 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning
Jun 03, 2021
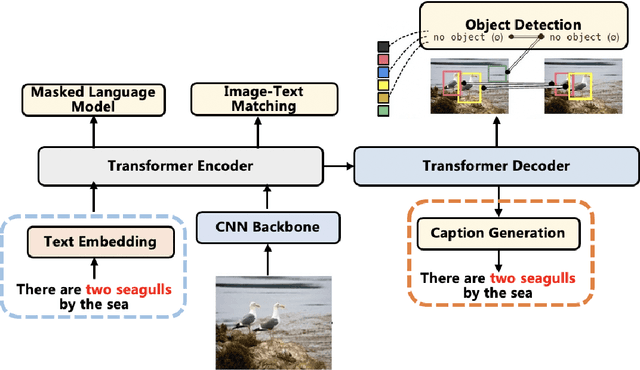
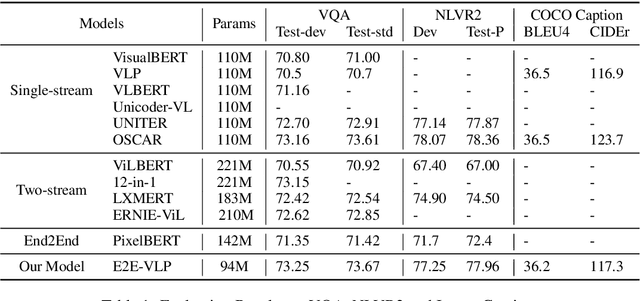
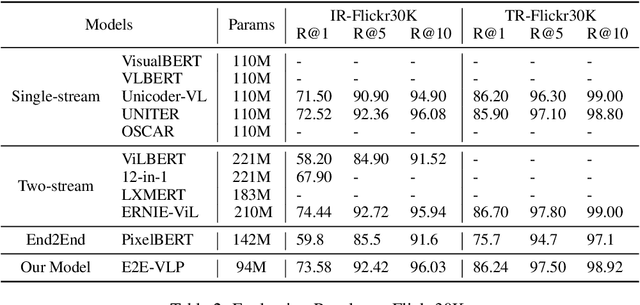
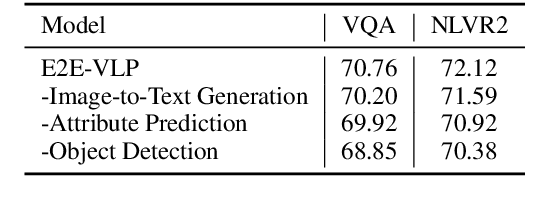
Vision-language pre-training (VLP) on large-scale image-text pairs has achieved huge success for the cross-modal downstream tasks. The most existing pre-training methods mainly adopt a two-step training procedure, which firstly employs a pre-trained object detector to extract region-based visual features, then concatenates the image representation and text embedding as the input of Transformer to train. However, these methods face problems of using task-specific visual representation of the specific object detector for generic cross-modal understanding, and the computation inefficiency of two-stage pipeline. In this paper, we propose the first end-to-end vision-language pre-trained model for both V+L understanding and generation, namely E2E-VLP, where we build a unified Transformer framework to jointly learn visual representation, and semantic alignments between image and text. We incorporate the tasks of object detection and image captioning into pre-training with a unified Transformer encoder-decoder architecture for enhancing visual learning. An extensive set of experiments have been conducted on well-established vision-language downstream tasks to demonstrate the effectiveness of this novel VLP paradigm.
Image Difficulty Curriculum for Generative Adversarial Networks (CuGAN)
Oct 20, 2019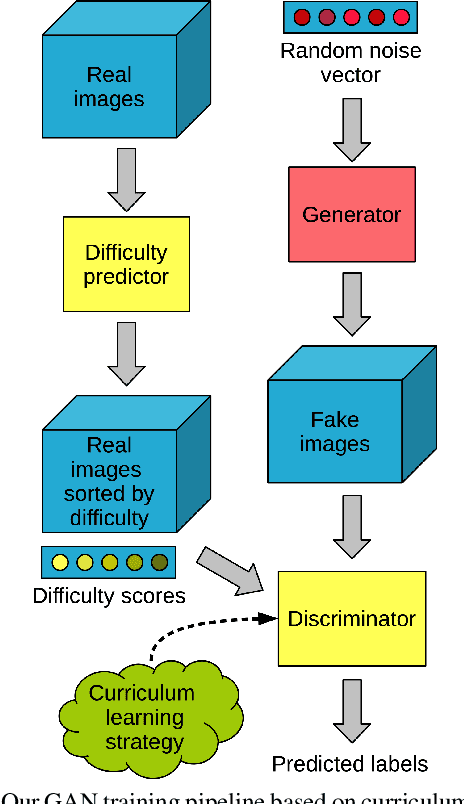


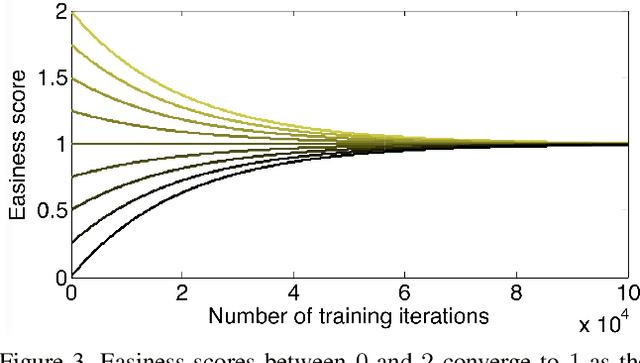
Despite the significant advances in recent years, Generative Adversarial Networks (GANs) are still notoriously hard to train. In this paper, we propose three novel curriculum learning strategies for training GANs. All strategies are first based on ranking the training images by their difficulty scores, which are estimated by a state-of-the-art image difficulty predictor. Our first strategy is to divide images into gradually more difficult batches. Our second strategy introduces a novel curriculum loss function for the discriminator that takes into account the difficulty scores of the real images. Our third strategy is based on sampling from an evolving distribution, which favors the easier images during the initial training stages and gradually converges to a uniform distribution, in which samples are equally likely, regardless of difficulty. We compare our curriculum learning strategies with the classic training procedure on two tasks: image generation and image translation. Our experiments indicate that all strategies provide faster convergence and superior results. For example, our best curriculum learning strategy applied on spectrally normalized GANs (SNGANs) fooled human annotators in thinking that generated CIFAR-like images are real in 25.0% of the presented cases, while the SNGANs trained using the classic procedure fooled the annotators in only 18.4% cases. Similarly, in image translation, the human annotators preferred the images produced by the Cycle-consistent GAN (CycleGAN) trained using curriculum learning in 40.5% cases and those produced by CycleGAN based on classic training in only 19.8% cases, $39.7\%$ cases being labeled as ties.
Spatio-Temporal Dual-Stream Neural Network for Sequential Whole-Body PET Segmentation
Jun 09, 2021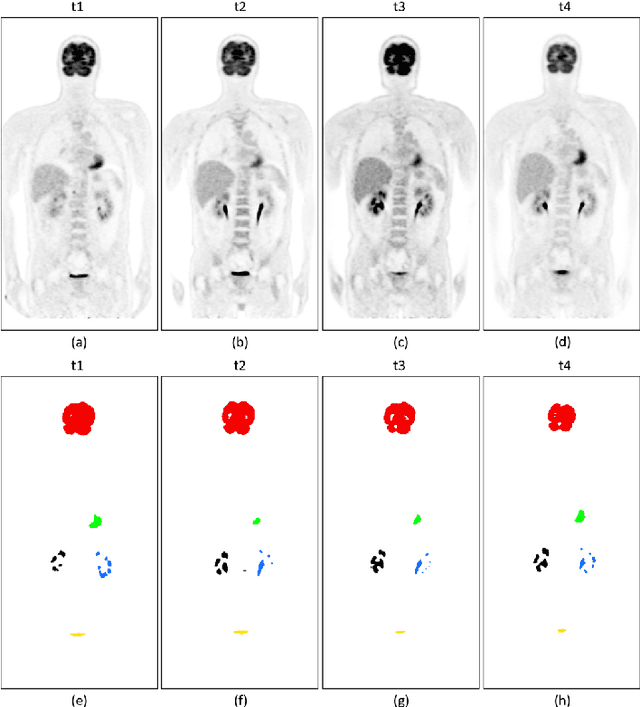

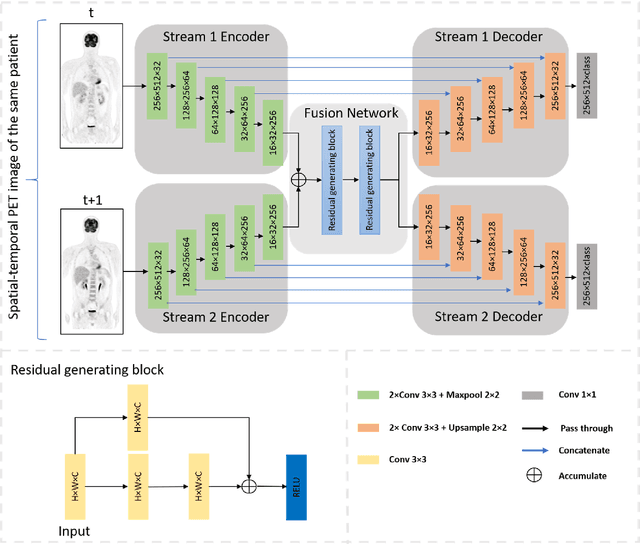
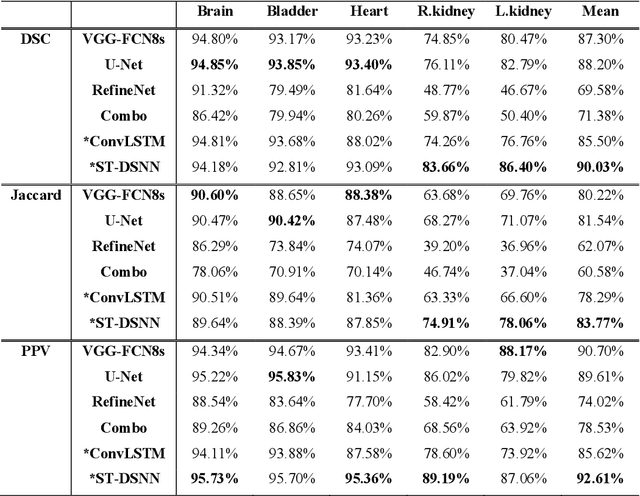
Sequential whole-body 18F-Fluorodeoxyglucose (FDG) positron emission tomography (PET) scans are regarded as the imaging modality of choice for the assessment of treatment response in the lymphomas because they detect treatment response when there may not be changes on anatomical imaging. Any computerized analysis of lymphomas in whole-body PET requires automatic segmentation of the studies so that sites of disease can be quantitatively monitored over time. State-of-the-art PET image segmentation methods are based on convolutional neural networks (CNNs) given their ability to leverage annotated datasets to derive high-level features about the disease process. Such methods, however, focus on PET images from a single time-point and discard information from other scans or are targeted towards specific organs and cannot cater for the multiple structures in whole-body PET images. In this study, we propose a spatio-temporal 'dual-stream' neural network (ST-DSNN) to segment sequential whole-body PET scans. Our ST-DSNN learns and accumulates image features from the PET images done over time. The accumulated image features are used to enhance the organs / structures that are consistent over time to allow easier identification of sites of active lymphoma. Our results show that our method outperforms the state-of-the-art PET image segmentation methods.
Temporally Consistent Video Colorization with Deep Feature Propagation and Self-regularization Learning
Oct 09, 2021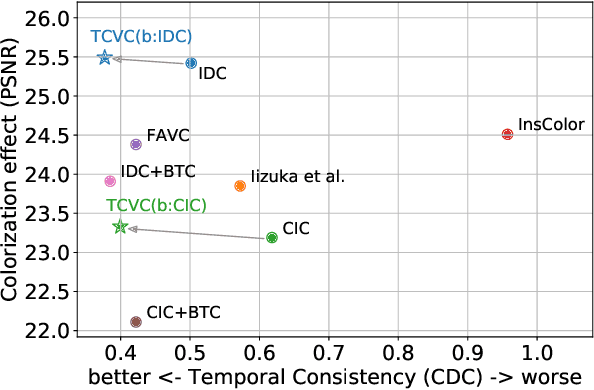
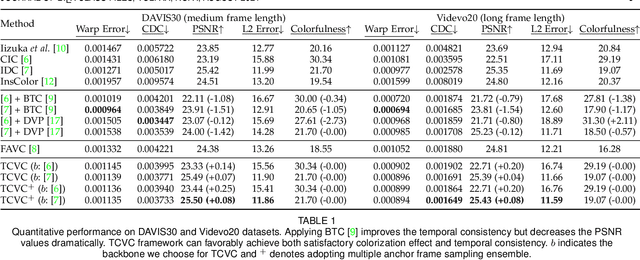

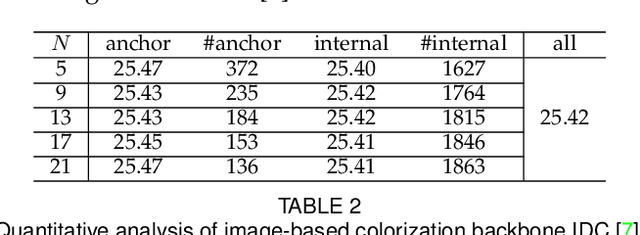
Video colorization is a challenging and highly ill-posed problem. Although recent years have witnessed remarkable progress in single image colorization, there is relatively less research effort on video colorization and existing methods always suffer from severe flickering artifacts (temporal inconsistency) or unsatisfying colorization performance. We address this problem from a new perspective, by jointly considering colorization and temporal consistency in a unified framework. Specifically, we propose a novel temporally consistent video colorization framework (TCVC). TCVC effectively propagates frame-level deep features in a bidirectional way to enhance the temporal consistency of colorization. Furthermore, TCVC introduces a self-regularization learning (SRL) scheme to minimize the prediction difference obtained with different time steps. SRL does not require any ground-truth color videos for training and can further improve temporal consistency. Experiments demonstrate that our method can not only obtain visually pleasing colorized video, but also achieve clearly better temporal consistency than state-of-the-art methods.
DARTS for Inverse Problems: a Study on Hyperparameter Sensitivity
Aug 12, 2021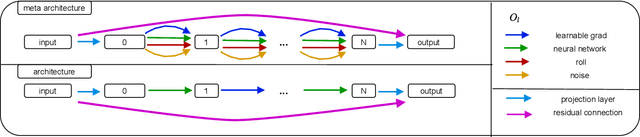
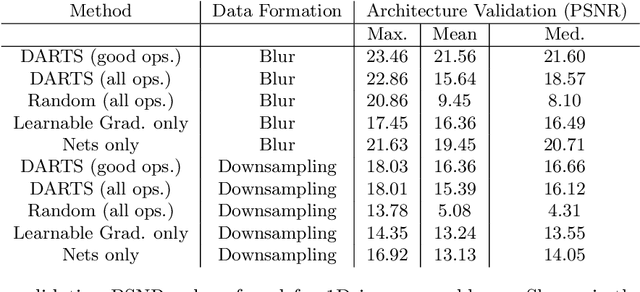
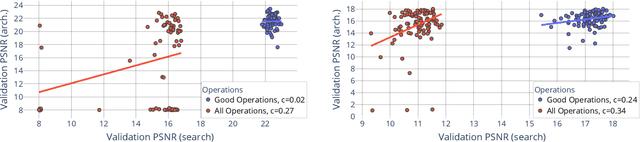
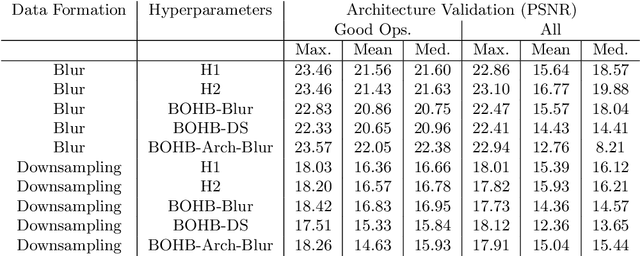
Differentiable architecture search (DARTS) is a widely researched tool for neural architecture search, due to its promising results for image classification. The main benefit of DARTS is the effectiveness achieved through the weight-sharing one-shot paradigm, which allows efficient architecture search. In this work, we investigate DARTS in a systematic case study of inverse problems, which allows us to analyze these potential benefits in a controlled manner. Although we demonstrate that the success of DARTS can be extended from image classification to reconstruction, our experiments yield three fundamental difficulties in the evaluation of DARTS-based methods: First, the results show a large variance in all test cases. Second, the final performance is highly dependent on the hyperparameters of the optimizer. And third, the performance of the weight-sharing architecture used during training does not reflect the final performance of the found architecture well. Thus, we conclude the necessity to 1) report the results of any DARTS-based methods from several runs along with its underlying performance statistics, 2) show the correlation of the training and final architecture performance, and 3) carefully consider if the computational efficiency of DARTS outweighs the costs of hyperparameter optimization and multiple runs.
Developmental Stage Classification of Embryos Using Two-Stream Neural Network with Linear-Chain Conditional Random Field
Jul 13, 2021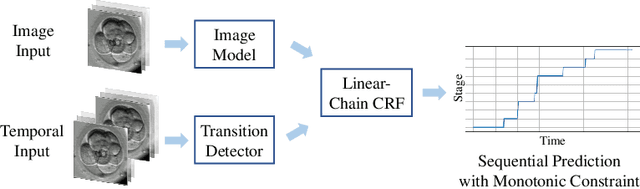
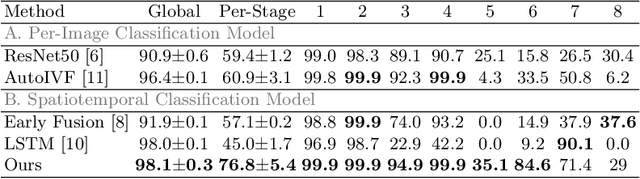

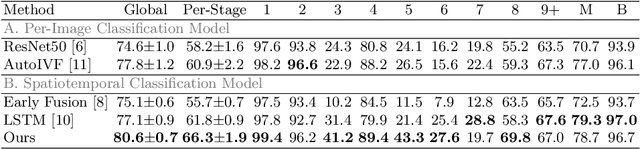
The developmental process of embryos follows a monotonic order. An embryo can progressively cleave from one cell to multiple cells and finally transform to morula and blastocyst. For time-lapse videos of embryos, most existing developmental stage classification methods conduct per-frame predictions using an image frame at each time step. However, classification using only images suffers from overlapping between cells and imbalance between stages. Temporal information can be valuable in addressing this problem by capturing movements between neighboring frames. In this work, we propose a two-stream model for developmental stage classification. Unlike previous methods, our two-stream model accepts both temporal and image information. We develop a linear-chain conditional random field (CRF) on top of neural network features extracted from the temporal and image streams to make use of both modalities. The linear-chain CRF formulation enables tractable training of global sequential models over multiple frames while also making it possible to inject monotonic development order constraints into the learning process explicitly. We demonstrate our algorithm on two time-lapse embryo video datasets: i) mouse and ii) human embryo datasets. Our method achieves 98.1 % and 80.6 % for mouse and human embryo stage classification, respectively. Our approach will enable more profound clinical and biological studies and suggests a new direction for developmental stage classification by utilizing temporal information.
Graphhopper: Multi-Hop Scene Graph Reasoning for Visual Question Answering
Jul 13, 2021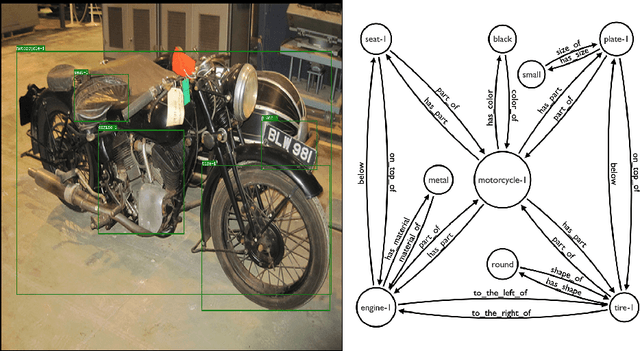
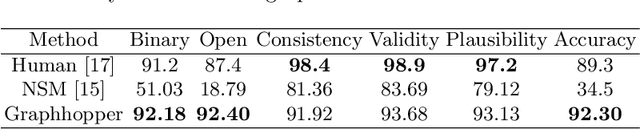
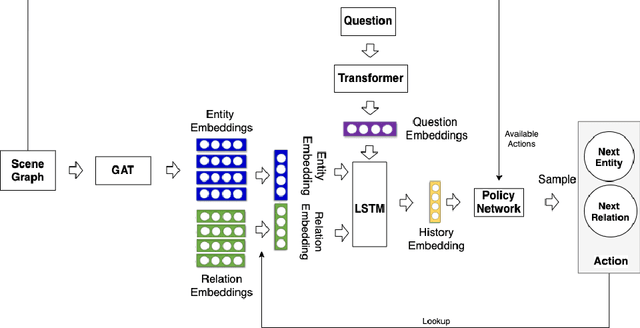

Visual Question Answering (VQA) is concerned with answering free-form questions about an image. Since it requires a deep semantic and linguistic understanding of the question and the ability to associate it with various objects that are present in the image, it is an ambitious task and requires multi-modal reasoning from both computer vision and natural language processing. We propose Graphhopper, a novel method that approaches the task by integrating knowledge graph reasoning, computer vision, and natural language processing techniques. Concretely, our method is based on performing context-driven, sequential reasoning based on the scene entities and their semantic and spatial relationships. As a first step, we derive a scene graph that describes the objects in the image, as well as their attributes and their mutual relationships. Subsequently, a reinforcement learning agent is trained to autonomously navigate in a multi-hop manner over the extracted scene graph to generate reasoning paths, which are the basis for deriving answers. We conduct an experimental study on the challenging dataset GQA, based on both manually curated and automatically generated scene graphs. Our results show that we keep up with a human performance on manually curated scene graphs. Moreover, we find that Graphhopper outperforms another state-of-the-art scene graph reasoning model on both manually curated and automatically generated scene graphs by a significant margin.
Homotopic Gradients of Generative Density Priors for MR Image Reconstruction
Aug 14, 2020
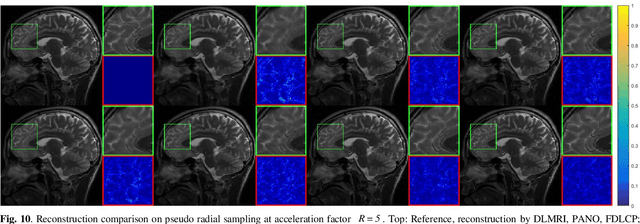
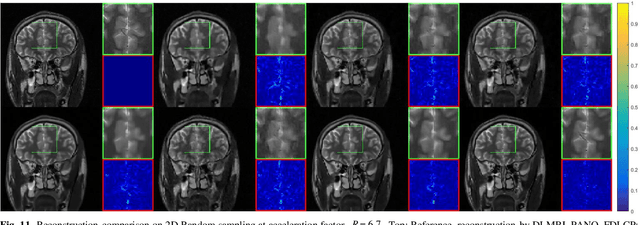
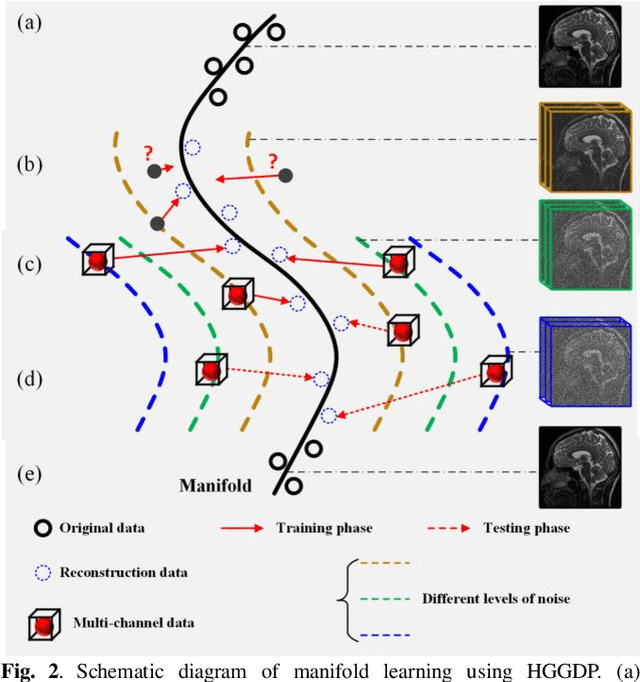
Deep learning, particularly the generative model, has demonstrated tremendous potential to significantly speed up image reconstruction with reduced measurements recently. Rather than the existing generative models that often optimize the density priors, in this work, by taking advantage of the denoising score matching, homotopic gradients of generative density priors (HGGDP) are proposed for magnetic resonance imaging (MRI) reconstruction. More precisely, to tackle the low-dimensional manifold and low data density region issues in generative density prior, we estimate the target gradients in higher-dimensional space. We train a more powerful noise conditional score network by forming high-dimensional tensor as the network input at the training phase. More artificial noise is also injected in the embedding space. At the reconstruction stage, a homotopy method is employed to pursue the density prior, such as to boost the reconstruction performance. Experiment results imply the remarkable performance of HGGDP in terms of high reconstruction accuracy; only 10% of the k-space data can still generate images of high quality as effectively as standard MRI reconstruction with the fully sampled data.
Feature Forwarding for Efficient Single Image Dehazing
May 03, 2019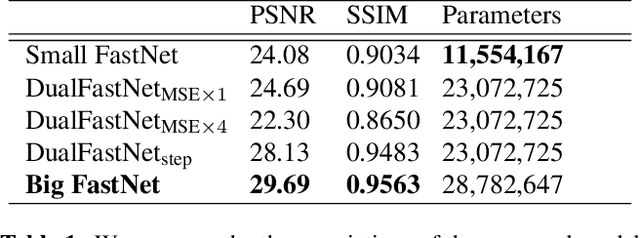
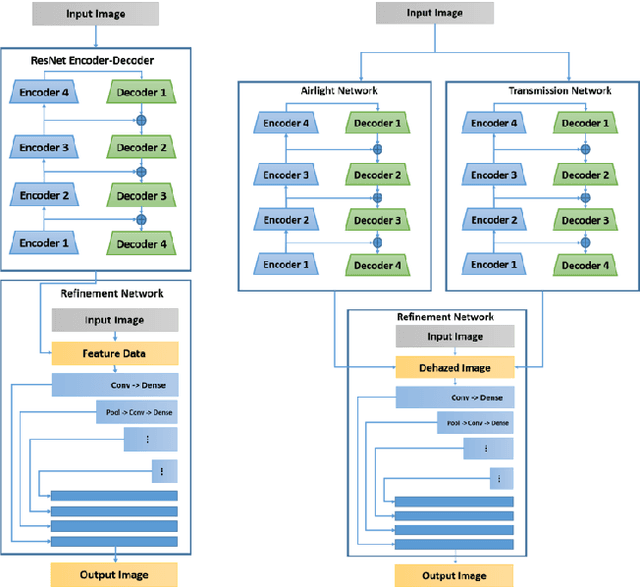
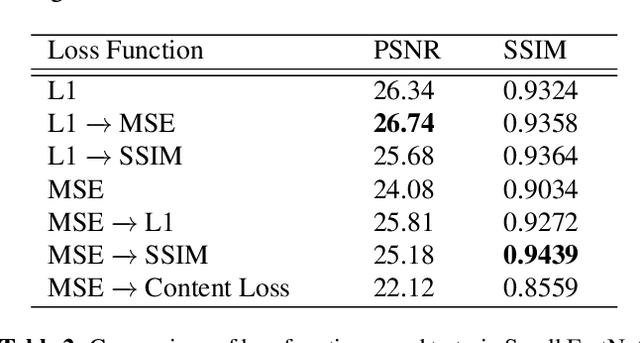
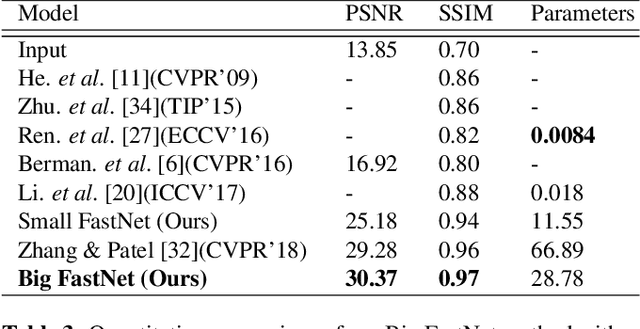
Haze degrades content and obscures information of images, which can negatively impact vision-based decision-making in real-time systems. In this paper, we propose an efficient fully convolutional neural network (CNN) image dehazing method designed to run on edge graphical processing units (GPUs). We utilize three variants of our architecture to explore the dependency of dehazed image quality on parameter count and model design. The first two variants presented, a small and big version, make use of a single efficient encoder-decoder convolutional feature extractor. The final variant utilizes a pair of encoder-decoders for atmospheric light and transmission map estimation. Each variant ends with an image refinement pyramid pooling network to form the final dehazed image. For the big variant of the single-encoder network, we demonstrate state-of-the-art performance on the NYU Depth dataset. For the small variant, we maintain competitive performance on the super-resolution O/I-HAZE datasets without the need for image cropping. Finally, we examine some challenges presented by the Dense-Haze dataset when leveraging CNN architectures for dehazing of dense haze imagery and examine the impact of loss function selection on image quality. Benchmarks are included to show the feasibility of introducing this approach into real-time systems.
High-Resolution Depth Maps Based on TOF-Stereo Fusion
Jul 30, 2021

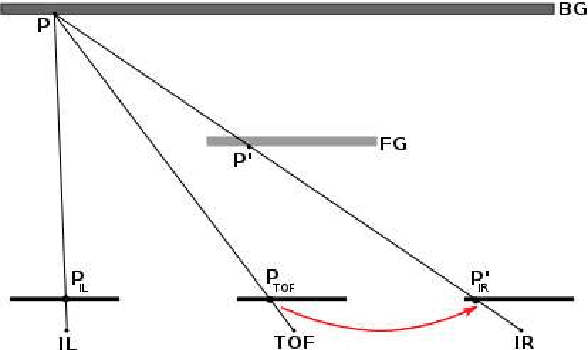

The combination of range sensors with color cameras can be very useful for robot navigation, semantic perception, manipulation, and telepresence. Several methods of combining range- and color-data have been investigated and successfully used in various robotic applications. Most of these systems suffer from the problems of noise in the range-data and resolution mismatch between the range sensor and the color cameras, since the resolution of current range sensors is much less than the resolution of color cameras. High-resolution depth maps can be obtained using stereo matching, but this often fails to construct accurate depth maps of weakly/repetitively textured scenes, or if the scene exhibits complex self-occlusions. Range sensors provide coarse depth information regardless of presence/absence of texture. The use of a calibrated system, composed of a time-of-flight (TOF) camera and of a stereoscopic camera pair, allows data fusion thus overcoming the weaknesses of both individual sensors. We propose a novel TOF-stereo fusion method based on an efficient seed-growing algorithm which uses the TOF data projected onto the stereo image pair as an initial set of correspondences. These initial "seeds" are then propagated based on a Bayesian model which combines an image similarity score with rough depth priors computed from the low-resolution range data. The overall result is a dense and accurate depth map at the resolution of the color cameras at hand. We show that the proposed algorithm outperforms 2D image-based stereo algorithms and that the results are of higher resolution than off-the-shelf color-range sensors, e.g., Kinect. Moreover, the algorithm potentially exhibits real-time performance on a single CPU.