 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mastering Atari Games with Limited Data
Oct 30, 2021
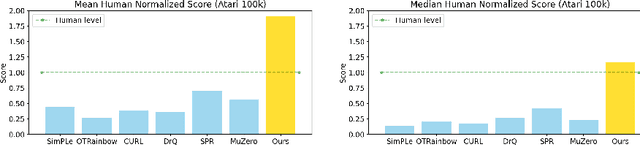
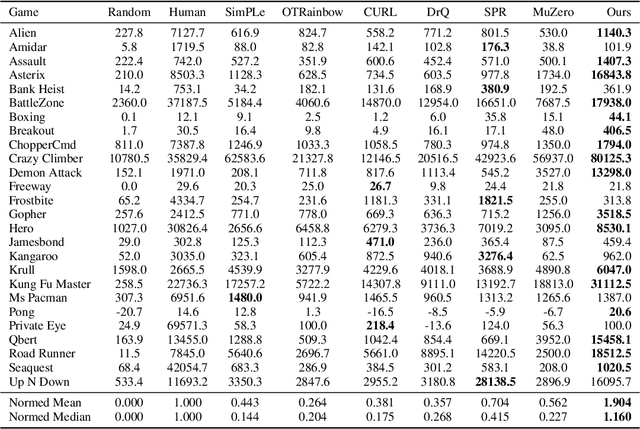
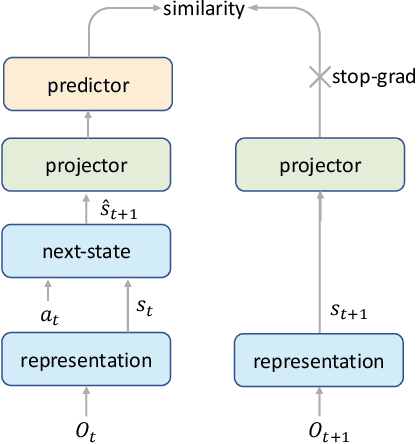

Reinforcement learning has achieved great success in many applications. However, sample efficiency remains a key challenge, with prominent methods requiring millions (or even billions) of environment steps to train. Recently, there has been significant progress in sample efficient image-based RL algorithms; however, consistent human-level performance on the Atari game benchmark remains an elusive goal. We propose a sample efficient model-based visual RL algorithm built on MuZero, which we name EfficientZero. Our method achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperforms the state SAC in some tasks on the DMControl 100k benchmark. This is the first time an algorithm achieves super-human performance on Atari games with such little data. EfficientZero's performance is also close to DQN's performance at 200 million frames while we consume 500 times less data. EfficientZero's low sample complexity and high performance can bring RL closer to real-world applicability. We implement our algorithm in an easy-to-understand manner and it is available at https://github.com/YeWR/EfficientZero. We hope it will accelerate the research of MCTS-based RL algorithms in the wider community.
Mix and match networks: multi-domain alignment for unpaired image-to-image translation
Mar 08, 2019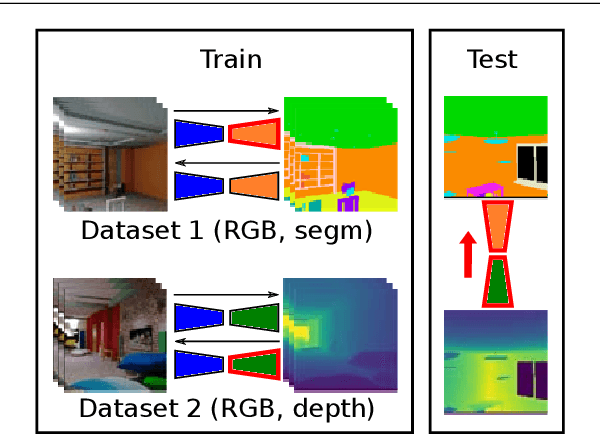
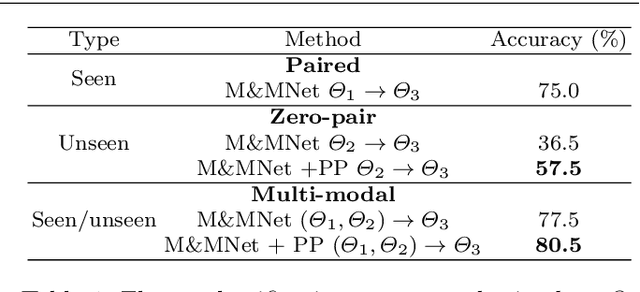

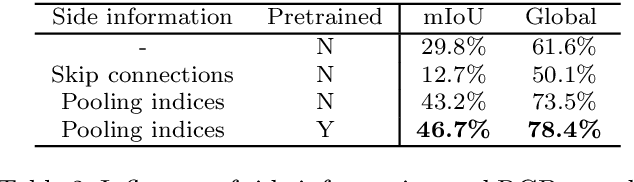
This paper addresses the problem of inferring unseen cross-domain and cross-modal image-to-image translations between multiple domains and modalities. We assume that only some of the pairwise translations have been seen (i.e. trained) and infer the remaining unseen translations (where training pairs are not available). We propose mix and match networks, an approach where multiple encoders and decoders are aligned in such a way that the desired translation can be obtained by simply cascading the source encoder and the target decoder, even when they have not interacted during the training stage (i.e. unseen). The main challenge lies in the alignment of the latent representations at the bottlenecks of encoder-decoder pairs. We propose an architecture with several tools to encourage alignment, including autoencoders and robust side information and latent consistency losses. We show the benefits of our approach in terms of effectiveness and scalability compared with other pairwise image-to-image translation approaches. We also propose zero-pair cross-modal image translation, a challenging setting where the objective is inferring semantic segmentation from depth (and vice-versa) without explicit segmentation-depth pairs, and only from two (disjoint) segmentation-RGB and depth-segmentation training sets. We observe that certain part of the shared information between unseen domains might not be reachable, so we further propose a variant that leverages pseudo-pairs to exploit all shared information.
FBSNet: A Fast Bilateral Symmetrical Network for Real-Time Semantic Segmentation
Sep 02, 2021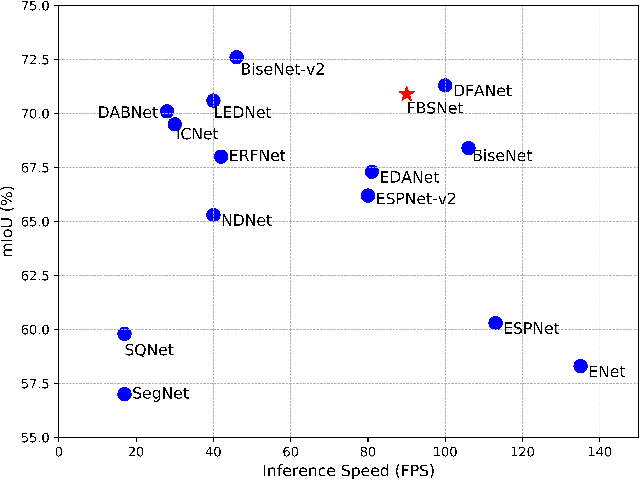
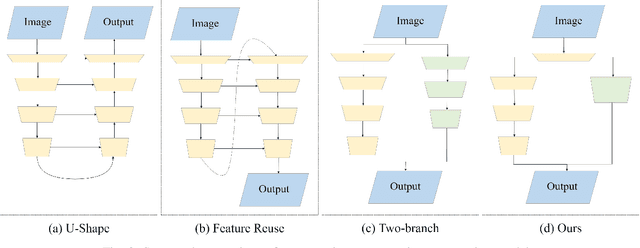
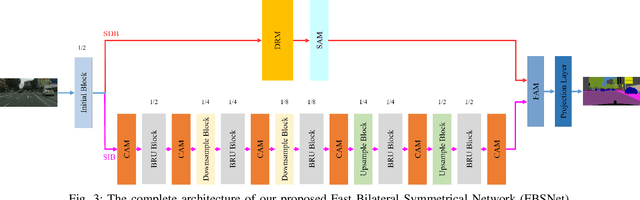
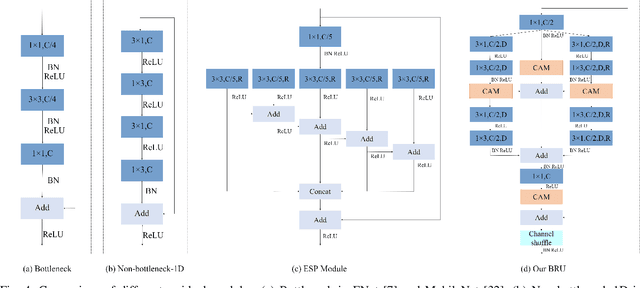
Real-time semantic segmentation, which can be visually understood as the pixel-level classification task on the input image, currently has broad application prospects, especially in the fast-developing fields of autonomous driving and drone navigation. However, the huge burden of calculation together with redundant parameters are still the obstacles to its technological development. In this paper, we propose a Fast Bilateral Symmetrical Network (FBSNet) to alleviate the above challenges. Specifically, FBSNet employs a symmetrical encoder-decoder structure with two branches, semantic information branch, and spatial detail branch. The semantic information branch is the main branch with deep network architecture to acquire the contextual information of the input image and meanwhile acquire sufficient receptive field. While spatial detail branch is a shallow and simple network used to establish local dependencies of each pixel for preserving details, which is essential for restoring the original resolution during the decoding phase. Meanwhile, a feature aggregation module (FAM) is designed to effectively combine the output features of the two branches. The experimental results of Cityscapes and CamVid show that the proposed FBSNet can strike a good balance between accuracy and efficiency. Specifically, it obtains 70.9\% and 68.9\% mIoU along with the inference speed of 90 fps and 120 fps on these two test datasets, respectively, with only 0.62 million parameters on a single RTX 2080Ti GPU.
Pathological Image Segmentation with Noisy Labels
Mar 20, 2021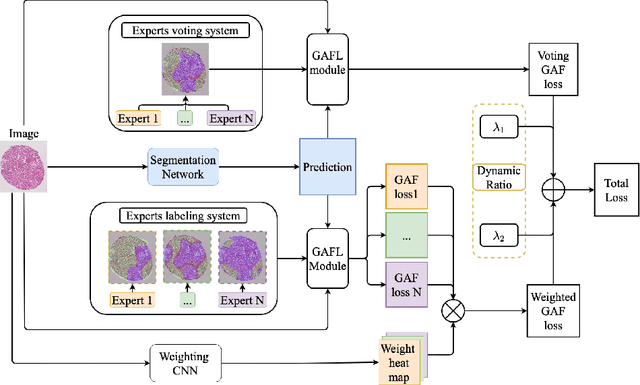
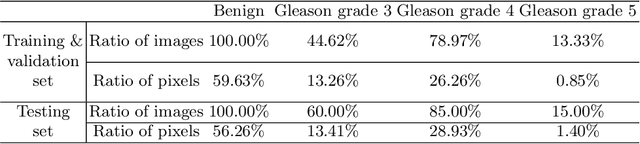
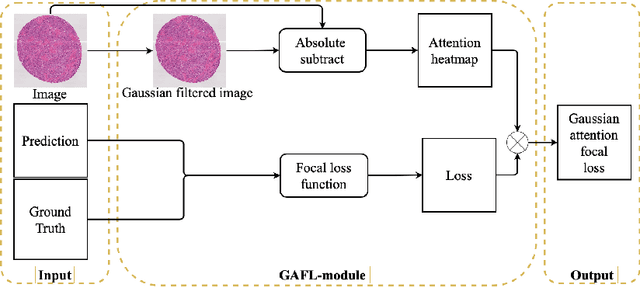
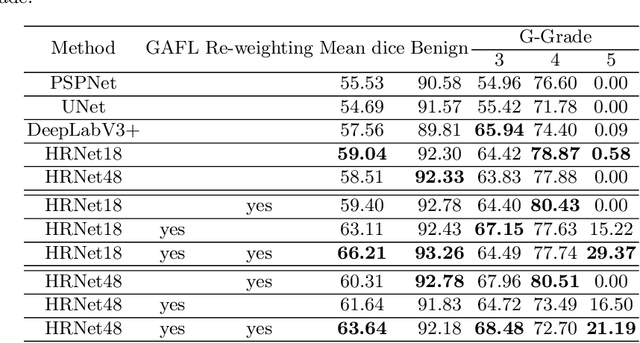
Segmentation of pathological images is essential for accurate disease diagnosis. The quality of manual labels plays a critical role in segmentation accuracy; yet, in practice, the labels between pathologists could be inconsistent, thus confusing the training process. In this work, we propose a novel label re-weighting framework to account for the reliability of different experts' labels on each pixel according to its surrounding features. We further devise a new attention heatmap, which takes roughness as prior knowledge to guide the model to focus on important regions. Our approach is evaluated on the public Gleason 2019 datasets. The results show that our approach effectively improves the model's robustness against noisy labels and outperforms state-of-the-art approaches.
Deep Learning models for benign and malign Ocular Tumor Growth Estimation
Jul 09, 2021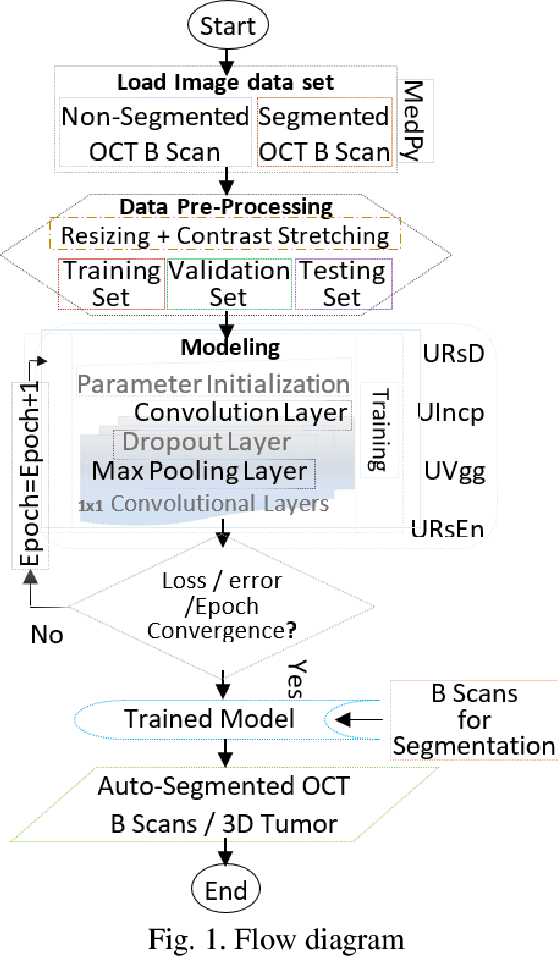
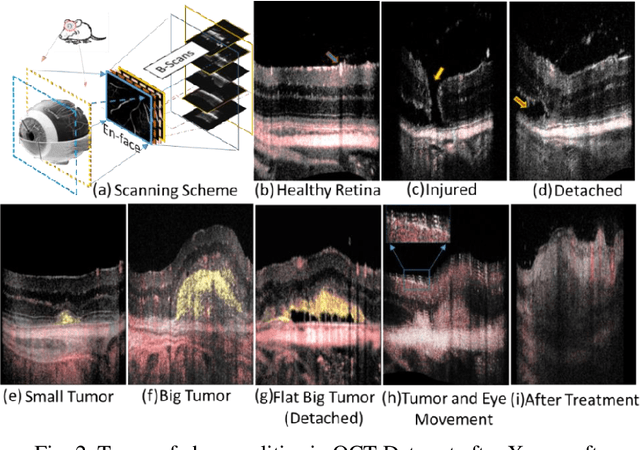
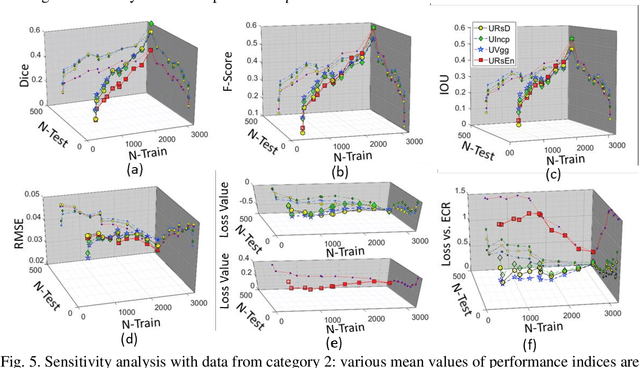
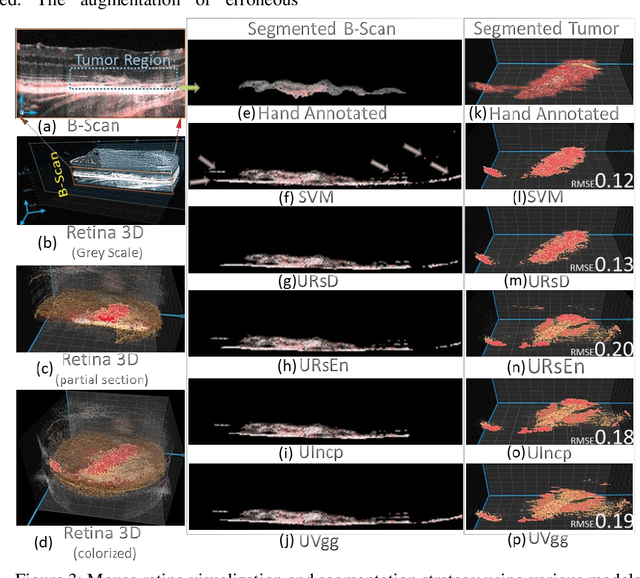
Relatively abundant availability of medical imaging data has provided significant support in the development and testing of Neural Network based image processing methods. Clinicians often face issues in selecting suitable image processing algorithm for medical imaging data. A strategy for the selection of a proper model is presented here. The training data set comprises optical coherence tomography (OCT) and angiography (OCT-A) images of 50 mice eyes with more than 100 days follow-up. The data contains images from treated and untreated mouse eyes. Four deep learning variants are tested for automatic (a) differentiation of tumor region with healthy retinal layer and (b) segmentation of 3D ocular tumor volumes. Exhaustive sensitivity analysis of deep learning models is performed with respect to the number of training and testing images using 8 eight performance indices to study accuracy, reliability/reproducibility, and speed. U-net with UVgg16 is best for malign tumor data set with treatment (having considerable variation) and U-net with Inception backbone for benign tumor data (with minor variation). Loss value and root mean square error (R.M.S.E.) are found most and least sensitive performance indices, respectively. The performance (via indices) is found to be exponentially improving regarding a number of training images. The segmented OCT-Angiography data shows that neovascularization drives the tumor volume. Image analysis shows that photodynamic imaging-assisted tumor treatment protocol is transforming an aggressively growing tumor into a cyst. An empirical expression is obtained to help medical professionals to choose a particular model given the number of images and types of characteristics. We recommend that the presented exercise should be taken as standard practice before employing a particular deep learning model for biomedical image analysis.
Self-supervised Dynamic CT Perfusion Image Denoising with Deep Neural Networks
May 19, 2020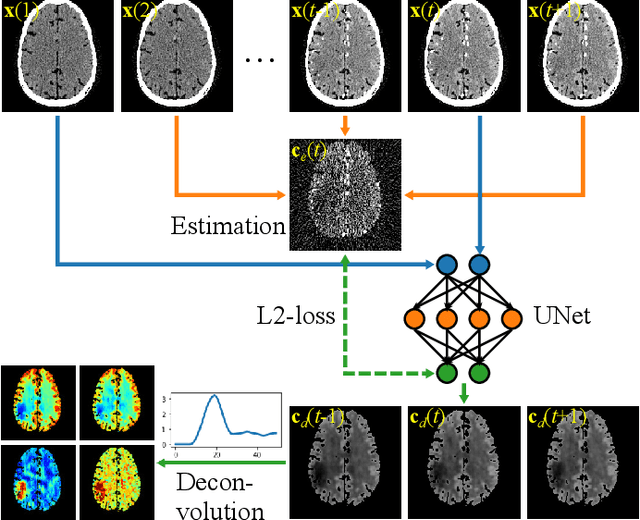
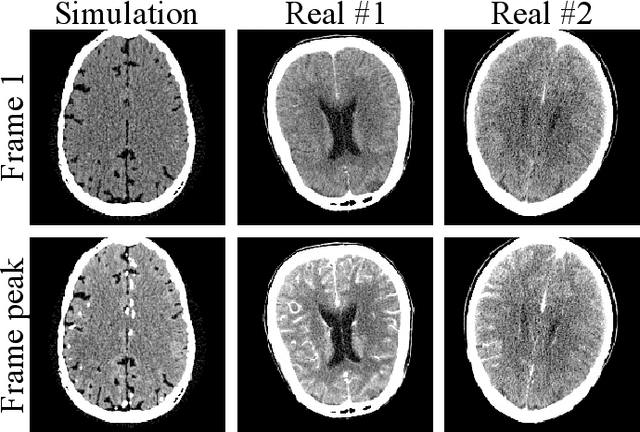
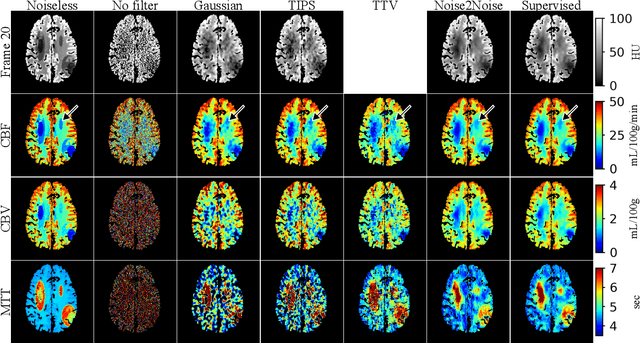
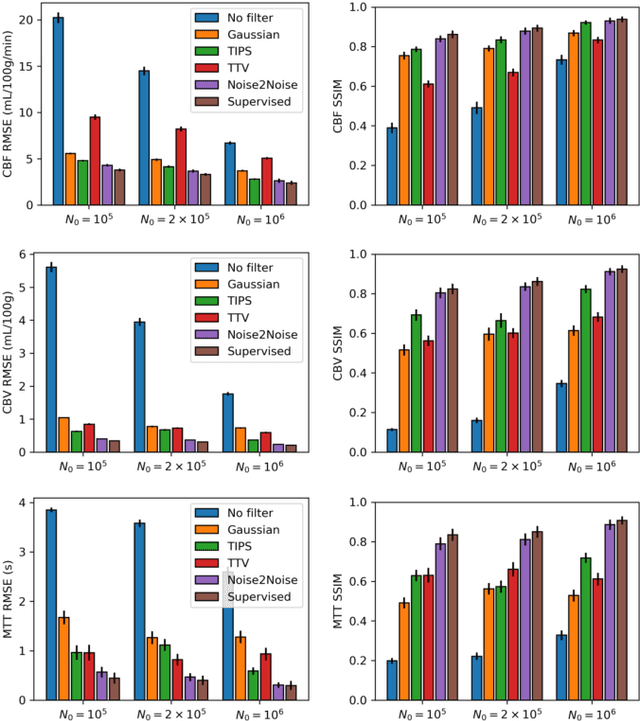
Dynamic computed tomography perfusion (CTP) imaging is a promising approach for acute ischemic stroke diagnosis and evaluation. Hemodynamic parametric maps of cerebral parenchyma are calculated from repeated CT scans of the first pass of iodinated contrast through the brain. It is necessary to reduce the dose of CTP for routine applications due to the high radiation exposure from the repeated scans, where image denoising is necessary to achieve a reliable diagnosis. In this paper, we proposed a self-supervised deep learning method for CTP denoising, which did not require any high-dose reference images for training. The network was trained by mapping each frame of CTP to an estimation from its adjacent frames. Because the noise in the source and target was independent, this approach could effectively remove the noise. Being free from high-dose training images granted the proposed method easier adaptation to different scanning protocols. The method was validated on both simulation and a public real dataset. The proposed method achieved improved image quality compared to conventional denoising methods. On the real data, the proposed method also had improved spatial resolution and contrast-to-noise ratio compared to supervised learning which was trained on the simulation data
IPG-Net: Image Pyramid Guidance Network for Object Detection
Dec 05, 2019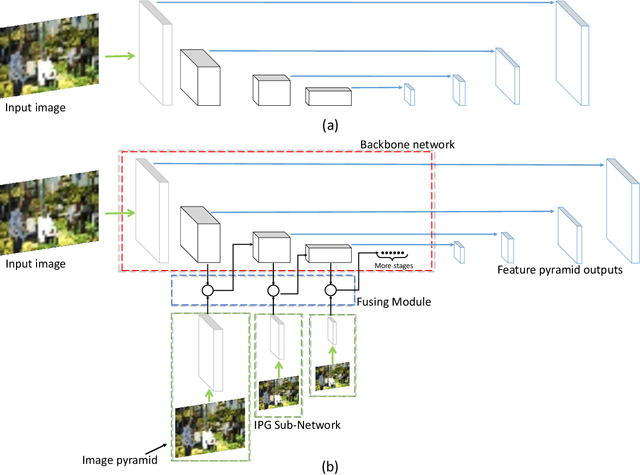
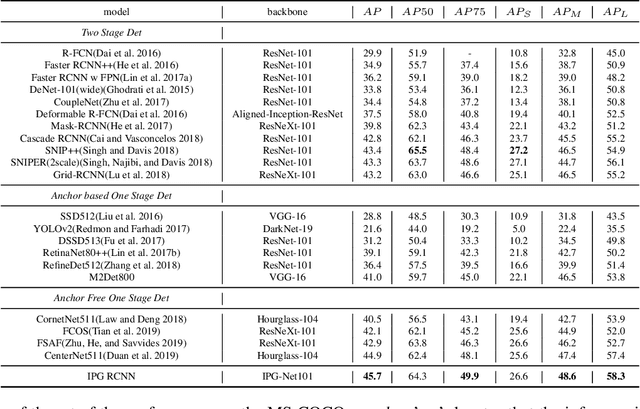
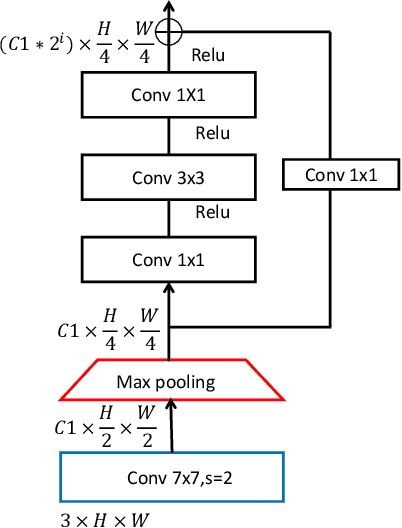
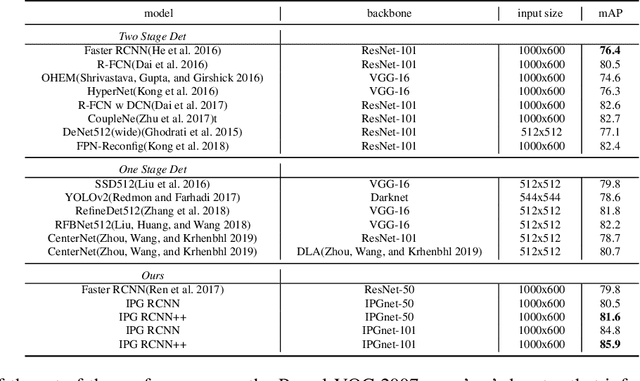
For Convolutional Neural Network based object detection, there is a typical dilemma: the spatial information is well kept in the shallow layers which unfortunately do not have enough semantic information, while the deep layers have high semantic concept but lost a lot of spatial information, resulting in serious information imbalance. To acquire enough semantic information for shallow layers, Feature Pyramid Networks (FPN) is used to build a top-down propagated path. In this paper, except for top-down combining of information for shallow layers, we propose a novel network called Image Pyramid Guidance Network(IPG-Net) to make sure both the spatial information and semantic information are abundant for each layer. Our IPG-Net has three main parts: the image pyramid guidance sub-network, the ResNet based backbone network and the fusing module. The image pyramid guidance sub-network supplies spatial information to each scale's feature to solve the information imbalance problem. This sub-network promise even in the deepest stage of the ResNet, there is enough spatial information for bounding box regression and classification. Furthermore, we designed an effective fusing module to fuse the features from the image pyramid and features from the feature pyramid. We have tried to apply this novel network to both one stage and two stage models, state of the art results are obtained on the most popular benchmark data sets, i.e. MS COCO and Pascal VOC.
Agriculture-Vision: A Large Aerial Image Database for Agricultural Pattern Analysis
Jan 05, 2020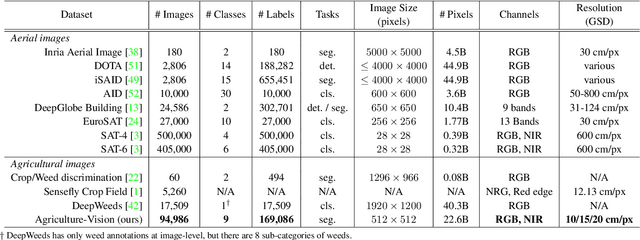


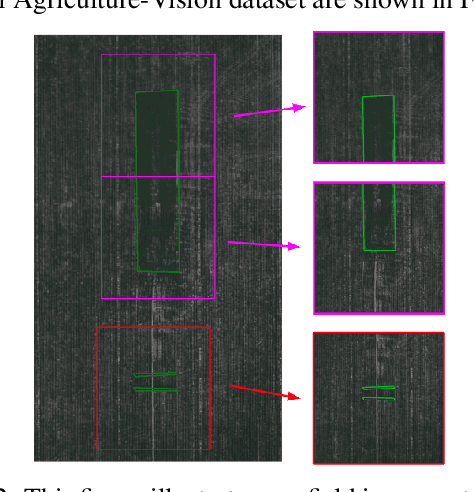
The success of deep learning in visual recognition tasks has driven advancements in multiple fields of research. Particularly, increasing attention has been drawn towards its application in agriculture. Nevertheless, while visual pattern recognition on farmlands carries enormous economic values, little progress has been made to merge computer vision and crop sciences due to the lack of suitable agricultural image datasets. Meanwhile, problems in agriculture also pose new challenges in computer vision. For example, semantic segmentation of aerial farmland images requires inference over extremely large-size images with extreme annotation sparsity. These challenges are not present in most of the common object datasets, and we show that they are more challenging than many other aerial image datasets. To encourage research in computer vision for agriculture, we present Agriculture-Vision: a large-scale aerial farmland image dataset for semantic segmentation of agricultural patterns. We collected 94,986 high-quality aerial images from 3,432 farmlands across the US, where each image consists of RGB and Near-infrared (NIR) channels with resolution as high as 10 cm per pixel. We annotate nine types of field anomaly patterns that are most important to farmers. As a pilot study of aerial agricultural semantic segmentation, we perform comprehensive experiments using popular semantic segmentation models; we also propose an effective model designed for aerial agricultural pattern recognition. Our experiments demonstrate several challenges Agriculture-Vision poses to both the computer vision and agriculture communities. Future versions of this dataset will include even more aerial images, anomaly patterns and image channels. More information at https://www.agriculture-vision.com.
Deep Face Video Inpainting via UV Mapping
Sep 02, 2021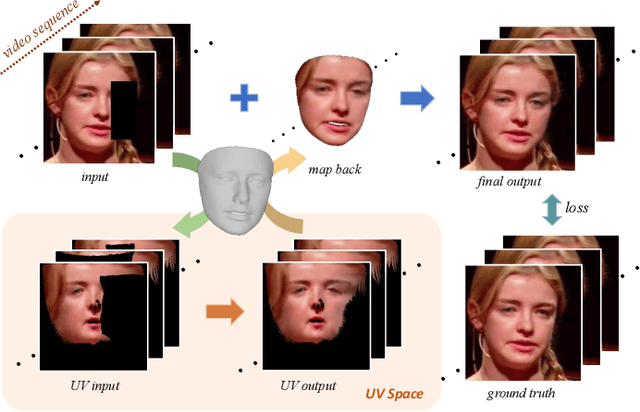
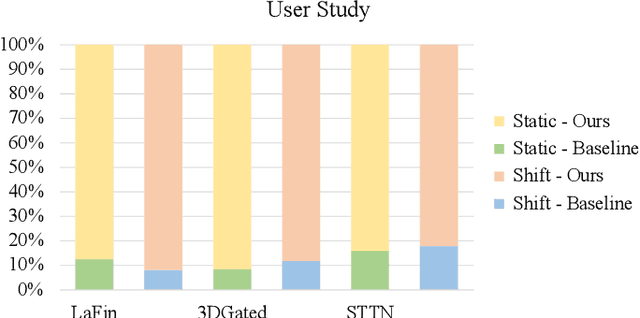


This paper addresses the problem of face video inpainting. Existing video inpainting methods target primarily at natural scenes with repetitive patterns. They do not make use of any prior knowledge of the face to help retrieve correspondences for the corrupted face. They therefore only achieve sub-optimal results, particularly for faces under large pose and expression variations where face components appear very differently across frames. In this paper, we propose a two-stage deep learning method for face video inpainting. We employ 3DMM as our 3D face prior to transform a face between the image space and the UV (texture) space. In Stage I, we perform face inpainting in the UV space. This helps to largely remove the influence of face poses and expressions and makes the learning task much easier with well aligned face features. We introduce a frame-wise attention module to fully exploit correspondences in neighboring frames to assist the inpainting task. In Stage II, we transform the inpainted face regions back to the image space and perform face video refinement that inpaints any background regions not covered in Stage I and also refines the inpainted face regions. Extensive experiments have been carried out which show our method can significantly outperform methods based merely on 2D information, especially for faces under large pose and expression variations.
MRI Image Reconstruction via Learning Optimization using Neural ODEs
Jun 24, 2020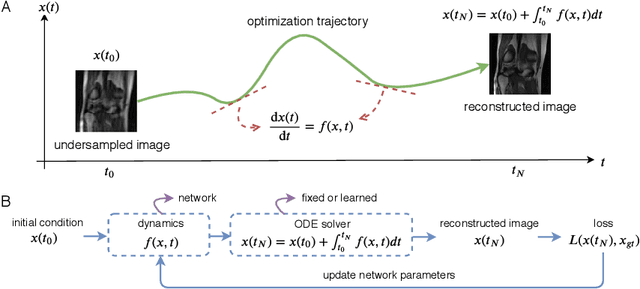
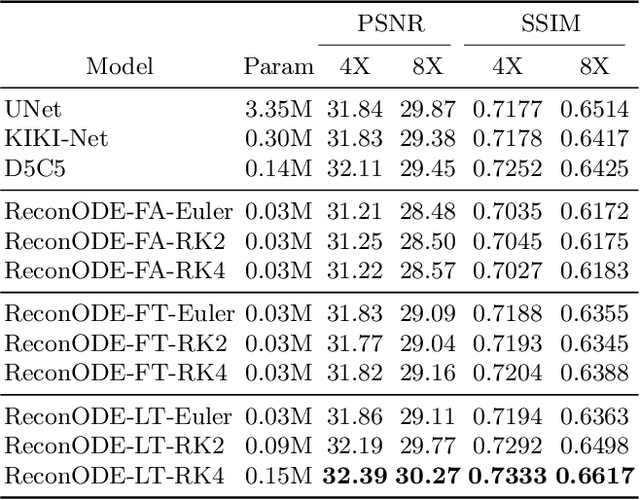
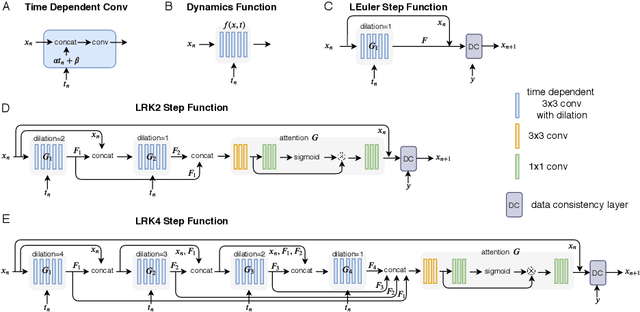
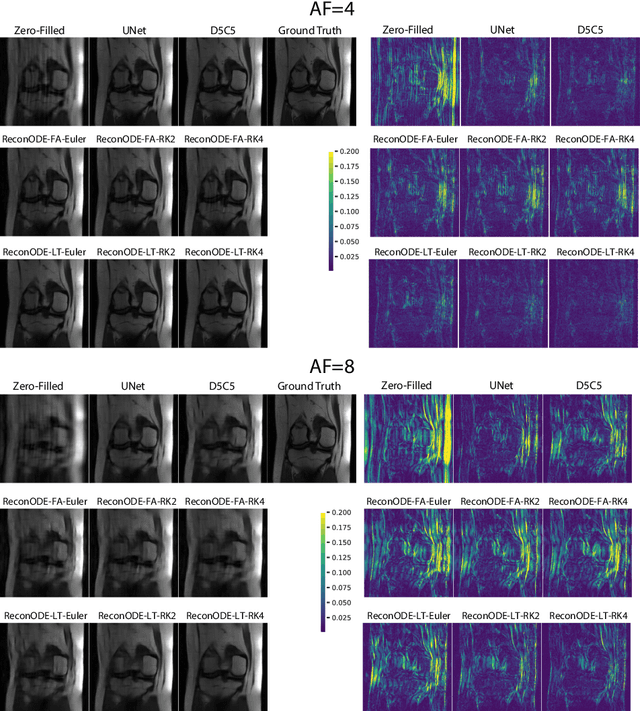
We propose to formulate MRI image reconstruction as an optimization problem and model the optimization trajectory as a dynamic process using ordinary differential equations (ODEs). We model the dynamics in ODE with a neural network and solve the desired ODE with the off-the-shelf (fixed) solver to obtain reconstructed images. We extend this model and incorporate the knowledge of off-the-shelf ODE solvers into the network design (learned solvers). We investigate several models based on three ODE solvers and compare models with fixed solvers and learned solvers. Our models achieve better reconstruction results and are more parameter efficient than other popular methods such as UNet and cascaded CNN. We introduce a new way of tackling the MRI reconstruction problem by modeling the continuous optimization dynamics using neural ODEs.