 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention-based 3D Object Reconstruction from a Single Image
Aug 11, 2020
Recently, learning-based approaches for 3D reconstruction from 2D images have gained popularity due to its modern applications, e.g., 3D printers, autonomous robots, self-driving cars, virtual reality, and augmented reality. The computer vision community has applied a great effort in developing functions to reconstruct the full 3D geometry of objects and scenes. However, to extract image features, they rely on convolutional neural networks, which are ineffective in capturing long-range dependencies. In this paper, we propose to substantially improve Occupancy Networks, a state-of-the-art method for 3D object reconstruction. For such we apply the concept of self-attention within the network's encoder in order to leverage complementary input features rather than those based on local regions, helping the encoder to extract global information. With our approach, we were capable of improving the original work in 5.05% of mesh IoU, 0.83% of Normal Consistency, and more than 10X the Chamfer-L1 distance. We also perform a qualitative study that shows that our approach was able to generate much more consistent meshes, confirming its increased generalization power over the current state-of-the-art.
* 8 pages, 4 figures, 3 tables
Styleformer: Transformer based Generative Adversarial Networks with Style Vector
Jul 05, 2021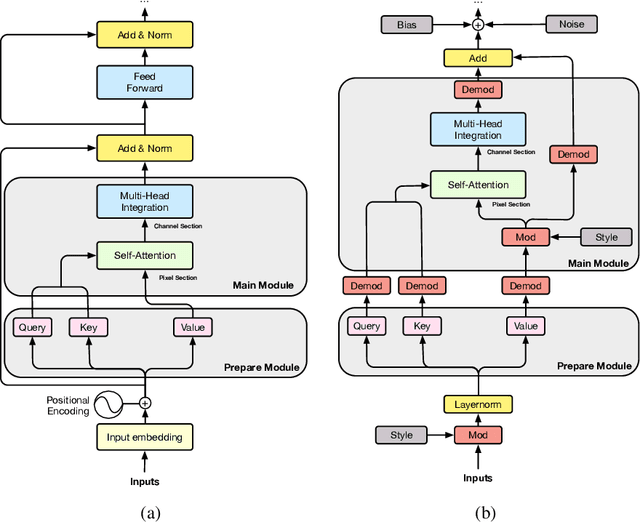
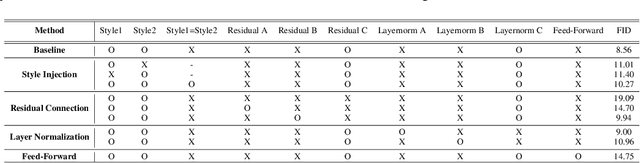
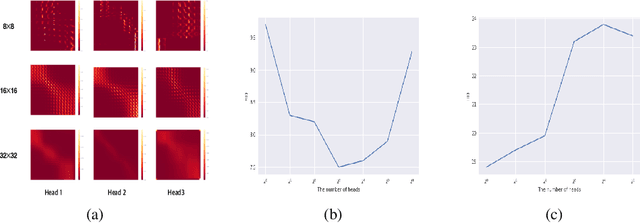

We propose Styleformer, which is a style-based generator for GAN architecture, but a convolution-free transformer-based generator. In our paper, we explain how a transformer can generate high-quality images, overcoming the disadvantage that convolution operations are difficult to capture global features in an image. Furthermore, we change the demodulation of StyleGAN2 and modify the existing transformer structure (e.g., residual connection, layer normalization) to create a strong style-based generator with a convolution-free structure. We also make Styleformer lighter by applying Linformer, enabling Styleformer to generate higher resolution images and result in improvements in terms of speed and memory. We experiment with the low-resolution image dataset such as CIFAR-10, as well as the high-resolution image dataset like LSUN-church. Styleformer records FID 2.82 and IS 9.94 on CIFAR-10, a benchmark dataset, which is comparable performance to the current state-of-the-art and outperforms all GAN-based generative models, including StyleGAN2-ADA with fewer parameters on the unconditional setting. We also both achieve new state-of-the-art with FID 15.17, IS 11.01, and FID 3.66, respectively on STL-10 and CelebA. We release our code at https://github.com/Jeeseung-Park/Styleformer.
GetNet: Get Target Area for Image Pairing
Oct 08, 2019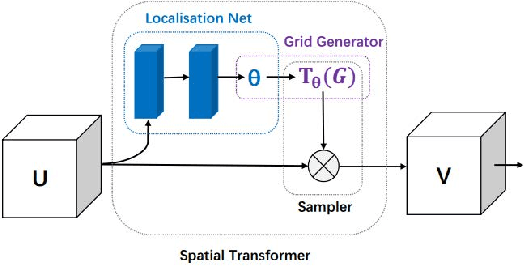
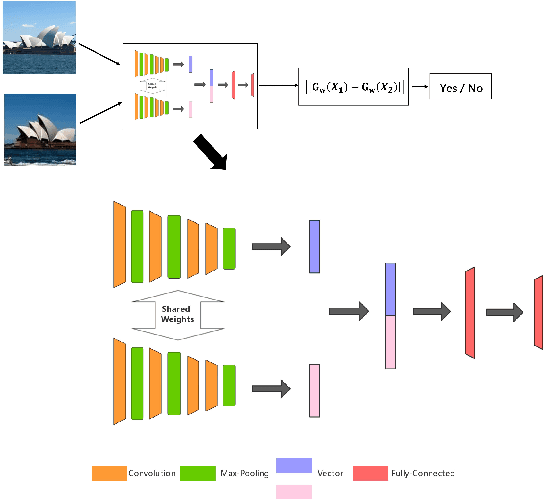
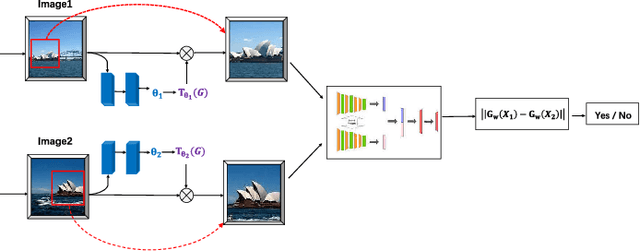

Image pairing is an important research task in the field of computer vision. And finding image pairs containing objects of the same category is the basis of many tasks such as tracking and person re-identification, etc., and it is also the focus of our research. Existing traditional methods and deep learning-based methods have some degree of defects in speed or accuracy. In this paper, we made improvements on the Siamese network and proposed GetNet. The proposed method GetNet combines STN and Siamese network to get the target area first and then perform subsequent processing. Experiments show that our method achieves competitive results in speed and accuracy.
Arbitrary Virtual Try-On Network: Characteristics Preservation and Trade-off between Body and Clothing
Nov 24, 2021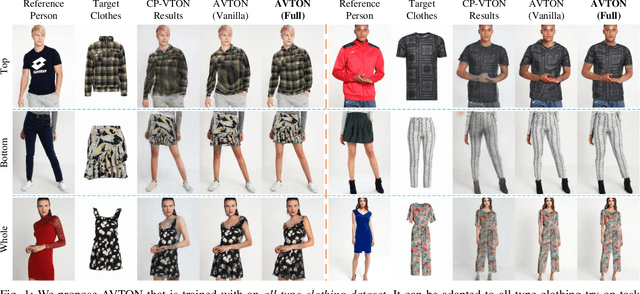
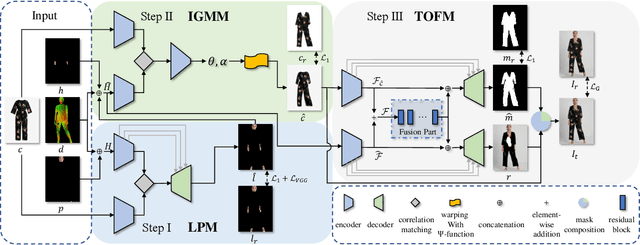


Deep learning based virtual try-on system has achieved some encouraging progress recently, but there still remain several big challenges that need to be solved, such as trying on arbitrary clothes of all types, trying on the clothes from one category to another and generating image-realistic results with few artifacts. To handle this issue, we in this paper first collect a new dataset with all types of clothes, \ie tops, bottoms, and whole clothes, each one has multiple categories with rich information of clothing characteristics such as patterns, logos, and other details. Based on this dataset, we then propose the Arbitrary Virtual Try-On Network (AVTON) that is utilized for all-type clothes, which can synthesize realistic try-on images by preserving and trading off characteristics of the target clothes and the reference person. Our approach includes three modules: 1) Limbs Prediction Module, which is utilized for predicting the human body parts by preserving the characteristics of the reference person. This is especially good for handling cross-category try-on task (\eg long sleeves \(\leftrightarrow\) short sleeves or long pants \(\leftrightarrow\) skirts, \etc), where the exposed arms or legs with the skin colors and details can be reasonably predicted; 2) Improved Geometric Matching Module, which is designed to warp clothes according to the geometry of the target person. We improve the TPS based warping method with a compactly supported radial function (Wendland's \(\Psi\)-function); 3) Trade-Off Fusion Module, which is to trade off the characteristics of the warped clothes and the reference person. This module is to make the generated try-on images look more natural and realistic based on a fine-tune symmetry of the network structure. Extensive simulations are conducted and our approach can achieve better performance compared with the state-of-the-art virtual try-on methods.
Characterizing Learning Dynamics of Deep Neural Networks via Complex Networks
Oct 18, 2021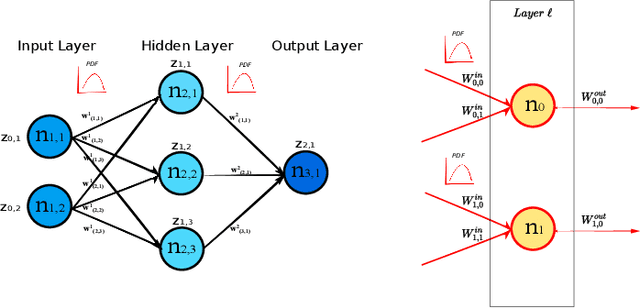
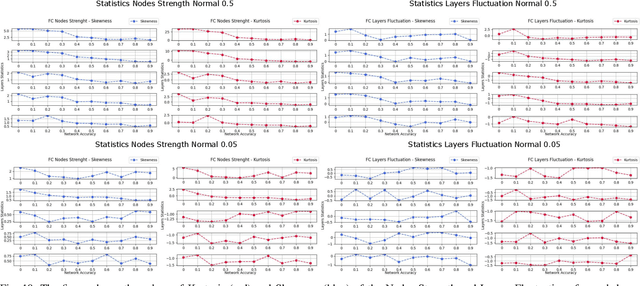
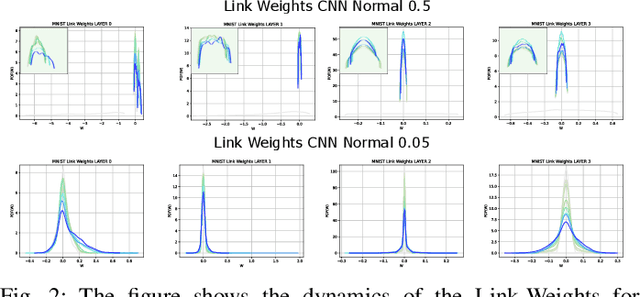
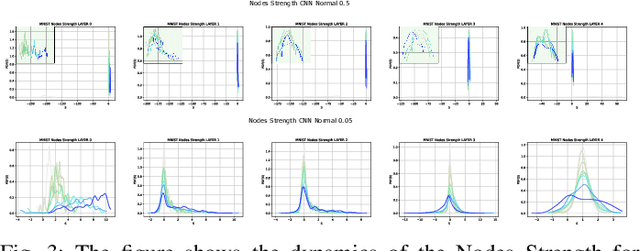
In this paper, we interpret Deep Neural Networks with Complex Network Theory. Complex Network Theory (CNT) represents Deep Neural Networks (DNNs) as directed weighted graphs to study them as dynamical systems. We efficiently adapt CNT measures to examine the evolution of the learning process of DNNs with different initializations and architectures: we introduce metrics for nodes/neurons and layers, namely Nodes Strength and Layers Fluctuation. Our framework distills trends in the learning dynamics and separates low from high accurate networks. We characterize populations of neural networks (ensemble analysis) and single instances (individual analysis). We tackle standard problems of image recognition, for which we show that specific learning dynamics are indistinguishable when analysed through the solely Link-Weights analysis. Further, Nodes Strength and Layers Fluctuations make unprecedented behaviours emerge: accurate networks, when compared to under-trained models, show substantially divergent distributions with the greater extremity of deviations. On top of this study, we provide an efficient implementation of the CNT metrics for both Convolutional and Fully Connected Networks, to fasten the research in this direction.
* IEEE/ICTAI2021 (full paper)
Advantage of Machine Learning over Maximum Likelihood in Limited-Angle Low-Photon X-Ray Tomography
Nov 15, 2021
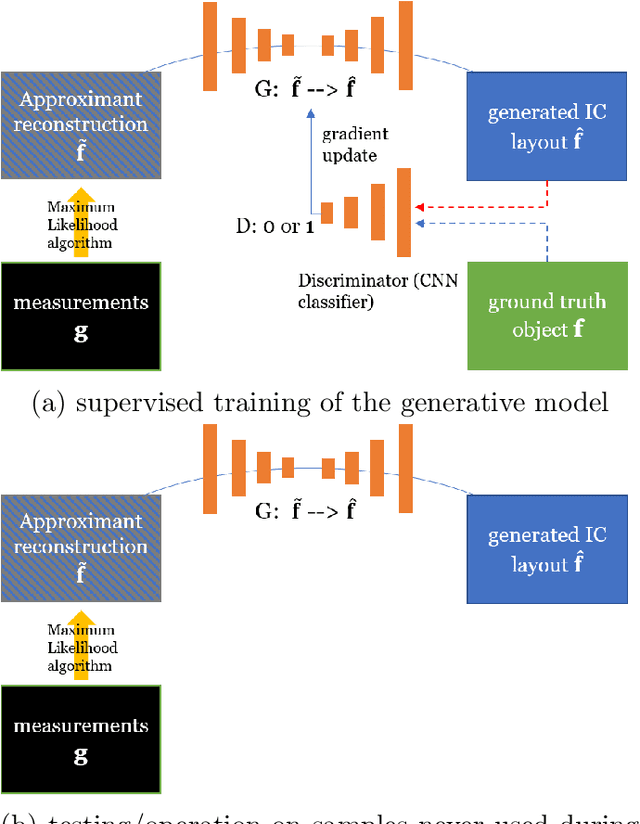

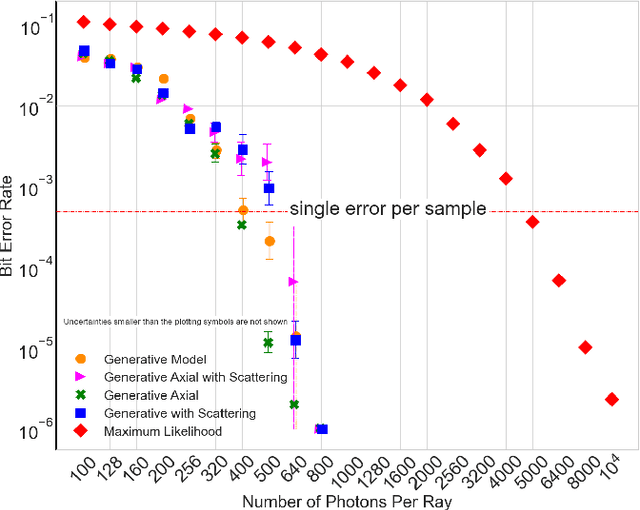
Limited-angle X-ray tomography reconstruction is an ill-conditioned inverse problem in general. Especially when the projection angles are limited and the measurements are taken in a photon-limited condition, reconstructions from classical algorithms such as filtered backprojection may lose fidelity and acquire artifacts due to the missing-cone problem. To obtain satisfactory reconstruction results, prior assumptions, such as total variation minimization and nonlocal image similarity, are usually incorporated within the reconstruction algorithm. In this work, we introduce deep neural networks to determine and apply a prior distribution in the reconstruction process. Our neural networks learn the prior directly from synthetic training samples. The neural nets thus obtain a prior distribution that is specific to the class of objects we are interested in reconstructing. In particular, we used deep generative models with 3D convolutional layers and 3D attention layers which are trained on 3D synthetic integrated circuit (IC) data from a model dubbed CircuitFaker. We demonstrate that, when the projection angles and photon budgets are limited, the priors from our deep generative models can dramatically improve the IC reconstruction quality on synthetic data compared with maximum likelihood estimation. Training the deep generative models with synthetic IC data from CircuitFaker illustrates the capabilities of the learned prior from machine learning. We expect that if the process were reproduced with experimental data, the advantage of the machine learning would persist. The advantages of machine learning in limited angle X-ray tomography may further enable applications in low-photon nanoscale imaging.
Shadow Transfer: Single Image Relighting For Urban Road Scenes
Sep 26, 2019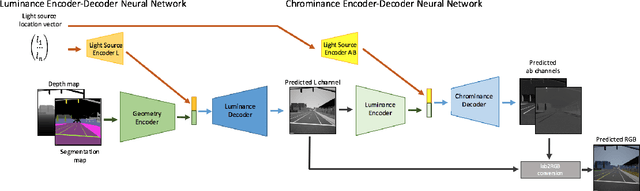



Illumination effects in images, specifically cast shadows and shading, have been shown to decrease the performance of deep neural networks on a large number of vision-based detection, recognition and segmentation tasks in urban driving scenes. A key factor that contributes to this performance gap is the lack of `time-of-day' diversity within real, labeled datasets. There have been impressive advances in the realm of image to image translation in transferring previously unseen visual effects into a dataset, specifically in day to night translation. However, it is not easy to constrain what visual effects, let alone illumination effects, are transferred from one dataset to another during the training process. To address this problem, we propose deep learning framework, called Shadow Transfer, that can relight complex outdoor scenes by transferring realistic shadow, shading, and other lighting effects onto a single image. The novelty of the proposed framework is that it is both self-supervised, and is designed to operate on sensor and label information that is easily available in autonomous vehicle datasets. We show the effectiveness of this method on both synthetic and real datasets, and we provide experiments that demonstrate that the proposed method produces images of higher visual quality than state of the art image to image translation methods.
MMIU: Dataset for Visual Intent Understanding in Multimodal Assistants
Oct 31, 2021
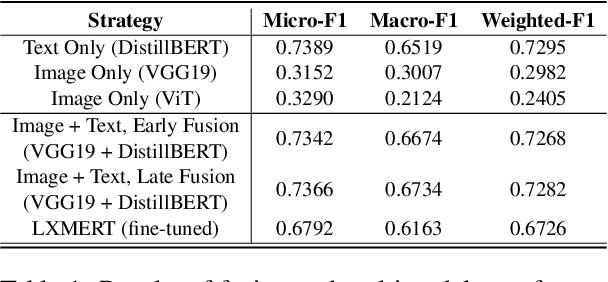


In multimodal assistant, where vision is also one of the input modalities, the identification of user intent becomes a challenging task as visual input can influence the outcome. Current digital assistants take spoken input and try to determine the user intent from conversational or device context. So, a dataset, which includes visual input (i.e. images or videos for the corresponding questions targeted for multimodal assistant use cases, is not readily available. The research in visual question answering (VQA) and visual question generation (VQG) is a great step forward. However, they do not capture questions that a visually-abled person would ask multimodal assistants. Moreover, many times questions do not seek information from external knowledge. In this paper, we provide a new dataset, MMIU (MultiModal Intent Understanding), that contains questions and corresponding intents provided by human annotators while looking at images. We, then, use this dataset for intent classification task in multimodal digital assistant. We also experiment with various approaches for combining vision and language features including the use of multimodal transformer for classification of image-question pairs into 14 intents. We provide the benchmark results and discuss the role of visual and text features for the intent classification task on our dataset.
Deep reinforcement learning with automated label extraction from clinical reports accurately classifies 3D MRI brain volumes
Jun 17, 2021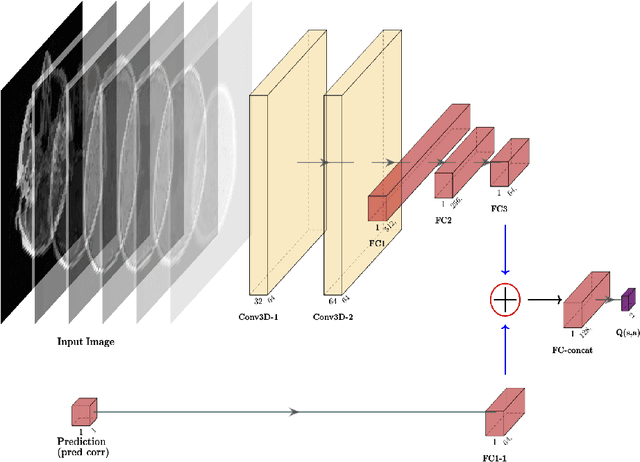
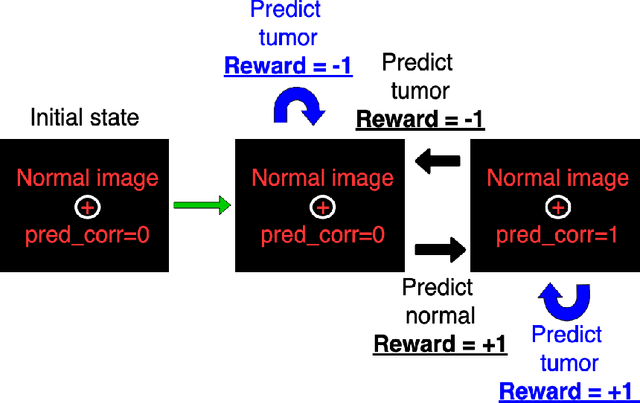
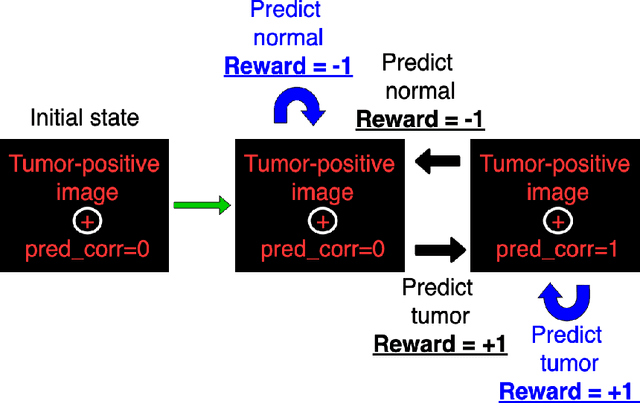
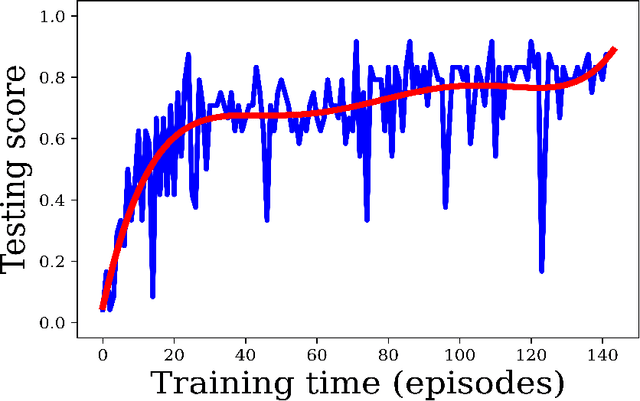
Purpose: Image classification is perhaps the most fundamental task in imaging AI. However, labeling images is time-consuming and tedious. We have recently demonstrated that reinforcement learning (RL) can classify 2D slices of MRI brain images with high accuracy. Here we make two important steps toward speeding image classification: Firstly, we automatically extract class labels from the clinical reports. Secondly, we extend our prior 2D classification work to fully 3D image volumes from our institution. Hence, we proceed as follows: in Part 1, we extract labels from reports automatically using the SBERT natural language processing approach. Then, in Part 2, we use these labels with RL to train a classification Deep-Q Network (DQN) for 3D image volumes. Methods: For Part 1, we trained SBERT with 90 radiology report impressions. We then used the trained SBERT to predict class labels for use in Part 2. In Part 2, we applied multi-step image classification to allow for combined Deep-Q learning using 3D convolutions and TD(0) Q learning. We trained on a set of 90 images. We tested on a separate set of 61 images, again using the classes predicted from patient reports by the trained SBERT in Part 1. For comparison, we also trained and tested a supervised deep learning classification network on the same set of training and testing images using the same labels. Results: Part 1: Upon training with the corpus of radiology reports, the SBERT model had 100% accuracy for both normal and metastasis-containing scans. Part 2: Then, using these labels, whereas the supervised approach quickly overfit the training data and as expected performed poorly on the testing set (66% accuracy, just over random guessing), the reinforcement learning approach achieved an accuracy of 92%. The results were found to be statistically significant, with a p-value of 3.1 x 10^-5.
Physics Driven Domain Specific Transporter Framework with Attention Mechanism for Ultrasound Imaging
Sep 13, 2021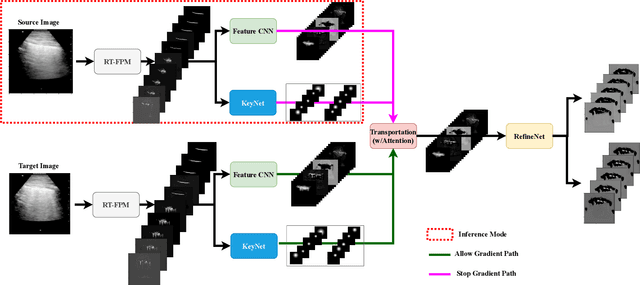
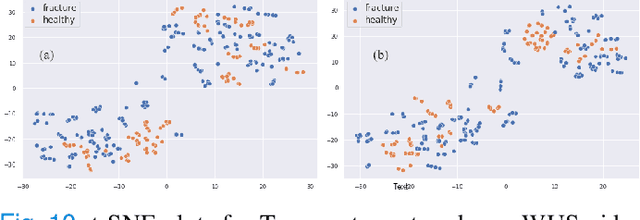
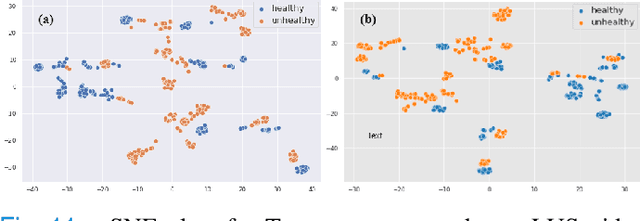
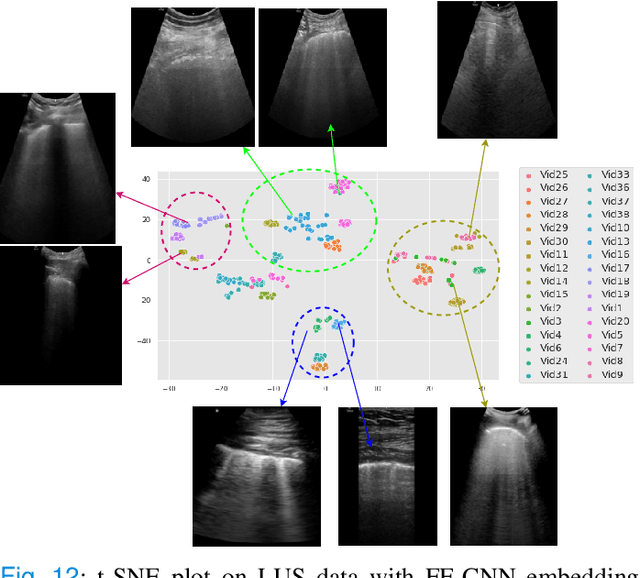
Most applications of deep learning techniques in medical imaging are supervised and require a large number of labeled data which is expensive and requires many hours of careful annotation by experts. In this paper, we propose an unsupervised, physics driven domain specific transporter framework with an attention mechanism to identify relevant key points with applications in ultrasound imaging. The proposed framework identifies key points that provide a concise geometric representation highlighting regions with high structural variation in ultrasound videos. We incorporate physics driven domain specific information as a feature probability map and use the radon transform to highlight features in specific orientations. The proposed framework has been trained on130 Lung ultrasound (LUS) videos and 113 Wrist ultrasound (WUS) videos and validated on 100 Lung ultrasound (LUS) videos and 58 Wrist ultrasound (WUS) videos acquired from multiple centers across the globe. Images from both datasets were independently assessed by experts to identify clinically relevant features such as A-lines, B-lines and pleura from LUS and radial metaphysis, radial epiphysis and carpal bones from WUS videos. The key points detected from both datasets showed high sensitivity (LUS = 99\% , WUS = 74\%) in detecting the image landmarks identified by experts. Also, on employing for classification of the given lung image into normal and abnormal classes, the proposed approach, even with no prior training, achieved an average accuracy of 97\% and an average F1-score of 95\% respectively on the task of co-classification with 3 fold cross-validation. With the purely unsupervised nature of the proposed approach, we expect the key point detection approach to increase the applicability of ultrasound in various examination performed in emergency and point of care.