 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Maximum likelihood estimation for disk image parameters
Jul 24, 2019
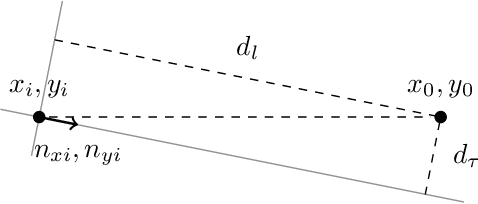
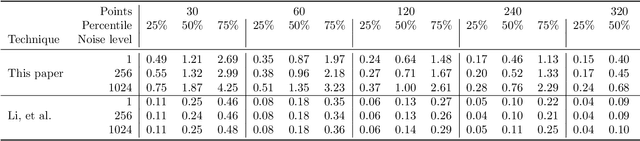
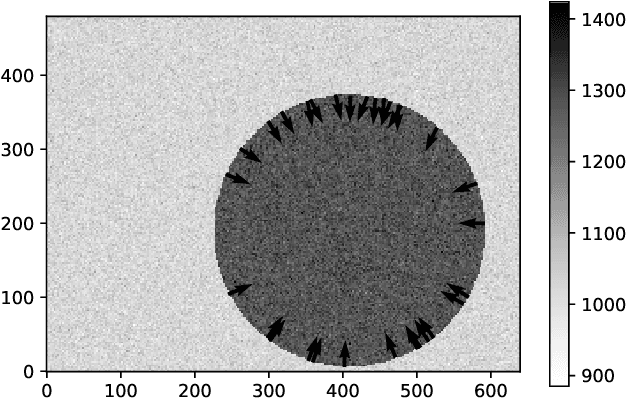
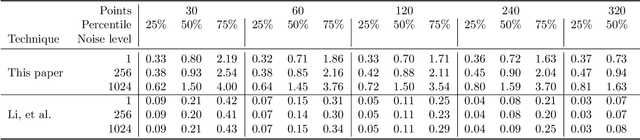
We present a novel technique for estimating disc parameters from its 2D image. It is based on the maximal likelihood approach utilising both edge coordinates and the image intensity gradients. We emphasise the following advantages of our likelihood model. It has closed-form formulae for parameter estimating, therefore requiring less computational resources than iterative algorithms. The likelihood model naturally distinguishes the outer and inner annulus edges. The proposed technique was evaluated on both synthetic and real data.
Automatic 2D-3D Registration without Contrast Agent during Neurovascular Interventions
Jun 08, 2021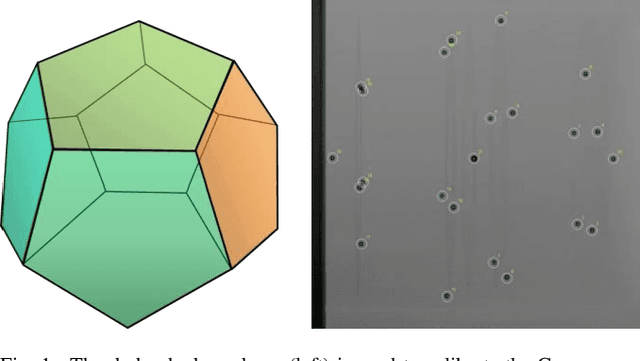
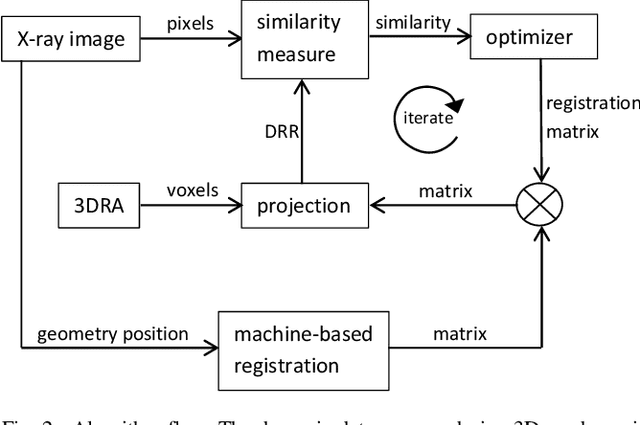
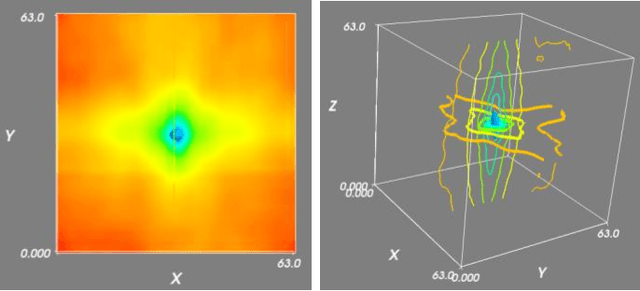
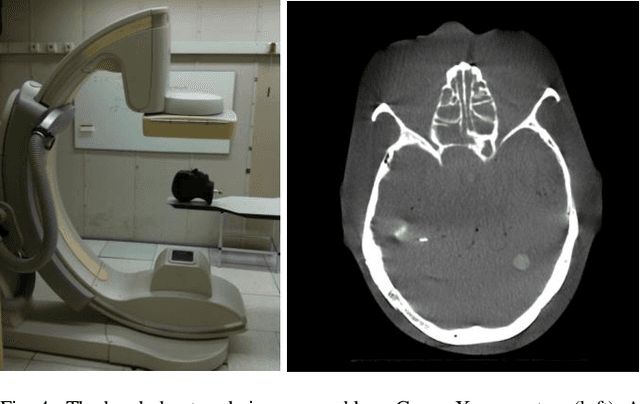
Fusing live fluoroscopy images with a 3D rotational reconstruction of the vasculature allows to navigate endovascular devices in minimally invasive neuro-vascular treatment, while reducing the usage of harmful iodine contrast medium. The alignment of the fluoroscopy images and the 3D reconstruction is initialized using the sensor information of the X-ray C-arm geometry. Patient motion is then corrected by an image-based registration algorithm, based on a gradient difference similarity measure using digital reconstructed radiographs of the 3D reconstruction. This algorithm does not require the vessels in the fluoroscopy image to be filled with iodine contrast agent, but rather relies on gradients in the image (bone structures, sinuses) as landmark features. This paper investigates the accuracy, robustness and computation time aspects of the image-based registration algorithm. Using phantom experiments 97% of the registration attempts passed the success criterion of a residual registration error of less than 1 mm translation and 3{\deg} rotation. The paper establishes a new method for validation of 2D-3D registration without requiring changes to the clinical workflow, such as attaching fiducial markers. As a consequence, this method can be retrospectively applied to pre-existing clinical data. For clinical data experiments, 87% of the registration attempts passed the criterion of a residual translational error of < 1 mm, and 84% possessed a rotational error of < 3{\deg}.
Survey on Semantic Stereo Matching / Semantic Depth Estimation
Sep 21, 2021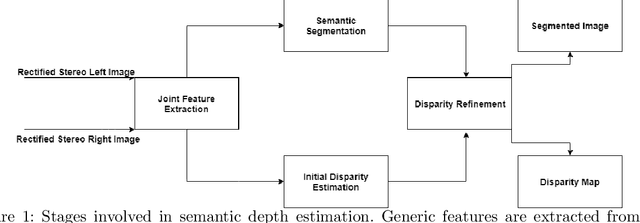
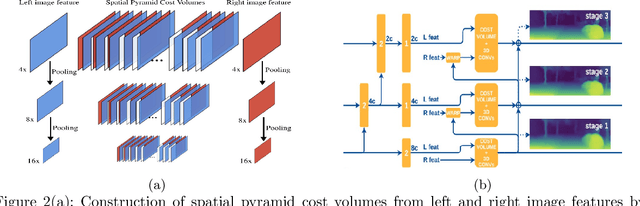

Stereo matching is one of the widely used techniques for inferring depth from stereo images owing to its robustness and speed. It has become one of the major topics of research since it finds its applications in autonomous driving, robotic navigation, 3D reconstruction, and many other fields. Finding pixel correspondences in non-textured, occluded and reflective areas is the major challenge in stereo matching. Recent developments have shown that semantic cues from image segmentation can be used to improve the results of stereo matching. Many deep neural network architectures have been proposed to leverage the advantages of semantic segmentation in stereo matching. This paper aims to give a comparison among the state of art networks both in terms of accuracy and in terms of speed which are of higher importance in real-time applications.
Uncertainty-Based Dynamic Graph Neighborhoods For Medical Segmentation
Aug 06, 2021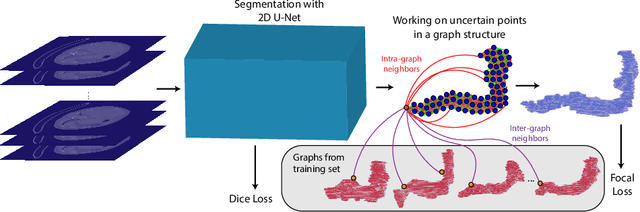
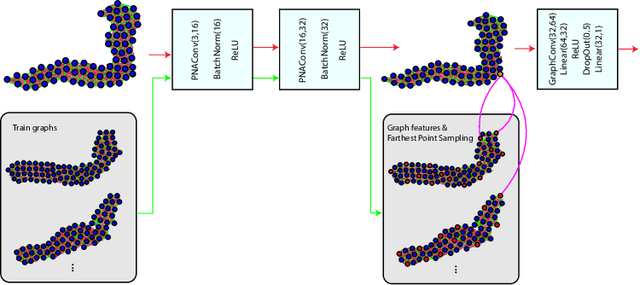

In recent years, deep learning based methods have shown success in essential medical image analysis tasks such as segmentation. Post-processing and refining the results of segmentation is a common practice to decrease the misclassifications originating from the segmentation network. In addition to widely used methods like Conditional Random Fields (CRFs) which focus on the structure of the segmented volume/area, a graph-based recent approach makes use of certain and uncertain points in a graph and refines the segmentation according to a small graph convolutional network (GCN). However, there are two drawbacks of the approach: most of the edges in the graph are assigned randomly and the GCN is trained independently from the segmentation network. To address these issues, we define a new neighbor-selection mechanism according to feature distances and combine the two networks in the training procedure. According to the experimental results on pancreas segmentation from Computed Tomography (CT) images, we demonstrate improvement in the quantitative measures. Also, examining the dynamic neighbors created by our method, edges between semantically similar image parts are observed. The proposed method also shows qualitative enhancements in the segmentation maps, as demonstrated in the visual results.
Improving Object Detection by Label Assignment Distillation
Aug 26, 2021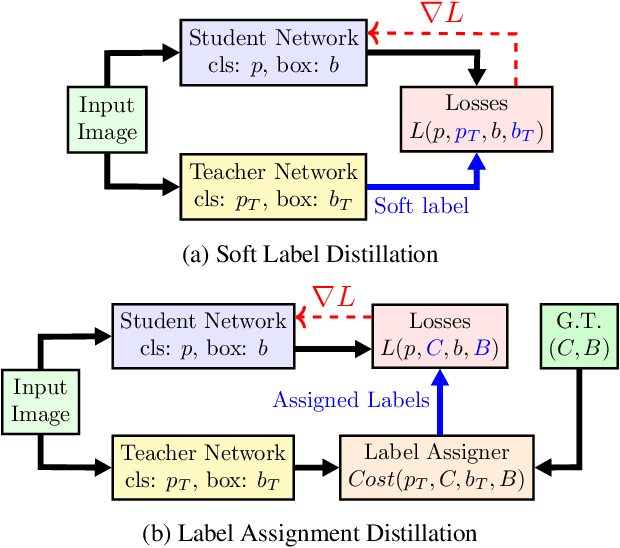
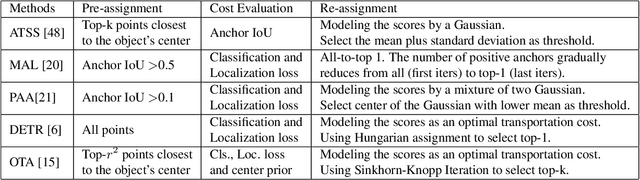
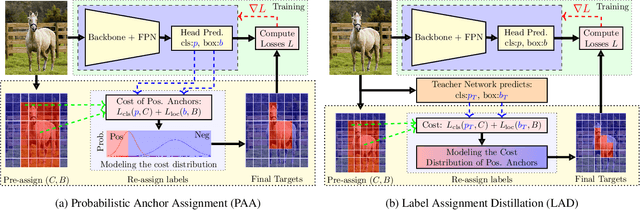
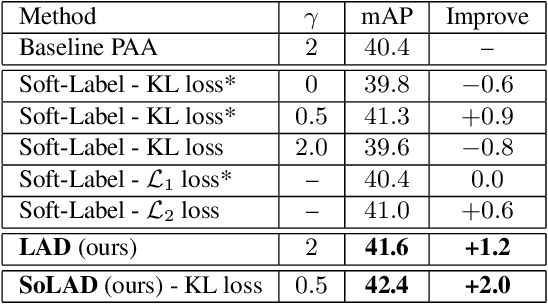
Label assignment in object detection aims to assign targets, foreground or background, to sampled regions in an image. Unlike labeling for image classification, this problem is not well defined due to the object's bounding box. In this paper, we investigate the problem from a perspective of distillation, hence we call Label Assignment Distillation (LAD). Our initial motivation is very simple, we use a teacher network to generate labels for the student. This can be achieved in two ways: either using the teacher's prediction as the direct targets (soft label), or through the hard labels dynamically assigned by the teacher (LAD). Our experiments reveal that: (i) LAD is more effective than soft-label, but they are complementary. (ii) Using LAD, a smaller teacher can also improve a larger student significantly, while soft-label can't. We then introduce Co-learning LAD, in which two networks simultaneously learn from scratch and the role of teacher and student are dynamically interchanged. Using PAA-ResNet50 as a teacher, our LAD techniques can improve detectors PAA-ResNet101 and PAA-ResNeXt101 to $46 \rm AP$ and $47.5\rm AP$ on the COCO test-dev set. With a strong teacher PAA-SwinB, we improve the PAA-ResNet50 to $43.9\rm AP$ with only \1x schedule training, and PAA-ResNet101 to $47.9\rm AP$, significantly surpassing the current methods. Our source code and checkpoints will be released at https://github.com/cybercore-co-ltd/CoLAD_paper.
Discovery-and-Selection: Towards Optimal Multiple Instance Learning for Weakly Supervised Object Detection
Oct 18, 2021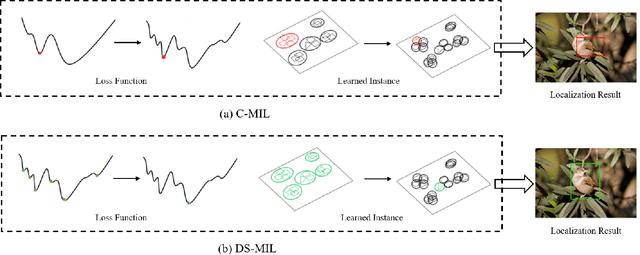
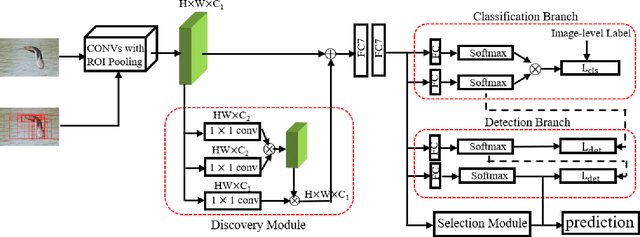
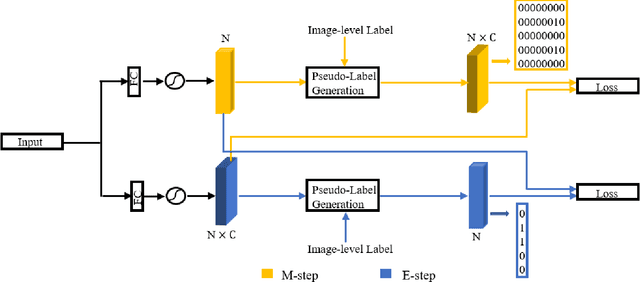

Weakly supervised object detection (WSOD) is a challenging task that requires simultaneously learn object classifiers and estimate object locations under the supervision of image category labels. A major line of WSOD methods roots in multiple instance learning which regards images as bags of instance and selects positive instances from each bag to learn the detector. However, a grand challenge emerges when the detector inclines to converge to discriminative parts of objects rather than the whole objects. In this paper, under the hypothesis that optimal solutions are included in local minima, we propose a discoveryand-selection approach fused with multiple instance learning (DS-MIL), which finds rich local minima and select optimal solutions from multiple local minima. To implement DS-MIL, an attention module is designed so that more context information can be captured by feature maps and more valuable proposals can be collected during training. With proposal candidates, a re-rank module is designed to select informative instances for object detector training. Experimental results on commonly used benchmarks show that our proposed DS-MIL approach can consistently improve the baselines, reporting state-of-the-art performance.
Deep Learning for Image Search and Retrieval in Large Remote Sensing Archives
Apr 03, 2020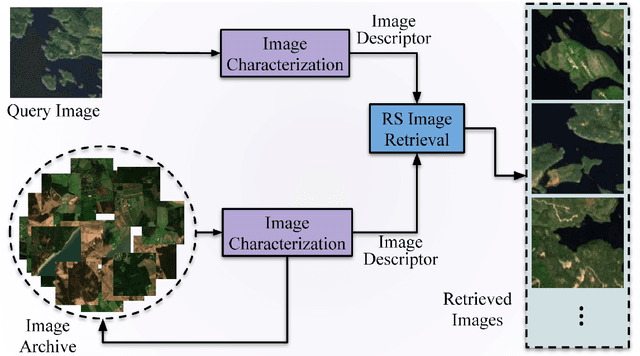
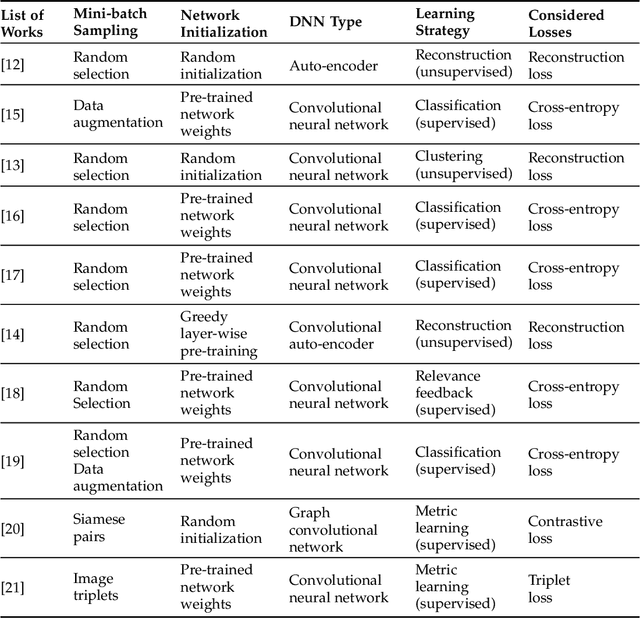
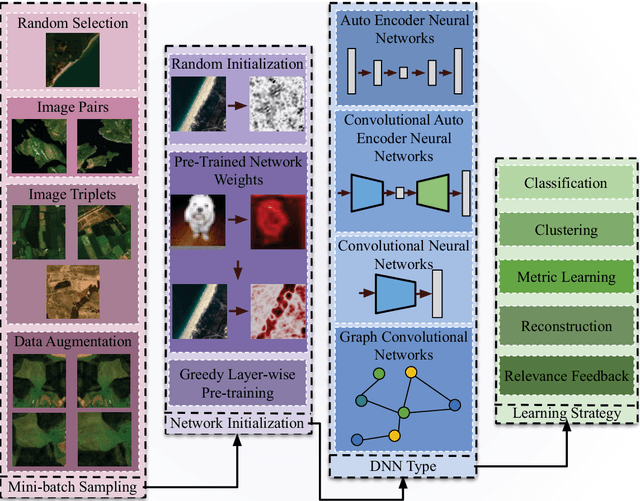
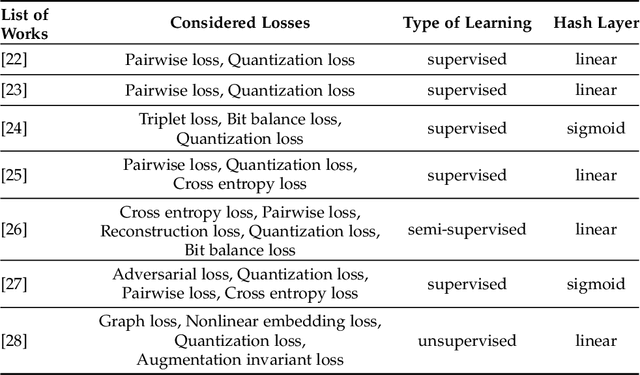
This chapter presents recent advances in content based image search and retrieval (CBIR) systems in remote sensing (RS) for fast and accurate information discovery from massive data archives. Initially, we analyze the limitations of the traditional CBIR systems that rely on the hand-crafted RS image descriptors applied to exhaustive search and retrieval problems. Then, we focus our attention on the advances in RS CBIR systems for which the deep learning (DL) models are at the forefront. In particular, we present the theoretical properties of the most recent DL based CBIR systems for the characterization of the complex semantic content of RS images. After discussing their strengths and limitations, we present the deep hashing based CBIR systems that have high time-efficient search capability within huge data archives. Finally, the most promising research directions in RS CBIR are discussed.
Progressive Coordinate Transforms for Monocular 3D Object Detection
Aug 13, 2021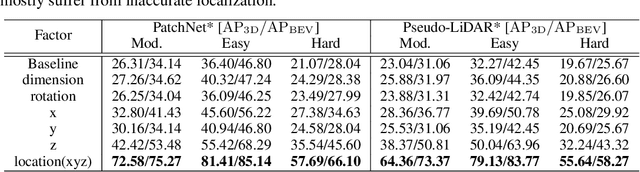

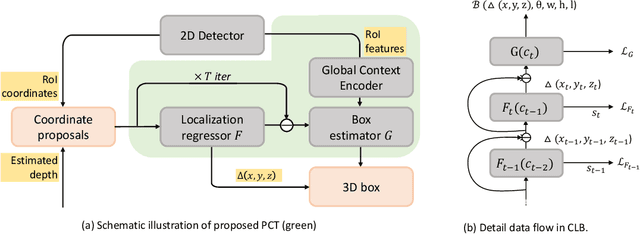
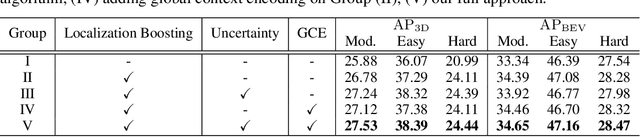
Recognizing and localizing objects in the 3D space is a crucial ability for an AI agent to perceive its surrounding environment. While significant progress has been achieved with expensive LiDAR point clouds, it poses a great challenge for 3D object detection given only a monocular image. While there exist different alternatives for tackling this problem, it is found that they are either equipped with heavy networks to fuse RGB and depth information or empirically ineffective to process millions of pseudo-LiDAR points. With in-depth examination, we realize that these limitations are rooted in inaccurate object localization. In this paper, we propose a novel and lightweight approach, dubbed {\em Progressive Coordinate Transforms} (PCT) to facilitate learning coordinate representations. Specifically, a localization boosting mechanism with confidence-aware loss is introduced to progressively refine the localization prediction. In addition, semantic image representation is also exploited to compensate for the usage of patch proposals. Despite being lightweight and simple, our strategy leads to superior improvements on the KITTI and Waymo Open Dataset monocular 3D detection benchmarks. At the same time, our proposed PCT shows great generalization to most coordinate-based 3D detection frameworks. The code is available at: https://github.com/amazon-research/progressive-coordinate-transforms .
NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
Oct 18, 2021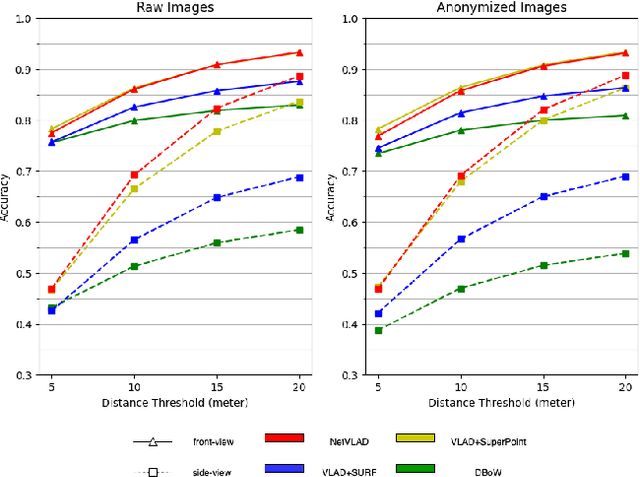
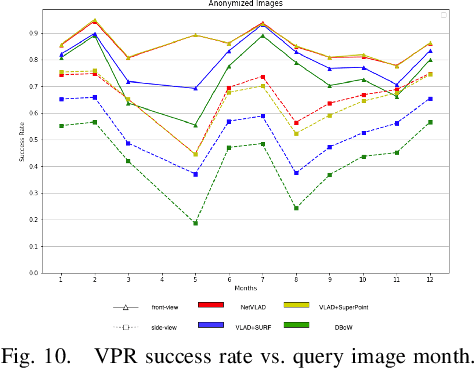
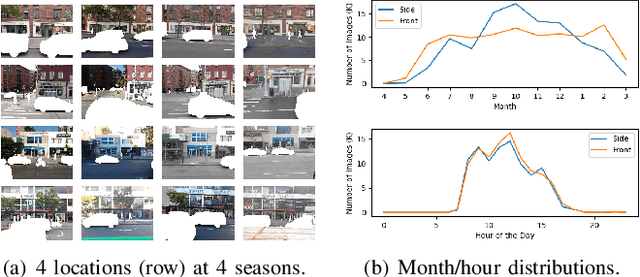

Visual place recognition (VPR) is critical in not only localization and mapping for autonomous driving vehicles, but also assistive navigation for the visually impaired population. To enable a long-term VPR system on a large scale, several challenges need to be addressed. First, different applications could require different image view directions, such as front views for self-driving cars while side views for the low vision people. Second, VPR in metropolitan scenes can often cause privacy concerns due to the imaging of pedestrian and vehicle identity information, calling for the need for data anonymization before VPR queries and database construction. Both factors could lead to VPR performance variations that are not well understood yet. To study their influences, we present the NYU-VPR dataset that contains more than 200,000 images over a 2km by 2km area near the New York University campus, taken within the whole year of 2016. We present benchmark results on several popular VPR algorithms showing that side views are significantly more challenging for current VPR methods while the influence of data anonymization is almost negligible, together with our hypothetical explanations and in-depth analysis.
Compressive Sensing Based Adaptive Defence Against Adversarial Images
Oct 11, 2021
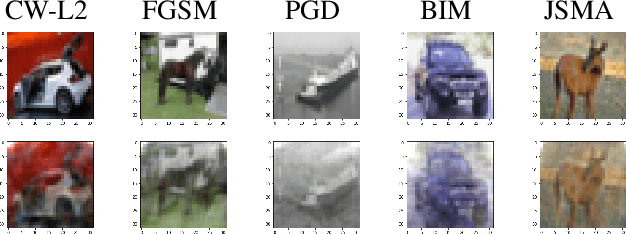
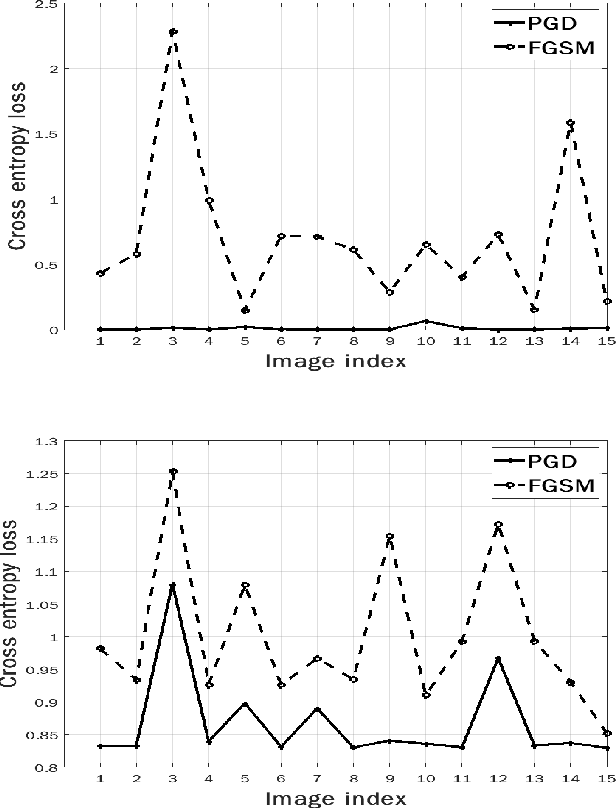
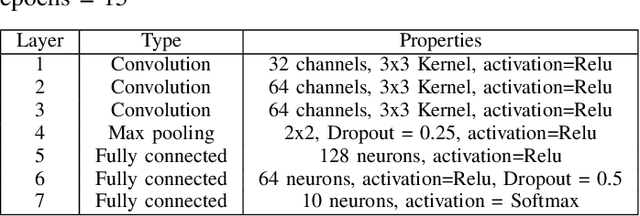
Herein, security of deep neural network against adversarial attack is considered. Existing compressive sensing based defence schemes assume that adversarial perturbations are usually on high frequency components, whereas recently it has been shown that low frequency perturbations are more effective. This paper proposes a novel Compressive sensing based Adaptive Defence (CAD) algorithm which combats distortion in frequency domain instead of time domain. Unlike existing literature, the proposed CAD algorithm does not use information about the type of attack such as l0, l2, l-infinity etc. CAD algorithm uses exponential weight algorithm for exploration and exploitation to identify the type of attack, compressive sampling matching pursuit (CoSaMP) to recover the coefficients in spectral domain, and modified basis pursuit using a novel constraint for l0, l-infinity norm attack. Tight performance bounds for various recovery schemes meant for various attack types are also provided. Experimental results against five state-of-the-art white box attacks on MNIST and CIFAR-10 show that the proposed CAD algorithm achieves excellent classification accuracy and generates good quality reconstructed image with much lower computation