 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
S2IGAN: Speech-to-Image Generation via Adversarial Learning
May 14, 2020
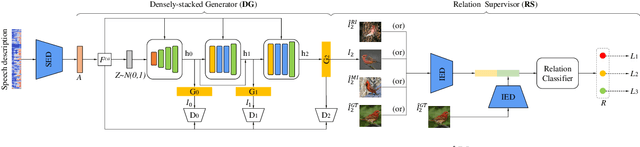
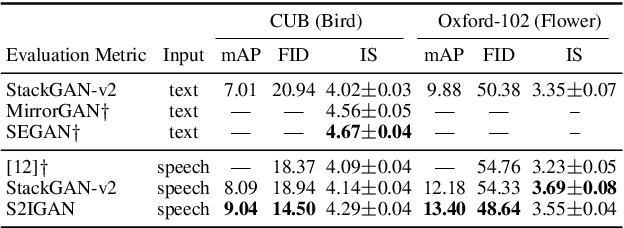


An estimated half of the world's languages do not have a written form, making it impossible for these languages to benefit from any existing text-based technologies. In this paper, a speech-to-image generation (S2IG) framework is proposed which translates speech descriptions to photo-realistic images without using any text information, thus allowing unwritten languages to potentially benefit from this technology. The proposed S2IG framework, named S2IGAN, consists of a speech embedding network (SEN) and a relation-supervised densely-stacked generative model (RDG). SEN learns the speech embedding with the supervision of the corresponding visual information. Conditioned on the speech embedding produced by SEN, the proposed RDG synthesizes images that are semantically consistent with the corresponding speech descriptions. Extensive experiments on two public benchmark datasets CUB and Oxford-102 demonstrate the effectiveness of the proposed S2IGAN on synthesizing high-quality and semantically-consistent images from the speech signal, yielding a good performance and a solid baseline for the S2IG task.
Maximum Entropy on the Mean: A Paradigm Shift for Regularization in Image Deblurring
Feb 24, 2020



Image deblurring is a notoriously challenging ill-posed inverse problem. In recent years, a wide variety of approaches have been proposed based upon regularization at the level of the image or on techniques from machine learning. We propose an alternative approach, shifting the paradigm towards regularization at the level of the probability distribution on the space of images. Our method is based upon the idea of maximum entropy on the mean wherein we work at the level of the probability density function of the image whose expectation is our estimate of the ground truth. Using techniques from convex analysis and probability theory, we show that the method is computationally feasible and amenable to very large blurs. Moreover, when images are imbedded with symbology (a known pattern), we show how our method can be applied to approximate the unknown blur kernel with remarkable effects. While our method is stable with respect to small amounts of noise, it does not actively denoise. However, for moderate to large amounts of noise, it performs well by preconditioned denoising with a state of the art method.
Eigencurve: Optimal Learning Rate Schedule for SGD on Quadratic Objectives with Skewed Hessian Spectrums
Oct 28, 2021
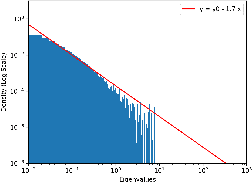
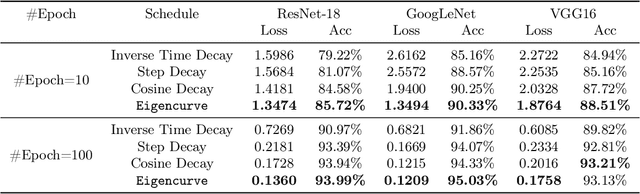
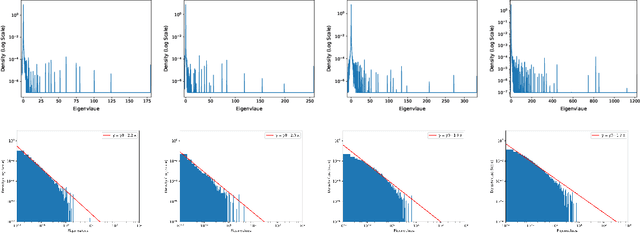
Learning rate schedulers have been widely adopted in training deep neural networks. Despite their practical importance, there is a discrepancy between its practice and its theoretical analysis. For instance, it is not known what schedules of SGD achieve best convergence, even for simple problems such as optimizing quadratic objectives. So far, step decay has been one of the strongest candidates under this setup, which is proved to be nearly optimal with a $\mathcal{O}(\log T)$ gap. However, according to our analysis, this gap turns out to be $\Omega(\log T)$ in a wide range of settings, which throws the schedule optimality problem into an open question again. Towards answering this reopened question, in this paper, we propose Eigencurve, the first family of learning rate schedules that can achieve minimax optimal convergence rates (up to a constant) for SGD on quadratic objectives when the eigenvalue distribution of the underlying Hessian matrix is skewed. The condition is quite common in practice. Experimental results show that Eigencurve can significantly outperform step decay in image classification tasks on CIFAR-10, especially when the number of epochs is small. Moreover, the theory inspires two simple learning rate schedulers for practical applications that can approximate Eigencurve. For some problems, the optimal shape of the proposed schedulers resembles that of cosine decay, which sheds light to the success of cosine decay for such situations. For other situations, the proposed schedulers are superior to cosine decay.
Deep Learning for Musculoskeletal Image Analysis
Mar 01, 2020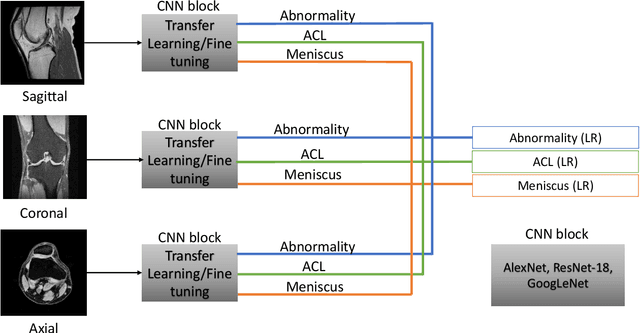
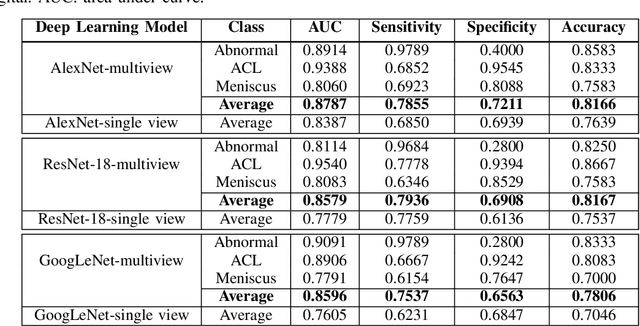
The diagnosis, prognosis, and treatment of patients with musculoskeletal (MSK) disorders require radiology imaging (using computed tomography, magnetic resonance imaging(MRI), and ultrasound) and their precise analysis by expert radiologists. Radiology scans can also help assessment of metabolic health, aging, and diabetes. This study presents how machinelearning, specifically deep learning methods, can be used for rapidand accurate image analysis of MRI scans, an unmet clinicalneed in MSK radiology. As a challenging example, we focus on automatic analysis of knee images from MRI scans and study machine learning classification of various abnormalities including meniscus and anterior cruciate ligament tears. Using widely used convolutional neural network (CNN) based architectures, we comparatively evaluated the knee abnormality classification performances of different neural network architectures under limited imaging data regime and compared single and multi-view imaging when classifying the abnormalities. Promising results indicated the potential use of multi-view deep learning based classification of MSK abnormalities in routine clinical assessment.
Dynamic Resolution Network
Jun 05, 2021
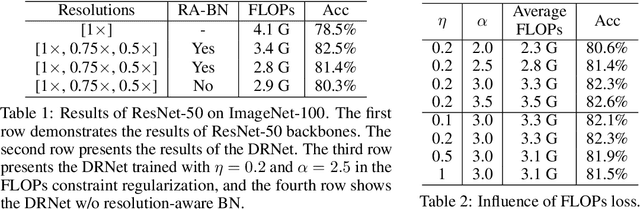
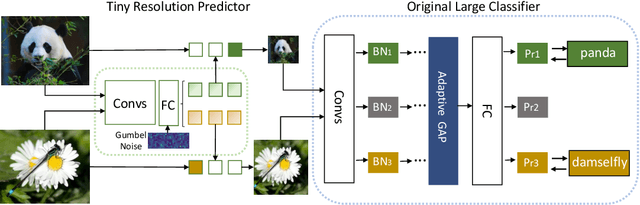
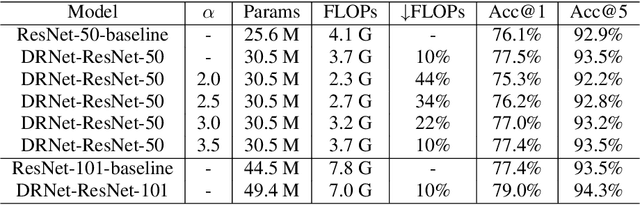
Deep convolutional neural networks (CNNs) are often of sophisticated design with numerous convolutional layers and learnable parameters for the accuracy reason. To alleviate the expensive costs of deploying them on mobile devices, recent works have made huge efforts for excavating redundancy in pre-defined architectures. Nevertheless, the redundancy on the input resolution of modern CNNs has not been fully investigated, i.e., the resolution of input image is fixed. In this paper, we observe that the smallest resolution for accurately predicting the given image is different using the same neural network. To this end, we propose a novel dynamic-resolution network (DRNet) in which the resolution is determined dynamically based on each input sample. Thus, a resolution predictor with negligible computational costs is explored and optimized jointly with the desired network. In practice, the predictor learns the smallest resolution that can retain and even exceed the original recognition accuracy for each image. During the inference, each input image will be resized to its predicted resolution for minimizing the overall computation burden. We then conduct extensive experiments on several benchmark networks and datasets. The results show that our DRNet can be embedded in any off-the-shelf network architecture to obtain a considerable reduction in computational complexity. For instance, DRNet achieves similar performance with an about 34% computation reduction, while gains 1.4% accuracy increase with 10% computation reduction compared to the original ResNet-50 on ImageNet.
O2NA: An Object-Oriented Non-Autoregressive Approach for Controllable Video Captioning
Aug 05, 2021
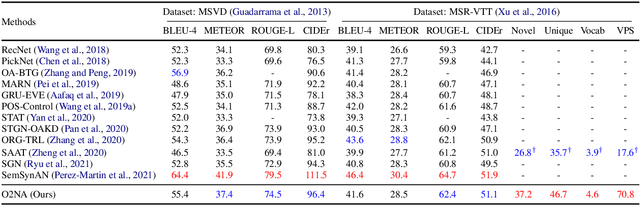
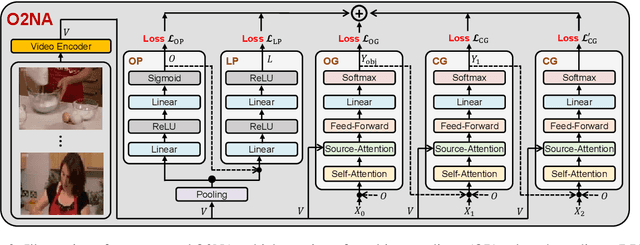
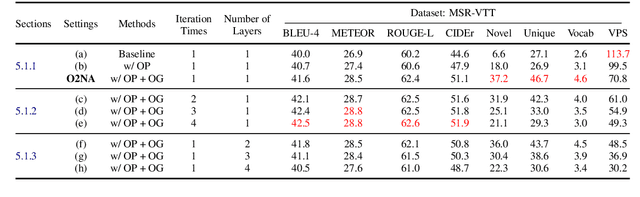
Video captioning combines video understanding and language generation. Different from image captioning that describes a static image with details of almost every object, video captioning usually considers a sequence of frames and biases towards focused objects, e.g., the objects that stay in focus regardless of the changing background. Therefore, detecting and properly accommodating focused objects is critical in video captioning. To enforce the description of focused objects and achieve controllable video captioning, we propose an Object-Oriented Non-Autoregressive approach (O2NA), which performs caption generation in three steps: 1) identify the focused objects and predict their locations in the target caption; 2) generate the related attribute words and relation words of these focused objects to form a draft caption; and 3) combine video information to refine the draft caption to a fluent final caption. Since the focused objects are generated and located ahead of other words, it is difficult to apply the word-by-word autoregressive generation process; instead, we adopt a non-autoregressive approach. The experiments on two benchmark datasets, i.e., MSR-VTT and MSVD, demonstrate the effectiveness of O2NA, which achieves results competitive with the state-of-the-arts but with both higher diversity and higher inference speed.
dp-GAN : Alleviating Mode Collapse in GAN via Diversity Penalty Module
Aug 05, 2021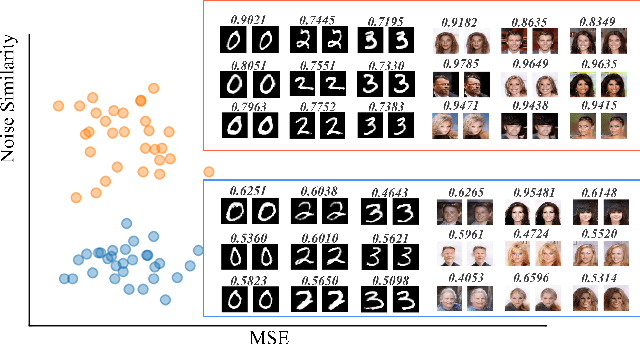
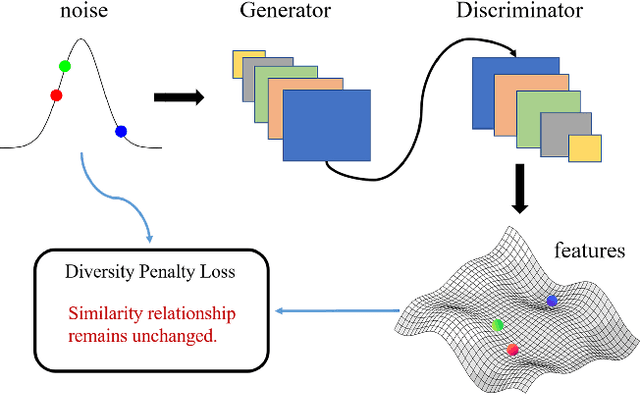
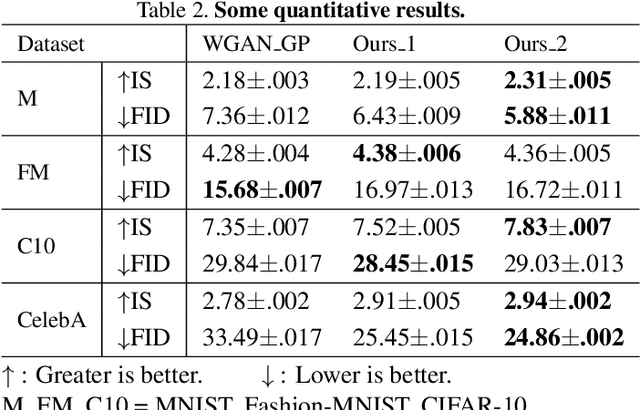
The vanilla GAN [5] suffers from mode collapse deeply, which usually manifests as that the images generated by generators tend to have a high similarity amongst them, even though their corresponding latent vectors have been very different. In this paper, we introduce a pluggable block called diversity penalty (dp) to alleviate mode collapse of GANs. It is used to reduce the similarity of image pairs in feature space, i.e., if two latent vectors are different, then we enforce the generator to generate two images with different features. The normalized Gram Matrix is used to measure the similarity. We compare the proposed method with Unrolled GAN [17], BourGAN [26], PacGAN [14], VEEGAN [23] and ALI [4] on 2D synthetic dataset, and results show that our proposed method can help GAN capture more modes of the data distribution. Further, we apply this penalty term into image data augmentation on MNIST, Fashion-MNIST and CIFAR-10, and the testing accuracy is improved by 0.24%, 1.34% and 0.52% compared with WGAN GP [6], respectively. Finally, we quantitatively evaluate the proposed method with IS and FID on CelebA, CIFAR-10, MNIST and Fashion-MNIST. Results show that our method gets much higher IS and lower FID compared with some current GAN architectures.
Federated Unlearning via Class-Discriminative Pruning
Oct 22, 2021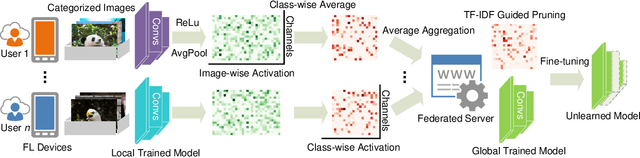



We explore the problem of selectively forgetting categories from trained CNN classification models in the federated learning (FL). Given that the data used for training cannot be accessed globally in FL, our insights probe deep into the internal influence of each channel. Through the visualization of feature maps activated by different channels, we observe that different channels have a varying contribution to different categories in image classification. Inspired by this, we propose a method for scrubbing the model clean of information about particular categories. The method does not require retraining from scratch, nor global access to the data used for training. Instead, we introduce the concept of Term Frequency Inverse Document Frequency (TF-IDF) to quantize the class discrimination of channels. Channels with high TF-IDF scores have more discrimination on the target categories and thus need to be pruned to unlearn. The channel pruning is followed by a fine-tuning process to recover the performance of the pruned model. Evaluated on CIFAR10 dataset, our method accelerates the speed of unlearning by 8.9x for the ResNet model, and 7.9x for the VGG model under no degradation in accuracy, compared to retraining from scratch. For CIFAR100 dataset, the speedups are 9.9x and 8.4x, respectively. We envision this work as a complementary block for FL towards compliance with legal and ethical criteria.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...
Image Segmentation using Multi-Threshold technique by Histogram Sampling
Sep 11, 2019
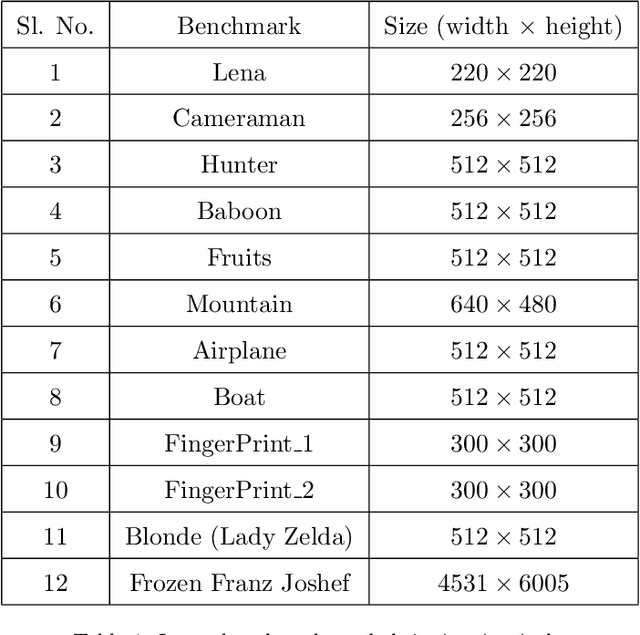
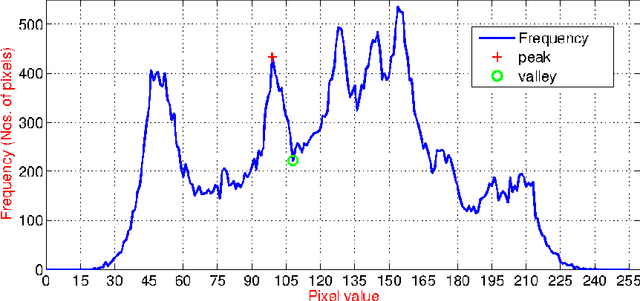
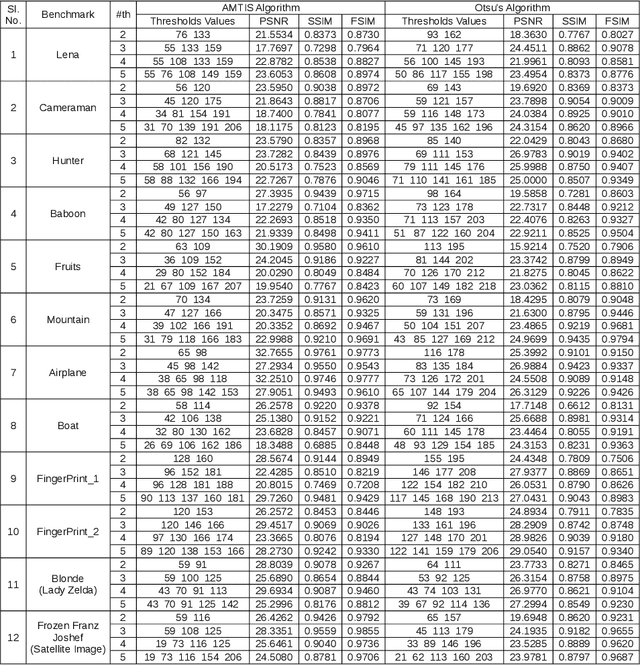
The segmentation of digital images is one of the essential steps in image processing or a computer vision system. It helps in separating the pixels into different regions according to their intensity level. A large number of segmentation techniques have been proposed, and a few of them use complex computational operations. Among all, the most straightforward procedure that can be easily implemented is thresholding. In this paper, we present a unique heuristic approach for image segmentation that automatically determines multilevel thresholds by sampling the histogram of a digital image. Our approach emphasis on selecting a valley as optimal threshold values. We demonstrated that our approach outperforms the popular Otsu's method in terms of CPU computational time. We demonstrated that our approach outperforms the popular Otsu's method in terms of CPU computational time. We observed a maximum speed-up of 35.58x and a minimum speed-up of 10.21x on popular image processing benchmarks. To demonstrate the correctness of our approach in determining threshold values, we compute PSNR, SSIM, and FSIM values to compare with the values obtained by Otsu's method. This evaluation shows that our approach is comparable and better in many cases as compared to well known Otsu's method.