 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PatchNet: Unsupervised Object Discovery based on Patch Embedding
Jun 16, 2021
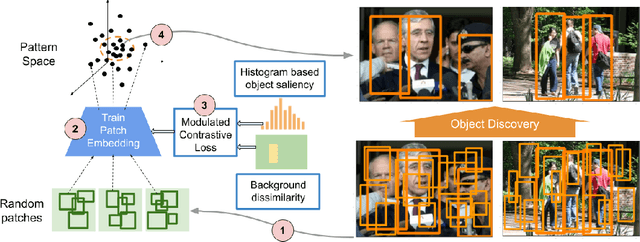
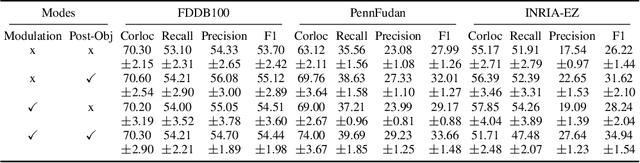
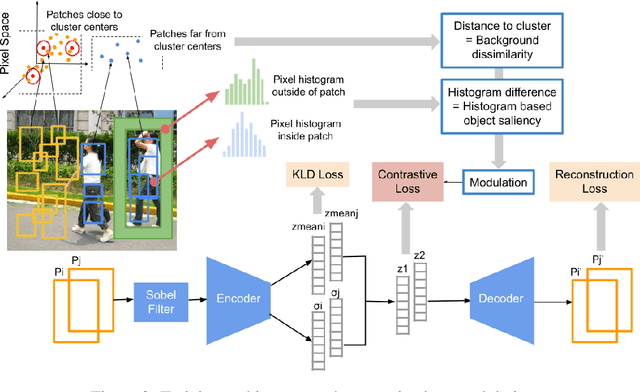
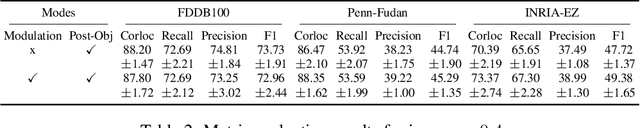
We demonstrate that frequently appearing objects can be discovered by training randomly sampled patches from a small number of images (100 to 200) by self-supervision. Key to this approach is the pattern space, a latent space of patterns that represents all possible sub-images of the given image data. The distance structure in the pattern space captures the co-occurrence of patterns due to the frequent objects. The pattern space embedding is learned by minimizing the contrastive loss between randomly generated adjacent patches. To prevent the embedding from learning the background, we modulate the contrastive loss by color-based object saliency and background dissimilarity. The learned distance structure serves as object memory, and the frequent objects are simply discovered by clustering the pattern vectors from the random patches sampled for inference. Our image representation based on image patches naturally handles the position and scale invariance property that is crucial to multi-object discovery. The method has been proven surprisingly effective, and successfully applied to finding multiple human faces and bodies from natural images.
Intermediate Layers Matter in Momentum Contrastive Self Supervised Learning
Oct 27, 2021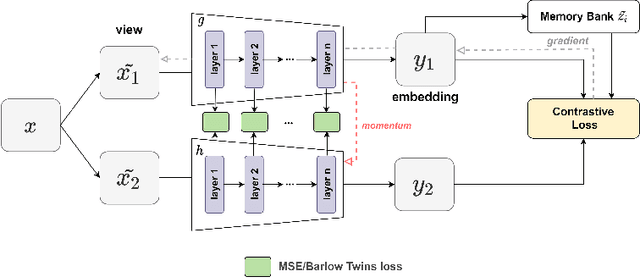
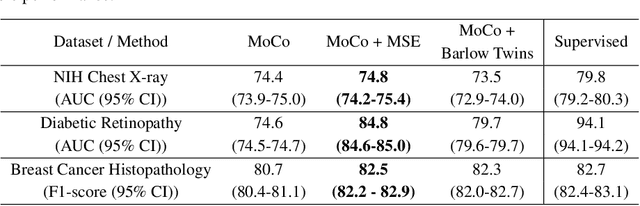
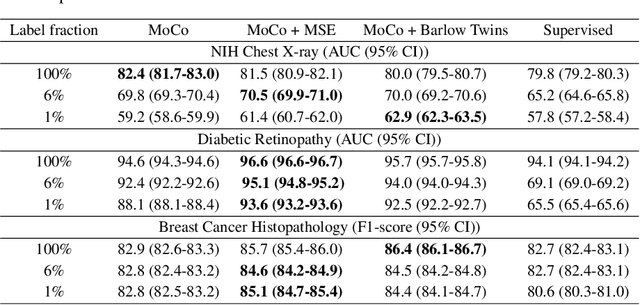
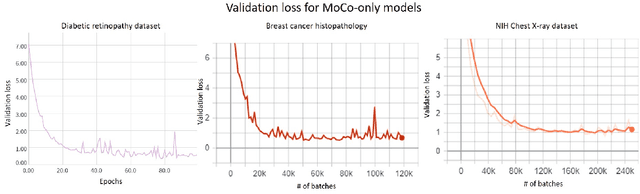
We show that bringing intermediate layers' representations of two augmented versions of an image closer together in self-supervised learning helps to improve the momentum contrastive (MoCo) method. To this end, in addition to the contrastive loss, we minimize the mean squared error between the intermediate layer representations or make their cross-correlation matrix closer to an identity matrix. Both loss objectives either outperform standard MoCo, or achieve similar performances on three diverse medical imaging datasets: NIH-Chest Xrays, Breast Cancer Histopathology, and Diabetic Retinopathy. The gains of the improved MoCo are especially large in a low-labeled data regime (e.g. 1% labeled data) with an average gain of 5% across three datasets. We analyze the models trained using our novel approach via feature similarity analysis and layer-wise probing. Our analysis reveals that models trained via our approach have higher feature reuse compared to a standard MoCo and learn informative features earlier in the network. Finally, by comparing the output probability distribution of models fine-tuned on small versus large labeled data, we conclude that our proposed method of pre-training leads to lower Kolmogorov-Smirnov distance, as compared to a standard MoCo. This provides additional evidence that our proposed method learns more informative features in the pre-training phase which could be leveraged in a low-labeled data regime.
Improvements in Micro-CT Method for Characterizing X-ray Monocapillary Optics
Jun 28, 2021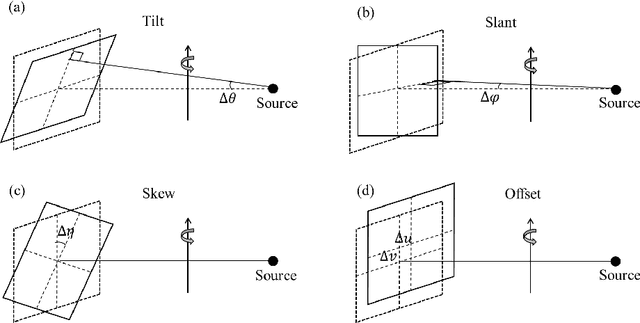
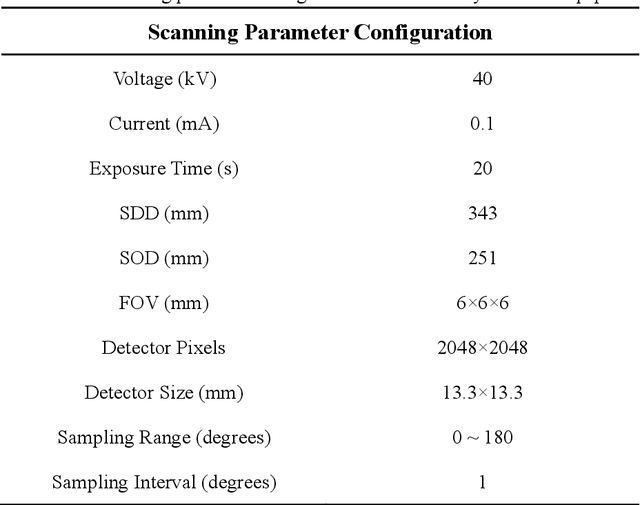
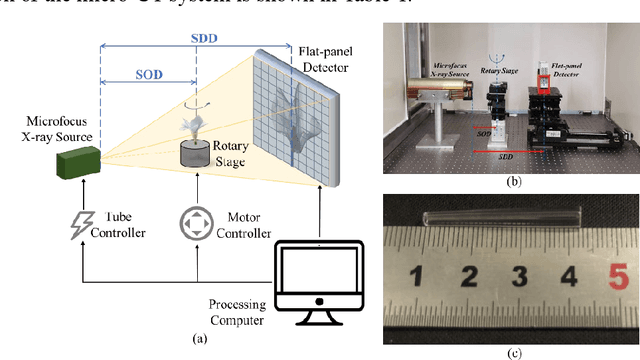

Accurate characterization of the inner surface of X-ray monocapillary optics (XMCO) is of great significance in X-ray optics research. Compared with other characterization methods, the micro computed tomography (micro-CT) method has its unique advantages but also has some disadvantages, such as a long scanning time, long image reconstruction time, and inconvenient scanning process. In this paper, sparse sampling was proposed to shorten the scanning time, GPU acceleration technology was used to improve the speed of image reconstruction, and a simple geometric calibration algorithm was proposed to avoid the calibration phantom and simplify the scanning process. These methodologies will popularize the use of the micro-CT method in XMCO characterization.
Who's Afraid of Adversarial Queries? The Impact of Image Modifications on Content-based Image Retrieval
Jan 29, 2019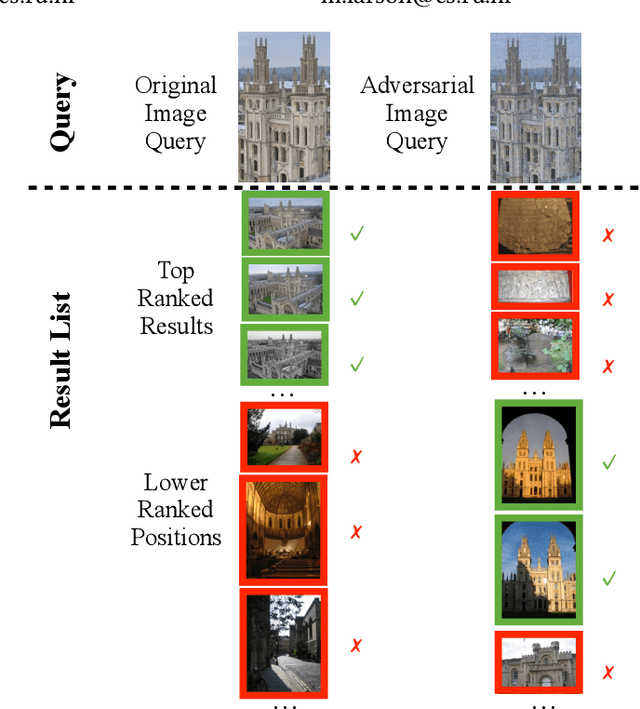
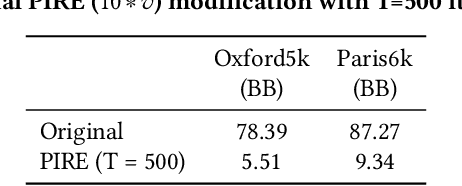
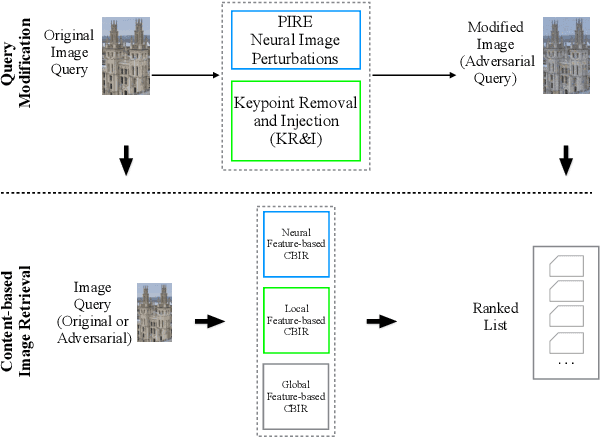
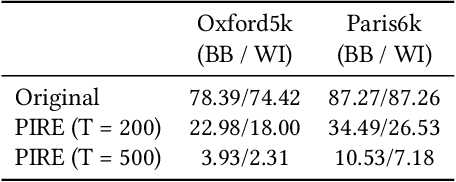
An adversarial query is an image that has been modified to disrupt content-based image retrieval (CBIR), while appearing nearly untouched to the human eye. This paper presents an analysis of adversarial queries for CBIR based on neural, local, and global features. We introduce an innovative neural image perturbation approach, called Perturbations for Image Retrieval Error (PIRE), that is capable of blocking neural-feature-based CBIR. To our knowledge PIRE is the first approach to creating neural adversarial examples for CBIR. PIRE differs significantly from existing approaches that create images adversarial with respect to CNN classifiers because it is unsupervised, i.e., it needs no labeled data from the data set to which it is applied. Our experimental analysis demonstrates the surprising effectiveness of PIRE in blocking CBIR, and also covers aspects of PIRE that must be taken into account in practical settings: saving images, image quality, image editing, and leaking adversarial queries into the background collection. Our experiments also compare PIRE (a neural approach) with existing keypoint removal and injection approaches (which modify local features). Finally, we discuss the challenges that face multimedia researchers in the future study of adversarial queries.
Image-Guided Depth Sampling and Reconstruction
Aug 04, 2019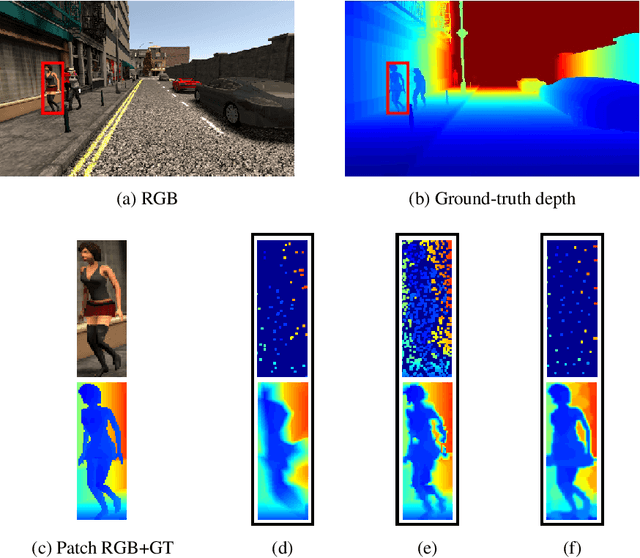
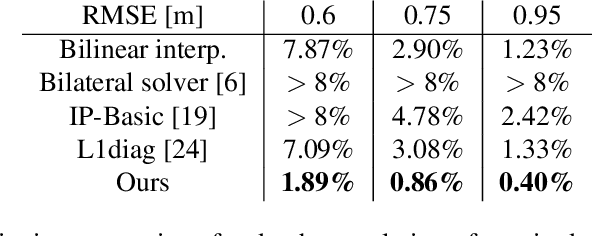
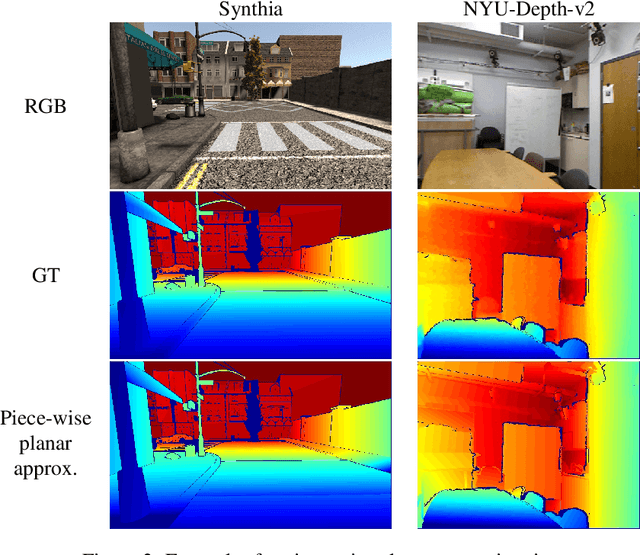
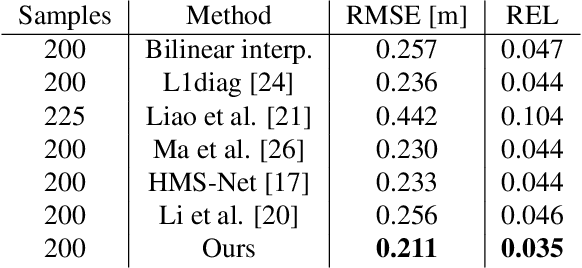
Depth acquisition, based on active illumination, is essential for autonomous and robotic navigation. LiDARs (Light Detection And Ranging) with mechanical, fixed, sampling templates are commonly used in today's autonomous vehicles. An emerging technology, based on solid-state depth sensors, with no mechanical parts, allows fast, adaptive, programmable scans. In this paper, we investigate the topic of adaptive, image-driven, sampling and reconstruction strategies. First, we formulate a piece-wise linear depth model with several tolerance parameters and estimate its validity for indoor and outdoor scenes. Our model and experiments predict that, in the optimal case, about 20-60 piece-wise linear structures can approximate well a depth map. This translates to a depth-to-image sampling ratio of about 1/1200. We propose a simple, generic, sampling and reconstruction algorithm, based on super-pixels. We reach a sampling rate which is still far from the optimal case. However, our sampling improves grid and random sampling, consistently, for a wide variety of reconstruction methods. Moreover, our proposed reconstruction achieves state-of-the-art results, compared to image-guided depth completion algorithms, reducing the required sampling rate by a factor of 3-4. A single-pixel depth camera built in our lab illustrates the concept.
Cell Detection from Imperfect Annotation by Pseudo Label Selection Using P-classification
Jul 20, 2021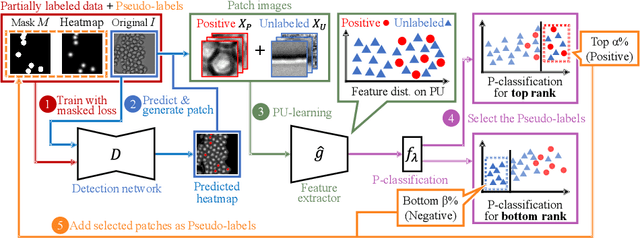
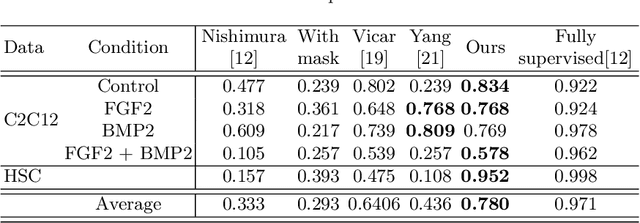
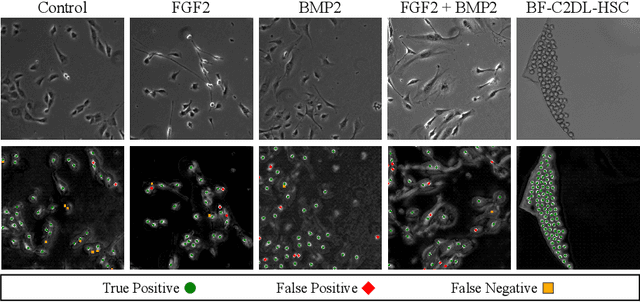
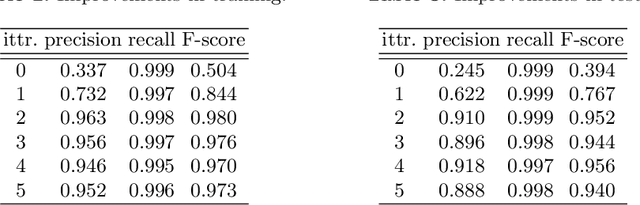
Cell detection is an essential task in cell image analysis. Recent deep learning-based detection methods have achieved very promising results. In general, these methods require exhaustively annotating the cells in an entire image. If some of the cells are not annotated (imperfect annotation), the detection performance significantly degrades due to noisy labels. This often occurs in real collaborations with biologists and even in public data-sets. Our proposed method takes a pseudo labeling approach for cell detection from imperfect annotated data. A detection convolutional neural network (CNN) trained using such missing labeled data often produces over-detection. We treat partially labeled cells as positive samples and the detected positions except for the labeled cell as unlabeled samples. Then we select reliable pseudo labels from unlabeled data using recent machine learning techniques; positive-and-unlabeled (PU) learning and P-classification. Experiments using microscopy images for five different conditions demonstrate the effectiveness of the proposed method.
Ask-n-Learn: Active Learning via Reliable Gradient Representations for Image Classification
Sep 30, 2020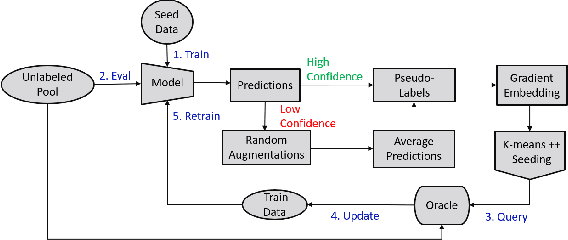
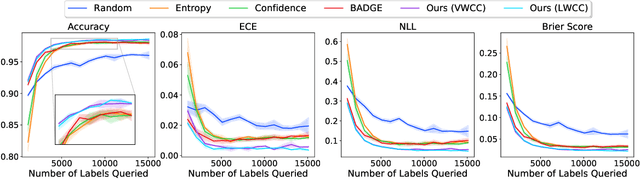
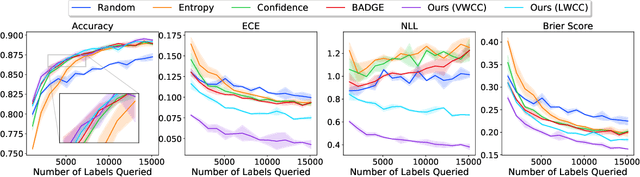
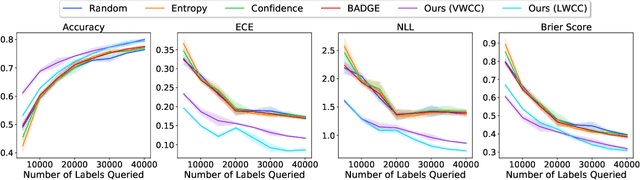
Deep predictive models rely on human supervision in the form of labeled training data. Obtaining large amounts of annotated training data can be expensive and time consuming, and this becomes a critical bottleneck while building such models in practice. In such scenarios, active learning (AL) strategies are used to achieve faster convergence in terms of labeling efforts. Existing active learning employ a variety of heuristics based on uncertainty and diversity to select query samples. Despite their wide-spread use, in practice, their performance is limited by a number of factors including non-calibrated uncertainties, insufficient trade-off between data exploration and exploitation, presence of confirmation bias etc. In order to address these challenges, we propose Ask-n-Learn, an active learning approach based on gradient embeddings obtained using the pesudo-labels estimated in each iteration of the algorithm. More importantly, we advocate the use of prediction calibration to obtain reliable gradient embeddings, and propose a data augmentation strategy to alleviate the effects of confirmation bias during pseudo-labeling. Through empirical studies on benchmark image classification tasks (CIFAR-10, SVHN, Fashion-MNIST, MNIST), we demonstrate significant improvements over state-of-the-art baselines, including the recently proposed BADGE algorithm.
A Hybrid Sparse-Dense Monocular SLAM System for Autonomous Driving
Aug 17, 2021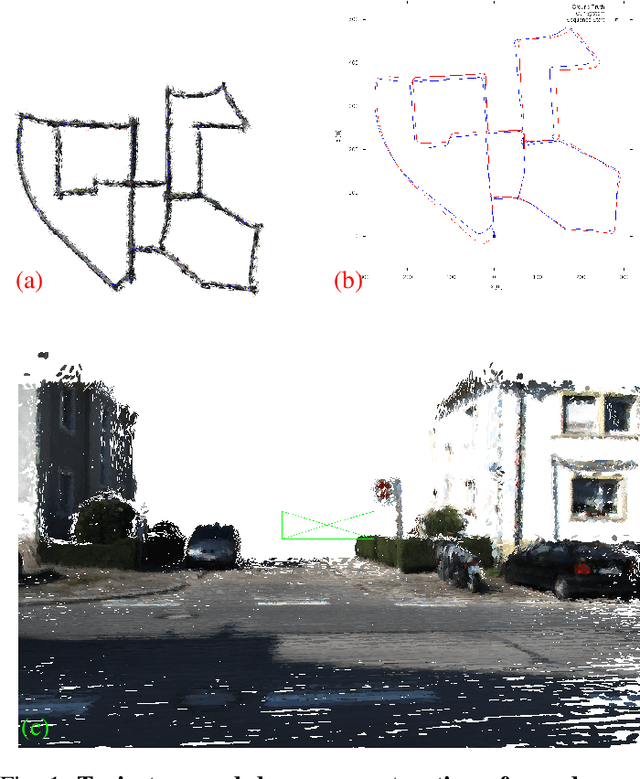
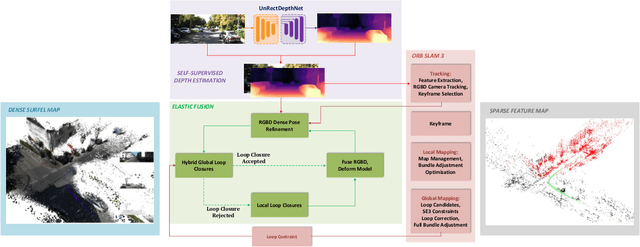

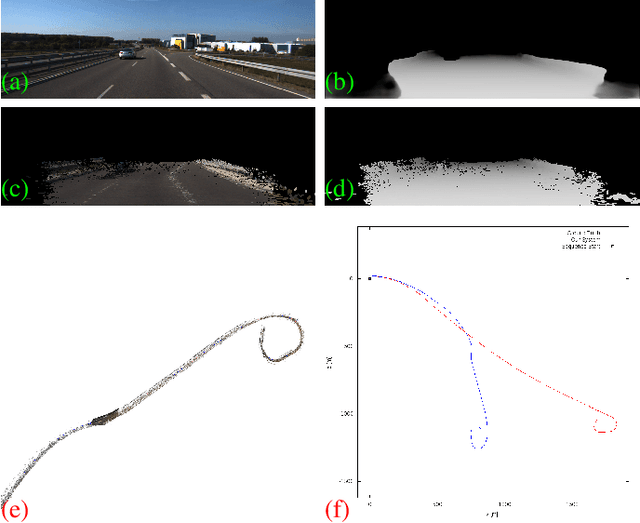
In this paper, we present a system for incrementally reconstructing a dense 3D model of the geometry of an outdoor environment using a single monocular camera attached to a moving vehicle. Dense models provide a rich representation of the environment facilitating higher-level scene understanding, perception, and planning. Our system employs dense depth prediction with a hybrid mapping architecture combining state-of-the-art sparse features and dense fusion-based visual SLAM algorithms within an integrated framework. Our novel contributions include design of hybrid sparse-dense camera tracking and loop closure, and scale estimation improvements in dense depth prediction. We use the motion estimates from the sparse method to overcome the large and variable inter-frame displacement typical of outdoor vehicle scenarios. Our system then registers the live image with the dense model using whole-image alignment. This enables the fusion of the live frame and dense depth prediction into the model. Global consistency and alignment between the sparse and dense models are achieved by applying pose constraints from the sparse method directly within the deformation of the dense model. We provide qualitative and quantitative results for both trajectory estimation and surface reconstruction accuracy, demonstrating competitive performance on the KITTI dataset. Qualitative results of the proposed approach are illustrated in https://youtu.be/Pn2uaVqjskY. Source code for the project is publicly available at the following repository https://github.com/robotvisionmu/DenseMonoSLAM.
PulseSatellite: A tool using human-AI feedback loops for satellite image analysis in humanitarian contexts
Jan 29, 2020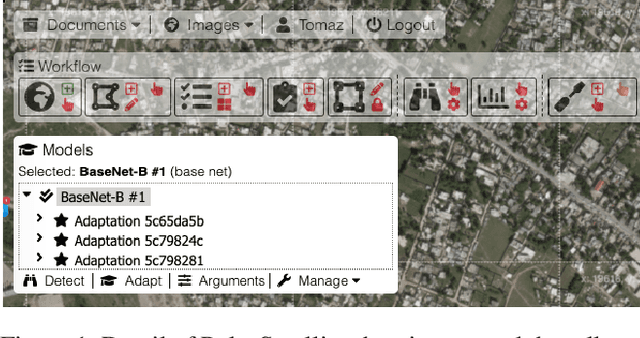

Humanitarian response to natural disasters and conflicts can be assisted by satellite image analysis. In a humanitarian context, very specific satellite image analysis tasks must be done accurately and in a timely manner to provide operational support. We present PulseSatellite, a collaborative satellite image analysis tool which leverages neural network models that can be retrained on-the fly and adapted to specific humanitarian contexts and geographies. We present two case studies, in mapping shelters and floods respectively, that illustrate the capabilities of PulseSatellite.
* 2 pages, 2 figures
PlaneTR: Structure-Guided Transformers for 3D Plane Recovery
Jul 27, 2021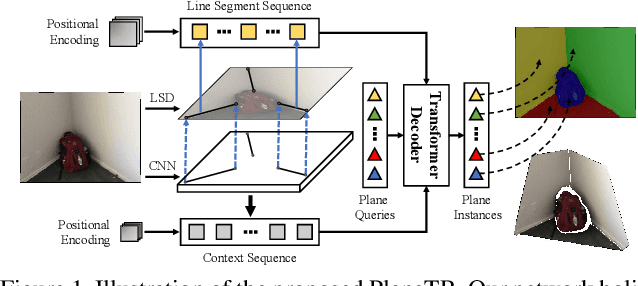
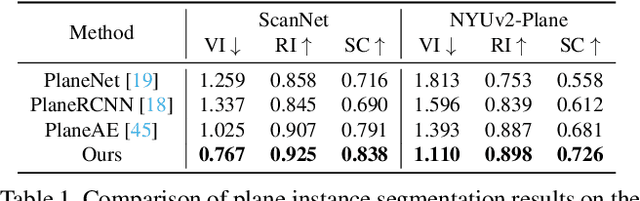
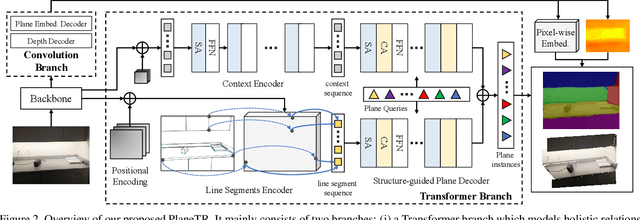
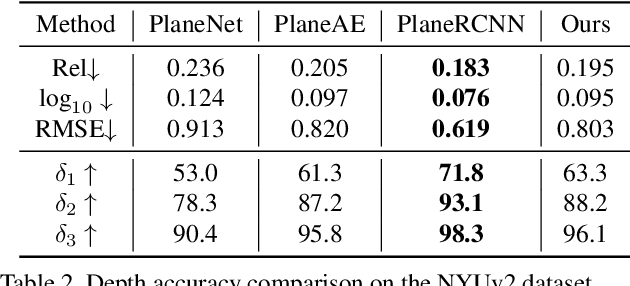
This paper presents a neural network built upon Transformers, namely PlaneTR, to simultaneously detect and reconstruct planes from a single image. Different from previous methods, PlaneTR jointly leverages the context information and the geometric structures in a sequence-to-sequence way to holistically detect plane instances in one forward pass. Specifically, we represent the geometric structures as line segments and conduct the network with three main components: (i) context and line segments encoders, (ii) a structure-guided plane decoder, (iii) a pixel-wise plane embedding decoder. Given an image and its detected line segments, PlaneTR generates the context and line segment sequences via two specially designed encoders and then feeds them into a Transformers-based decoder to directly predict a sequence of plane instances by simultaneously considering the context and global structure cues. Finally, the pixel-wise embeddings are computed to assign each pixel to one predicted plane instance which is nearest to it in embedding space. Comprehensive experiments demonstrate that PlaneTR achieves a state-of-the-art performance on the ScanNet and NYUv2 datasets.