 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Noise or Signal: The Role of Image Backgrounds in Object Recognition
Jun 17, 2020

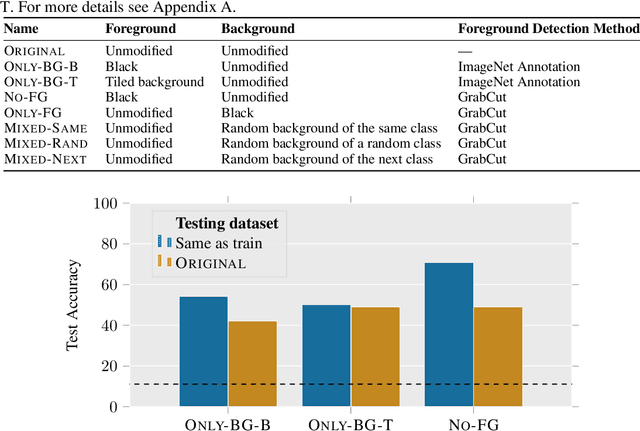
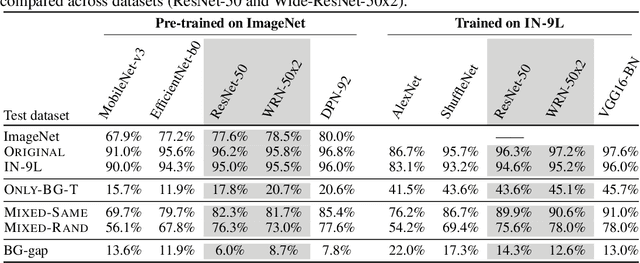

We assess the tendency of state-of-the-art object recognition models to depend on signals from image backgrounds. We create a toolkit for disentangling foreground and background signal on ImageNet images, and find that (a) models can achieve non-trivial accuracy by relying on the background alone, (b) models often misclassify images even in the presence of correctly classified foregrounds--up to 87.5% of the time with adversarially chosen backgrounds, and (c) more accurate models tend to depend on backgrounds less. Our analysis of backgrounds brings us closer to understanding which correlations machine learning models use, and how they determine models' out of distribution performance.
Disrupting DeepFakes: Adversarial Attacks Against Conditional Image Translation Networks and Facial Manipulation Systems
Mar 03, 2020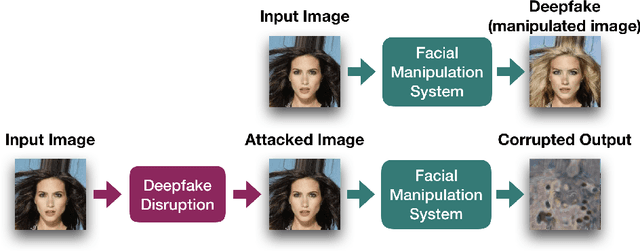
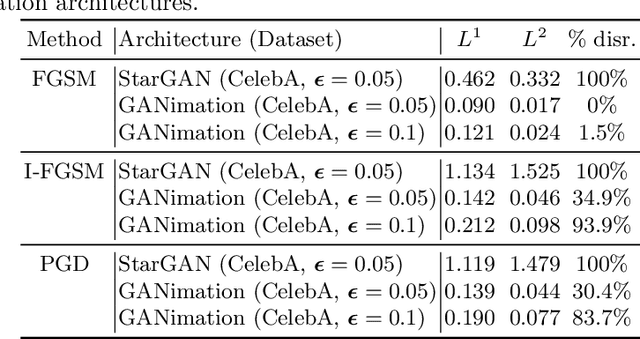

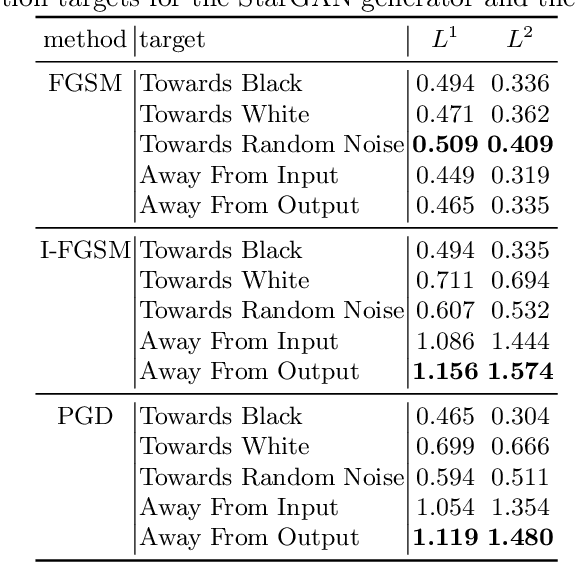
Face modification systems using deep learning have become increasingly powerful and accessible. Given images of a person's face, such systems can generate new images of that same person under different expressions and poses. Some systems can also modify targeted attributes such as hair color or age. This type of manipulated images and video have been coined DeepFakes. In order to prevent a malicious user from generating modified images of a person without their consent we tackle the new problem of generating adversarial attacks against image translation systems, which disrupt the resulting output image. We call this problem disrupting deepfakes. We adapt traditional adversarial attacks to our scenario. Most image translation architectures are generative models conditioned on an attribute (e.g. put a smile on this person's face). We present class transferable adversarial attacks that generalize to different classes, which means that the attacker does not need to have knowledge about the conditioning vector. In gray-box scenarios, blurring can mount a successful defense against disruption. We present a spread-spectrum adversarial attack, which evades blurring defenses.
FMFCC-A: A Challenging Mandarin Dataset for Synthetic Speech Detection
Oct 18, 2021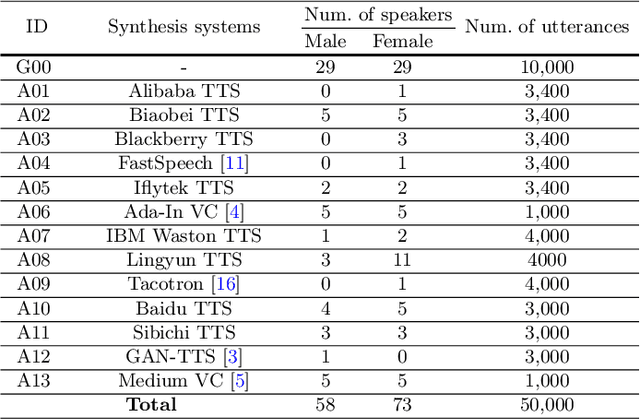
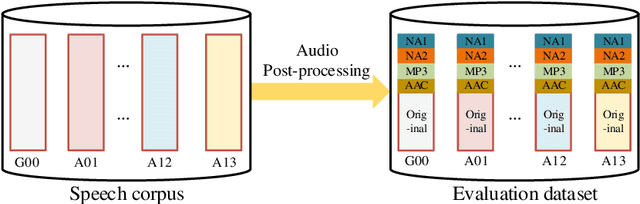

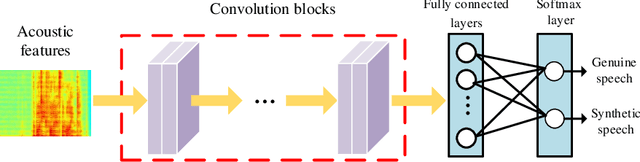
As increasing development of text-to-speech (TTS) and voice conversion (VC) technologies, the detection of synthetic speech has been suffered dramatically. In order to promote the development of synthetic speech detection model against Mandarin TTS and VC technologies, we have constructed a challenging Mandarin dataset and organized the accompanying audio track of the first fake media forensic challenge of China Society of Image and Graphics (FMFCC-A). The FMFCC-A dataset is by far the largest publicly-available Mandarin dataset for synthetic speech detection, which contains 40,000 synthesized Mandarin utterances that generated by 11 Mandarin TTS systems and two Mandarin VC systems, and 10,000 genuine Mandarin utterances collected from 58 speakers. The FMFCC-A dataset is divided into the training, development and evaluation sets, which are used for the research of detection of synthesized Mandarin speech under various previously unknown speech synthesis systems or audio post-processing operations. In addition to describing the construction of the FMFCC-A dataset, we provide a detailed analysis of two baseline methods and the top-performing submissions from the FMFCC-A, which illustrates the usefulness and challenge of FMFCC-A dataset. We hope that the FMFCC-A dataset can fill the gap of lack of Mandarin datasets for synthetic speech detection.
Clustering by Maximizing Mutual Information Across Views
Jul 24, 2021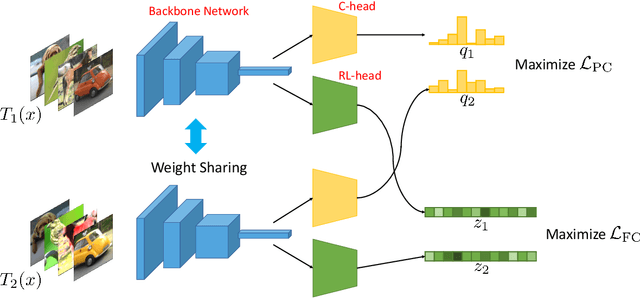
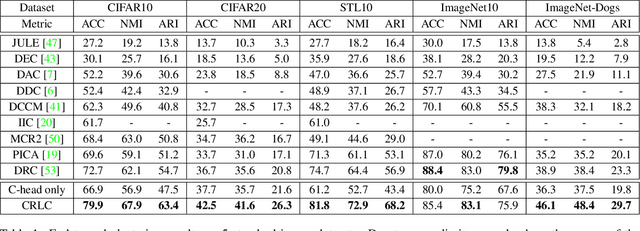


We propose a novel framework for image clustering that incorporates joint representation learning and clustering. Our method consists of two heads that share the same backbone network - a "representation learning" head and a "clustering" head. The "representation learning" head captures fine-grained patterns of objects at the instance level which serve as clues for the "clustering" head to extract coarse-grain information that separates objects into clusters. The whole model is trained in an end-to-end manner by minimizing the weighted sum of two sample-oriented contrastive losses applied to the outputs of the two heads. To ensure that the contrastive loss corresponding to the "clustering" head is optimal, we introduce a novel critic function called "log-of-dot-product". Extensive experimental results demonstrate that our method significantly outperforms state-of-the-art single-stage clustering methods across a variety of image datasets, improving over the best baseline by about 5-7% in accuracy on CIFAR10/20, STL10, and ImageNet-Dogs. Further, the "two-stage" variant of our method also achieves better results than baselines on three challenging ImageNet subsets.
HoloSketch: Wireless Semantic Segmentation by Reconfigurable Intelligent Surfaces
Aug 14, 2021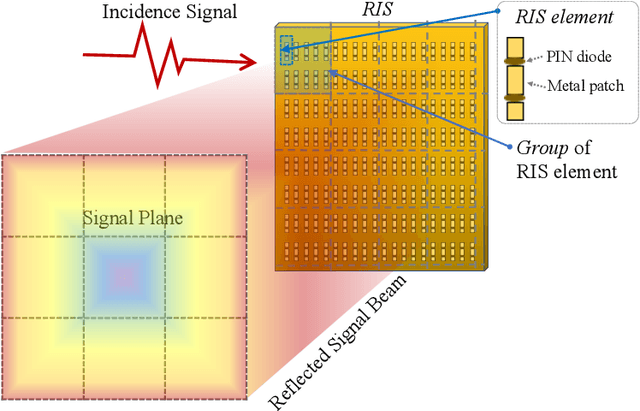
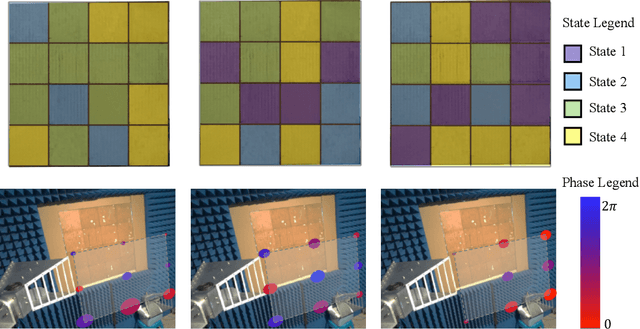

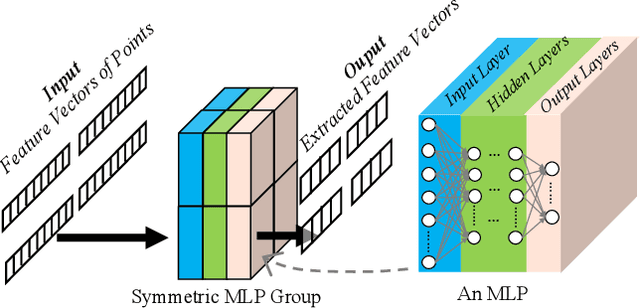
Semantic segmentation is a process of partitioning an image into multiple segments for recognizing humans and objects, which can be widely applied in scenarios such as healthcare and safety monitoring. To avoid privacy violation, using RF signals instead of an image for human and object recognition has gained increasing attention. However, human and object recognition by using RF signals is usually a passive signal collection and analysis process without changing the radio environment, and the recognition accuracy is restricted significantly by unwanted multi-path fading, and/or the limited number of independent channels between RF transceivers in uncontrollable radio environments. This paper introduces HoloSketch, a novel RF-sensing system that performs semantic recognition and segmentation for humans and objects by making the radio environment reconfigurable. A reconfigurable intelligent surface~(RIS) is incorporated into HoloSketch and diversifies the information carried by RF signals. Using compressive sensing techniques, HoloSketch reconstructs a point cloud consisting of the reflection coefficients of humans and objects at different spatial points, and recognizes the semantic meaning of the points by using symmetric multilayer perceptron groups. Our evaluation results show that HoloSketch is capable of generating favorable radio environments and extracting exact point clouds, and labeling the semantic meaning of the points with an average error rate of less than 1% in an indoor space.
Structured Bird's-Eye-View Traffic Scene Understanding from Onboard Images
Oct 05, 2021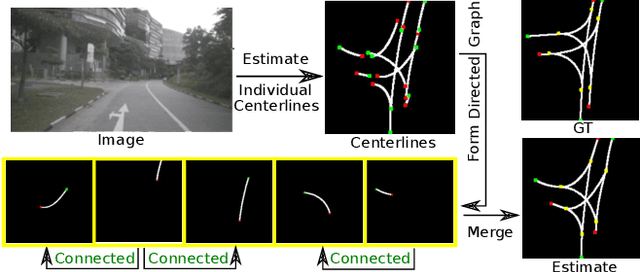
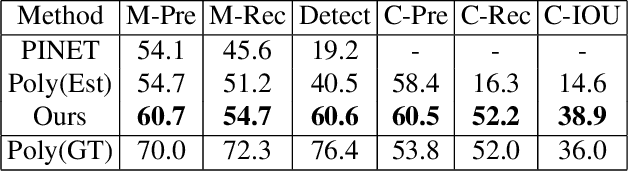
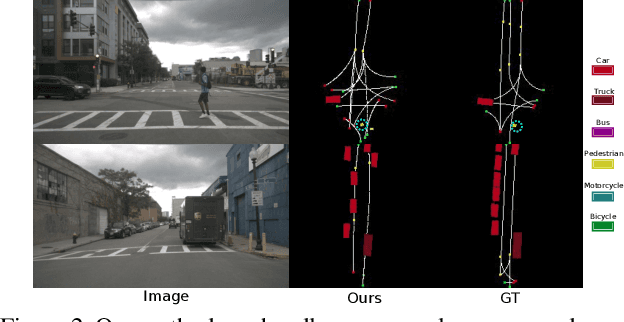
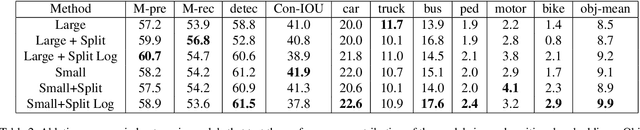
Autonomous navigation requires structured representation of the road network and instance-wise identification of the other traffic agents. Since the traffic scene is defined on the ground plane, this corresponds to scene understanding in the bird's-eye-view (BEV). However, the onboard cameras of autonomous cars are customarily mounted horizontally for a better view of the surrounding, making this task very challenging. In this work, we study the problem of extracting a directed graph representing the local road network in BEV coordinates, from a single onboard camera image. Moreover, we show that the method can be extended to detect dynamic objects on the BEV plane. The semantics, locations, and orientations of the detected objects together with the road graph facilitates a comprehensive understanding of the scene. Such understanding becomes fundamental for the downstream tasks, such as path planning and navigation. We validate our approach against powerful baselines and show that our network achieves superior performance. We also demonstrate the effects of various design choices through ablation studies. Code: https://github.com/ybarancan/STSU
Multi-level Encoder-Decoder Architectures for Image Restoration
May 06, 2019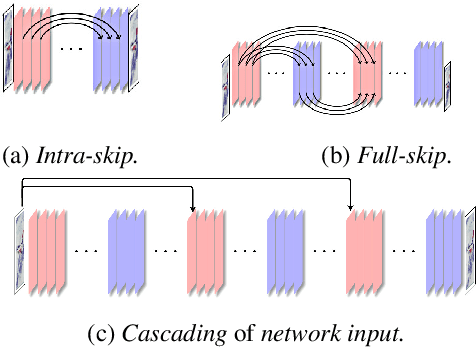
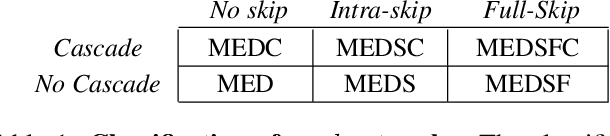
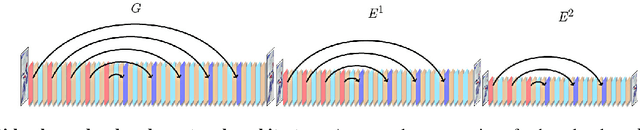
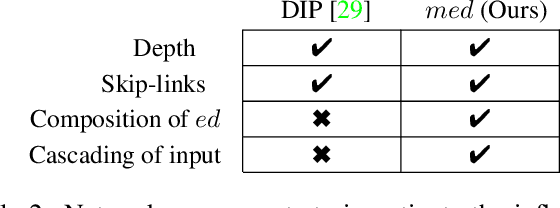
Many real-world solutions for image restoration are learning-free and based on handcrafted image priors such as self-similarity. Recently, deep-learning methods that use training data have achieved state-of-the-art results in various image restoration tasks (e.g., super-resolution and inpainting). Ulyanov et al. bridge the gap between these two families of methods (CVPR 18). They have shown that learning-free methods perform close to the state-of-the-art learning-based methods (approximately 1 PSNR). Their approach benefits from the encoder-decoder network. In this paper, we propose a framework based on the multi-level extensions of the encoder-decoder network, to investigate interesting aspects of the relationship between image restoration and network construction independent of learning. Our framework allows various network structures by modifying the following network components: skip links, cascading of the network input into intermediate layers, a composition of the encoder-decoder subnetworks, and network depth. These handcrafted network structures illustrate how the construction of untrained networks influence the following image restoration tasks: denoising, super-resolution, and inpainting. We also demonstrate image reconstruction using flash and no-flash image pairs. We provide performance comparisons with the state-of-the-art methods for all the restoration tasks above.
Warp-Refine Propagation: Semi-Supervised Auto-labeling via Cycle-consistency
Sep 28, 2021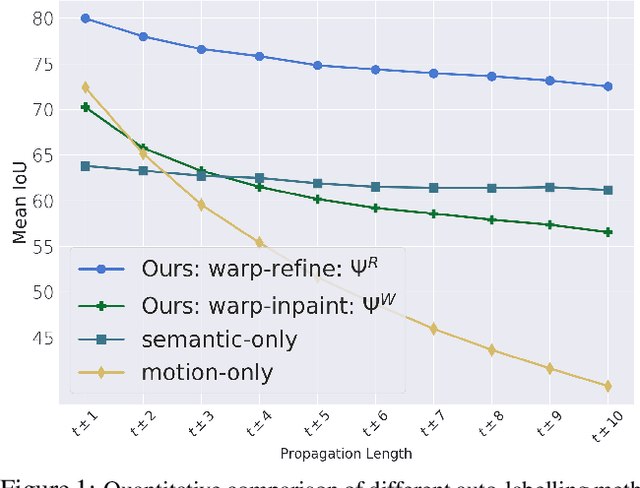
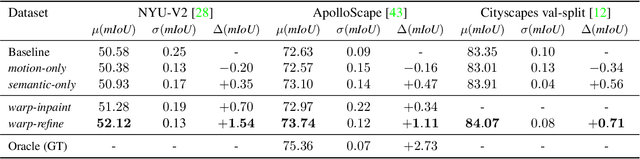
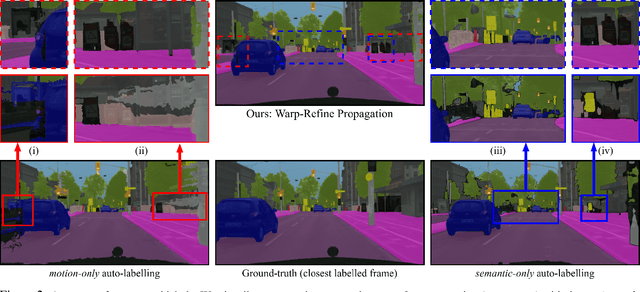

Deep learning models for semantic segmentation rely on expensive, large-scale, manually annotated datasets. Labelling is a tedious process that can take hours per image. Automatically annotating video sequences by propagating sparsely labeled frames through time is a more scalable alternative. In this work, we propose a novel label propagation method, termed Warp-Refine Propagation, that combines semantic cues with geometric cues to efficiently auto-label videos. Our method learns to refine geometrically-warped labels and infuse them with learned semantic priors in a semi-supervised setting by leveraging cycle consistency across time. We quantitatively show that our method improves label-propagation by a noteworthy margin of 13.1 mIoU on the ApolloScape dataset. Furthermore, by training with the auto-labelled frames, we achieve competitive results on three semantic-segmentation benchmarks, improving the state-of-the-art by a large margin of 1.8 and 3.61 mIoU on NYU-V2 and KITTI, while matching the current best results on Cityscapes.
BEV-Net: Assessing Social Distancing Compliance by Joint People Localization and Geometric Reasoning
Oct 12, 2021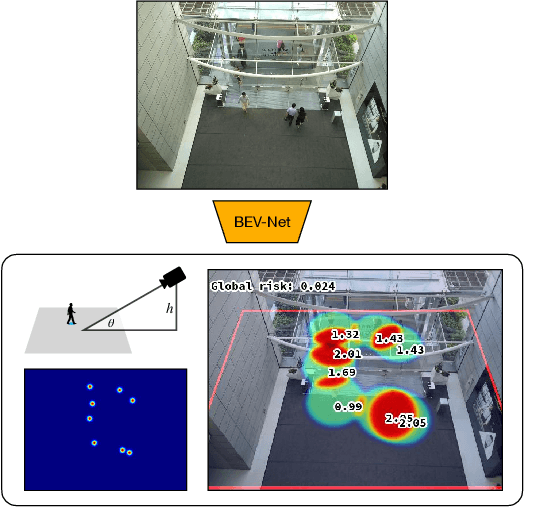
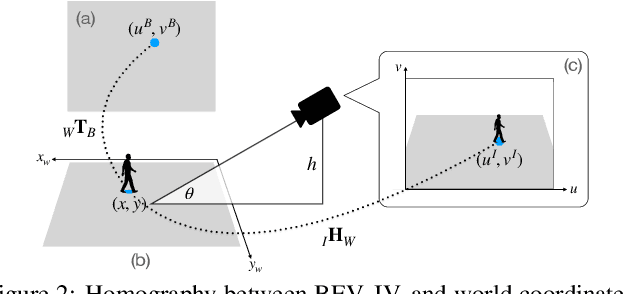

Social distancing, an essential public health measure to limit the spread of contagious diseases, has gained significant attention since the outbreak of the COVID-19 pandemic. In this work, the problem of visual social distancing compliance assessment in busy public areas, with wide field-of-view cameras, is considered. A dataset of crowd scenes with people annotations under a bird's eye view (BEV) and ground truth for metric distances is introduced, and several measures for the evaluation of social distance detection systems are proposed. A multi-branch network, BEV-Net, is proposed to localize individuals in world coordinates and identify high-risk regions where social distancing is violated. BEV-Net combines detection of head and feet locations, camera pose estimation, a differentiable homography module to map image into BEV coordinates, and geometric reasoning to produce a BEV map of the people locations in the scene. Experiments on complex crowded scenes demonstrate the power of the approach and show superior performance over baselines derived from methods in the literature. Applications of interest for public health decision makers are finally discussed. Datasets, code and pretrained models are publicly available at GitHub.
Joint coded aperture optimization and compressive hyperspectral image classification using 3D coded neural network
Oct 04, 2020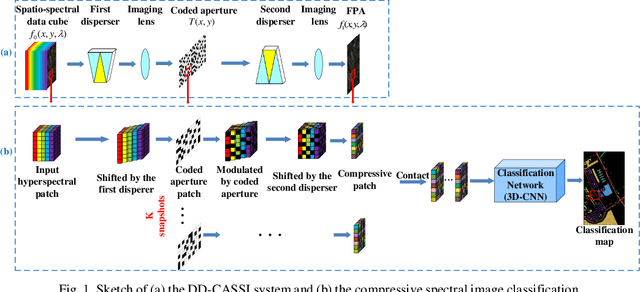

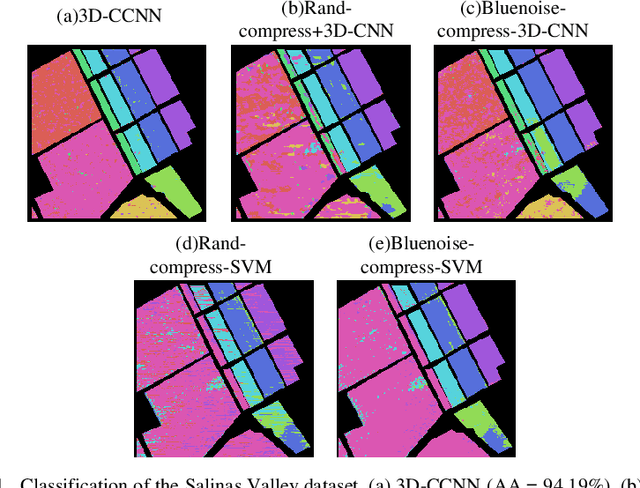

Hyperspectral image classification (HIC) is an active research topic in remote sensing. However, the huge volume of three-dimensional (3D) hyperspectral images poses big challenges in data acquisition, storage, transmission and processing. To overcome these limitations, this paper develops a novel deep learning HIC approach based on the compressive measurements of coded-aperture snapshot spectral imaging (CASSI) system, without reconstructing the complete hyperspectral data cube. A new kind of deep learning strategy, namely 3D coded convolutional neural network (3D-CCNN) is proposed to efficiently solve for the HIC problem, where the hardware-based coded aperture is regarded as a pixel-wise connected network layer. An end-to-end training method is developed to jointly optimize the network parameters and the coded aperture pattern with periodic structure. The accuracy of HIC approach is effectively improved by involving the degrees of optimization freedom from the coded aperture. The superiority of the proposed method is assessed on some public hyperspectral datasets over the state-of-the-art HIC methods.