 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contrastive Active Inference
Oct 19, 2021
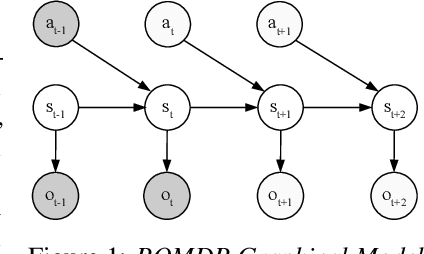
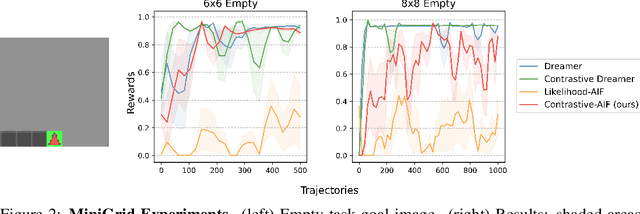

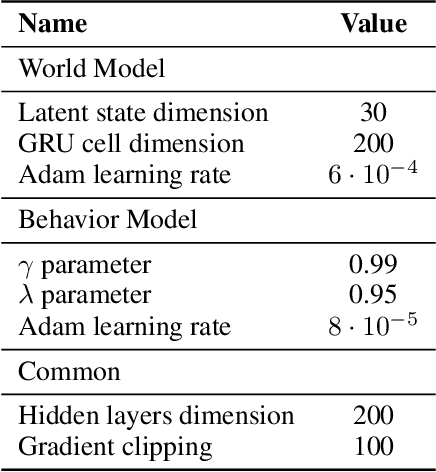
Active inference is a unifying theory for perception and action resting upon the idea that the brain maintains an internal model of the world by minimizing free energy. From a behavioral perspective, active inference agents can be seen as self-evidencing beings that act to fulfill their optimistic predictions, namely preferred outcomes or goals. In contrast, reinforcement learning requires human-designed rewards to accomplish any desired outcome. Although active inference could provide a more natural self-supervised objective for control, its applicability has been limited because of the shortcomings in scaling the approach to complex environments. In this work, we propose a contrastive objective for active inference that strongly reduces the computational burden in learning the agent's generative model and planning future actions. Our method performs notably better than likelihood-based active inference in image-based tasks, while also being computationally cheaper and easier to train. We compare to reinforcement learning agents that have access to human-designed reward functions, showing that our approach closely matches their performance. Finally, we also show that contrastive methods perform significantly better in the case of distractors in the environment and that our method is able to generalize goals to variations in the background.
Improving Shape Deformation in Unsupervised Image-to-Image Translation
Aug 13, 2018



Unsupervised image-to-image translation techniques are able to map local texture between two domains, but they are typically unsuccessful when the domains require larger shape change. Inspired by semantic segmentation, we introduce a discriminator with dilated convolutions that is able to use information from across the entire image to train a more context-aware generator. This is coupled with a multi-scale perceptual loss that is better able to represent error in the underlying shape of objects. We demonstrate that this design is more capable of representing shape deformation in a challenging toy dataset, plus in complex mappings with significant dataset variation between humans, dolls, and anime faces, and between cats and dogs.
SIRe-Networks: Skip Connections over Interlaced Multi-Task Learning and Residual Connections for Structure Preserving Object Classification
Oct 06, 2021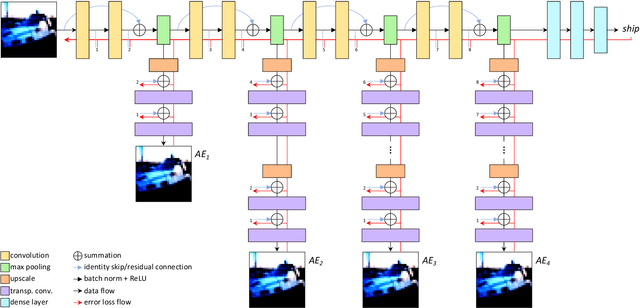
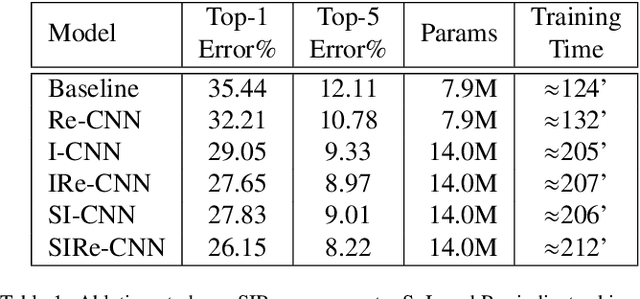

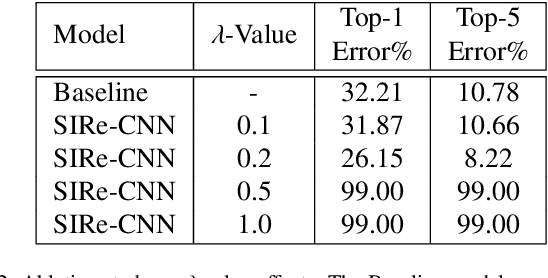
Improving existing neural network architectures can involve several design choices such as manipulating the loss functions, employing a diverse learning strategy, exploiting gradient evolution at training time, optimizing the network hyper-parameters, or increasing the architecture depth. The latter approach is a straightforward solution, since it directly enhances the representation capabilities of a network; however, the increased depth generally incurs in the well-known vanishing gradient problem. In this paper, borrowing from different methods addressing this issue, we introduce an interlaced multi-task learning strategy, defined SIRe, to reduce the vanishing gradient in relation to the object classification task. The presented methodology directly improves a convolutional neural network (CNN) by enforcing the input image structure preservation through interlaced auto-encoders, and further refines the base network architecture by means of skip and residual connections. To validate the presented methodology, a simple CNN and various implementations of famous networks are extended via the SIRe strategy and extensively tested on the CIFAR100 dataset; where the SIRe-extended architectures achieve significantly increased performances across all models, thus confirming the presented approach effectiveness.
Knothe-Rosenblatt transport for Unsupervised Domain Adaptation
Oct 06, 2021
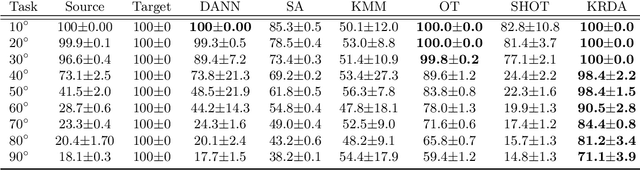
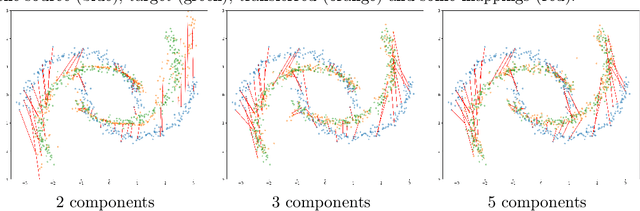
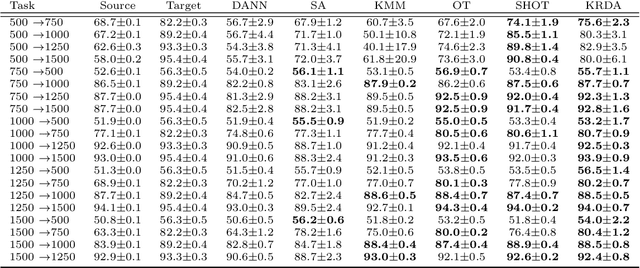
Unsupervised domain adaptation (UDA) aims at exploiting related but different data sources to tackle a common task in a target domain. UDA remains a central yet challenging problem in machine learning. In this paper, we present an approach tailored to moderate-dimensional tabular problems which are hugely important in industrial applications and less well-served by the plethora of methods designed for image and language data. Knothe-Rosenblatt Domain Adaptation (KRDA) is based on the Knothe-Rosenblatt transport: we exploit autoregressive density estimation algorithms to accurately model the different sources by an autoregressive model using a mixture of Gaussians. KRDA then takes advantage of the triangularity of the autoregressive models to build an explicit mapping of the source samples into the target domain. We show that the transfer map built by KRDA preserves each component quantiles of the observations, hence aligning the representations of the different data sets in the same target domain. Finally, we show that KRDA has state-of-the-art performance on both synthetic and real world UDA problems.
2.5D Image based Robotic Grasping
May 31, 2019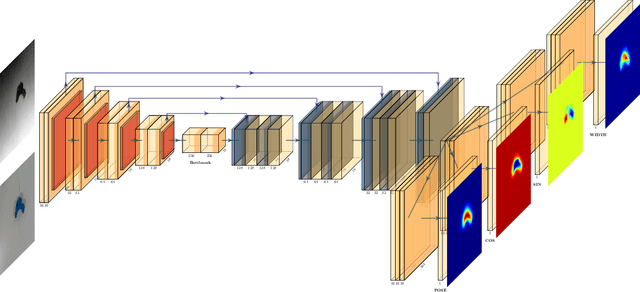

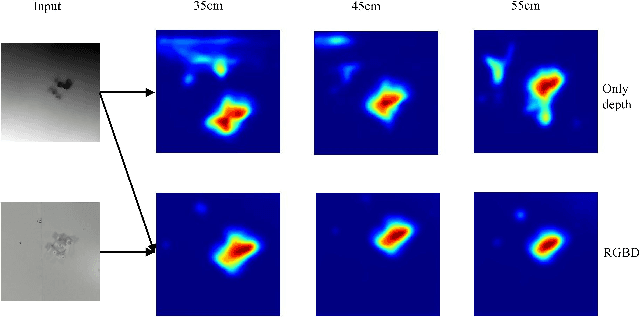
We consider the problem of robotic grasping using depth + RGB information sampling from a real sensor. we design an encoder-decoder neural network to predict grasp policy in real time. This method can fuse the advantage of depth image and RGB image at the same time and is robust for grasp and observation height.We evaluate our method in a physical robotic system and propose an open-loop algorithm to realize robotic grasp operation. We analyze the result of experiment from multi-perspective and the result shows that our method is competitive with the state-of-the-art in grasp performance, real-time and model size. The video is available in https://youtu.be/Wxw_r5a8qV0
Controllable List-wise Ranking for Universal No-reference Image Quality Assessment
Jan 06, 2020
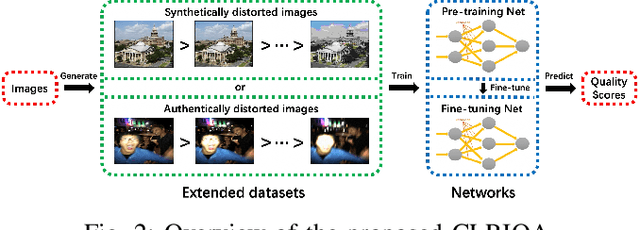

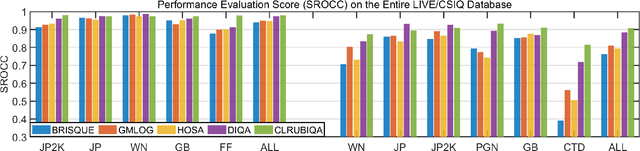
No-reference image quality assessment (NR-IQA) has received increasing attention in the IQA community since reference image is not always available. Real-world images generally suffer from various types of distortion. Unfortunately, existing NR-IQA methods do not work with all types of distortion. It is a challenging task to develop universal NR-IQA that has the ability of evaluating all types of distorted images. In this paper, we propose a universal NR-IQA method based on controllable list-wise ranking (CLRIQA). First, to extend the authentically distorted image dataset, we present an imaging-heuristic approach, in which the over-underexposure is formulated as an inverse of Weber-Fechner law, and fusion strategy and probabilistic compression are adopted, to generate the degraded real-world images. These degraded images are label-free yet associated with quality ranking information. We then design a controllable list-wise ranking function by limiting rank range and introducing an adaptive margin to tune rank interval. Finally, the extended dataset and controllable list-wise ranking function are used to pre-train a CNN. Moreover, in order to obtain an accurate prediction model, we take advantage of the original dataset to further fine-tune the pre-trained network. Experiments evaluated on four benchmark datasets (i.e. LIVE, CSIQ, TID2013, and LIVE-C) show that the proposed CLRIQA improves the state of the art by over 9% in terms of overall performance. The code and model are publicly available at https://github.com/GZHU-Image-Lab/CLRIQA.
Characterizing Learning Dynamics of Deep Neural Networks via Complex Networks
Oct 06, 2021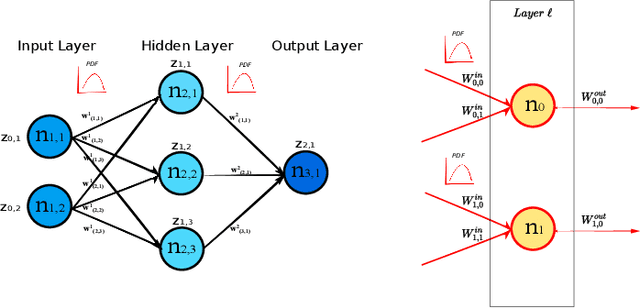
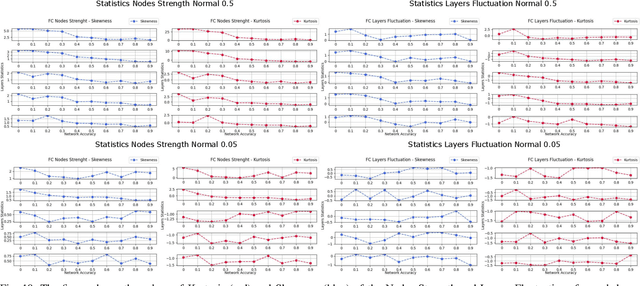
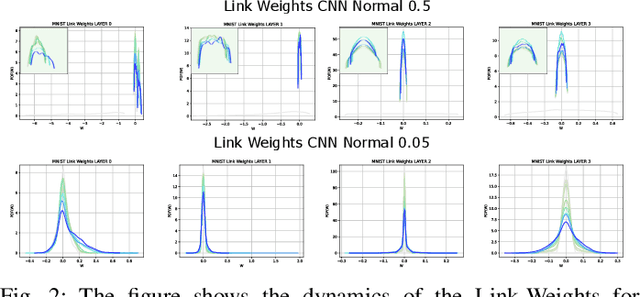
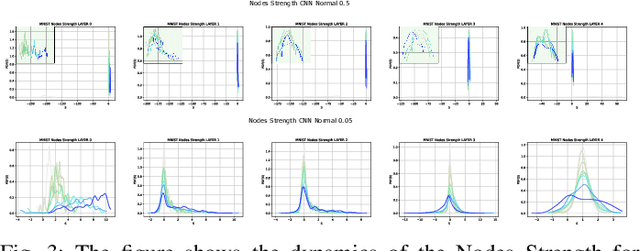
In this paper, we interpret Deep Neural Networks with Complex Network Theory. Complex Network Theory (CNT) represents Deep Neural Networks (DNNs) as directed weighted graphs to study them as dynamical systems. We efficiently adapt CNT measures to examine the evolution of the learning process of DNNs with different initializations and architectures: we introduce metrics for nodes/neurons and layers, namely Nodes Strength and Layers Fluctuation. Our framework distills trends in the learning dynamics and separates low from high accurate networks. We characterize populations of neural networks (ensemble analysis) and single instances (individual analysis). We tackle standard problems of image recognition, for which we show that specific learning dynamics are indistinguishable when analysed through the solely Link-Weights analysis. Further, Nodes Strength and Layers Fluctuations make unprecedented behaviours emerge: accurate networks, when compared to under-trained models, show substantially divergent distributions with the greater extremity of deviations. On top of this study, we provide an efficient implementation of the CNT metrics for both Convolutional and Fully Connected Networks, to fasten the research in this direction.
* IEEE/ICTAI2021 (full paper)
Personalizing Pre-trained Models
Jun 02, 2021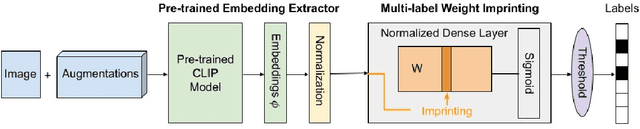
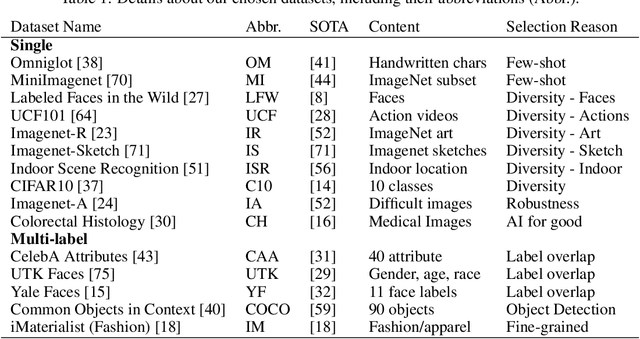
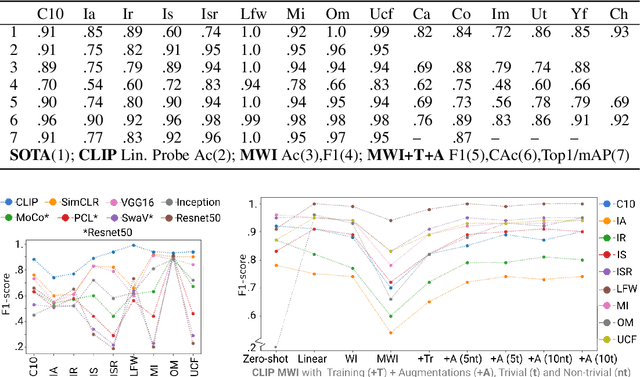
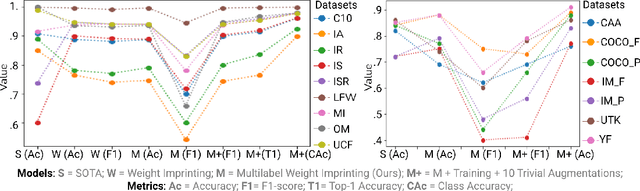
Self-supervised or weakly supervised models trained on large-scale datasets have shown sample-efficient transfer to diverse datasets in few-shot settings. We consider how upstream pretrained models can be leveraged for downstream few-shot, multilabel, and continual learning tasks. Our model CLIPPER (CLIP PERsonalized) uses image representations from CLIP, a large-scale image representation learning model trained using weak natural language supervision. We developed a technique, called Multi-label Weight Imprinting (MWI), for multi-label, continual, and few-shot learning, and CLIPPER uses MWI with image representations from CLIP. We evaluated CLIPPER on 10 single-label and 5 multi-label datasets. Our model shows robust and competitive performance, and we set new benchmarks for few-shot, multi-label, and continual learning. Our lightweight technique is also compute-efficient and enables privacy-preserving applications as the data is not sent to the upstream model for fine-tuning.
Fusion of Complex Networks-based Global and Local Features for Texture Classification
Jun 20, 2021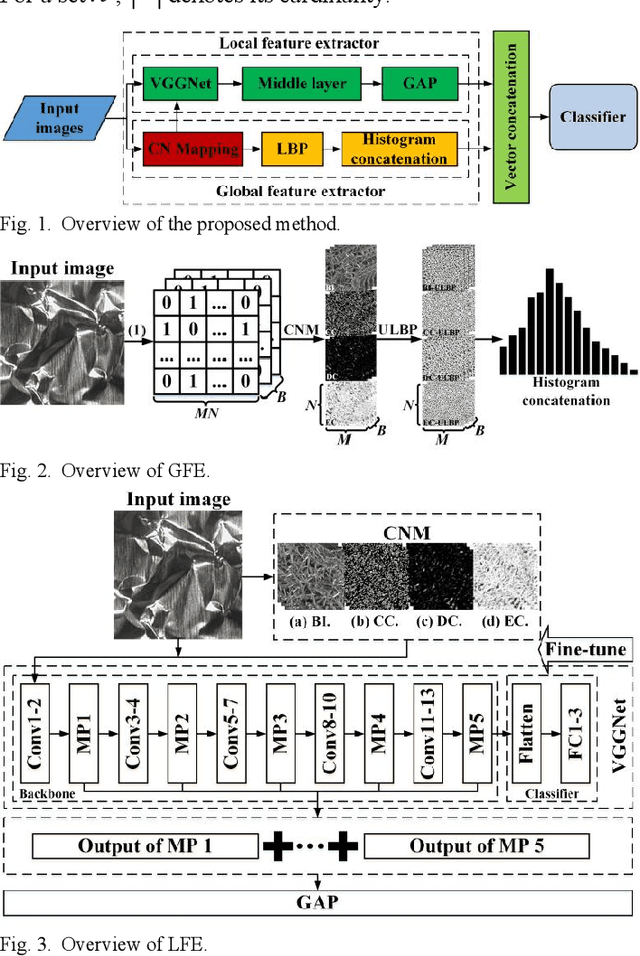
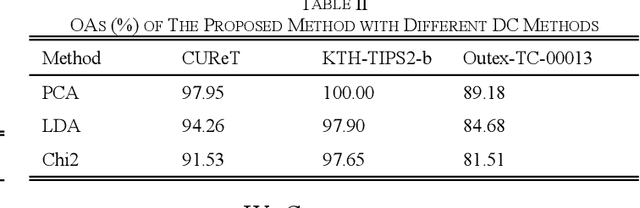
To realize accurate texture classification, this article proposes a complex networks (CN)-based multi-feature fusion method to recognize texture images. Specifically, we propose two feature extractors to detect the global and local features of texture images respectively. To capture the global features, we first map a texture image as an undirected graph based on pixel location and intensity, and three feature measurements are designed to further decipher the image features, which retains the image information as much as possible. Then, given the original band images (BI) and the generated feature images, we encode them based on the local binary patterns (LBP). Therefore, the global feature vector is obtained by concatenating four spatial histograms. To decipher the local features, we jointly transfer and fine-tune the pre-trained VGGNet-16 model. Next, we fuse and connect the middle outputs of max-pooling layers (MP), and generate the local feature vector by a global average pooling layer (GAP). Finally, the global and local feature vectors are concatenated to form the final feature representation of texture images. Experiment results show that the proposed method outperforms the state-of-the-art statistical descriptors and the deep convolutional neural networks (CNN) models.
Faces in the Wild: Efficient Gender Recognition in Surveillance Conditions
Jul 14, 2021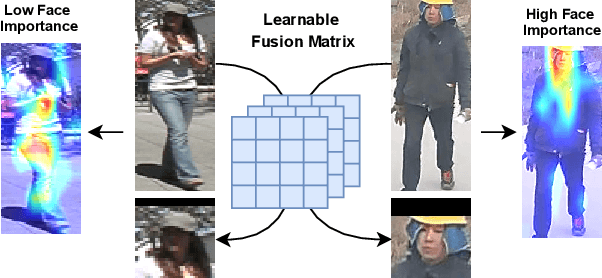
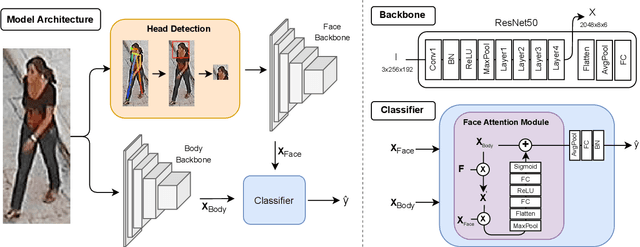


Soft biometrics inference in surveillance scenarios is a topic of interest for various applications, particularly in security-related areas. However, soft biometric analysis is not extensively reported in wild conditions. In particular, previous works on gender recognition report their results in face datasets, with relatively good image quality and frontal poses. Given the uncertainty of the availability of the facial region in wild conditions, we consider that these methods are not adequate for surveillance settings. To overcome these limitations, we: 1) present frontal and wild face versions of three well-known surveillance datasets; and 2) propose a model that effectively and dynamically combines facial and body information, which makes it suitable for gender recognition in wild conditions. The frontal and wild face datasets derive from widely used Pedestrian Attribute Recognition (PAR) sets (PETA, PA-100K, and RAP), using a pose-based approach to filter the frontal samples and facial regions. This approach retrieves the facial region of images with varying image/subject conditions, where the state-of-the-art face detectors often fail. Our model combines facial and body information through a learnable fusion matrix and a channel-attention sub-network, focusing on the most influential body parts according to the specific image/subject features. We compare it with five PAR methods, consistently obtaining state-of-the-art results on gender recognition, and reducing the prediction errors by up to 24% in frontal samples. The announced PAR datasets versions and model serve as the basis for wild soft biometrics classification and are available in https://github.com/Tiago-Roxo.