 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021
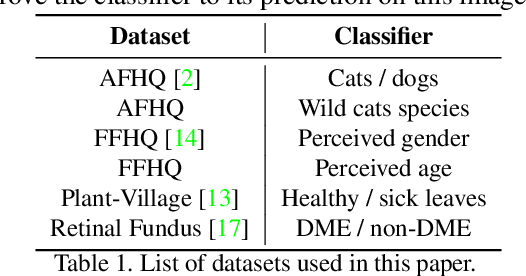
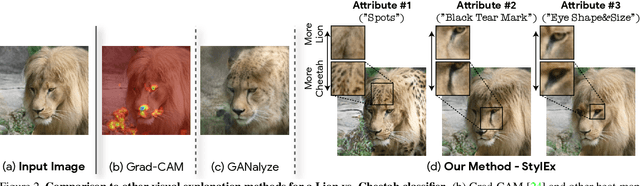
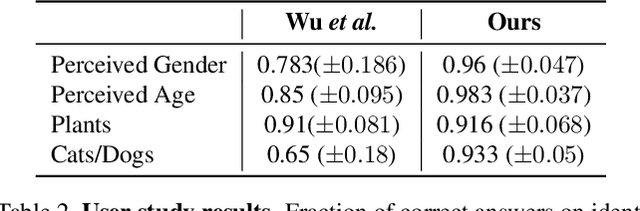
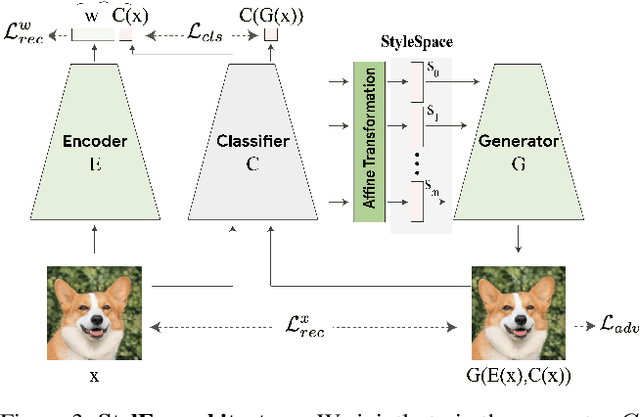
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.
Generative Image Inpainting with Submanifold Alignment
Aug 01, 2019
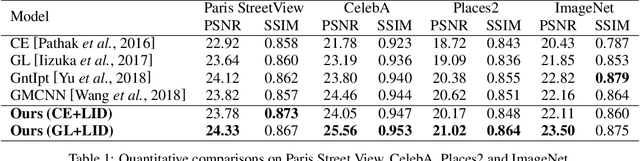
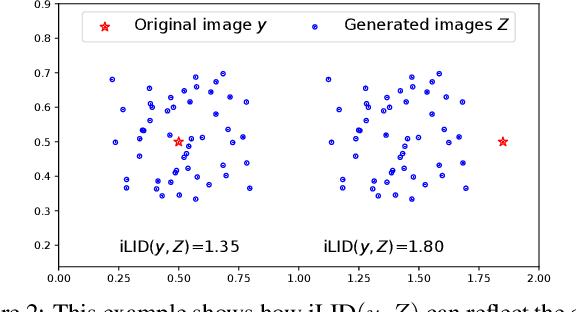
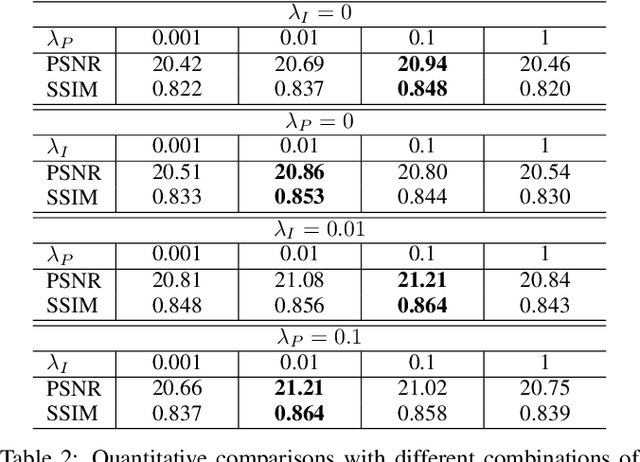
Image inpainting aims at restoring missing regions of corrupted images, which has many applications such as image restoration and object removal. However, current GAN-based generative inpainting models do not explicitly exploit the structural or textural consistency between restored contents and their surrounding contexts.To address this limitation, we propose to enforce the alignment (or closeness) between the local data submanifolds (or subspaces) around restored images and those around the original (uncorrupted) images during the learning process of GAN-based inpainting models. We exploit Local Intrinsic Dimensionality (LID) to measure, in deep feature space, the alignment between data submanifolds learned by a GAN model and those of the original data, from a perspective of both images (denoted as iLID) and local patches (denoted as pLID) of images. We then apply iLID and pLID as regularizations for GAN-based inpainting models to encourage two levels of submanifold alignment: 1) an image-level alignment for improving structural consistency, and 2) a patch-level alignment for improving textural details. Experimental results on four benchmark datasets show that our proposed model can generate more accurate results than state-of-the-art models.
End-to-End License Plate Recognition Pipeline for Real-time Low Resource Video Based Applications
Aug 18, 2021

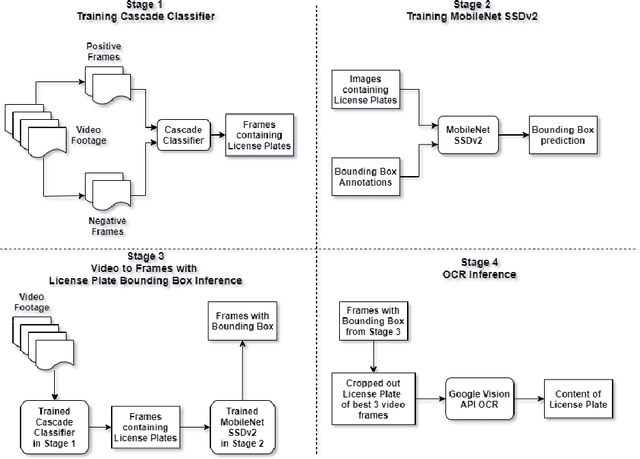
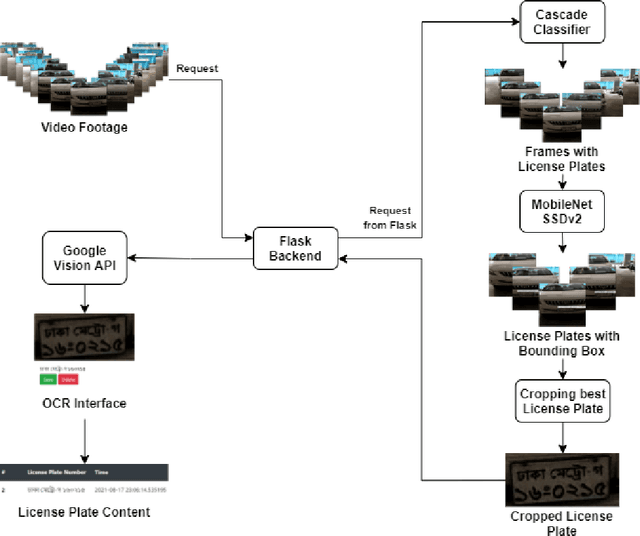
Automatic License Plate Recognition systems aim to provide an end-to-end solution towards detecting, localizing, and recognizing license plate characters from vehicles appearing in video frames. However, deploying such systems in the real world requires real-time performance in low-resource environments. In our paper, we propose a novel two-stage detection pipeline paired with Vision API that aims to provide real-time inference speed along with consistently accurate detection and recognition performance. We used a haar-cascade classifier as a filter on top of our backbone MobileNet SSDv2 detection model. This reduces inference time by only focusing on high confidence detections and using them for recognition. We also impose a temporal frame separation strategy to identify multiple vehicle license plates in the same clip. Furthermore, there are no publicly available Bangla license plate datasets, for which we created an image dataset and a video dataset containing license plates in the wild. We trained our models on the image dataset and achieved an AP(0.5) score of 86% and tested our pipeline on the video dataset and observed reasonable detection and recognition performance (82.7% detection rate, and 60.8% OCR F1 score) with real-time processing speed (27.2 frames per second).
A Good Prompt Is Worth Millions of Parameters? Low-resource Prompt-based Learning for Vision-Language Models
Oct 16, 2021
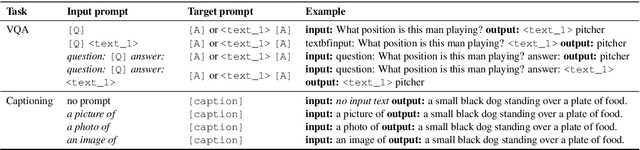
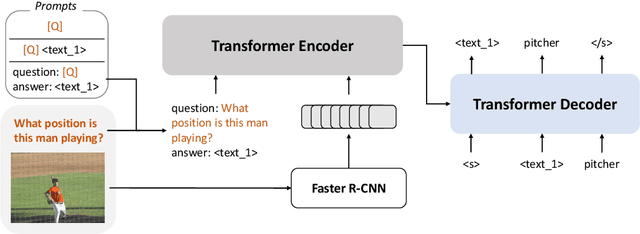
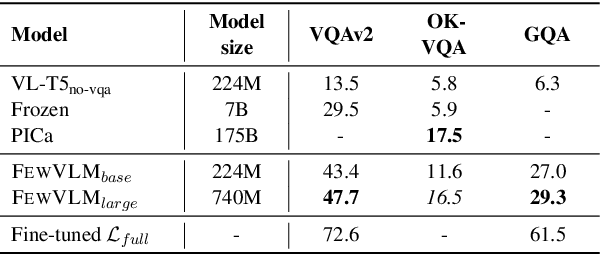
Large pretrained vision-language (VL) models can learn a new task with a handful of examples or generalize to a new task without fine-tuning. However, these gigantic VL models are hard to deploy for real-world applications due to their impractically huge model size and slow inference speed. In this work, we propose FewVLM, a few-shot prompt-based learner on vision-language tasks. We pretrain a sequence-to-sequence Transformer model with both prefix language modeling (PrefixLM) and masked language modeling (MaskedLM), and introduce simple prompts to improve zero-shot and few-shot performance on VQA and image captioning. Experimental results on five VQA and captioning datasets show that \method\xspace outperforms Frozen which is 31 times larger than ours by 18.2% point on zero-shot VQAv2 and achieves comparable results to a 246$\times$ larger model, PICa. We observe that (1) prompts significantly affect zero-shot performance but marginally affect few-shot performance, (2) MaskedLM helps few-shot VQA tasks while PrefixLM boosts captioning performance, and (3) performance significantly increases when training set size is small.
Light Field Synthesis by Training Deep Network in the Refocused Image Domain
Nov 07, 2019

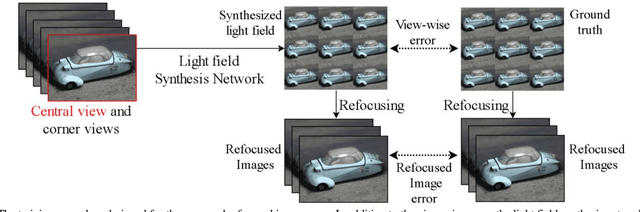
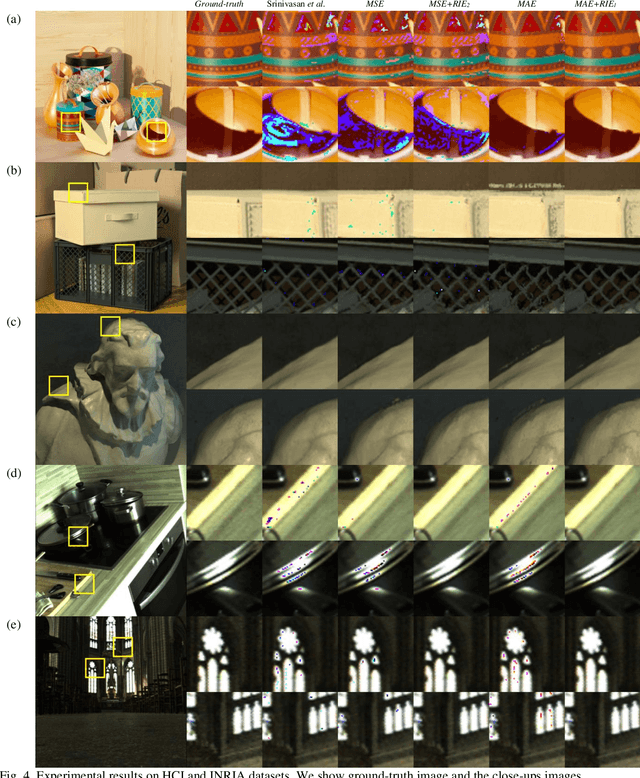
Light field imaging, which captures spatio-angular information of incident light on image sensor, enables many interesting applications like image refocusing and augmented reality. However, due to the limited sensor resolution, a trade-off exists between the spatial and angular resolution. To increase the angular resolution, view synthesis techniques have been adopted to generate new views from existing views. However, traditional learning-based view synthesis mainly considers the image quality of each view of the light field and neglects the quality of the refocused images. In this paper, we propose a new loss function called refocused image error (RIE) to address the issue. The main idea is that the image quality of the synthesized light field should be optimized in the refocused image domain because it is where the light field is perceived. We analyze the behavior of RIL in the spectral domain and test the performance of our approach against previous approaches on both real and software-rendered light field datasets using objective assessment metrics such as MSE, MAE, PSNR, SSIM, and GMSD. Experimental results show that the light field generated by our method results in better refocused images than previous methods.
Toward a Visual Concept Vocabulary for GAN Latent Space
Oct 08, 2021
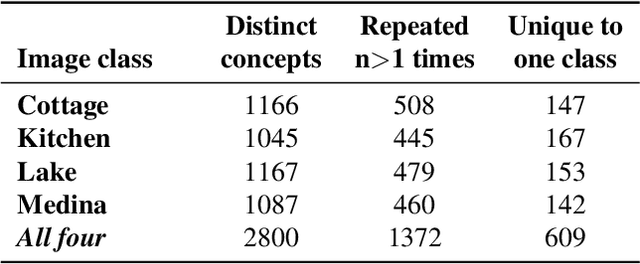

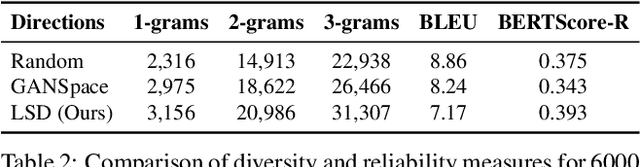
A large body of recent work has identified transformations in the latent spaces of generative adversarial networks (GANs) that consistently and interpretably transform generated images. But existing techniques for identifying these transformations rely on either a fixed vocabulary of pre-specified visual concepts, or on unsupervised disentanglement techniques whose alignment with human judgments about perceptual salience is unknown. This paper introduces a new method for building open-ended vocabularies of primitive visual concepts represented in a GAN's latent space. Our approach is built from three components: (1) automatic identification of perceptually salient directions based on their layer selectivity; (2) human annotation of these directions with free-form, compositional natural language descriptions; and (3) decomposition of these annotations into a visual concept vocabulary, consisting of distilled directions labeled with single words. Experiments show that concepts learned with our approach are reliable and composable -- generalizing across classes, contexts, and observers, and enabling fine-grained manipulation of image style and content.
Recurrent Variational Network: A Deep Learning Inverse Problem Solver applied to the task of Accelerated MRI Reconstruction
Nov 18, 2021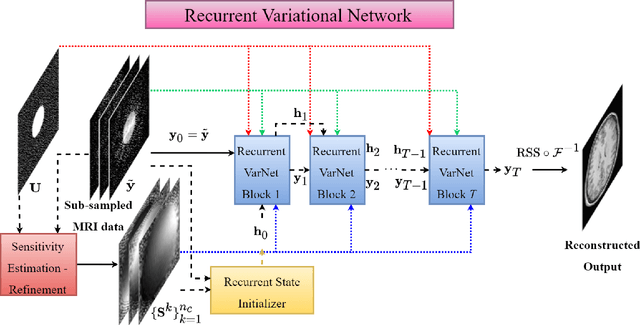
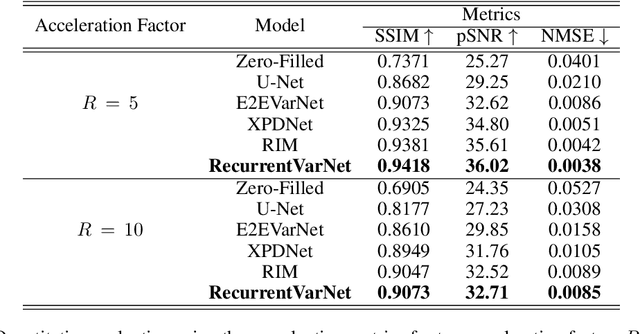
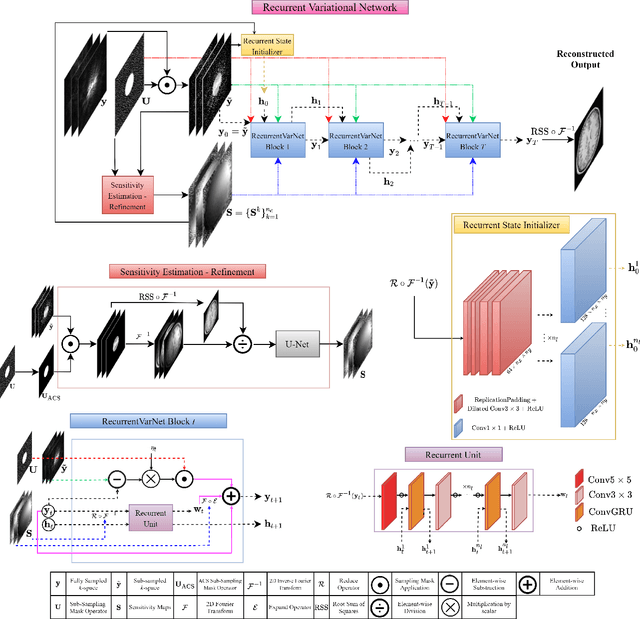

Magnetic Resonance Imaging can produce detailed images of the anatomy and physiology of the human body that can assist doctors in diagnosing and treating pathologies such as tumours. However, MRI suffers from very long acquisition times that make it susceptible to patient motion artifacts and limit its potential to deliver dynamic treatments. Conventional approaches such as Parallel Imaging and Compressed Sensing allow for an increase in MRI acquisition speed by reconstructing MR images by acquiring less MRI data using multiple receiver coils. Recent advancements in Deep Learning combined with Parallel Imaging and Compressed Sensing techniques have the potential to produce high-fidelity reconstructions from highly accelerated MRI data. In this work we present a novel Deep Learning-based Inverse Problem solver applied to the task of accelerated MRI reconstruction, called Recurrent Variational Network (RecurrentVarNet) by exploiting the properties of Convolution Recurrent Networks and unrolled algorithms for solving Inverse Problems. The RecurrentVarNet consists of multiple blocks, each responsible for one unrolled iteration of the gradient descent optimization algorithm for solving inverse problems. Contrary to traditional approaches, the optimization steps are performed in the observation domain ($k$-space) instead of the image domain. Each recurrent block of RecurrentVarNet refines the observed $k$-space and is comprised of a data consistency term and a recurrent unit which takes as input a learned hidden state and the prediction of the previous block. Our proposed method achieves new state of the art qualitative and quantitative reconstruction results on 5-fold and 10-fold accelerated data from a public multi-channel brain dataset, outperforming previous conventional and deep learning-based approaches. We will release all models code and baselines on our public repository.
An Image Based Visual Servo Approach with Deep Learning for Robotic Manipulation
Sep 17, 2019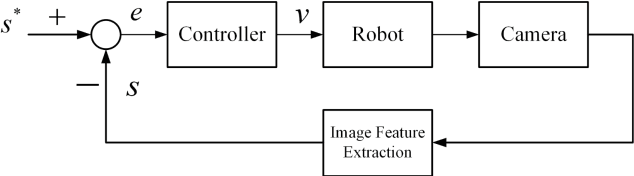
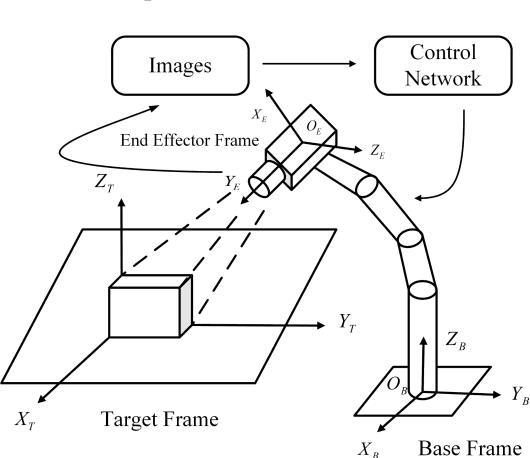
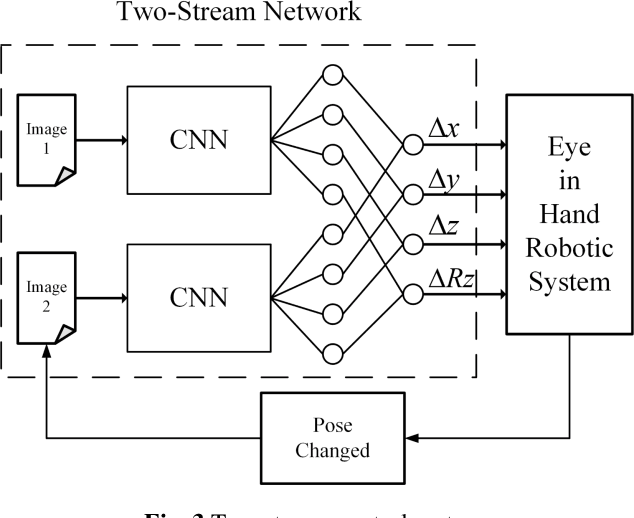
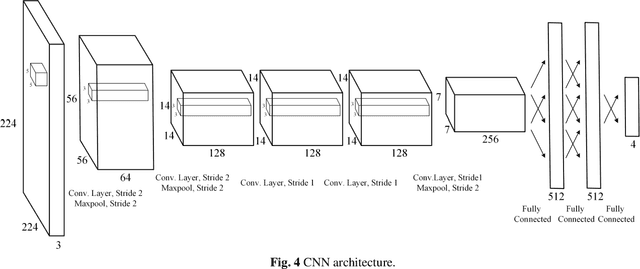
Aiming at the difficulty of extracting image features and estimating the Jacobian matrix in image based visual servo, this paper proposes an image based visual servo approach with deep learning. With the powerful learning capabilities of convolutional neural networks(CNN), autonomous learning to extract features from images and fitting the nonlinear relationships from image space to task space is achieved, which can greatly facilitate the image based visual servo procedure. Based on the above ideas a two-stream network based on convolutional neural network is designed and the corresponding control scheme is proposed to realize the four degrees of freedom visual servo of the robot manipulator. Collecting images of observed target under different pose parameters of the manipulator as training samples for CNN, the trained network can be used to estimate the nonlinear relationship from 2D image space to 3D Cartesian space. The two-stream network takes the current image and the desirable image as inputs and makes them equal to guide the manipulator to the desirable pose. The effectiveness of the approach is verified with experimental results.
Mutual-GAN: Towards Unsupervised Cross-Weather Adaptation with Mutual Information Constraint
Jun 30, 2021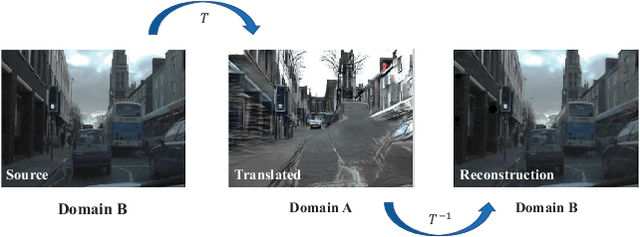
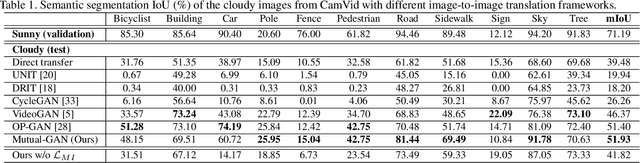
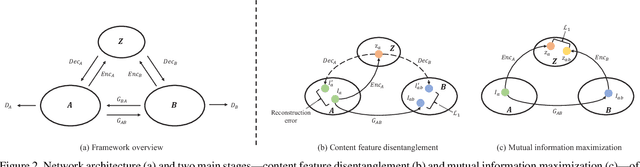
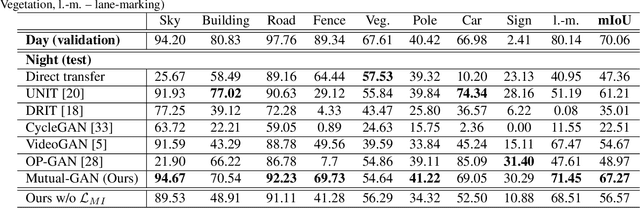
Convolutional neural network (CNN) have proven its success for semantic segmentation, which is a core task of emerging industrial applications such as autonomous driving. However, most progress in semantic segmentation of urban scenes is reported on standard scenarios, i.e., daytime scenes with favorable illumination conditions. In practical applications, the outdoor weather and illumination are changeable, e.g., cloudy and nighttime, which results in a significant drop of semantic segmentation accuracy of CNN only trained with daytime data. In this paper, we propose a novel generative adversarial network (namely Mutual-GAN) to alleviate the accuracy decline when daytime-trained neural network is applied to videos captured under adverse weather conditions. The proposed Mutual-GAN adopts mutual information constraint to preserve image-objects during cross-weather adaptation, which is an unsolved problem for most unsupervised image-to-image translation approaches (e.g., CycleGAN). The proposed Mutual-GAN is evaluated on two publicly available driving video datasets (i.e., CamVid and SYNTHIA). The experimental results demonstrate that our Mutual-GAN can yield visually plausible translated images and significantly improve the semantic segmentation accuracy of daytime-trained deep learning network while processing videos under challenging weathers.
Homotopic Gradients of Generative Density Priors for MR Image Reconstruction
Aug 14, 2020
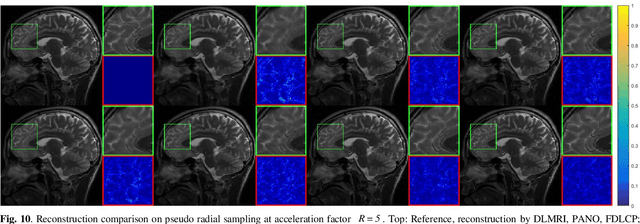
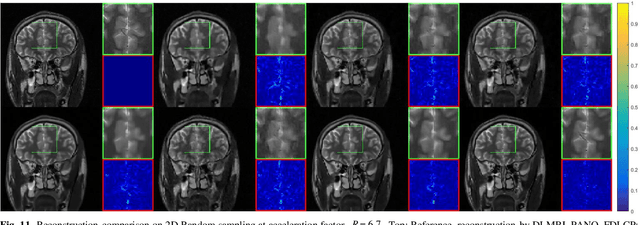
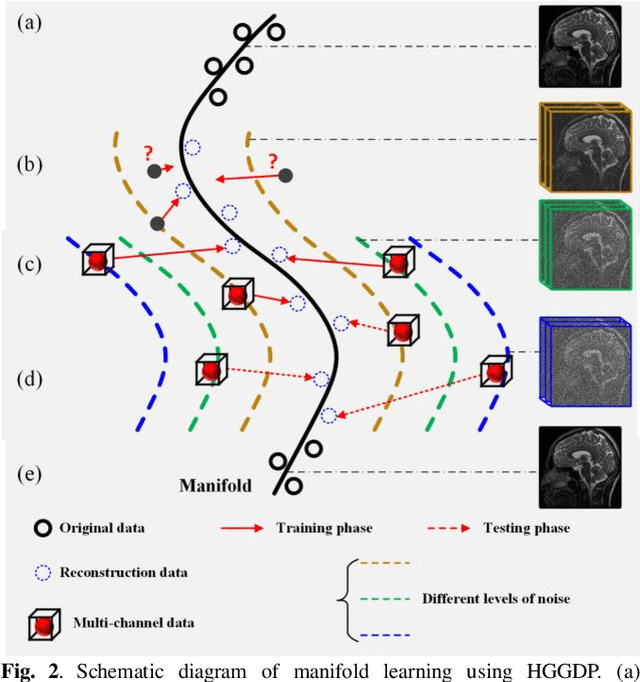
Deep learning, particularly the generative model, has demonstrated tremendous potential to significantly speed up image reconstruction with reduced measurements recently. Rather than the existing generative models that often optimize the density priors, in this work, by taking advantage of the denoising score matching, homotopic gradients of generative density priors (HGGDP) are proposed for magnetic resonance imaging (MRI) reconstruction. More precisely, to tackle the low-dimensional manifold and low data density region issues in generative density prior, we estimate the target gradients in higher-dimensional space. We train a more powerful noise conditional score network by forming high-dimensional tensor as the network input at the training phase. More artificial noise is also injected in the embedding space. At the reconstruction stage, a homotopy method is employed to pursue the density prior, such as to boost the reconstruction performance. Experiment results imply the remarkable performance of HGGDP in terms of high reconstruction accuracy; only 10% of the k-space data can still generate images of high quality as effectively as standard MRI reconstruction with the fully sampled data.