 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gabor filter incorporated CNN for compression
Oct 29, 2021
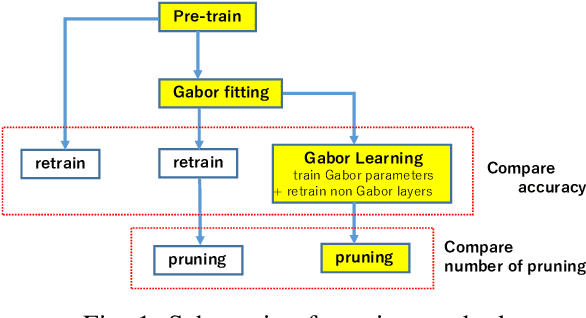
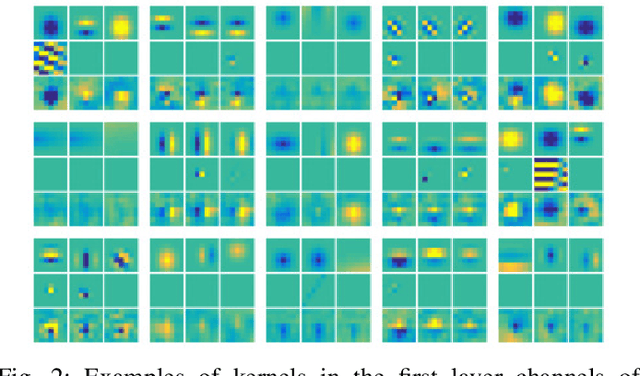
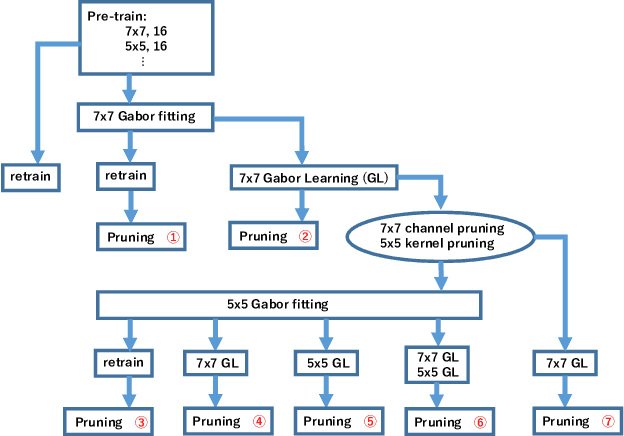
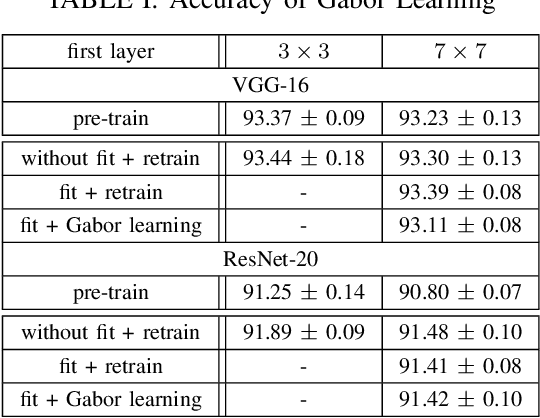
Convolutional neural networks (CNNs) are remarkably successful in many computer vision tasks. However, the high cost of inference is problematic for embedded and real-time systems, so there are many studies on compressing the networks. On the other hand, recent advances in self-attention models showed that convolution filters are preferable to self-attention in the earlier layers, which indicates that stronger inductive biases are better in the earlier layers. As shown in convolutional filters, strong biases can train specific filters and construct unnecessarily filters to zero. This is analogous to classical image processing tasks, where choosing the suitable filters makes a compact dictionary to represent features. We follow this idea and incorporate Gabor filters in the earlier layers of CNNs for compression. The parameters of Gabor filters are learned through backpropagation, so the features are restricted to Gabor filters. We show that the first layer of VGG-16 for CIFAR-10 has 192 kernels/features, but learning Gabor filters requires an average of 29.4 kernels. Also, using Gabor filters, an average of 83% and 94% of kernels in the first and the second layer, respectively, can be removed on the altered ResNet-20, where the first five layers are exchanged with two layers of larger kernels for CIFAR-10.
Multi-Temporal Aerial Image Registration Using Semantic Features
Sep 19, 2019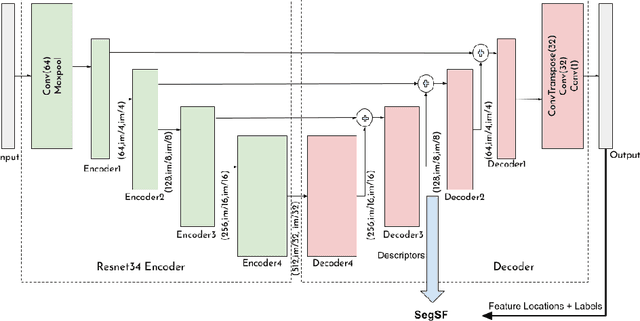


A semantic feature extraction method for multitemporal high resolution aerial image registration is proposed in this paper. These features encode properties or information about temporally invariant objects such as roads and help deal with issues such as changing foliage in image registration, which classical handcrafted features are unable to address. These features are extracted from a semantic segmentation network and have shown good robustness and accuracy in registering aerial images across years and seasons in the experiments.
Mutual-GAN: Towards Unsupervised Cross-Weather Adaptation with Mutual Information Constraint
Jun 30, 2021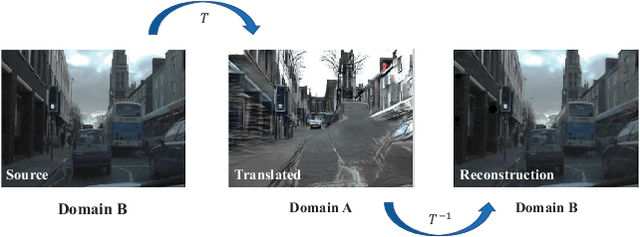
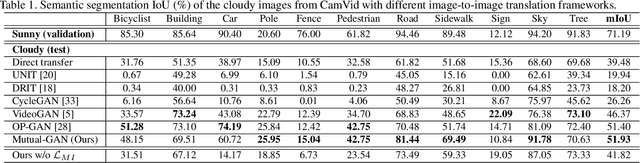
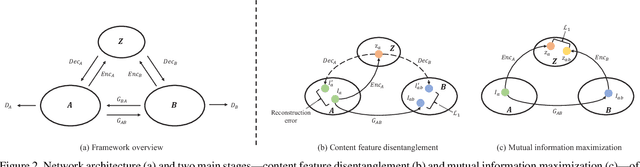
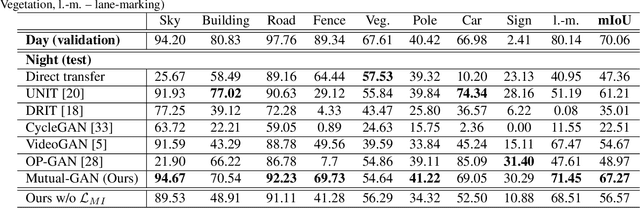
Convolutional neural network (CNN) have proven its success for semantic segmentation, which is a core task of emerging industrial applications such as autonomous driving. However, most progress in semantic segmentation of urban scenes is reported on standard scenarios, i.e., daytime scenes with favorable illumination conditions. In practical applications, the outdoor weather and illumination are changeable, e.g., cloudy and nighttime, which results in a significant drop of semantic segmentation accuracy of CNN only trained with daytime data. In this paper, we propose a novel generative adversarial network (namely Mutual-GAN) to alleviate the accuracy decline when daytime-trained neural network is applied to videos captured under adverse weather conditions. The proposed Mutual-GAN adopts mutual information constraint to preserve image-objects during cross-weather adaptation, which is an unsolved problem for most unsupervised image-to-image translation approaches (e.g., CycleGAN). The proposed Mutual-GAN is evaluated on two publicly available driving video datasets (i.e., CamVid and SYNTHIA). The experimental results demonstrate that our Mutual-GAN can yield visually plausible translated images and significantly improve the semantic segmentation accuracy of daytime-trained deep learning network while processing videos under challenging weathers.
Multi-modal gated recurrent units for image description
Apr 20, 2019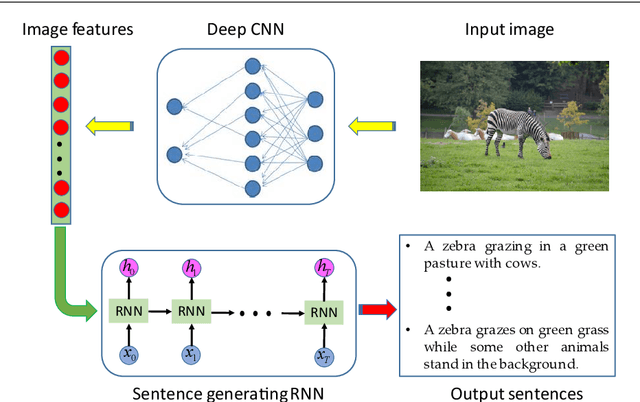
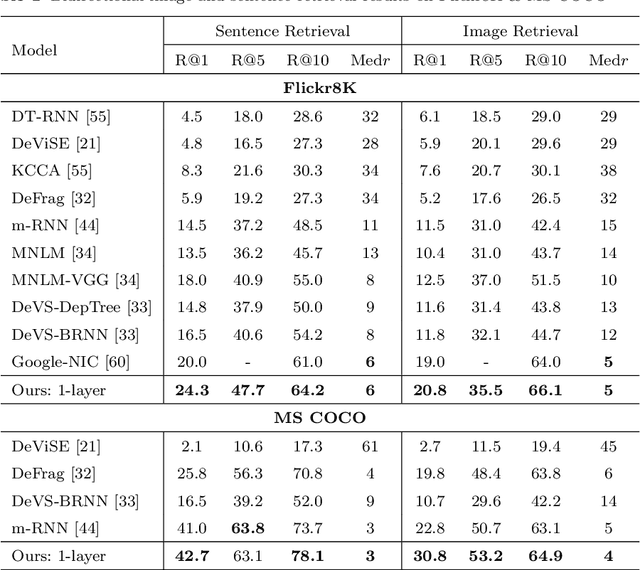
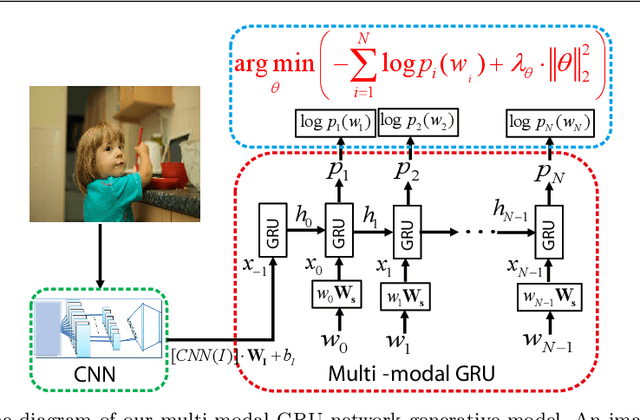
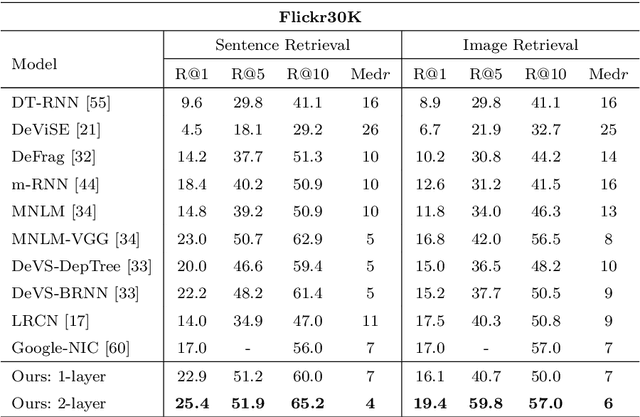
Using a natural language sentence to describe the content of an image is a challenging but very important task. It is challenging because a description must not only capture objects contained in the image and the relationships among them, but also be relevant and grammatically correct. In this paper a multi-modal embedding model based on gated recurrent units (GRU) which can generate variable-length description for a given image. In the training step, we apply the convolutional neural network (CNN) to extract the image feature. Then the feature is imported into the multi-modal GRU as well as the corresponding sentence representations. The multi-modal GRU learns the inter-modal relations between image and sentence. And in the testing step, when an image is imported to our multi-modal GRU model, a sentence which describes the image content is generated. The experimental results demonstrate that our multi-modal GRU model obtains the state-of-the-art performance on Flickr8K, Flickr30K and MS COCO datasets.
* 25 pages, 7 figures, 6 tables, magazine
A Good Prompt Is Worth Millions of Parameters? Low-resource Prompt-based Learning for Vision-Language Models
Oct 16, 2021
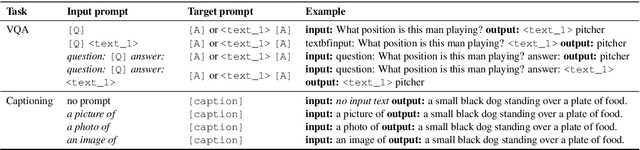
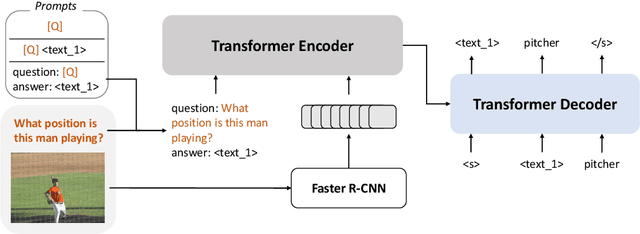
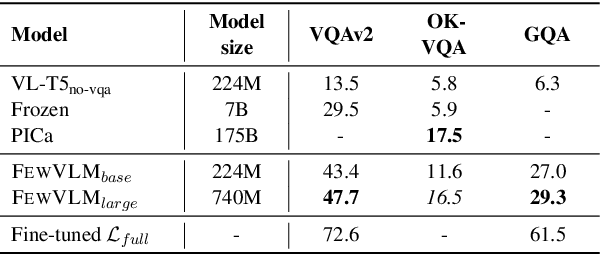
Large pretrained vision-language (VL) models can learn a new task with a handful of examples or generalize to a new task without fine-tuning. However, these gigantic VL models are hard to deploy for real-world applications due to their impractically huge model size and slow inference speed. In this work, we propose FewVLM, a few-shot prompt-based learner on vision-language tasks. We pretrain a sequence-to-sequence Transformer model with both prefix language modeling (PrefixLM) and masked language modeling (MaskedLM), and introduce simple prompts to improve zero-shot and few-shot performance on VQA and image captioning. Experimental results on five VQA and captioning datasets show that \method\xspace outperforms Frozen which is 31 times larger than ours by 18.2% point on zero-shot VQAv2 and achieves comparable results to a 246$\times$ larger model, PICa. We observe that (1) prompts significantly affect zero-shot performance but marginally affect few-shot performance, (2) MaskedLM helps few-shot VQA tasks while PrefixLM boosts captioning performance, and (3) performance significantly increases when training set size is small.
Using Deep Object Features for Image Descriptions
Feb 25, 2019
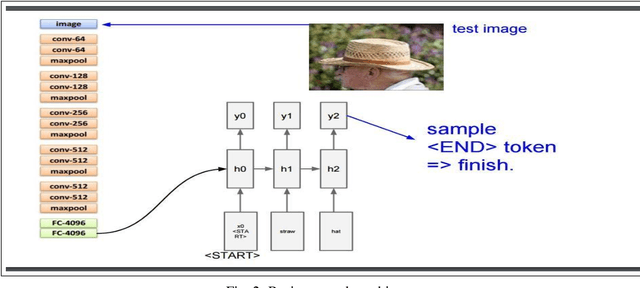
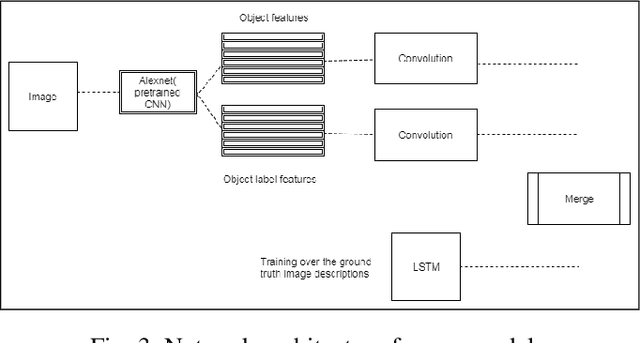

Inspired by recent advances in leveraging multiple modalities in machine translation, we introduce an encoder-decoder pipeline that uses (1) specific objects within an image and their object labels, (2) a language model for decoding joint embedding of object features and the object labels. Our pipeline merges prior detected objects from the image and their object labels and then learns the sequences of captions describing the particular image. The decoder model learns to extract descriptions for the image from scratch by decoding the joint representation of the object visual features and their object classes conditioned by the encoder component. The idea of the model is to concentrate only on the specific objects of the image and their labels for generating descriptions of the image rather than visual feature of the entire image. The model needs to be calibrated more by adjusting the parameters and settings to result in better accuracy and performance.
Show, Edit and Tell: A Framework for Editing Image Captions
Mar 06, 2020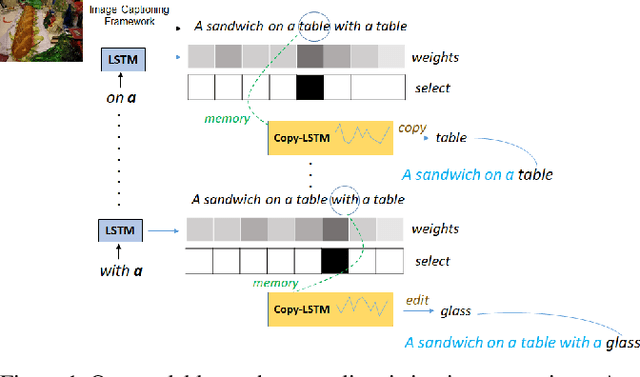
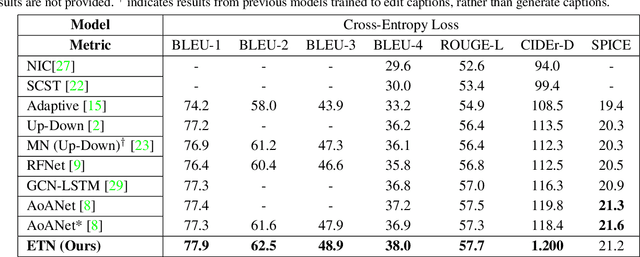
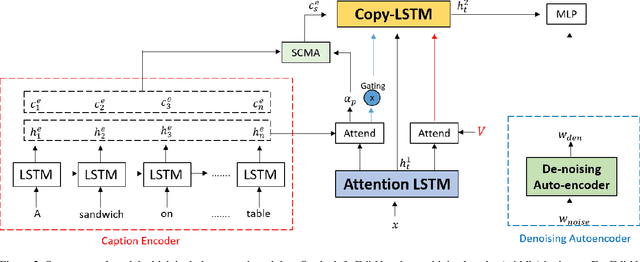
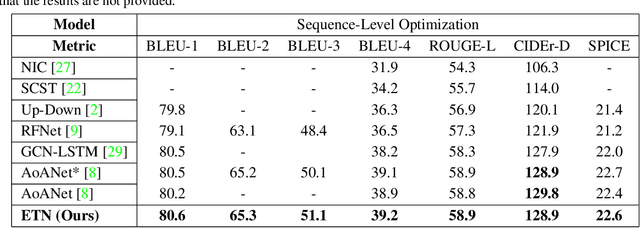
Most image captioning frameworks generate captions directly from images, learning a mapping from visual features to natural language. However, editing existing captions can be easier than generating new ones from scratch. Intuitively, when editing captions, a model is not required to learn information that is already present in the caption (i.e. sentence structure), enabling it to focus on fixing details (e.g. replacing repetitive words). This paper proposes a novel approach to image captioning based on iterative adaptive refinement of an existing caption. Specifically, our caption-editing model consisting of two sub-modules: (1) EditNet, a language module with an adaptive copy mechanism (Copy-LSTM) and a Selective Copy Memory Attention mechanism (SCMA), and (2) DCNet, an LSTM-based denoising auto-encoder. These components enable our model to directly copy from and modify existing captions. Experiments demonstrate that our new approach achieves state-of-art performance on the MS COCO dataset both with and without sequence-level training.
Exploiting Spatial-Temporal Semantic Consistency for Video Scene Parsing
Sep 06, 2021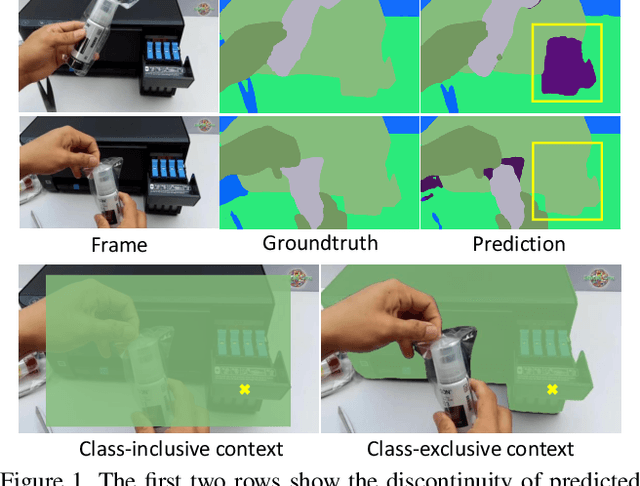
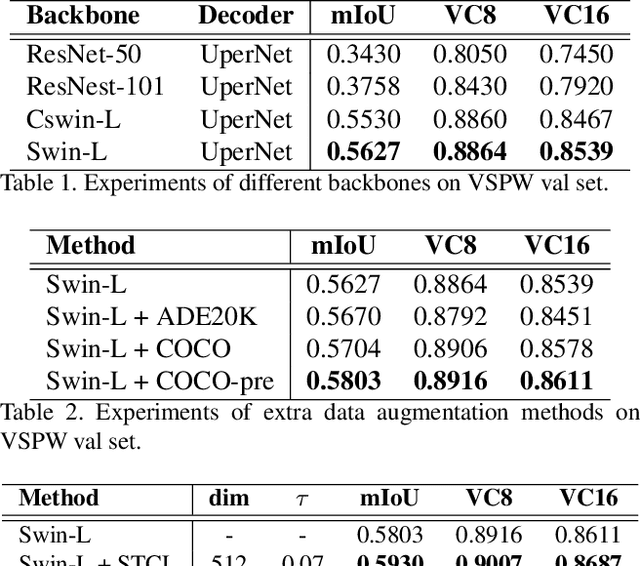
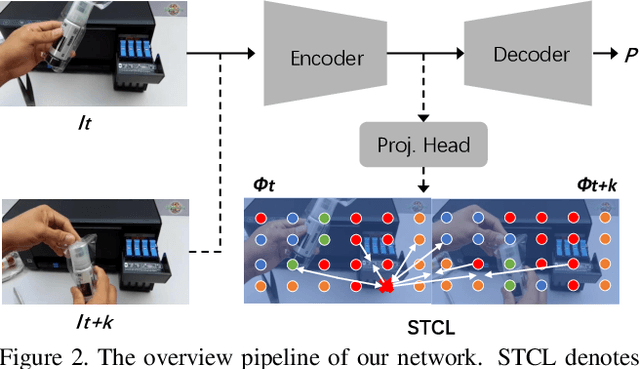
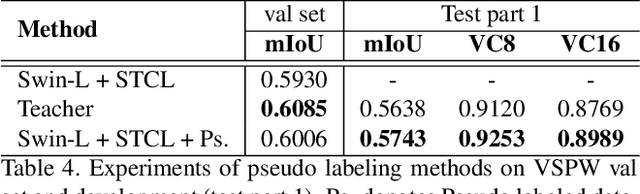
Compared with image scene parsing, video scene parsing introduces temporal information, which can effectively improve the consistency and accuracy of prediction. In this paper, we propose a Spatial-Temporal Semantic Consistency method to capture class-exclusive context information. Specifically, we design a spatial-temporal consistency loss to constrain the semantic consistency in spatial and temporal dimensions. In addition, we adopt an pseudo-labeling strategy to enrich the training dataset. We obtain the scores of 59.84% and 58.85% mIoU on development (test part 1) and testing set of VSPW, respectively. And our method wins the 1st place on VSPW challenge at ICCV2021.
Toward a Visual Concept Vocabulary for GAN Latent Space
Oct 08, 2021
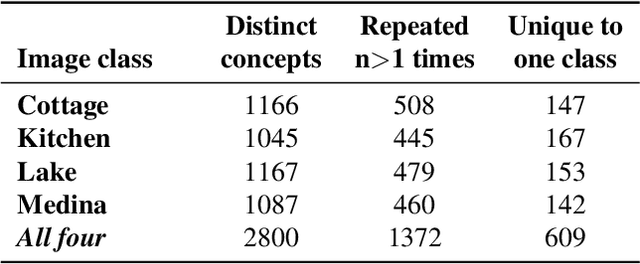

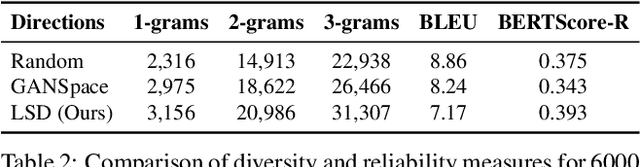
A large body of recent work has identified transformations in the latent spaces of generative adversarial networks (GANs) that consistently and interpretably transform generated images. But existing techniques for identifying these transformations rely on either a fixed vocabulary of pre-specified visual concepts, or on unsupervised disentanglement techniques whose alignment with human judgments about perceptual salience is unknown. This paper introduces a new method for building open-ended vocabularies of primitive visual concepts represented in a GAN's latent space. Our approach is built from three components: (1) automatic identification of perceptually salient directions based on their layer selectivity; (2) human annotation of these directions with free-form, compositional natural language descriptions; and (3) decomposition of these annotations into a visual concept vocabulary, consisting of distilled directions labeled with single words. Experiments show that concepts learned with our approach are reliable and composable -- generalizing across classes, contexts, and observers, and enabling fine-grained manipulation of image style and content.
Efficient Real-Time Image Recognition Using Collaborative Swarm of UAVs and Convolutional Networks
Jul 09, 2021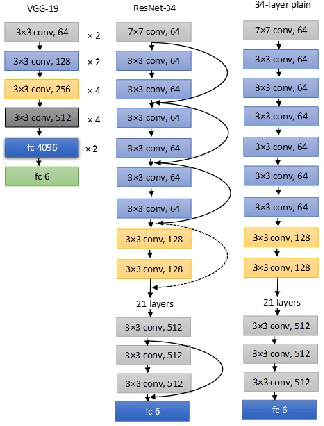
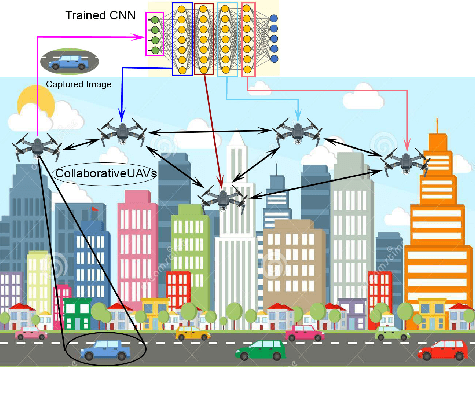
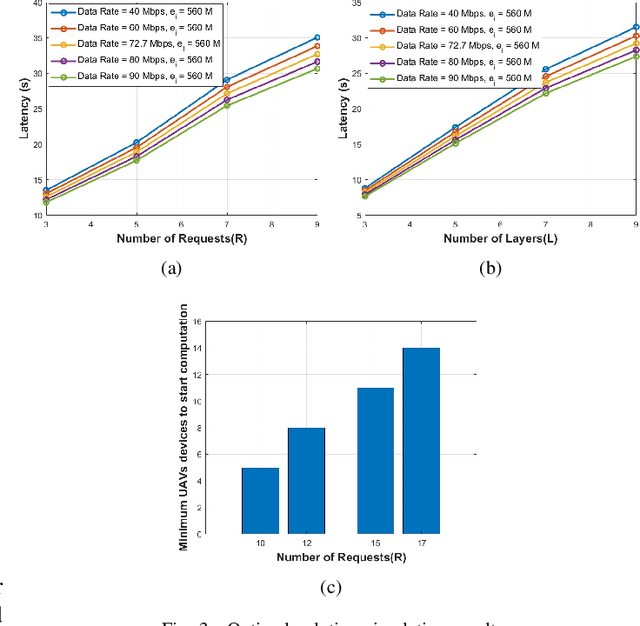
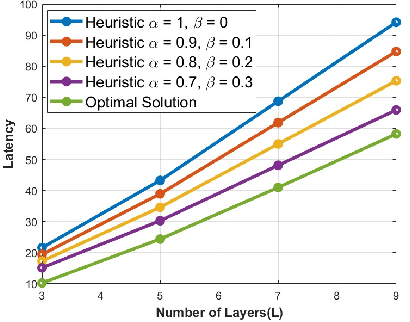
Unmanned Aerial Vehicles (UAVs) have recently attracted significant attention due to their outstanding ability to be used in different sectors and serve in difficult and dangerous areas. Moreover, the advancements in computer vision and artificial intelligence have increased the use of UAVs in various applications and solutions, such as forest fires detection and borders monitoring. However, using deep neural networks (DNNs) with UAVs introduces several challenges of processing deeper networks and complex models, which restricts their on-board computation. In this work, we present a strategy aiming at distributing inference requests to a swarm of resource-constrained UAVs that classifies captured images on-board and finds the minimum decision-making latency. We formulate the model as an optimization problem that minimizes the latency between acquiring images and making the final decisions. The formulated optimization solution is an NP-hard problem. Hence it is not adequate for online resource allocation. Therefore, we introduce an online heuristic solution, namely DistInference, to find the layers placement strategy that gives the best latency among the available UAVs. The proposed approach is general enough to be used for different low decision-latency applications as well as for all CNN types organized into the pipeline of layers (e.g., VGG) or based on residual blocks (e.g., ResNet).