 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mastering Atari Games with Limited Data
Oct 30, 2021
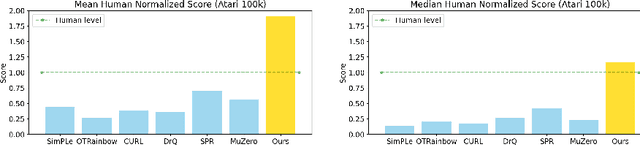
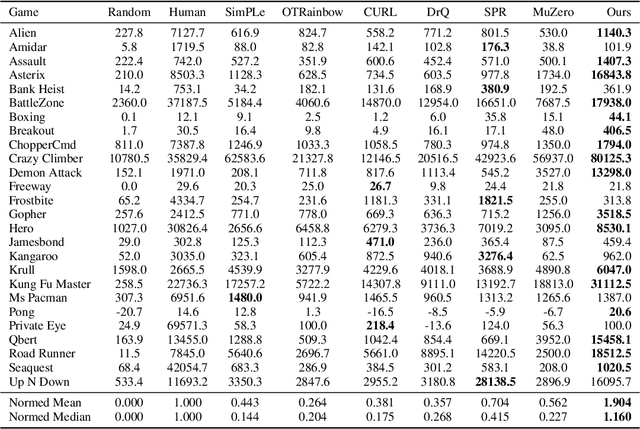
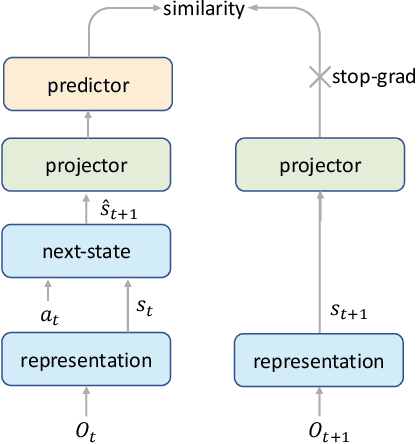

Reinforcement learning has achieved great success in many applications. However, sample efficiency remains a key challenge, with prominent methods requiring millions (or even billions) of environment steps to train. Recently, there has been significant progress in sample efficient image-based RL algorithms; however, consistent human-level performance on the Atari game benchmark remains an elusive goal. We propose a sample efficient model-based visual RL algorithm built on MuZero, which we name EfficientZero. Our method achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperforms the state SAC in some tasks on the DMControl 100k benchmark. This is the first time an algorithm achieves super-human performance on Atari games with such little data. EfficientZero's performance is also close to DQN's performance at 200 million frames while we consume 500 times less data. EfficientZero's low sample complexity and high performance can bring RL closer to real-world applicability. We implement our algorithm in an easy-to-understand manner and it is available at https://github.com/YeWR/EfficientZero. We hope it will accelerate the research of MCTS-based RL algorithms in the wider community.
A Review of Machine Learning Techniques for Applied Eye Fundus and Tongue Digital Image Processing with Diabetes Management System
Dec 30, 2020Diabetes is a global epidemic and it is increasing at an alarming rate. The International Diabetes Federation (IDF) projected that the total number of people with diabetes globally may increase by 48%, from 425 million (year 2017) to 629 million (year 2045). Moreover, diabetes had caused millions of deaths and the number is increasing drastically. Therefore, this paper addresses the background of diabetes and its complications. In addition, this paper investigates innovative applications and past researches in the areas of diabetes management system with applied eye fundus and tongue digital images. Different types of existing applied eye fundus and tongue digital image processing with diabetes management systems in the market and state-of-the-art machine learning techniques from previous literature have been reviewed. The implication of this paper is to have an overview in diabetic research and what new machine learning techniques can be proposed in solving this global epidemic.
Deep Face Video Inpainting via UV Mapping
Sep 02, 2021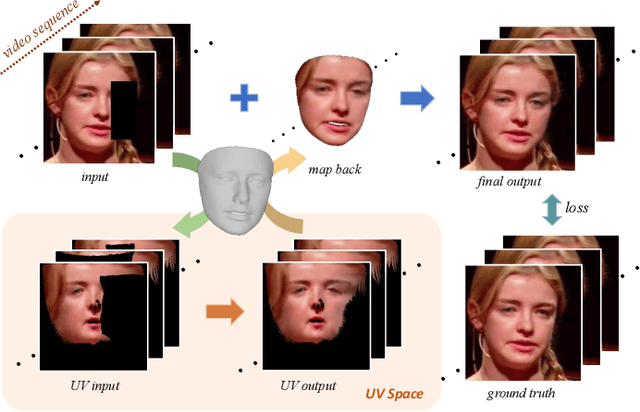
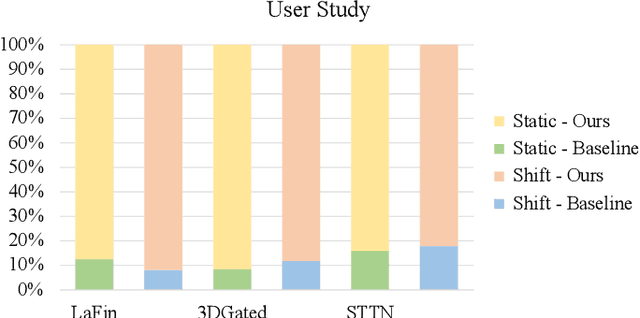


This paper addresses the problem of face video inpainting. Existing video inpainting methods target primarily at natural scenes with repetitive patterns. They do not make use of any prior knowledge of the face to help retrieve correspondences for the corrupted face. They therefore only achieve sub-optimal results, particularly for faces under large pose and expression variations where face components appear very differently across frames. In this paper, we propose a two-stage deep learning method for face video inpainting. We employ 3DMM as our 3D face prior to transform a face between the image space and the UV (texture) space. In Stage I, we perform face inpainting in the UV space. This helps to largely remove the influence of face poses and expressions and makes the learning task much easier with well aligned face features. We introduce a frame-wise attention module to fully exploit correspondences in neighboring frames to assist the inpainting task. In Stage II, we transform the inpainted face regions back to the image space and perform face video refinement that inpaints any background regions not covered in Stage I and also refines the inpainted face regions. Extensive experiments have been carried out which show our method can significantly outperform methods based merely on 2D information, especially for faces under large pose and expression variations.
Interpretable Compositional Convolutional Neural Networks
Jul 09, 2021
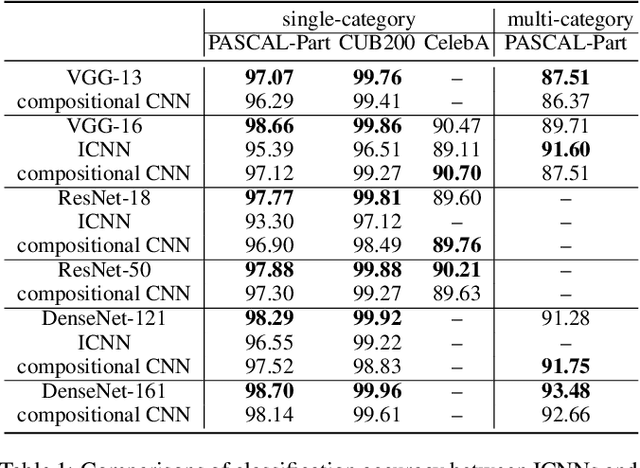
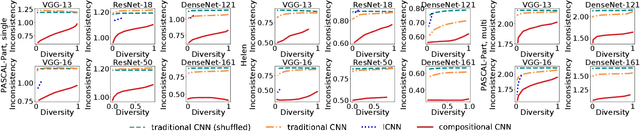

The reasonable definition of semantic interpretability presents the core challenge in explainable AI. This paper proposes a method to modify a traditional convolutional neural network (CNN) into an interpretable compositional CNN, in order to learn filters that encode meaningful visual patterns in intermediate convolutional layers. In a compositional CNN, each filter is supposed to consistently represent a specific compositional object part or image region with a clear meaning. The compositional CNN learns from image labels for classification without any annotations of parts or regions for supervision. Our method can be broadly applied to different types of CNNs. Experiments have demonstrated the effectiveness of our method.
Iris Recognition Based on SIFT Features
Oct 30, 2021Biometric methods based on iris images are believed to allow very high accuracy, and there has been an explosion of interest in iris biometrics in recent years. In this paper, we use the Scale Invariant Feature Transformation (SIFT) for recognition using iris images. Contrarily to traditional iris recognition systems, the SIFT approach does not rely on the transformation of the iris pattern to polar coordinates or on highly accurate segmentation, allowing less constrained image acquisition conditions. We extract characteristic SIFT feature points in scale space and perform matching based on the texture information around the feature points using the SIFT operator. Experiments are done using the BioSec multimodal database, which includes 3,200 iris images from 200 individuals acquired in two different sessions. We contribute with the analysis of the influence of different SIFT parameters on the recognition performance. We also show the complementarity between the SIFT approach and a popular matching approach based on transformation to polar coordinates and Log-Gabor wavelets. The combination of the two approaches achieves significantly better performance than either of the individual schemes, with a performance improvement of 24% in the Equal Error Rate.
Image Retrieval and Pattern Spotting using Siamese Neural Network
Jun 22, 2019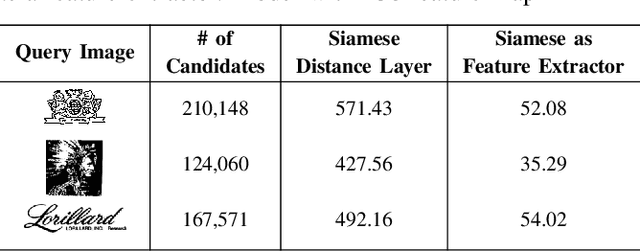
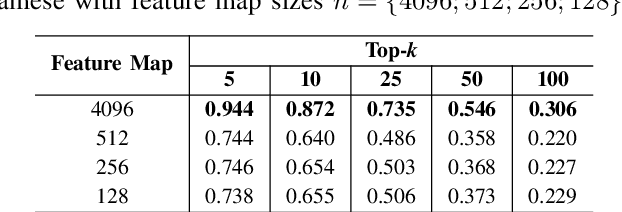
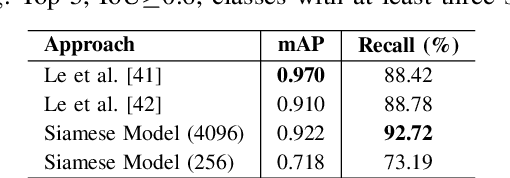

This paper presents a novel approach for image retrieval and pattern spotting in document image collections. The manual feature engineering is avoided by learning a similarity-based representation using a Siamese Neural Network trained on a previously prepared subset of image pairs from the ImageNet dataset. The learned representation is used to provide the similarity-based feature maps used to find relevant image candidates in the data collection given an image query. A robust experimental protocol based on the public Tobacco800 document image collection shows that the proposed method compares favorably against state-of-the-art document image retrieval methods, reaching 0.94 and 0.83 of mean average precision (mAP) for retrieval and pattern spotting (IoU=0.7), respectively. Besides, we have evaluated the proposed method considering feature maps of different sizes, showing the impact of reducing the number of features in the retrieval performance and time-consuming.
Dynamic Differential-Privacy Preserving SGD
Oct 30, 2021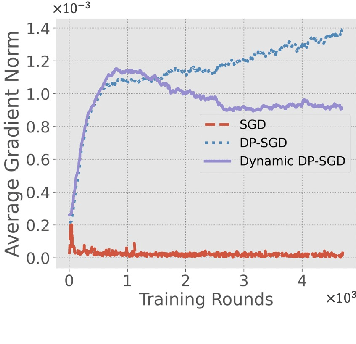
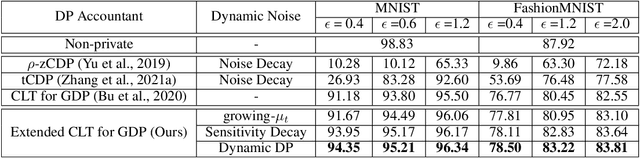
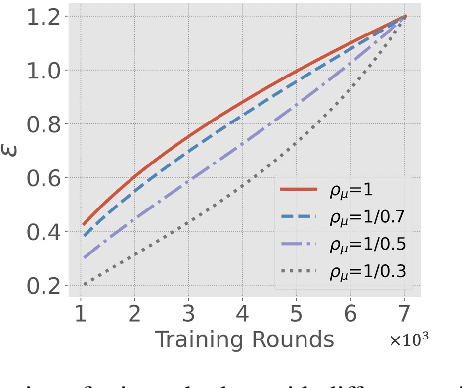
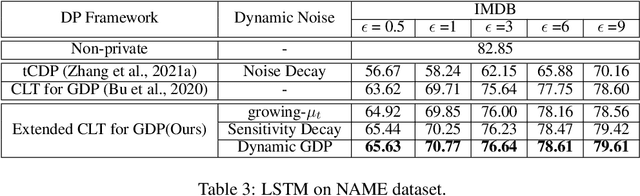
Differentially-Private Stochastic Gradient Descent (DP-SGD) prevents training-data privacy breaches by adding noise to the clipped gradient during SGD training to satisfy the differential privacy (DP) definition. On the other hand, the same clipping operation and additive noise across training steps results in unstable updates and even a ramp-up period, which significantly reduces the model's accuracy. In this paper, we extend the Gaussian DP central limit theorem to calibrate the clipping value and the noise power for each individual step separately. We, therefore, are able to propose the dynamic DP-SGD, which has a lower privacy cost than the DP-SGD during updates until they achieve the same target privacy budget at a target number of updates. Dynamic DP-SGD, in particular, improves model accuracy without sacrificing privacy by gradually lowering both clipping value and noise power while adhering to a total privacy budget constraint. Extensive experiments on a variety of deep learning tasks, including image classification, natural language processing, and federated learning, show that the proposed dynamic DP-SGD algorithm stabilizes updates and, as a result, significantly improves model accuracy in the strong privacy protection region when compared to DP-SGD.
SyMetric: Measuring the Quality of Learnt Hamiltonian Dynamics Inferred from Vision
Nov 10, 2021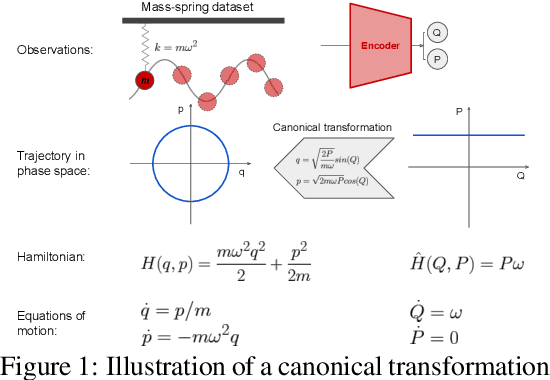

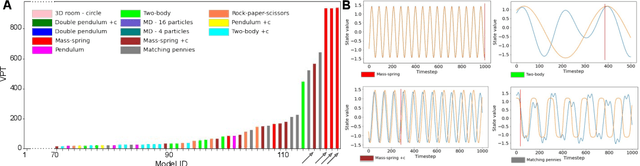
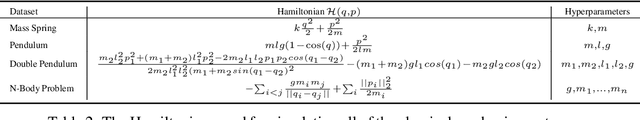
A recently proposed class of models attempts to learn latent dynamics from high-dimensional observations, like images, using priors informed by Hamiltonian mechanics. While these models have important potential applications in areas like robotics or autonomous driving, there is currently no good way to evaluate their performance: existing methods primarily rely on image reconstruction quality, which does not always reflect the quality of the learnt latent dynamics. In this work, we empirically highlight the problems with the existing measures and develop a set of new measures, including a binary indicator of whether the underlying Hamiltonian dynamics have been faithfully captured, which we call Symplecticity Metric or SyMetric. Our measures take advantage of the known properties of Hamiltonian dynamics and are more discriminative of the model's ability to capture the underlying dynamics than reconstruction error. Using SyMetric, we identify a set of architectural choices that significantly improve the performance of a previously proposed model for inferring latent dynamics from pixels, the Hamiltonian Generative Network (HGN). Unlike the original HGN, the new HGN++ is able to discover an interpretable phase space with physically meaningful latents on some datasets. Furthermore, it is stable for significantly longer rollouts on a diverse range of 13 datasets, producing rollouts of essentially infinite length both forward and backwards in time with no degradation in quality on a subset of the datasets.
Correlate-and-Excite: Real-Time Stereo Matching via Guided Cost Volume Excitation
Aug 12, 2021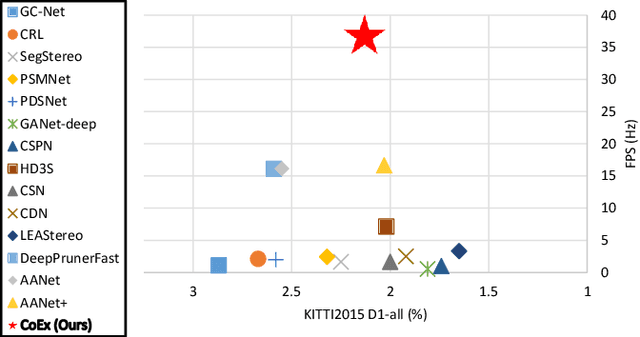
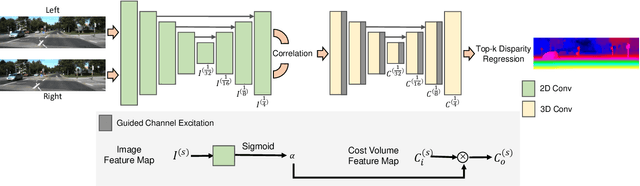

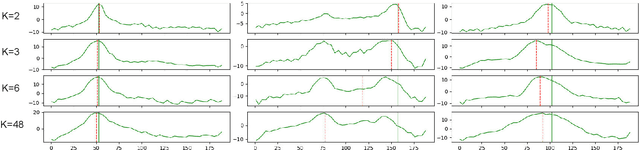
Volumetric deep learning approach towards stereo matching aggregates a cost volume computed from input left and right images using 3D convolutions. Recent works showed that utilization of extracted image features and a spatially varying cost volume aggregation complements 3D convolutions. However, existing methods with spatially varying operations are complex, cost considerable computation time, and cause memory consumption to increase. In this work, we construct Guided Cost volume Excitation (GCE) and show that simple channel excitation of cost volume guided by image can improve performance considerably. Moreover, we propose a novel method of using top-k selection prior to soft-argmin disparity regression for computing the final disparity estimate. Combining our novel contributions, we present an end-to-end network that we call Correlate-and-Excite (CoEx). Extensive experiments of our model on the SceneFlow, KITTI 2012, and KITTI 2015 datasets demonstrate the effectiveness and efficiency of our model and show that our model outperforms other speed-based algorithms while also being competitive to other state-of-the-art algorithms. Codes will be made available at https://github.com/antabangun/coex.
The Unreasonable Effectiveness of the Final Batch Normalization Layer
Sep 18, 2021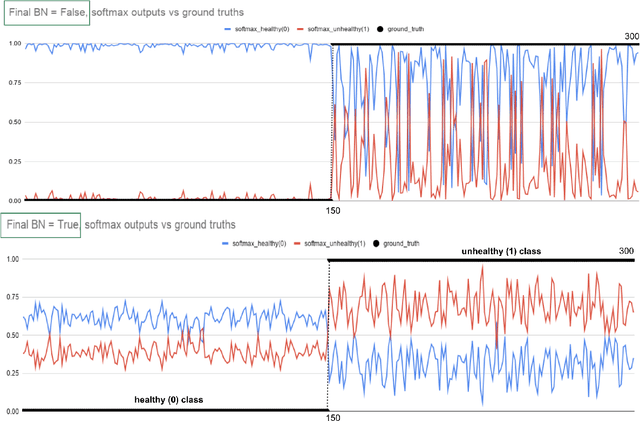
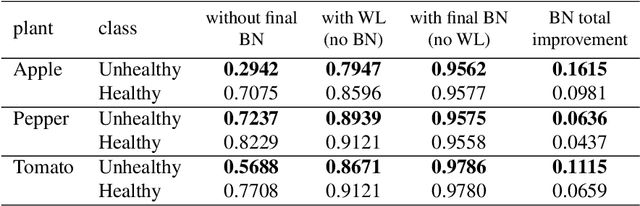

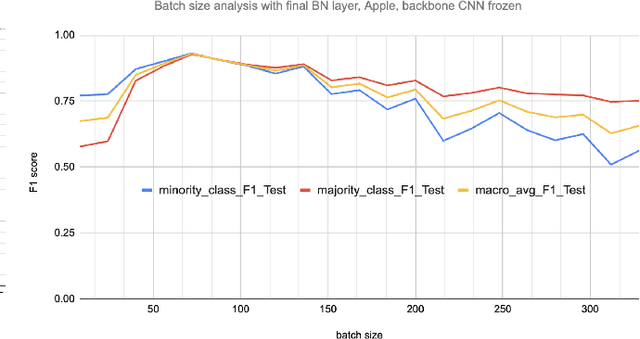
Early-stage disease indications are rarely recorded in real-world domains, such as Agriculture and Healthcare, and yet, their accurate identification is critical in that point of time. In this type of highly imbalanced classification problems, which encompass complex features, deep learning (DL) is much needed because of its strong detection capabilities. At the same time, DL is observed in practice to favor majority over minority classes and consequently suffer from inaccurate detection of the targeted early-stage indications. In this work, we extend the study done by Kocaman et al., 2020, showing that the final BN layer, when placed before the softmax output layer, has a considerable impact in highly imbalanced image classification problems as well as undermines the role of the softmax outputs as an uncertainty measure. This current study addresses additional hypotheses and reports on the following findings: (i) the performance gain after adding the final BN layer in highly imbalanced settings could still be achieved after removing this additional BN layer in inference; (ii) there is a certain threshold for the imbalance ratio upon which the progress gained by the final BN layer reaches its peak; (iii) the batch size also plays a role and affects the outcome of the final BN application; (iv) the impact of the BN application is also reproducible on other datasets and when utilizing much simpler neural architectures; (v) the reported BN effect occurs only per a single majority class and multiple minority classes i.e., no improvements are evident when there are two majority classes; and finally, (vi) utilizing this BN layer with sigmoid activation has almost no impact when dealing with a strongly imbalanced image classification tasks.