 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Challenging deep image descriptors for retrieval in heterogeneous iconographic collections
Sep 19, 2019
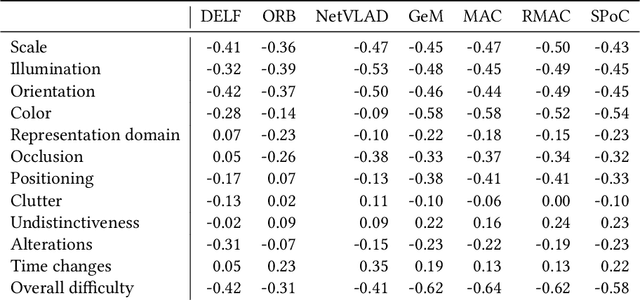
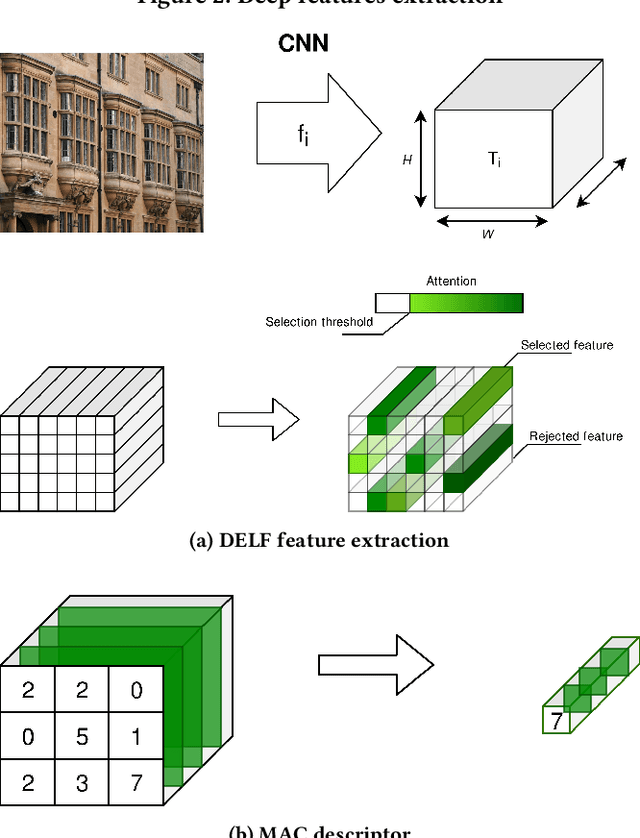

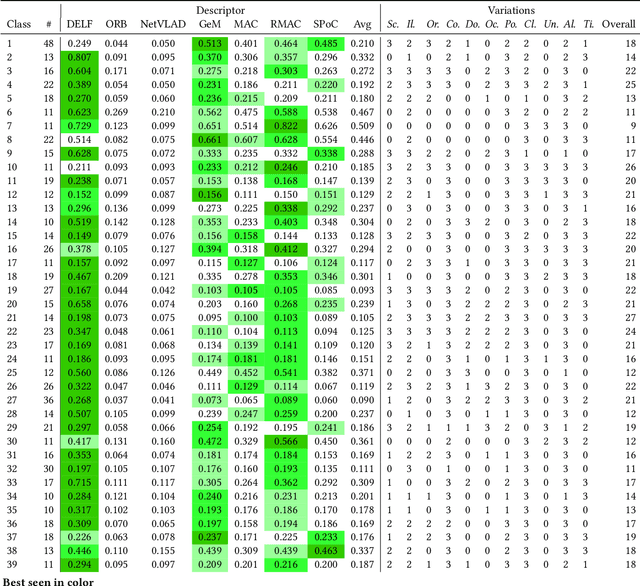
This article proposes to study the behavior of recent and efficient state-of-the-art deep-learning based image descriptors for content-based image retrieval, facing a panel of complex variations appearing in heterogeneous image datasets, in particular in cultural collections that may involve multi-source, multi-date and multi-view Permission to make digital
Sim2Air - Synthetic aerial dataset for UAV monitoring
Oct 11, 2021



In this paper we propose a novel approach to generate a synthetic aerial dataset for application in UAV monitoring. We propose to accentuate shape-based object representation by applying texture randomization. A diverse dataset with photorealism in all parameters such as shape, pose, lighting, scale, viewpoint, etc. except for atypical textures is created in a 3D modelling software Blender. Our approach specifically targets two conditions in aerial images where texture of objects is difficult to detect, namely illumination changes and objects occupying only a small portion of the image. Experimental evaluation confirmed our approach by increasing the mAP value by 17 and 3.7 points on two test datasets of real images. In analysing domain similarity, we conclude that the more the generalisation capability is put to the test, the more obvious are the advantages of the shape-based representation.
TYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video
Nov 19, 2021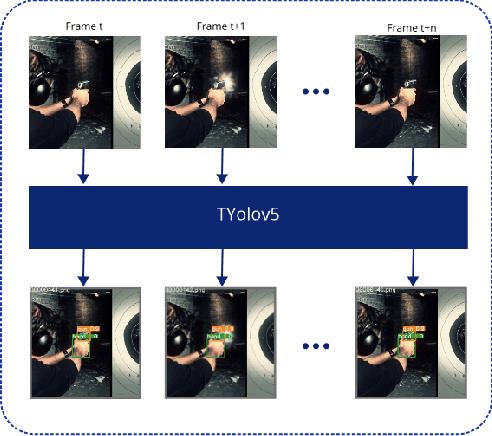
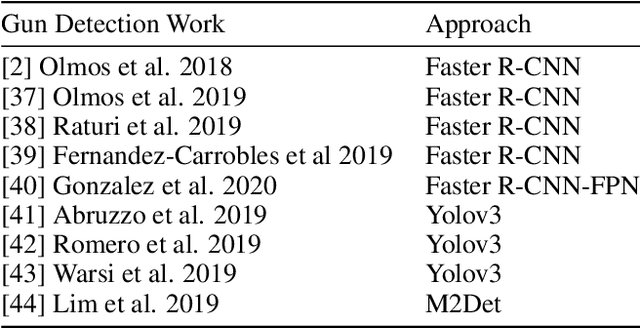
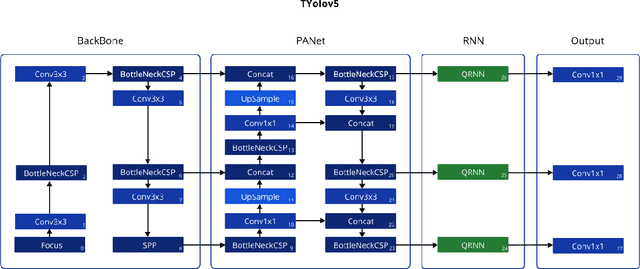
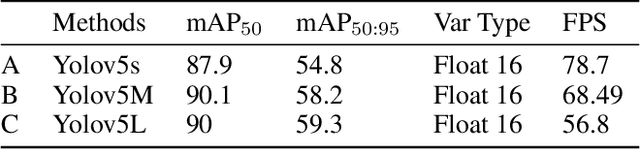
Timely handgun detection is a crucial problem to improve public safety; nevertheless, the effectiveness of many surveillance systems still depends of finite human attention. Much of the previous research on handgun detection is based on static image detectors, leaving aside valuable temporal information that could be used to improve object detection in videos. To improve the performance of surveillance systems, a real-time temporal handgun detection system should be built. Using Temporal Yolov5, an architecture based on Quasi-Recurrent Neural Networks, temporal information is extracted from video to improve the results of handgun detection. Moreover, two publicly available datasets are proposed, labeled with hands, guns, and phones. One containing 2199 static images to train static detectors, and another with 5960 frames of videos to train temporal modules. Additionally, we explore two temporal data augmentation techniques based on Mosaic and Mixup. The resulting systems are three temporal architectures: one focused in reducing inference with a mAP$_{50:95}$ of 55.9, another in having a good balance between inference and accuracy with a mAP$_{50:95}$ of 59, and a last one specialized in accuracy with a mAP$_{50:95}$ of 60.2. Temporal Yolov5 achieves real-time detection in the small and medium architectures. Moreover, it takes advantage of temporal features contained in videos to perform better than Yolov5 in our temporal dataset, making TYolov5 suitable for real-world applications. The source code is publicly available at https://github.com/MarioDuran/TYolov5.
Learning a Generative Transition Model for Uncertainty-Aware Robotic Manipulation
Jul 06, 2021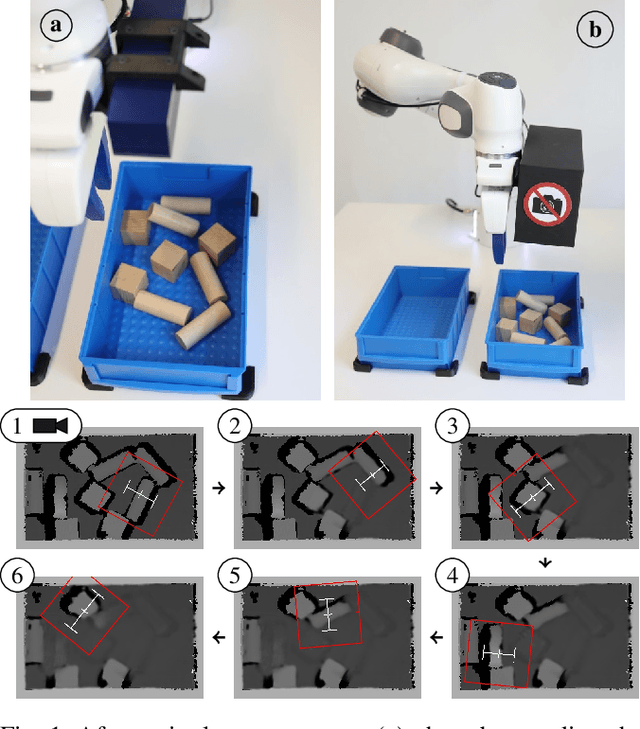
Robot learning of real-world manipulation tasks remains challenging and time consuming, even though actions are often simplified by single-step manipulation primitives. In order to compensate the removed time dependency, we additionally learn an image-to-image transition model that is able to predict a next state including its uncertainty. We apply this approach to bin picking, the task of emptying a bin using grasping as well as pre-grasping manipulation as fast as possible. The transition model is trained with up to 42000 pairs of real-world images before and after a manipulation action. Our approach enables two important skills: First, for applications with flange-mounted cameras, picks per hours (PPH) can be increased by around 15% by skipping image measurements. Second, we use the model to plan action sequences ahead of time and optimize time-dependent rewards, e.g. to minimize the number of actions required to empty the bin. We evaluate both improvements with real-robot experiments and achieve over 700 PPH in the YCB Box and Blocks Test.
Using Metamorphic Relations to Verify and Enhance Artcode Classification
Aug 05, 2021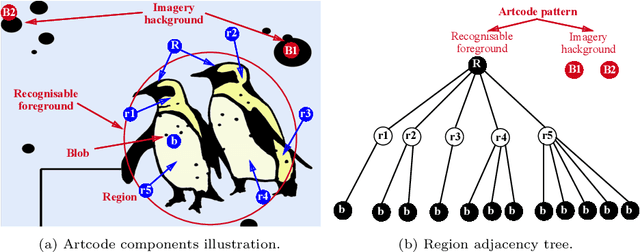
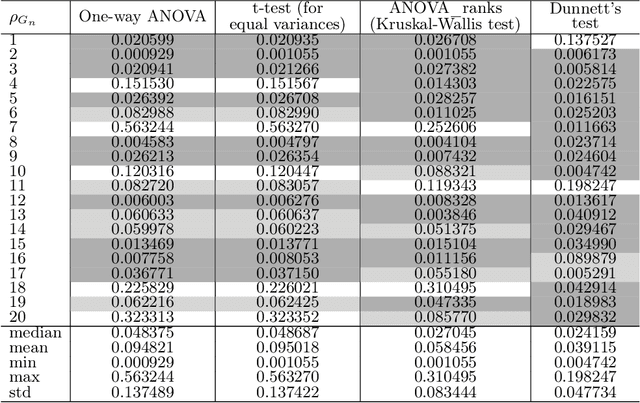


Software testing is often hindered where it is impossible or impractical to determine the correctness of the behaviour or output of the software under test (SUT), a situation known as the oracle problem. An example of an area facing the oracle problem is automatic image classification, using machine learning to classify an input image as one of a set of predefined classes. An approach to software testing that alleviates the oracle problem is metamorphic testing (MT). While traditional software testing examines the correctness of individual test cases, MT instead examines the relations amongst multiple executions of test cases and their outputs. These relations are called metamorphic relations (MRs): if an MR is found to be violated, then a fault must exist in the SUT. This paper examines the problem of classifying images containing visually hidden markers called Artcodes, and applies MT to verify and enhance the trained classifiers. This paper further examines two MRs, Separation and Occlusion, and reports on their capability in verifying the image classification using one-way analysis of variance (ANOVA) in conjunction with three other statistical analysis methods: t-test (for unequal variances), Kruskal-Wallis test, and Dunnett's test. In addition to our previously-studied classifier, that used Random Forests, we introduce a new classifier that uses a support vector machine, and present its MR-augmented version. Experimental evaluations across a number of performance metrics show that the augmented classifiers can achieve better performance than non-augmented classifiers. This paper also analyses how the enhanced performance is obtained.
Superpixel Image Classification with Graph Attention Networks
Feb 13, 2020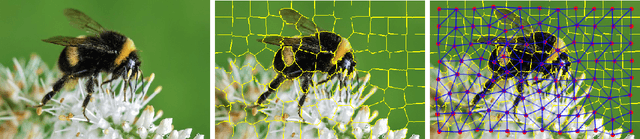
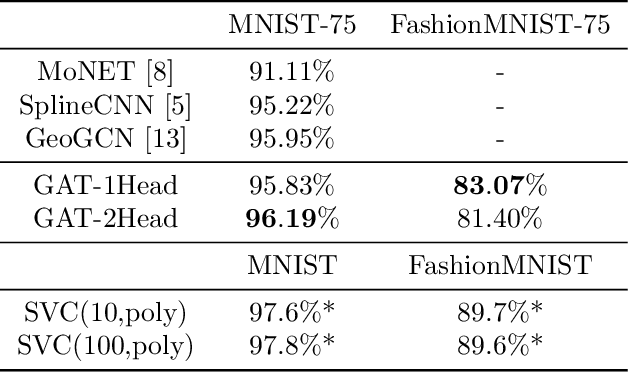
This document reports the use of Graph Attention Networks for classifying oversegmented images, as well as a general procedure for generating oversegmented versions of image-based datasets. The code and learnt models for/from the experiments are available on github. The experiments were ran from June 2019 until December 2019. We obtained better results than the baseline models that uses geometric distance-based attention by using instead self attention, in a more sparsely connected graph network.
Self-Supervised Fine-tuning for Image Enhancement of Super-Resolution Deep Neural Networks
Dec 30, 2019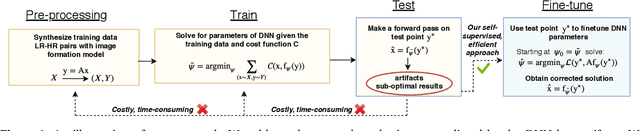



While Deep Neural Networks (DNNs) trained for image and video super-resolution regularly achieve new state-of-the-art performance, they also suffer from significant drawbacks. One of their limitations is their tendency to generate strong artifacts in their solution. This may occur when the low-resolution image formation model does not match that seen during training. Artifacts also regularly arise when training Generative Adversarial Networks for inverse imaging problems. In this paper, we propose an efficient, fully self-supervised approach to remove the observed artifacts. More specifically, at test time, given an image and its known image formation model, we fine-tune the parameters of the trained network and iteratively update them using a data consistency loss. We apply our method to image and video super-resolution neural networks and show that our proposed framework consistently enhances the solution originally provided by the neural network.
Detecting Blurred Ground-based Sky/Cloud Images
Oct 19, 2021


Ground-based whole sky imagers (WSIs) are being used by researchers in various fields to study the atmospheric events. These ground-based sky cameras capture visible-light images of the sky at regular intervals of time. Owing to the atmospheric interference and camera sensor noise, the captured images often exhibit noise and blur. This may pose a problem in subsequent image processing stages. Therefore, it is important to accurately identify the blurred images. This is a difficult task, as clouds have varying shapes, textures, and soft edges whereas the sky acts as a homogeneous and uniform background. In this paper, we propose an efficient framework that can identify the blurred sky/cloud images. Using a static external marker, our proposed methodology has a detection accuracy of 94\%. To the best of our knowledge, our approach is the first of its kind in the automatic identification of blurred images for ground-based sky/cloud images.
Follow the Curve: Robotic-Ultrasound Navigation with Learning Based Localization of Spinous Processes for Scoliosis Assessment
Sep 11, 2021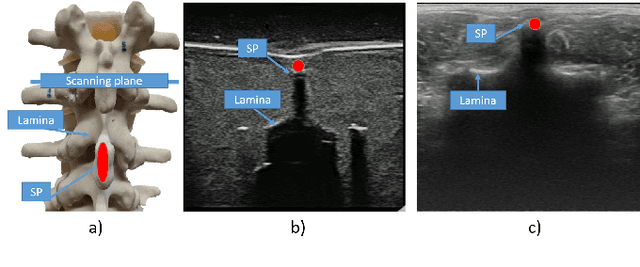
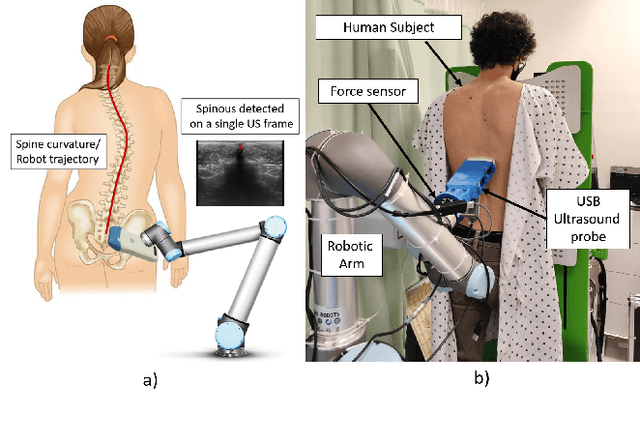
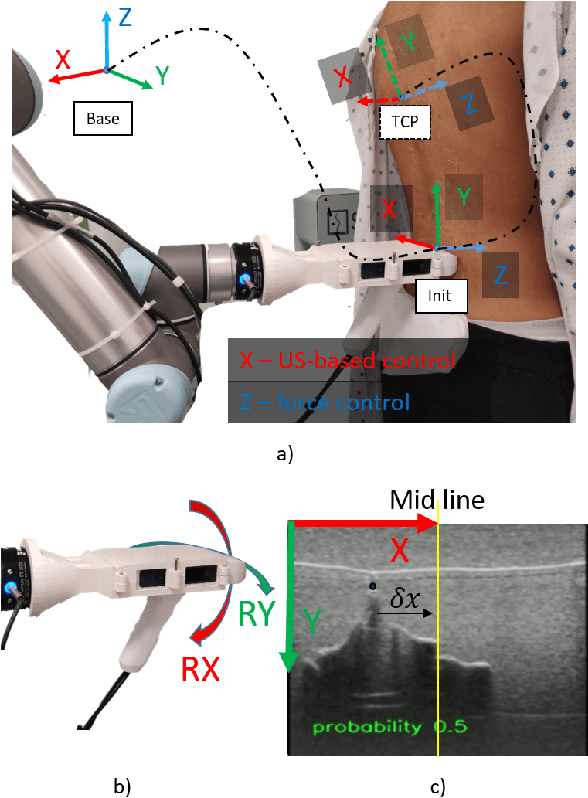
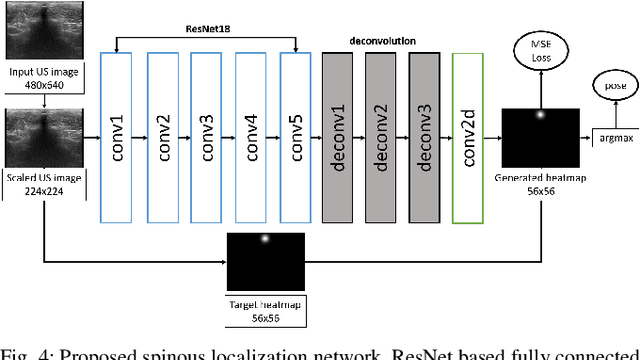
The scoliosis progression in adolescents requires close monitoring to timely take treatment measures. Ultrasound imaging is a radiation-free and low-cost alternative in scoliosis assessment to X-rays, which are typically used in clinical practice. However, ultrasound images are prone to speckle noises, making it challenging for sonographers to detect bony features and follow the spine's curvature. This paper introduces a robotic-ultrasound approach for spinal curvature tracking and automatic navigation. A fully connected network with deconvolutional heads is developed to locate the spinous process efficiently with real-time ultrasound images. We use this machine learning-based method to guide the motion of the robot-held ultrasound probe and follow the spinal curvature while capturing ultrasound images and correspondent position. We developed a new force-driven controller that automatically adjusts the probe's pose relative to the skin surface to ensure a good acoustic coupling between the probe and skin. After the scanning, the acquired data is used to reconstruct the coronal spinal image, where the deformity of the scoliosis spine can be assessed and measured. To evaluate the performance of our methodology, we conducted an experimental study with human subjects where the deviations from the image center during the robotized procedure are compared to that obtained from manual scanning. The angles of spinal deformity measured on spinal reconstruction images were similar for both methods, implying that they equally reflect human anatomy.
Exploring Machine Teaching with Children
Sep 27, 2021
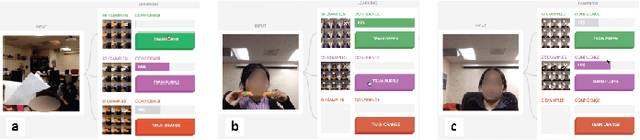

Iteratively building and testing machine learning models can help children develop creativity, flexibility, and comfort with machine learning and artificial intelligence. We explore how children use machine teaching interfaces with a team of 14 children (aged 7-13 years) and adult co-designers. Children trained image classifiers and tested each other's models for robustness. Our study illuminates how children reason about ML concepts, offering these insights for designing machine teaching experiences for children: (i) ML metrics (e.g. confidence scores) should be visible for experimentation; (ii) ML activities should enable children to exchange models for promoting reflection and pattern recognition; and (iii) the interface should allow quick data inspection (e.g. images vs. gestures).
* 11 pages, 8 images