 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interactive Analysis of CNN Robustness
Oct 14, 2021

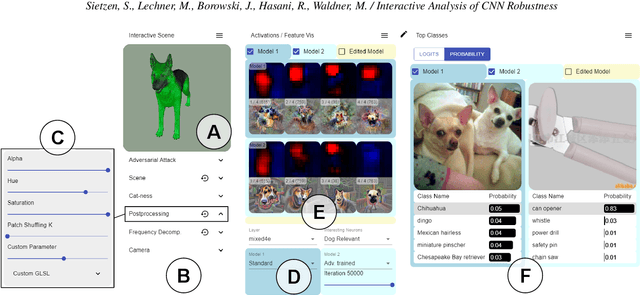

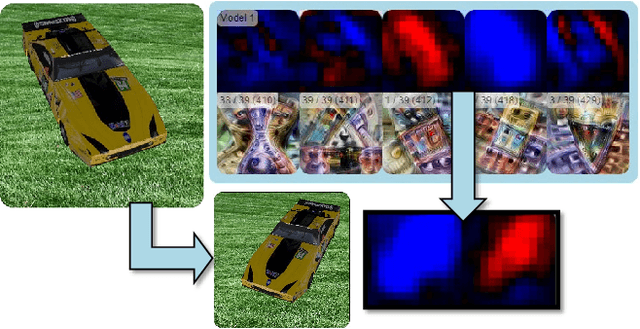
While convolutional neural networks (CNNs) have found wide adoption as state-of-the-art models for image-related tasks, their predictions are often highly sensitive to small input perturbations, which the human vision is robust against. This paper presents Perturber, a web-based application that allows users to instantaneously explore how CNN activations and predictions evolve when a 3D input scene is interactively perturbed. Perturber offers a large variety of scene modifications, such as camera controls, lighting and shading effects, background modifications, object morphing, as well as adversarial attacks, to facilitate the discovery of potential vulnerabilities. Fine-tuned model versions can be directly compared for qualitative evaluation of their robustness. Case studies with machine learning experts have shown that Perturber helps users to quickly generate hypotheses about model vulnerabilities and to qualitatively compare model behavior. Using quantitative analyses, we could replicate users' insights with other CNN architectures and input images, yielding new insights about the vulnerability of adversarially trained models.
Learning Multimodal VAEs through Mutual Supervision
Jun 23, 2021

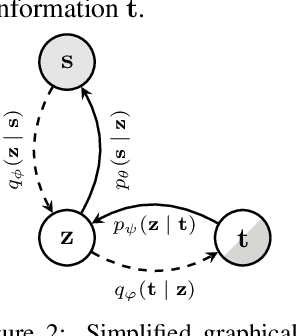

Multimodal VAEs seek to model the joint distribution over heterogeneous data (e.g.\ vision, language), whilst also capturing a shared representation across such modalities. Prior work has typically combined information from the modalities by reconciling idiosyncratic representations directly in the recognition model through explicit products, mixtures, or other such factorisations. Here we introduce a novel alternative, the MEME, that avoids such explicit combinations by repurposing semi-supervised VAEs to combine information between modalities implicitly through mutual supervision. This formulation naturally allows learning from partially-observed data where some modalities can be entirely missing -- something that most existing approaches either cannot handle, or do so to a limited extent. We demonstrate that MEME outperforms baselines on standard metrics across both partial and complete observation schemes on the MNIST-SVHN (image-image) and CUB (image-text) datasets. We also contrast the quality of the representations learnt by mutual supervision against standard approaches and observe interesting trends in its ability to capture relatedness between data.
HYPER-SNN: Towards Energy-efficient Quantized Deep Spiking Neural Networks for Hyperspectral Image Classification
Jul 28, 2021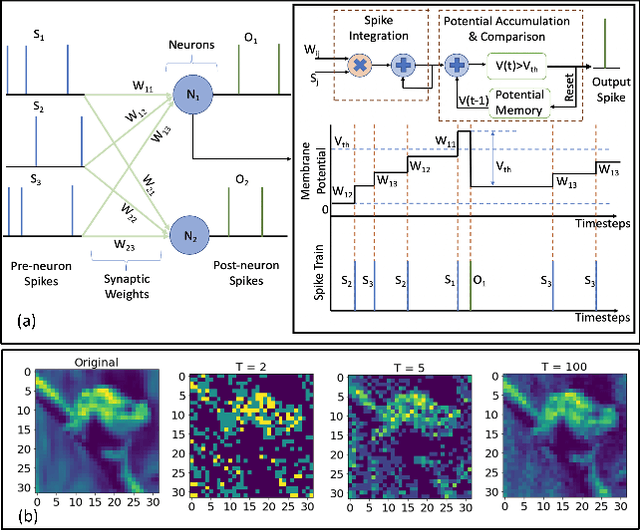
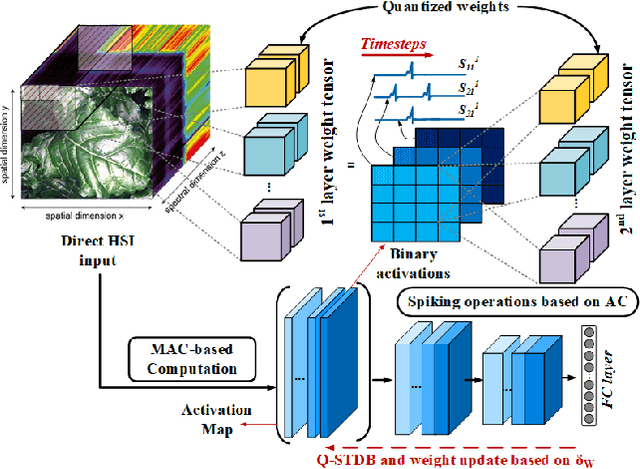
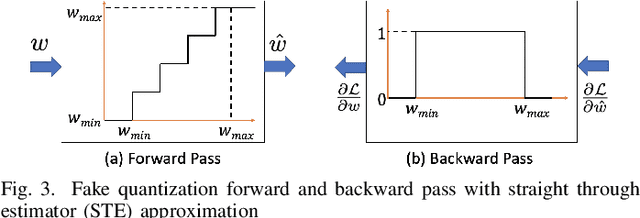
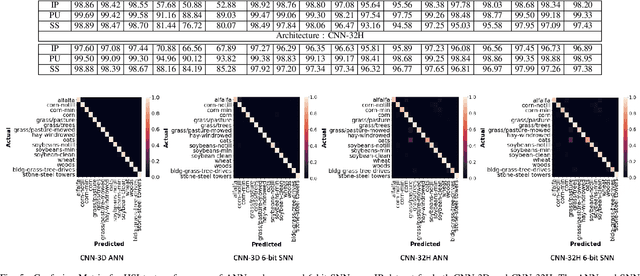
Hyper spectral images (HSI) provide rich spectral and spatial information across a series of contiguous spectral bands. However, the accurate processing of the spectral and spatial correlation between the bands requires the use of energy-expensive 3-D Convolutional Neural Networks (CNNs). To address this challenge, we propose the use of Spiking Neural Networks (SNNs) that are generated from iso-architecture CNNs and trained with quantization-aware gradient descent to optimize their weights, membrane leak, and firing thresholds. During both training and inference, the analog pixel values of a HSI are directly applied to the input layer of the SNN without the need to convert to a spike-train. The reduced latency of our training technique combined with high activation sparsity yields significant improvements in computational efficiency. We evaluate our proposal using three HSI datasets on a 3-D and a 3-D/2-D hybrid convolutional architecture. We achieve overall accuracy, average accuracy, and kappa coefficient of 98.68%, 98.34%, and 98.20% respectively with 5 time steps (inference latency) and 6-bit weight quantization on the Indian Pines dataset. In particular, our models achieved accuracies similar to state-of-the-art (SOTA) with 560.6 and 44.8 times less compute energy on average over three HSI datasets than an iso-architecture full-precision and 6-bit quantized CNN, respectively.
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 14, 2021
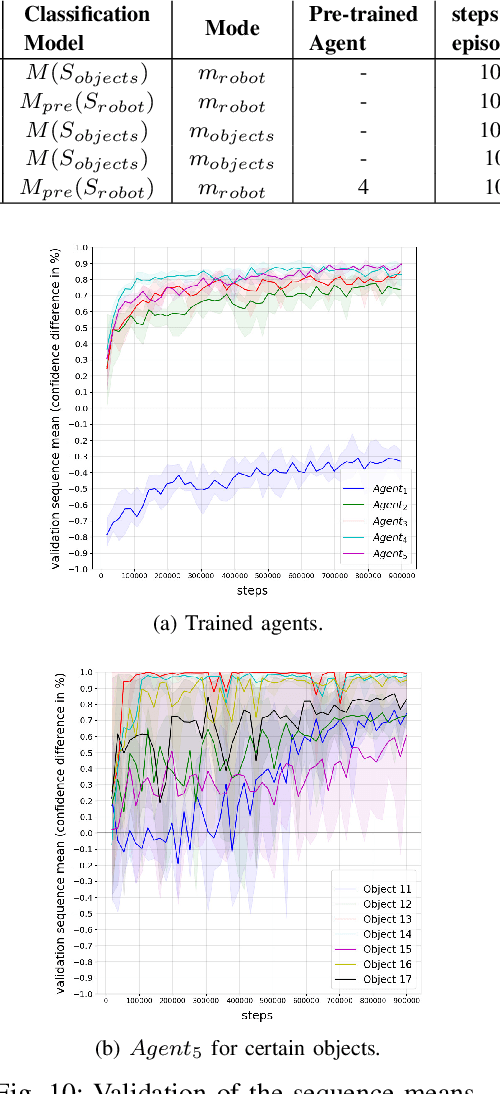
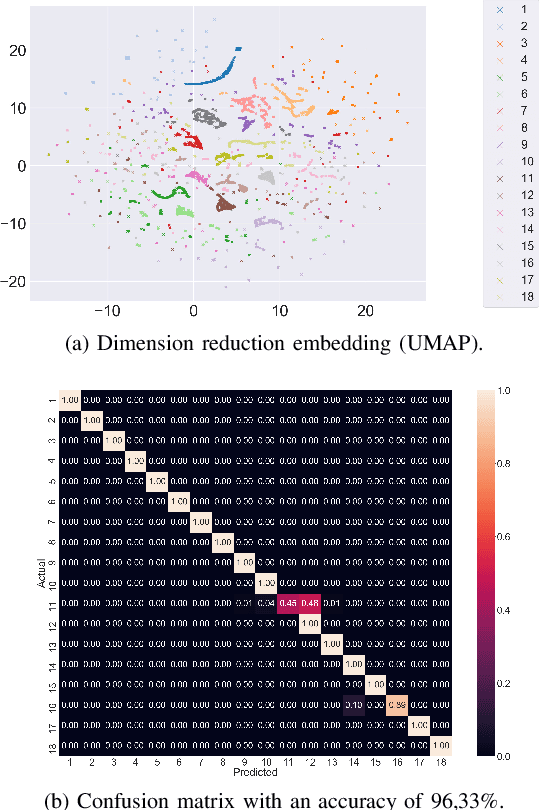
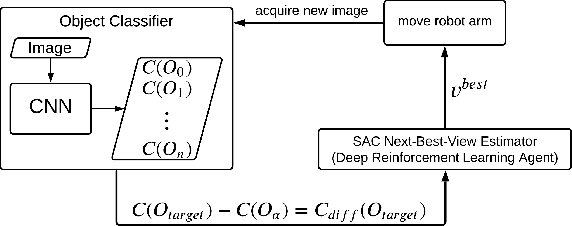
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The next-best-view problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility.
Accelerating Robotic Reinforcement Learning via Parameterized Action Primitives
Oct 28, 2021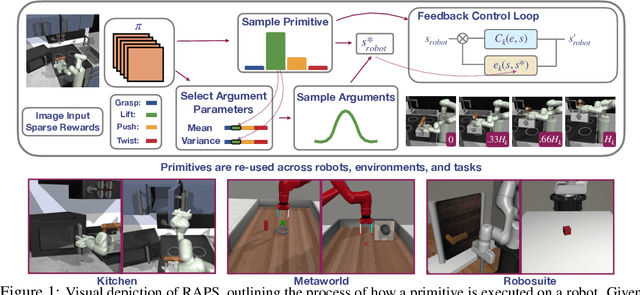


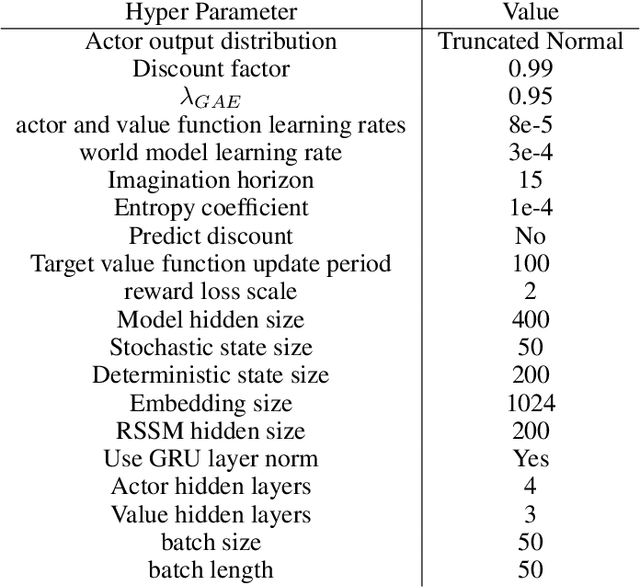
Despite the potential of reinforcement learning (RL) for building general-purpose robotic systems, training RL agents to solve robotics tasks still remains challenging due to the difficulty of exploration in purely continuous action spaces. Addressing this problem is an active area of research with the majority of focus on improving RL methods via better optimization or more efficient exploration. An alternate but important component to consider improving is the interface of the RL algorithm with the robot. In this work, we manually specify a library of robot action primitives (RAPS), parameterized with arguments that are learned by an RL policy. These parameterized primitives are expressive, simple to implement, enable efficient exploration and can be transferred across robots, tasks and environments. We perform a thorough empirical study across challenging tasks in three distinct domains with image input and a sparse terminal reward. We find that our simple change to the action interface substantially improves both the learning efficiency and task performance irrespective of the underlying RL algorithm, significantly outperforming prior methods which learn skills from offline expert data. Code and videos at https://mihdalal.github.io/raps/
Image Restoration Using Deep Regulated Convolutional Networks
Oct 19, 2019
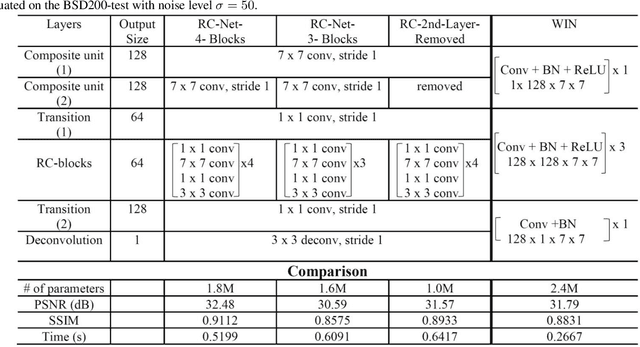
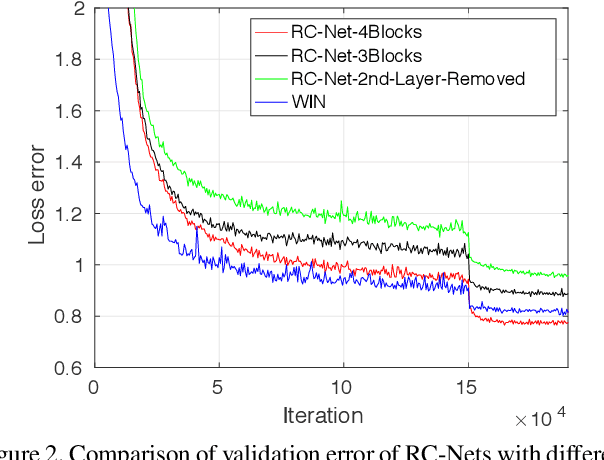

While the depth of convolutional neural networks has attracted substantial attention in the deep learning research, the width of these networks has recently received greater interest. The width of networks, defined as the size of the receptive fields and the density of the channels, has demonstrated crucial importance in low-level vision tasks such as image denoising and restoration. However, the limited generalization ability, due to the increased width of networks, creates a bottleneck in designing wider networks. In this paper, we propose the Deep Regulated Convolutional Network (RC-Net), a deep network composed of regulated sub-network blocks cascaded by skip-connections, to overcome this bottleneck. Specifically, the Regulated Convolution block (RC-block), featured by a combination of large and small convolution filters, balances the effectiveness of prominent feature extraction and the generalization ability of the network. RC-Nets have several compelling advantages: they embrace diversified features through large-small filter combinations, alleviate the hazy boundary and blurred details in image denoising and super-resolution problems, and stabilize the learning process. Our proposed RC-Nets outperform state-of-the-art approaches with significant performance gains in various image restoration tasks while demonstrating promising generalization ability. The code is available at https://github.com/cswin/RC-Nets.
Guided Evolution for Neural Architecture Search
Oct 28, 2021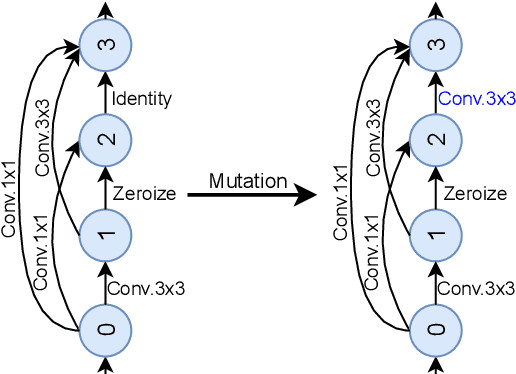
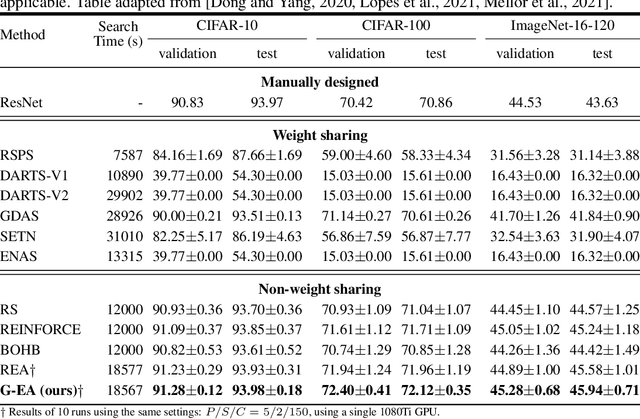
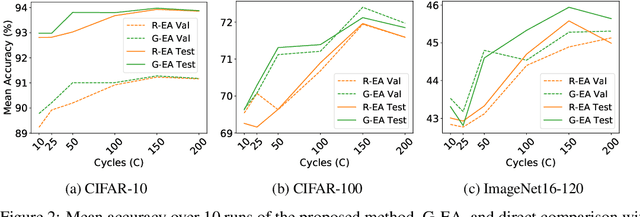
Neural Architecture Search (NAS) methods have been successfully applied to image tasks with excellent results. However, NAS methods are often complex and tend to converge to local minima as soon as generated architectures seem to yield good results. In this paper, we propose G-EA, a novel approach for guided evolutionary NAS. The rationale behind G-EA, is to explore the search space by generating and evaluating several architectures in each generation at initialization stage using a zero-proxy estimator, where only the highest-scoring network is trained and kept for the next generation. This evaluation at initialization stage allows continuous extraction of knowledge from the search space without increasing computation, thus allowing the search to be efficiently guided. Moreover, G-EA forces exploitation of the most performant networks by descendant generation while at the same time forcing exploration by parent mutation and by favouring younger architectures to the detriment of older ones. Experimental results demonstrate the effectiveness of the proposed method, showing that G-EA achieves state-of-the-art results in NAS-Bench-201 search space in CIFAR-10, CIFAR-100 and ImageNet16-120, with mean accuracies of 93.98%, 72.12% and 45.94% respectively.
Inverse Problems Leveraging Pre-trained Contrastive Representations
Oct 14, 2021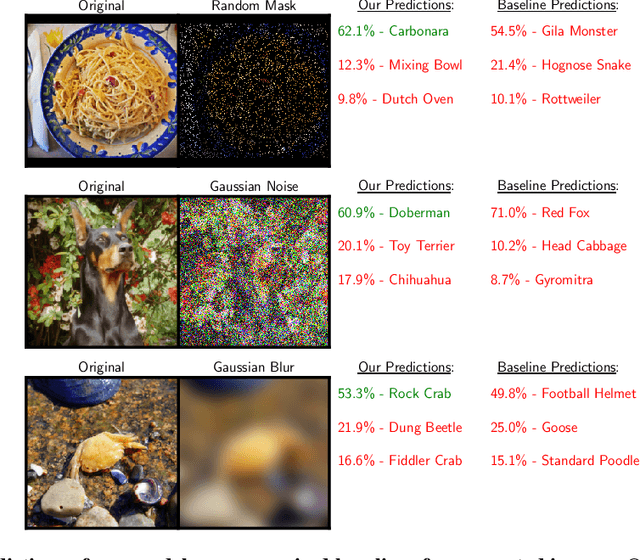
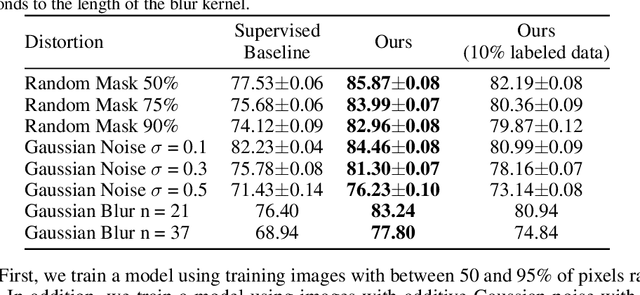
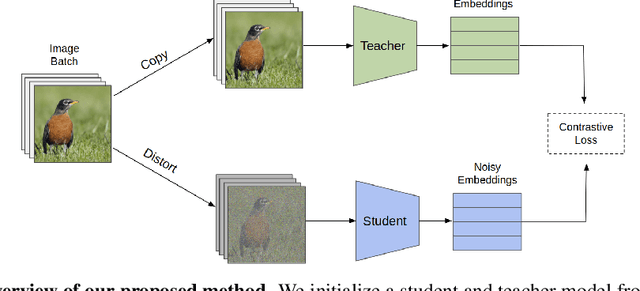
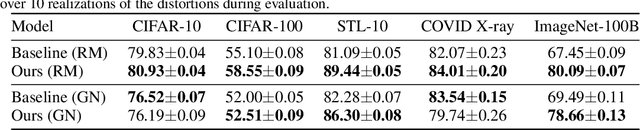
We study a new family of inverse problems for recovering representations of corrupted data. We assume access to a pre-trained representation learning network R(x) that operates on clean images, like CLIP. The problem is to recover the representation of an image R(x), if we are only given a corrupted version A(x), for some known forward operator A. We propose a supervised inversion method that uses a contrastive objective to obtain excellent representations for highly corrupted images. Using a linear probe on our robust representations, we achieve a higher accuracy than end-to-end supervised baselines when classifying images with various types of distortions, including blurring, additive noise, and random pixel masking. We evaluate on a subset of ImageNet and observe that our method is robust to varying levels of distortion. Our method outperforms end-to-end baselines even with a fraction of the labeled data in a wide range of forward operators.
Scenes and Surroundings: Scene Graph Generation using Relation Transformer
Jul 12, 2021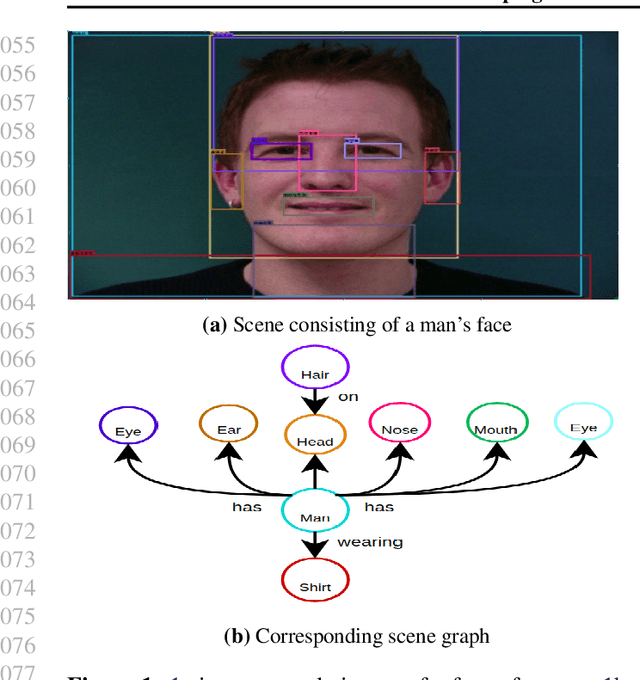
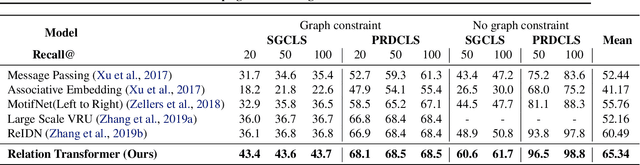
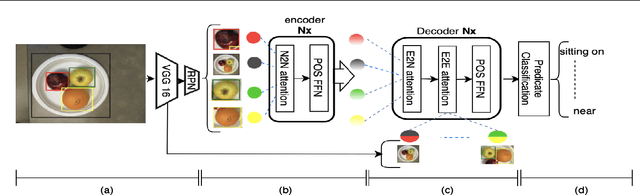
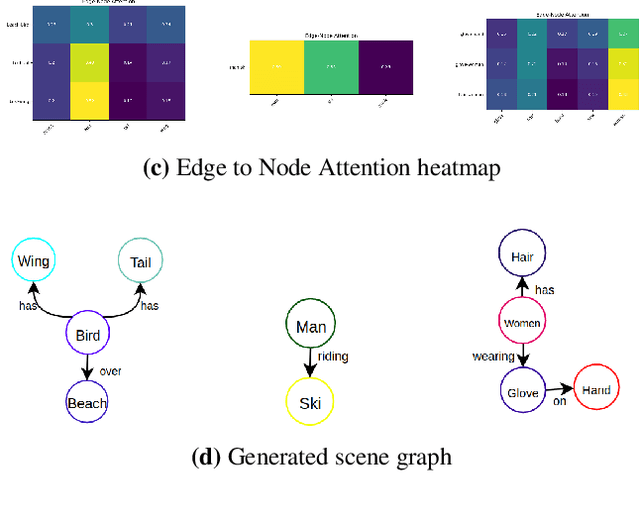
Identifying objects in an image and their mutual relationships as a scene graph leads to a deep understanding of image content. Despite the recent advancement in deep learning, the detection and labeling of visual object relationships remain a challenging task. This work proposes a novel local-context aware architecture named relation transformer, which exploits complex global objects to object and object to edge (relation) interactions. Our hierarchical multi-head attention-based approach efficiently captures contextual dependencies between objects and predicts their relationships. In comparison to state-of-the-art approaches, we have achieved an overall mean \textbf{4.85\%} improvement and a new benchmark across all the scene graph generation tasks on the Visual Genome dataset.
Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey
Feb 10, 2020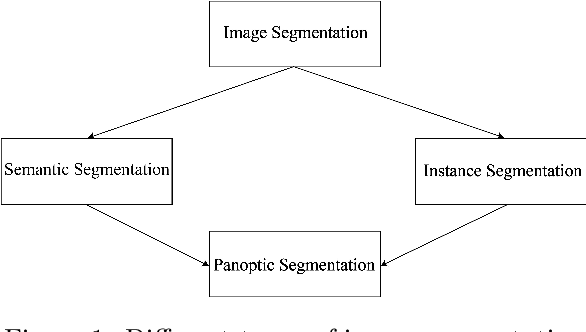
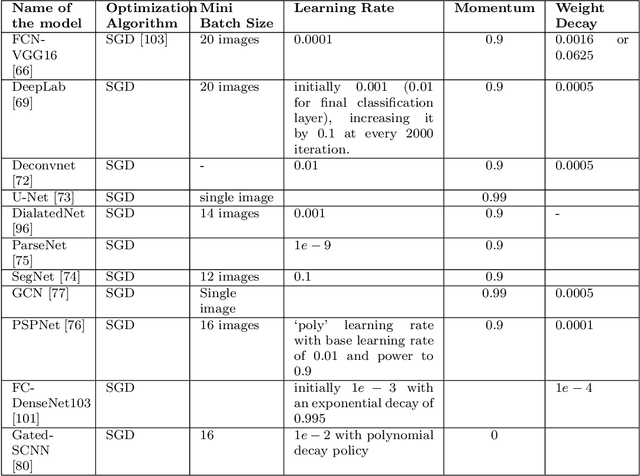
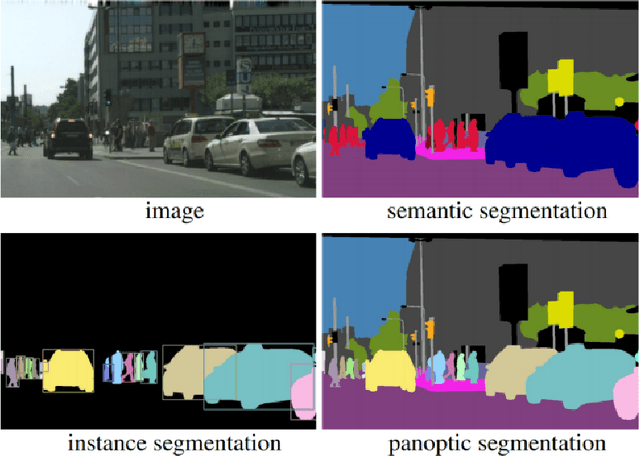
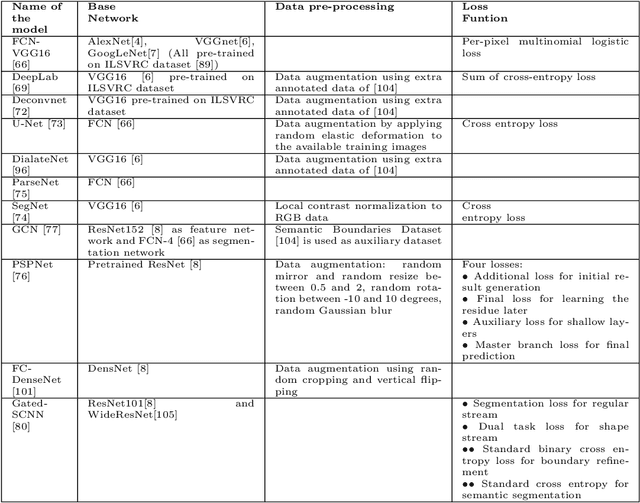
From the autonomous car driving to medical diagnosis, the requirement of the task of image segmentation is everywhere. Segmentation of an image is one of the indispensable tasks in computer vision. This task is comparatively complicated than other vision tasks as it needs low-level spatial information. Basically, image segmentation can be of two types: semantic segmentation and instance segmentation. The combined version of these two basic tasks is known as panoptic segmentation. In the recent era, the success of deep convolutional neural network (CNN) has influenced the field of segmentation greatly and gave us various successful models to date. In this survey, we are going to take a glance at the evolution of both semantic and instance segmentation work based on CNN. We have also specified comparative architectural details of some state-of-the-art models and discuss their training details to present a lucid understanding of hyper-parameter tuning of those models. Lastly, we have drawn a comparison among the performance of those models on different datasets.