 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Precise Visual-Inertial Localization for UAV with the Aid of A 2D Georeferenced Map
Jul 13, 2021
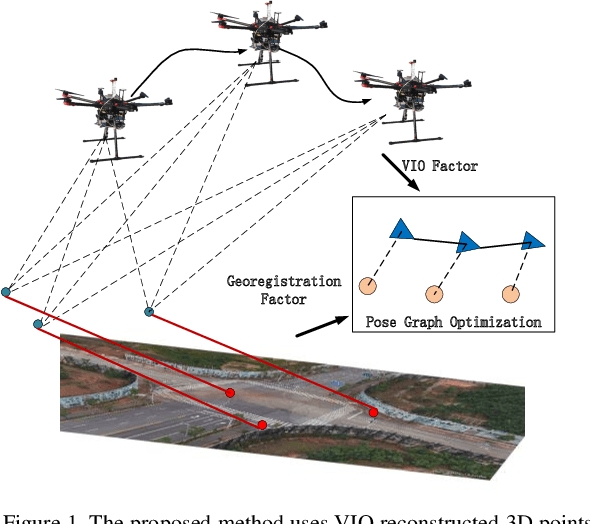
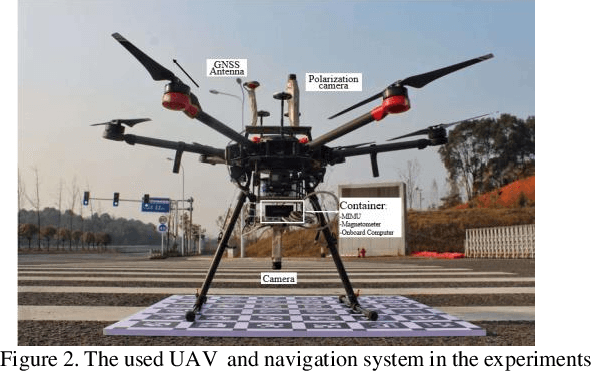
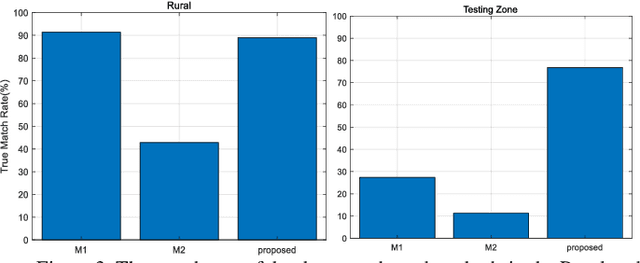
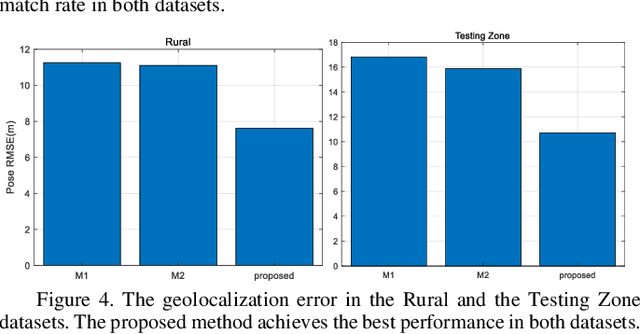
Precise geolocalization is crucial for unmanned aerial vehicles (UAVs). However, most current deployed UAVs rely on the global navigation satellite systems (GNSS) or high precision inertial navigation systems (INS) for geolocalization. In this paper, we propose to use a lightweight visual-inertial system with a 2D georeference map to obtain accurate and consecutive geodetic positions for UAVs. The proposed system firstly integrates a micro inertial measurement unit (MIMU) and a monocular camera as odometry to consecutively estimate the navigation states and reconstruct the 3D position of the observed visual features in the local world frame. To obtain the geolocation, the visual features tracked by the odometry are further registered to the 2D georeferenced map. While most conventional methods perform image-level aerial image registration, we propose to align the reconstructed points to the map points in the geodetic frame; this helps to filter out the large portion of outliers and decouples the negative effects from the horizontal angles. The registered points are then used to relocalize the vehicle in the geodetic frame. Finally, a pose graph is deployed to fuse the geolocation from the aerial image registration and the local navigation result from the visual-inertial odometry (VIO) to achieve consecutive and drift-free geolocalization performance. We have validated the proposed method by installing the sensors to a UAV body rigidly and have conducted two flights in different environments with unknown initials. The results show that the proposed method can achieve less than 4m position error in flight at 100m high and less than 9m position error in flight about 300m high.
Multi-StyleGAN: Towards Image-Based Simulation of Time-Lapse Live-Cell Microscopy
Jun 15, 2021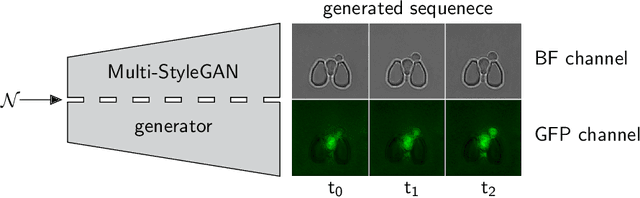

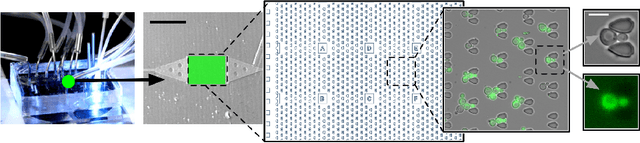
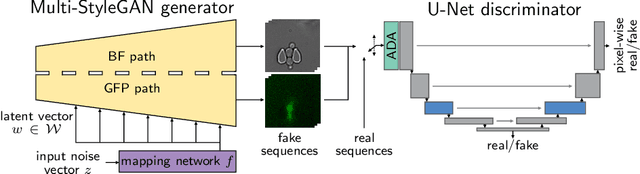
Time-lapse fluorescent microscopy (TLFM) combined with predictive mathematical modelling is a powerful tool to study the inherently dynamic processes of life on the single-cell level. Such experiments are costly, complex and labour intensive. A complimentary approach and a step towards completely in silico experiments, is to synthesise the imagery itself. Here, we propose Multi-StyleGAN as a descriptive approach to simulate time-lapse fluorescence microscopy imagery of living cells, based on a past experiment. This novel generative adversarial network synthesises a multi-domain sequence of consecutive timesteps. We showcase Multi-StyleGAN on imagery of multiple live yeast cells in microstructured environments and train on a dataset recorded in our laboratory. The simulation captures underlying biophysical factors and time dependencies, such as cell morphology, growth, physical interactions, as well as the intensity of a fluorescent reporter protein. An immediate application is to generate additional training and validation data for feature extraction algorithms or to aid and expedite development of advanced experimental techniques such as online monitoring or control of cells. Code and dataset is available at https://git.rwth-aachen.de/bcs/projects/tp/multi-stylegan.
Quantifying Predictive Uncertainty in Medical Image Analysis with Deep Kernel Learning
Jun 01, 2021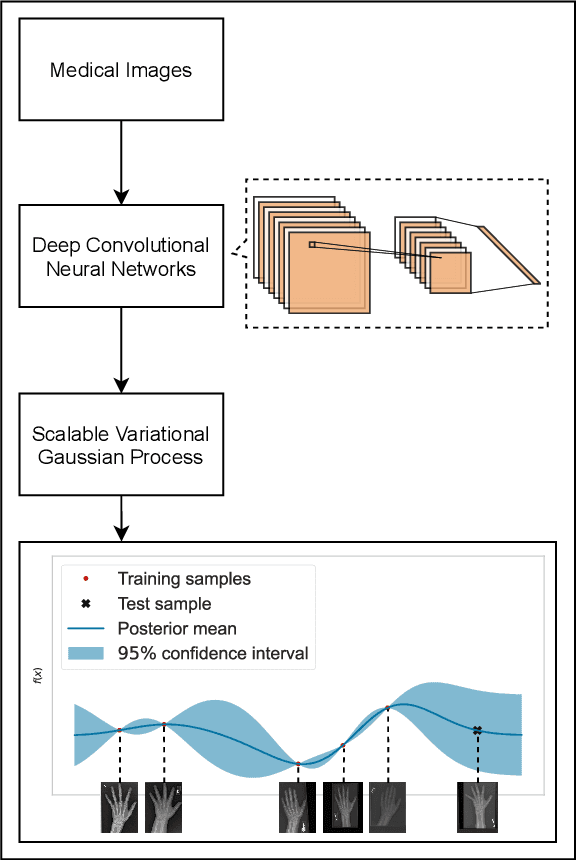
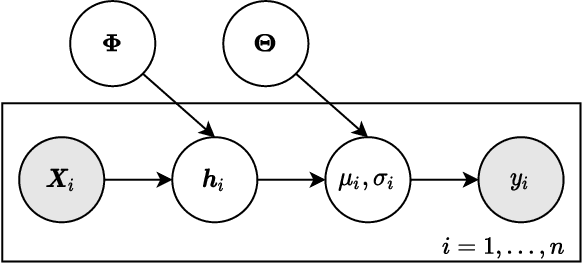
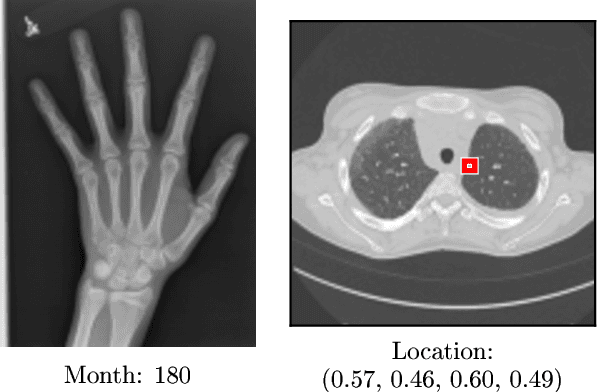
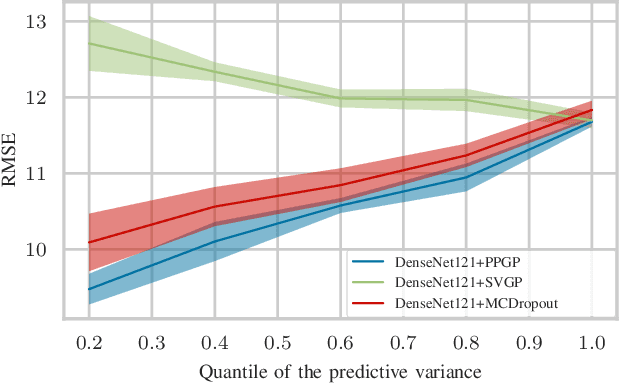
Deep neural networks are increasingly being used for the analysis of medical images. However, most works neglect the uncertainty in the model's prediction. We propose an uncertainty-aware deep kernel learning model which permits the estimation of the uncertainty in the prediction by a pipeline of a Convolutional Neural Network and a sparse Gaussian Process. Furthermore, we adapt different pre-training methods to investigate their impacts on the proposed model. We apply our approach to Bone Age Prediction and Lesion Localization. In most cases, the proposed model shows better performance compared to common architectures. More importantly, our model expresses systematically higher confidence in more accurate predictions and less confidence in less accurate ones. Our model can also be used to detect challenging and controversial test samples. Compared to related methods such as Monte-Carlo Dropout, our approach derives the uncertainty information in a purely analytical fashion and is thus computationally more efficient.
Text2Brain: Synthesis of Brain Activation Maps from Free-form Text Query
Sep 28, 2021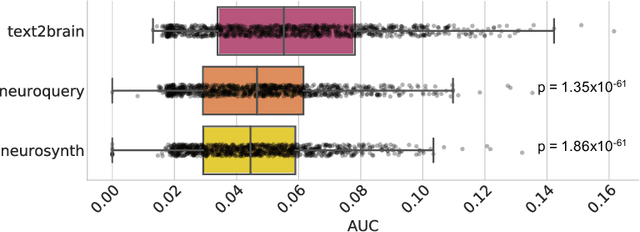
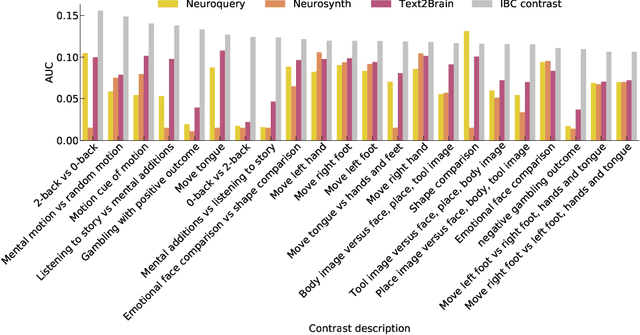
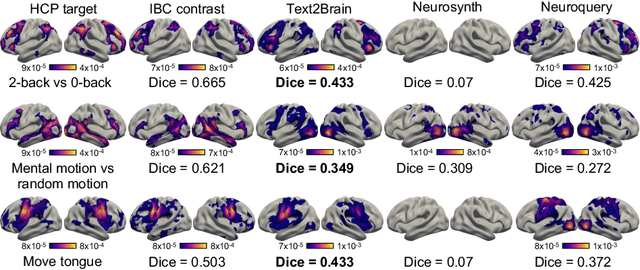
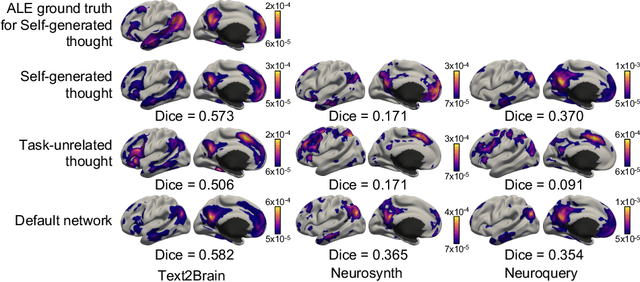
Most neuroimaging experiments are under-powered, limited by the number of subjects and cognitive processes that an individual study can investigate. Nonetheless, over decades of research, neuroscience has accumulated an extensive wealth of results. It remains a challenge to digest this growing knowledge base and obtain new insights since existing meta-analytic tools are limited to keyword queries. In this work, we propose Text2Brain, a neural network approach for coordinate-based meta-analysis of neuroimaging studies to synthesize brain activation maps from open-ended text queries. Combining a transformer-based text encoder and a 3D image generator, Text2Brain was trained on variable-length text snippets and their corresponding activation maps sampled from 13,000 published neuroimaging studies. We demonstrate that Text2Brain can synthesize anatomically-plausible neural activation patterns from free-form textual descriptions of cognitive concepts. Text2Brain is available at https://braininterpreter.com as a web-based tool for retrieving established priors and generating new hypotheses for neuroscience research.
End-to-end Alternating Optimization for Blind Super Resolution
May 14, 2021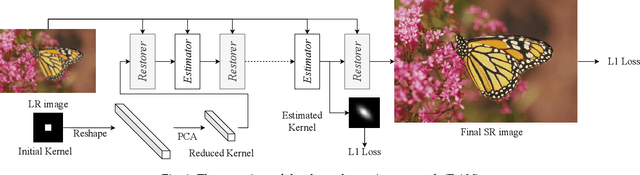
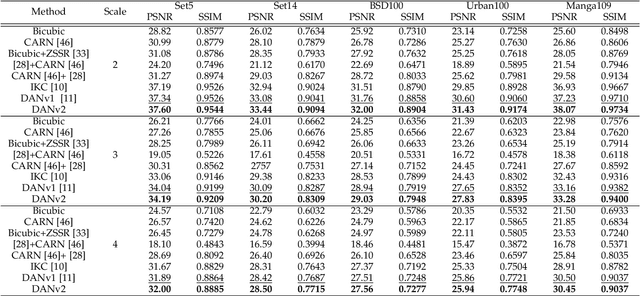
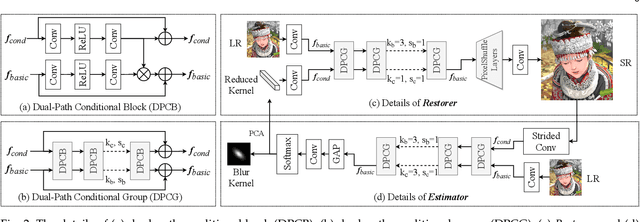

Previous methods decompose the blind super-resolution (SR) problem into two sequential steps: \textit{i}) estimating the blur kernel from given low-resolution (LR) image and \textit{ii}) restoring the SR image based on the estimated kernel. This two-step solution involves two independently trained models, which may not be well compatible with each other. A small estimation error of the first step could cause a severe performance drop of the second one. While on the other hand, the first step can only utilize limited information from the LR image, which makes it difficult to predict a highly accurate blur kernel. Towards these issues, instead of considering these two steps separately, we adopt an alternating optimization algorithm, which can estimate the blur kernel and restore the SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores the SR image based on the predicted kernel, and \textit{Estimator} estimates the blur kernel with the help of the restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, \textit{Estimator} utilizes information from both LR and SR images, which makes the estimation of the blur kernel easier. More importantly, \textit{Restorer} is trained with the kernel estimated by \textit{Estimator}, instead of the ground-truth kernel, thus \textit{Restorer} could be more tolerant to the estimation error of \textit{Estimator}. Extensive experiments on synthetic datasets and real-world images show that our model can largely outperform state-of-the-art methods and produce more visually favorable results at a much higher speed. The source code is available at \url{https://github.com/greatlog/DAN.git}.
A Column Streaming-Based Convolution Engine and Mapping Algorithm for CNN-based Edge AI accelerators
Sep 15, 2021
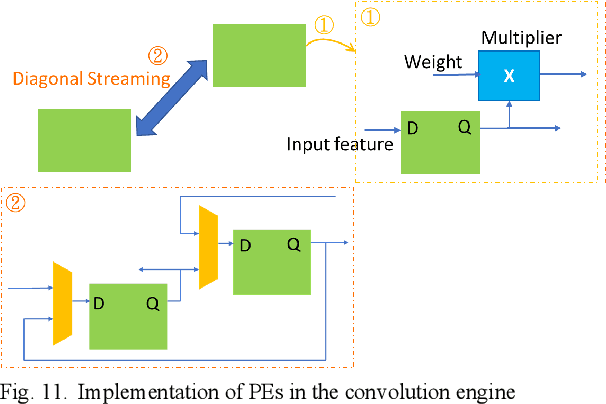
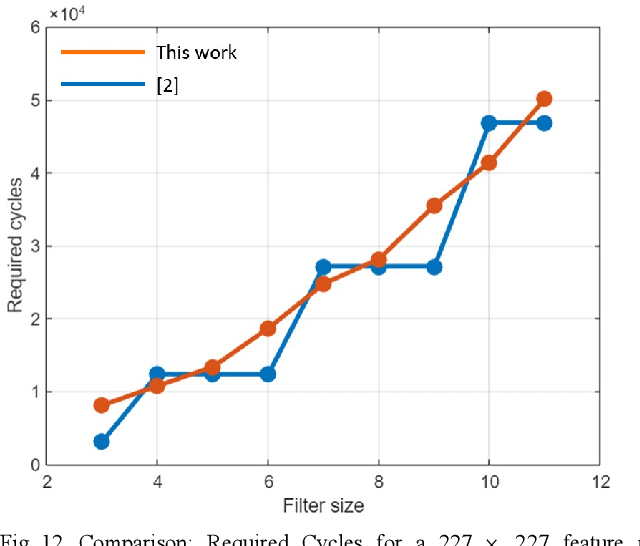
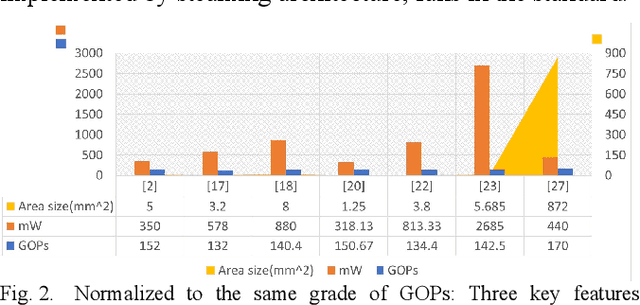
Edge AI accelerators have been emerging as a solution for near customers' applications in areas such as unmanned aerial vehicles (UAVs), image recognition sensors, wearable devices, robotics, and remote sensing satellites. These applications not only require meeting performance targets but also meeting strict area and power constraints due to their portable mobility feature and limited power sources. As a result, a column streaming-based convolution engine has been proposed in this paper that includes column sets of processing elements design for flexibility in terms of the applicability for different CNN algorithms in edge AI accelerators. Comparing to a commercialized CNN accelerator, the key results reveal that the column streaming-based convolution engine requires similar execution cycles for processing a 227 x 227 feature map with avoiding zero-padding penalties.
Optimal Latent Vector Alignment for Unsupervised Domain Adaptation in Medical Image Segmentation
Jun 15, 2021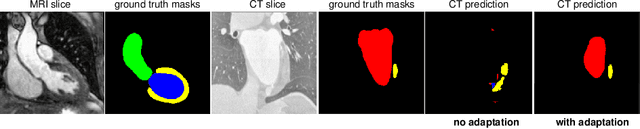
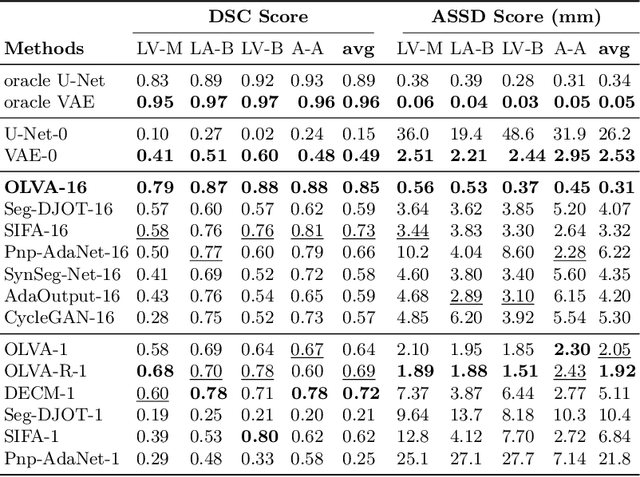
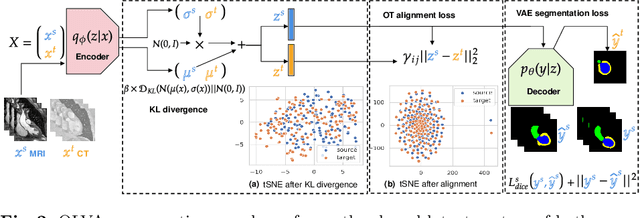
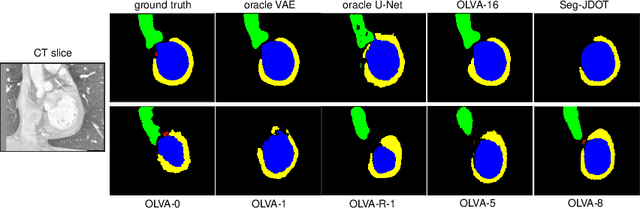
This paper addresses the domain shift problem for segmentation. As a solution, we propose OLVA, a novel and lightweight unsupervised domain adaptation method based on a Variational Auto-Encoder (VAE) and Optimal Transport (OT) theory. Thanks to the VAE, our model learns a shared cross-domain latent space that follows a normal distribution, which reduces the domain shift. To guarantee valid segmentations, our shared latent space is designed to model the shape rather than the intensity variations. We further rely on an OT loss to match and align the remaining discrepancy between the two domains in the latent space. We demonstrate OLVA's effectiveness for the segmentation of multiple cardiac structures on the public Multi-Modality Whole Heart Segmentation (MM-WHS) dataset, where the source domain consists of annotated 3D MR images and the unlabelled target domain of 3D CTs. Our results show remarkable improvements with an additional margin of 12.5\% dice score over concurrent generative training approaches.
Aesthetic Photo Collage with Deep Reinforcement Learning
Oct 19, 2021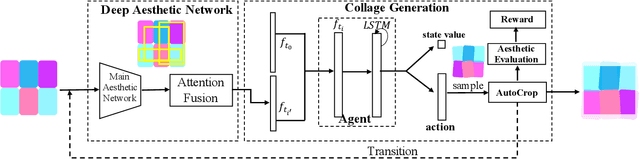



Photo collage aims to automatically arrange multiple photos on a given canvas with high aesthetic quality. Existing methods are based mainly on handcrafted feature optimization, which cannot adequately capture high-level human aesthetic senses. Deep learning provides a promising way, but owing to the complexity of collage and lack of training data, a solution has yet to be found. In this paper, we propose a novel pipeline for automatic generation of aspect ratio specified collage and the reinforcement learning technique is introduced in collage for the first time. Inspired by manual collages, we model the collage generation as sequential decision process to adjust spatial positions, orientation angles, placement order and the global layout. To instruct the agent to improve both the overall layout and local details, the reward function is specially designed for collage, considering subjective and objective factors. To overcome the lack of training data, we pretrain our deep aesthetic network on a large scale image aesthetic dataset (CPC) for general aesthetic feature extraction and propose an attention fusion module for structural collage feature representation. We test our model against competing methods on two movie datasets and our results outperform others in aesthetic quality evaluation. Further user study is also conducted to demonstrate the effectiveness.
Dynamic Inference with Neural Interpreters
Oct 12, 2021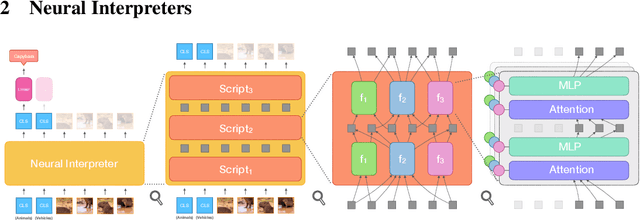
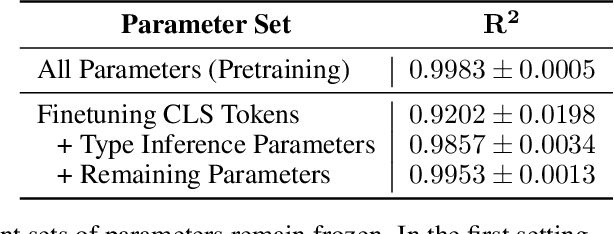
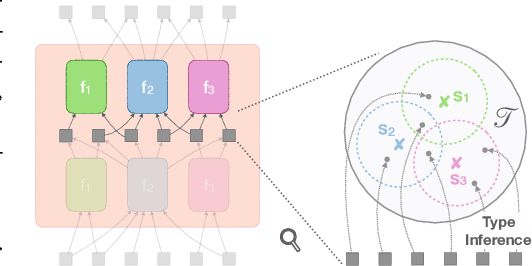
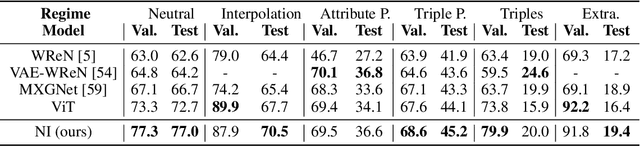
Modern neural network architectures can leverage large amounts of data to generalize well within the training distribution. However, they are less capable of systematic generalization to data drawn from unseen but related distributions, a feat that is hypothesized to require compositional reasoning and reuse of knowledge. In this work, we present Neural Interpreters, an architecture that factorizes inference in a self-attention network as a system of modules, which we call \emph{functions}. Inputs to the model are routed through a sequence of functions in a way that is end-to-end learned. The proposed architecture can flexibly compose computation along width and depth, and lends itself well to capacity extension after training. To demonstrate the versatility of Neural Interpreters, we evaluate it in two distinct settings: image classification and visual abstract reasoning on Raven Progressive Matrices. In the former, we show that Neural Interpreters perform on par with the vision transformer using fewer parameters, while being transferrable to a new task in a sample efficient manner. In the latter, we find that Neural Interpreters are competitive with respect to the state-of-the-art in terms of systematic generalization
Fast and Robust Cascade Model for Multiple Degradation Single Image Super-Resolution
Nov 16, 2020
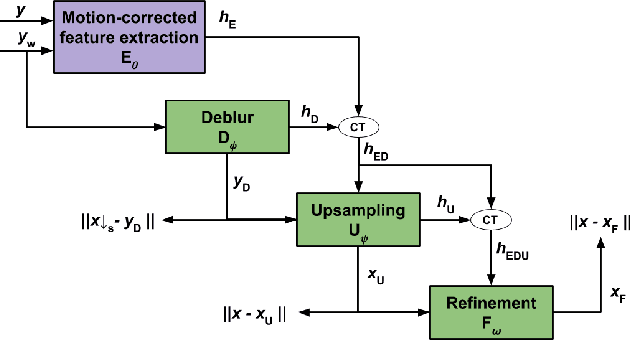

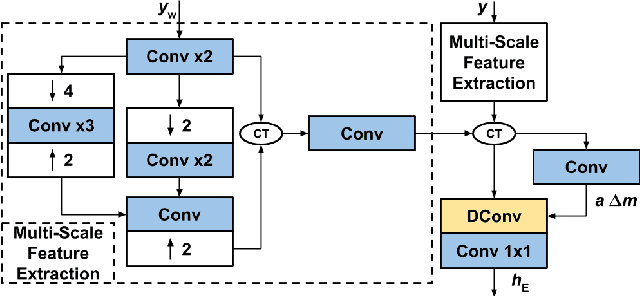
Single Image Super-Resolution (SISR) is one of the low-level computer vision problems that has received increased attention in the last few years. Current approaches are primarily based on harnessing the power of deep learning models and optimization techniques to reverse the degradation model. Owing to its hardness, isotropic blurring or Gaussians with small anisotropic deformations have been mainly considered. Here, we widen this scenario by including large non-Gaussian blurs that arise in real camera movements. Our approach leverages the degradation model and proposes a new formulation of the Convolutional Neural Network (CNN) cascade model, where each network sub-module is constrained to solve a specific degradation: deblurring or upsampling. A new densely connected CNN-architecture is proposed where the output of each sub-module is restricted using some external knowledge to focus it on its specific task. As far we know this use of domain-knowledge to module-level is a novelty in SISR. To fit the finest model, a final sub-module takes care of the residual errors propagated by the previous sub-modules. We check our model with three state of the art (SOTA) datasets in SISR and compare the results with the SOTA models. The results show that our model is the only one able to manage our wider set of deformations. Furthermore, our model overcomes all current SOTA methods for a standard set of deformations. In terms of computational load, our model also improves on the two closest competitors in terms of efficiency. Although the approach is non-blind and requires an estimation of the blur kernel, it shows robustness to blur kernel estimation errors, making it a good alternative to blind models.