 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Egoshots, an ego-vision life-logging dataset and semantic fidelity metric to evaluate diversity in image captioning models
Mar 27, 2020
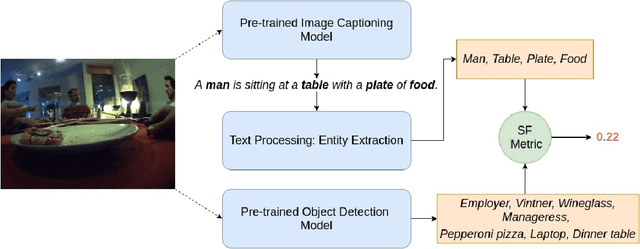

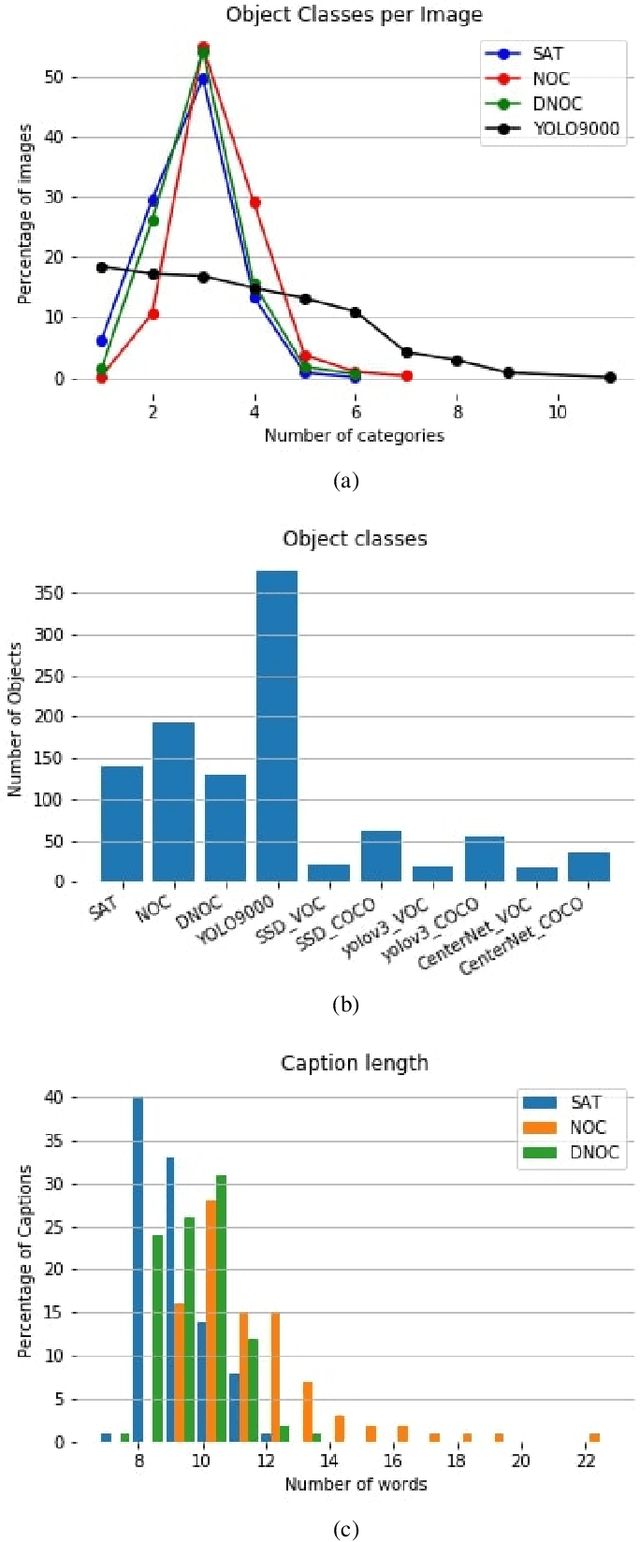
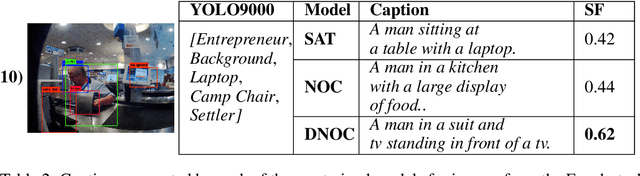
Image captioning models have been able to generate grammatically correct and human understandable sentences. However most of the captions convey limited information as the model used is trained on datasets that do not caption all possible objects existing in everyday life. Due to this lack of prior information most of the captions are biased to only a few objects present in the scene, hence limiting their usage in daily life. In this paper, we attempt to show the biased nature of the currently existing image captioning models and present a new image captioning dataset, Egoshots, consisting of 978 real life images with no captions. We further exploit the state of the art pre-trained image captioning and object recognition networks to annotate our images and show the limitations of existing works. Furthermore, in order to evaluate the quality of the generated captions, we propose a new image captioning metric, object based Semantic Fidelity (SF). Existing image captioning metrics can evaluate a caption only in the presence of their corresponding annotations; however, SF allows evaluating captions generated for images without annotations, making it highly useful for real life generated captions.
TransforMesh: A Transformer Network for Longitudinal modeling of Anatomical Meshes
Sep 23, 2021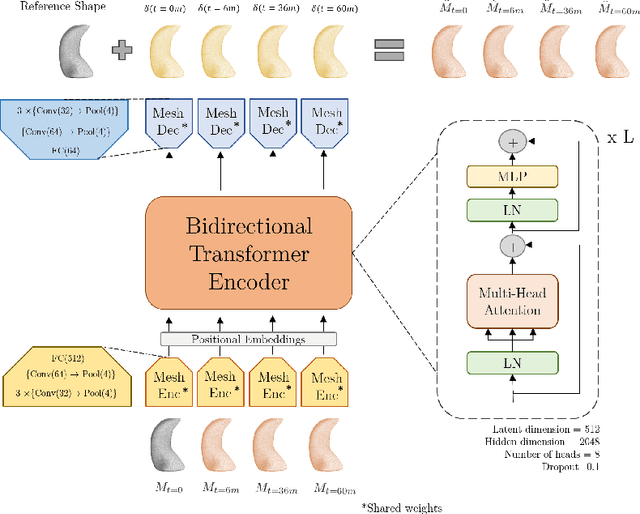
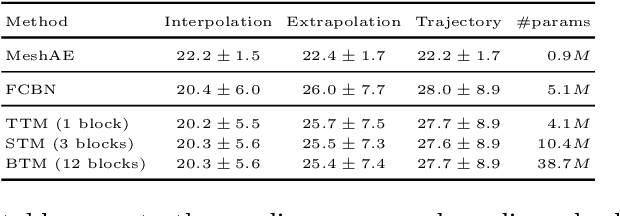
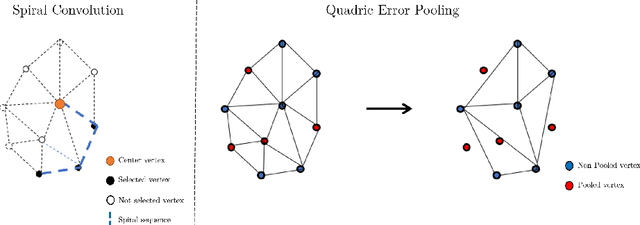
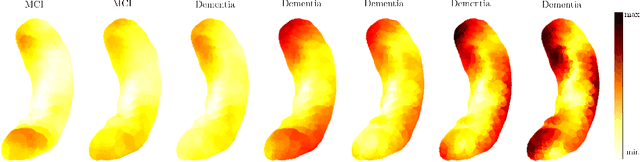
The longitudinal modeling of neuroanatomical changes related to Alzheimer's disease (AD) is crucial for studying the progression of the disease. To this end, we introduce TransforMesh, a spatio-temporal network based on transformers that models longitudinal shape changes on 3D anatomical meshes. While transformer and mesh networks have recently shown impressive performances in natural language processing and computer vision, their application to medical image analysis has been very limited. To the best of our knowledge, this is the first work that combines transformer and mesh networks. Our results show that TransforMesh can model shape trajectories better than other baseline architectures that do not capture temporal dependencies. Moreover, we also explore the capabilities of TransforMesh in detecting structural anomalies of the hippocampus in patients developing AD.
Semantic Diversity Learning for Zero-Shot Multi-label Classification
May 12, 2021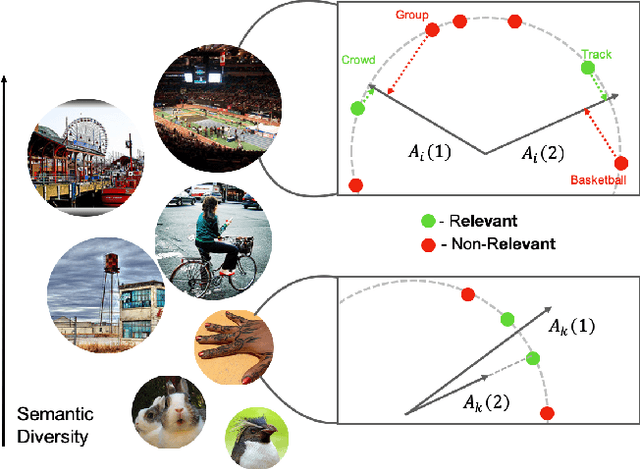
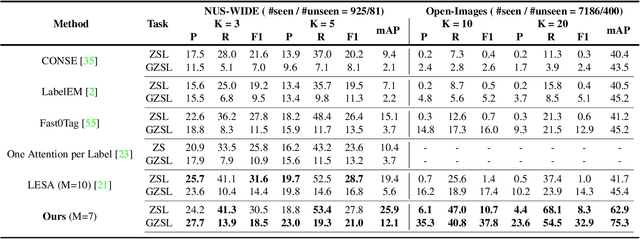
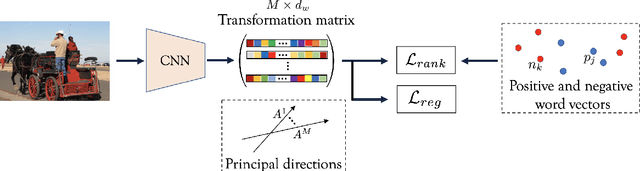
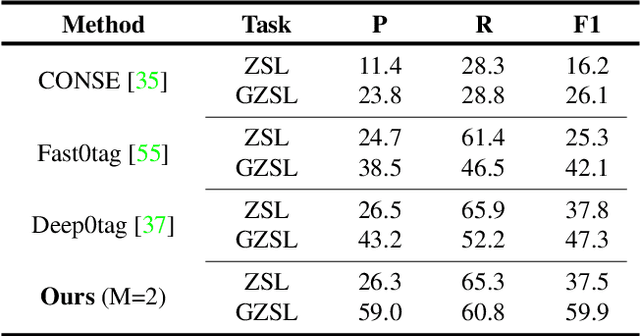
Training a neural network model for recognizing multiple labels associated with an image, including identifying unseen labels, is challenging, especially for images that portray numerous semantically diverse labels. As challenging as this task is, it is an essential task to tackle since it represents many real-world cases, such as image retrieval of natural images. We argue that using a single embedding vector to represent an image, as commonly practiced, is not sufficient to rank both relevant seen and unseen labels accurately. This study introduces an end-to-end model training for multi-label zero-shot learning that supports semantic diversity of the images and labels. We propose to use an embedding matrix having principal embedding vectors trained using a tailored loss function. In addition, during training, we suggest up-weighting in the loss function image samples presenting higher semantic diversity to encourage the diversity of the embedding matrix. Extensive experiments show that our proposed method improves the zero-shot model's quality in tag-based image retrieval achieving SoTA results on several common datasets (NUS-Wide, COCO, Open Images).
Competing Ratio Loss for Discriminative Multi-class Image Classification
Jul 31, 2019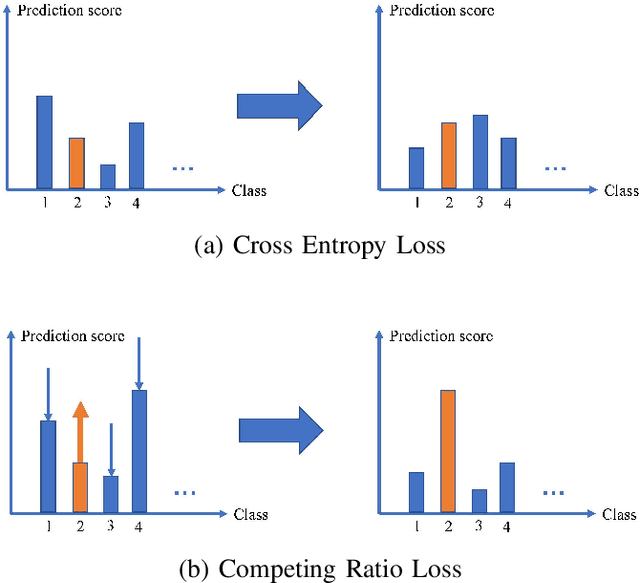
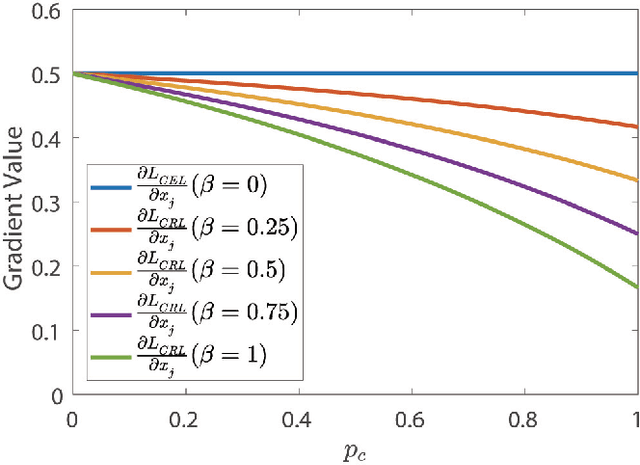
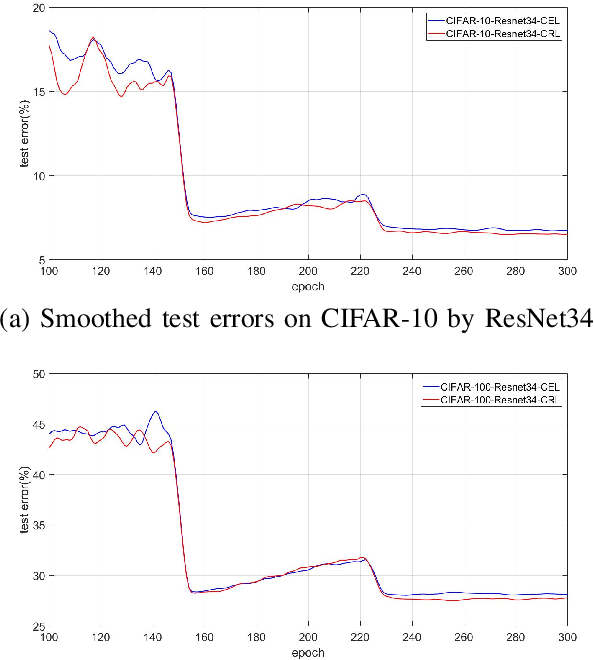

The development of deep convolutional neural network architecture is critical to the improvement of image classification task performance. A lot of studies of image classification based on deep convolutional neural network focus on the network structure to improve the image classification performance. Contrary to these studies, we focus on the loss function. Cross-entropy Loss (CEL) is widely used for training a multi-class classification deep convolutional neural network. While CEL has been successfully implemented in image classification tasks, it only focuses on the posterior probability of correct class when the labels of training images are one-hot. It cannot be discriminated against the classes not belong to correct class (wrong classes) directly. In order to solve the problem of CEL, we propose Competing Ratio Loss (CRL), which calculates the posterior probability ratio between the correct class and competing wrong classes to better discriminate the correct class from competing wrong classes, increasing the difference between the negative log likelihood of the correct class and the negative log likelihood of competing wrong classes, widening the difference between the probability of the correct class and the probabilities of wrong classes. To demonstrate the effectiveness of our loss function, we perform some sets of experiments on different types of image classification datasets, including CIFAR, SVHN, CUB200- 2011, Adience and ImageNet datasets. The experimental results show the effectiveness and robustness of our loss function on different deep convolutional neural network architectures and different image classification tasks, such as fine-grained image classification, hard face age estimation and large-scale image classification.
TEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding
Oct 17, 2021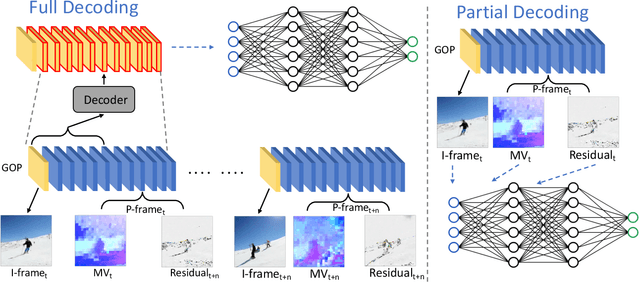


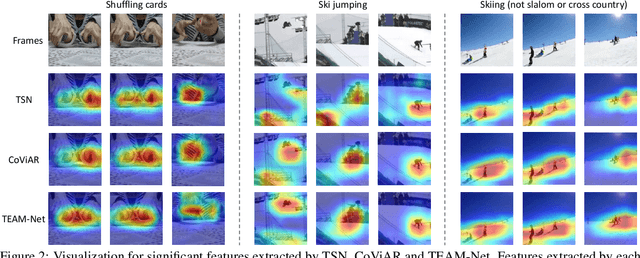
Most of existing video action recognition models ingest raw RGB frames. However, the raw video stream requires enormous storage and contains significant temporal redundancy. Video compression (e.g., H.264, MPEG-4) reduces superfluous information by representing the raw video stream using the concept of Group of Pictures (GOP). Each GOP is composed of the first I-frame (aka RGB image) followed by a number of P-frames, represented by motion vectors and residuals, which can be regarded and used as pre-extracted features. In this work, we 1) introduce sampling the input for the network from partially decoded videos based on the GOP-level, and 2) propose a plug-and-play mulTi-modal lEArning Module (TEAM) for training the network using information from I-frames and P-frames in an end-to-end manner. We demonstrate the superior performance of TEAM-Net compared to the baseline using RGB only. TEAM-Net also achieves the state-of-the-art performance in the area of video action recognition with partial decoding. Code is provided at https://github.com/villawang/TEAM-Net.
Human Recognition based on Retinal Bifurcations and Modified Correlation Function
Sep 18, 2021
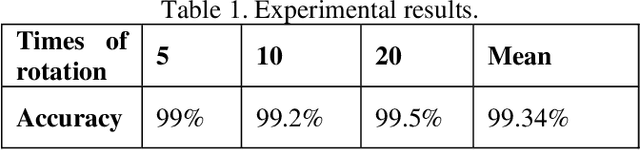
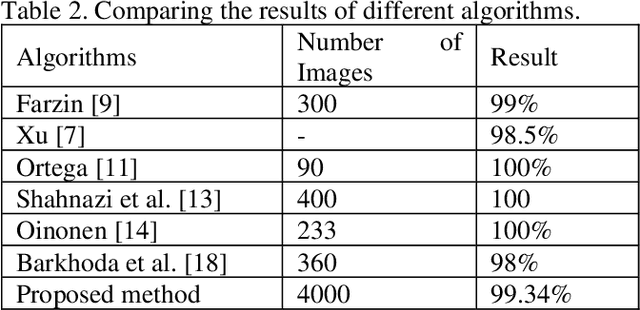
Nowadays high security is an important issue for most of the secure places and recent advances increase the needs of high-security systems. Therefore, needs to high security for controlling and permitting the allowable people to enter the high secure places, increases and extends the use of conventional recognition methods. Therefore, a novel identification method using retinal images is proposed in this paper. For this purpose, new mathematical functions are applied on corners and bifurcations. To evaluate the proposed method we use 40 retinal images from the DRIVE database, 20 normal retinal image from STARE database and 140 normal retinal images from local collected database and the accuracy rate is 99.34 percent.
VisionISP: Repurposing the Image Signal Processor for Computer Vision Applications
Nov 14, 2019
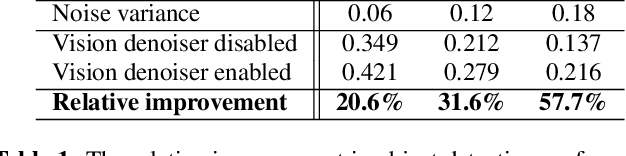


Traditional image signal processors (ISPs) are primarily designed and optimized to improve the image quality perceived by humans. However, optimal perceptual image quality does not always translate into optimal performance for computer vision applications. We propose a set of methods, which we collectively call VisionISP, to repurpose the ISP for machine consumption. VisionISP significantly reduces data transmission needs by reducing the bit-depth and resolution while preserving the relevant information. The blocks in VisionISP are simple, content-aware, and trainable. Experimental results show that VisionISP boosts the performance of a subsequent computer vision system trained to detect objects in an autonomous driving setting. The results demonstrate the potential and the practicality of VisionISP for computer vision applications.
Perceptually Motivated Method for Image Inpainting Comparison
Jul 14, 2019


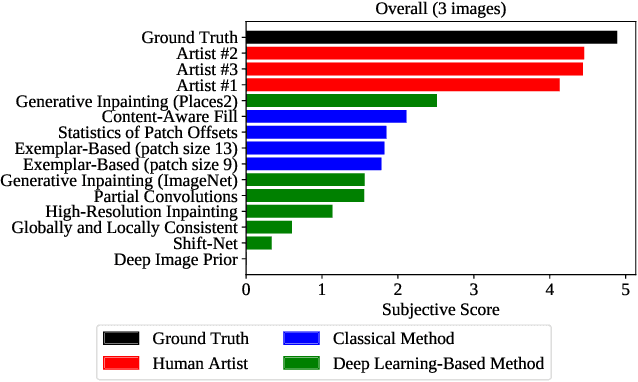
The field of automatic image inpainting has progressed rapidly in recent years, but no one has yet proposed a standard method of evaluating algorithms. This absence is due to the problem's challenging nature: image-inpainting algorithms strive for realism in the resulting images, but realism is a subjective concept intrinsic to human perception. Existing objective image-quality metrics provide a poor approximation of what humans consider more or less realistic. To improve the situation and to better organize both prior and future research in this field, we conducted a subjective comparison of nine state-of-the-art inpainting algorithms and propose objective quality metrics that exhibit high correlation with the results of our comparison.
CTSpine1K: A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
May 31, 2021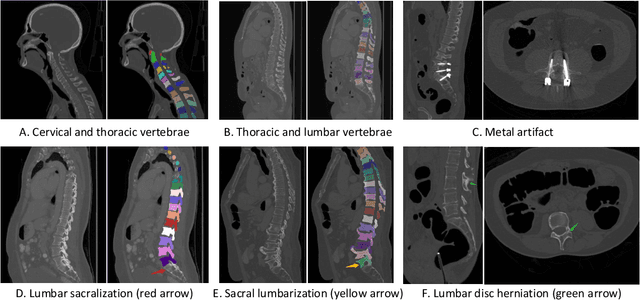

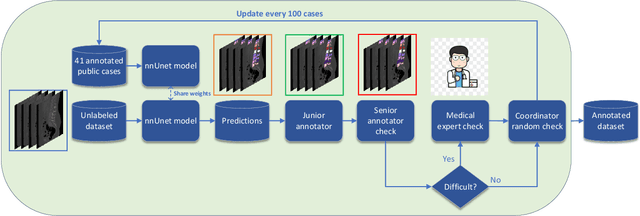
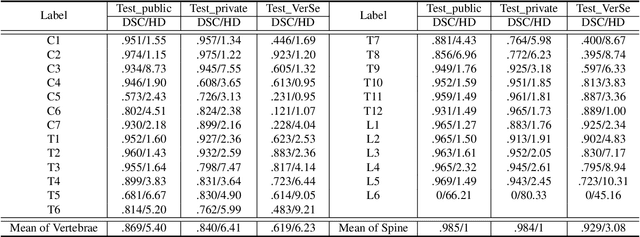
Spine-related diseases have high morbidity and cause a huge burden of social cost. Spine imaging is an essential tool for noninvasively visualizing and assessing spinal pathology. Segmenting vertebrae in computed tomography (CT) images is the basis of quantitative medical image analysis for clinical diagnosis and surgery planning of spine diseases. Current publicly available annotated datasets on spinal vertebrae are small in size. Due to the lack of a large-scale annotated spine image dataset, the mainstream deep learning-based segmentation methods, which are data-driven, are heavily restricted. In this paper, we introduce a large-scale spine CT dataset, called CTSpine1K, curated from multiple sources for vertebra segmentation, which contains 1,005 CT volumes with over 11,100 labeled vertebrae belonging to different spinal conditions. Based on this dataset, we conduct several spinal vertebrae segmentation experiments to set the first benchmark. We believe that this large-scale dataset will facilitate further research in many spine-related image analysis tasks, including but not limited to vertebrae segmentation, labeling, 3D spine reconstruction from biplanar radiographs, image super-resolution, and enhancement.
Exploring Multi-Scale Feature Propagation and Communication for Image Super Resolution
Aug 14, 2020

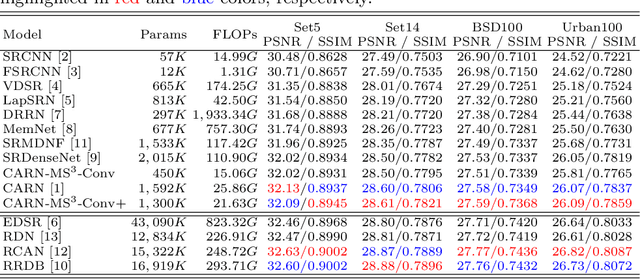
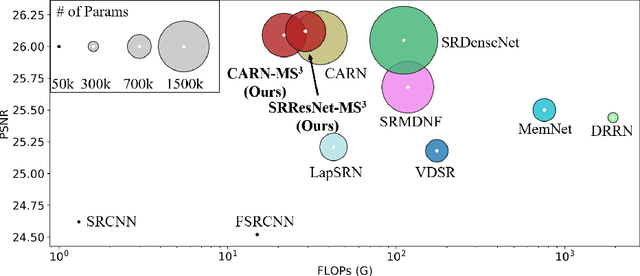
Multi-scale techniques have achieved great success in a wide range of computer vision tasks. However, while this technique is incorporated in existing works, there still lacks a comprehensive investigation on variants of multi-scale convolution in image super resolution. In this work, we present a unified formulation over widely-used multi-scale structures. With this framework, we systematically explore the two factors of multi-scale convolution -- feature propagation and cross-scale communication. Based on the investigation, we propose a generic and efficient multi-scale convolution unit -- Multi-Scale cross-Scale Share-weights convolution (MS$^3$-Conv). Extensive experiments demonstrate that the proposed MS$^3$-Conv can achieve better SR performance than the standard convolution with less parameters and computational cost. Beyond quantitative analysis, we comprehensively study the visual quality, which shows that MS$^3$-Conv behave better to recover high-frequency details.