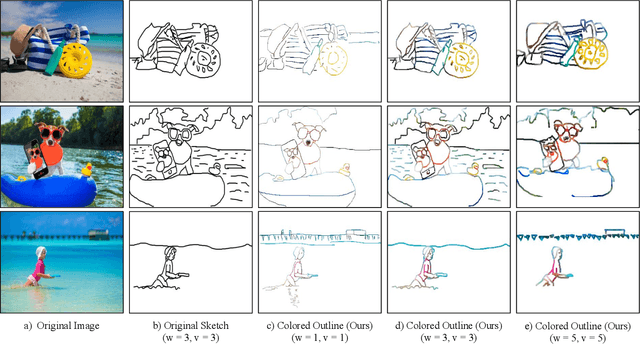
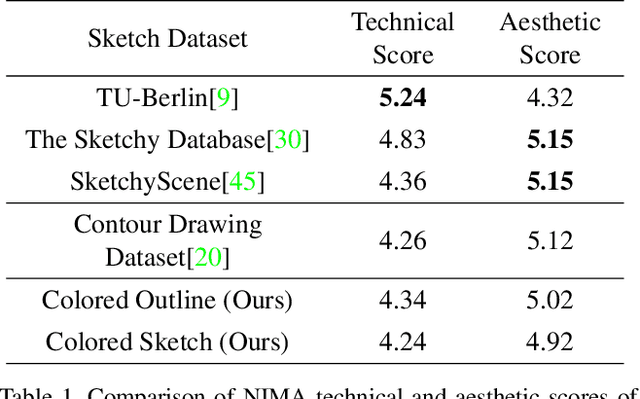
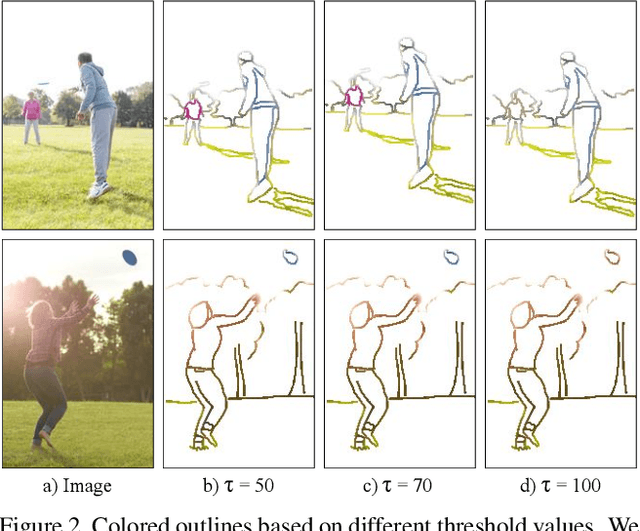
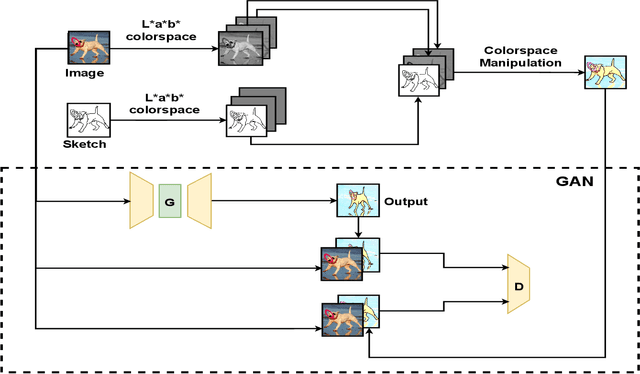
Sketches are a medium to convey a visual scene from an individual's creative perspective. The addition of color substantially enhances the overall expressivity of a sketch. This paper proposes two methods to mimic human-drawn colored sketches by utilizing the Contour Drawing Dataset. Our first approach renders colored outline sketches by applying image processing techniques aided by k-means color clustering. The second method uses a generative adversarial network to develop a model that can generate colored sketches from previously unobserved images. We assess the results obtained through quantitative and qualitative evaluations.
Towards Demystifying Representation Learning with Non-contrastive Self-supervision
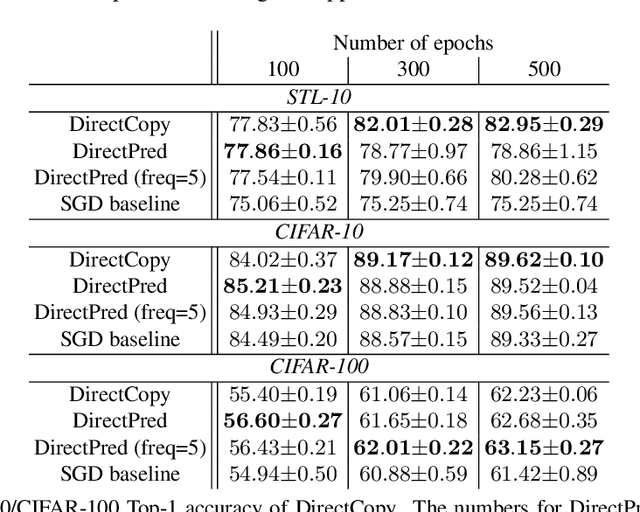
Oct 11, 2021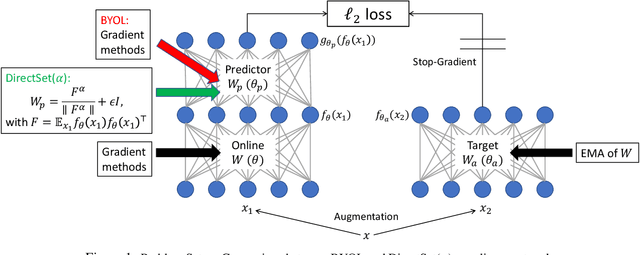
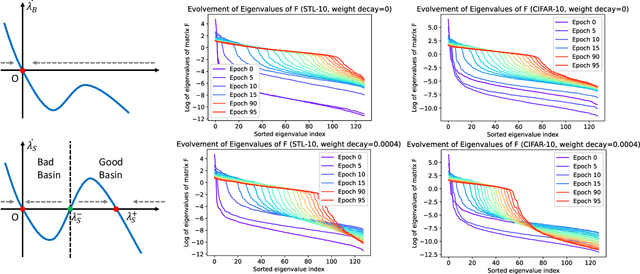
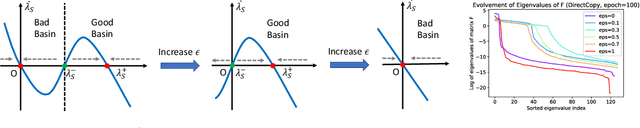
Non-contrastive methods of self-supervised learning (such as BYOL and SimSiam) learn representations by minimizing the distance between two views of the same image. These approaches have achieved remarkable performance in practice, but it is not well understood 1) why these methods do not collapse to the trivial solutions and 2) how the representation is learned. Tian el al. (2021) made an initial attempt on the first question and proposed DirectPred that sets the predictor directly. In our work, we analyze a generalized version of DirectPred, called DirectSet($\alpha$). We show that in a simple linear network, DirectSet($\alpha$) provably learns a desirable projection matrix and also reduces the sample complexity on downstream tasks. Our analysis suggests that weight decay acts as an implicit threshold that discard the features with high variance under augmentation, and keep the features with low variance. Inspired by our theory, we simplify DirectPred by removing the expensive eigen-decomposition step. On CIFAR-10, CIFAR-100, STL-10 and ImageNet, DirectCopy, our simpler and more computationally efficient algorithm, rivals or even outperforms DirectPred.