 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Column Streaming-Based Convolution Engine and Mapping Algorithm for CNN-based Edge AI accelerators
Sep 15, 2021
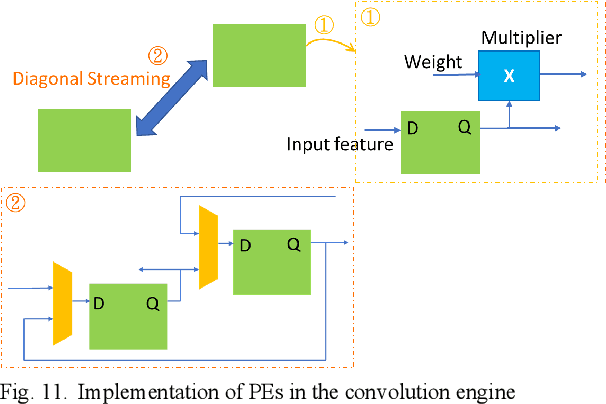
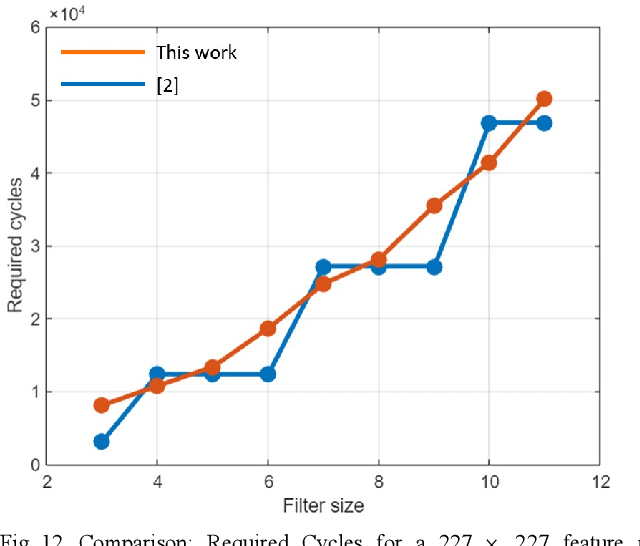
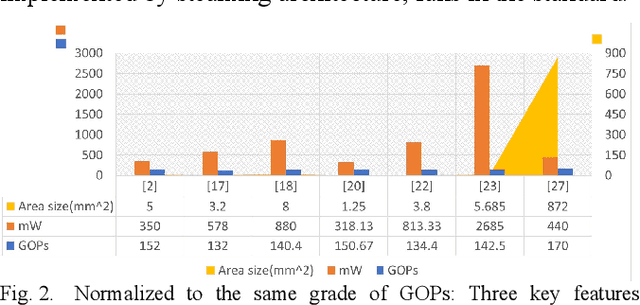
Edge AI accelerators have been emerging as a solution for near customers' applications in areas such as unmanned aerial vehicles (UAVs), image recognition sensors, wearable devices, robotics, and remote sensing satellites. These applications not only require meeting performance targets but also meeting strict area and power constraints due to their portable mobility feature and limited power sources. As a result, a column streaming-based convolution engine has been proposed in this paper that includes column sets of processing elements design for flexibility in terms of the applicability for different CNN algorithms in edge AI accelerators. Comparing to a commercialized CNN accelerator, the key results reveal that the column streaming-based convolution engine requires similar execution cycles for processing a 227 x 227 feature map with avoiding zero-padding penalties.
Impact of loss functions on the performance of a deep neural network designed to restore low-dose digital mammography
Nov 12, 2021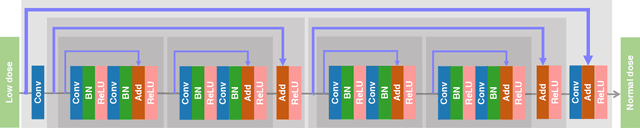
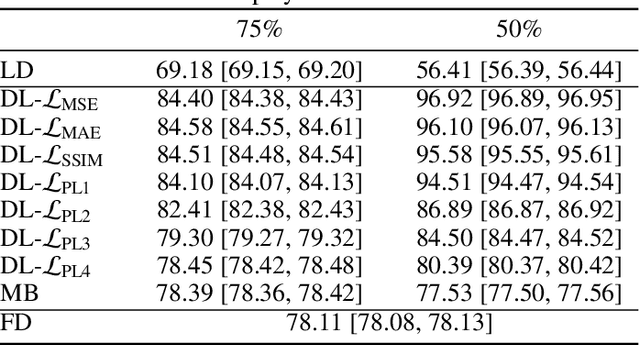
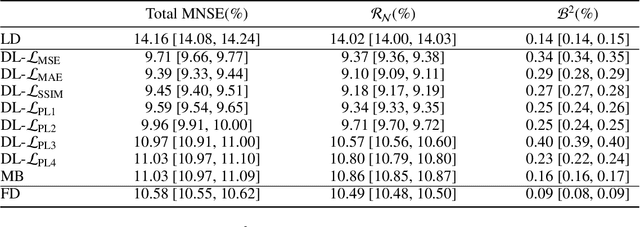
Digital mammography is still the most common imaging tool for breast cancer screening. Although the benefits of using digital mammography for cancer screening outweigh the risks associated with the x-ray exposure, the radiation dose must be kept as low as possible while maintaining the diagnostic utility of the generated images, thus minimizing patient risks. Many studies investigated the feasibility of dose reduction by restoring low-dose images using deep neural networks. In these cases, choosing the appropriate training database and loss function is crucial and impacts the quality of the results. In this work, a modification of the ResNet architecture, with hierarchical skip connections, is proposed to restore low-dose digital mammography. We compared the restored images to the standard full-dose images. Moreover, we evaluated the performance of several loss functions for this task. For training purposes, we extracted 256,000 image patches from a dataset of 400 images of retrospective clinical mammography exams, where different dose levels were simulated to generate low and standard-dose pairs. To validate the network in a real scenario, a physical anthropomorphic breast phantom was used to acquire real low-dose and standard full-dose images in a commercially avaliable mammography system, which were then processed through our trained model. An analytical restoration model for low-dose digital mammography, previously presented, was used as a benchmark in this work. Objective assessment was performed through the signal-to-noise ratio (SNR) and mean normalized squared error (MNSE), decomposed into residual noise and bias. Results showed that the perceptual loss function (PL4) is able to achieve virtually the same noise levels of a full-dose acquisition, while resulting in smaller signal bias compared to other loss functions.
Optimal Latent Vector Alignment for Unsupervised Domain Adaptation in Medical Image Segmentation
Jun 15, 2021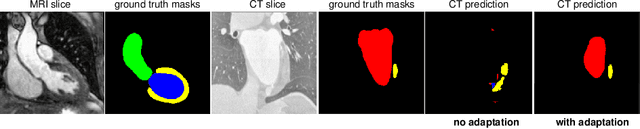
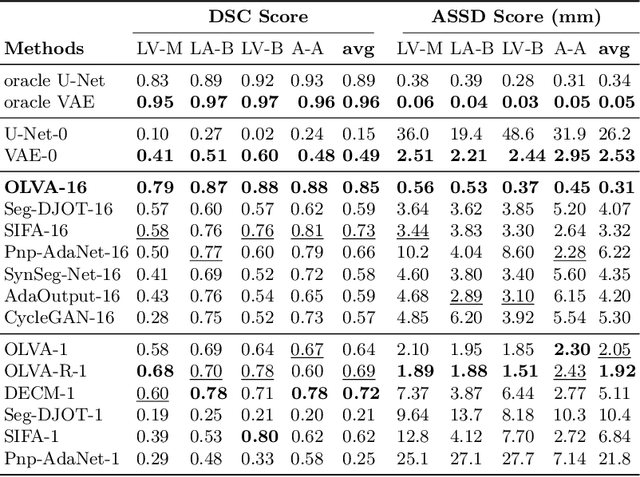
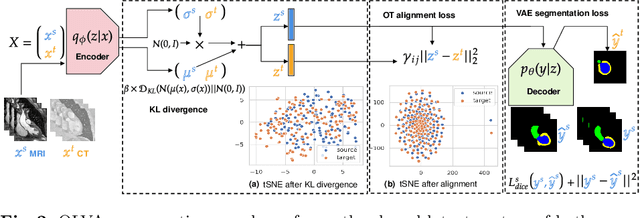
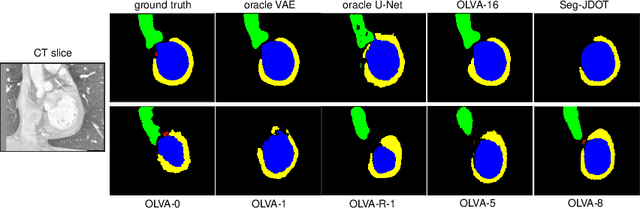
This paper addresses the domain shift problem for segmentation. As a solution, we propose OLVA, a novel and lightweight unsupervised domain adaptation method based on a Variational Auto-Encoder (VAE) and Optimal Transport (OT) theory. Thanks to the VAE, our model learns a shared cross-domain latent space that follows a normal distribution, which reduces the domain shift. To guarantee valid segmentations, our shared latent space is designed to model the shape rather than the intensity variations. We further rely on an OT loss to match and align the remaining discrepancy between the two domains in the latent space. We demonstrate OLVA's effectiveness for the segmentation of multiple cardiac structures on the public Multi-Modality Whole Heart Segmentation (MM-WHS) dataset, where the source domain consists of annotated 3D MR images and the unlabelled target domain of 3D CTs. Our results show remarkable improvements with an additional margin of 12.5\% dice score over concurrent generative training approaches.
LIFE: Lighting Invariant Flow Estimation
Apr 07, 2021

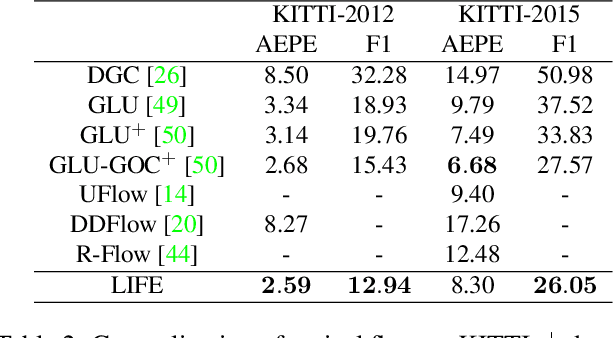
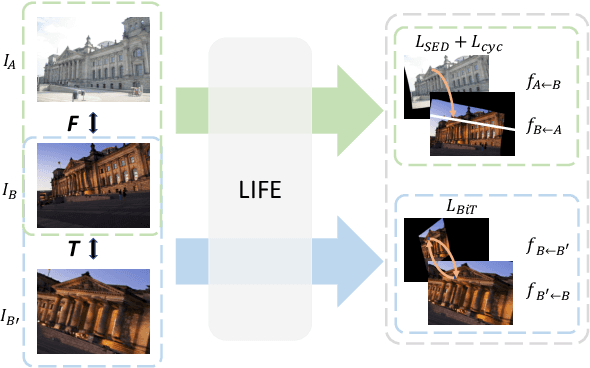
We tackle the problem of estimating flow between two images with large lighting variations. Recent learning-based flow estimation frameworks have shown remarkable performance on image pairs with small displacement and constant illuminations, but cannot work well on cases with large viewpoint change and lighting variations because of the lack of pixel-wise flow annotations for such cases. We observe that via the Structure-from-Motion (SfM) techniques, one can easily estimate relative camera poses between image pairs with large viewpoint change and lighting variations. We propose a novel weakly supervised framework LIFE to train a neural network for estimating accurate lighting-invariant flows between image pairs. Sparse correspondences are conventionally established via feature matching with descriptors encoding local image contents. However, local image contents are inevitably ambiguous and error-prone during the cross-image feature matching process, which hinders downstream tasks. We propose to guide feature matching with the flows predicted by LIFE, which addresses the ambiguous matching by utilizing abundant context information in the image pairs. We show that LIFE outperforms previous flow learning frameworks by large margins in challenging scenarios, consistently improves feature matching, and benefits downstream tasks.
Annotation-Efficient Learning for Medical Image Segmentation based on Noisy Pseudo Labels and Adversarial Learning
Dec 29, 2020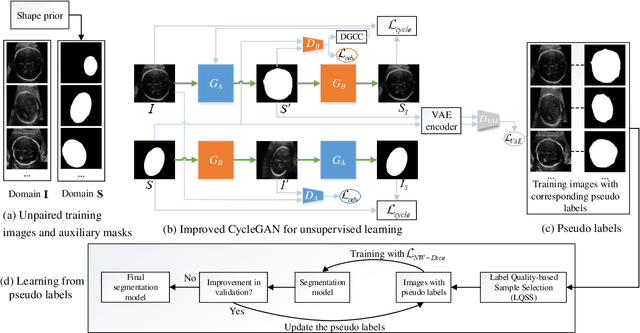
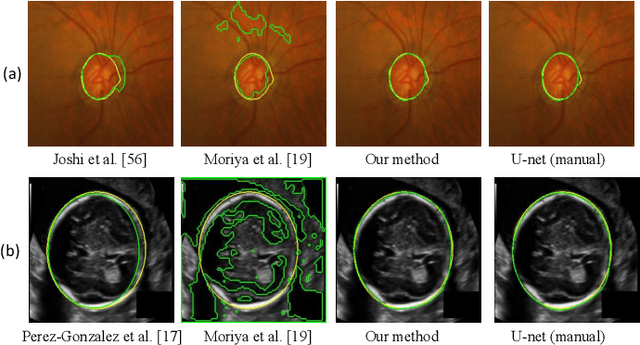
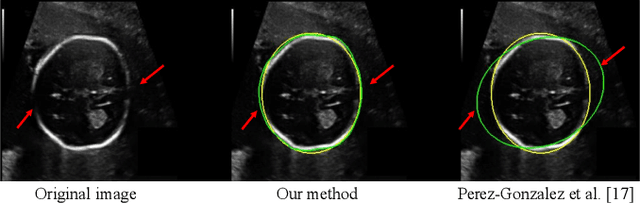
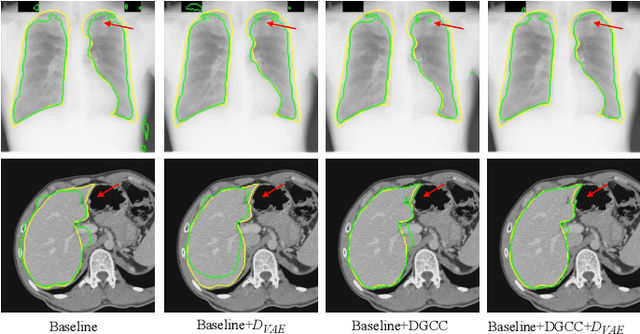
Despite that deep learning has achieved state-of-the-art performance for medical image segmentation, its success relies on a large set of manually annotated images for training that are expensive to acquire. In this paper, we propose an annotation-efficient learning framework for segmentation tasks that avoids annotations of training images, where we use an improved Cycle-Consistent Generative Adversarial Network (GAN) to learn from a set of unpaired medical images and auxiliary masks obtained either from a shape model or public datasets. We first use the GAN to generate pseudo labels for our training images under the implicit high-level shape constraint represented by a Variational Auto-encoder (VAE)-based discriminator with the help of the auxiliary masks, and build a Discriminator-guided Generator Channel Calibration (DGCC) module which employs our discriminator's feedback to calibrate the generator for better pseudo labels. To learn from the pseudo labels that are noisy, we further introduce a noise-robust iterative learning method using noise-weighted Dice loss. We validated our framework with two situations: objects with a simple shape model like optic disc in fundus images and fetal head in ultrasound images, and complex structures like lung in X-Ray images and liver in CT images. Experimental results demonstrated that 1) Our VAE-based discriminator and DGCC module help to obtain high-quality pseudo labels. 2) Our proposed noise-robust learning method can effectively overcome the effect of noisy pseudo labels. 3) The segmentation performance of our method without using annotations of training images is close or even comparable to that of learning from human annotations.
Quantifying Predictive Uncertainty in Medical Image Analysis with Deep Kernel Learning
Jun 01, 2021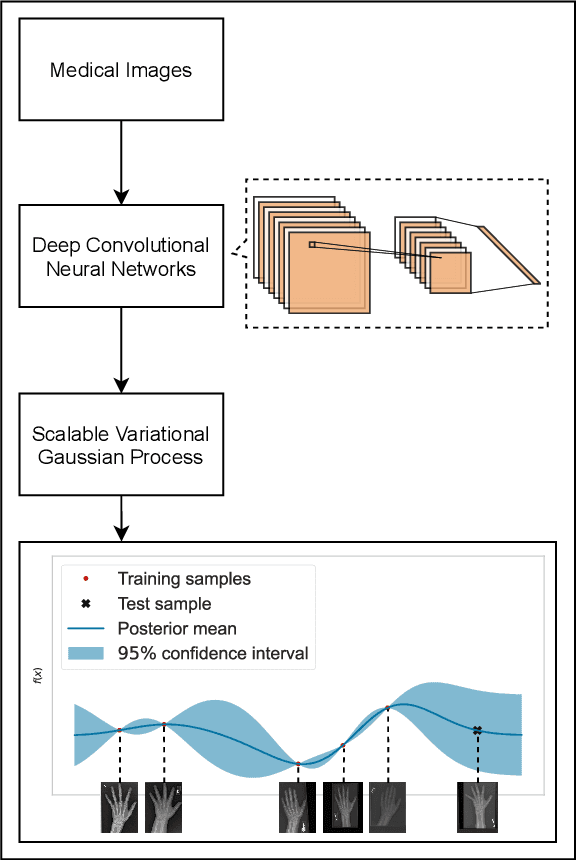
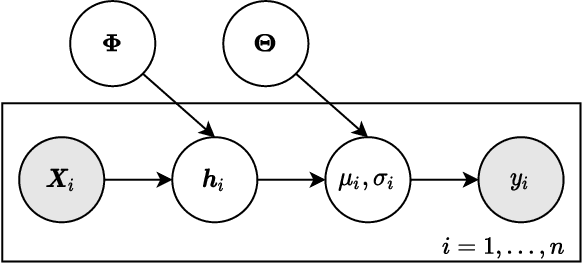
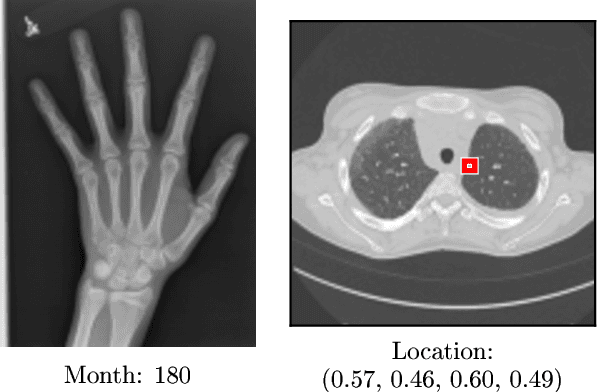
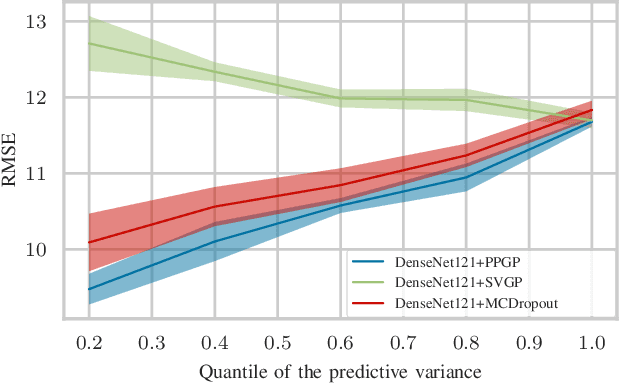
Deep neural networks are increasingly being used for the analysis of medical images. However, most works neglect the uncertainty in the model's prediction. We propose an uncertainty-aware deep kernel learning model which permits the estimation of the uncertainty in the prediction by a pipeline of a Convolutional Neural Network and a sparse Gaussian Process. Furthermore, we adapt different pre-training methods to investigate their impacts on the proposed model. We apply our approach to Bone Age Prediction and Lesion Localization. In most cases, the proposed model shows better performance compared to common architectures. More importantly, our model expresses systematically higher confidence in more accurate predictions and less confidence in less accurate ones. Our model can also be used to detect challenging and controversial test samples. Compared to related methods such as Monte-Carlo Dropout, our approach derives the uncertainty information in a purely analytical fashion and is thus computationally more efficient.
FMFCC-A: A Challenging Mandarin Dataset for Synthetic Speech Detection
Oct 18, 2021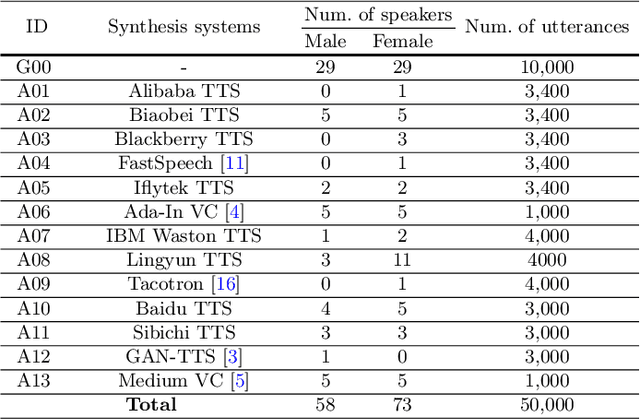
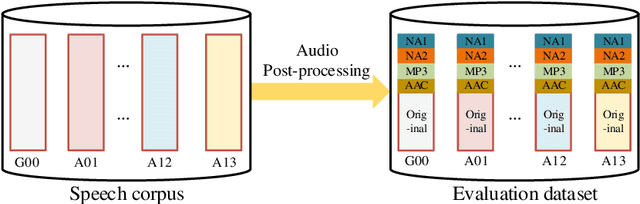

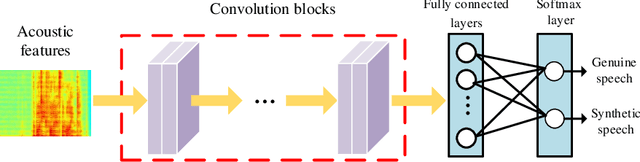
As increasing development of text-to-speech (TTS) and voice conversion (VC) technologies, the detection of synthetic speech has been suffered dramatically. In order to promote the development of synthetic speech detection model against Mandarin TTS and VC technologies, we have constructed a challenging Mandarin dataset and organized the accompanying audio track of the first fake media forensic challenge of China Society of Image and Graphics (FMFCC-A). The FMFCC-A dataset is by far the largest publicly-available Mandarin dataset for synthetic speech detection, which contains 40,000 synthesized Mandarin utterances that generated by 11 Mandarin TTS systems and two Mandarin VC systems, and 10,000 genuine Mandarin utterances collected from 58 speakers. The FMFCC-A dataset is divided into the training, development and evaluation sets, which are used for the research of detection of synthesized Mandarin speech under various previously unknown speech synthesis systems or audio post-processing operations. In addition to describing the construction of the FMFCC-A dataset, we provide a detailed analysis of two baseline methods and the top-performing submissions from the FMFCC-A, which illustrates the usefulness and challenge of FMFCC-A dataset. We hope that the FMFCC-A dataset can fill the gap of lack of Mandarin datasets for synthetic speech detection.
Deep Spherical Quantization for Image Search
Jun 07, 2019
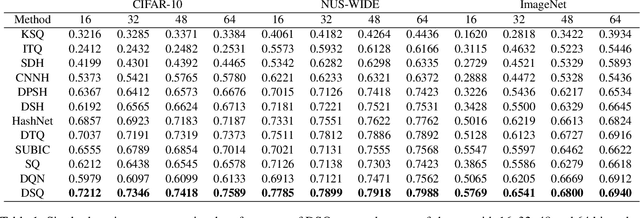
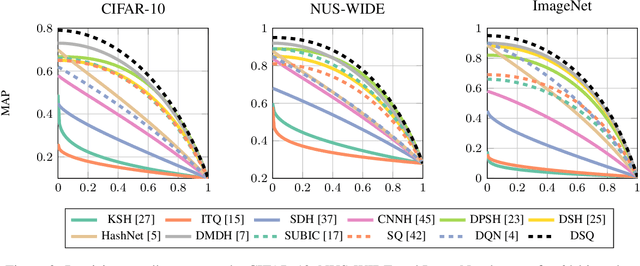
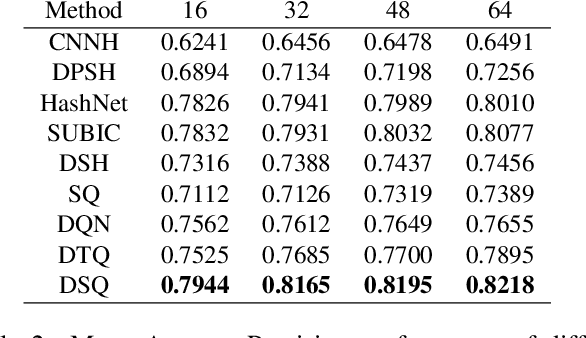
Hashing methods, which encode high-dimensional images with compact discrete codes, have been widely applied to enhance large-scale image retrieval. In this paper, we put forward Deep Spherical Quantization (DSQ), a novel method to make deep convolutional neural networks generate supervised and compact binary codes for efficient image search. Our approach simultaneously learns a mapping that transforms the input images into a low-dimensional discriminative space, and quantizes the transformed data points using multi-codebook quantization. To eliminate the negative effect of norm variance on codebook learning, we force the network to L_2 normalize the extracted features and then quantize the resulting vectors using a new supervised quantization technique specifically designed for points lying on a unit hypersphere. Furthermore, we introduce an easy-to-implement extension of our quantization technique that enforces sparsity on the codebooks. Extensive experiments demonstrate that DSQ and its sparse variant can generate semantically separable compact binary codes outperforming many state-of-the-art image retrieval methods on three benchmarks.
Clustering by Maximizing Mutual Information Across Views
Jul 24, 2021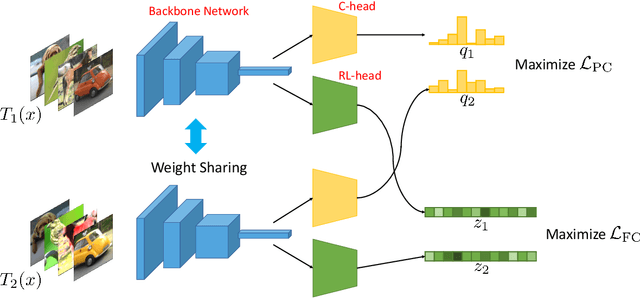
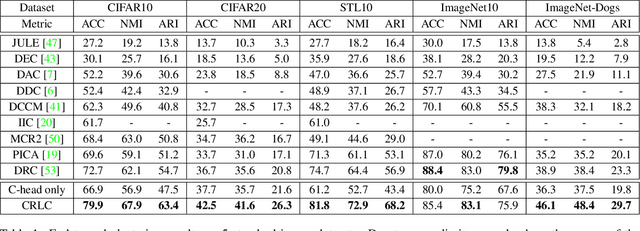


We propose a novel framework for image clustering that incorporates joint representation learning and clustering. Our method consists of two heads that share the same backbone network - a "representation learning" head and a "clustering" head. The "representation learning" head captures fine-grained patterns of objects at the instance level which serve as clues for the "clustering" head to extract coarse-grain information that separates objects into clusters. The whole model is trained in an end-to-end manner by minimizing the weighted sum of two sample-oriented contrastive losses applied to the outputs of the two heads. To ensure that the contrastive loss corresponding to the "clustering" head is optimal, we introduce a novel critic function called "log-of-dot-product". Extensive experimental results demonstrate that our method significantly outperforms state-of-the-art single-stage clustering methods across a variety of image datasets, improving over the best baseline by about 5-7% in accuracy on CIFAR10/20, STL10, and ImageNet-Dogs. Further, the "two-stage" variant of our method also achieves better results than baselines on three challenging ImageNet subsets.
EventGAN: Leveraging Large Scale Image Datasets for Event Cameras
Dec 19, 2019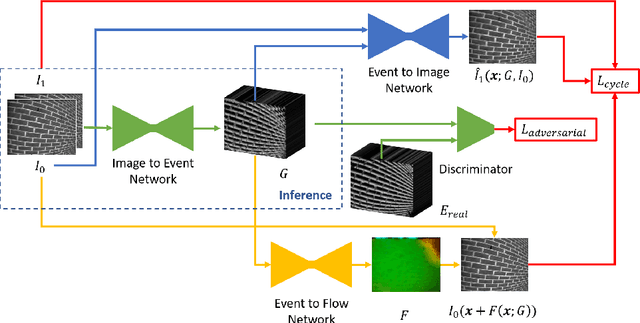



Event cameras provide a number of benefits over traditional cameras, such as the ability to track incredibly fast motions, high dynamic range, and low power consumption. However, their application into computer vision problems, many of which are primarily dominated by deep learning solutions, has been limited by the lack of labeled training data for events. In this work, we propose a method which leverages the existing labeled data for images by simulating events from a pair of temporal image frames, using a convolutional neural network. We train this network on pairs of images and events, using an adversarial discriminator loss and a pair of cycle consistency losses. The cycle consistency losses utilize a pair of pre-trained self-supervised networks which perform optical flow estimation and image reconstruction from events, and constrain our network to generate events which result in accurate outputs from both of these networks. Trained fully end to end, our network learns a generative model for events from images without the need for accurate modeling of the motion in the scene, exhibited by modeling based methods, while also implicitly modeling event noise. Using this simulator, we train a pair of downstream networks on object detection and 2D human pose estimation from events, using simulated data from large scale image datasets, and demonstrate the networks' abilities to generalize to datasets with real events.