 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Human Eye-based Text Color Scheme Generation Method for Image Synthesis
Oct 15, 2020
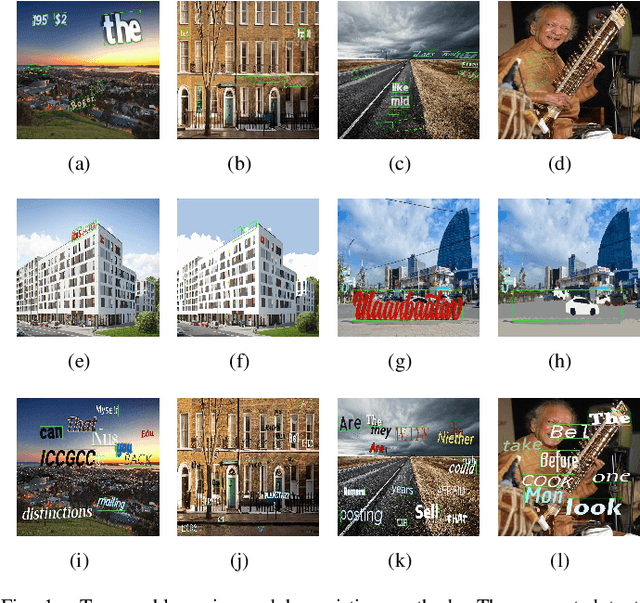
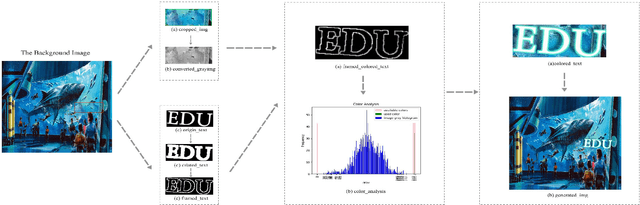

Synthetic data used for scene text detection and recognition tasks have proven effective. However, there are still two problems: First, the color schemes used for text coloring in the existing methods are relatively fixed color key-value pairs learned from real datasets. The dirty data in real datasets may cause the problem that the colors of text and background are too similar to be distinguished from each other. Second, the generated texts are uniformly limited to the same depth of a picture, while there are special cases in the real world that text may appear across depths. To address these problems, in this paper we design a novel method to generate color schemes, which are consistent with the characteristics of human eyes to observe things. The advantages of our method are as follows: (1) overcomes the color confusion problem between text and background caused by dirty data; (2) the texts generated are allowed to appear in most locations of any image, even across depths; (3) avoids analyzing the depth of background, such that the performance of our method exceeds the state-of-the-art methods; (4) the speed of generating images is fast, nearly one picture generated per three milliseconds. The effectiveness of our method is verified on several public datasets.
Sparse Pose Trajectory Completion
May 01, 2021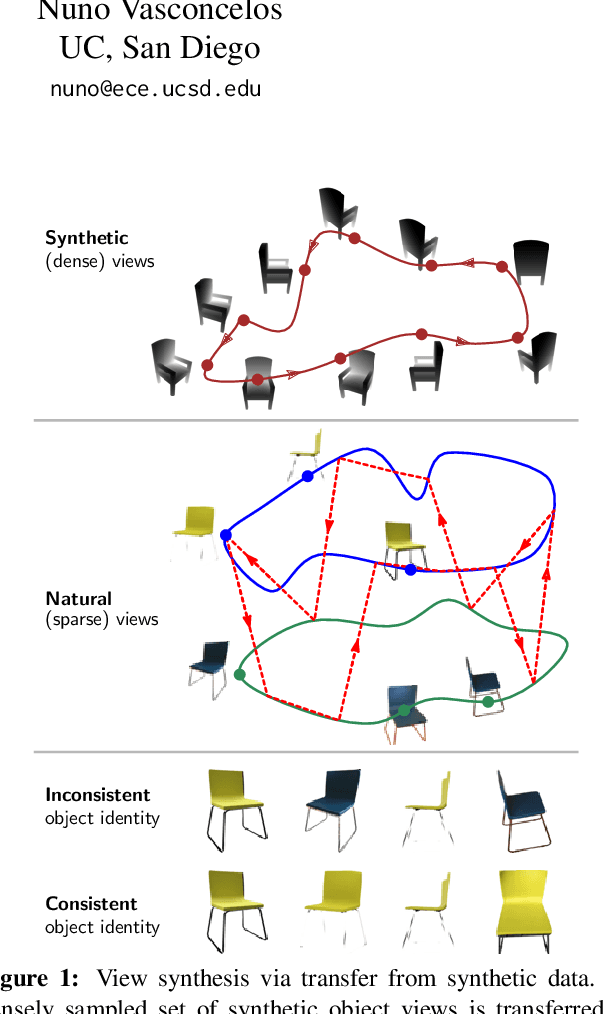
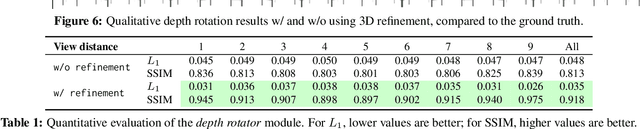
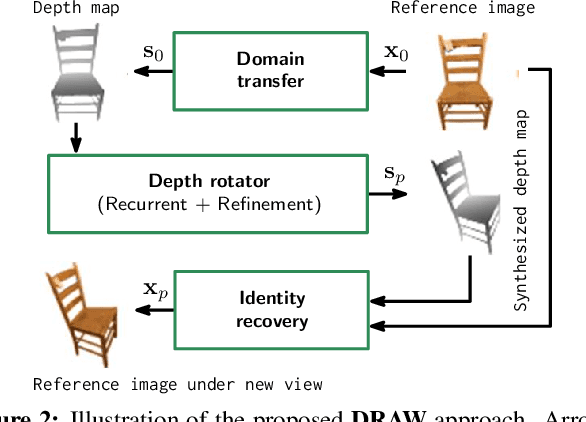
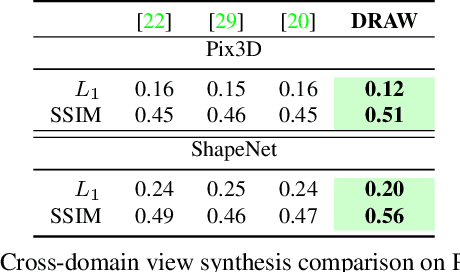
We propose a method to learn, even using a dataset where objects appear only in sparsely sampled views (e.g. Pix3D), the ability to synthesize a pose trajectory for an arbitrary reference image. This is achieved with a cross-modal pose trajectory transfer mechanism. First, a domain transfer function is trained to predict, from an RGB image of the object, its 2D depth map. Then, a set of image views is generated by learning to simulate object rotation in the depth space. Finally, the generated poses are mapped from this latent space into a set of corresponding RGB images using a learned identity preserving transform. This results in a dense pose trajectory of the object in image space. For each object type (e.g., a specific Ikea chair model), a 3D CAD model is used to render a full pose trajectory of 2D depth maps. In the absence of dense pose sampling in image space, these latent space trajectories provide cross-modal guidance for learning. The learned pose trajectories can be transferred to unseen examples, effectively synthesizing all object views in image space. Our method is evaluated on the Pix3D and ShapeNet datasets, in the setting of novel view synthesis under sparse pose supervision, demonstrating substantial improvements over recent art.
Stable Anderson Acceleration for Deep Learning
Oct 26, 2021
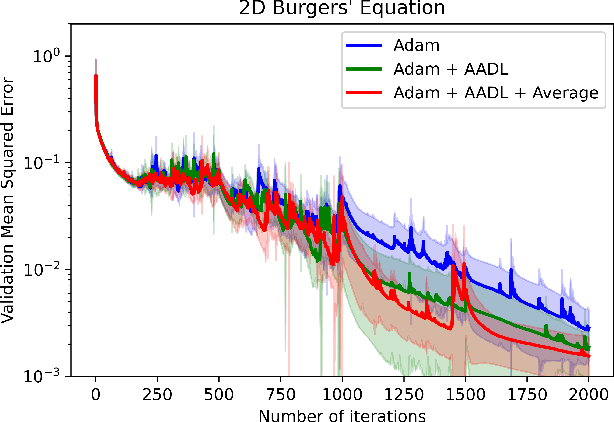
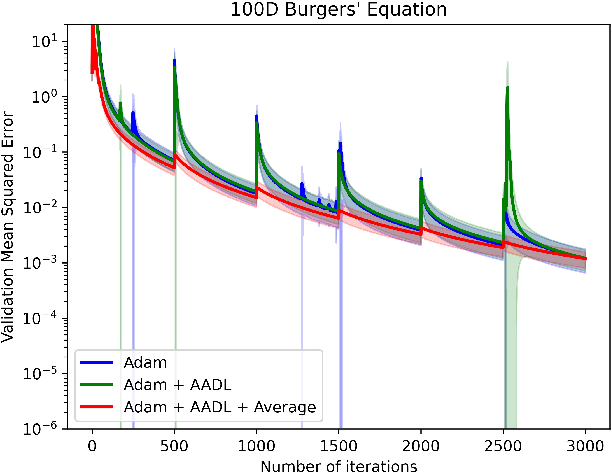
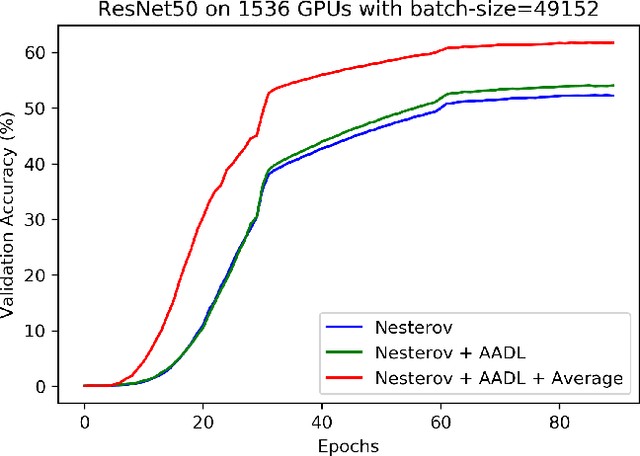
Anderson acceleration (AA) is an extrapolation technique designed to speed-up fixed-point iterations like those arising from the iterative training of DL models. Training DL models requires large datasets processed in randomly sampled batches that tend to introduce in the fixed-point iteration stochastic oscillations of amplitude roughly inversely proportional to the size of the batch. These oscillations reduce and occasionally eliminate the positive effect of AA. To restore AA's advantage, we combine it with an adaptive moving average procedure that smoothes the oscillations and results in a more regular sequence of gradient descent updates. By monitoring the relative standard deviation between consecutive iterations, we also introduce a criterion to automatically assess whether the moving average is needed. We applied the method to the following DL instantiations: (i) multi-layer perceptrons (MLPs) trained on the open-source graduate admissions dataset for regression, (ii) physics informed neural networks (PINNs) trained on source data to solve 2d and 100d Burgers' partial differential equations (PDEs), and (iii) ResNet50 trained on the open-source ImageNet1k dataset for image classification. Numerical results obtained using up to 1,536 NVIDIA V100 GPUs on the OLCF supercomputer Summit showed the stabilizing effect of the moving average on AA for all the problems above.
Mobile Manipulation Leveraging Multiple Views
Oct 02, 2021
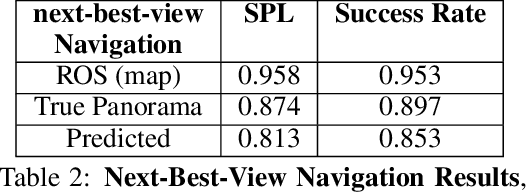

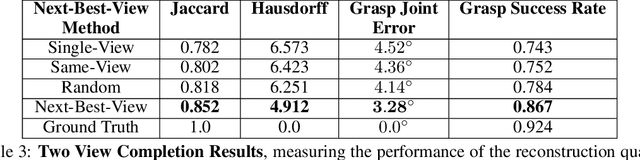
While both navigation and manipulation are challenging topics in isolation, many tasks require the ability to both navigate and manipulate in concert. To this end, we propose a mobile manipulation system that leverages novel navigation and shape completion methods to manipulate an object with a mobile robot. Our system utilizes uncertainty in the initial estimation of a manipulation target to calculate a predicted next-best-view. Without the need of localization, the robot then uses the predicted panoramic view at the next-best-view location to navigate to the desired location, capture a second view of the object, create a new model that predicts the shape of object more accurately than a single image alone, and uses this model for grasp planning. We show that the system is highly effective for mobile manipulation tasks through simulation experiments using real world data, as well as ablations on each component of our system.
MFIF-GAN: A New Generative Adversarial Network for Multi-Focus Image Fusion
Sep 21, 2020
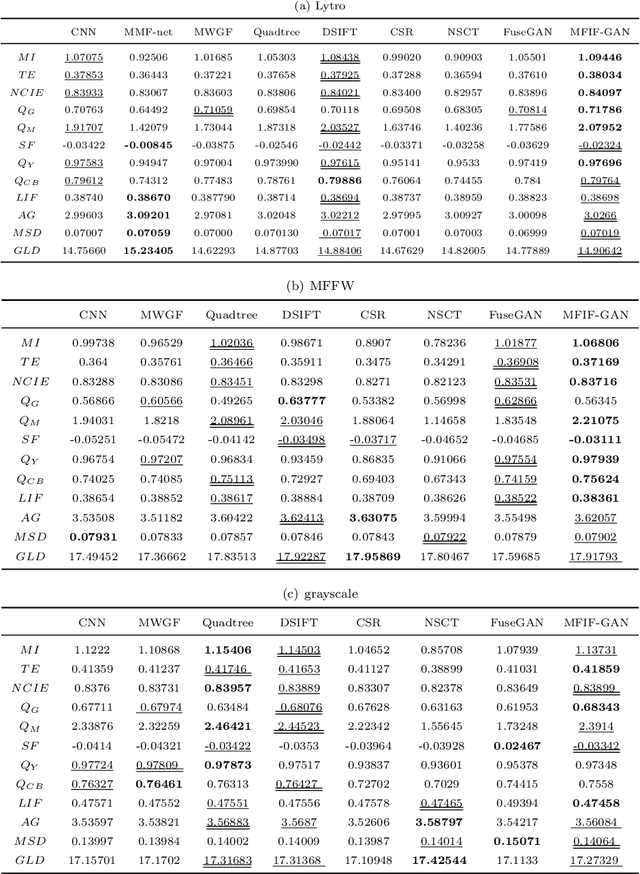

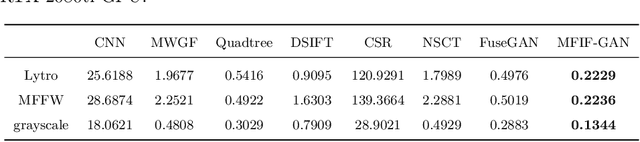
Multi-Focus Image Fusion (MFIF) is one of the promising techniques to obtain all-in-focus images to meet people's visual needs and it is a precondition of other computer vision tasks. One of the research trends of MFIF is to solve the defocus spread effect (DSE) around the focus/defocus boundary (FDB). In this paper, we present a novel generative adversarial network termed MFIF-GAN to translate multi-focus images into focus maps and to get the all-in-focus images further. The Squeeze and Excitation Residual Network (SE-ResNet) module as an attention mechanism is employed in the network. During the training, we propose reconstruction and gradient regularization loss functions to guarantee the accuracy of generated focus maps. In addition, by combining the prior knowledge of training conditon, this network is trained on a synthetic dataset with DSE by an {\alpha}-matte model. A series of experimental results demonstrate that the MFIF-GAN is superior to several representative state-of-the-art (SOTA) algorithms in visual perception, quantitative analysis as well as efficiency.
Multi-modal Visual Place Recognition in Dynamics-Invariant Perception Space
May 17, 2021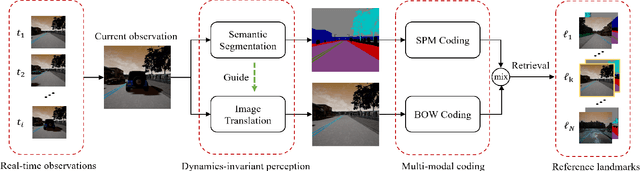
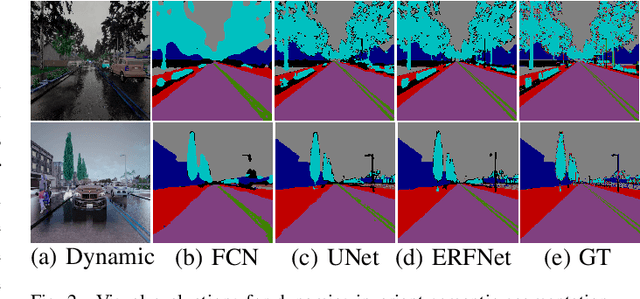

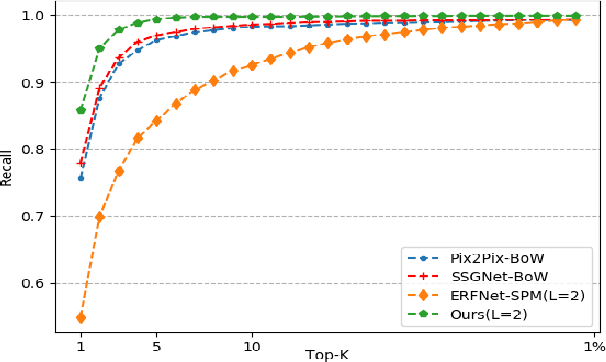
Visual place recognition is one of the essential and challenging problems in the fields of robotics. In this letter, we for the first time explore the use of multi-modal fusion of semantic and visual modalities in dynamics-invariant space to improve place recognition in dynamic environments. We achieve this by first designing a novel deep learning architecture to generate the static semantic segmentation and recover the static image directly from the corresponding dynamic image. We then innovatively leverage the spatial-pyramid-matching model to encode the static semantic segmentation into feature vectors. In parallel, the static image is encoded using the popular Bag-of-words model. On the basis of the above multi-modal features, we finally measure the similarity between the query image and target landmark by the joint similarity of their semantic and visual codes. Extensive experiments demonstrate the effectiveness and robustness of the proposed approach for place recognition in dynamic environments.
Scene-based Factored Attention for Image Captioning
Aug 07, 2019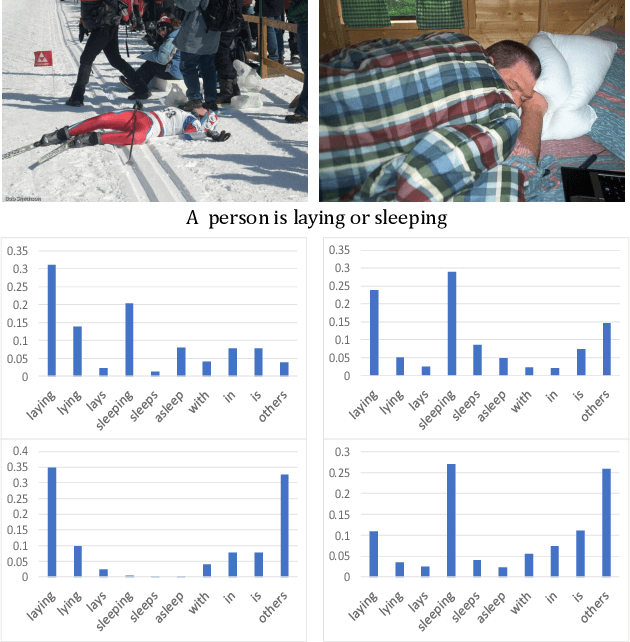
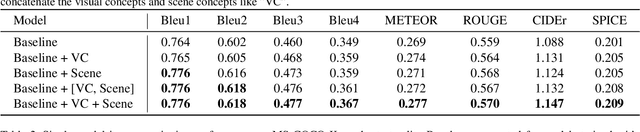
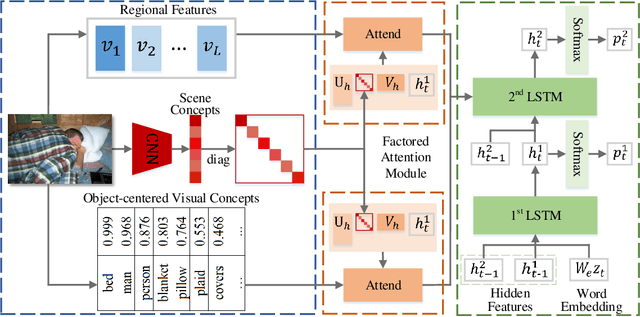
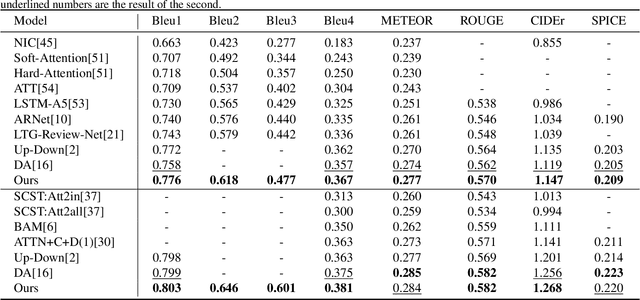
Image captioning has attracted ever-increasing research attention in the multimedia community. To this end, most cutting-edge works rely on an encoder-decoder framework with attention mechanisms, which have achieved remarkable progress. However, such a framework does not consider scene concepts to attend visual information, which leads to sentence bias in caption generation and defects the performance correspondingly. We argue that such scene concepts capture higher-level visual semantics and serve as an important cue in describing images. In this paper, we propose a novel scene-based factored attention module for image captioning. Specifically, the proposed module first embeds the scene concepts into factored weights explicitly and attends the visual information extracted from the input image. Then, an adaptive LSTM is used to generate captions for specific scene types. Experimental results on Microsoft COCO benchmark show that the proposed scene-based attention module improves model performance a lot, which outperforms the state-of-the-art approaches under various evaluation metrics.
A Personalized Diagnostic Generation Framework Based on Multi-source Heterogeneous Data
Oct 26, 2021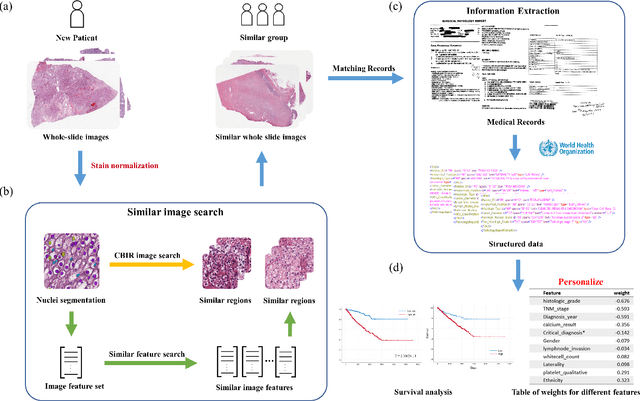
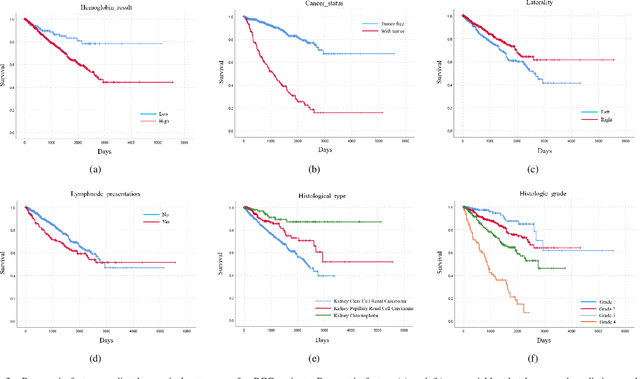
Personalized diagnoses have not been possible due to sear amount of data pathologists have to bear during the day-to-day routine. This lead to the current generalized standards that are being continuously updated as new findings are reported. It is noticeable that these effective standards are developed based on a multi-source heterogeneous data, including whole-slide images and pathology and clinical reports. In this study, we propose a framework that combines pathological images and medical reports to generate a personalized diagnosis result for individual patient. We use nuclei-level image feature similarity and content-based deep learning method to search for a personalized group of population with similar pathological characteristics, extract structured prognostic information from descriptive pathology reports of the similar patient population, and assign importance of different prognostic factors to generate a personalized pathological diagnosis result. We use multi-source heterogeneous data from TCGA (The Cancer Genome Atlas) database. The result demonstrate that our framework matches the performance of pathologists in the diagnosis of renal cell carcinoma. This framework is designed to be generic, thus could be applied for other types of cancer. The weights could provide insights to the known prognostic factors and further guide more precise clinical treatment protocols.
3DFaceFill: An Analysis-By-Synthesis Approach to Face Completion
Oct 20, 2021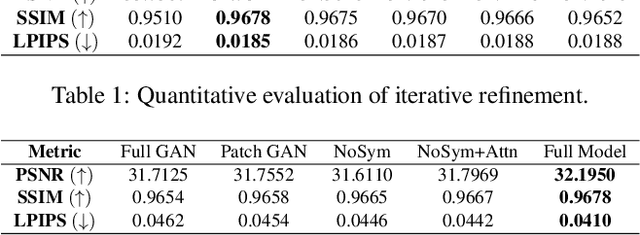
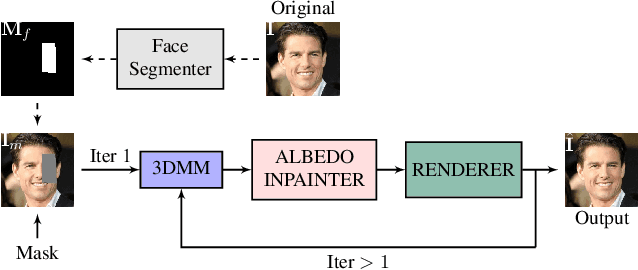

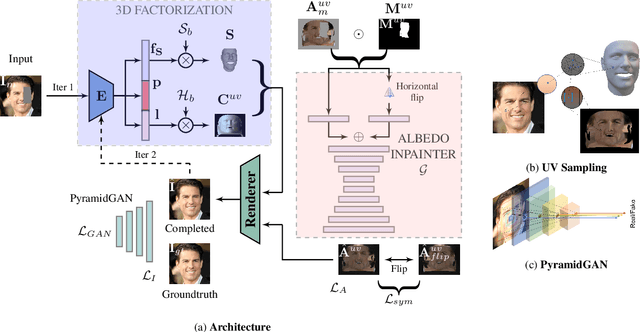
Existing face completion solutions are primarily driven by end-to-end models that directly generate 2D completions of 2D masked faces. By having to implicitly account for geometric and photometric variations in facial shape and appearance, such approaches result in unrealistic completions, especially under large variations in pose, shape, illumination and mask sizes. To alleviate these limitations, we introduce 3DFaceFill, an analysis-by-synthesis approach for face completion that explicitly considers the image formation process. It comprises three components, (1) an encoder that disentangles the face into its constituent 3D mesh, 3D pose, illumination and albedo factors, (2) an autoencoder that inpaints the UV representation of facial albedo, and (3) a renderer that resynthesizes the completed face. By operating on the UV representation, 3DFaceFill affords the power of correspondence and allows us to naturally enforce geometrical priors (e.g. facial symmetry) more effectively. Quantitatively, 3DFaceFill improves the state-of-the-art by up to 4dB higher PSNR and 25% better LPIPS for large masks. And, qualitatively, it leads to demonstrably more photorealistic face completions over a range of masks and occlusions while preserving consistency in global and component-wise shape, pose, illumination and eye-gaze.
Hyperspectral Neutron CT with Material Decomposition
Oct 06, 2021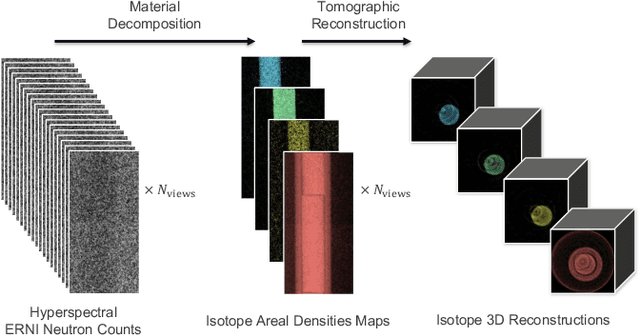

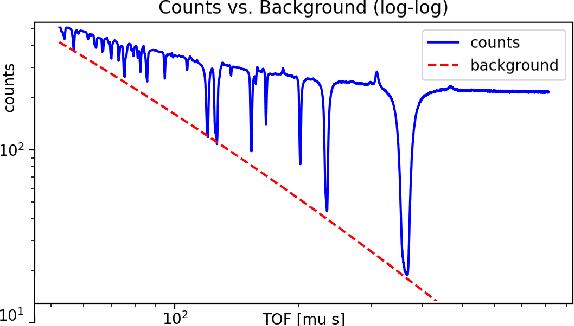
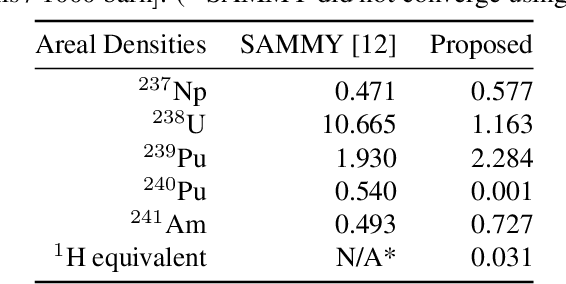
Energy resolved neutron imaging (ERNI) is an advanced neutron radiography technique capable of non-destructively extracting spatial isotopic information within a given material. Energy-dependent radiography image sequences can be created by utilizing neutron time-of-flight techniques. In combination with uniquely characteristic isotopic neutron cross-section spectra, isotopic areal densities can be determined on a per-pixel basis, thus resulting in a set of areal density images for each isotope present in the sample. By preforming ERNI measurements over several rotational views, an isotope decomposed 3D computed tomography is possible. We demonstrate a method involving a robust and automated background estimation based on a linear programming formulation. The extremely high noise due to low count measurements is overcome using a sparse coding approach. It allows for a significant computation time improvement, from weeks to a few hours compared to existing neutron evaluation tools, enabling at the present stage a semi-quantitative, user-friendly routine application.
* 5 pages, 4 figures