 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Meta-class Memory for Few-Shot Semantic Segmentation
Aug 16, 2021
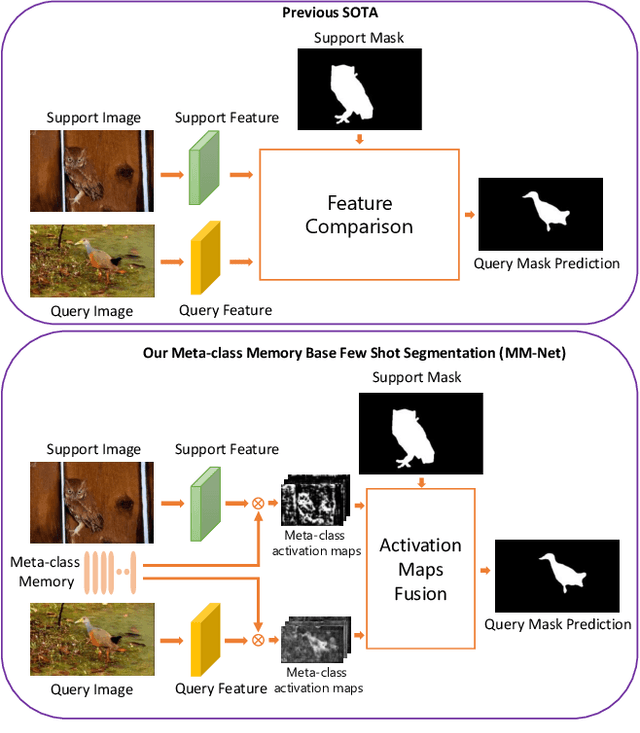
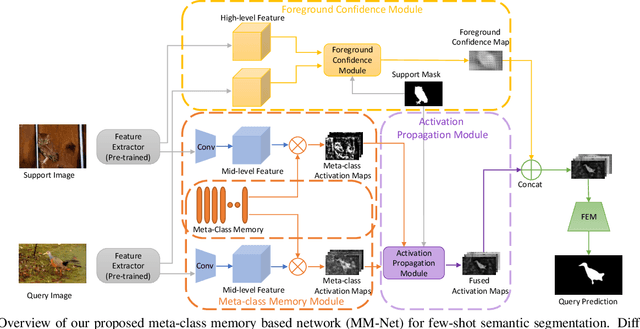
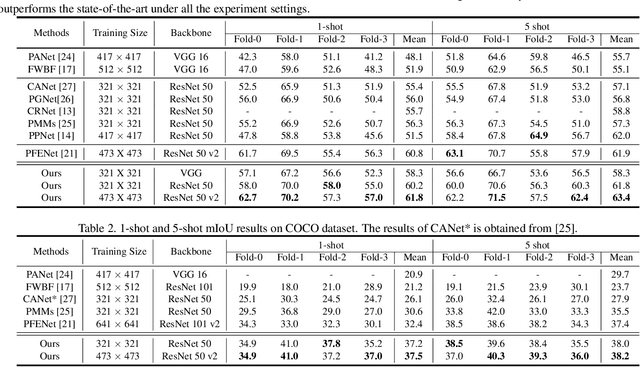
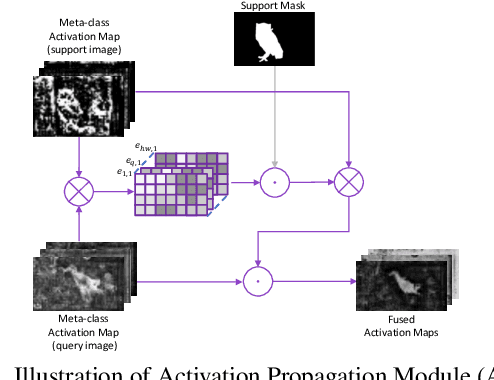
Currently, the state-of-the-art methods treat few-shot semantic segmentation task as a conditional foreground-background segmentation problem, assuming each class is independent. In this paper, we introduce the concept of meta-class, which is the meta information (e.g. certain middle-level features) shareable among all classes. To explicitly learn meta-class representations in few-shot segmentation task, we propose a novel Meta-class Memory based few-shot segmentation method (MM-Net), where we introduce a set of learnable memory embeddings to memorize the meta-class information during the base class training and transfer to novel classes during the inference stage. Moreover, for the $k$-shot scenario, we propose a novel image quality measurement module to select images from the set of support images. A high-quality class prototype could be obtained with the weighted sum of support image features based on the quality measure. Experiments on both PASCAL-$5^i$ and COCO dataset shows that our proposed method is able to achieve state-of-the-art results in both 1-shot and 5-shot settings. Particularly, our proposed MM-Net achieves 37.5\% mIoU on the COCO dataset in 1-shot setting, which is 5.1\% higher than the previous state-of-the-art.
DiagSet: a dataset for prostate cancer histopathological image classification
May 09, 2021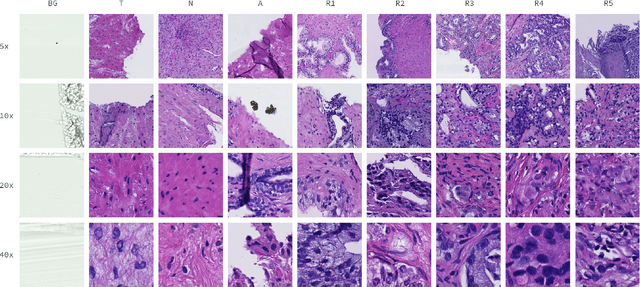

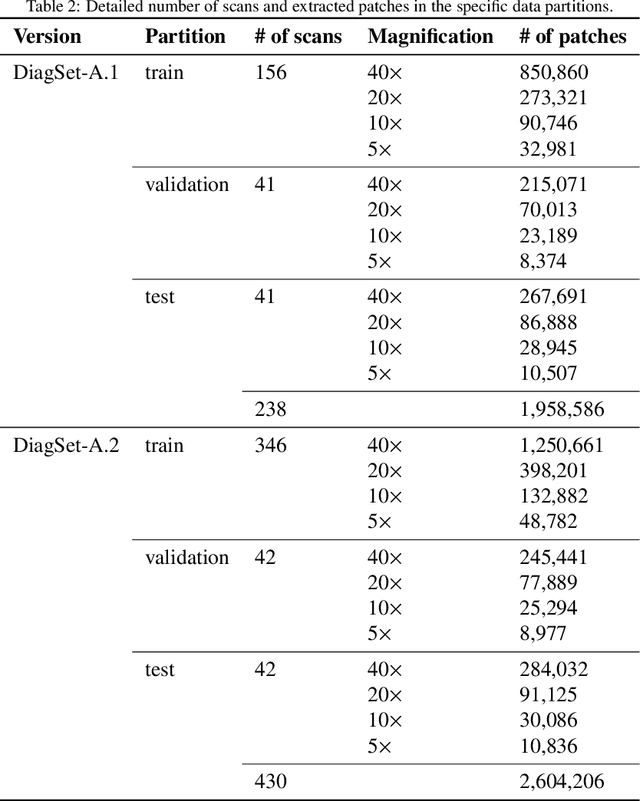
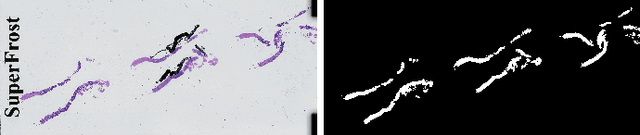
Cancer diseases constitute one of the most significant societal challenges. In this paper we introduce a novel histopathological dataset for prostate cancer detection. The proposed dataset, consisting of over 2.6 million tissue patches extracted from 430 fully annotated scans, 4675 scans with assigned binary diagnosis, and 46 scans with diagnosis given independently by a group of histopathologists, can be found at https://ai-econsilio.diag.pl. Furthermore, we propose a machine learning framework for detection of cancerous tissue regions and prediction of scan-level diagnosis, utilizing thresholding and statistical analysis to abstain from the decision in uncertain cases. During the experimental evaluation we identify several factors negatively affecting the performance of considered models, such as presence of label noise, data imbalance, and quantity of data, that can serve as a basis for further research. The proposed approach, composed of ensembles of deep neural networks operating on the histopathological scans at different scales, achieves 94.6% accuracy in patch-level recognition, and is compared in a scan-level diagnosis with 9 human histopathologists.
Soft Sensing Transformer: Hundreds of Sensors are Worth a Single Word
Nov 10, 2021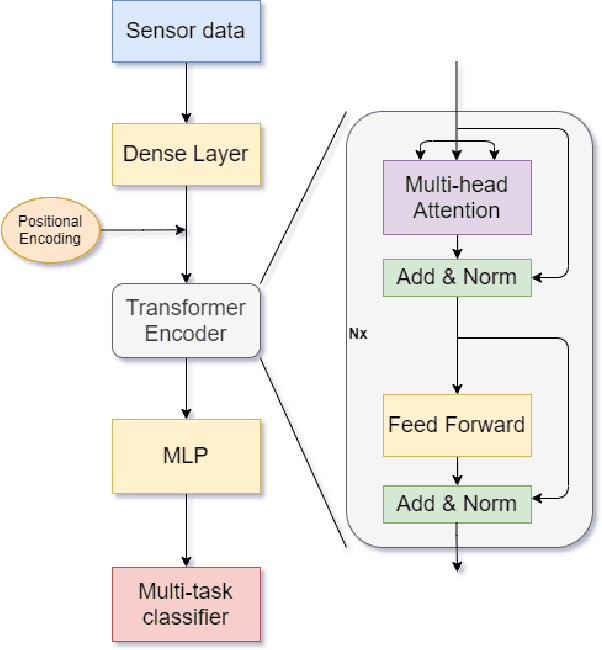

With the rapid development of AI technology in recent years, there have been many studies with deep learning models in soft sensing area. However, the models have become more complex, yet, the data sets remain limited: researchers are fitting million-parameter models with hundreds of data samples, which is insufficient to exercise the effectiveness of their models and thus often fail to perform when implemented in industrial applications. To solve this long-lasting problem, we are providing large scale, high dimensional time series manufacturing sensor data from Seagate Technology to the public. We demonstrate the challenges and effectiveness of modeling industrial big data by a Soft Sensing Transformer model on these data sets. Transformer is used because, it has outperformed state-of-the-art techniques in Natural Language Processing, and since then has also performed well in the direct application to computer vision without introduction of image-specific inductive biases. We observe the similarity of a sentence structure to the sensor readings and process the multi-variable sensor readings in a time series in a similar manner of sentences in natural language. The high-dimensional time-series data is formatted into the same shape of embedded sentences and fed into the transformer model. The results show that transformer model outperforms the benchmark models in soft sensing field based on auto-encoder and long short-term memory (LSTM) models. To the best of our knowledge, we are the first team in academia or industry to benchmark the performance of original transformer model with large-scale numerical soft sensing data.
A nonlocal feature-driven exemplar-based approach for image inpainting
Sep 20, 2019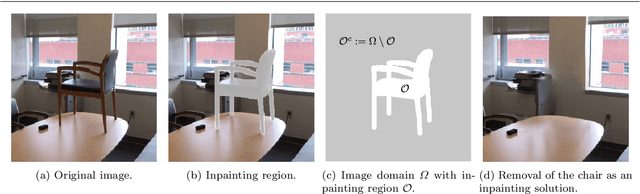
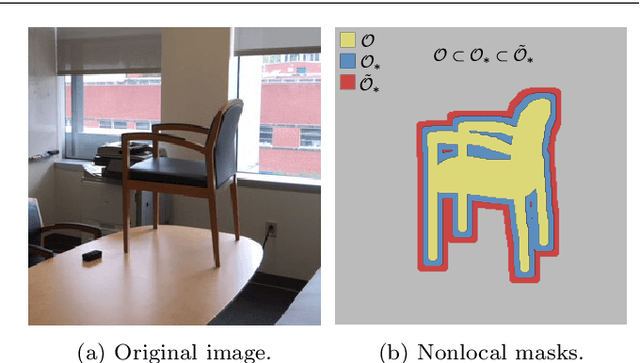


We present a nonlocal variational image completion technique which admits simultaneous inpainting of multiple structures and textures in a unified framework. The recovery of geometric structures is achieved by using general convolution operators as a measure of behavior within an image. These are combined with a nonlocal exemplar-based approach to exploit the self-similarity of an image in the selected feature domains and to ensure the inpainting of textures. We also introduce an anisotropic patch distance metric to allow for better control of the feature selection within an image and present a nonlocal energy functional based on this metric. Finally, we derive an optimization algorithm for the proposed variational model and examine its validity experimentally with various test images.
Complete Scanning Application Using OpenCv
Jul 08, 2021In the following paper, we have combined the various basic functionalities provided by the NumPy library and OpenCv library, which is an open source for Computer Vision applications, like conversion of colored images to grayscale, calculating threshold, finding contours and using those contour points to take perspective transform of the image inputted by the user, using Python version 3.7. Additional features include cropping, rotating and saving as well. All these functions and features, when implemented step by step, results in a complete scanning application. The applied procedure involves the following steps: Finding contours, applying Perspective transform and brightening the image, Adaptive Thresholding and applying filters for noise cancellation, and Rotation features and perspective transform for a special cropping algorithm. The described technique is implemented on various samples.
When in Doubt, Summon the Titans: Efficient Inference with Large Models
Oct 19, 2021
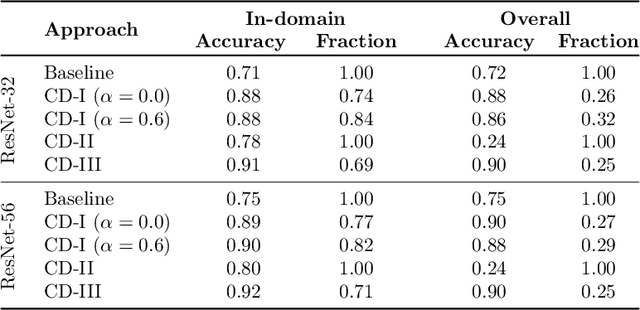
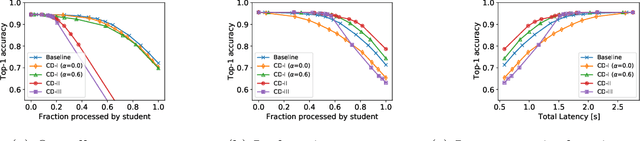
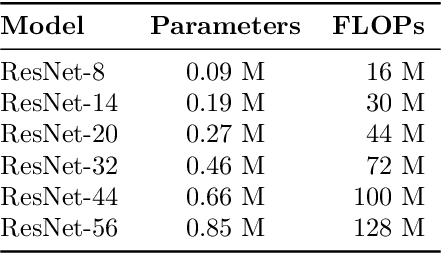
Scaling neural networks to "large" sizes, with billions of parameters, has been shown to yield impressive results on many challenging problems. However, the inference cost incurred by such large models often prevents their application in most real-world settings. In this paper, we propose a two-stage framework based on distillation that realizes the modelling benefits of the large models, while largely preserving the computational benefits of inference with more lightweight models. In a nutshell, we use the large teacher models to guide the lightweight student models to only make correct predictions on a subset of "easy" examples; for the "hard" examples, we fall-back to the teacher. Such an approach allows us to efficiently employ large models in practical scenarios where easy examples are much more frequent than rare hard examples. Our proposed use of distillation to only handle easy instances allows for a more aggressive trade-off in the student size, thereby reducing the amortized cost of inference and achieving better accuracy than standard distillation. Empirically, we demonstrate the benefits of our approach on both image classification and natural language processing benchmarks.
Light Field Synthesis by Training Deep Network in the Refocused Image Domain
Nov 07, 2019

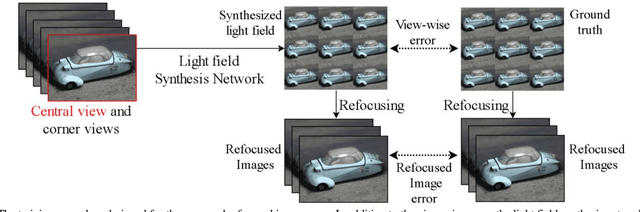
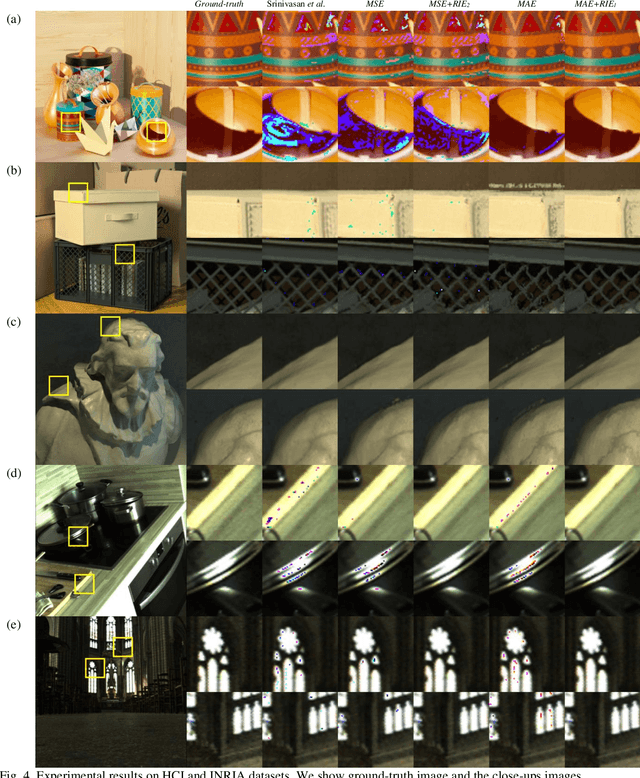
Light field imaging, which captures spatio-angular information of incident light on image sensor, enables many interesting applications like image refocusing and augmented reality. However, due to the limited sensor resolution, a trade-off exists between the spatial and angular resolution. To increase the angular resolution, view synthesis techniques have been adopted to generate new views from existing views. However, traditional learning-based view synthesis mainly considers the image quality of each view of the light field and neglects the quality of the refocused images. In this paper, we propose a new loss function called refocused image error (RIE) to address the issue. The main idea is that the image quality of the synthesized light field should be optimized in the refocused image domain because it is where the light field is perceived. We analyze the behavior of RIL in the spectral domain and test the performance of our approach against previous approaches on both real and software-rendered light field datasets using objective assessment metrics such as MSE, MAE, PSNR, SSIM, and GMSD. Experimental results show that the light field generated by our method results in better refocused images than previous methods.
Deep Super-Resolution Network for Single Image Super-Resolution with Realistic Degradations
Sep 09, 2019
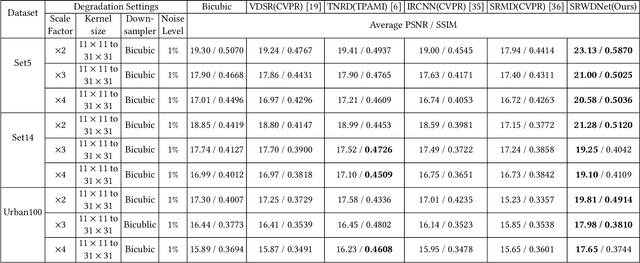

Single Image Super-Resolution (SISR) aims to generate a high-resolution (HR) image of a given low-resolution (LR) image. The most of existing convolutional neural network (CNN) based SISR methods usually take an assumption that a LR image is only bicubicly down-sampled version of an HR image. However, the true degradation (i.e. the LR image is a bicubicly downsampled, blurred and noisy version of an HR image) of a LR image goes beyond the widely used bicubic assumption, which makes the SISR problem highly ill-posed nature of inverse problems. To address this issue, we propose a deep SISR network that works for blur kernels of different sizes, and different noise levels in an unified residual CNN-based denoiser network, which significantly improves a practical CNN-based super-resolver for real applications. Extensive experimental results on synthetic LR datasets and real images demonstrate that our proposed method not only can produce better results on more realistic degradation but also computational efficient to practical SISR applications.
* 7 pages
Image Difficulty Curriculum for Generative Adversarial Networks (CuGAN)
Oct 20, 2019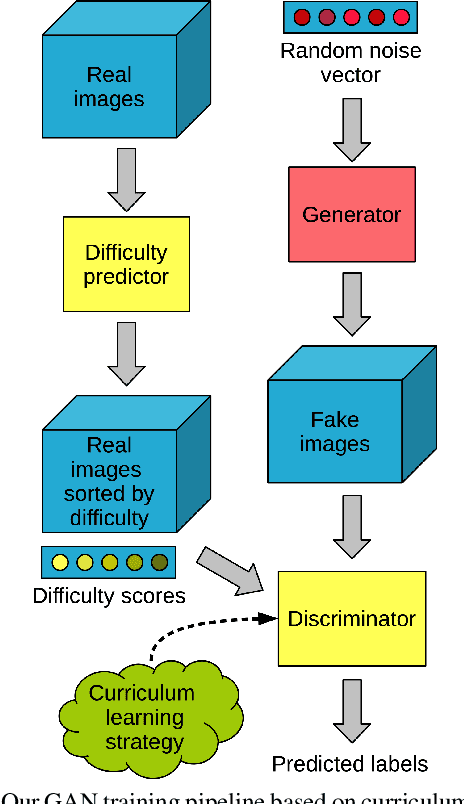


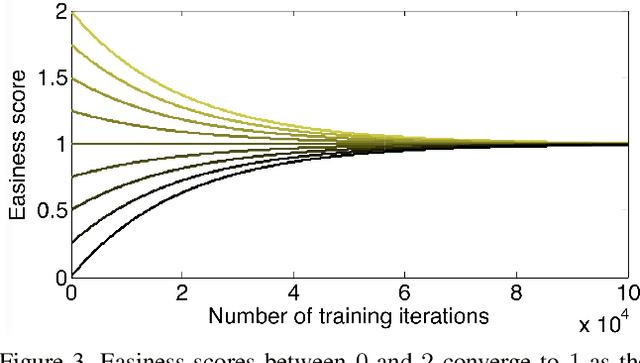
Despite the significant advances in recent years, Generative Adversarial Networks (GANs) are still notoriously hard to train. In this paper, we propose three novel curriculum learning strategies for training GANs. All strategies are first based on ranking the training images by their difficulty scores, which are estimated by a state-of-the-art image difficulty predictor. Our first strategy is to divide images into gradually more difficult batches. Our second strategy introduces a novel curriculum loss function for the discriminator that takes into account the difficulty scores of the real images. Our third strategy is based on sampling from an evolving distribution, which favors the easier images during the initial training stages and gradually converges to a uniform distribution, in which samples are equally likely, regardless of difficulty. We compare our curriculum learning strategies with the classic training procedure on two tasks: image generation and image translation. Our experiments indicate that all strategies provide faster convergence and superior results. For example, our best curriculum learning strategy applied on spectrally normalized GANs (SNGANs) fooled human annotators in thinking that generated CIFAR-like images are real in 25.0% of the presented cases, while the SNGANs trained using the classic procedure fooled the annotators in only 18.4% cases. Similarly, in image translation, the human annotators preferred the images produced by the Cycle-consistent GAN (CycleGAN) trained using curriculum learning in 40.5% cases and those produced by CycleGAN based on classic training in only 19.8% cases, $39.7\%$ cases being labeled as ties.
3dDepthNet: Point Cloud Guided Depth Completion Network for Sparse Depth and Single Color Image
Mar 20, 2020
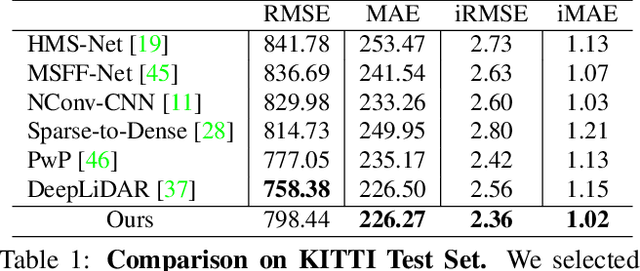


In this paper, we propose an end-to-end deep learning network named 3dDepthNet, which produces an accurate dense depth image from a single pair of sparse LiDAR depth and color image for robotics and autonomous driving tasks. Based on the dimensional nature of depth images, our network offers a novel 3D-to-2D coarse-to-fine dual densification design that is both accurate and lightweight. Depth densification is first performed in 3D space via point cloud completion, followed by a specially designed encoder-decoder structure that utilizes the projected dense depth from 3D completion and the original RGB-D images to perform 2D image completion. Experiments on the KITTI dataset show our network achieves state-of-art accuracy while being more efficient. Ablation and generalization tests prove that each module in our network has positive influences on the final results, and furthermore, our network is resilient to even sparser depth.