 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Human Shape Reconstruction from a Polarization Image
Jul 17, 2020
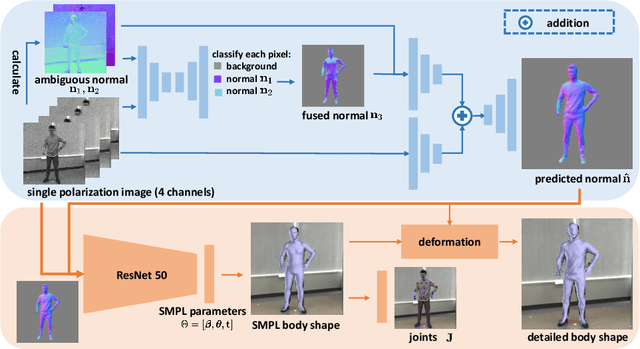
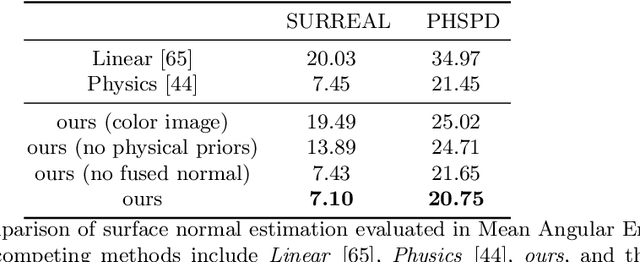


This paper tackles the problem of estimating 3D body shape of clothed humans from single polarized 2D images, i.e. polarization images. Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing surface normal of the objects of interest. Inspired by the recent advances in human shape estimation from single color images, in this paper, we attempt at estimating human body shapes by leveraging the geometric cues from single polarization images. A dedicated two-stage deep learning approach, SfP, is proposed: given a polarization image, stage one aims at inferring the fined-detailed body surface normal; stage two gears to reconstruct the 3D body shape of clothing details. Empirical evaluations on a synthetic dataset (SURREAL) as well as a real-world dataset (PHSPD) demonstrate the qualitative and quantitative performance of our approach in estimating human poses and shapes. This indicates polarization camera is a promising alternative to the more conventional color or depth imaging for human shape estimation. Further, normal maps inferred from polarization imaging play a significant role in accurately recovering the body shapes of clothed people.
Trade-offs of Local SGD at Scale: An Empirical Study
Oct 15, 2021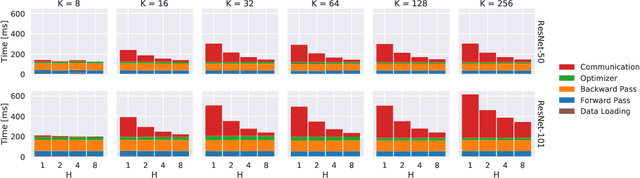
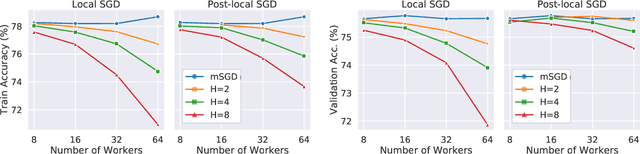
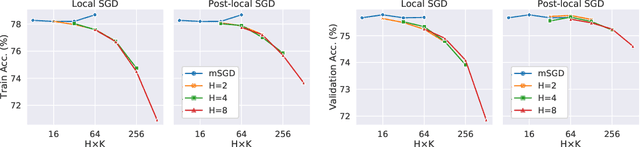
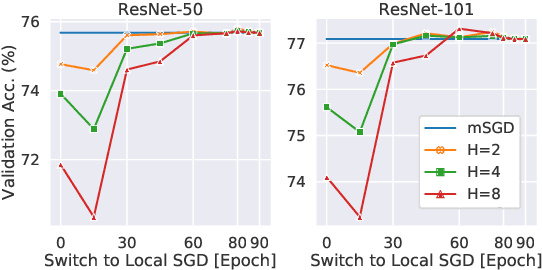
As datasets and models become increasingly large, distributed training has become a necessary component to allow deep neural networks to train in reasonable amounts of time. However, distributed training can have substantial communication overhead that hinders its scalability. One strategy for reducing this overhead is to perform multiple unsynchronized SGD steps independently on each worker between synchronization steps, a technique known as local SGD. We conduct a comprehensive empirical study of local SGD and related methods on a large-scale image classification task. We find that performing local SGD comes at a price: lower communication costs (and thereby faster training) are accompanied by lower accuracy. This finding is in contrast from the smaller-scale experiments in prior work, suggesting that local SGD encounters challenges at scale. We further show that incorporating the slow momentum framework of Wang et al. (2020) consistently improves accuracy without requiring additional communication, hinting at future directions for potentially escaping this trade-off.
Image Retrieval and Pattern Spotting using Siamese Neural Network
Jun 22, 2019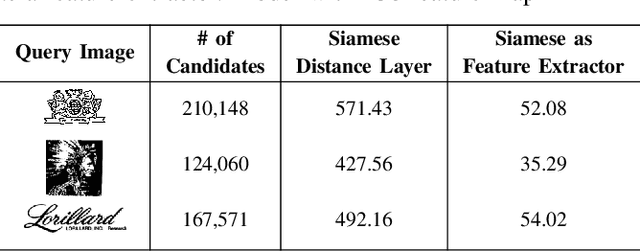
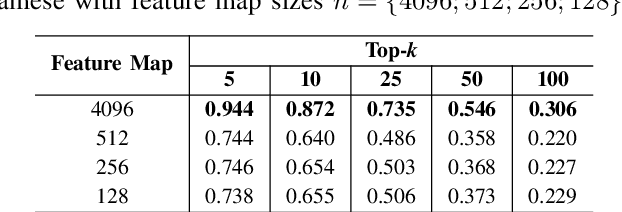
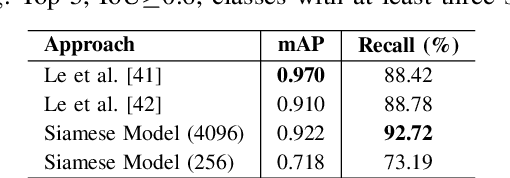

This paper presents a novel approach for image retrieval and pattern spotting in document image collections. The manual feature engineering is avoided by learning a similarity-based representation using a Siamese Neural Network trained on a previously prepared subset of image pairs from the ImageNet dataset. The learned representation is used to provide the similarity-based feature maps used to find relevant image candidates in the data collection given an image query. A robust experimental protocol based on the public Tobacco800 document image collection shows that the proposed method compares favorably against state-of-the-art document image retrieval methods, reaching 0.94 and 0.83 of mean average precision (mAP) for retrieval and pattern spotting (IoU=0.7), respectively. Besides, we have evaluated the proposed method considering feature maps of different sizes, showing the impact of reducing the number of features in the retrieval performance and time-consuming.
Fine-grained Image Classification and Retrieval by Combining Visual and Locally Pooled Textual Features
Jan 14, 2020
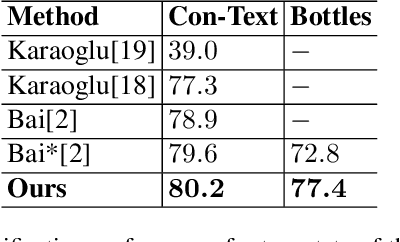
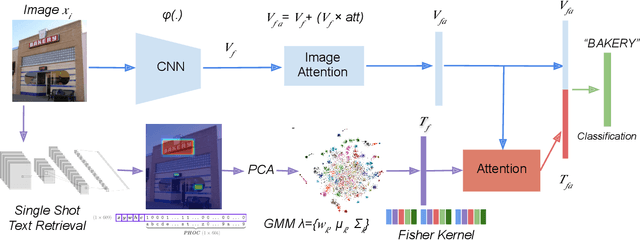
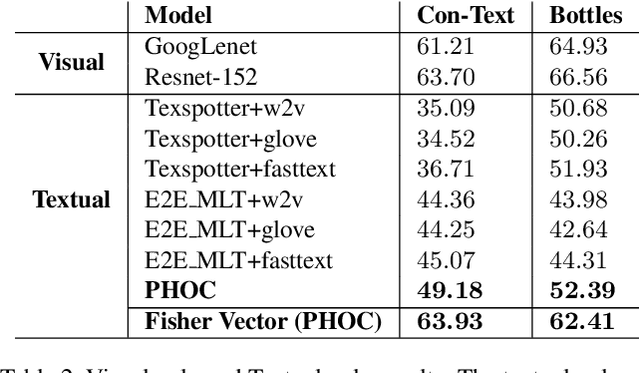
Text contained in an image carries high-level semantics that can be exploited to achieve richer image understanding. In particular, the mere presence of text provides strong guiding content that should be employed to tackle a diversity of computer vision tasks such as image retrieval, fine-grained classification, and visual question answering. In this paper, we address the problem of fine-grained classification and image retrieval by leveraging textual information along with visual cues to comprehend the existing intrinsic relation between the two modalities. The novelty of the proposed model consists of the usage of a PHOC descriptor to construct a bag of textual words along with a Fisher Vector Encoding that captures the morphology of text. This approach provides a stronger multimodal representation for this task and as our experiments demonstrate, it achieves state-of-the-art results on two different tasks, fine-grained classification and image retrieval.
Cloud removal in remote sensing images using generative adversarial networks and SAR-to-optical image translation
Dec 22, 2020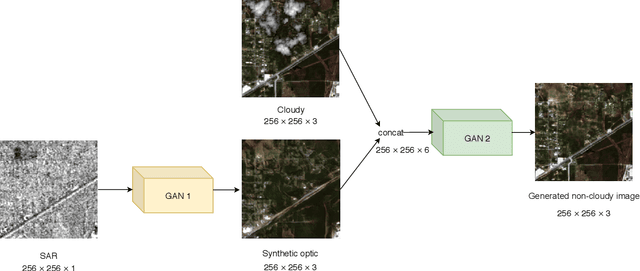
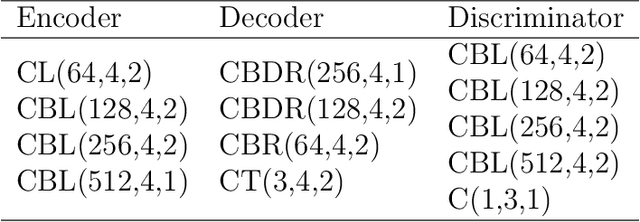

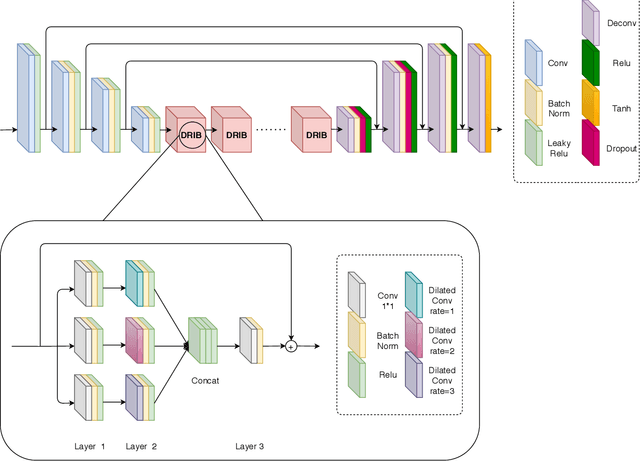
Satellite images are often contaminated by clouds. Cloud removal has received much attention due to the wide range of satellite image applications. As the clouds thicken, the process of removing the clouds becomes more challenging. In such cases, using auxiliary images such as near-infrared or synthetic aperture radar (SAR) for reconstructing is common. In this study, we attempt to solve the problem using two generative adversarial networks (GANs). The first translates SAR images into optical images, and the second removes clouds using the translated images of prior GAN. Also, we propose dilated residual inception blocks (DRIBs) instead of vanilla U-net in the generator networks and use structural similarity index measure (SSIM) in addition to the L1 Loss function. Reducing the number of downsamplings and expanding receptive fields by dilated convolutions increase the quality of output images. We used the SEN1-2 dataset to train and test both GANs, and we made cloudy images by adding synthetic clouds to optical images. The restored images are evaluated with PSNR and SSIM. We compare the proposed method with state-of-the-art deep learning models and achieve more accurate results in both SAR-to-optical translation and cloud removal parts.
Text is NOT Enough: Integrating Visual Impressions into Open-domain Dialogue Generation
Sep 18, 2021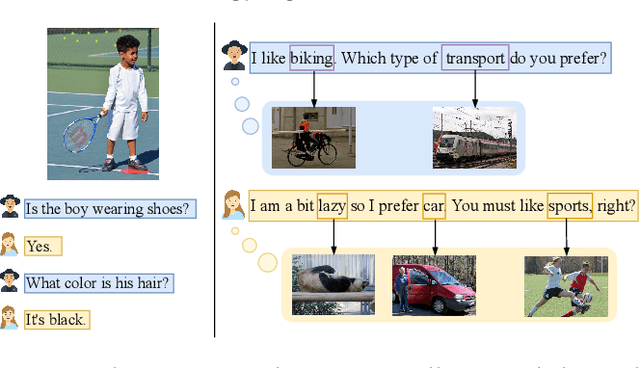
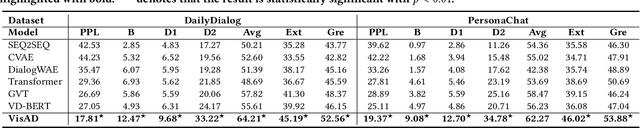
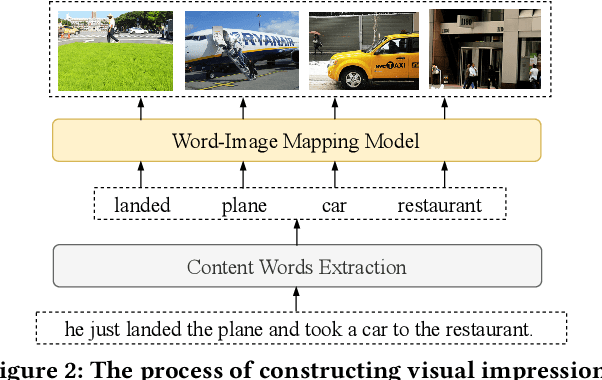
Open-domain dialogue generation in natural language processing (NLP) is by default a pure-language task, which aims to satisfy human need for daily communication on open-ended topics by producing related and informative responses. In this paper, we point out that hidden images, named as visual impressions (VIs), can be explored from the text-only data to enhance dialogue understanding and help generate better responses. Besides, the semantic dependency between an dialogue post and its response is complicated, e.g., few word alignments and some topic transitions. Therefore, the visual impressions of them are not shared, and it is more reasonable to integrate the response visual impressions (RVIs) into the decoder, rather than the post visual impressions (PVIs). However, both the response and its RVIs are not given directly in the test process. To handle the above issues, we propose a framework to explicitly construct VIs based on pure-language dialogue datasets and utilize them for better dialogue understanding and generation. Specifically, we obtain a group of images (PVIs) for each post based on a pre-trained word-image mapping model. These PVIs are used in a co-attention encoder to get a post representation with both visual and textual information. Since the RVIs are not provided directly during testing, we design a cascade decoder that consists of two sub-decoders. The first sub-decoder predicts the content words in response, and applies the word-image mapping model to get those RVIs. Then, the second sub-decoder generates the response based on the post and RVIs. Experimental results on two open-domain dialogue datasets show that our proposed approach achieves superior performance over competitive baselines.
An Underwater Image Semantic Segmentation Method Focusing on Boundaries and a Real Underwater Scene Semantic Segmentation Dataset
Aug 26, 2021With the development of underwater object grabbing technology, underwater object recognition and segmentation of high accuracy has become a challenge. The existing underwater object detection technology can only give the general position of an object, unable to give more detailed information such as the outline of the object, which seriously affects the grabbing efficiency. To address this problem, we label and establish the first underwater semantic segmentation dataset of real scene(DUT-USEG:DUT Underwater Segmentation Dataset). The DUT- USEG dataset includes 6617 images, 1487 of which have semantic segmentation and instance segmentation annotations, and the remaining 5130 images have object detection box annotations. Based on this dataset, we propose a semi-supervised underwater semantic segmentation network focusing on the boundaries(US-Net: Underwater Segmentation Network). By designing a pseudo label generator and a boundary detection subnetwork, this network realizes the fine learning of boundaries between underwater objects and background, and improves the segmentation effect of boundary areas. Experiments show that the proposed method improves by 6.7% in three categories of holothurian, echinus, starfish in DUT-USEG dataset, and achieves state-of-the-art results. The DUT- USEG dataset will be released at https://github.com/baxiyi/DUT-USEG.
GetNet: Get Target Area for Image Pairing
Oct 08, 2019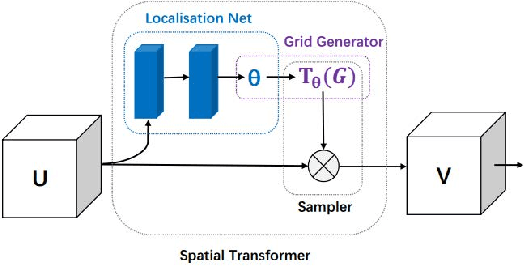
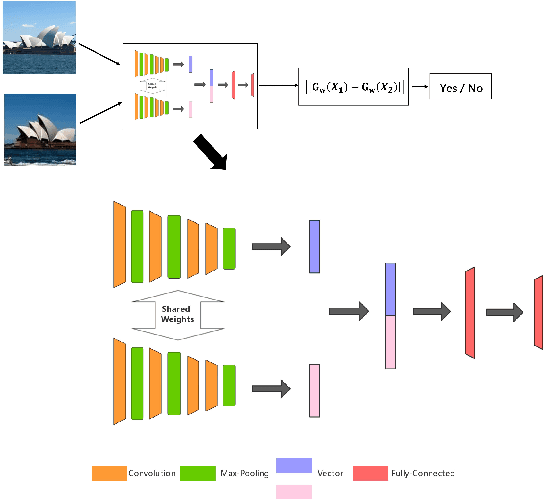
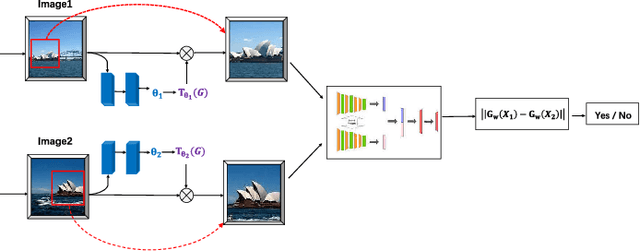

Image pairing is an important research task in the field of computer vision. And finding image pairs containing objects of the same category is the basis of many tasks such as tracking and person re-identification, etc., and it is also the focus of our research. Existing traditional methods and deep learning-based methods have some degree of defects in speed or accuracy. In this paper, we made improvements on the Siamese network and proposed GetNet. The proposed method GetNet combines STN and Siamese network to get the target area first and then perform subsequent processing. Experiments show that our method achieves competitive results in speed and accuracy.
Shadow Transfer: Single Image Relighting For Urban Road Scenes
Sep 26, 2019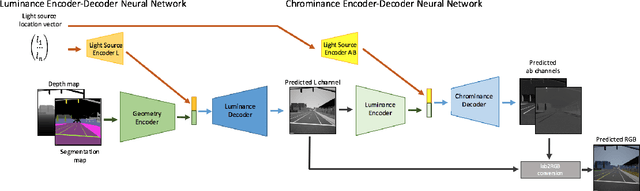



Illumination effects in images, specifically cast shadows and shading, have been shown to decrease the performance of deep neural networks on a large number of vision-based detection, recognition and segmentation tasks in urban driving scenes. A key factor that contributes to this performance gap is the lack of `time-of-day' diversity within real, labeled datasets. There have been impressive advances in the realm of image to image translation in transferring previously unseen visual effects into a dataset, specifically in day to night translation. However, it is not easy to constrain what visual effects, let alone illumination effects, are transferred from one dataset to another during the training process. To address this problem, we propose deep learning framework, called Shadow Transfer, that can relight complex outdoor scenes by transferring realistic shadow, shading, and other lighting effects onto a single image. The novelty of the proposed framework is that it is both self-supervised, and is designed to operate on sensor and label information that is easily available in autonomous vehicle datasets. We show the effectiveness of this method on both synthetic and real datasets, and we provide experiments that demonstrate that the proposed method produces images of higher visual quality than state of the art image to image translation methods.
Multi-Resolution Continuous Normalizing Flows
Jun 17, 2021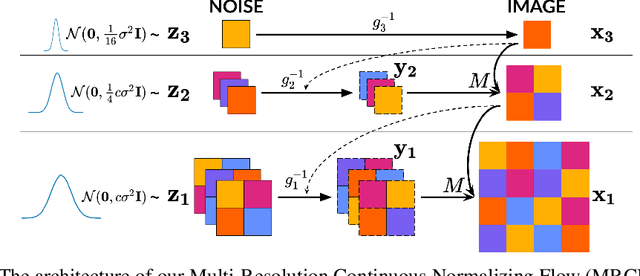
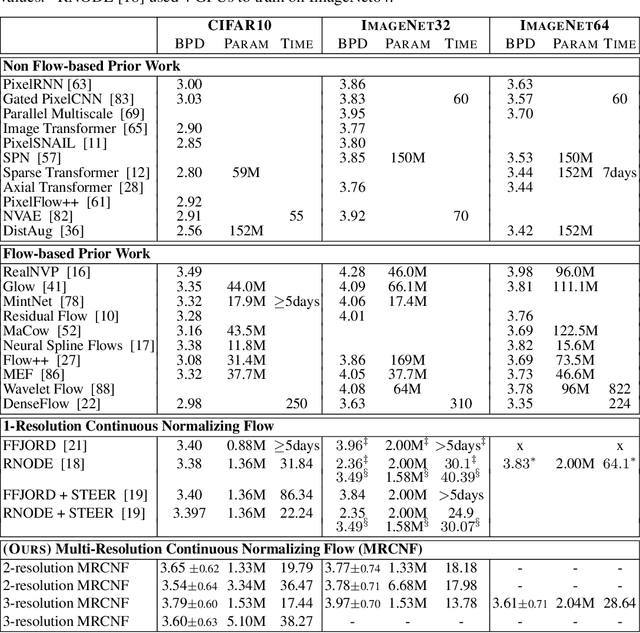
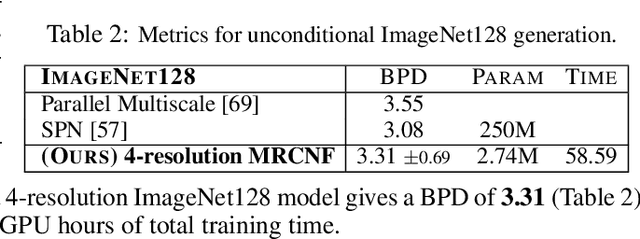

Recent work has shown that Neural Ordinary Differential Equations (ODEs) can serve as generative models of images using the perspective of Continuous Normalizing Flows (CNFs). Such models offer exact likelihood calculation, and invertible generation/density estimation. In this work we introduce a Multi-Resolution variant of such models (MRCNF), by characterizing the conditional distribution over the additional information required to generate a fine image that is consistent with the coarse image. We introduce a transformation between resolutions that allows for no change in the log likelihood. We show that this approach yields comparable likelihood values for various image datasets, with improved performance at higher resolutions, with fewer parameters, using only 1 GPU. Further, we examine the out-of-distribution properties of (Multi-Resolution) Continuous Normalizing Flows, and find that they are similar to those of other likelihood-based generative models.