 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Distance Transform and its Computation
Jun 07, 2021
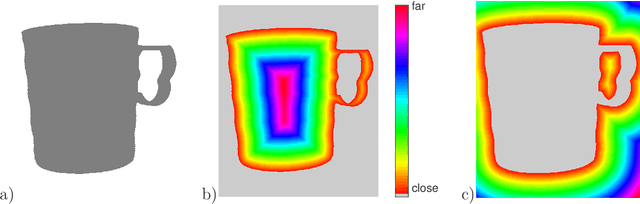



Distance transformation is an image processing technique used for many different applications. Related to a binary image, the general idea is to determine the distance of all background points to the nearest object point (or vice versa). In this tutorial, different approaches are explained in detail and compared using examples. Corresponding source code is provided to facilitate own investigations. A particular objective of this tutorial is to clarify the difference between arbitrary distance transforms and exact Euclidean distance transformations.
Dual Reconstruction with Densely Connected Residual Network for Single Image Super-Resolution
Nov 20, 2019
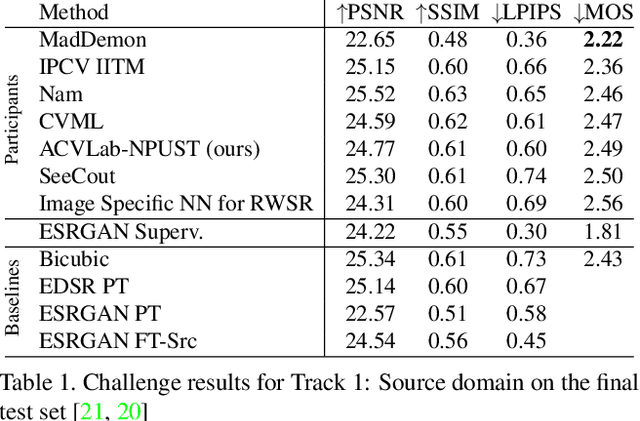
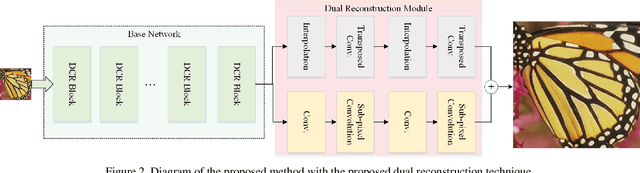
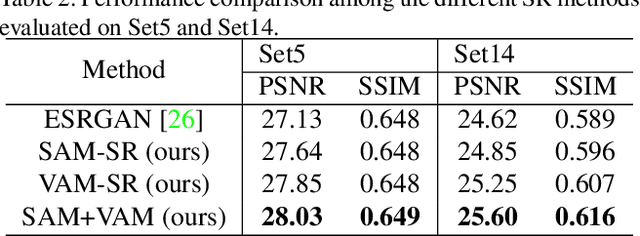
Deep learning-based single image super-resolution enables very fast and high-visual-quality reconstruction. Recently, an enhanced super-resolution based on generative adversarial network (ESRGAN) has achieved excellent performance in terms of both qualitative and quantitative quality of the reconstructed high-resolution image. In this paper, we propose to add one more shortcut between two dense-blocks, as well as add shortcut between two convolution layers inside a dense-block. With this simple strategy of adding more shortcuts in the proposed network, it enables a faster learning process as the gradient information can be back-propagated more easily. Based on the improved ESRGAN, the dual reconstruction is proposed to learn different aspects of the super-resolved image for judiciously enhancing the quality of the reconstructed image. In practice, the super-resolution model is pre-trained solely based on pixel distance, followed by fine-tuning the parameters in the model based on adversarial loss and perceptual loss. Finally, we fuse two different models by weighted-summing their parameters to obtain the final super-resolution model. Experimental results demonstrated that the proposed method achieves excellent performance in the real-world image super-resolution challenge. We have also verified that the proposed dual reconstruction does further improve the quality of the reconstructed image in terms of both PSNR and SSIM.
Who's Afraid of Adversarial Queries? The Impact of Image Modifications on Content-based Image Retrieval
Feb 04, 2019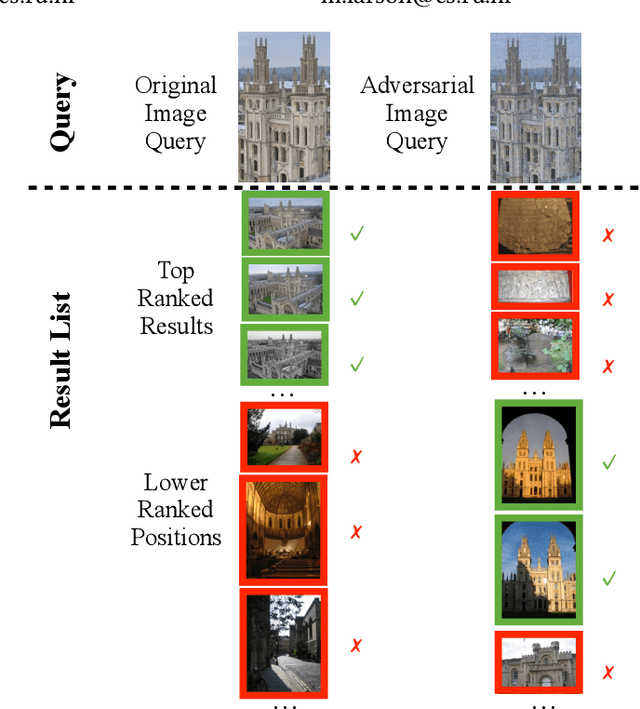
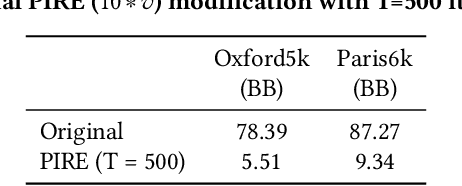
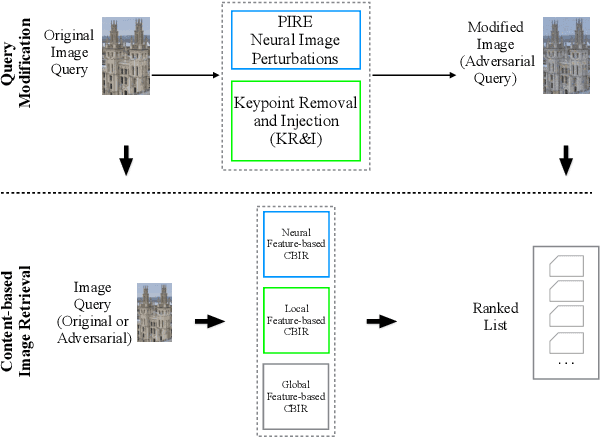
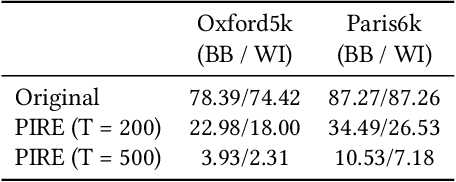
An adversarial query is an image that has been modified to disrupt content-based image retrieval (CBIR), while appearing nearly untouched to the human eye. This paper presents an analysis of adversarial queries for CBIR based on neural, local, and global features. We introduce an innovative neural image perturbation approach, called Perturbations for Image Retrieval Error (PIRE), that is capable of blocking neural-feature-based CBIR. To our knowledge PIRE is the first approach to creating neural adversarial examples for CBIR. PIRE differs significantly from existing approaches that create images adversarial with respect to CNN classifiers because it is unsupervised, i.e., it needs no labeled data from the data set to which it is applied. Our experimental analysis demonstrates the surprising effectiveness of PIRE in blocking CBIR, and also covers aspects of PIRE that must be taken into account in practical settings: saving images, image quality, image editing, and leaking adversarial queries into the background collection. Our experiments also compare PIRE (a neural approach) with existing keypoint removal and injection approaches (which modify local features). Finally, we discuss the challenges that face multimedia researchers in the future study of adversarial queries.
Bilinear pooling and metric learning network for early Alzheimer's disease identification with FDG-PET images
Nov 09, 2021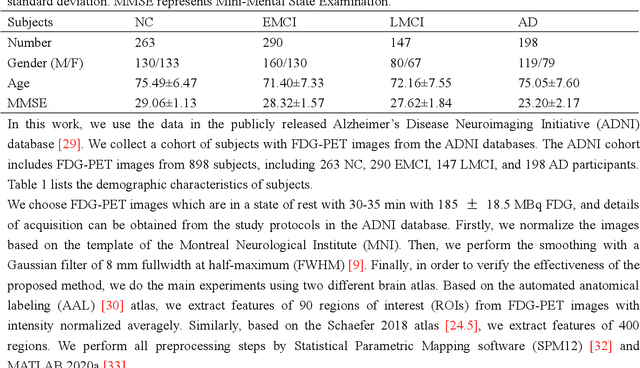
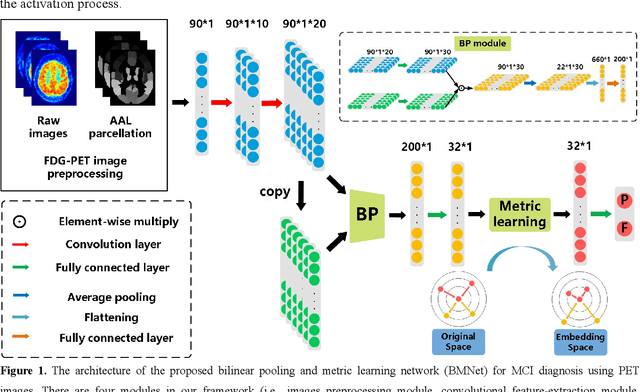
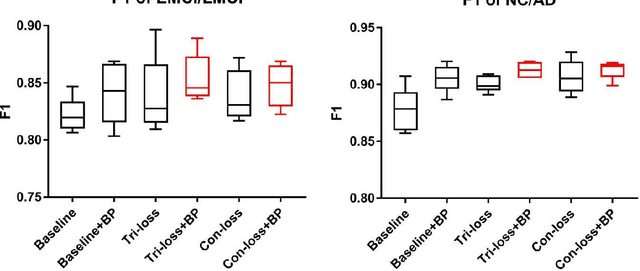
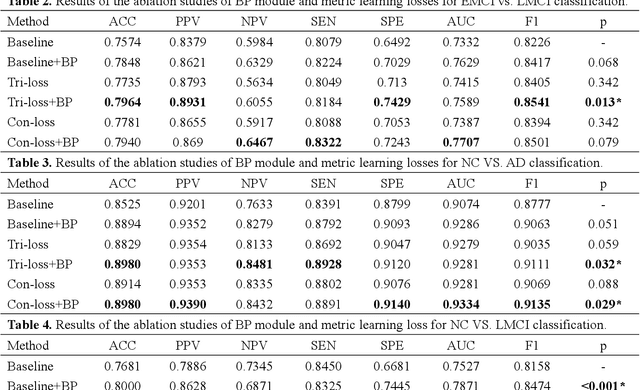
FDG-PET reveals altered brain metabolism in individuals with mild cognitive impairment (MCI) and Alzheimer's disease (AD). Some biomarkers derived from FDG-PET by computer-aided-diagnosis (CAD) technologies have been proved that they can accurately diagnosis normal control (NC), MCI, and AD. However, the studies of identification of early MCI (EMCI) and late MCI (LMCI) with FDG-PET images are still insufficient. Compared with studies based on fMRI and DTI images, the researches of the inter-region representation features in FDG-PET images are insufficient. Moreover, considering the variability in different individuals, some hard samples which are very similar with both two classes limit the classification performance. To tackle these problems, in this paper, we propose a novel bilinear pooling and metric learning network (BMNet), which can extract the inter-region representation features and distinguish hard samples by constructing embedding space. To validate the proposed method, we collect 998 FDG-PET images from ADNI. Following the common preprocessing steps, 90 features are extracted from each FDG-PET image according to the automatic anatomical landmark (AAL) template and then sent into the proposed network. Extensive 5-fold cross-validation experiments are performed for multiple two-class classifications. Experiments show that most metrics are improved after adding the bilinear pooling module and metric losses to the Baseline model respectively. Specifically, in the classification task between EMCI and LMCI, the specificity improves 6.38% after adding the triple metric loss, and the negative predictive value (NPV) improves 3.45% after using the bilinear pooling module.
NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
Oct 18, 2021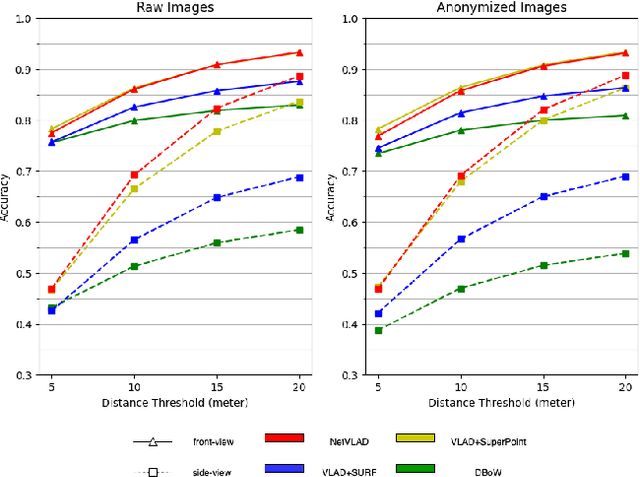
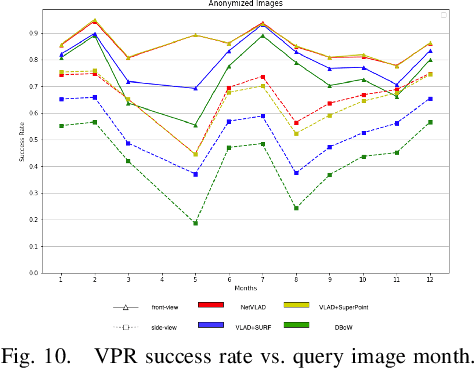
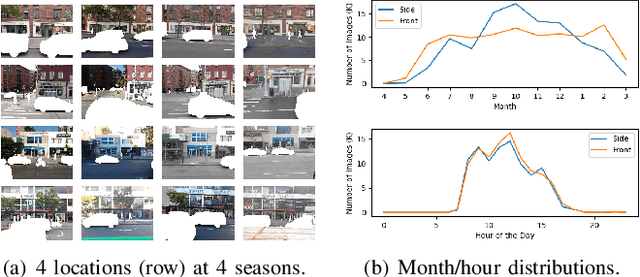

Visual place recognition (VPR) is critical in not only localization and mapping for autonomous driving vehicles, but also assistive navigation for the visually impaired population. To enable a long-term VPR system on a large scale, several challenges need to be addressed. First, different applications could require different image view directions, such as front views for self-driving cars while side views for the low vision people. Second, VPR in metropolitan scenes can often cause privacy concerns due to the imaging of pedestrian and vehicle identity information, calling for the need for data anonymization before VPR queries and database construction. Both factors could lead to VPR performance variations that are not well understood yet. To study their influences, we present the NYU-VPR dataset that contains more than 200,000 images over a 2km by 2km area near the New York University campus, taken within the whole year of 2016. We present benchmark results on several popular VPR algorithms showing that side views are significantly more challenging for current VPR methods while the influence of data anonymization is almost negligible, together with our hypothetical explanations and in-depth analysis.
MFIF-GAN: A New Generative Adversarial Network for Multi-Focus Image Fusion
Sep 21, 2020
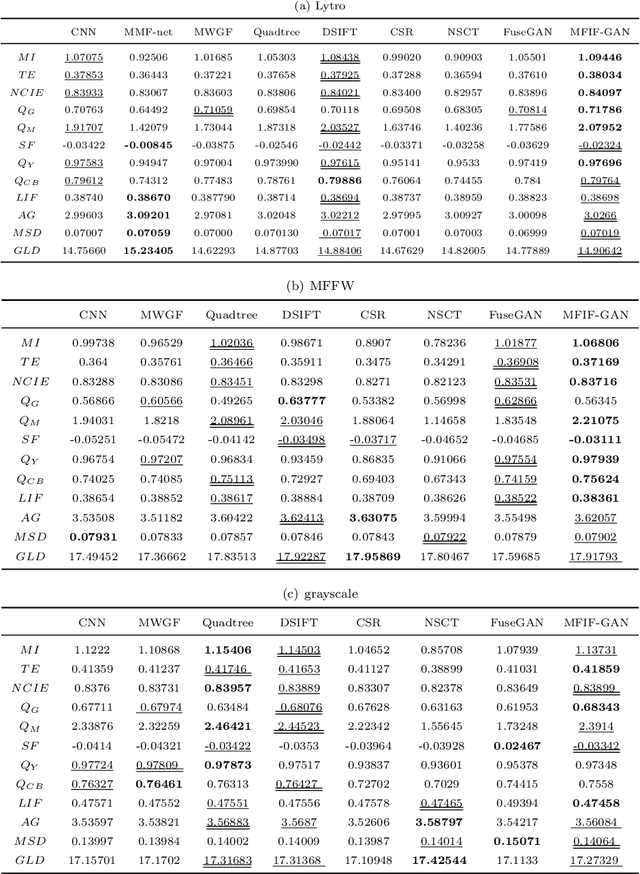

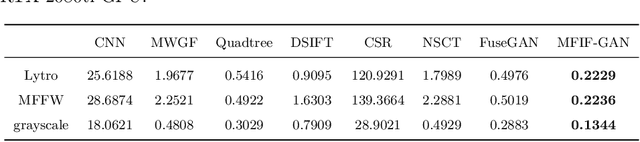
Multi-Focus Image Fusion (MFIF) is one of the promising techniques to obtain all-in-focus images to meet people's visual needs and it is a precondition of other computer vision tasks. One of the research trends of MFIF is to solve the defocus spread effect (DSE) around the focus/defocus boundary (FDB). In this paper, we present a novel generative adversarial network termed MFIF-GAN to translate multi-focus images into focus maps and to get the all-in-focus images further. The Squeeze and Excitation Residual Network (SE-ResNet) module as an attention mechanism is employed in the network. During the training, we propose reconstruction and gradient regularization loss functions to guarantee the accuracy of generated focus maps. In addition, by combining the prior knowledge of training conditon, this network is trained on a synthetic dataset with DSE by an {\alpha}-matte model. A series of experimental results demonstrate that the MFIF-GAN is superior to several representative state-of-the-art (SOTA) algorithms in visual perception, quantitative analysis as well as efficiency.
Survey on Semantic Stereo Matching / Semantic Depth Estimation
Sep 21, 2021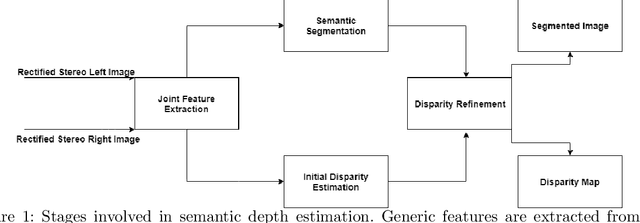
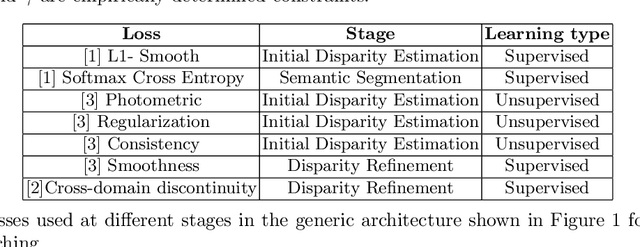
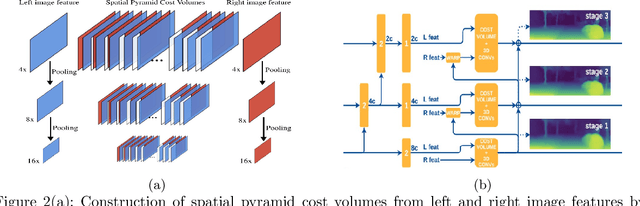

Stereo matching is one of the widely used techniques for inferring depth from stereo images owing to its robustness and speed. It has become one of the major topics of research since it finds its applications in autonomous driving, robotic navigation, 3D reconstruction, and many other fields. Finding pixel correspondences in non-textured, occluded and reflective areas is the major challenge in stereo matching. Recent developments have shown that semantic cues from image segmentation can be used to improve the results of stereo matching. Many deep neural network architectures have been proposed to leverage the advantages of semantic segmentation in stereo matching. This paper aims to give a comparison among the state of art networks both in terms of accuracy and in terms of speed which are of higher importance in real-time applications.
FU-net: Multi-class Image Segmentation Using Feedback Weighted U-net
Apr 28, 2020
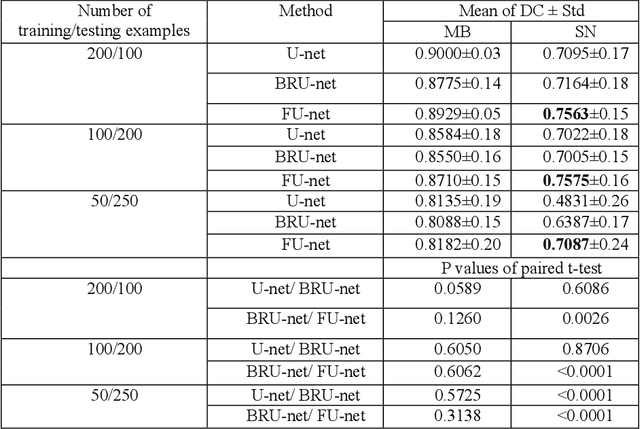
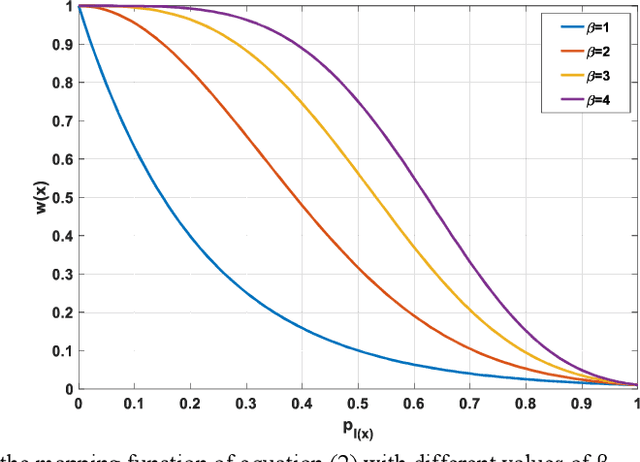
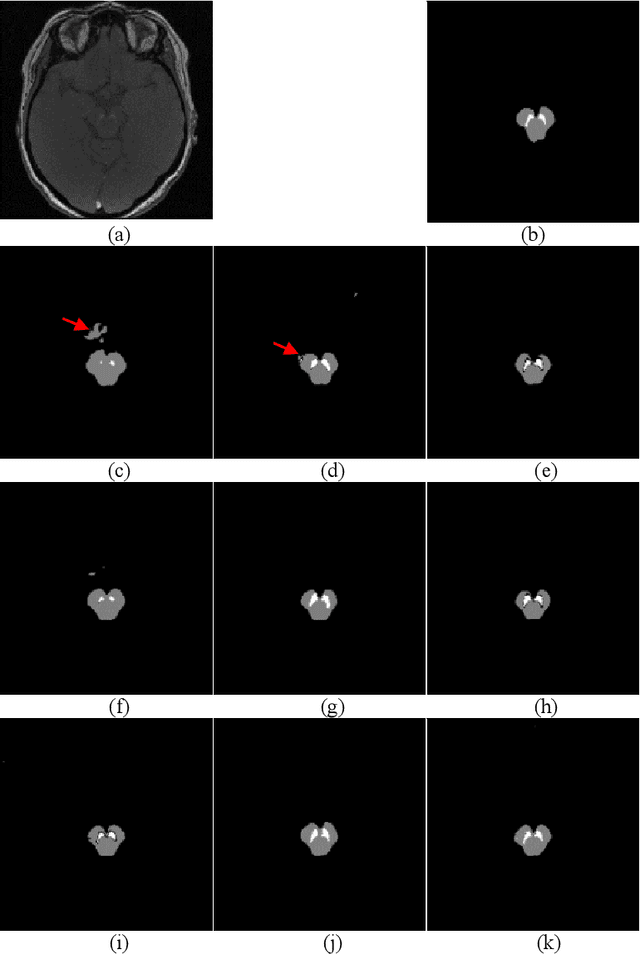
In this paper, we present a generic deep convolutional neural network (DCNN) for multi-class image segmentation. It is based on a well-established supervised end-to-end DCNN model, known as U-net. U-net is firstly modified by adding widely used batch normalization and residual block (named as BRU-net) to improve the efficiency of model training. Based on BRU-net, we further introduce a dynamically weighted cross-entropy loss function. The weighting scheme is calculated based on the pixel-wise prediction accuracy during the training process. Assigning higher weights to pixels with lower segmentation accuracies enables the network to learn more from poorly predicted image regions. Our method is named as feedback weighted U-net (FU-net). We have evaluated our method based on T1- weighted brain MRI for the segmentation of midbrain and substantia nigra, where the number of pixels in each class is extremely unbalanced to each other. Based on the dice coefficient measurement, our proposed FU-net has outperformed BRU-net and U-net with statistical significance, especially when only a small number of training examples are available. The code is publicly available in GitHub (GitHub link: https://github.com/MinaJf/FU-net).
* Accepted for publication at International Conference on Image and Graphics (ICIG 2019)
Learning a Sensor-invariant Embedding of Satellite Data: A Case Study for Lake Ice Monitoring
Jul 19, 2021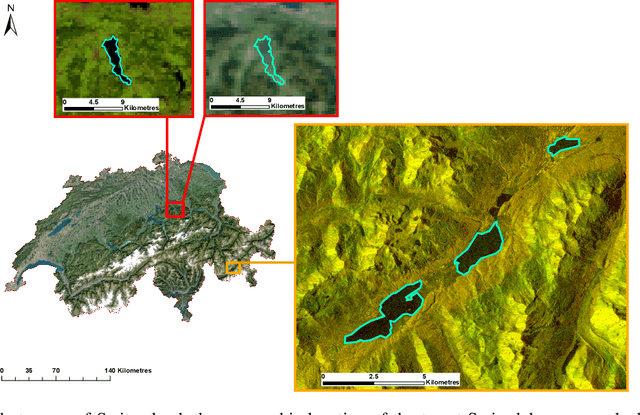
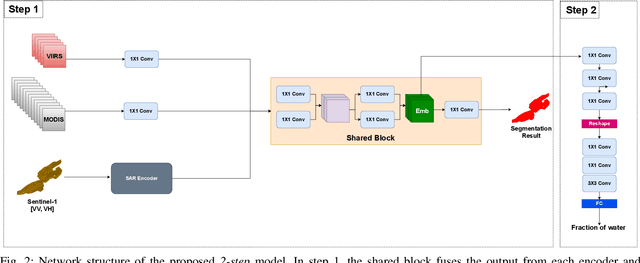
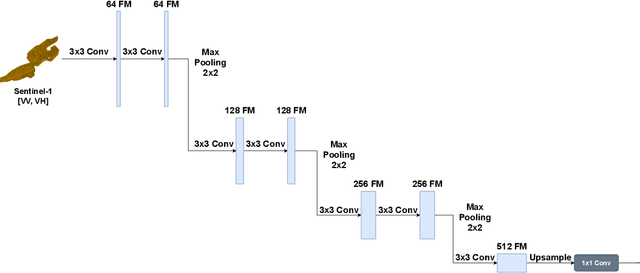
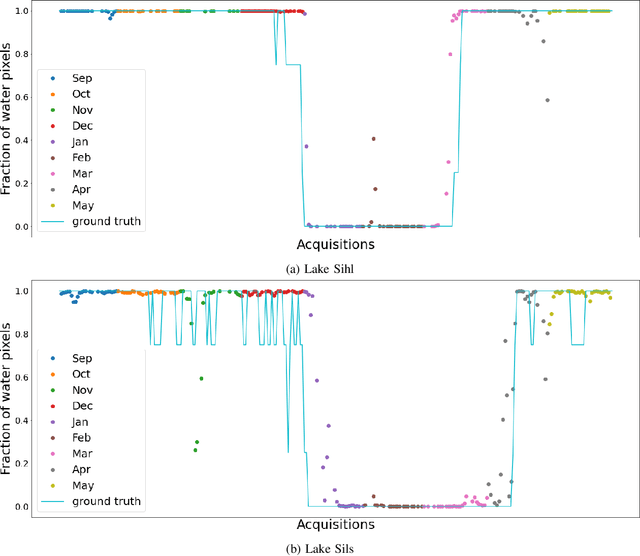
Fusing satellite imagery acquired with different sensors has been a long-standing challenge of Earth observation, particularly across different modalities such as optical and Synthetic Aperture Radar (SAR) images. Here, we explore the joint analysis of imagery from different sensors in the light of representation learning: we propose to learn a joint, sensor-invariant embedding (feature representation) within a deep neural network. Our application problem is the monitoring of lake ice on Alpine lakes. To reach the temporal resolution requirement of the Swiss Global Climate Observing System (GCOS) office, we combine three image sources: Sentinel-1 SAR (S1-SAR), Terra MODIS and Suomi-NPP VIIRS. The large gaps between the optical and SAR domains and between the sensor resolutions make this a challenging instance of the sensor fusion problem. Our approach can be classified as a feature-level fusion that is learnt in a data-driven manner. The proposed network architecture has separate encoding branches for each image sensor, which feed into a single latent embedding. I.e., a common feature representation shared by all inputs, such that subsequent processing steps deliver comparable output irrespective of which sort of input image was used. By fusing satellite data, we map lake ice at a temporal resolution of <1.5 days. The network produces spatially explicit lake ice maps with pixel-wise accuracies >91.3% (respectively, mIoU scores >60.7%) and generalises well across different lakes and winters. Moreover, it sets a new state-of-the-art for determining the important ice-on and ice-off dates for the target lakes, in many cases meeting the GCOS requirement.
Compressive Sensing Based Adaptive Defence Against Adversarial Images
Oct 11, 2021
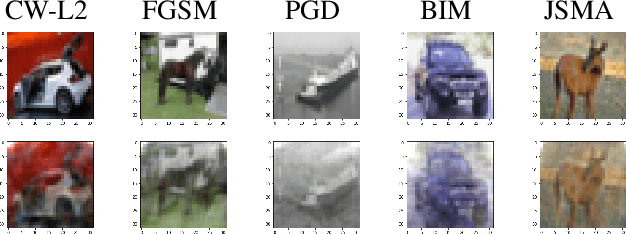
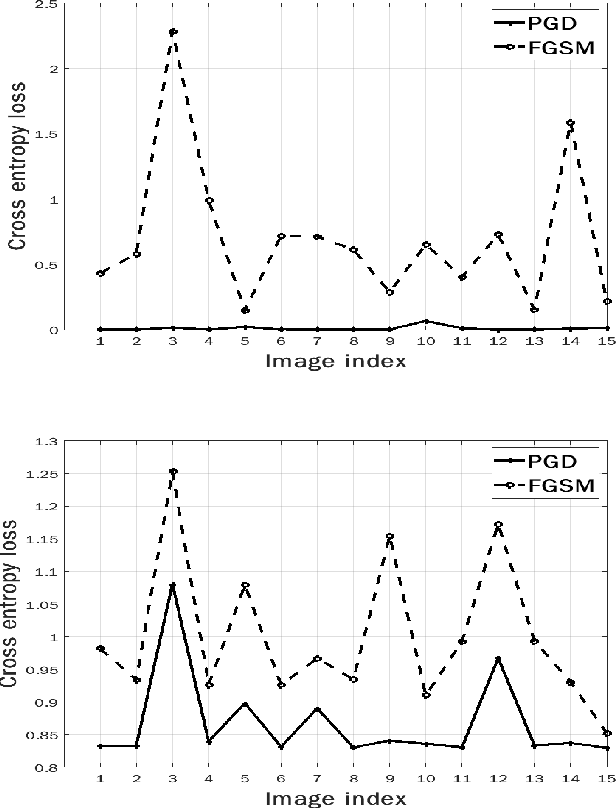
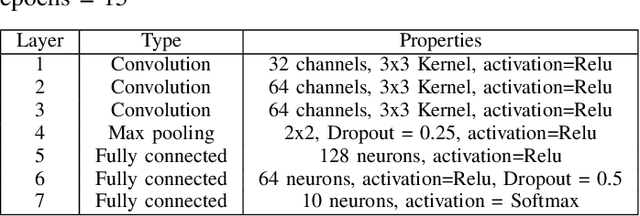
Herein, security of deep neural network against adversarial attack is considered. Existing compressive sensing based defence schemes assume that adversarial perturbations are usually on high frequency components, whereas recently it has been shown that low frequency perturbations are more effective. This paper proposes a novel Compressive sensing based Adaptive Defence (CAD) algorithm which combats distortion in frequency domain instead of time domain. Unlike existing literature, the proposed CAD algorithm does not use information about the type of attack such as l0, l2, l-infinity etc. CAD algorithm uses exponential weight algorithm for exploration and exploitation to identify the type of attack, compressive sampling matching pursuit (CoSaMP) to recover the coefficients in spectral domain, and modified basis pursuit using a novel constraint for l0, l-infinity norm attack. Tight performance bounds for various recovery schemes meant for various attack types are also provided. Experimental results against five state-of-the-art white box attacks on MNIST and CIFAR-10 show that the proposed CAD algorithm achieves excellent classification accuracy and generates good quality reconstructed image with much lower computation