 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Medical Segmentation Decathlon
Jun 10, 2021
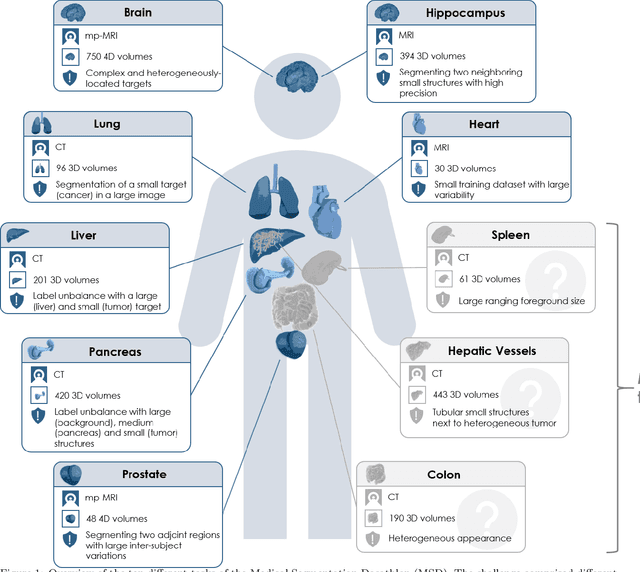
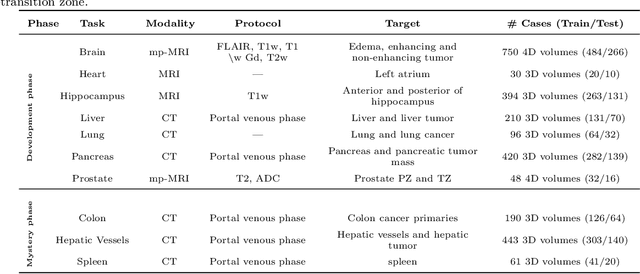
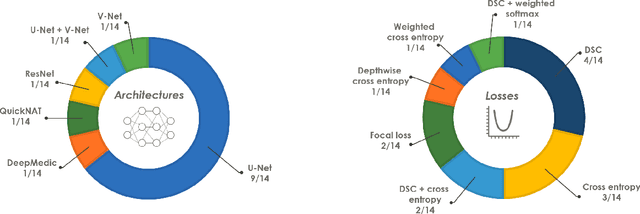
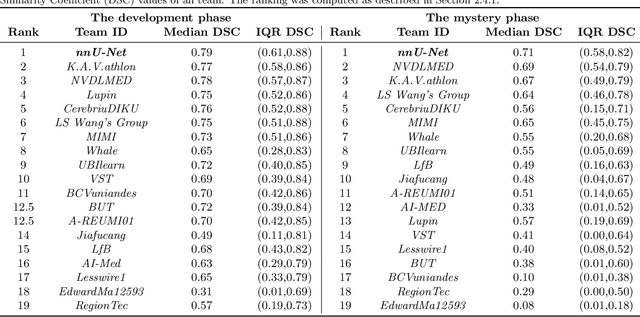
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Image Segmentation using Multi-Threshold technique by Histogram Sampling
Sep 11, 2019
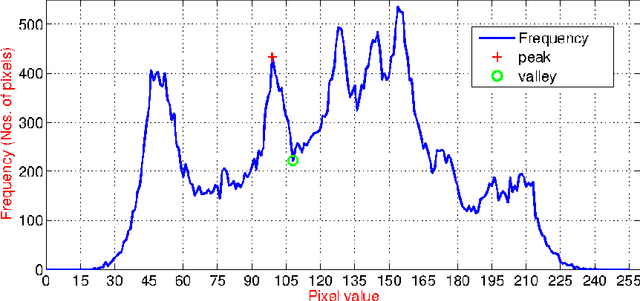
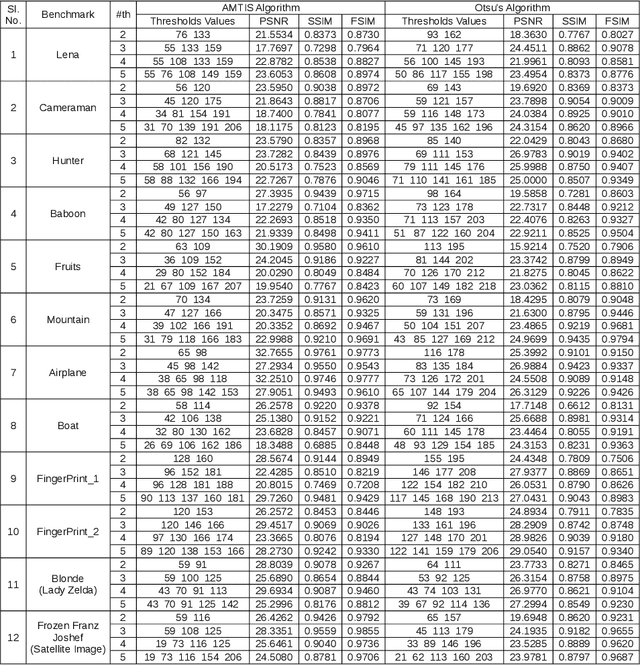
The segmentation of digital images is one of the essential steps in image processing or a computer vision system. It helps in separating the pixels into different regions according to their intensity level. A large number of segmentation techniques have been proposed, and a few of them use complex computational operations. Among all, the most straightforward procedure that can be easily implemented is thresholding. In this paper, we present a unique heuristic approach for image segmentation that automatically determines multilevel thresholds by sampling the histogram of a digital image. Our approach emphasis on selecting a valley as optimal threshold values. We demonstrated that our approach outperforms the popular Otsu's method in terms of CPU computational time. We demonstrated that our approach outperforms the popular Otsu's method in terms of CPU computational time. We observed a maximum speed-up of 35.58x and a minimum speed-up of 10.21x on popular image processing benchmarks. To demonstrate the correctness of our approach in determining threshold values, we compute PSNR, SSIM, and FSIM values to compare with the values obtained by Otsu's method. This evaluation shows that our approach is comparable and better in many cases as compared to well known Otsu's method.
Aug3D-RPN: Improving Monocular 3D Object Detection by Synthetic Images with Virtual Depth
Jul 28, 2021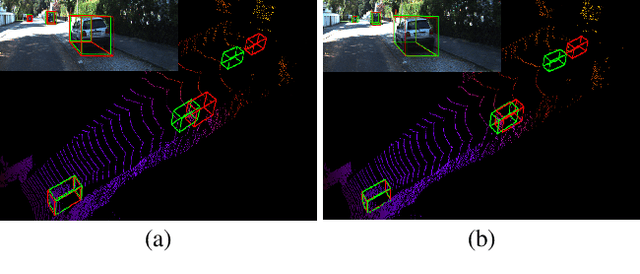
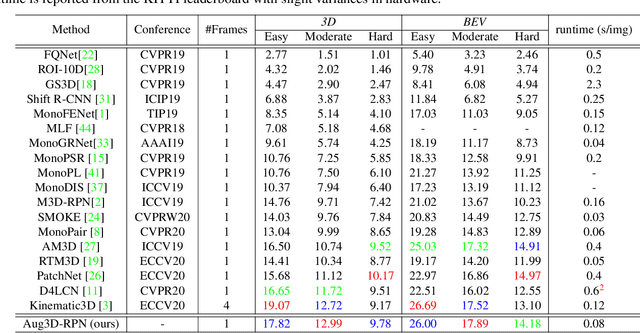
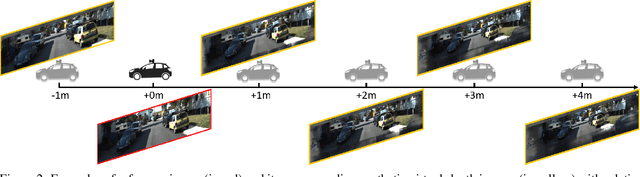
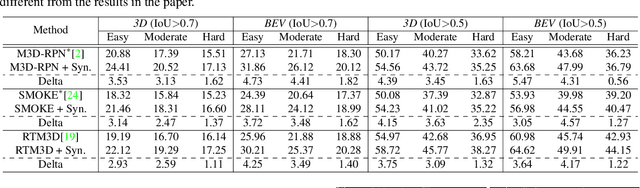
Current geometry-based monocular 3D object detection models can efficiently detect objects by leveraging perspective geometry, but their performance is limited due to the absence of accurate depth information. Though this issue can be alleviated in a depth-based model where a depth estimation module is plugged to predict depth information before 3D box reasoning, the introduction of such module dramatically reduces the detection speed. Instead of training a costly depth estimator, we propose a rendering module to augment the training data by synthesizing images with virtual-depths. The rendering module takes as input the RGB image and its corresponding sparse depth image, outputs a variety of photo-realistic synthetic images, from which the detection model can learn more discriminative features to adapt to the depth changes of the objects. Besides, we introduce an auxiliary module to improve the detection model by jointly optimizing it through a depth estimation task. Both modules are working in the training time and no extra computation will be introduced to the detection model. Experiments show that by working with our proposed modules, a geometry-based model can represent the leading accuracy on the KITTI 3D detection benchmark.
Self-Supervised Learning with Kernel Dependence Maximization
Jun 15, 2021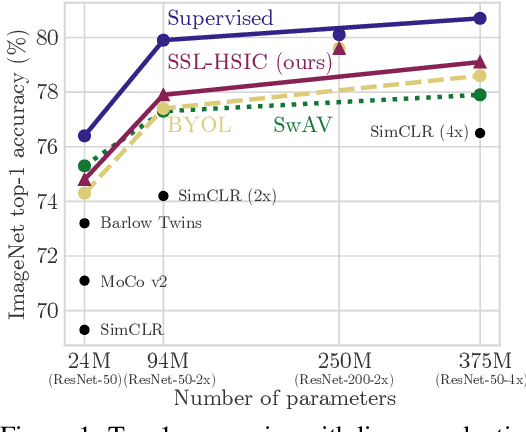
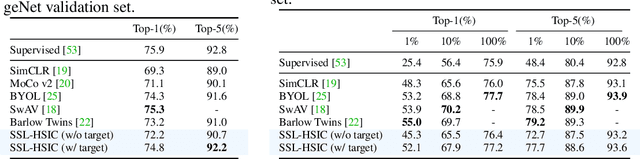
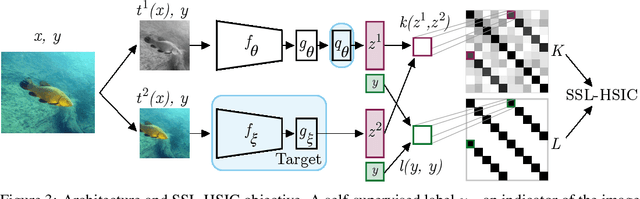
We approach self-supervised learning of image representations from a statistical dependence perspective, proposing Self-Supervised Learning with the Hilbert-Schmidt Independence Criterion (SSL-HSIC). SSL-HSIC maximizes dependence between representations of transformed versions of an image and the image identity, while minimizing the kernelized variance of those features. This self-supervised learning framework yields a new understanding of InfoNCE, a variational lower bound on the mutual information (MI) between different transformations. While the MI itself is known to have pathologies which can result in meaningless representations being learned, its bound is much better behaved: we show that it implicitly approximates SSL-HSIC (with a slightly different regularizer). Our approach also gives us insight into BYOL, since SSL-HSIC similarly learns local neighborhoods of samples. SSL-HSIC allows us to directly optimize statistical dependence in time linear in the batch size, without restrictive data assumptions or indirect mutual information estimators. Trained with or without a target network, SSL-HSIC matches the current state-of-the-art for standard linear evaluation on ImageNet, semi-supervised learning and transfer to other classification and vision tasks such as semantic segmentation, depth estimation and object recognition.
Neural Dubber: Dubbing for Silent Videos According to Scripts
Oct 15, 2021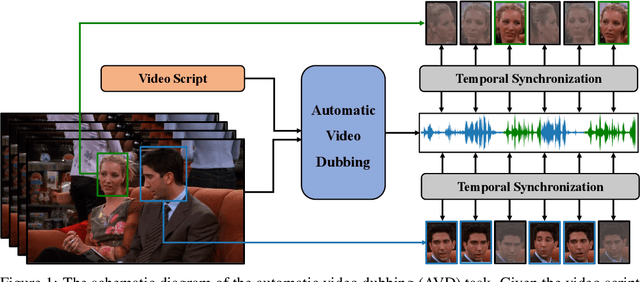
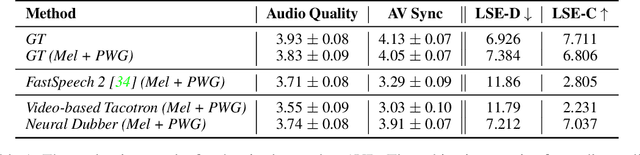
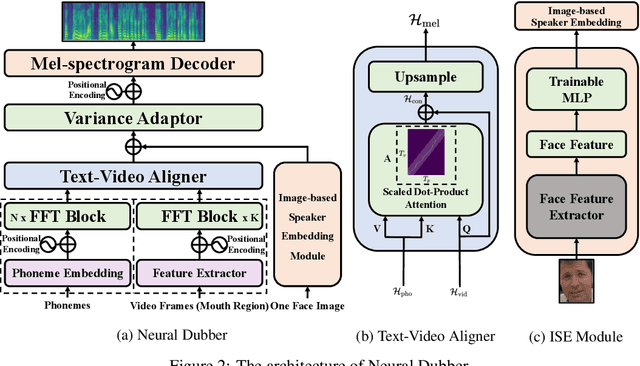
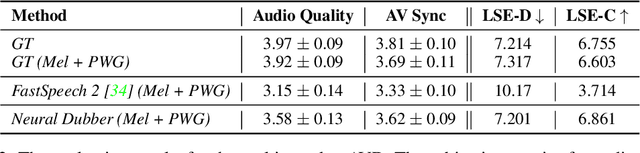
Dubbing is a post-production process of re-recording actors' dialogues, which is extensively used in filmmaking and video production. It is usually performed manually by professional voice actors who read lines with proper prosody, and in synchronization with the pre-recorded videos. In this work, we propose Neural Dubber, the first neural network model to solve a novel automatic video dubbing (AVD) task: synthesizing human speech synchronized with the given silent video from the text. Neural Dubber is a multi-modal text-to-speech (TTS) model that utilizes the lip movement in the video to control the prosody of the generated speech. Furthermore, an image-based speaker embedding (ISE) module is developed for the multi-speaker setting, which enables Neural Dubber to generate speech with a reasonable timbre according to the speaker's face. Experiments on the chemistry lecture single-speaker dataset and LRS2 multi-speaker dataset show that Neural Dubber can generate speech audios on par with state-of-the-art TTS models in terms of speech quality. Most importantly, both qualitative and quantitative evaluations show that Neural Dubber can control the prosody of synthesized speech by the video, and generate high-fidelity speech temporally synchronized with the video.
Hepatic vessel segmentation based on 3Dswin-transformer with inductive biased multi-head self-attention
Nov 05, 2021
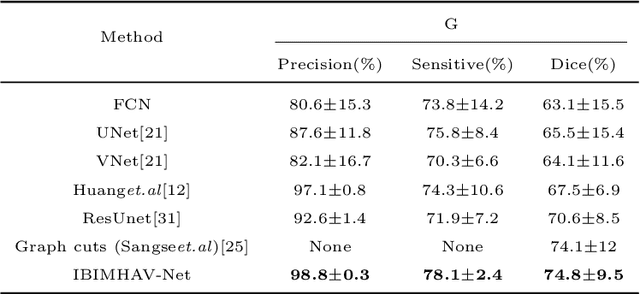
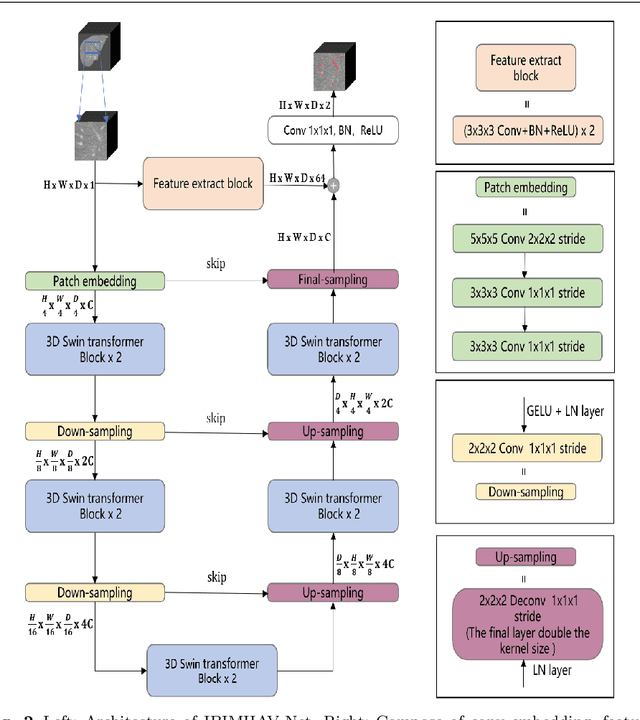
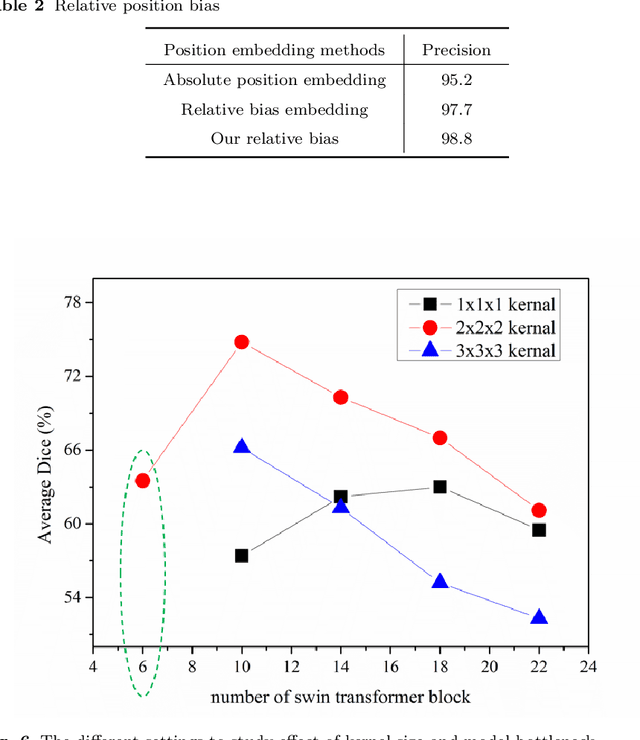
Purpose: Segmentation of liver vessels from CT images is indispensable prior to surgical planning and aroused broad range of interests in the medical image analysis community. Due to the complex structure and low contrast background, automatic liver vessel segmentation remains particularly challenging. Most of the related researches adopt FCN, U-net, and V-net variants as a backbone. However, these methods mainly focus on capturing multi-scale local features which may produce misclassified voxels due to the convolutional operator's limited locality reception field. Methods: We propose a robust end-to-end vessel segmentation network called Inductive BIased Multi-Head Attention Vessel Net(IBIMHAV-Net) by expanding swin transformer to 3D and employing an effective combination of convolution and self-attention. In practice, we introduce the voxel-wise embedding rather than patch-wise embedding to locate precise liver vessel voxels, and adopt multi-scale convolutional operators to gain local spatial information. On the other hand, we propose the inductive biased multi-head self-attention which learns inductive biased relative positional embedding from initialized absolute position embedding. Based on this, we can gain a more reliable query and key matrix. To validate the generalization of our model, we test on samples which have different structural complexity. Results: We conducted experiments on the 3DIRCADb datasets. The average dice and sensitivity of the four tested cases were 74.8% and 77.5%, which exceed results of existing deep learning methods and improved graph cuts method. Conclusion: The proposed model IBIMHAV-Net provides an automatic, accurate 3D liver vessel segmentation with an interleaved architecture that better utilizes both global and local spatial features in CT volumes. It can be further extended for other clinical data.
Guiding Visual Question Generation
Oct 15, 2021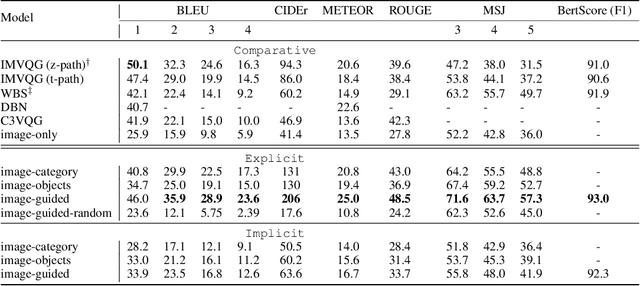
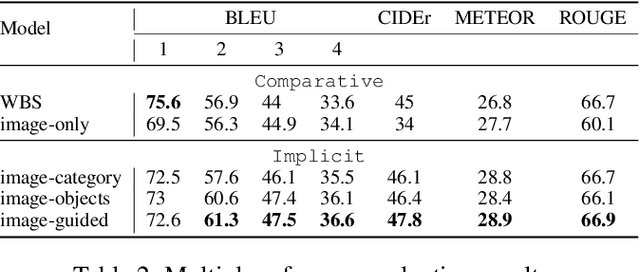


In traditional Visual Question Generation (VQG), most images have multiple concepts (e.g. objects and categories) for which a question could be generated, but models are trained to mimic an arbitrary choice of concept as given in their training data. This makes training difficult and also poses issues for evaluation -- multiple valid questions exist for most images but only one or a few are captured by the human references. We present Guiding Visual Question Generation - a variant of VQG which conditions the question generator on categorical information based on expectations on the type of question and the objects it should explore. We propose two variants: (i) an explicitly guided model that enables an actor (human or automated) to select which objects and categories to generate a question for; and (ii) an implicitly guided model that learns which objects and categories to condition on, based on discrete latent variables. The proposed models are evaluated on an answer-category augmented VQA dataset and our quantitative results show a substantial improvement over the current state of the art (over 9 BLEU-4 increase). Human evaluation validates that guidance helps the generation of questions that are grammatically coherent and relevant to the given image and objects.
IR-NAS: Neural Architecture Search for Image Restoration
Sep 18, 2019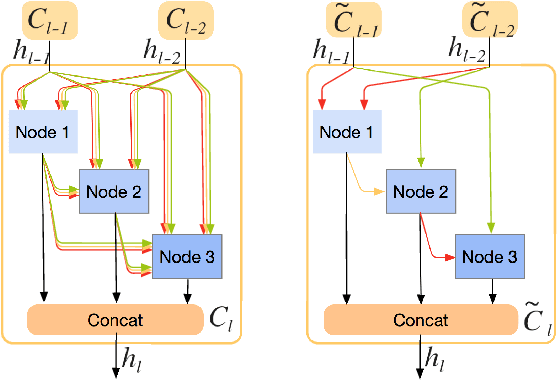
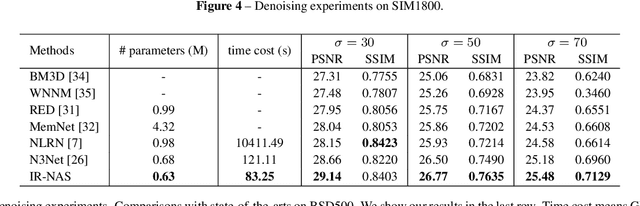
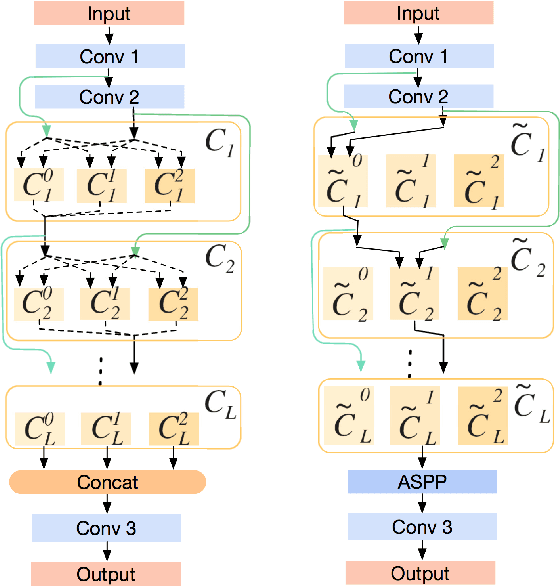
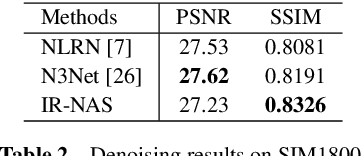
Recently, neural architecture search (NAS) methods have attracted much attention and outperformed manually designed architectures on a few high-level vision tasks. In this paper, we propose IR-NAS, an effort towards employing NAS to automatically design effective neural network architectures for low-level image restoration tasks, and apply to two such tasks: image denoising and image de-raining. IR-NAS adopts an flexible hierarchical search space, including inner cell structures and outer layer widths. The proposed IR-NAS is both memory and computationally efficient, which takes only 6 hours for searching using a single GPU and saves memory by sharing cell weights across different feature levels. We evaluate the effectiveness of our proposed IR-NAS on three different datasets, including an additive white Gaussian noise dataset BSD500, a realistic noise dataset SIM1800 and a challenging de-raining dataset Rain800. Results show that the architectures found by IR-NAS have fewer parameters and enjoy a faster inference speed, while achieving highly competitive performance compared with state-of-the-art methods. We also present analysis on the architectures found by NAS.
Using Undervolting as an On-Device Defense Against Adversarial Machine Learning Attacks
Jul 20, 2021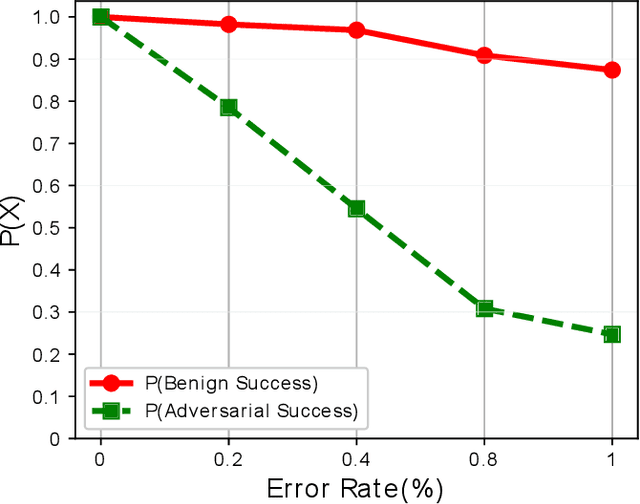
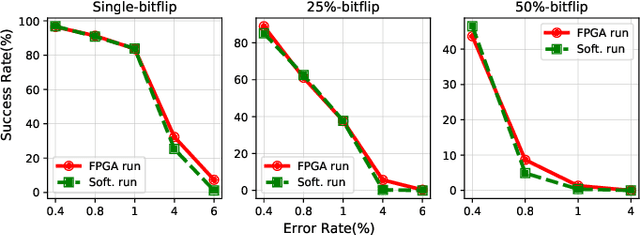
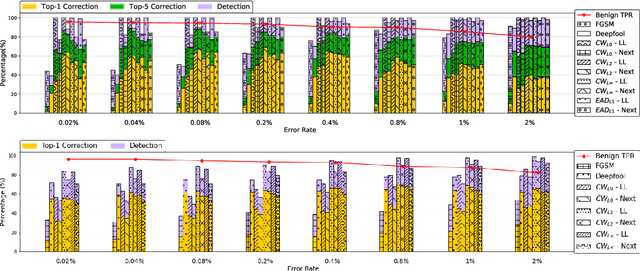
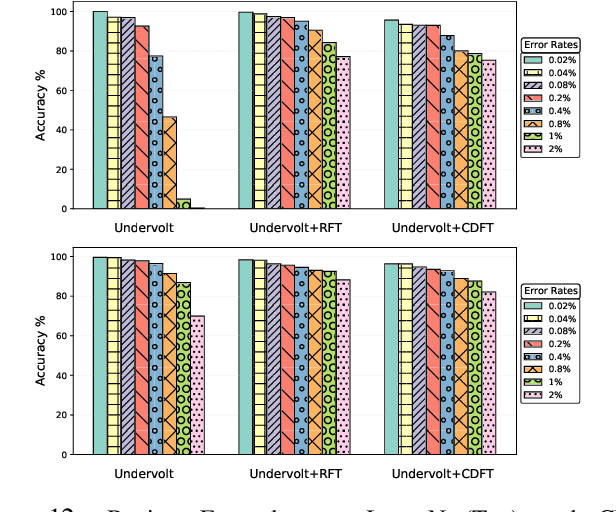
Deep neural network (DNN) classifiers are powerful tools that drive a broad spectrum of important applications, from image recognition to autonomous vehicles. Unfortunately, DNNs are known to be vulnerable to adversarial attacks that affect virtually all state-of-the-art models. These attacks make small imperceptible modifications to inputs that are sufficient to induce the DNNs to produce the wrong classification. In this paper we propose a novel, lightweight adversarial correction and/or detection mechanism for image classifiers that relies on undervolting (running a chip at a voltage that is slightly below its safe margin). We propose using controlled undervolting of the chip running the inference process in order to introduce a limited number of compute errors. We show that these errors disrupt the adversarial input in a way that can be used either to correct the classification or detect the input as adversarial. We evaluate the proposed solution in an FPGA design and through software simulation. We evaluate 10 attacks on two popular DNNs and show an average detection rate of 80% to 95%.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021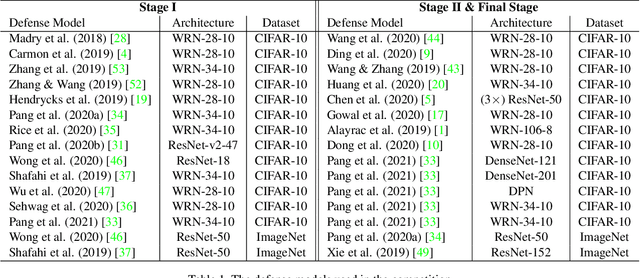
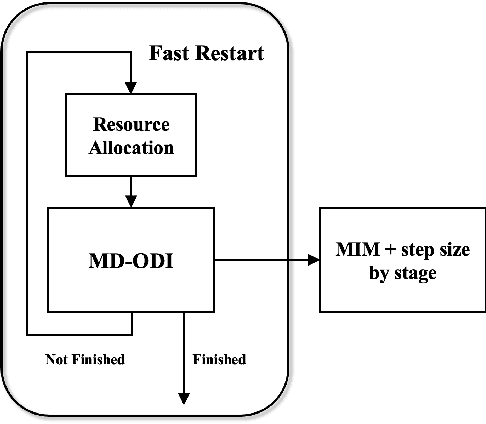
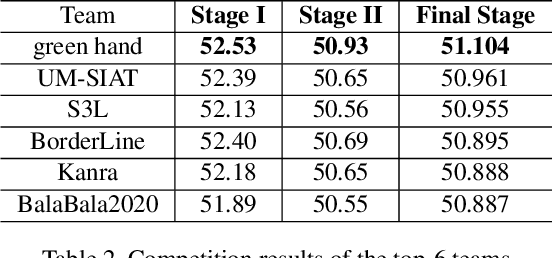
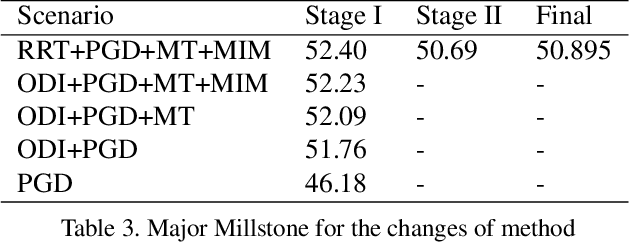
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.