 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Sep 21, 2018

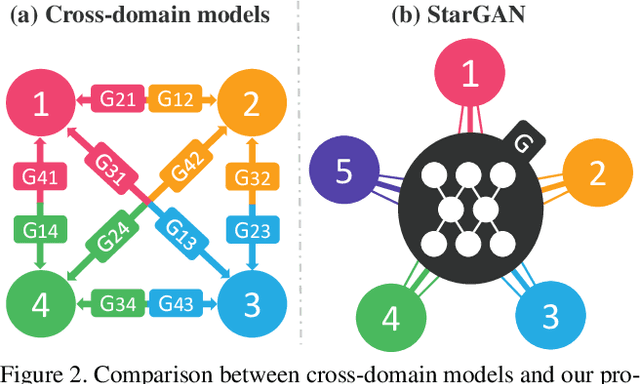
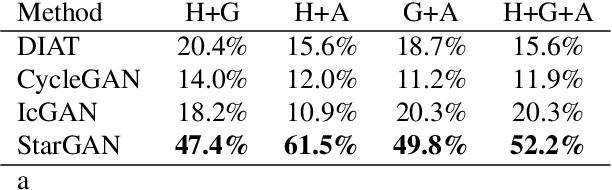
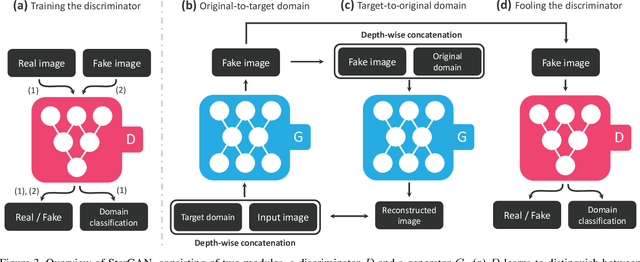
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN's superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
* Accepted to CVPR 2018 (Oral)
Mutual-GAN: Towards Unsupervised Cross-Weather Adaptation with Mutual Information Constraint
Jun 30, 2021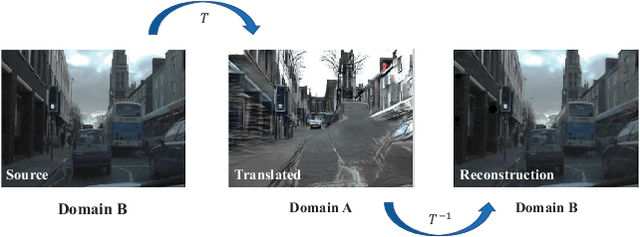
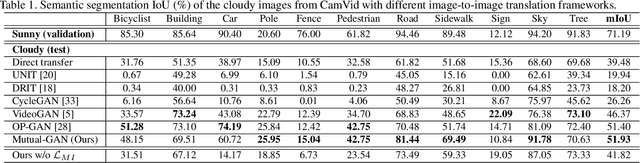
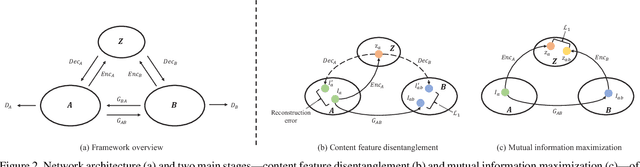
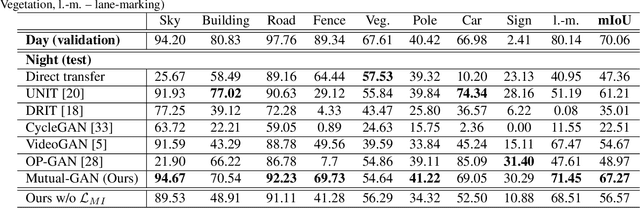
Convolutional neural network (CNN) have proven its success for semantic segmentation, which is a core task of emerging industrial applications such as autonomous driving. However, most progress in semantic segmentation of urban scenes is reported on standard scenarios, i.e., daytime scenes with favorable illumination conditions. In practical applications, the outdoor weather and illumination are changeable, e.g., cloudy and nighttime, which results in a significant drop of semantic segmentation accuracy of CNN only trained with daytime data. In this paper, we propose a novel generative adversarial network (namely Mutual-GAN) to alleviate the accuracy decline when daytime-trained neural network is applied to videos captured under adverse weather conditions. The proposed Mutual-GAN adopts mutual information constraint to preserve image-objects during cross-weather adaptation, which is an unsolved problem for most unsupervised image-to-image translation approaches (e.g., CycleGAN). The proposed Mutual-GAN is evaluated on two publicly available driving video datasets (i.e., CamVid and SYNTHIA). The experimental results demonstrate that our Mutual-GAN can yield visually plausible translated images and significantly improve the semantic segmentation accuracy of daytime-trained deep learning network while processing videos under challenging weathers.
Deep MR Brain Image Super-Resolution Using Spatio-Structural Priors
Sep 10, 2019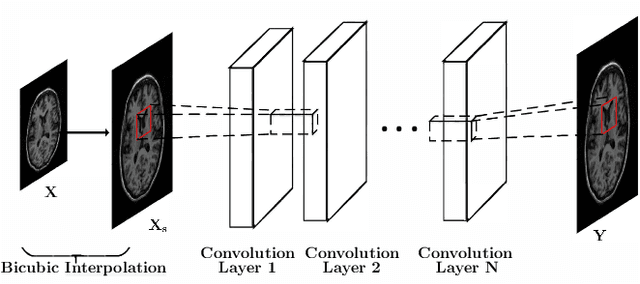
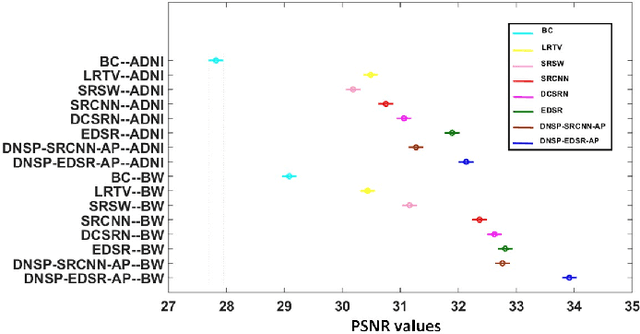
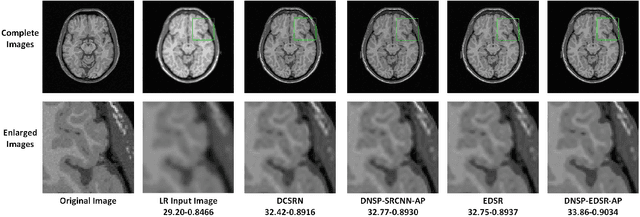
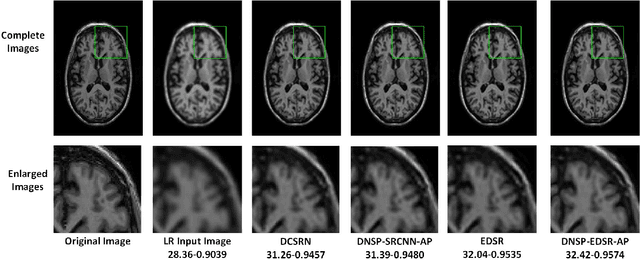
High resolution Magnetic Resonance (MR) images are desired for accurate diagnostics. In practice, image resolution is restricted by factors like hardware and processing constraints. Recently, deep learning methods have been shown to produce compelling state-of-the-art results for image enhancement/super-resolution. Paying particular attention to desired hi-resolution MR image structure, we propose a new regularized network that exploits image priors, namely a low-rank structure and a sharpness prior to enhance deep MR image super-resolution (SR). Our contributions are then incorporating these priors in an analytically tractable fashion \color{black} as well as towards a novel prior guided network architecture that accomplishes the super-resolution task. This is particularly challenging for the low rank prior since the rank is not a differentiable function of the image matrix(and hence the network parameters), an issue we address by pursuing differentiable approximations of the rank. Sharpness is emphasized by the variance of the Laplacian which we show can be implemented by a fixed feedback layer at the output of the network. As a key extension, we modify the fixed feedback (Laplacian) layer by learning a new set of training data driven filters that are optimized for enhanced sharpness. Experiments performed on publicly available MR brain image databases and comparisons against existing state-of-the-art methods show that the proposed prior guided network offers significant practical gains in terms of improved SNR/image quality measures. Because our priors are on output images, the proposed method is versatile and can be combined with a wide variety of existing network architectures to further enhance their performance.
Point detection through multi-instance deep heatmap regression for sutures in endoscopy
Nov 16, 2021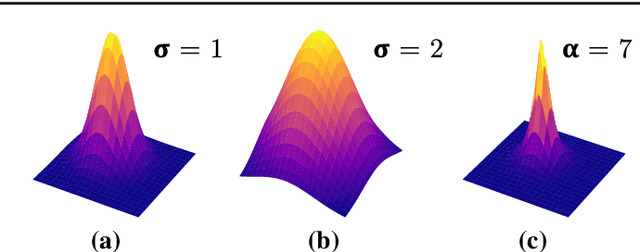
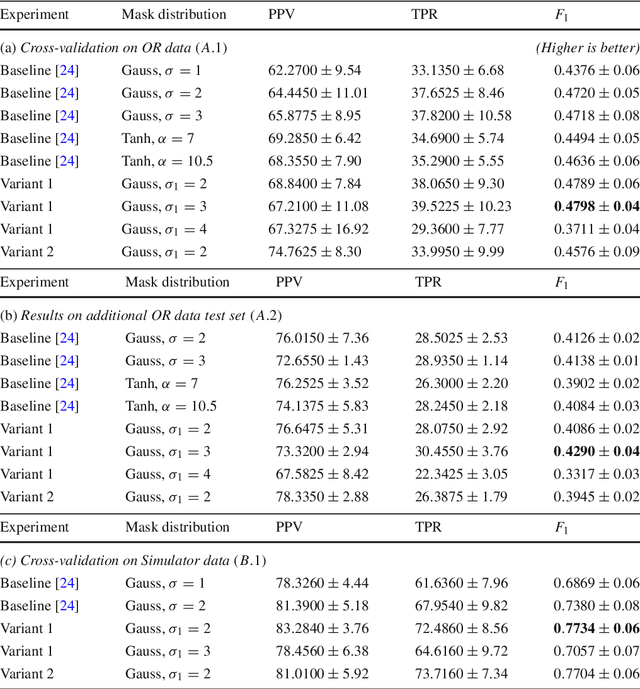
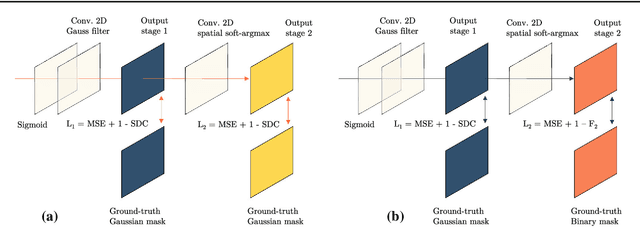
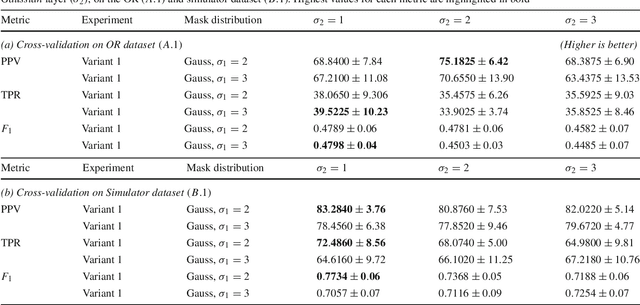
Purpose: Mitral valve repair is a complex minimally invasive surgery of the heart valve. In this context, suture detection from endoscopic images is a highly relevant task that provides quantitative information to analyse suturing patterns, assess prosthetic configurations and produce augmented reality visualisations. Facial or anatomical landmark detection tasks typically contain a fixed number of landmarks, and use regression or fixed heatmap-based approaches to localize the landmarks. However in endoscopy, there are a varying number of sutures in every image, and the sutures may occur at any location in the annulus, as they are not semantically unique. Method: In this work, we formulate the suture detection task as a multi-instance deep heatmap regression problem, to identify entry and exit points of sutures. We extend our previous work, and introduce the novel use of a 2D Gaussian layer followed by a differentiable 2D spatial Soft-Argmax layer to function as a local non-maximum suppression. Results: We present extensive experiments with multiple heatmap distribution functions and two variants of the proposed model. In the intra-operative domain, Variant 1 showed a mean F1 of +0.0422 over the baseline. Similarly, in the simulator domain, Variant 1 showed a mean F1 of +0.0865 over the baseline. Conclusion: The proposed model shows an improvement over the baseline in the intra-operative and the simulator domains. The data is made publicly available within the scope of the MICCAI AdaptOR2021 Challenge https://adaptor2021.github.io/, and the code at https://github.com/Cardio-AI/suture-detection-pytorch/. DOI:10.1007/s11548-021-02523-w. The link to the open access article can be found here: https://link.springer.com/article/10.1007%2Fs11548-021-02523-w
* Accepted to International Journal of Computer Assisted Radiology and Surgery, 15 pages, 5 figures
A Survey on Biomedical Image Captioning
May 26, 2019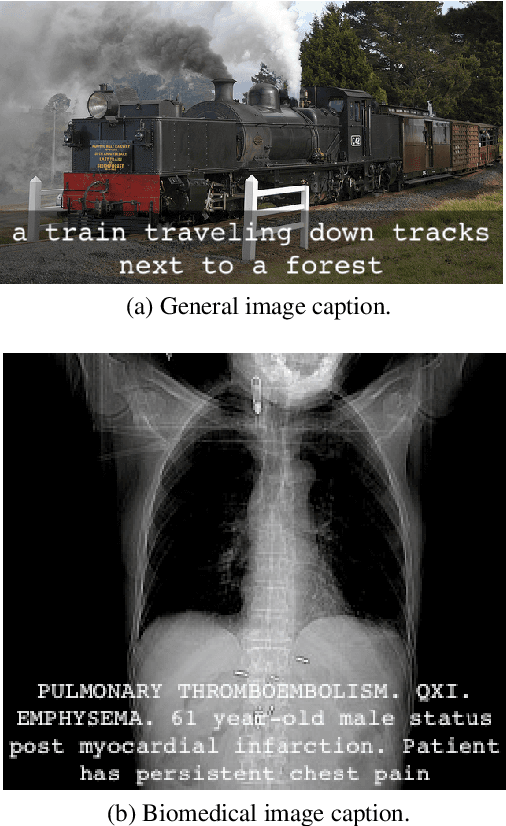
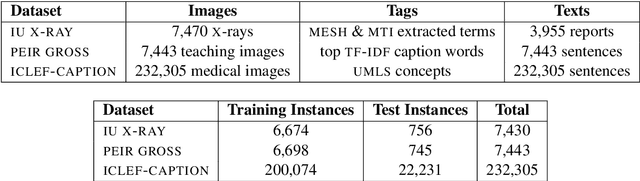
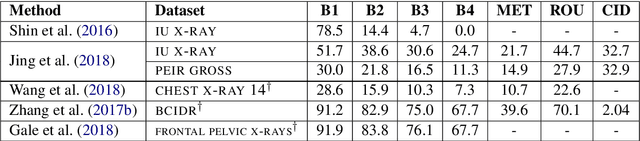
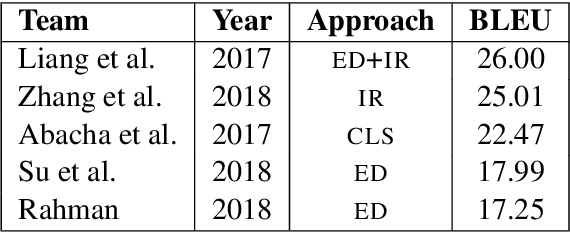
Image captioning applied to biomedical images can assist and accelerate the diagnosis process followed by clinicians. This article is the first survey of biomedical image captioning, discussing datasets, evaluation measures, and state of the art methods. Additionally, we suggest two baselines, a weak and a stronger one; the latter outperforms all current state of the art systems on one of the datasets.
Low-Weight and Learnable Image Denoising
Nov 17, 2019

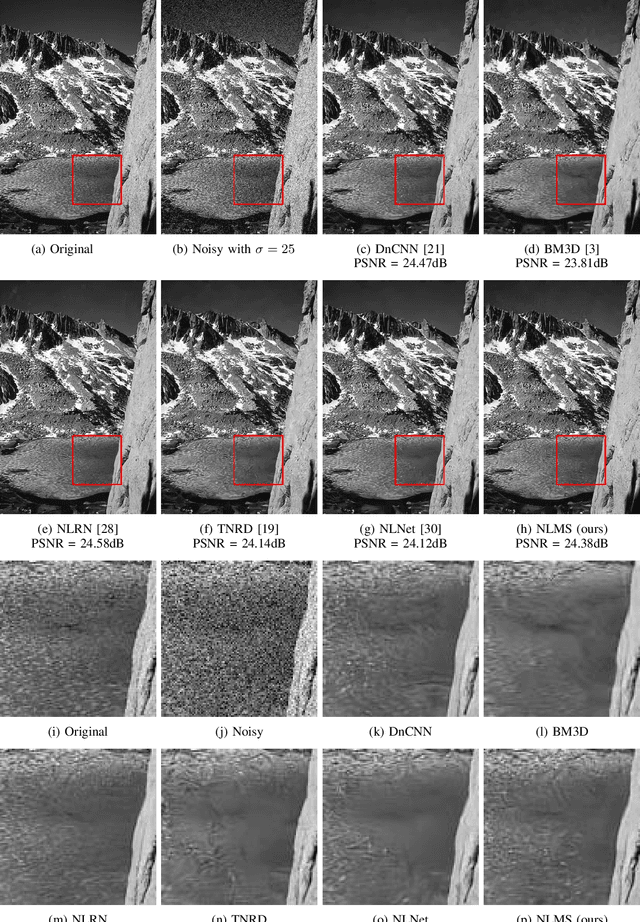

Image denoising is a well studied problem with an extensive activity that has spread over several decades. Despite the many available denoising algorithms, the quest for simple, powerful and fast denoisers is still an active and vibrant topic of research. Leading classical denoising methods are typically designed to exploit the inner structure in images by modeling local overlapping patches. In contrast, recent newcomers to this arena are supervised neural-network-based methods that bypass this modeling altogether, targeting the inference goal directly and globally, while tending to be very deep and parameter heavy. This work proposes a novel low-weight learnable architecture that embeds in it several of the main concepts from the classical methods, while being trained for best denoising performance. More specifically, our proposed network relies on patch processing, leveraging non-local self-similarity, representation sparsity and a multiscale treatment. The proposed architecture achieves near state-of-the-art denoising results, while using a small fraction of the typical number of parameters. Furthermore, we demonstrate the ability of the proposed network to adapt itself to an incoming image by leveraging similar clean ones.
Robust Contrastive Learning Using Negative Samples with Diminished Semantics
Oct 27, 2021
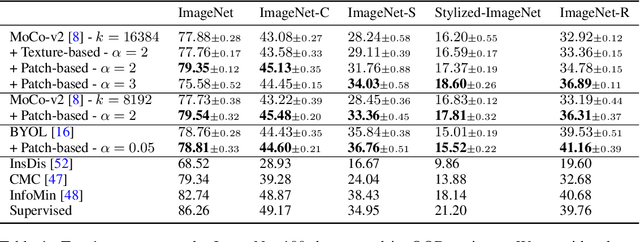
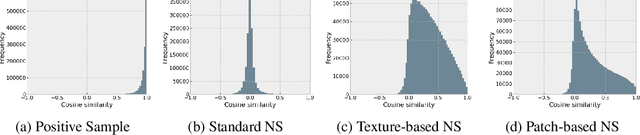

Unsupervised learning has recently made exceptional progress because of the development of more effective contrastive learning methods. However, CNNs are prone to depend on low-level features that humans deem non-semantic. This dependency has been conjectured to induce a lack of robustness to image perturbations or domain shift. In this paper, we show that by generating carefully designed negative samples, contrastive learning can learn more robust representations with less dependence on such features. Contrastive learning utilizes positive pairs that preserve semantic information while perturbing superficial features in the training images. Similarly, we propose to generate negative samples in a reversed way, where only the superfluous instead of the semantic features are preserved. We develop two methods, texture-based and patch-based augmentations, to generate negative samples. These samples achieve better generalization, especially under out-of-domain settings. We also analyze our method and the generated texture-based samples, showing that texture features are indispensable in classifying particular ImageNet classes and especially finer classes. We also show that model bias favors texture and shape features differently under different test settings. Our code, trained models, and ImageNet-Texture dataset can be found at https://github.com/SongweiGe/Contrastive-Learning-with-Non-Semantic-Negatives.
LIFE: Lighting Invariant Flow Estimation
Apr 19, 2021

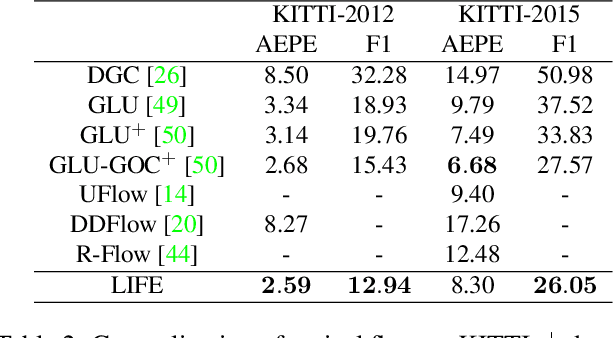
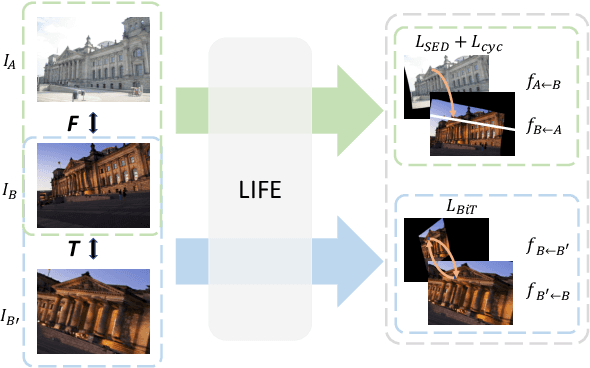
We tackle the problem of estimating flow between two images with large lighting variations. Recent learning-based flow estimation frameworks have shown remarkable performance on image pairs with small displacement and constant illuminations, but cannot work well on cases with large viewpoint change and lighting variations because of the lack of pixel-wise flow annotations for such cases. We observe that via the Structure-from-Motion (SfM) techniques, one can easily estimate relative camera poses between image pairs with large viewpoint change and lighting variations. We propose a novel weakly supervised framework LIFE to train a neural network for estimating accurate lighting-invariant flows between image pairs. Sparse correspondences are conventionally established via feature matching with descriptors encoding local image contents. However, local image contents are inevitably ambiguous and error-prone during the cross-image feature matching process, which hinders downstream tasks. We propose to guide feature matching with the flows predicted by LIFE, which addresses the ambiguous matching by utilizing abundant context information in the image pairs. We show that LIFE outperforms previous flow learning frameworks by large margins in challenging scenarios, consistently improves feature matching, and benefits downstream tasks.
Depth Infused Binaural Audio Generation using Hierarchical Cross-Modal Attention
Aug 10, 2021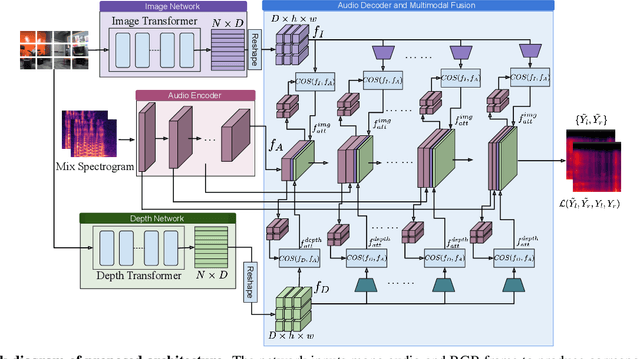
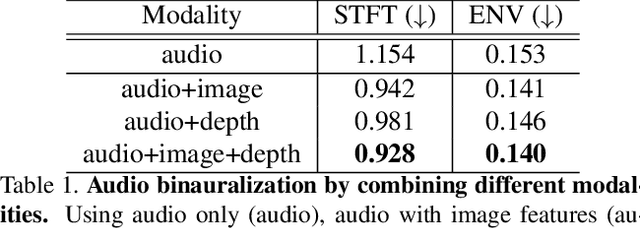
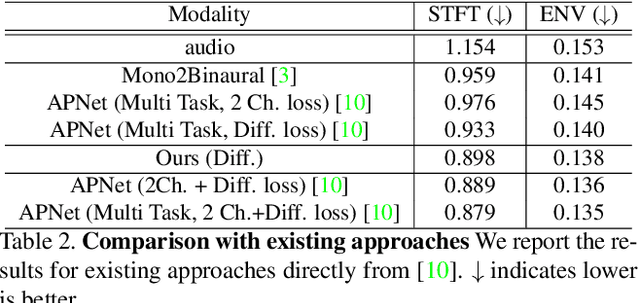

Binaural audio gives the listener the feeling of being in the recording place and enhances the immersive experience if coupled with AR/VR. But the problem with binaural audio recording is that it requires a specialized setup which is not possible to fabricate within handheld devices as compared to traditional mono audio that can be recorded with a single microphone. In order to overcome this drawback, prior works have tried to uplift the mono recorded audio to binaural audio as a post processing step conditioning on the visual input. But all the prior approaches missed other most important information required for the task, i.e. distance of different sound producing objects from the recording setup. In this work, we argue that the depth map of the scene can act as a proxy for encoding distance information of objects in the scene and show that adding depth features along with image features improves the performance both qualitatively and quantitatively. We propose a novel encoder-decoder architecture, where we use a hierarchical attention mechanism to encode the image and depth feature extracted from individual transformer backbone, with audio features at each layer of the decoder.
FocusFace: Multi-task Contrastive Learning for Masked Face Recognition
Nov 01, 2021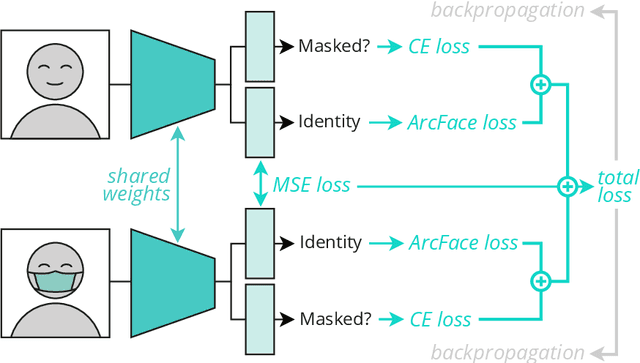

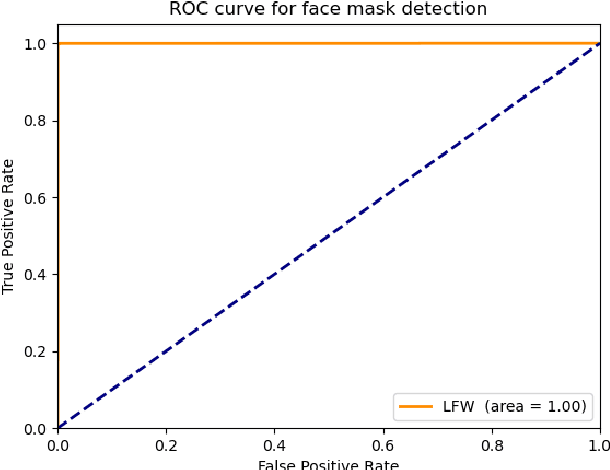
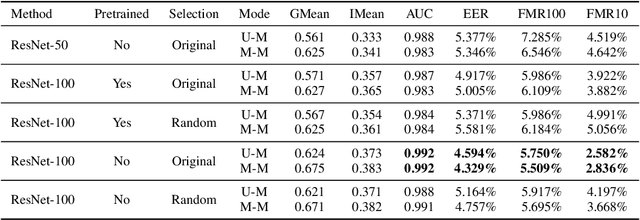
SARS-CoV-2 has presented direct and indirect challenges to the scientific community. One of the most prominent indirect challenges advents from the mandatory use of face masks in a large number of countries. Face recognition methods struggle to perform identity verification with similar accuracy on masked and unmasked individuals. It has been shown that the performance of these methods drops considerably in the presence of face masks, especially if the reference image is unmasked. We propose FocusFace, a multi-task architecture that uses contrastive learning to be able to accurately perform masked face recognition. The proposed architecture is designed to be trained from scratch or to work on top of state-of-the-art face recognition methods without sacrificing the capabilities of a existing models in conventional face recognition tasks. We also explore different approaches to design the contrastive learning module. Results are presented in terms of masked-masked (M-M) and unmasked-masked (U-M) face verification performance. For both settings, the results are on par with published methods, but for M-M specifically, the proposed method was able to outperform all the solutions that it was compared to. We further show that when using our method on top of already existing methods the training computational costs decrease significantly while retaining similar performances. The implementation and the trained models are available at GitHub.