 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learned Image Downscaling for Upscaling using Content Adaptive Resampler
Jul 22, 2019
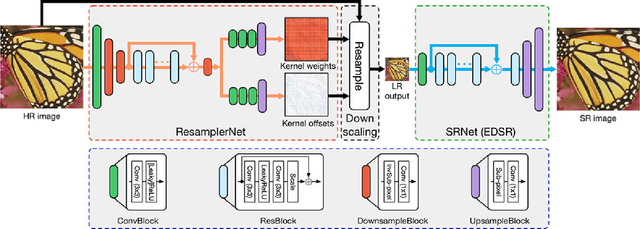
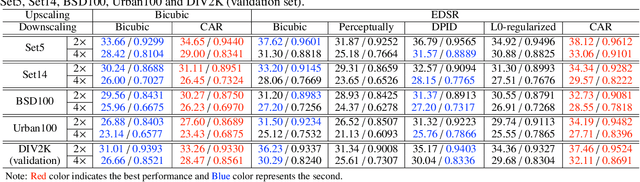
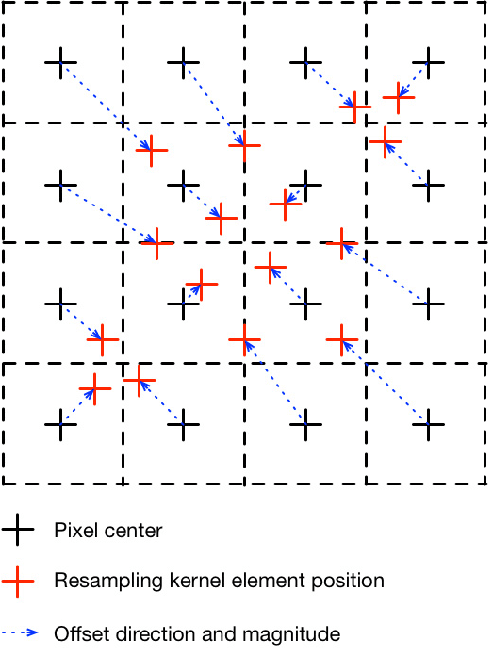
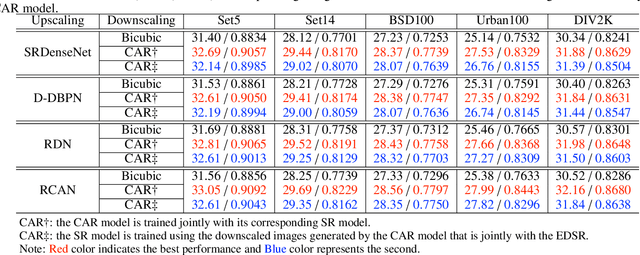
Deep convolutional neural network based image super-resolution (SR) models have shown superior performance in recovering the underlying high resolution (HR) images from low resolution (LR) images obtained from the predefined downscaling methods. In this paper we propose a learned image downscaling method based on content adaptive resampler (CAR) with consideration on the upscaling process. The proposed resampler network generates content adaptive image resampling kernels that are applied to the original HR input to generate pixels on the downscaled image. Moreover, a differentiable upscaling (SR) module is employed to upscale the LR result into its underlying HR counterpart. By back-propagating the reconstruction error down to the original HR input across the entire framework to adjust model parameters, the proposed framework achieves a new state-of-the-art SR performance through upscaling guided image resamplers which adaptively preserve detailed information that is essential to the upscaling. Experimental results indicate that the quality of the generated LR image is comparable to that of the traditional interpolation based method, but the significant SR performance gain is achieved by deep SR models trained jointly with the CAR model. The code is publicly available on: URL https://github.com/sunwj/CAR.
Image-Adaptive GAN based Reconstruction
Jun 12, 2019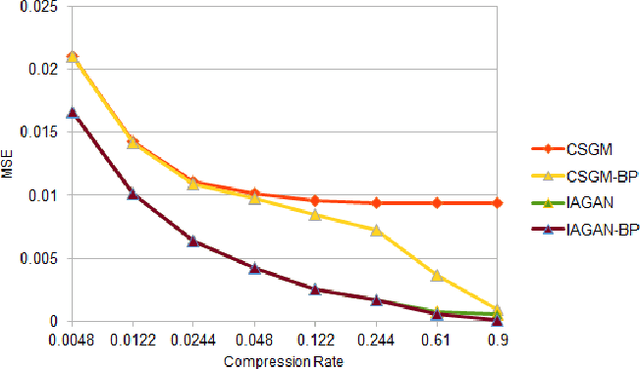



In the recent years, there has been a significant improvement in the quality of samples produced by (deep) generative models such as variational auto-encoders and generative adversarial networks. However, the representation capabilities of these methods still do not capture the full distribution for complex classes of images, such as human faces. This deficiency has been clearly observed in previous works that use pre-trained generative models to solve imaging inverse problems. In this paper, we suggest to mitigate the limited representation capabilities of generators by making them image-adaptive and enforcing compliance of the restoration with the observations via back-projections. We empirically demonstrate the advantages of our proposed approach for image super-resolution and compressed sensing
Sparse Pose Trajectory Completion
May 01, 2021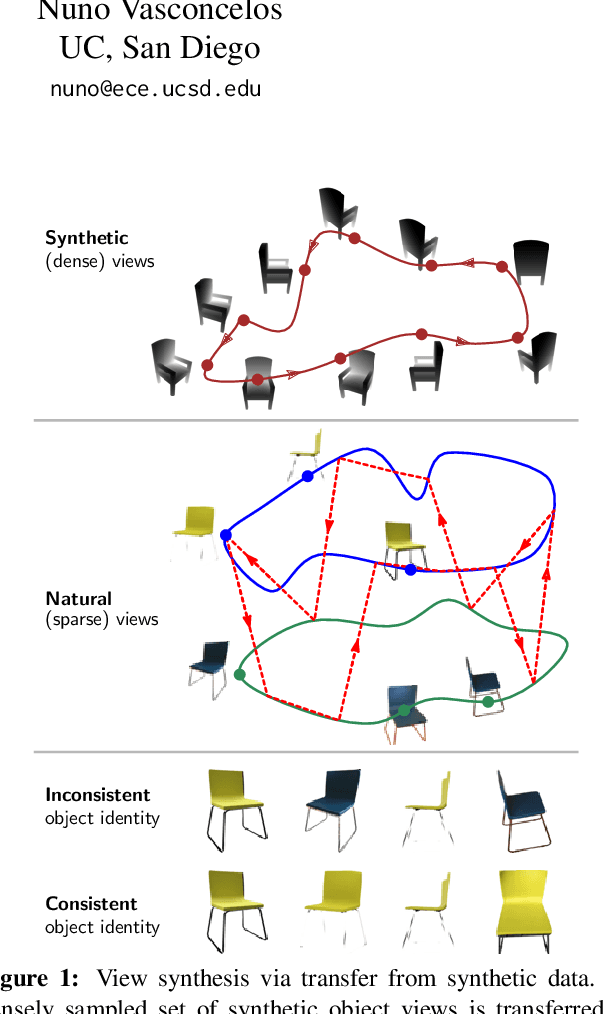
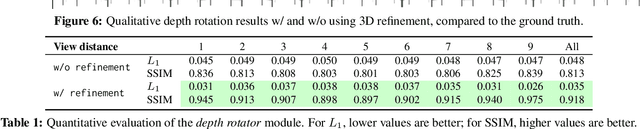
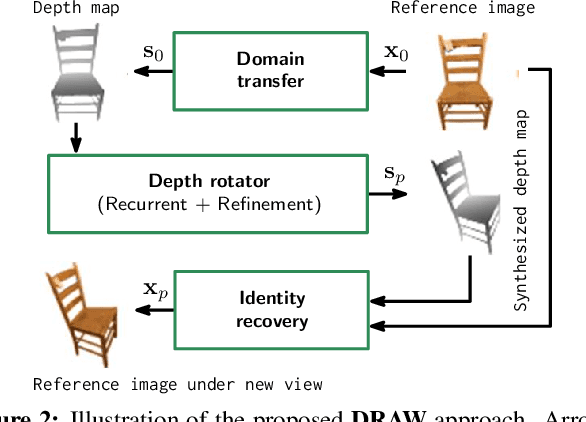
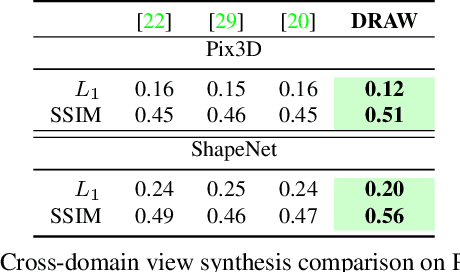
We propose a method to learn, even using a dataset where objects appear only in sparsely sampled views (e.g. Pix3D), the ability to synthesize a pose trajectory for an arbitrary reference image. This is achieved with a cross-modal pose trajectory transfer mechanism. First, a domain transfer function is trained to predict, from an RGB image of the object, its 2D depth map. Then, a set of image views is generated by learning to simulate object rotation in the depth space. Finally, the generated poses are mapped from this latent space into a set of corresponding RGB images using a learned identity preserving transform. This results in a dense pose trajectory of the object in image space. For each object type (e.g., a specific Ikea chair model), a 3D CAD model is used to render a full pose trajectory of 2D depth maps. In the absence of dense pose sampling in image space, these latent space trajectories provide cross-modal guidance for learning. The learned pose trajectories can be transferred to unseen examples, effectively synthesizing all object views in image space. Our method is evaluated on the Pix3D and ShapeNet datasets, in the setting of novel view synthesis under sparse pose supervision, demonstrating substantial improvements over recent art.
Bilinear pooling and metric learning network for early Alzheimer's disease identification with FDG-PET images
Nov 09, 2021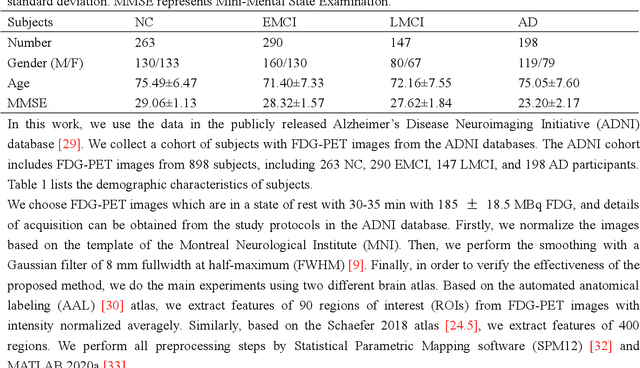
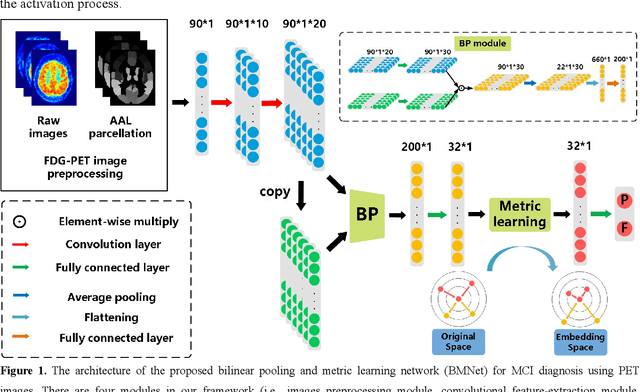
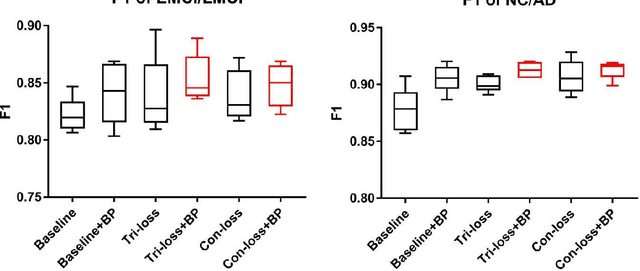
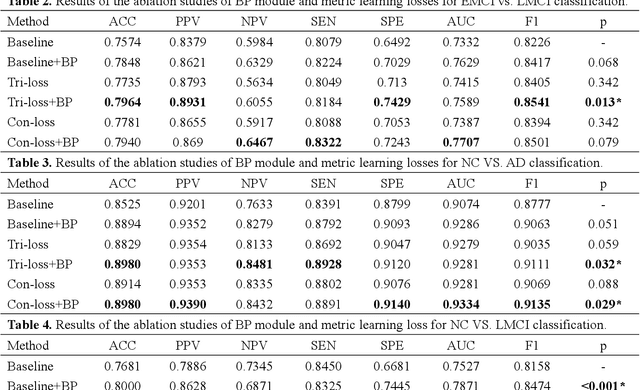
FDG-PET reveals altered brain metabolism in individuals with mild cognitive impairment (MCI) and Alzheimer's disease (AD). Some biomarkers derived from FDG-PET by computer-aided-diagnosis (CAD) technologies have been proved that they can accurately diagnosis normal control (NC), MCI, and AD. However, the studies of identification of early MCI (EMCI) and late MCI (LMCI) with FDG-PET images are still insufficient. Compared with studies based on fMRI and DTI images, the researches of the inter-region representation features in FDG-PET images are insufficient. Moreover, considering the variability in different individuals, some hard samples which are very similar with both two classes limit the classification performance. To tackle these problems, in this paper, we propose a novel bilinear pooling and metric learning network (BMNet), which can extract the inter-region representation features and distinguish hard samples by constructing embedding space. To validate the proposed method, we collect 998 FDG-PET images from ADNI. Following the common preprocessing steps, 90 features are extracted from each FDG-PET image according to the automatic anatomical landmark (AAL) template and then sent into the proposed network. Extensive 5-fold cross-validation experiments are performed for multiple two-class classifications. Experiments show that most metrics are improved after adding the bilinear pooling module and metric losses to the Baseline model respectively. Specifically, in the classification task between EMCI and LMCI, the specificity improves 6.38% after adding the triple metric loss, and the negative predictive value (NPV) improves 3.45% after using the bilinear pooling module.
A One-Shot Texture-Perceiving Generative Adversarial Network for Unsupervised Surface Inspection
Jun 12, 2021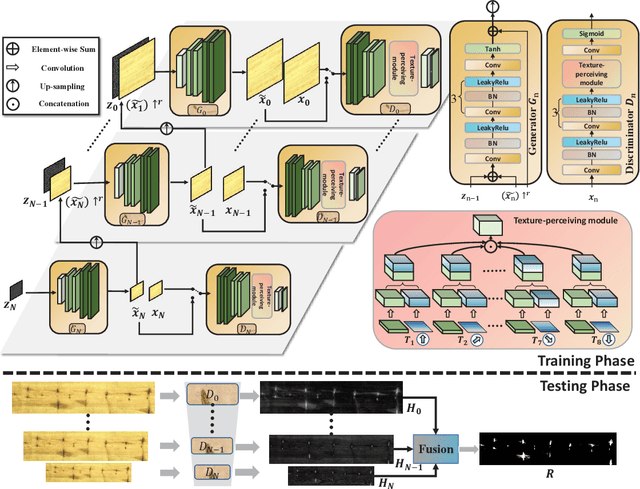



Visual surface inspection is a challenging task owing to the highly diverse appearance of target surfaces and defective regions. Previous attempts heavily rely on vast quantities of training examples with manual annotation. However, in some practical cases, it is difficult to obtain a large number of samples for inspection. To combat it, we propose a hierarchical texture-perceiving generative adversarial network (HTP-GAN) that is learned from the one-shot normal image in an unsupervised scheme. Specifically, the HTP-GAN contains a pyramid of convolutional GANs that can capture the global structure and fine-grained representation of an image simultaneously. This innovation helps distinguishing defective surface regions from normal ones. In addition, in the discriminator, a texture-perceiving module is devised to capture the spatially invariant representation of normal image via directional convolutions, making it more sensitive to defective areas. Experiments on a variety of datasets consistently demonstrate the effectiveness of our method.
SR-Net: Cooperative Image Segmentation and Restoration in Adverse Environmental Conditions
Nov 24, 2019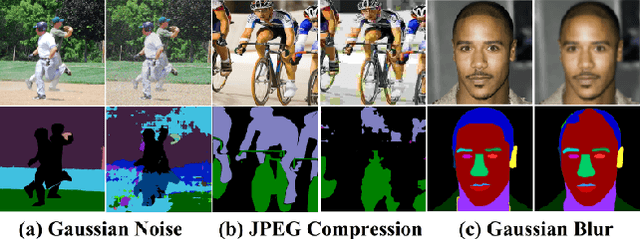
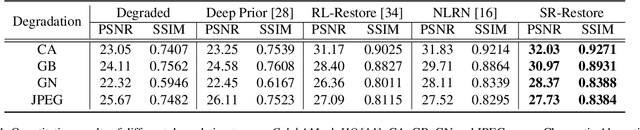
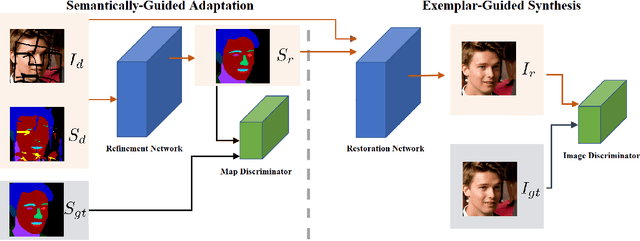
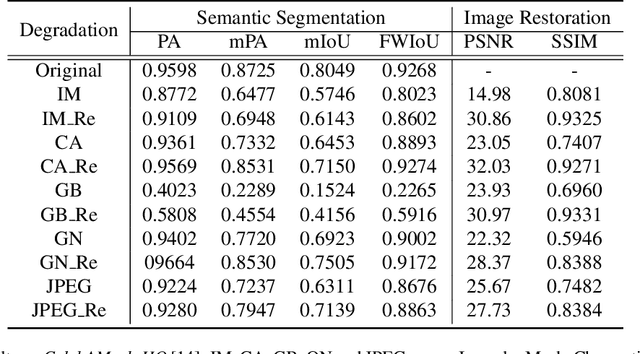
Most state-of-the-art semantic segmentation or scene parsing approaches only achieve high accuracy rates in good environmental conditions. The performance decrease enormously if images with unknown disturbances occur, which is less discussed but appears more in real applications. Most existing research works cast the handling of the challenging adverse conditions as a post-processing step of signal restoration or enhancement after sensing, then feed the restored images for visual understanding. However, the performance will largely depend on the quality of restoration or enhancement. Whether restoration-based approaches would actually boost the semantic segmentation performance remains questionable. In this paper, we propose a novel net framework to tackle semantic Segmentation and image Restoration in adverse environmental conditions (SR-Net). The proposed approach contains two components: Semantically-Guided Adaptation, which exploits and leverages semantic information from degraded images then help to refine the segmentation; and Exemplar-Guided Synthesis, which synthesizes restored or enhanced images from semantic label maps given specific degraded exemplars. SR-Net exploits the possibility of building connections of low-level image processing and high level computer vision tasks, achieving image restoration via segmentation refinement. Extensive experiments on several datasets demonstrate that our approach can not only improve the accuracy of high-level vision tasks with image adaption, but also boosts the perceptual quality and structural similarity of degraded images with image semantic guidance.
Using Deep Object Features for Image Descriptions
Feb 25, 2019
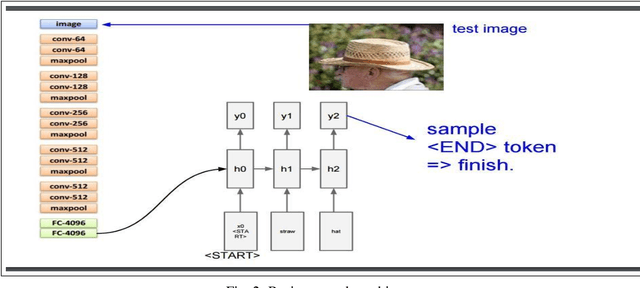
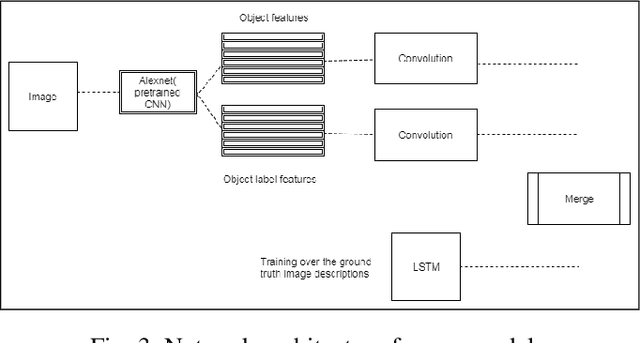

Inspired by recent advances in leveraging multiple modalities in machine translation, we introduce an encoder-decoder pipeline that uses (1) specific objects within an image and their object labels, (2) a language model for decoding joint embedding of object features and the object labels. Our pipeline merges prior detected objects from the image and their object labels and then learns the sequences of captions describing the particular image. The decoder model learns to extract descriptions for the image from scratch by decoding the joint representation of the object visual features and their object classes conditioned by the encoder component. The idea of the model is to concentrate only on the specific objects of the image and their labels for generating descriptions of the image rather than visual feature of the entire image. The model needs to be calibrated more by adjusting the parameters and settings to result in better accuracy and performance.
Rethinking of the Image Salient Object Detection: Object-level Semantic Saliency Re-ranking First, Pixel-wise Saliency Refinement Latter
Aug 10, 2020
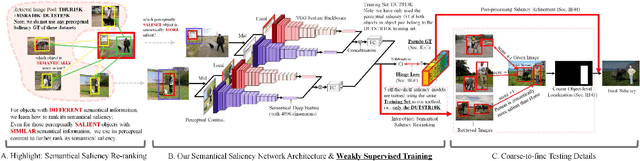


The real human attention is an interactive activity between our visual system and our brain, using both low-level visual stimulus and high-level semantic information. Previous image salient object detection (SOD) works conduct their saliency predictions in a multi-task manner, i.e., performing pixel-wise saliency regression and segmentation-like saliency refinement at the same time, which degenerates their feature backbones in revealing semantic information. However, given an image, we tend to pay more attention to those regions which are semantically salient even in the case that these regions are perceptually not the most salient ones at first glance. In this paper, we divide the SOD problem into two sequential tasks: 1) we propose a lightweight, weakly supervised deep network to coarsely locate those semantically salient regions first; 2) then, as a post-processing procedure, we selectively fuse multiple off-the-shelf deep models on these semantically salient regions as the pixel-wise saliency refinement. In sharp contrast to the state-of-the-art (SOTA) methods that focus on learning pixel-wise saliency in "single image" using perceptual clues mainly, our method has investigated the "object-level semantic ranks between multiple images", of which the methodology is more consistent with the real human attention mechanism. Our method is simple yet effective, which is the first attempt to consider the salient object detection mainly as an object-level semantic re-ranking problem.
Discovery-and-Selection: Towards Optimal Multiple Instance Learning for Weakly Supervised Object Detection
Oct 18, 2021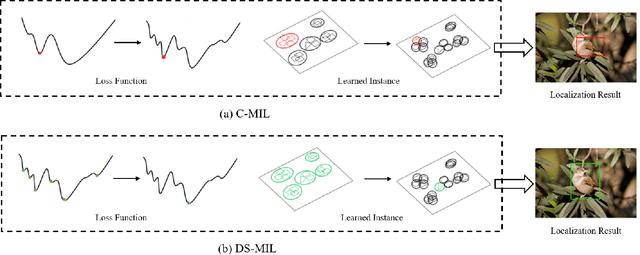
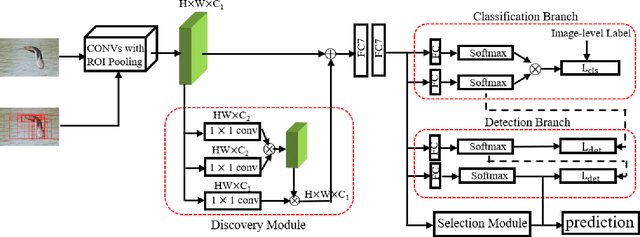

Weakly supervised object detection (WSOD) is a challenging task that requires simultaneously learn object classifiers and estimate object locations under the supervision of image category labels. A major line of WSOD methods roots in multiple instance learning which regards images as bags of instance and selects positive instances from each bag to learn the detector. However, a grand challenge emerges when the detector inclines to converge to discriminative parts of objects rather than the whole objects. In this paper, under the hypothesis that optimal solutions are included in local minima, we propose a discoveryand-selection approach fused with multiple instance learning (DS-MIL), which finds rich local minima and select optimal solutions from multiple local minima. To implement DS-MIL, an attention module is designed so that more context information can be captured by feature maps and more valuable proposals can be collected during training. With proposal candidates, a re-rank module is designed to select informative instances for object detector training. Experimental results on commonly used benchmarks show that our proposed DS-MIL approach can consistently improve the baselines, reporting state-of-the-art performance.
ShapeEditer: a StyleGAN Encoder for Face Swapping
Jun 26, 2021
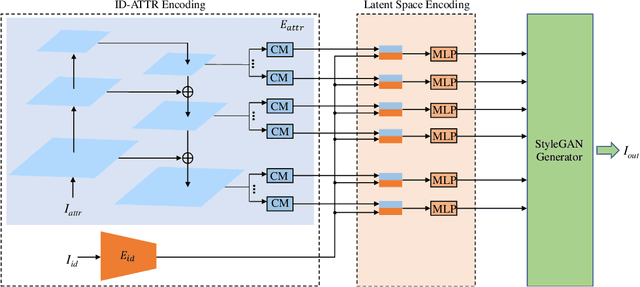

In this paper, we propose a novel encoder, called ShapeEditor, for high-resolution, realistic and high-fidelity face exchange. First of all, in order to ensure sufficient clarity and authenticity, our key idea is to use an advanced pretrained high-quality random face image generator, i.e. StyleGAN, as backbone. Secondly, we design ShapeEditor, a two-step encoder, to make the swapped face integrate the identity and attribute of the input faces. In the first step, we extract the identity vector of the source image and the attribute vector of the target image respectively; in the second step, we map the concatenation of identity vector and attribute vector into the $\mathcal{W+}$ potential space. In addition, for learning to map into the latent space of StyleGAN, we propose a set of self-supervised loss functions with which the training data do not need to be labeled manually. Extensive experiments on the test dataset show that the results of our method not only have a great advantage in clarity and authenticity than other state-of-the-art methods, but also reflect the sufficient integration of identity and attribute.