 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Follow the Curve: Robotic-Ultrasound Navigation with Learning Based Localization of Spinous Processes for Scoliosis Assessment
Sep 11, 2021
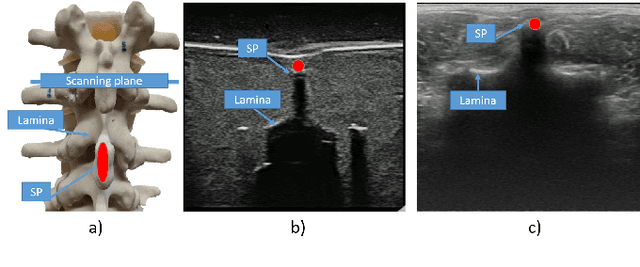
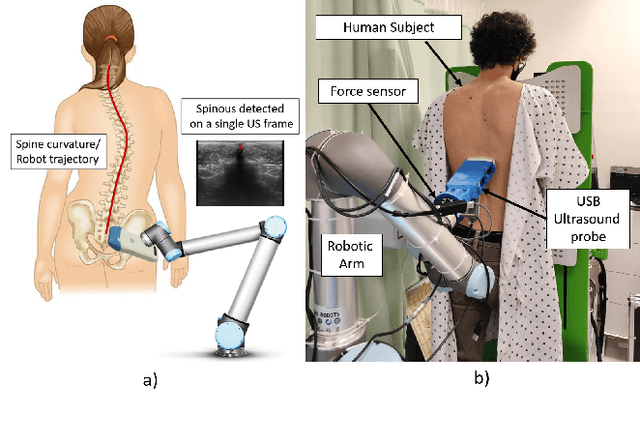
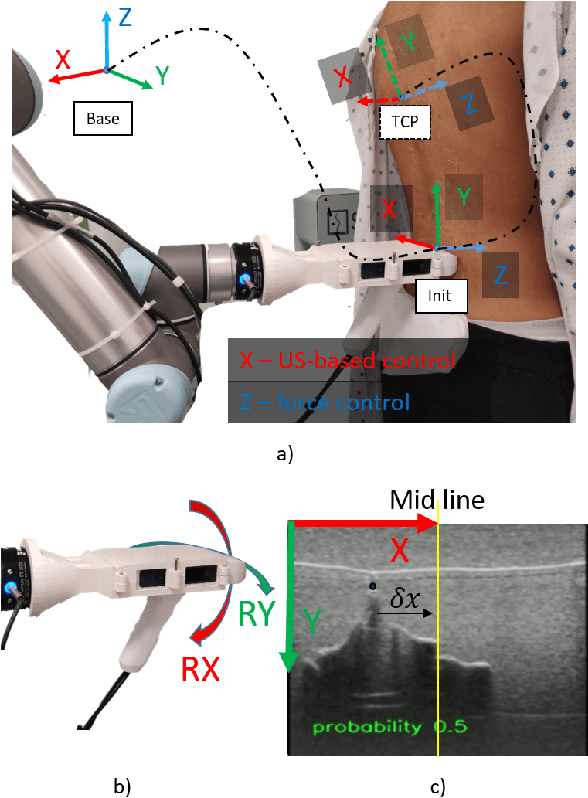
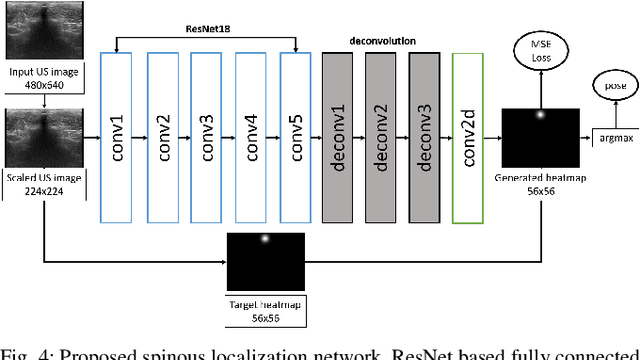
The scoliosis progression in adolescents requires close monitoring to timely take treatment measures. Ultrasound imaging is a radiation-free and low-cost alternative in scoliosis assessment to X-rays, which are typically used in clinical practice. However, ultrasound images are prone to speckle noises, making it challenging for sonographers to detect bony features and follow the spine's curvature. This paper introduces a robotic-ultrasound approach for spinal curvature tracking and automatic navigation. A fully connected network with deconvolutional heads is developed to locate the spinous process efficiently with real-time ultrasound images. We use this machine learning-based method to guide the motion of the robot-held ultrasound probe and follow the spinal curvature while capturing ultrasound images and correspondent position. We developed a new force-driven controller that automatically adjusts the probe's pose relative to the skin surface to ensure a good acoustic coupling between the probe and skin. After the scanning, the acquired data is used to reconstruct the coronal spinal image, where the deformity of the scoliosis spine can be assessed and measured. To evaluate the performance of our methodology, we conducted an experimental study with human subjects where the deviations from the image center during the robotized procedure are compared to that obtained from manual scanning. The angles of spinal deformity measured on spinal reconstruction images were similar for both methods, implying that they equally reflect human anatomy.
Detecting Blurred Ground-based Sky/Cloud Images
Oct 19, 2021


Ground-based whole sky imagers (WSIs) are being used by researchers in various fields to study the atmospheric events. These ground-based sky cameras capture visible-light images of the sky at regular intervals of time. Owing to the atmospheric interference and camera sensor noise, the captured images often exhibit noise and blur. This may pose a problem in subsequent image processing stages. Therefore, it is important to accurately identify the blurred images. This is a difficult task, as clouds have varying shapes, textures, and soft edges whereas the sky acts as a homogeneous and uniform background. In this paper, we propose an efficient framework that can identify the blurred sky/cloud images. Using a static external marker, our proposed methodology has a detection accuracy of 94\%. To the best of our knowledge, our approach is the first of its kind in the automatic identification of blurred images for ground-based sky/cloud images.
MetaSketch: Wireless Semantic Segmentation by Metamaterial Surfaces
Aug 29, 2021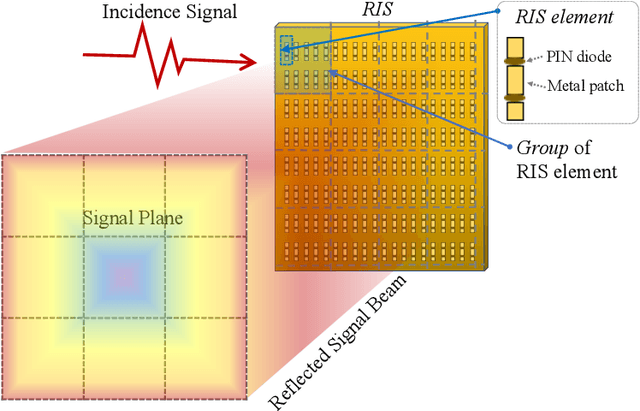
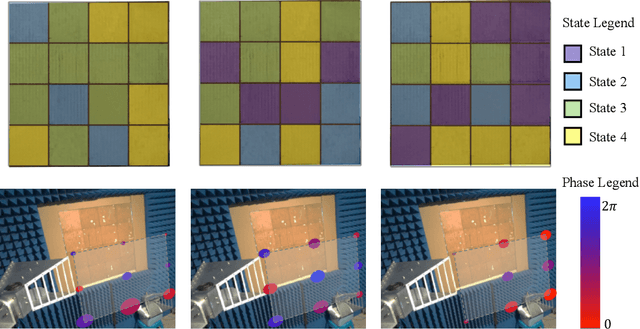

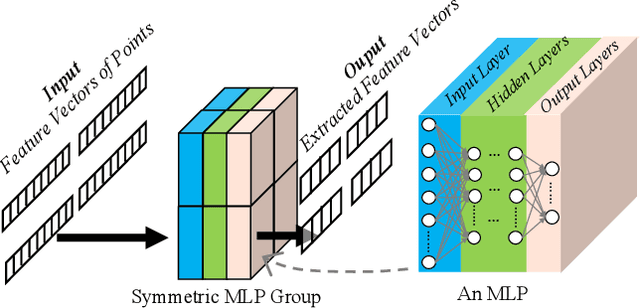
Semantic segmentation is a process of partitioning an image into multiple segments for recognizing humans and objects, which can be widely applied in scenarios such as healthcare and safety monitoring. To avoid privacy violation, using RF signals instead of an image for human and object recognition has gained increasing attention. However, human and object recognition by using RF signals is usually a passive signal collection and analysis process without changing the radio environment, and the recognition accuracy is restricted significantly by unwanted multi-path fading, and/or the limited number of independent channels between RF transceivers in uncontrollable radio environments. This paper introduces MetaSketch, a novel RF-sensing system that performs semantic recognition and segmentation for humans and objects by making the radio environment reconfigurable. A metamaterial surface is incorporated into MetaSketch and diversifies the information carried by RF signals. Using compressive sensing techniques, MetaSketch reconstructs a point cloud consisting of the reflection coefficients of humans and objects at different spatial points, and recognizes the semantic meaning of the points by using symmetric multilayer perceptron groups. Our evaluation results show that MetaSketch is capable of generating favorable radio environments and extracting exact point clouds, and labeling the semantic meaning of the points with an average error rate of less than 1% in an indoor space.
Exploring Machine Teaching with Children
Sep 27, 2021
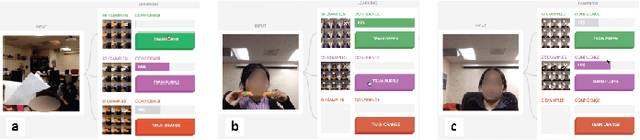

Iteratively building and testing machine learning models can help children develop creativity, flexibility, and comfort with machine learning and artificial intelligence. We explore how children use machine teaching interfaces with a team of 14 children (aged 7-13 years) and adult co-designers. Children trained image classifiers and tested each other's models for robustness. Our study illuminates how children reason about ML concepts, offering these insights for designing machine teaching experiences for children: (i) ML metrics (e.g. confidence scores) should be visible for experimentation; (ii) ML activities should enable children to exchange models for promoting reflection and pattern recognition; and (iii) the interface should allow quick data inspection (e.g. images vs. gestures).
* 11 pages, 8 images
End-to-End Boundary Aware Networks for Medical Image Segmentation
Sep 10, 2019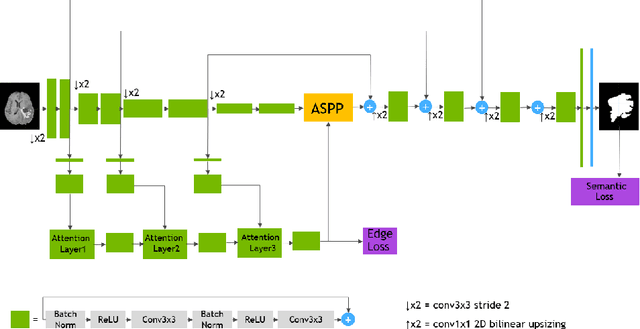
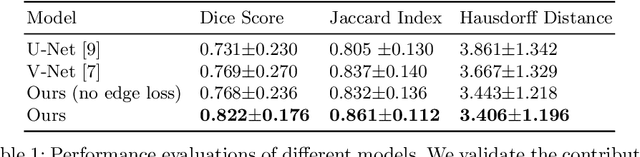
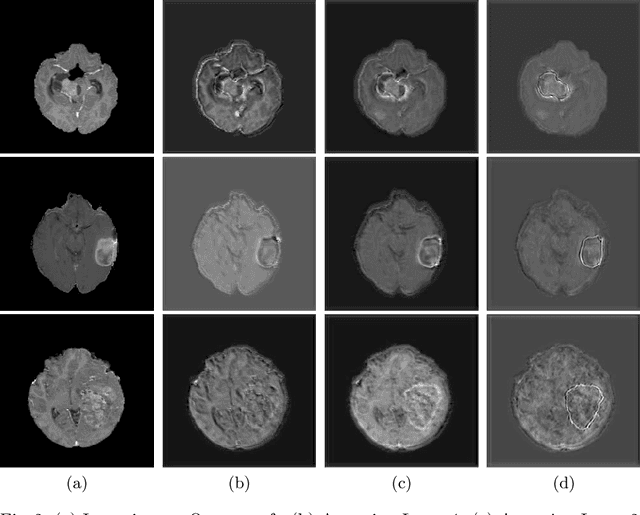
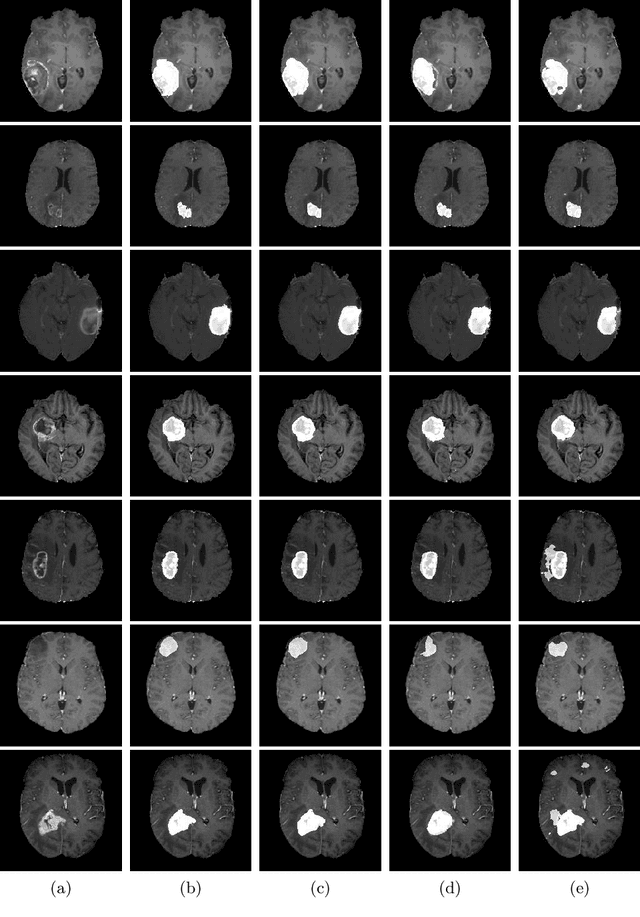
Fully convolutional neural networks (CNNs) have proven to be effective at representing and classifying textural information, thus transforming image intensity into output class masks that achieve semantic image segmentation. In medical image analysis, however, expert manual segmentation often relies on the boundaries of anatomical structures of interest. We propose boundary aware CNNs for medical image segmentation. Our networks are designed to account for organ boundary information, both by providing a special network edge branch and edge-aware loss terms, and they are trainable end-to-end. We validate their effectiveness on the task of brain tumor segmentation using the BraTS 2018 dataset. Our experiments reveal that our approach yields more accurate segmentation results, which makes it promising for more extensive application to medical image segmentation.
* Accepted to MICCAI Machine Learning in Medical Imaging (MLMI 2019)
Penalized-likelihood PET Image Reconstruction Using 3D Structural Convolutional Sparse Coding
Dec 16, 2019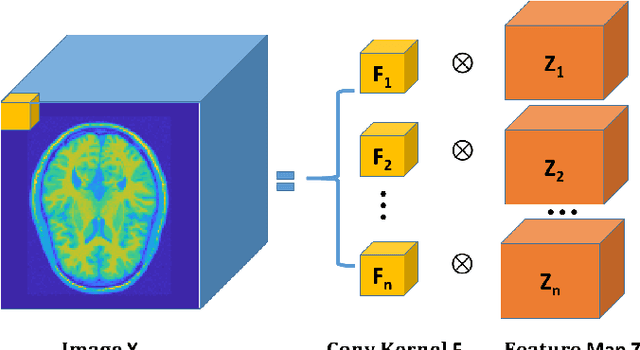
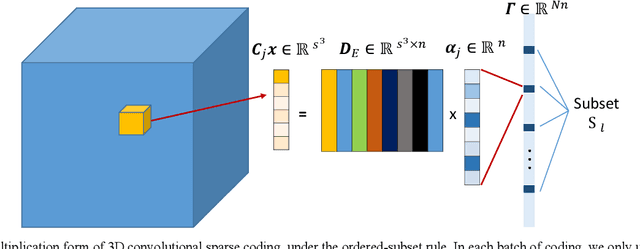
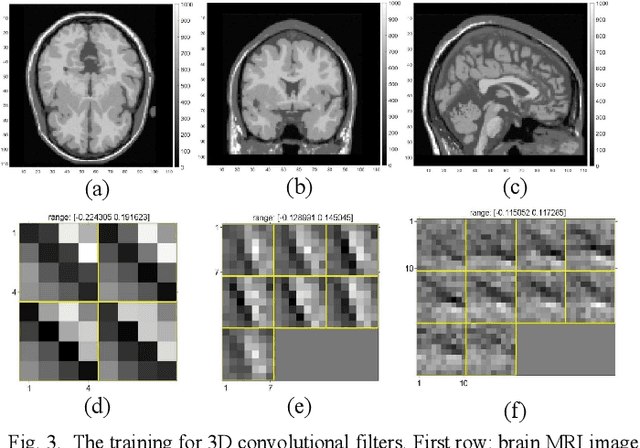
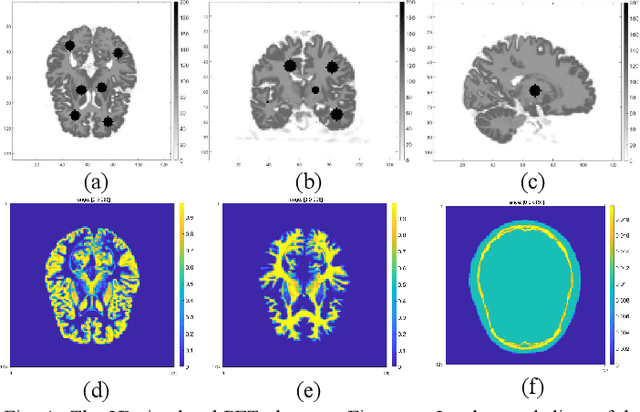
Positron emission tomography (PET) is widely used for clinical diagnosis. As PET suffers from low resolution and high noise, numerous efforts try to incorporate anatomical priors into PET image reconstruction, especially with the development of hybrid PET/CT and PET/MRI systems. In this work, we proposed a novel 3D structural convolutional sparse coding (CSC) concept for penalized-likelihood PET image reconstruction, named 3D PET-CSC. The proposed 3D PET-CSC takes advantage of the convolutional operation and manages to incorporate anatomical priors without the need of registration or supervised training. As 3D PET-CSC codes the whole 3D PET image, instead of patches, it alleviates the staircase artifacts commonly presented in traditional patch-based sparse coding methods. Moreover, we developed the residual-image and order-subset mechanisms to further reduce the computational cost and accelerate the convergence for the proposed 3D PET-CSC method. Experiments based on computer simulations and clinical datasets demonstrate the superiority of 3D PET-CSC compared with other reference methods.
A Weighted Difference of Anisotropic and Isotropic Total Variation for Relaxed Mumford-Shah Color and Multiphase Image Segmentation
May 09, 2020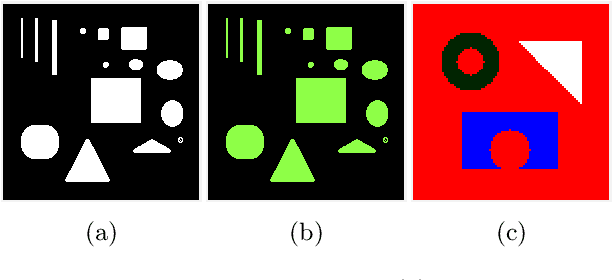


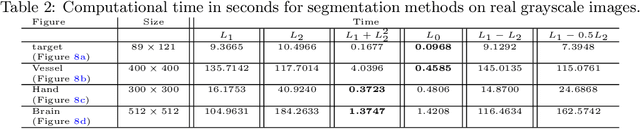
In a class of piecewise-constant image segmentation models, we incorporate a weighted difference of anisotropic and isotropic total variation (TV) to regularize the partition boundaries in an image. To deal with the weighted anisotropic-isotropic TV, we apply the difference-of-convex algorithm (DCA), where the subproblems can be minimized by the primal-dual hybrid gradient method (PDHG). As a result, we are able to design an alternating minimization algorithm to solve the proposed image segmentation models. The models and algorithms are further extended to segment color images and to perform multiphase segmentation. In the numerical experiments, we compare our proposed models with the Chan-Vese models that use either anisotropic or isotropic TV and the two-stage segmentation methods (denoising and then thresholding) on various images. The results demonstrate the effectiveness and robustness of incorporating weighted anisotropic-isotropic TV in image segmentation.
An optical biomimetic eyes with interested object imaging
Aug 08, 2021
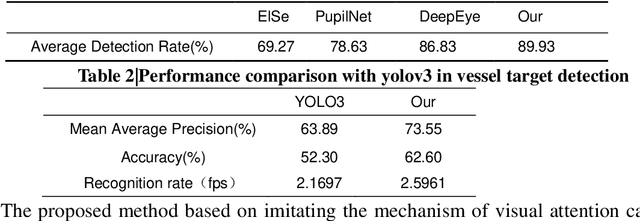
We presented an optical system to perform imaging interested objects in complex scenes, like the creature easy see the interested prey in the hunt for complex environments. It utilized Deep-learning network to learn the interested objects's vision features and designed the corresponding "imaging matrices", furthermore the learned matrixes act as the measurement matrix to complete compressive imaging with a single-pixel camera, finally we can using the compressed image data to only image the interested objects without the rest objects and backgrounds of the scenes with the previous Deep-learning network. Our results demonstrate that no matter interested object is single feature or rich details, the interference can be successfully filtered out and this idea can be applied in some common applications that effectively improve the performance. This bio-inspired optical system can act as the creature eye to achieve success on interested-based object imaging, object detection, object recognition and object tracking, etc.
Human Pose and Shape Estimation from Single Polarization Images
Aug 15, 2021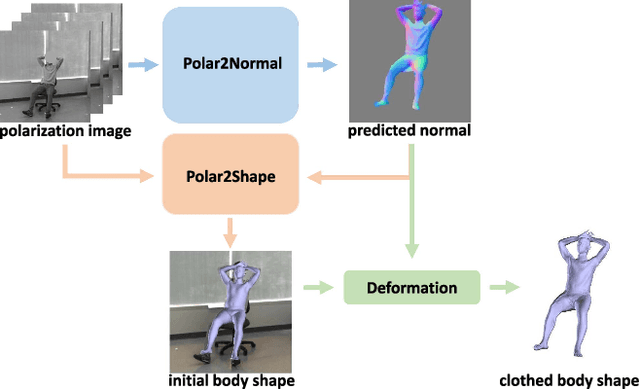
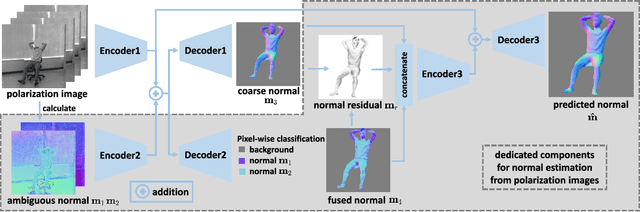
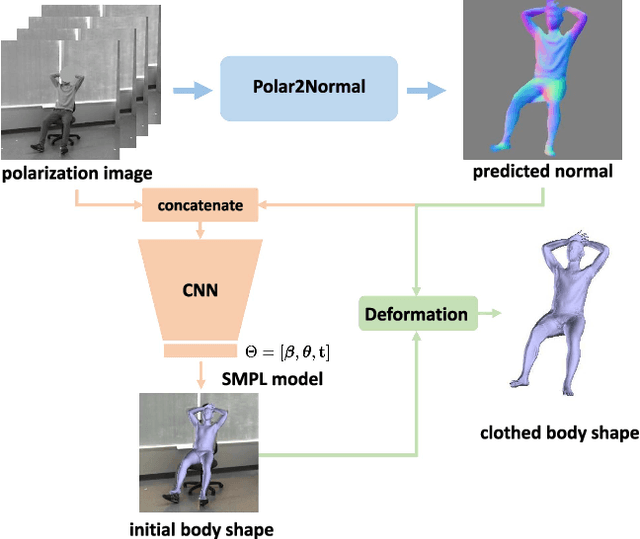
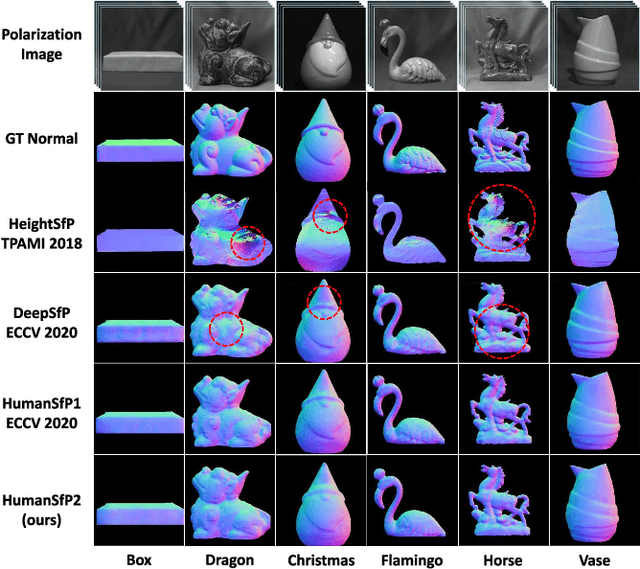
This paper focuses on a new problem of estimating human pose and shape from single polarization images. Polarization camera is known to be able to capture the polarization of reflected lights that preserves rich geometric cues of an object surface. Inspired by the recent applications in surface normal reconstruction from polarization images, in this paper, we attempt to estimate human pose and shape from single polarization images by leveraging the polarization-induced geometric cues. A dedicated two-stage pipeline is proposed: given a single polarization image, stage one (Polar2Normal) focuses on the fine detailed human body surface normal estimation; stage two (Polar2Shape) then reconstructs clothed human shape from the polarization image and the estimated surface normal. To empirically validate our approach, a dedicated dataset (PHSPD) is constructed, consisting of over 500K frames with accurate pose and shape annotations. Empirical evaluations on this real-world dataset as well as a synthetic dataset, SURREAL, demonstrate the effectiveness of our approach. It suggests polarization camera as a promising alternative to the more conventional RGB camera for human pose and shape estimation.
Meta-Learning for Multi-Label Few-Shot Classification
Oct 26, 2021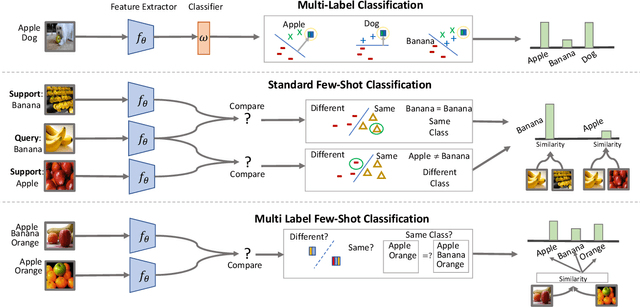
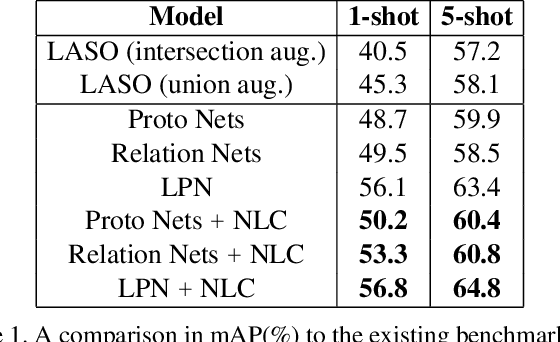
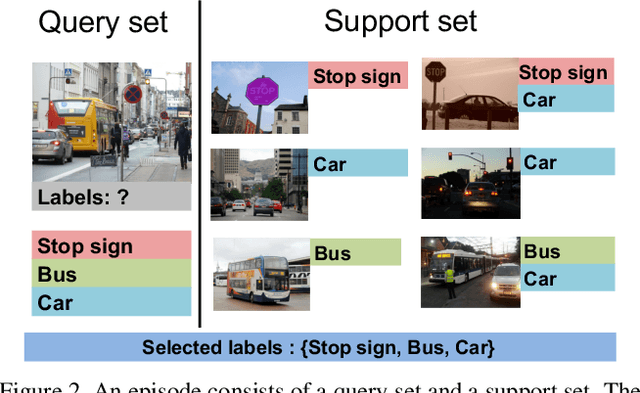
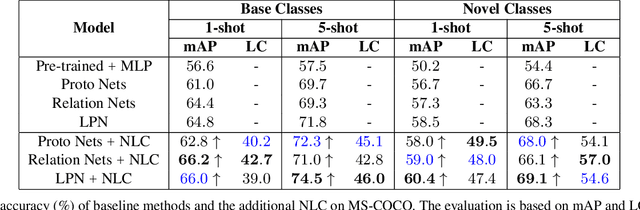
Even with the luxury of having abundant data, multi-label classification is widely known to be a challenging task to address. This work targets the problem of multi-label meta-learning, where a model learns to predict multiple labels within a query (e.g., an image) by just observing a few supporting examples. In doing so, we first propose a benchmark for Few-Shot Learning (FSL) with multiple labels per sample. Next, we discuss and extend several solutions specifically designed to address the conventional and single-label FSL, to work in the multi-label regime. Lastly, we introduce a neural module to estimate the label count of a given sample by exploiting the relational inference. We will show empirically the benefit of the label count module, the label propagation algorithm, and the extensions of conventional FSL methods on three challenging datasets, namely MS-COCO, iMaterialist, and Open MIC. Overall, our thorough experiments suggest that the proposed label-propagation algorithm in conjunction with the neural label count module (NLC) shall be considered as the method of choice.