 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sequential Voting with Relational Box Fields for Active Object Detection
Nov 21, 2021
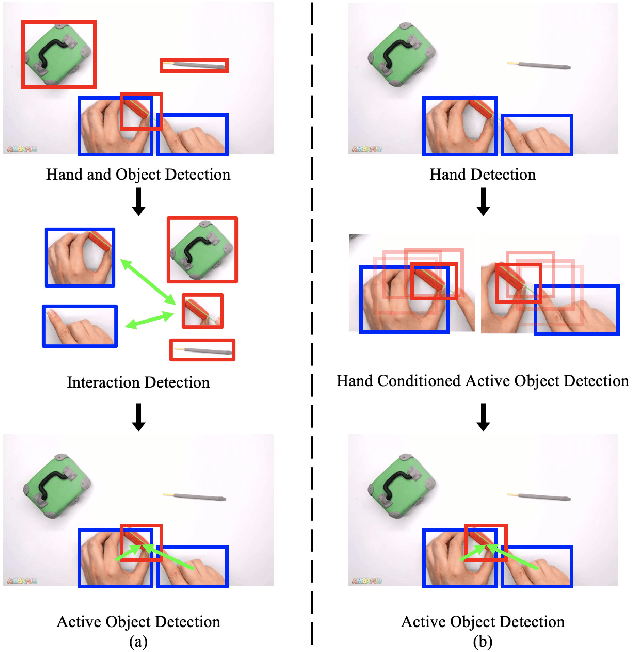

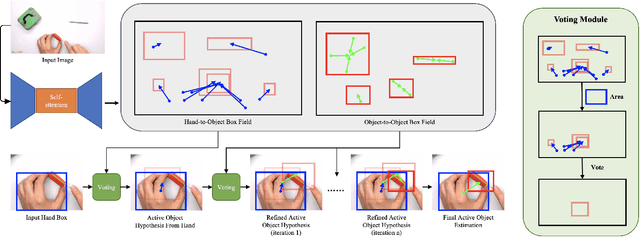

A key component of understanding hand-object interactions is the ability to identify the active object -- the object that is being manipulated by the human hand. In order to accurately localize the active object, any method must reason using information encoded by each image pixel, such as whether it belongs to the hand, the object, or the background. To leverage each pixel as evidence to determine the bounding box of the active object, we propose a pixel-wise voting function. Our pixel-wise voting function takes an initial bounding box as input and produces an improved bounding box of the active object as output. The voting function is designed so that each pixel inside of the input bounding box votes for an improved bounding box, and the box with the majority vote is selected as the output. We call the collection of bounding boxes generated inside of the voting function, the Relational Box Field, as it characterizes a field of bounding boxes defined in relationship to the current bounding box. While our voting function is able to improve the bounding box of the active object, one round of voting is typically not enough to accurately localize the active object. Therefore, we repeatedly apply the voting function to sequentially improve the location of the bounding box. However, since it is known that repeatedly applying a one-step predictor (i.e., auto-regressive processing with our voting function) can cause a data distribution shift, we mitigate this issue using reinforcement learning (RL). We adopt standard RL to learn the voting function parameters and show that it provides a meaningful improvement over a standard supervised learning approach. We perform experiments on two large-scale datasets: 100DOH and MECCANO, improving AP50 performance by 8% and 30%, respectively, over the state of the art.
AutoNovel: Automatically Discovering and Learning Novel Visual Categories
Jun 29, 2021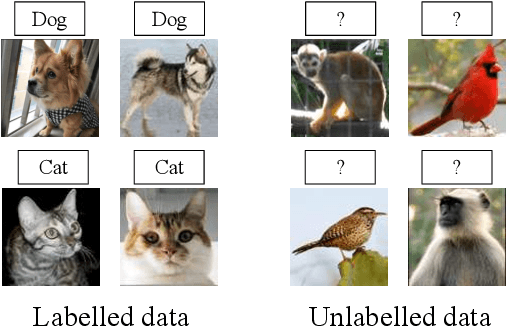
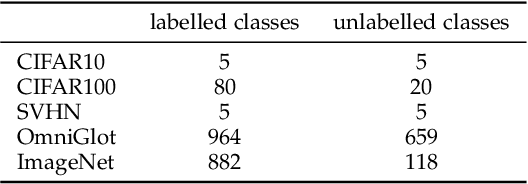

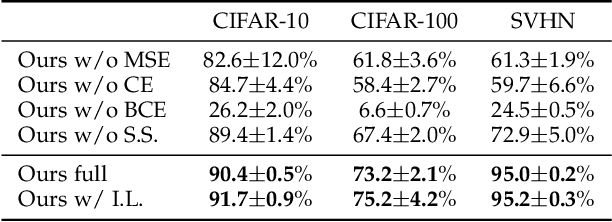
We tackle the problem of discovering novel classes in an image collection given labelled examples of other classes. We present a new approach called AutoNovel to address this problem by combining three ideas: (1) we suggest that the common approach of bootstrapping an image representation using the labelled data only introduces an unwanted bias, and that this can be avoided by using self-supervised learning to train the representation from scratch on the union of labelled and unlabelled data; (2) we use ranking statistics to transfer the model's knowledge of the labelled classes to the problem of clustering the unlabelled images; and, (3) we train the data representation by optimizing a joint objective function on the labelled and unlabelled subsets of the data, improving both the supervised classification of the labelled data, and the clustering of the unlabelled data. Moreover, we propose a method to estimate the number of classes for the case where the number of new categories is not known a priori. We evaluate AutoNovel on standard classification benchmarks and substantially outperform current methods for novel category discovery. In addition, we also show that AutoNovel can be used for fully unsupervised image clustering, achieving promising results.
Multi-Temporal Aerial Image Registration Using Semantic Features
Sep 19, 2019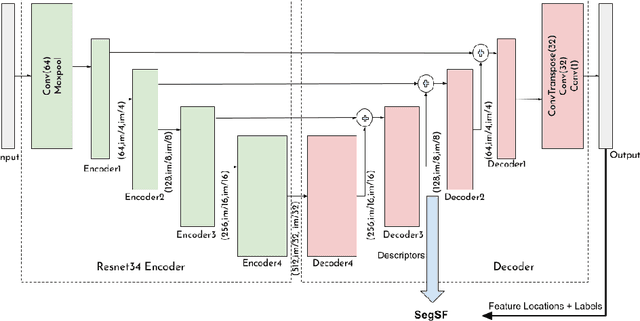


A semantic feature extraction method for multitemporal high resolution aerial image registration is proposed in this paper. These features encode properties or information about temporally invariant objects such as roads and help deal with issues such as changing foliage in image registration, which classical handcrafted features are unable to address. These features are extracted from a semantic segmentation network and have shown good robustness and accuracy in registering aerial images across years and seasons in the experiments.
Show, Edit and Tell: A Framework for Editing Image Captions
Mar 06, 2020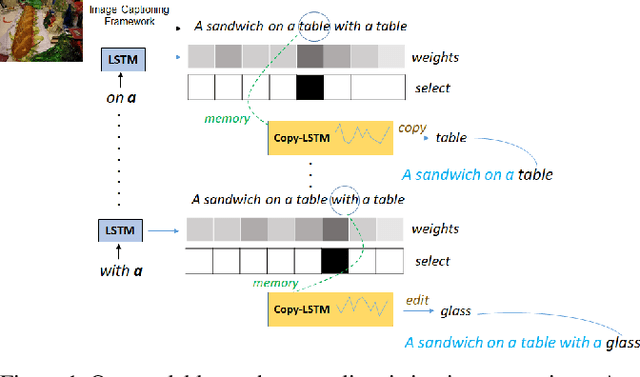
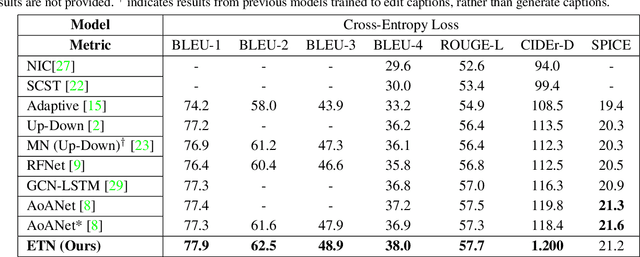
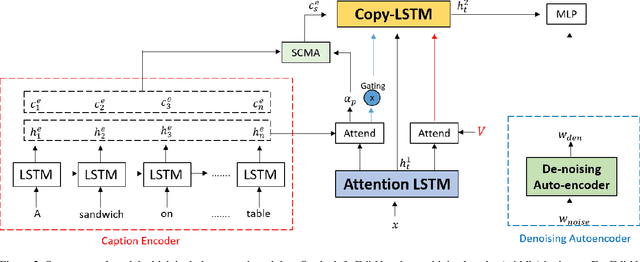
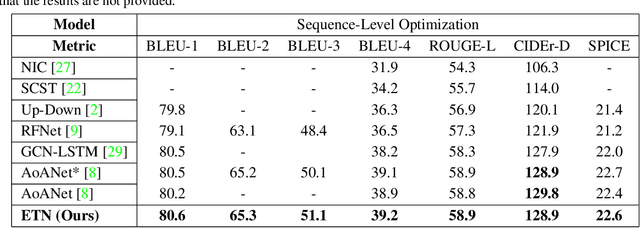
Most image captioning frameworks generate captions directly from images, learning a mapping from visual features to natural language. However, editing existing captions can be easier than generating new ones from scratch. Intuitively, when editing captions, a model is not required to learn information that is already present in the caption (i.e. sentence structure), enabling it to focus on fixing details (e.g. replacing repetitive words). This paper proposes a novel approach to image captioning based on iterative adaptive refinement of an existing caption. Specifically, our caption-editing model consisting of two sub-modules: (1) EditNet, a language module with an adaptive copy mechanism (Copy-LSTM) and a Selective Copy Memory Attention mechanism (SCMA), and (2) DCNet, an LSTM-based denoising auto-encoder. These components enable our model to directly copy from and modify existing captions. Experiments demonstrate that our new approach achieves state-of-art performance on the MS COCO dataset both with and without sequence-level training.
Creating Training Sets via Weak Indirect Supervision
Oct 07, 2021
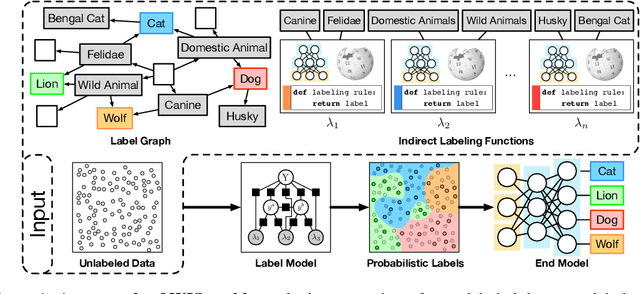
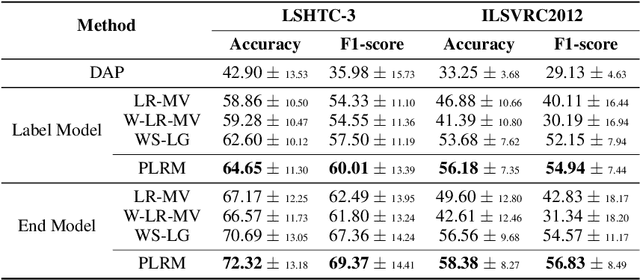
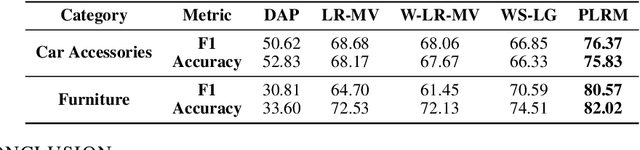
Creating labeled training sets has become one of the major roadblocks in machine learning. To address this, recent Weak Supervision (WS) frameworks synthesize training labels from multiple potentially noisy supervision sources. However, existing frameworks are restricted to supervision sources that share the same output space as the target task. To extend the scope of usable sources, we formulate Weak Indirect Supervision (WIS), a new research problem for automatically synthesizing training labels based on indirect supervision sources that have different output label spaces. To overcome the challenge of mismatched output spaces, we develop a probabilistic modeling approach, PLRM, which uses user-provided label relations to model and leverage indirect supervision sources. Moreover, we provide a theoretically-principled test of the distinguishability of PLRM for unseen labels, along with an generalization bound. On both image and text classification tasks as well as an industrial advertising application, we demonstrate the advantages of PLRM by outperforming baselines by a margin of 2%-9%.
Tomographic phase and attenuation extraction for a sample composed of unknown materials using X-ray propagation-based phase-contrast imaging
Oct 14, 2021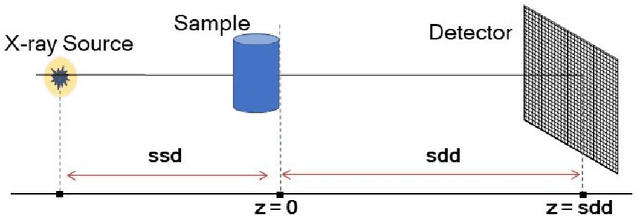
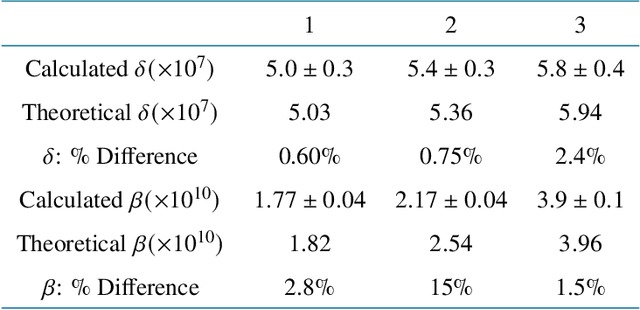
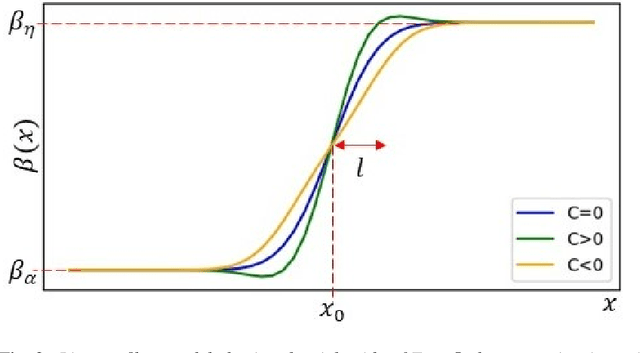
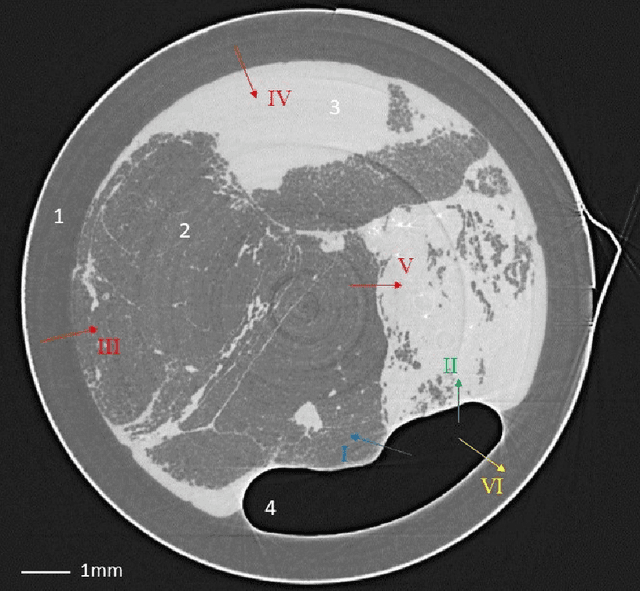
Propagation-based phase-contrast X-ray imaging (PB-PCXI) generates image contrast by utilizing sample-imposed phase-shifts. This has proven useful when imaging weakly-attenuating samples, as conventional attenuation-based imaging does not always provide adequate contrast. We present a PB-PCXI algorithm capable of extracting the X-ray attenuation, $\beta$, and refraction, $\delta$, components of the complex refractive index of distinct materials within an unknown sample. The method involves curve-fitting an error-function-based model to a phase-retrieved interface in a PB-PCXI tomographic reconstruction, which is obtained when Paganin-type phase-retrieval is applied with incorrect values of $\delta$ and $\beta$. The fit parameters can then be used to calculate true $\delta$ and $\beta$ values for composite materials. This approach requires no a priori sample information, making it broadly applicable. Our PB-PCXI reconstruction is single distance, requiring only one exposure per tomographic angle, which is important for radiosensitive samples. We apply this approach to a breast-tissue sample, recovering the refraction component, $\delta$, with 0.6 - 2.4\% accuracy compared to theoretical values.
Multi-modal gated recurrent units for image description
Apr 20, 2019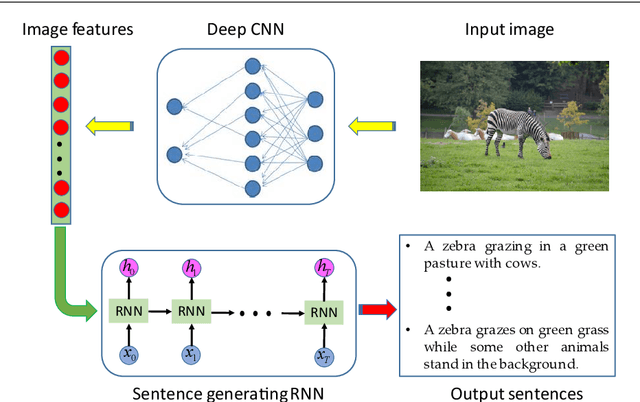
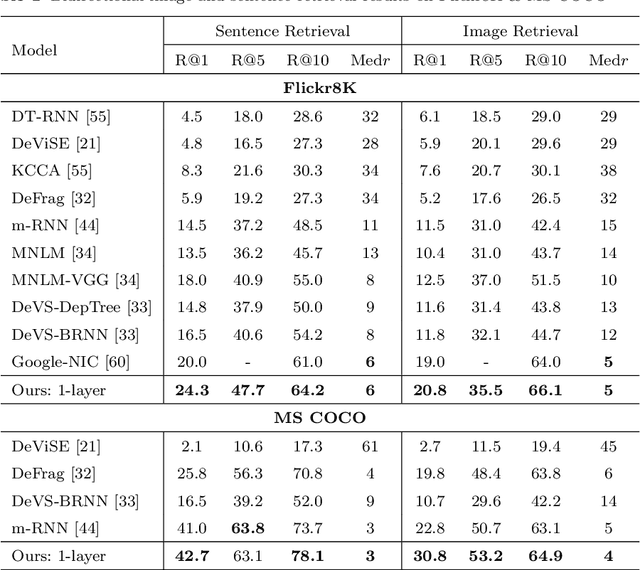
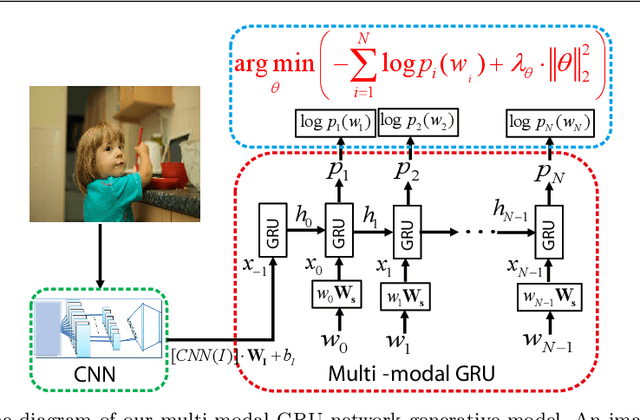
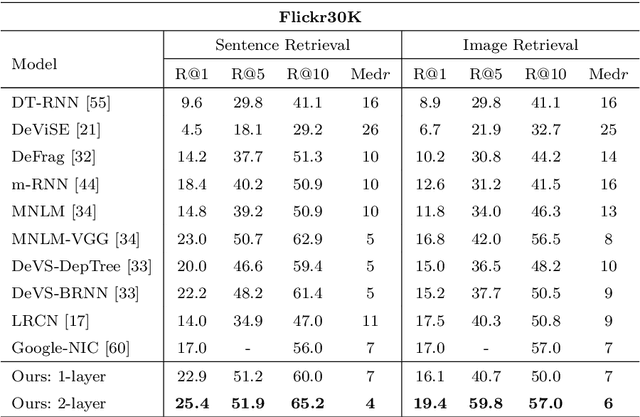
Using a natural language sentence to describe the content of an image is a challenging but very important task. It is challenging because a description must not only capture objects contained in the image and the relationships among them, but also be relevant and grammatically correct. In this paper a multi-modal embedding model based on gated recurrent units (GRU) which can generate variable-length description for a given image. In the training step, we apply the convolutional neural network (CNN) to extract the image feature. Then the feature is imported into the multi-modal GRU as well as the corresponding sentence representations. The multi-modal GRU learns the inter-modal relations between image and sentence. And in the testing step, when an image is imported to our multi-modal GRU model, a sentence which describes the image content is generated. The experimental results demonstrate that our multi-modal GRU model obtains the state-of-the-art performance on Flickr8K, Flickr30K and MS COCO datasets.
* 25 pages, 7 figures, 6 tables, magazine
Algorithmic encoding of protected characteristics and its implications on disparities across subgroups
Oct 27, 2021
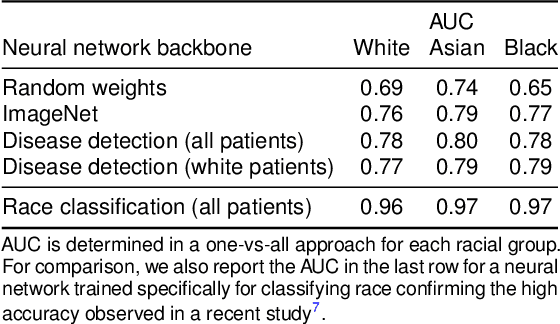
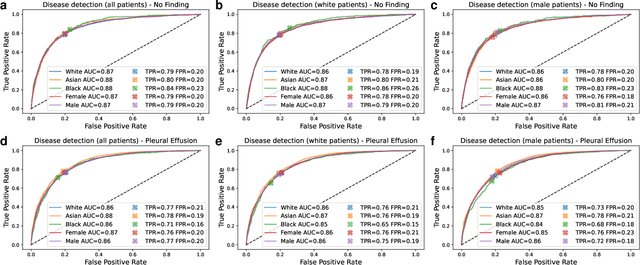
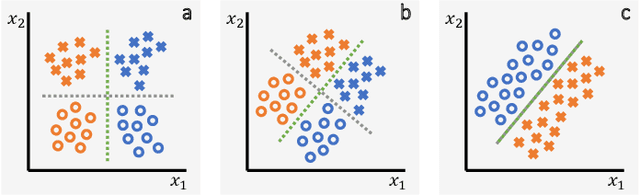
It has been rightfully emphasized that the use of AI for clinical decision making could amplify health disparities. A machine learning model may pick up undesirable correlations, for example, between a patient's racial identity and clinical outcome. Such correlations are often present in (historical) data used for model development. There has been an increase in studies reporting biases in disease detection models across patient subgroups. Besides the scarcity of data from underserved populations, very little is known about how these biases are encoded and how one may reduce or even remove disparate performance. There is some speculation whether algorithms may recognize patient characteristics such as biological sex or racial identity, and then directly or indirectly use this information when making predictions. But it remains unclear how we can establish whether such information is actually used. This article aims to shed some light on these issues by exploring new methodology allowing intuitive inspections of the inner working of machine learning models for image-based detection of disease. We also evaluate an effective yet debatable technique for addressing disparities leveraging the automatic prediction of patient characteristics, resulting in models with comparable true and false positive rates across subgroups. Our findings may stimulate the discussion about safe and ethical use of AI.
Semi-DerainGAN: A New Semi-supervised Single Image Deraining Network
Jan 23, 2020

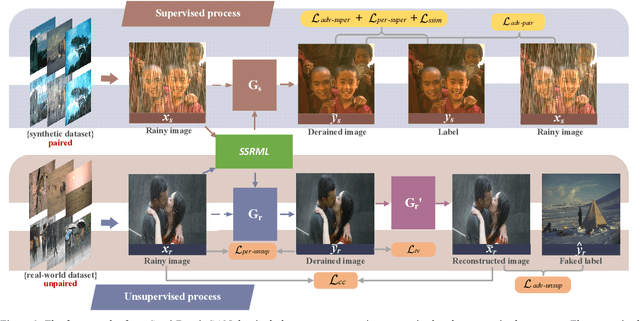
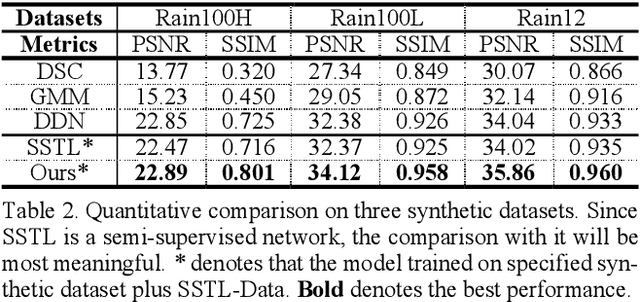
Removing the rain streaks from single image is still a challenging task, since the shapes and direc-tions of rain streaks in the synthetic datasets are very different from real images. Although super-vised deep deraining networks have obtained im-pressive results on synthetic datasets, they still cannot obtain satisfactory results on real images due to weak generalization of rain removal capac-ity, i.e., the pre-trained models usually cannot handle new shapes and directions that may lead to over-derained/under-derained results. In this paper, we propose a new semi-supervised GAN-based deraining network termed Semi-DerainGAN, which can use both synthetic and real rainy images in a uniform network using two supervised and unsupervised processes. Specifically, a semi-supervised rain streak learner termed SSRML sharing the same parameters of both processes is derived, which makes the real images contribute more rain streak information. To deliver better deraining results, we design a paired discriminator for distinguishing the real pairs from fake pairs. Note that we also contribute a new real-world rainy image dataset Real200 to alleviate the dif-ference between the synthetic and real image do-mains. Extensive results on public datasets show that our model can obtain competitive perfor-mance, especially on real images.
Using Deep Object Features for Image Descriptions
Feb 25, 2019
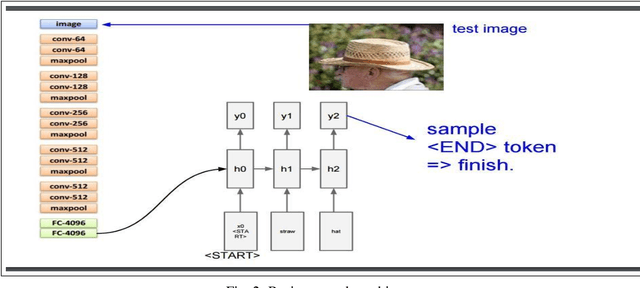
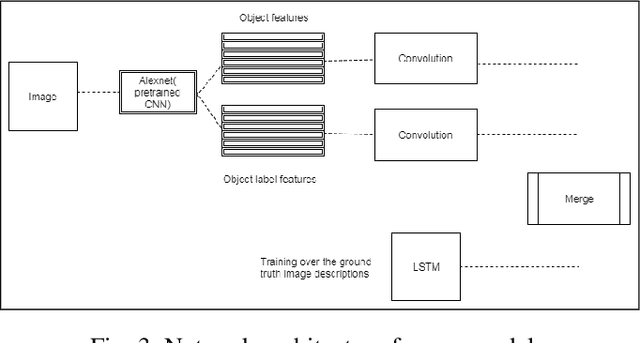

Inspired by recent advances in leveraging multiple modalities in machine translation, we introduce an encoder-decoder pipeline that uses (1) specific objects within an image and their object labels, (2) a language model for decoding joint embedding of object features and the object labels. Our pipeline merges prior detected objects from the image and their object labels and then learns the sequences of captions describing the particular image. The decoder model learns to extract descriptions for the image from scratch by decoding the joint representation of the object visual features and their object classes conditioned by the encoder component. The idea of the model is to concentrate only on the specific objects of the image and their labels for generating descriptions of the image rather than visual feature of the entire image. The model needs to be calibrated more by adjusting the parameters and settings to result in better accuracy and performance.