 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automatic Multi-Stain Registration of Whole Slide Images in Histopathology
Jul 29, 2021
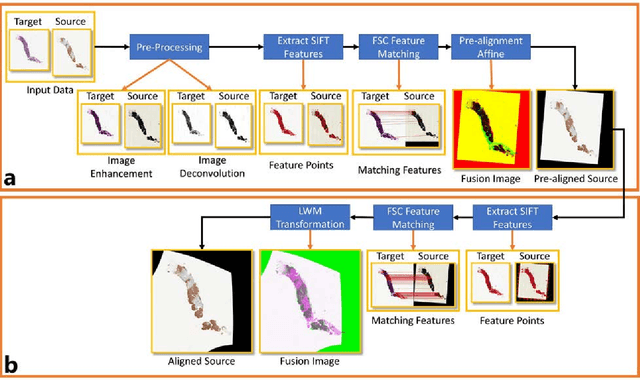
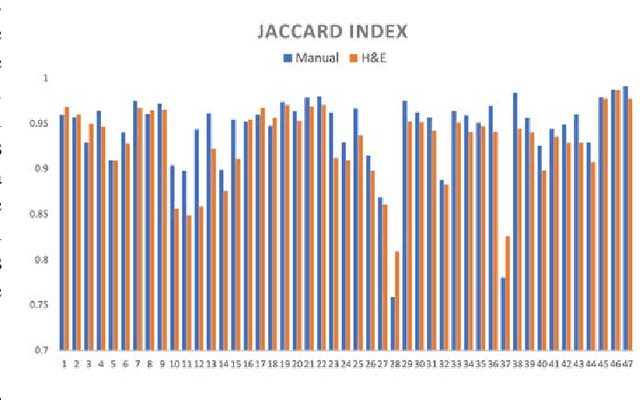
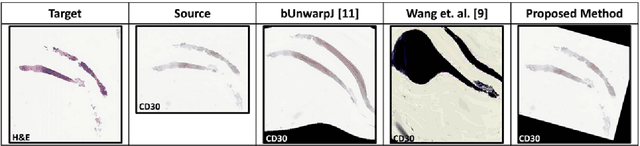
Joint analysis of multiple biomarker images and tissue morphology is important for disease diagnosis, treatment planning and drug development. It requires cross-staining comparison among Whole Slide Images (WSIs) of immuno-histochemical and hematoxylin and eosin (H&E) microscopic slides. However, automatic, and fast cross-staining alignment of enormous gigapixel WSIs at single-cell precision is challenging. In addition to morphological deformations introduced during slide preparation, there are large variations in cell appearance and tissue morphology across different staining. In this paper, we propose a two-step automatic feature-based cross-staining WSI alignment to assist localization of even tiny metastatic foci in the assessment of lymph node. Image pairs were aligned allowing for translation, rotation, and scaling. The registration was performed automatically by first detecting landmarks in both images, using the scale-invariant image transform (SIFT), followed by the fast sample consensus (FSC) protocol for finding point correspondences and finally aligned the images. The Registration results were evaluated using both visual and quantitative criteria using the Jaccard index. The average Jaccard similarity index of the results produced by the proposed system is 0.942 when compared with the manual registration.
Generative Imaging and Image Processing via Generative Encoder
May 23, 2019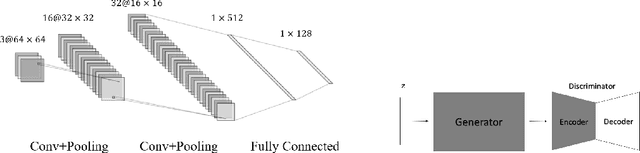

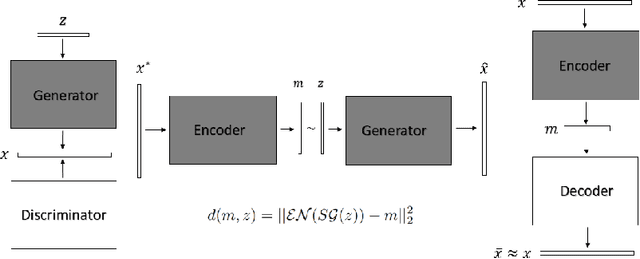

This paper introduces a novel generative encoder (GE) model for generative imaging and image processing with applications in compressed sensing and imaging, image compression, denoising, inpainting, deblurring, and super-resolution. The GE model consists of a pre-training phase and a solving phase. In the pre-training phase, we separately train two deep neural networks: a generative adversarial network (GAN) with a generator $\G$ that captures the data distribution of a given image set, and an auto-encoder (AE) network with an encoder $\EN$ that compresses images following the estimated distribution by GAN. In the solving phase, given a noisy image $x=\mathcal{P}(x^*)$, where $x^*$ is the target unknown image, $\mathcal{P}$ is an operator adding an addictive, or multiplicative, or convolutional noise, or equivalently given such an image $x$ in the compressed domain, i.e., given $m=\EN(x)$, we solve the optimization problem \[ z^*=\underset{z}{\mathrm{argmin}} \|\EN(\G(z))-m\|_2^2+\lambda\|z\|_2^2 \] to recover the image $x^*$ in a generative way via $\hat{x}:=\G(z^*)\approx x^*$, where $\lambda>0$ is a hyperparameter. The GE model unifies the generative capacity of GANs and the stability of AEs in an optimization framework above instead of stacking GANs and AEs into a single network or combining their loss functions into one as in existing literature. Numerical experiments show that the proposed model outperforms several state-of-the-art algorithms.
Explainable, automated urban interventions to improve pedestrian and vehicle safety
Oct 22, 2021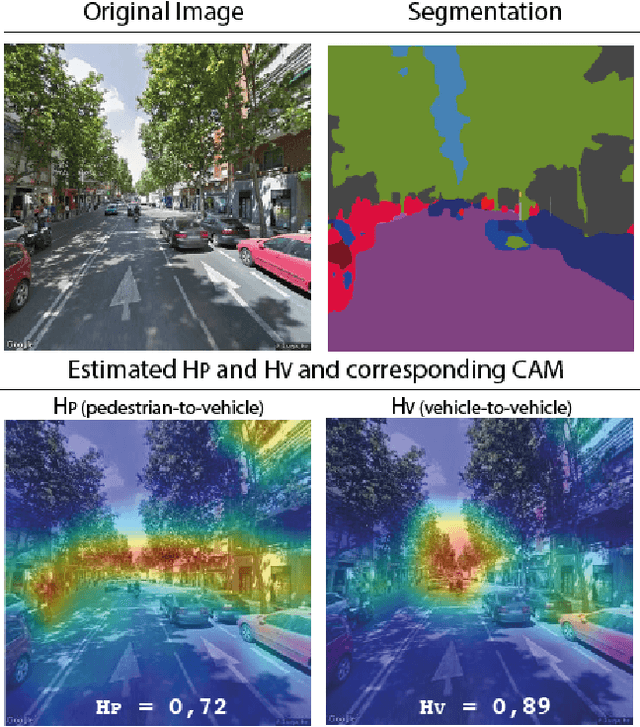
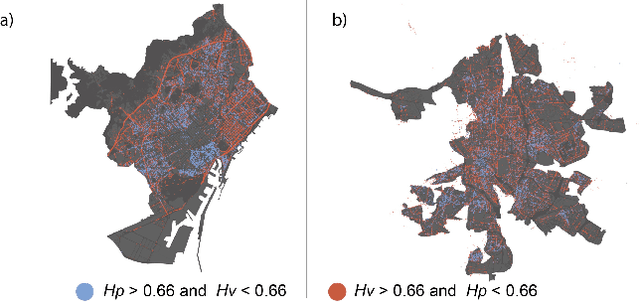
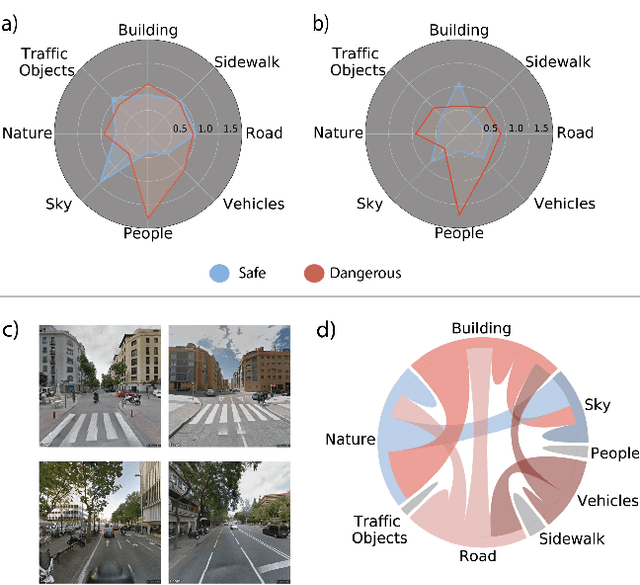
At the moment, urban mobility research and governmental initiatives are mostly focused on motor-related issues, e.g. the problems of congestion and pollution. And yet, we can not disregard the most vulnerable elements in the urban landscape: pedestrians, exposed to higher risks than other road users. Indeed, safe, accessible, and sustainable transport systems in cities are a core target of the UN's 2030 Agenda. Thus, there is an opportunity to apply advanced computational tools to the problem of traffic safety, in regards especially to pedestrians, who have been often overlooked in the past. This paper combines public data sources, large-scale street imagery and computer vision techniques to approach pedestrian and vehicle safety with an automated, relatively simple, and universally-applicable data-processing scheme. The steps involved in this pipeline include the adaptation and training of a Residual Convolutional Neural Network to determine a hazard index for each given urban scene, as well as an interpretability analysis based on image segmentation and class activation mapping on those same images. Combined, the outcome of this computational approach is a fine-grained map of hazard levels across a city, and an heuristic to identify interventions that might simultaneously improve pedestrian and vehicle safety. The proposed framework should be taken as a complement to the work of urban planners and public authorities.
An overcome of far-distance limitation on tunnel CCTV-based accident detection in AI deep-learning frameworks
Jul 22, 2021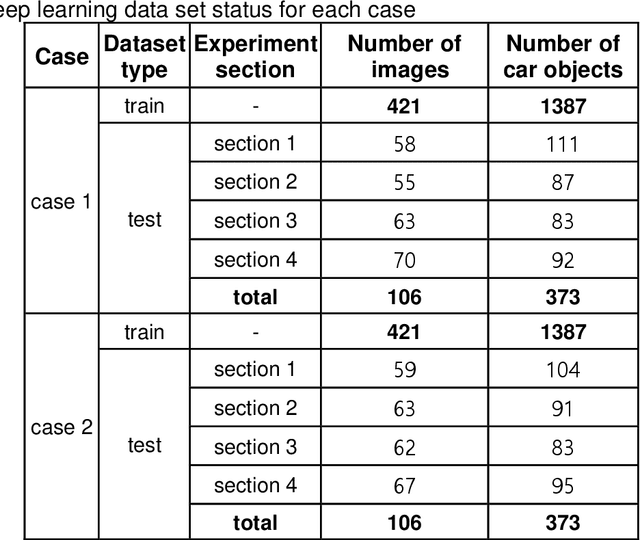
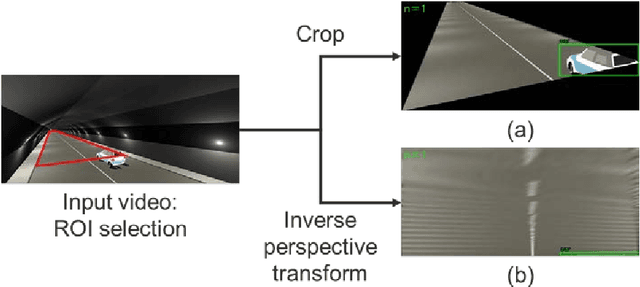
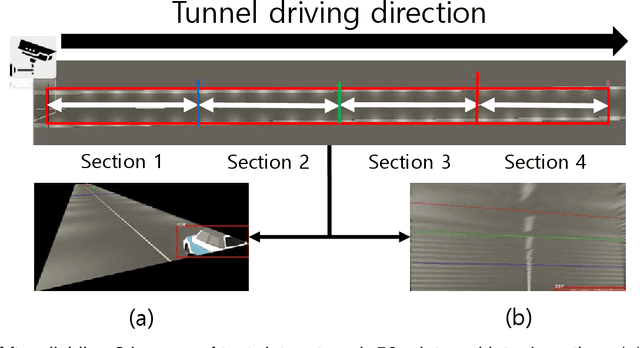
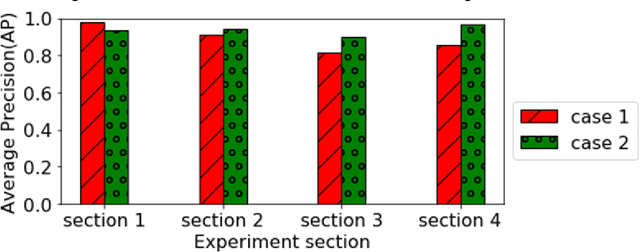
Tunnel CCTVs are installed to low height and long-distance interval. However, because of the limitation of installation height, severe perspective effect in distance occurs, and it is almost impossible to detect vehicles in far distance from the CCTV in the existing tunnel CCTV-based accident detection system (Pflugfelder 2005). To overcome the limitation, a vehicle object is detected through an object detection algorithm based on an inverse perspective transform by re-setting the region of interest (ROI). It can detect vehicles that are far away from the CCTV. To verify this process, this paper creates each dataset consisting of images and bounding boxes based on the original and warped images of the CCTV at the same time, and then compares performance of the deep learning object detection models trained with the two datasets. As a result, the model that trained the warped image was able to detect vehicle objects more accurately at the position far from the CCTV compared to the model that trained the original image.
Towards Robust Classification Model by Counterfactual and Invariant Data Generation
Jun 03, 2021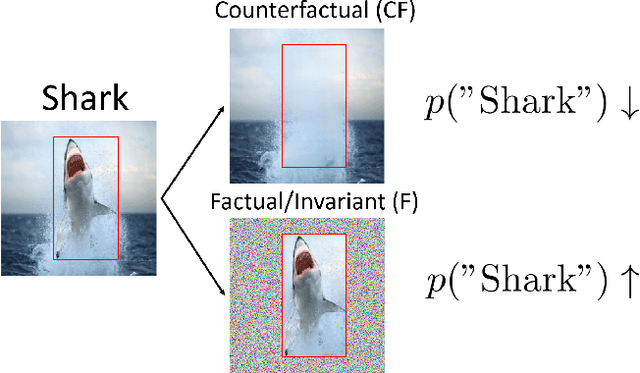
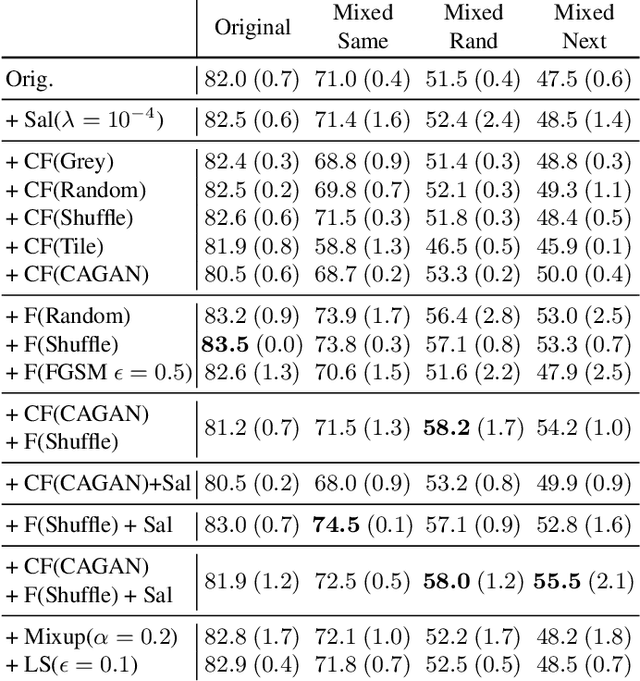

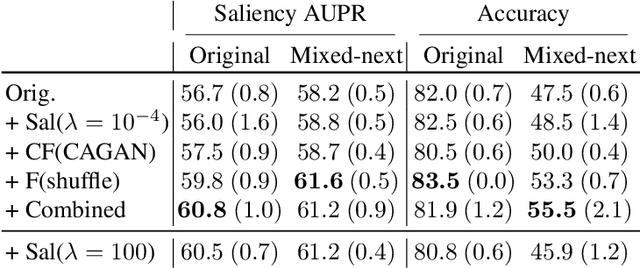
Despite the success of machine learning applications in science, industry, and society in general, many approaches are known to be non-robust, often relying on spurious correlations to make predictions. Spuriousness occurs when some features correlate with labels but are not causal; relying on such features prevents models from generalizing to unseen environments where such correlations break. In this work, we focus on image classification and propose two data generation processes to reduce spuriousness. Given human annotations of the subset of the features responsible (causal) for the labels (e.g. bounding boxes), we modify this causal set to generate a surrogate image that no longer has the same label (i.e. a counterfactual image). We also alter non-causal features to generate images still recognized as the original labels, which helps to learn a model invariant to these features. In several challenging datasets, our data generations outperform state-of-the-art methods in accuracy when spurious correlations break, and increase the saliency focus on causal features providing better explanations.
Modeling Conceptual Understanding in Image Reference Games
Oct 10, 2019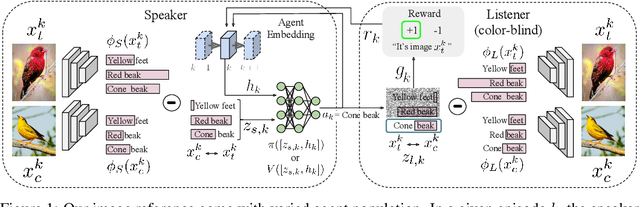
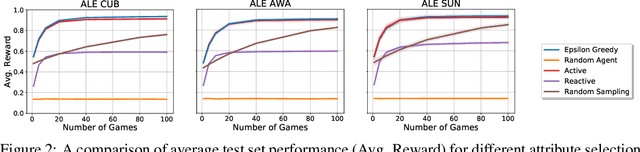
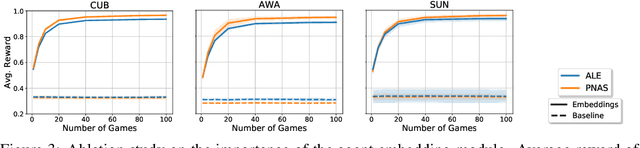
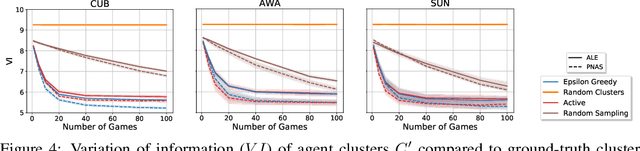
An agent who interacts with a wide population of other agents needs to be aware that there may be variations in their understanding of the world. Furthermore, the machinery which they use to perceive may be inherently different, as is the case between humans and machines. In this work, we present both an image reference game between a speaker and a population of listeners where reasoning about the concepts other agents can comprehend is necessary and a model formulation with this capability. We focus on reasoning about the conceptual understanding of others, as well as adapting to novel gameplay partners and dealing with differences in perceptual machinery. Our experiments on three benchmark image/attribute datasets suggest that our learner indeed encodes information directly pertaining to the understanding of other agents, and that leveraging this information is crucial for maximizing gameplay performance.
Lifelong GAN: Continual Learning for Conditional Image Generation
Jul 23, 2019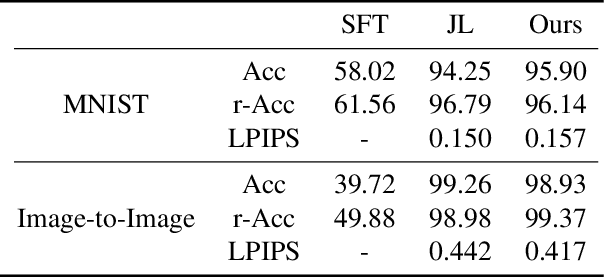
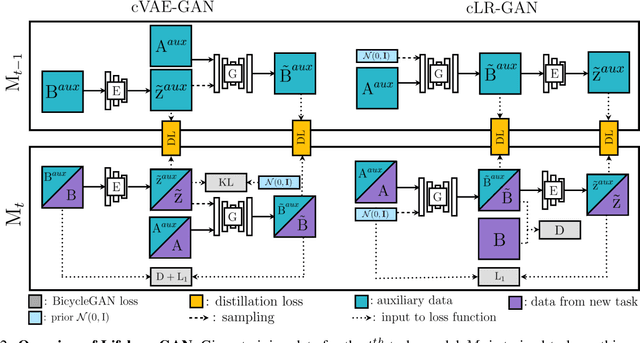
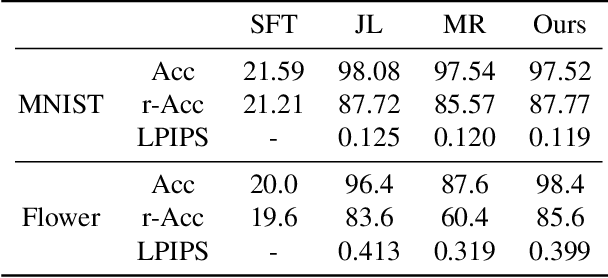

Lifelong learning is challenging for deep neural networks due to their susceptibility to catastrophic forgetting. Catastrophic forgetting occurs when a trained network is not able to maintain its ability to accomplish previously learned tasks when it is trained to perform new tasks. We study the problem of lifelong learning for generative models, extending a trained network to new conditional generation tasks without forgetting previous tasks, while assuming access to the training data for the current task only. In contrast to state-of-the-art memory replay based approaches which are limited to label-conditioned image generation tasks, a more generic framework for continual learning of generative models under different conditional image generation settings is proposed in this paper. Lifelong GAN employs knowledge distillation to transfer learned knowledge from previous networks to the new network. This makes it possible to perform image-conditioned generation tasks in a lifelong learning setting. We validate Lifelong GAN for both image-conditioned and label-conditioned generation tasks, and provide qualitative and quantitative results to show the generality and effectiveness of our method.
Neural Network Pruning Through Constrained Reinforcement Learning
Oct 16, 2021
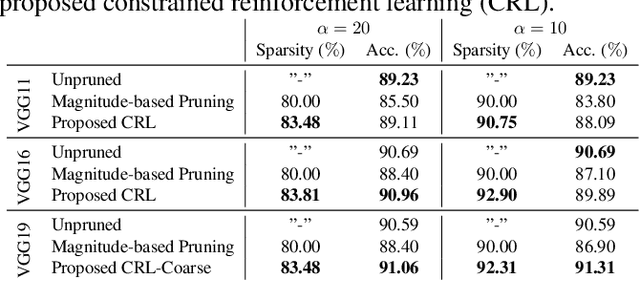
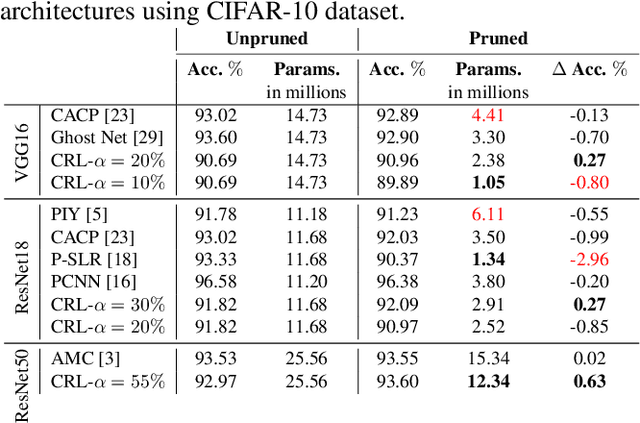
Network pruning reduces the size of neural networks by removing (pruning) neurons such that the performance drop is minimal. Traditional pruning approaches focus on designing metrics to quantify the usefulness of a neuron which is often quite tedious and sub-optimal. More recent approaches have instead focused on training auxiliary networks to automatically learn how useful each neuron is however, they often do not take computational limitations into account. In this work, we propose a general methodology for pruning neural networks. Our proposed methodology can prune neural networks to respect pre-defined computational budgets on arbitrary, possibly non-differentiable, functions. Furthermore, we only assume the ability to be able to evaluate these functions for different inputs, and hence they do not need to be fully specified beforehand. We achieve this by proposing a novel pruning strategy via constrained reinforcement learning algorithms. We prove the effectiveness of our approach via comparison with state-of-the-art methods on standard image classification datasets. Specifically, we reduce 83-92.90 of total parameters on various variants of VGG while achieving comparable or better performance than that of original networks. We also achieved 75.09 reduction in parameters on ResNet18 without incurring any loss in accuracy.
Generating Thermal Image Data Samples using 3D Facial Modelling Techniques and Deep Learning Methodologies
May 07, 2020



Methods for generating synthetic data have become of increasing importance to build large datasets required for Convolution Neural Networks (CNN) based deep learning techniques for a wide range of computer vision applications. In this work, we extend existing methodologies to show how 2D thermal facial data can be mapped to provide 3D facial models. For the proposed research work we have used tufts datasets for generating 3D varying face poses by using a single frontal face pose. The system works by refining the existing image quality by performing fusion based image preprocessing operations. The refined outputs have better contrast adjustments, decreased noise level and higher exposedness of the dark regions. It makes the facial landmarks and temperature patterns on the human face more discernible and visible when compared to original raw data. Different image quality metrics are used to compare the refined version of images with original images. In the next phase of the proposed study, the refined version of images is used to create 3D facial geometry structures by using Convolution Neural Networks (CNN). The generated outputs are then imported in blender software to finally extract the 3D thermal facial outputs of both males and females. The same technique is also used on our thermal face data acquired using prototype thermal camera (developed under Heliaus EU project) in an indoor lab environment which is then used for generating synthetic 3D face data along with varying yaw face angles and lastly facial depth map is generated.
Transferability of Adversarial Examples to Attack Cloud-based Image Classifier Service
Jan 20, 2020

In recent years, Deep Learning(DL) techniques have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. While many recent works demonstrated that DL models are vulnerable to adversarial examples. Fortunately, generating adversarial examples usually requires white-box access to the victim model, and real-world cloud-based image classification services are more complex than white-box classifier,the architecture and parameters of DL models on cloud platforms cannot be obtained by the attacker. The attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security. In this paper, we mainly focus on studying the security of real-world cloud-based image classification services. Specifically, (1) We propose a novel attack method, Fast Featuremap Loss PGD (FFL-PGD) attack based on Substitution model, which achieves a high bypass rate with a very limited number of queries. Instead of millions of queries in previous studies, our method finds the adversarial examples using only two queries per image; and (2) we make the first attempt to conduct an extensive empirical study of black-box attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that FFL-PGD attack has a success rate over 90\% among different classification services. (3) We discuss the possible defenses to address these security challenges in cloud-based classification services. Our defense technology is mainly divided into model training stage and image preprocessing stage.