 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Graph Attention Layer Evolves Semantic Segmentation for Road Pothole Detection: A Benchmark and Algorithms
Sep 06, 2021

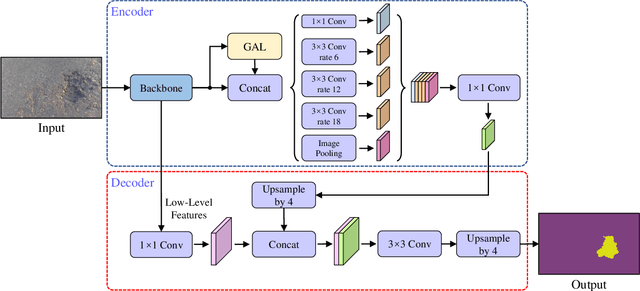
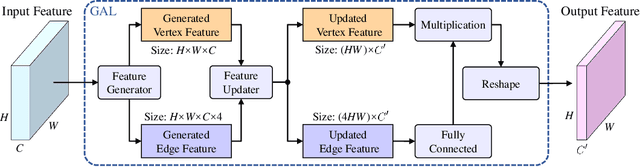
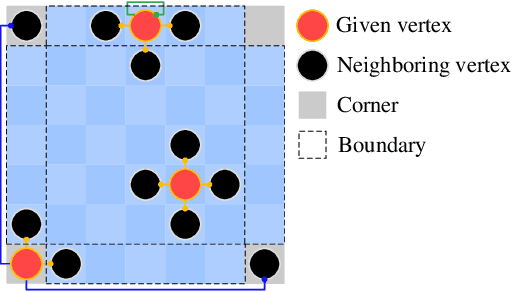
Existing road pothole detection approaches can be classified as computer vision-based or machine learning-based. The former approaches typically employ 2-D image analysis/understanding or 3-D point cloud modeling and segmentation algorithms to detect road potholes from vision sensor data. The latter approaches generally address road pothole detection using convolutional neural networks (CNNs) in an end-to-end manner. However, road potholes are not necessarily ubiquitous and it is challenging to prepare a large well-annotated dataset for CNN training. In this regard, while computer vision-based methods were the mainstream research trend in the past decade, machine learning-based methods were merely discussed. Recently, we published the first stereo vision-based road pothole detection dataset and a novel disparity transformation algorithm, whereby the damaged and undamaged road areas can be highly distinguished. However, there are no benchmarks currently available for state-of-the-art (SoTA) CNNs trained using either disparity images or transformed disparity images. Therefore, in this paper, we first discuss the SoTA CNNs designed for semantic segmentation and evaluate their performance for road pothole detection with extensive experiments. Additionally, inspired by graph neural network (GNN), we propose a novel CNN layer, referred to as graph attention layer (GAL), which can be easily deployed in any existing CNN to optimize image feature representations for semantic segmentation. Our experiments compare GAL-DeepLabv3+, our best-performing implementation, with nine SoTA CNNs on three modalities of training data: RGB images, disparity images, and transformed disparity images. The experimental results suggest that our proposed GAL-DeepLabv3+ achieves the best overall pothole detection accuracy on all training data modalities.
Feature Forwarding for Efficient Single Image Dehazing
May 03, 2019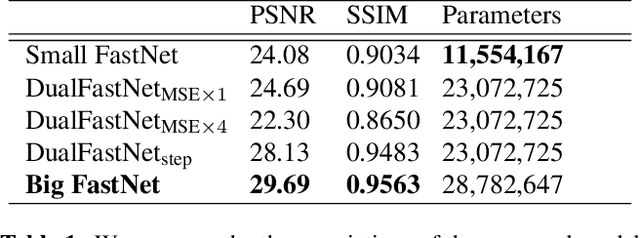
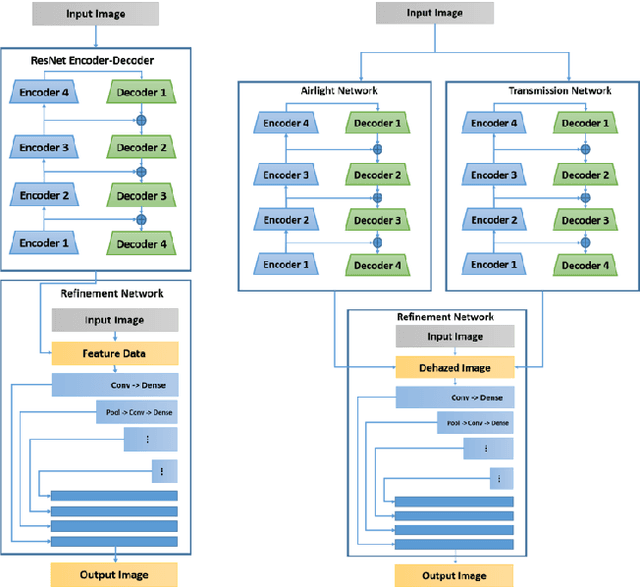
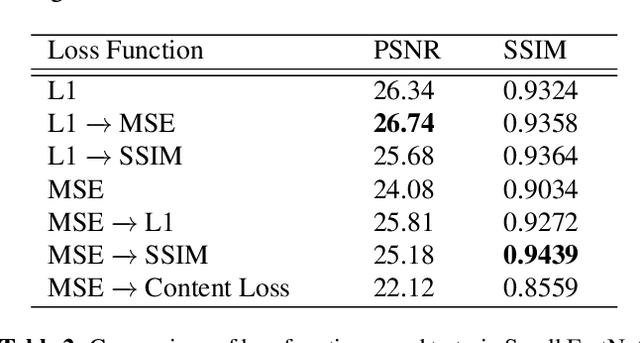
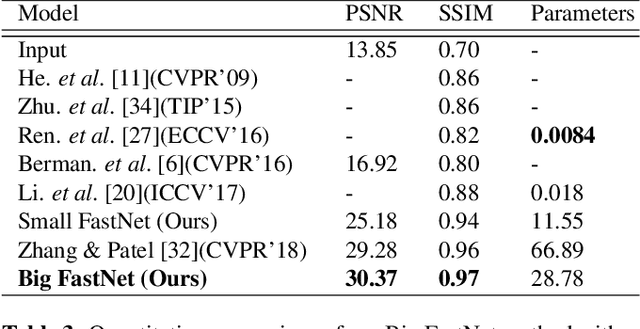
Haze degrades content and obscures information of images, which can negatively impact vision-based decision-making in real-time systems. In this paper, we propose an efficient fully convolutional neural network (CNN) image dehazing method designed to run on edge graphical processing units (GPUs). We utilize three variants of our architecture to explore the dependency of dehazed image quality on parameter count and model design. The first two variants presented, a small and big version, make use of a single efficient encoder-decoder convolutional feature extractor. The final variant utilizes a pair of encoder-decoders for atmospheric light and transmission map estimation. Each variant ends with an image refinement pyramid pooling network to form the final dehazed image. For the big variant of the single-encoder network, we demonstrate state-of-the-art performance on the NYU Depth dataset. For the small variant, we maintain competitive performance on the super-resolution O/I-HAZE datasets without the need for image cropping. Finally, we examine some challenges presented by the Dense-Haze dataset when leveraging CNN architectures for dehazing of dense haze imagery and examine the impact of loss function selection on image quality. Benchmarks are included to show the feasibility of introducing this approach into real-time systems.
Sickle Cell Disease Severity Prediction from Percoll Gradient Images using Graph Convolutional Networks
Sep 11, 2021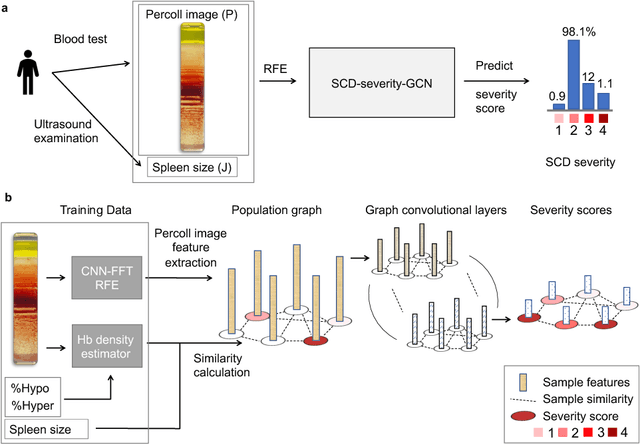
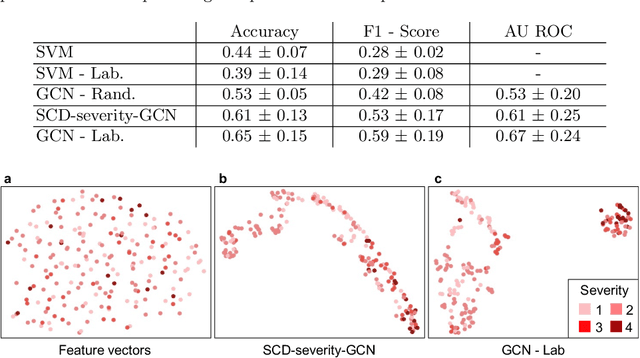


Sickle cell disease (SCD) is a severe genetic hemoglobin disorder that results in premature destruction of red blood cells. Assessment of the severity of the disease is a challenging task in clinical routine since the causes of broad variance in SCD manifestation despite the common genetic cause remain unclear. Identification of the biomarkers that would predict the severity grade is of importance for prognosis and assessment of responsiveness of patients to therapy. Detection of the changes in red blood cell (RBC) density through separation of Percoll density gradient could be such marker as it allows to resolve intercellular differences and follow the most damaged dense cells prone to destruction and vaso-occlusion. Quantification of the images obtained from the distribution of RBCs in Percoll gradient and interpretation of the obtained is an important prerequisite for establishment of this approach. Here, we propose a novel approach combining a graph convolutional network, a convolutional neural network, fast Fourier transform, and recursive feature elimination to predict the severity of SCD directly from a Percoll image. Two important but expensive laboratory blood test parameters measurements are used for training the graph convolutional network. To make the model independent from such tests during prediction, the two parameters are estimated by a neural network from the Percoll image directly. On a cohort of 216 subjects, we achieve a prediction performance that is only slightly below an approach where the groundtruth laboratory measurements are used. Our proposed method is the first computational approach for the difficult task of SCD severity prediction. The two-step approach relies solely on inexpensive and simple blood analysis tools and can have a significant impact on the patients' survival in underdeveloped countries where access to medical instruments and doctors is limited
SIPSA-Net: Shift-Invariant Pan Sharpening with Moving Object Alignment for Satellite Imagery
May 06, 2021
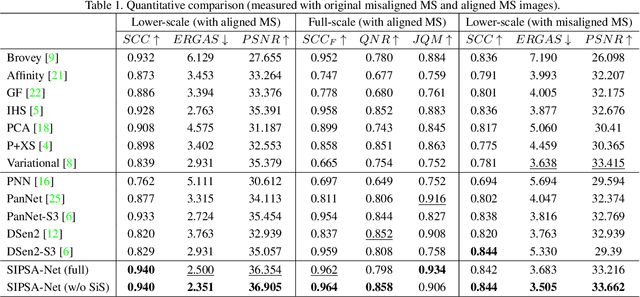
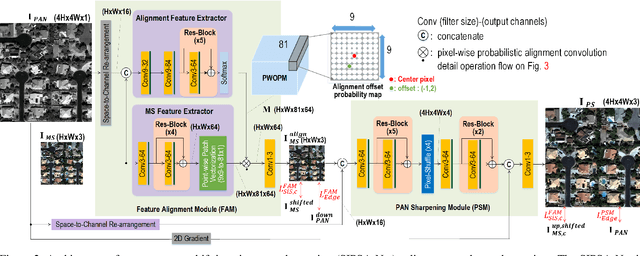
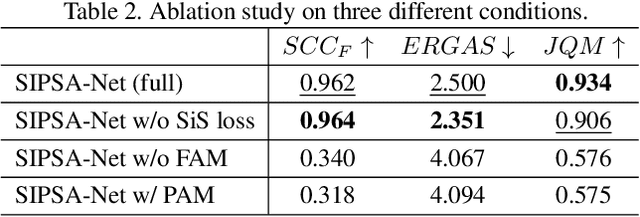
Pan-sharpening is a process of merging a high-resolution (HR) panchromatic (PAN) image and its corresponding low-resolution (LR) multi-spectral (MS) image to create an HR-MS and pan-sharpened image. However, due to the different sensors' locations, characteristics and acquisition time, PAN and MS image pairs often tend to have various amounts of misalignment. Conventional deep-learning-based methods that were trained with such misaligned PAN-MS image pairs suffer from diverse artifacts such as double-edge and blur artifacts in the resultant PAN-sharpened images. In this paper, we propose a novel framework called shift-invariant pan-sharpening with moving object alignment (SIPSA-Net) which is the first method to take into account such large misalignment of moving object regions for PAN sharpening. The SISPA-Net has a feature alignment module (FAM) that can adjust one feature to be aligned to another feature, even between the two different PAN and MS domains. For better alignment in pan-sharpened images, a shift-invariant spectral loss is newly designed, which ignores the inherent misalignment in the original MS input, thereby having the same effect as optimizing the spectral loss with a well-aligned MS image. Extensive experimental results show that our SIPSA-Net can generate pan-sharpened images with remarkable improvements in terms of visual quality and alignment, compared to the state-of-the-art methods.
Discovery-and-Selection: Towards Optimal Multiple Instance Learning for Weakly Supervised Object Detection
Oct 18, 2021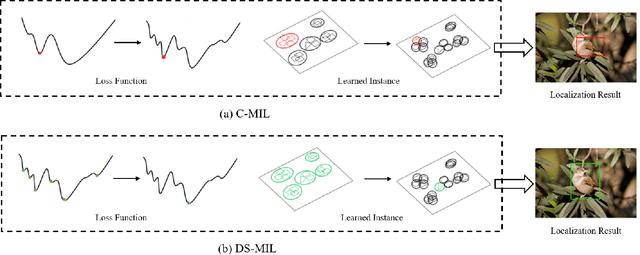
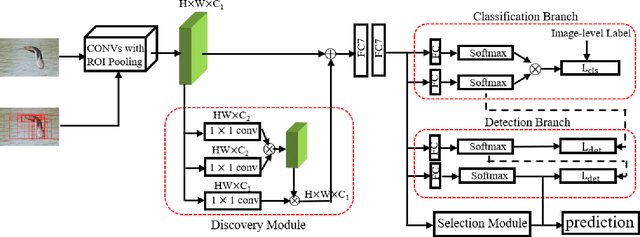
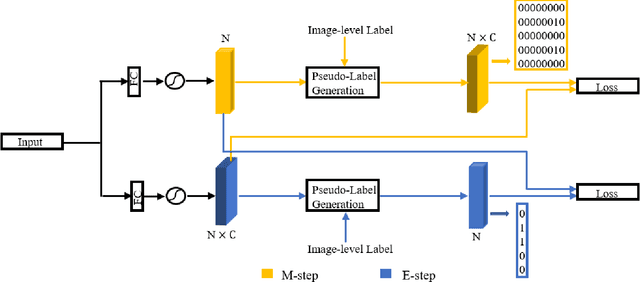

Weakly supervised object detection (WSOD) is a challenging task that requires simultaneously learn object classifiers and estimate object locations under the supervision of image category labels. A major line of WSOD methods roots in multiple instance learning which regards images as bags of instance and selects positive instances from each bag to learn the detector. However, a grand challenge emerges when the detector inclines to converge to discriminative parts of objects rather than the whole objects. In this paper, under the hypothesis that optimal solutions are included in local minima, we propose a discoveryand-selection approach fused with multiple instance learning (DS-MIL), which finds rich local minima and select optimal solutions from multiple local minima. To implement DS-MIL, an attention module is designed so that more context information can be captured by feature maps and more valuable proposals can be collected during training. With proposal candidates, a re-rank module is designed to select informative instances for object detector training. Experimental results on commonly used benchmarks show that our proposed DS-MIL approach can consistently improve the baselines, reporting state-of-the-art performance.
MFIF-GAN: A New Generative Adversarial Network for Multi-Focus Image Fusion
Sep 22, 2020
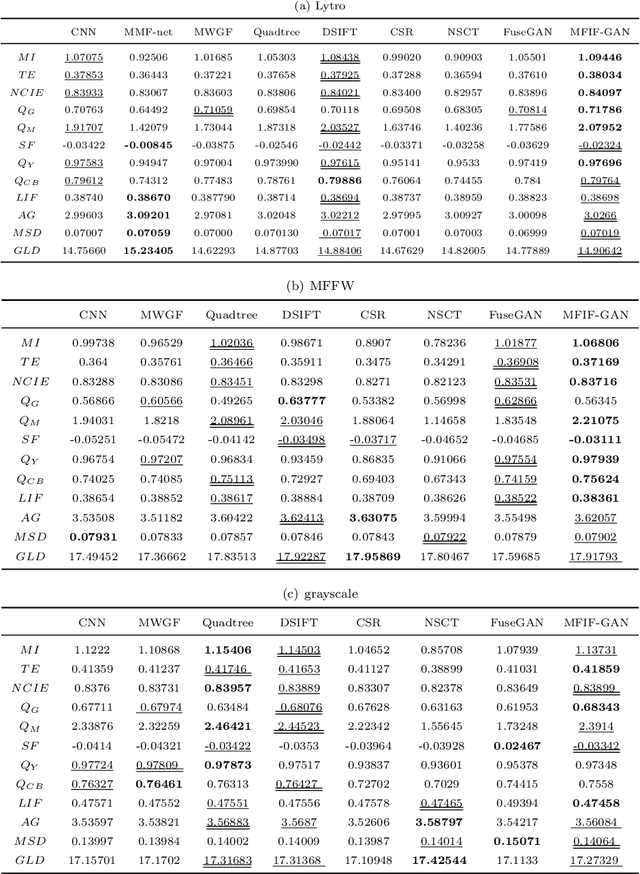

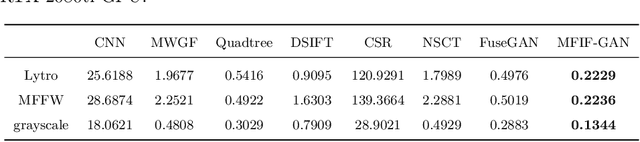
Multi-Focus Image Fusion (MFIF) is one of the promising techniques to obtain all-in-focus images to meet people's visual needs and it is a precondition of other computer vision tasks. One of the research trends of MFIF is to solve the defocus spread effect (DSE) around the focus/defocus boundary (FDB). In this paper, we present a novel generative adversarial network termed MFIF-GAN to translate multi-focus images into focus maps and to get the all-in-focus images further. The Squeeze and Excitation Residual Network (SE-ResNet) module as an attention mechanism is employed in the network. During the training, we propose reconstruction and gradient regularization loss functions to guarantee the accuracy of generated focus maps. In addition, by combining the prior knowledge of training conditon, this network is trained on a synthetic dataset with DSE based on an {\alpha}-matte model. A series of experimental results demonstrate that the MFIF-GAN is superior to several representative state-of-the-art (SOTA) algorithms in visual perception, quantitative analysis as well as efficiency.
Multi-modal Visual Place Recognition in Dynamics-Invariant Perception Space
May 17, 2021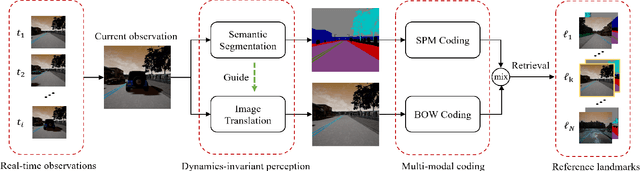
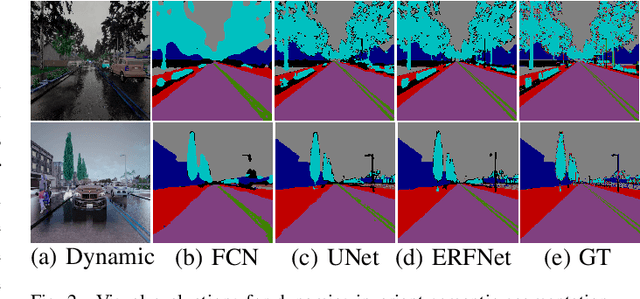

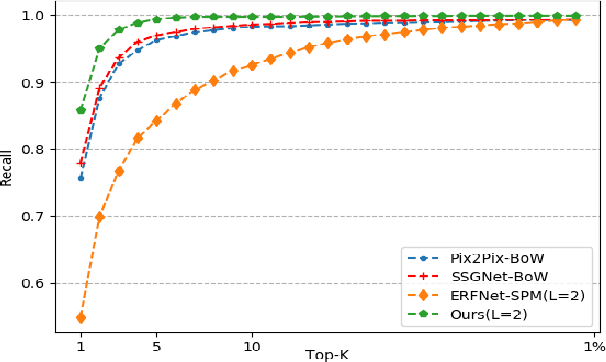
Visual place recognition is one of the essential and challenging problems in the fields of robotics. In this letter, we for the first time explore the use of multi-modal fusion of semantic and visual modalities in dynamics-invariant space to improve place recognition in dynamic environments. We achieve this by first designing a novel deep learning architecture to generate the static semantic segmentation and recover the static image directly from the corresponding dynamic image. We then innovatively leverage the spatial-pyramid-matching model to encode the static semantic segmentation into feature vectors. In parallel, the static image is encoded using the popular Bag-of-words model. On the basis of the above multi-modal features, we finally measure the similarity between the query image and target landmark by the joint similarity of their semantic and visual codes. Extensive experiments demonstrate the effectiveness and robustness of the proposed approach for place recognition in dynamic environments.
AffectGAN: Affect-Based Generative Art Driven by Semantics
Sep 30, 2021
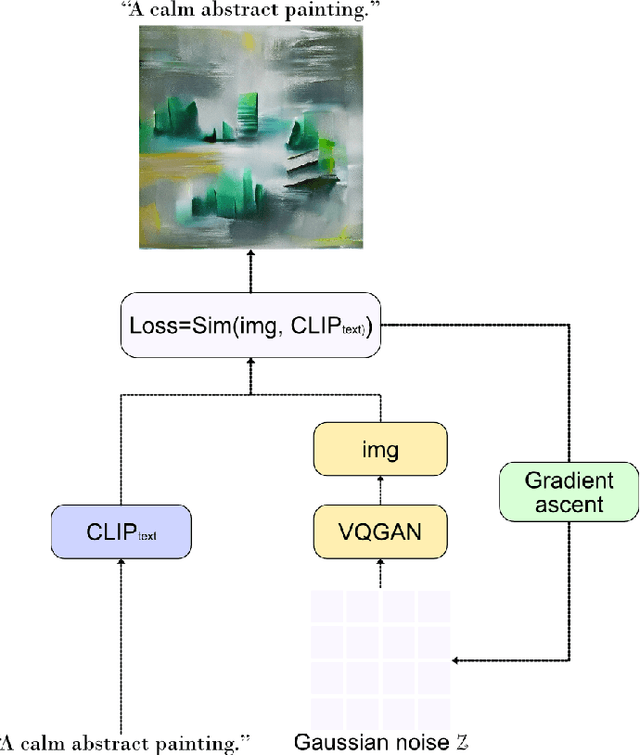
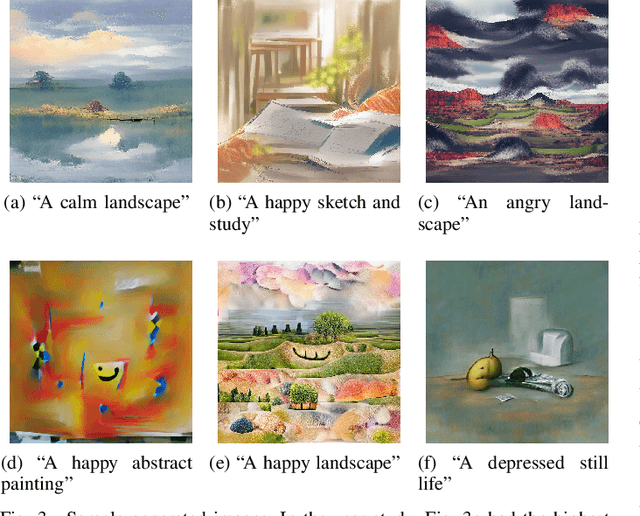

This paper introduces a novel method for generating artistic images that express particular affective states. Leveraging state-of-the-art deep learning methods for visual generation (through generative adversarial networks), semantic models from OpenAI, and the annotated dataset of the visual art encyclopedia WikiArt, our AffectGAN model is able to generate images based on specific or broad semantic prompts and intended affective outcomes. A small dataset of 32 images generated by AffectGAN is annotated by 50 participants in terms of the particular emotion they elicit, as well as their quality and novelty. Results show that for most instances the intended emotion used as a prompt for image generation matches the participants' responses. This small-scale study brings forth a new vision towards blending affective computing with computational creativity, enabling generative systems with intentionality in terms of the emotions they wish their output to elicit.
Two-Stage Resampling for Convolutional Neural Network Training in the Imbalanced Colorectal Cancer Image Classification
Apr 07, 2020
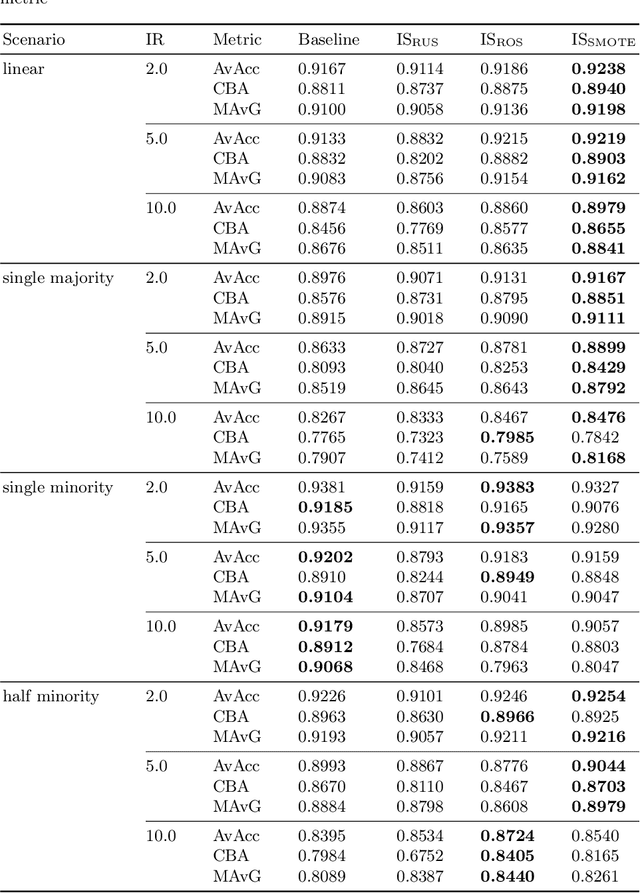
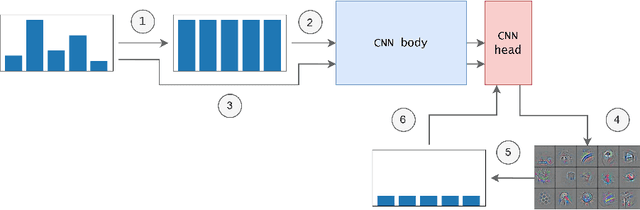
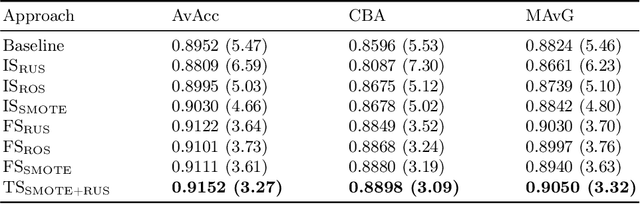
Data imbalance remains one of the open challenges in the contemporary machine learning. It is especially prevalent in case of medical data, such as histopathological images. Traditional data-level approaches for dealing with data imbalance are ill-suited for image data: oversampling methods such as SMOTE and its derivatives lead to creation of unrealistic synthetic observations, whereas undersampling reduces the amount of available data, critical for successful training of convolutional neural networks. To alleviate the problems associated with over- and undersampling we propose a novel two-stage resampling methodology, in which we initially use the oversampling techniques in the image space to leverage a large amount of data for training of a convolutional neural network, and afterwards apply undersampling in the feature space to fine-tune the last layers of the network. Experiments conducted on a colorectal cancer image dataset indicate the usefulness of the proposed approach.
NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
Oct 18, 2021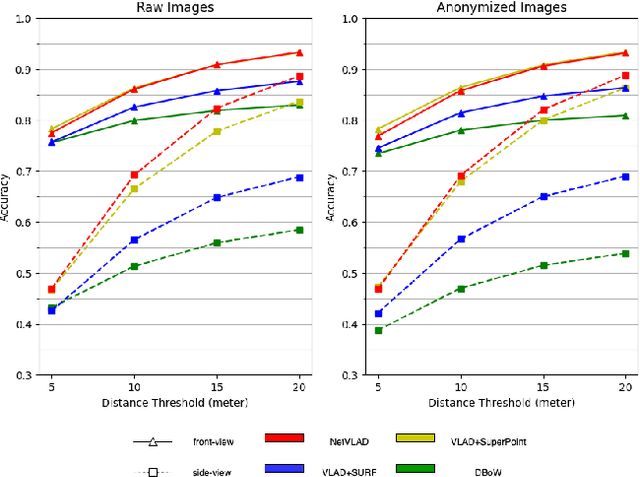
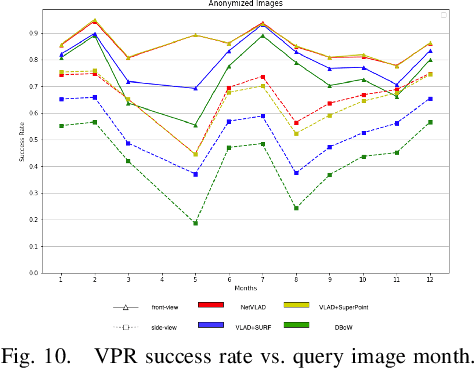
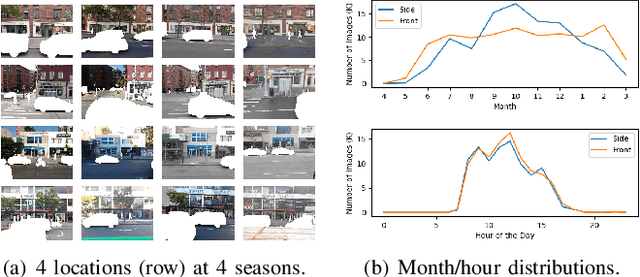

Visual place recognition (VPR) is critical in not only localization and mapping for autonomous driving vehicles, but also assistive navigation for the visually impaired population. To enable a long-term VPR system on a large scale, several challenges need to be addressed. First, different applications could require different image view directions, such as front views for self-driving cars while side views for the low vision people. Second, VPR in metropolitan scenes can often cause privacy concerns due to the imaging of pedestrian and vehicle identity information, calling for the need for data anonymization before VPR queries and database construction. Both factors could lead to VPR performance variations that are not well understood yet. To study their influences, we present the NYU-VPR dataset that contains more than 200,000 images over a 2km by 2km area near the New York University campus, taken within the whole year of 2016. We present benchmark results on several popular VPR algorithms showing that side views are significantly more challenging for current VPR methods while the influence of data anonymization is almost negligible, together with our hypothetical explanations and in-depth analysis.