 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CNNC: A Visual Analytics System for Comparative Studies of Deep Convolutional Neural Networks
Oct 25, 2021
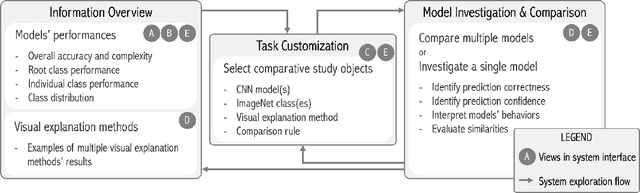
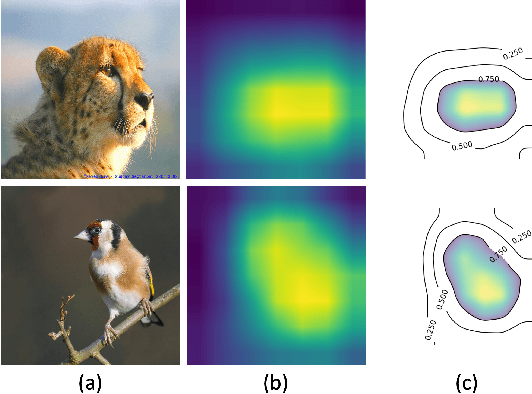

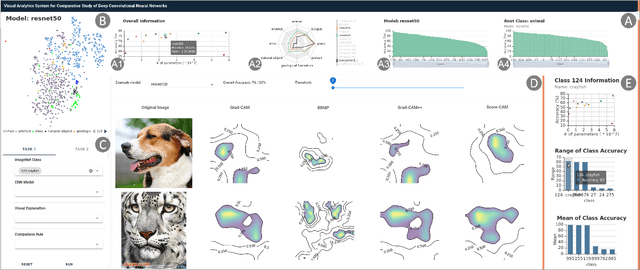
The rapid development of Convolutional Neural Networks (CNNs) in recent years has triggered significant breakthroughs in many machine learning (ML) applications. The ability to understand and compare various CNN models available is thus essential. The conventional approach with visualizing each model's quantitative features, such as classification accuracy and computational complexity, is not sufficient for a deeper understanding and comparison of the behaviors of different models. Moreover, most of the existing tools for assessing CNN behaviors only support comparison between two models and lack the flexibility of customizing the analysis tasks according to user needs. This paper presents a visual analytics system, CNN Comparator (CNNC), that supports the in-depth inspection of a single CNN model as well as comparative studies of two or more models. The ability to compare a larger number of (e.g., tens of) models especially distinguishes our system from previous ones. With a carefully designed model visualization and explaining support, CNNC facilitates a highly interactive workflow that promptly presents both quantitative and qualitative information at each analysis stage. We demonstrate CNNC's effectiveness for assisting ML practitioners in evaluating and comparing multiple CNN models through two use cases and one preliminary evaluation study using the image classification tasks on the ImageNet dataset.
Tomographic phase and attenuation extraction for a sample composed of unknown materials using X-ray propagation-based phase-contrast imaging
Oct 12, 2021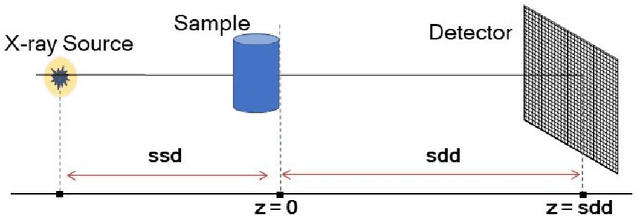
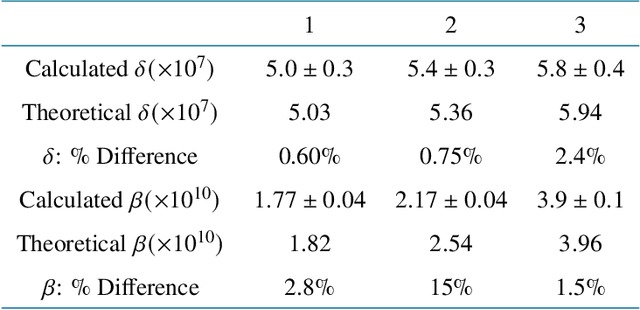
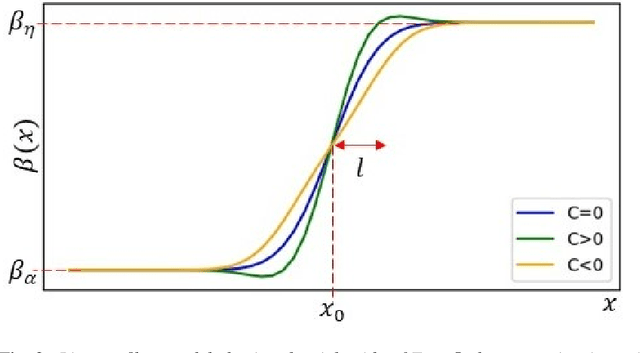
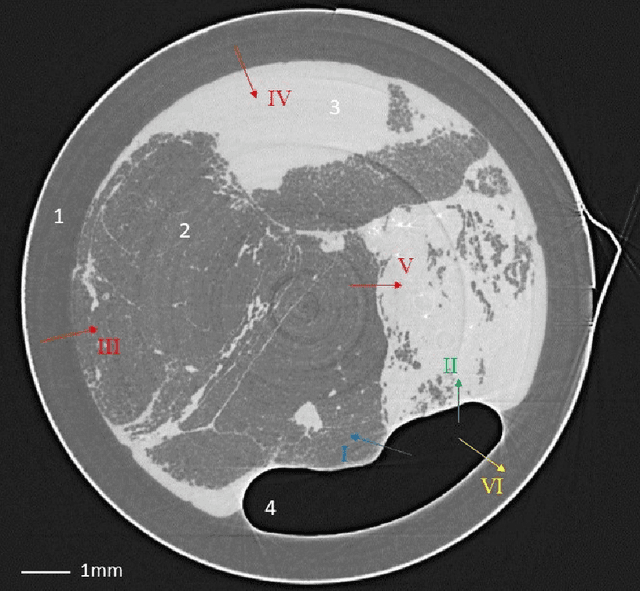
Propagation-based phase-contrast X-ray imaging (PB-PCXI) generates image contrast by utilizing sample-imposed phase-shifts. This has proven useful when imaging weakly-attenuating samples, as conventional attenuation-based imaging does not always provide adequate contrast. We present a PB-PCXI algorithm capable of extracting the X-ray attenuation, $\beta$, and refraction, $\delta$, components of the complex refractive index of distinct materials within an unknown sample. The method involves curve-fitting an error-function-based model to a phase-retrieved interface in a PB-PCXI tomographic reconstruction, which is obtained when Paganin-type phase-retrieval is applied with incorrect values of $\delta$ and $\beta$. The fit parameters can then be used to calculate true $\delta$ and $\beta$ values for composite materials. This approach requires no a priori sample information, making it broadly applicable. Our PB-PCXI reconstruction is single distance, requiring only one exposure per tomographic angle, which is important for radiosensitive samples. We apply this approach to a breast-tissue sample, recovering the refraction component, $\delta$, with 0.6 - 2.4\% accuracy compared to theoretical values.
ShapeEditer: a StyleGAN Encoder for Face Swapping
Jun 26, 2021
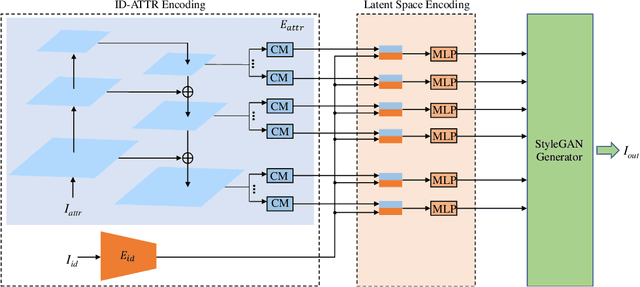

In this paper, we propose a novel encoder, called ShapeEditor, for high-resolution, realistic and high-fidelity face exchange. First of all, in order to ensure sufficient clarity and authenticity, our key idea is to use an advanced pretrained high-quality random face image generator, i.e. StyleGAN, as backbone. Secondly, we design ShapeEditor, a two-step encoder, to make the swapped face integrate the identity and attribute of the input faces. In the first step, we extract the identity vector of the source image and the attribute vector of the target image respectively; in the second step, we map the concatenation of identity vector and attribute vector into the $\mathcal{W+}$ potential space. In addition, for learning to map into the latent space of StyleGAN, we propose a set of self-supervised loss functions with which the training data do not need to be labeled manually. Extensive experiments on the test dataset show that the results of our method not only have a great advantage in clarity and authenticity than other state-of-the-art methods, but also reflect the sufficient integration of identity and attribute.
Image Modeling with Deep Convolutional Gaussian Mixture Models
Apr 19, 2021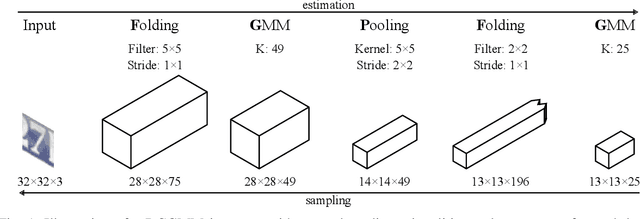

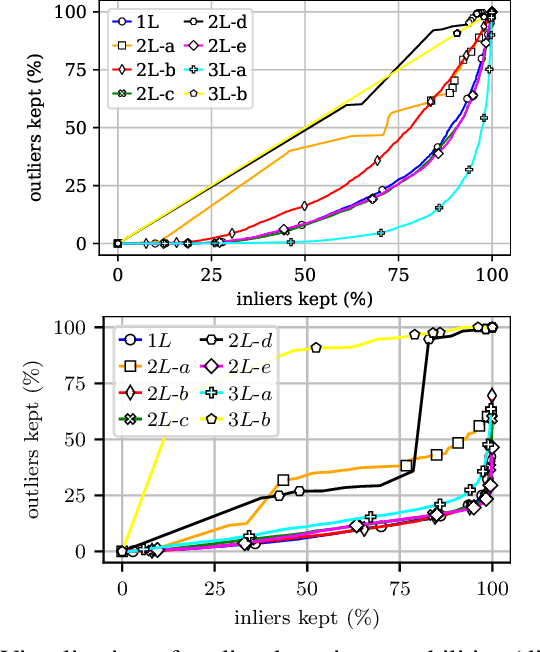

In this conceptual work, we present Deep Convolutional Gaussian Mixture Models (DCGMMs): a new formulation of deep hierarchical Gaussian Mixture Models (GMMs) that is particularly suitable for describing and generating images. Vanilla (i.e., flat) GMMs require a very large number of components to describe images well, leading to long training times and memory issues. DCGMMs avoid this by a stacked architecture of multiple GMM layers, linked by convolution and pooling operations. This allows to exploit the compositionality of images in a similar way as deep CNNs do. DCGMMs can be trained end-to-end by Stochastic Gradient Descent. This sets them apart from vanilla GMMs which are trained by Expectation-Maximization, requiring a prior k-means initialization which is infeasible in a layered structure. For generating sharp images with DCGMMs, we introduce a new gradient-based technique for sampling through non-invertible operations like convolution and pooling. Based on the MNIST and FashionMNIST datasets, we validate the DCGMMs model by demonstrating its superiority over flat GMMs for clustering, sampling and outlier detection.
MultiSiam: Self-supervised Multi-instance Siamese Representation Learning for Autonomous Driving
Aug 27, 2021
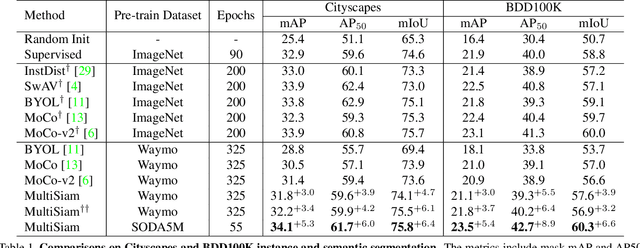
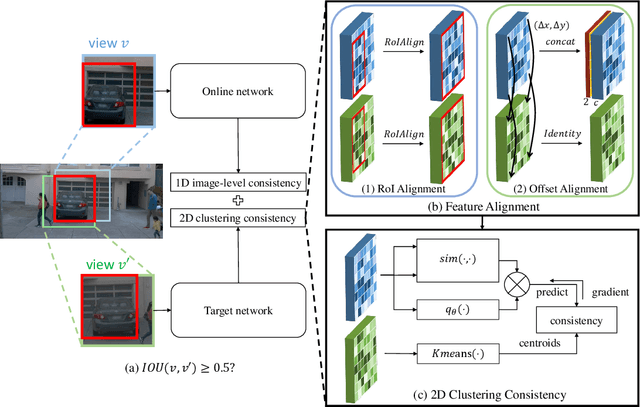
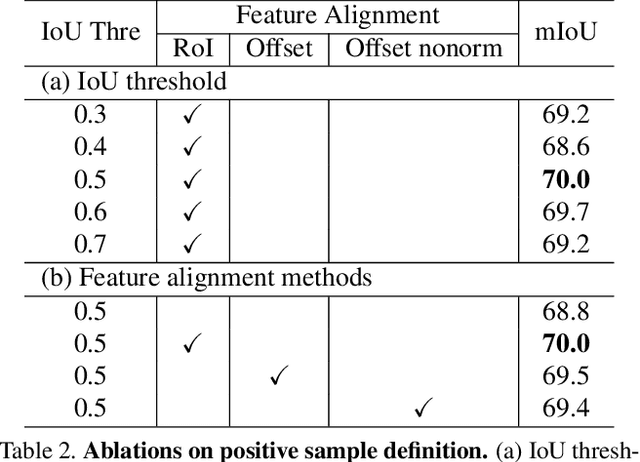
Autonomous driving has attracted much attention over the years but turns out to be harder than expected, probably due to the difficulty of labeled data collection for model training. Self-supervised learning (SSL), which leverages unlabeled data only for representation learning, might be a promising way to improve model performance. Existing SSL methods, however, usually rely on the single-centric-object guarantee, which may not be applicable for multi-instance datasets such as street scenes. To alleviate this limitation, we raise two issues to solve: (1) how to define positive samples for cross-view consistency and (2) how to measure similarity in multi-instance circumstances. We first adopt an IoU threshold during random cropping to transfer global-inconsistency to local-consistency. Then, we propose two feature alignment methods to enable 2D feature maps for multi-instance similarity measurement. Additionally, we adopt intra-image clustering with self-attention for further mining intra-image similarity and translation-invariance. Experiments show that, when pre-trained on Waymo dataset, our method called Multi-instance Siamese Network (MultiSiam) remarkably improves generalization ability and achieves state-of-the-art transfer performance on autonomous driving benchmarks, including Cityscapes and BDD100K, while existing SSL counterparts like MoCo, MoCo-v2, and BYOL show significant performance drop. By pre-training on SODA10M, a large-scale autonomous driving dataset, MultiSiam exceeds the ImageNet pre-trained MoCo-v2, demonstrating the potential of domain-specific pre-training. Code will be available at https://github.com/KaiChen1998/MultiSiam.
Leveraging Multiple CNNs for Triaging Medical Workflow
Sep 27, 2021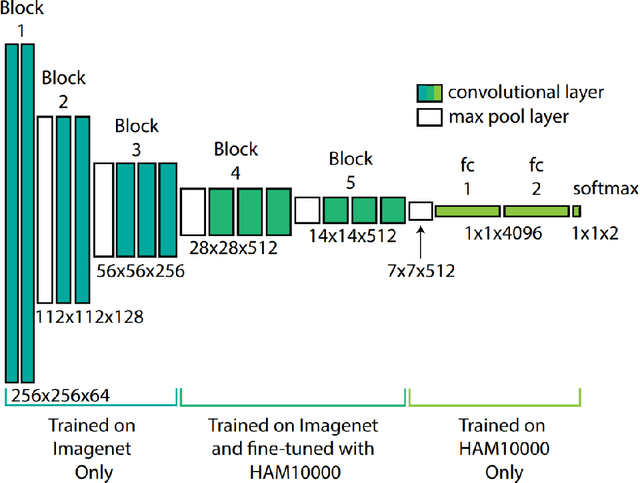
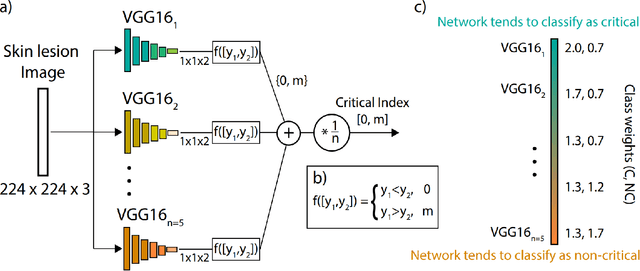
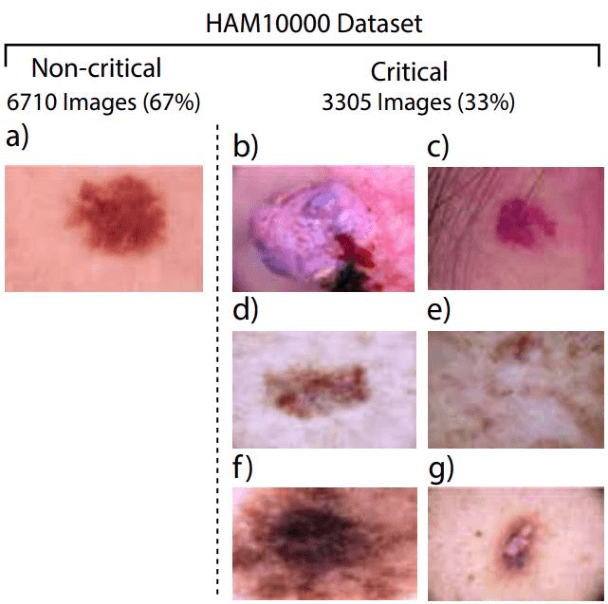
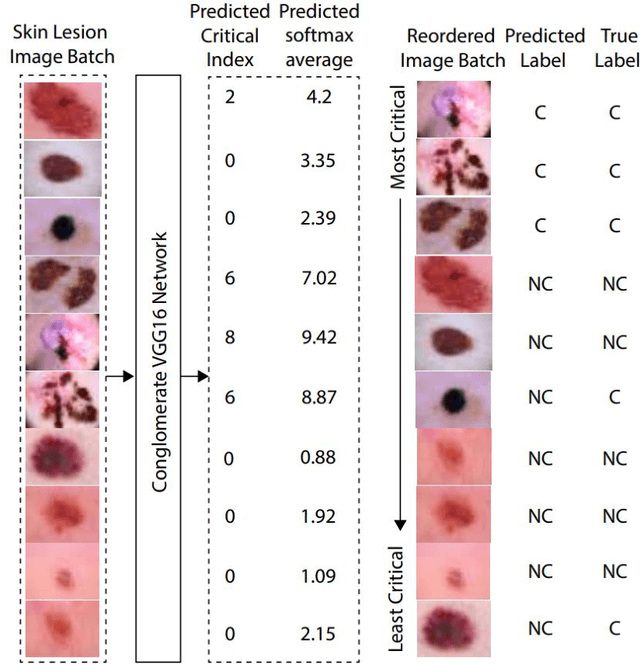
High hospitalization rates due to the global spread of Covid-19 bring about a need for improvements to classical triaging workflows. To this end, convolutional neural networks (CNNs) can effectively differentiate critical from non-critical images so that critical cases may be addressed quickly, so long as there exists some representative image for the illness. Presented is a conglomerate neural network system consisting of multiple VGG16 CNNs; the system trains on weighted skin disease images re-labelled as critical or non-critical, to then attach to input images a critical index between 0 and 10. A critical index offers a more comprehensive rating system compared to binary critical/non-critical labels. Results for batches of input images run through the trained network are promising. A batch is shown being re-ordered by the proposed architecture from most critical to least critical roughly accurately.
A Label Management Mechanism for Retinal Fundus Image Classification of Diabetic Retinopathy
Jun 23, 2021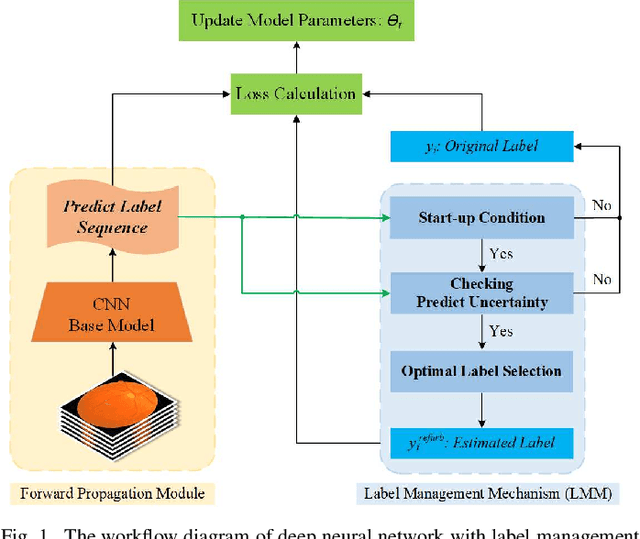
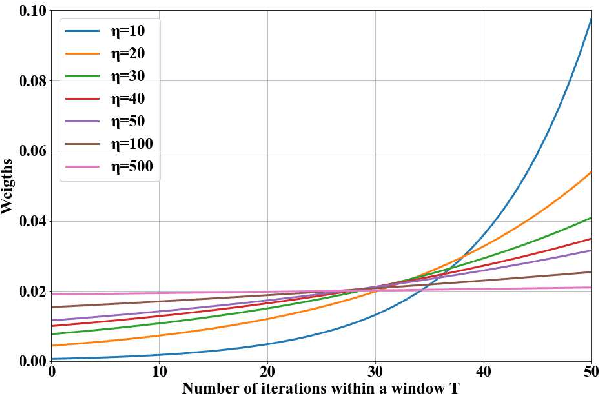
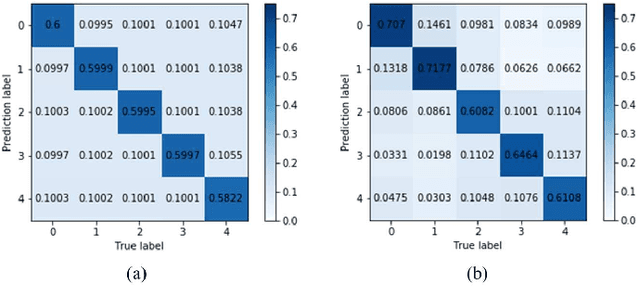
Diabetic retinopathy (DR) remains the most prevalent cause of vision impairment and irreversible blindness in the working-age adults. Due to the renaissance of deep learning (DL), DL-based DR diagnosis has become a promising tool for the early screening and severity grading of DR. However, training deep neural networks (DNNs) requires an enormous amount of carefully labeled data. Noisy label data may be introduced when labeling plenty of data, degrading the performance of models. In this work, we propose a novel label management mechanism (LMM) for the DNN to overcome overfitting on the noisy data. LMM utilizes maximum posteriori probability (MAP) in the Bayesian statistic and time-weighted technique to selectively correct the labels of unclean data, which gradually purify the training data and improve classification performance. Comprehensive experiments on both synthetic noise data (Messidor \& our collected DR dataset) and real-world noise data (ANIMAL-10N) demonstrated that LMM could boost performance of models and is superior to three state-of-the-art methods.
Where were my keys? -- Aggregating Spatial-Temporal Instances of Objects for Efficient Retrieval over Long Periods of Time
Oct 25, 2021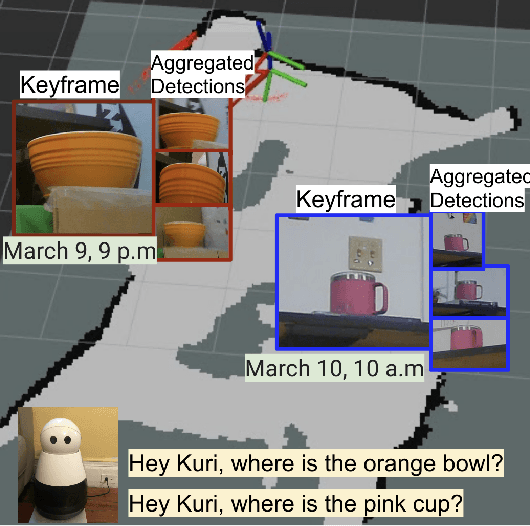

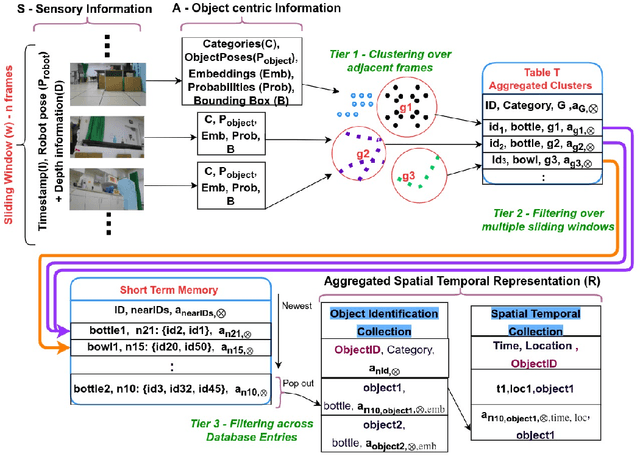
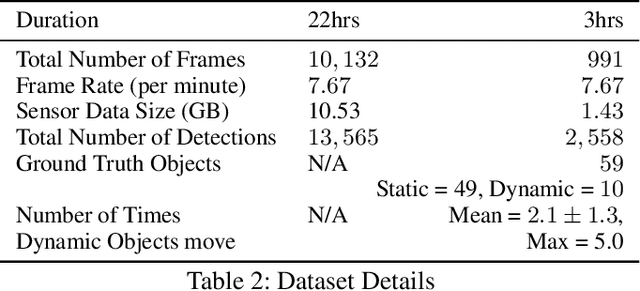
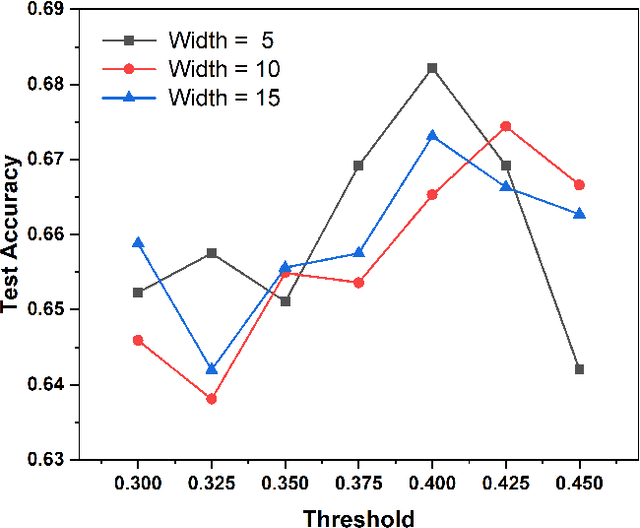
Robots equipped with situational awareness can help humans efficiently find their lost objects by leveraging spatial and temporal structure. Existing approaches to video and image retrieval do not take into account the unique constraints imposed by a moving camera with a partial view of the environment. We present a Detection-based 3-level hierarchical Association approach, D3A, to create an efficient query-able spatial-temporal representation of unique object instances in an environment. D3A performs online incremental and hierarchical learning to identify keyframes that best represent the unique objects in the environment. These keyframes are learned based on both spatial and temporal features and once identified their corresponding spatial-temporal information is organized in a key-value database. D3A allows for a variety of query patterns such as querying for objects with/without the following: 1) specific attributes, 2) spatial relationships with other objects, and 3) time slices. For a given set of 150 queries, D3A returns a small set of candidate keyframes (which occupy only 0.17% of the total sensory data) with 81.98\% mean accuracy in 11.7 ms. This is 47x faster and 33% more accurate than a baseline that naively stores the object matches (detections) in the database without associating spatial-temporal information.
Towards Compact Single Image Super-Resolution via Contrastive Self-distillation
May 25, 2021
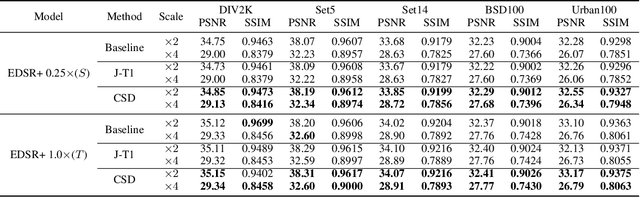
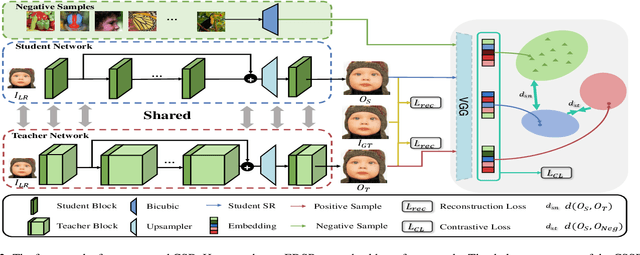
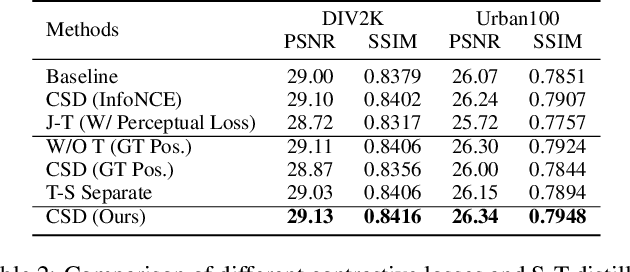
Convolutional neural networks (CNNs) are highly successful for super-resolution (SR) but often require sophisticated architectures with heavy memory cost and computational overhead, significantly restricts their practical deployments on resource-limited devices. In this paper, we proposed a novel contrastive self-distillation (CSD) framework to simultaneously compress and accelerate various off-the-shelf SR models. In particular, a channel-splitting super-resolution network can first be constructed from a target teacher network as a compact student network. Then, we propose a novel contrastive loss to improve the quality of SR images and PSNR/SSIM via explicit knowledge transfer. Extensive experiments demonstrate that the proposed CSD scheme effectively compresses and accelerates several standard SR models such as EDSR, RCAN and CARN. Code is available at https://github.com/Booooooooooo/CSD.
CIPS-3D: A 3D-Aware Generator of GANs Based on Conditionally-Independent Pixel Synthesis
Oct 19, 2021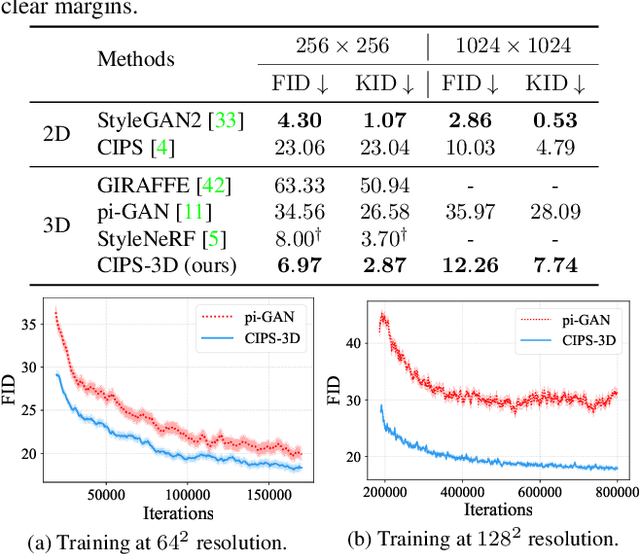
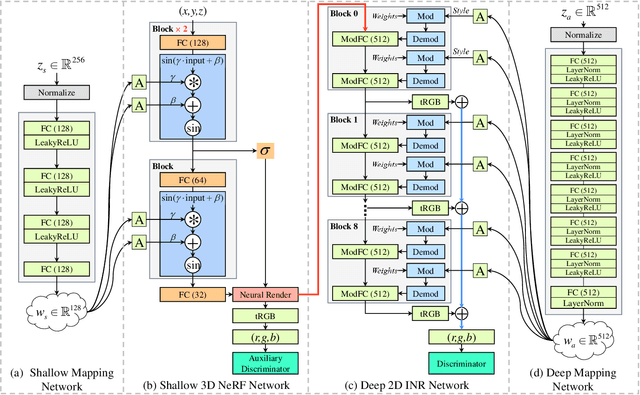

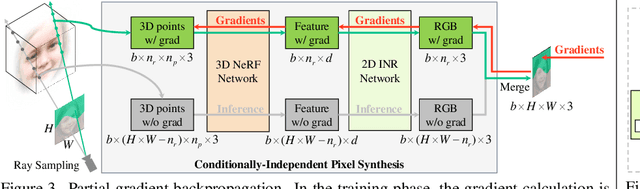
The style-based GAN (StyleGAN) architecture achieved state-of-the-art results for generating high-quality images, but it lacks explicit and precise control over camera poses. The recently proposed NeRF-based GANs made great progress towards 3D-aware generators, but they are unable to generate high-quality images yet. This paper presents CIPS-3D, a style-based, 3D-aware generator that is composed of a shallow NeRF network and a deep implicit neural representation (INR) network. The generator synthesizes each pixel value independently without any spatial convolution or upsampling operation. In addition, we diagnose the problem of mirror symmetry that implies a suboptimal solution and solve it by introducing an auxiliary discriminator. Trained on raw, single-view images, CIPS-3D sets new records for 3D-aware image synthesis with an impressive FID of 6.97 for images at the $256\times256$ resolution on FFHQ. We also demonstrate several interesting directions for CIPS-3D such as transfer learning and 3D-aware face stylization. The synthesis results are best viewed as videos, so we recommend the readers to check our github project at https://github.com/PeterouZh/CIPS-3D