 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MISO: Mutual Information Loss with Stochastic Style Representations for Multimodal Image-to-Image Translation
Feb 11, 2019

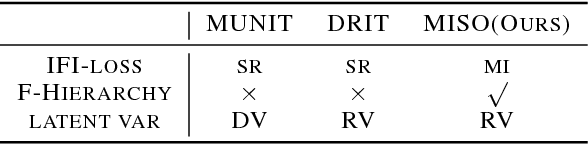
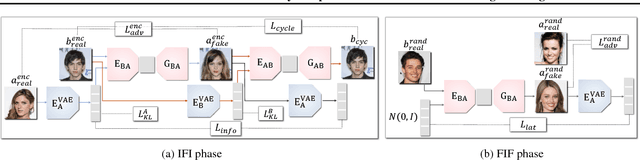
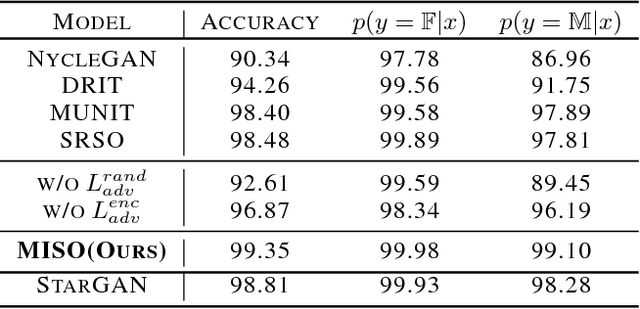
Unpaired multimodal image-to-image translation is a task of translating a given image in a source domain into diverse images in the target domain, overcoming the limitation of one-to-one mapping. Existing multimodal translation models are mainly based on the disentangled representations with an image reconstruction loss. We propose two approaches to improve multimodal translation quality. First, we use a content representation from the source domain conditioned on a style representation from the target domain. Second, rather than using a typical image reconstruction loss, we design MILO (Mutual Information LOss), a new stochastically-defined loss function based on information theory. This loss function directly reflects the interpretation of latent variables as a random variable. We show that our proposed model Mutual Information with StOchastic Style Representation(MISO) achieves state-of-the-art performance through extensive experiments on various real-world datasets.
Rheumatoid Arthritis: Automated Scoring of Radiographic Joint Damage
Oct 17, 2021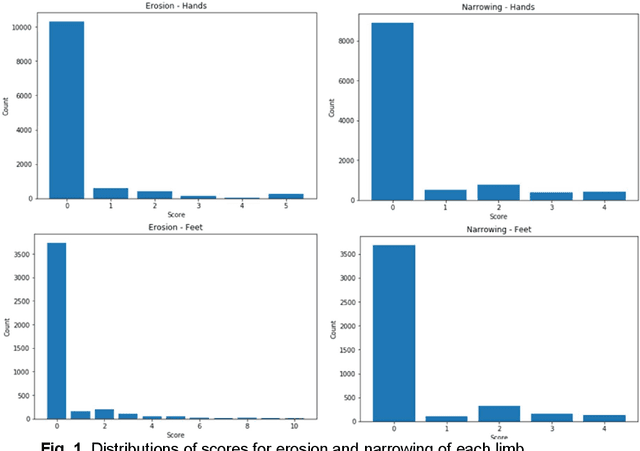

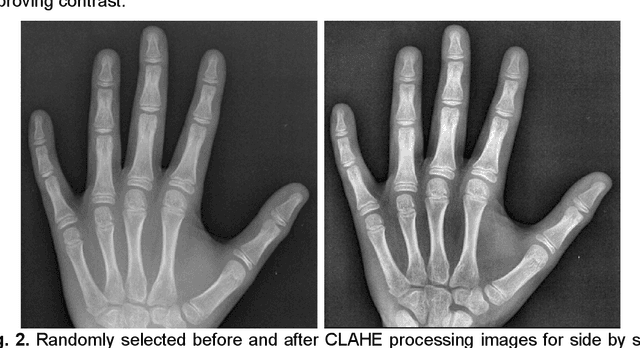
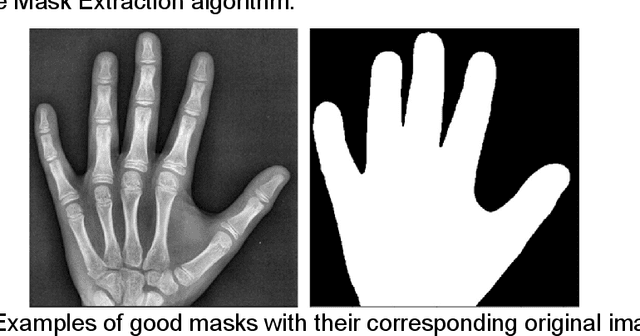
Rheumatoid arthritis is an autoimmune disease that causes joint damage due to inflammation in the soft tissue lining the joints known as the synovium. It is vital to identify joint damage as soon as possible to provide necessary treatment early and prevent further damage to the bone structures. Radiographs are often used to assess the extent of the joint damage. Currently, the scoring of joint damage from the radiograph takes expertise, effort, and time. Joint damage associated with rheumatoid arthritis is also not quantitated in clinical practice and subjective descriptors are used. In this work, we describe a pipeline of deep learning models to automatically identify and score rheumatoid arthritic joint damage from a radiographic image. Our automatic tool was shown to produce scores with extremely high balanced accuracy within a couple of minutes and utilizing this would remove the subjectivity of the scores between human reviewers.
An animated picture says at least a thousand words: Selecting Gif-based Replies in Multimodal Dialog
Sep 29, 2021
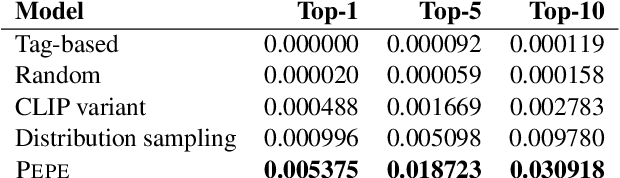
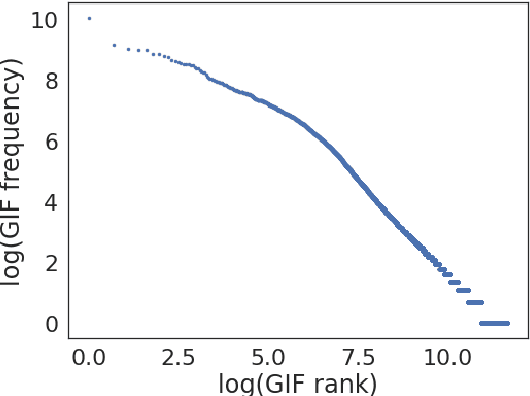

Online conversations include more than just text. Increasingly, image-based responses such as memes and animated gifs serve as culturally recognized and often humorous responses in conversation. However, while NLP has broadened to multimodal models, conversational dialog systems have largely focused only on generating text replies. Here, we introduce a new dataset of 1.56M text-gif conversation turns and introduce a new multimodal conversational model Pepe the King Prawn for selecting gif-based replies. We demonstrate that our model produces relevant and high-quality gif responses and, in a large randomized control trial of multiple models replying to real users, we show that our model replies with gifs that are significantly better received by the community.
LULC Segmentation of RGB Satellite Image Using FCN-8
Aug 24, 2020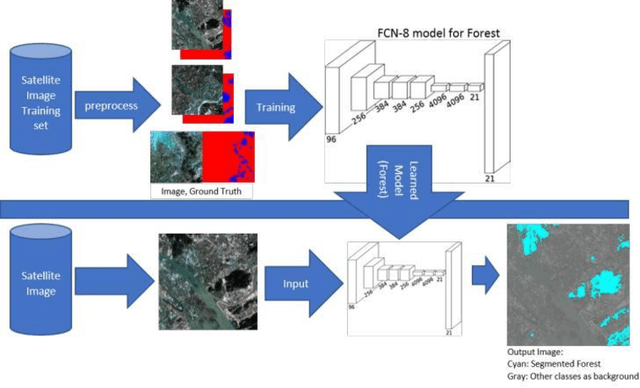


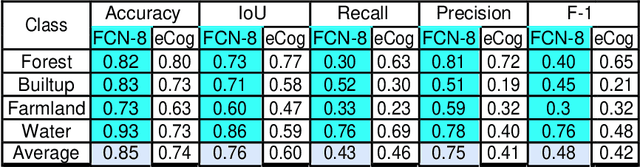
This work presents use of Fully Convolutional Network (FCN-8) for semantic segmentation of high-resolution RGB earth surface satel-lite images into land use land cover (LULC) categories. Specically, we propose a non-overlapping grid-based approach to train a Fully Convo-lutional Network (FCN-8) with vgg-16 weights to segment satellite im-ages into four (forest, built-up, farmland and water) classes. The FCN-8 semantically projects the discriminating features in lower resolution learned by the encoder onto the pixel space in higher resolution to get a dense classi cation. We experimented the proposed system with Gaofen-2 image dataset, that contains 150 images of over 60 di erent cities in china. For comparison, we used available ground-truth along with images segmented using a widely used commeriial GIS software called eCogni-tion. With the proposed non-overlapping grid-based approach, FCN-8 obtains signi cantly improved performance, than the eCognition soft-ware. Our model achieves average accuracy of 91.0% and average Inter-section over Union (IoU) of 0.84. In contrast, eCognitions average accu-racy is 74.0% and IoU is 0.60. This paper also reports a detail analysis of errors occurred at the LULC boundary.
Learning Multimodal VAEs through Mutual Supervision
Jul 01, 2021

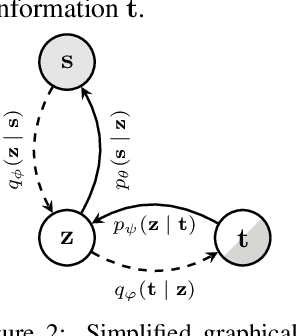

Multimodal VAEs seek to model the joint distribution over heterogeneous data (e.g.\ vision, language), whilst also capturing a shared representation across such modalities. Prior work has typically combined information from the modalities by reconciling idiosyncratic representations directly in the recognition model through explicit products, mixtures, or other such factorisations. Here we introduce a novel alternative, the MEME, that avoids such explicit combinations by repurposing semi-supervised VAEs to combine information between modalities implicitly through mutual supervision. This formulation naturally allows learning from partially-observed data where some modalities can be entirely missing -- something that most existing approaches either cannot handle, or do so to a limited extent. We demonstrate that MEME outperforms baselines on standard metrics across both partial and complete observation schemes on the MNIST-SVHN (image-image) and CUB (image-text) datasets. We also contrast the quality of the representations learnt by mutual supervision against standard approaches and observe interesting trends in its ability to capture relatedness between data.
AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection
Aug 25, 2021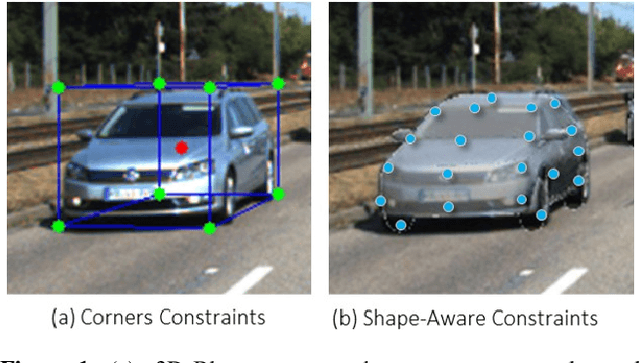
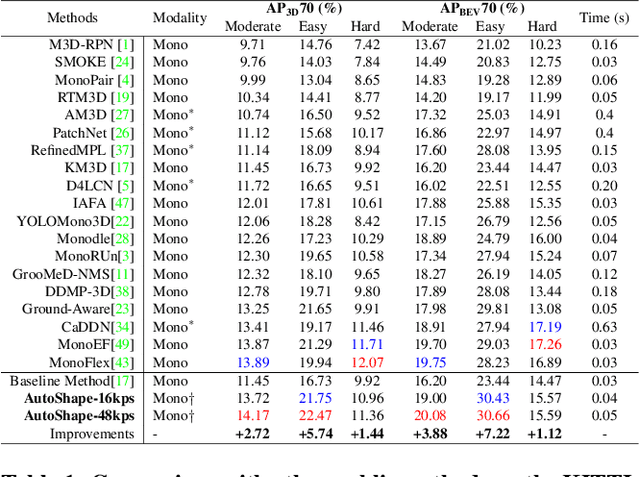
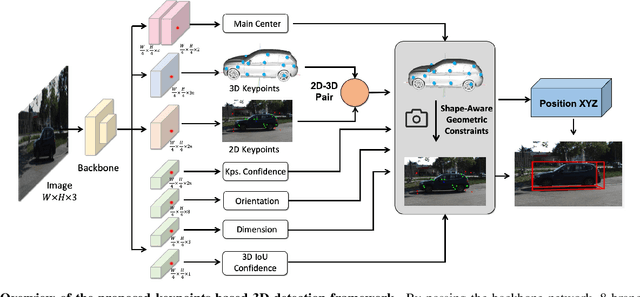
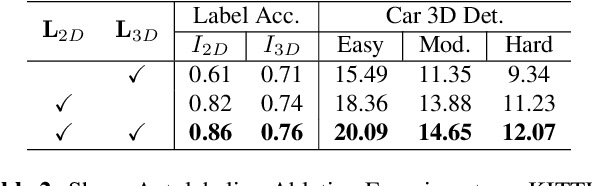
Existing deep learning-based approaches for monocular 3D object detection in autonomous driving often model the object as a rotated 3D cuboid while the object's geometric shape has been ignored. In this work, we propose an approach for incorporating the shape-aware 2D/3D constraints into the 3D detection framework. Specifically, we employ the deep neural network to learn distinguished 2D keypoints in the 2D image domain and regress their corresponding 3D coordinates in the local 3D object coordinate first. Then the 2D/3D geometric constraints are built by these correspondences for each object to boost the detection performance. For generating the ground truth of 2D/3D keypoints, an automatic model-fitting approach has been proposed by fitting the deformed 3D object model and the object mask in the 2D image. The proposed framework has been verified on the public KITTI dataset and the experimental results demonstrate that by using additional geometrical constraints the detection performance has been significantly improved as compared to the baseline method. More importantly, the proposed framework achieves state-of-the-art performance with real time. Data and code will be available at https://github.com/zongdai/AutoShape
Compact Heterogeneous Integration for Next Generation High Frequency Scalable Array with Miniaturized and Efficient Power Delivery Network
Nov 15, 2021


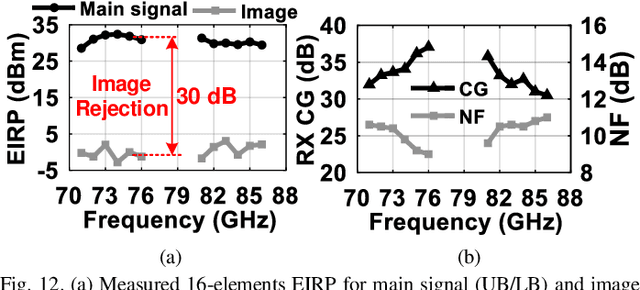
Next generation communication and sensing require enabling technologies for miniaturized and efficient heterogeneous systems while integrating technologies ranging from silicon to compound semiconductors and from photonic chips to micro-sensors. To this end, high frequency and mm-wave (MMW) lossy parasitics and delay between modules need to be significantly reduced to minimize area, loss and thermal heating of inter-chip wiring and power delivery networks. In this work, we propose novel approaches to achieve an efficient wideband MMW array integrations. The proposed techniques are built upon the following: 1) fixed antenna package buildup for every element with differential excitation on two half sides of array to reduce the fabrication cost and the IC-to-antenna routing loss; 2) miniaturized aperture coupled local oscillator (LO) and intermediate frequency (IF) power delivery feed distribution to minimize the packaging stacked layers and their loss. The proposed 16-element antenna array is integrated which 4 dies in 2x2 configurations implemented in a 90-nm SiGe BiCMOS process using compact Weaver image-selection architecture (WISA). The proposed miniaturized and efficient architecture from circuit and chip level to package level results in 1.5 GHz modulation bandwidth for 64 QAM (9 Gb/s) and 2 GHz for 16 QAM with only +-2 dB EVM variation over the 20% FBW (71-86 GHz). The system produces 30-dBm EIRP with enhanced efficiency of 25% EIRP/PDC over the bandwidth
Rethinking Recurrent Neural Networks and other Improvements for Image Classification
Jul 30, 2020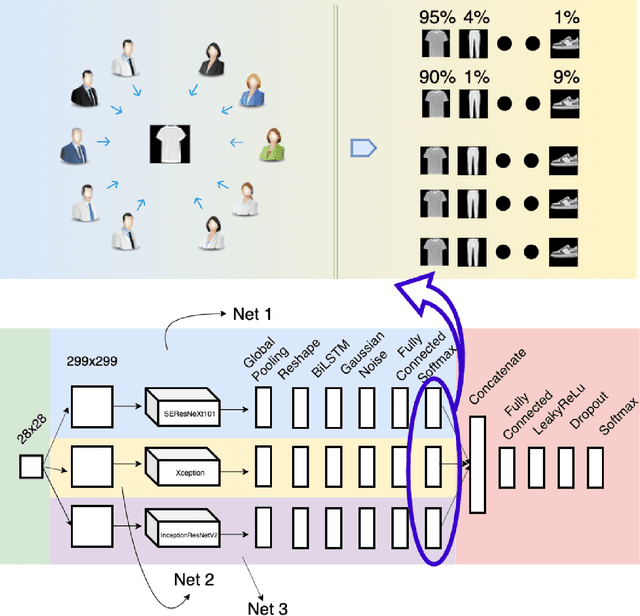
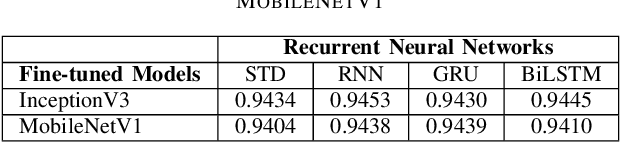
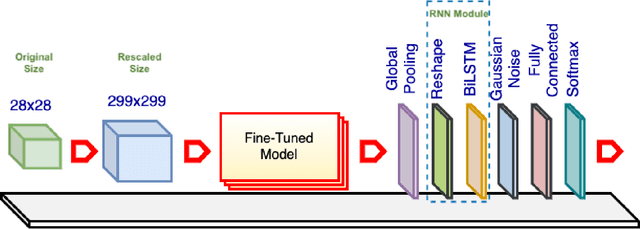
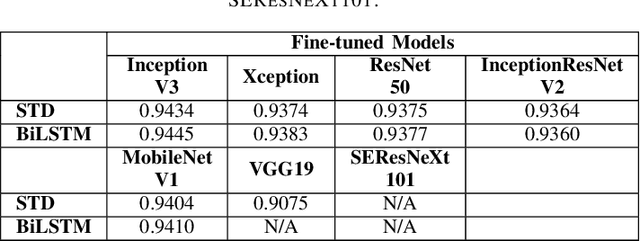
For a long history of Machine Learning which dates back to several decades, Recurrent Neural Networks (RNNs) have been mainly used for sequential data and time series or generally 1D information. Even in some rare researches on 2D images, the networks merely learn and generate data sequentially rather than for recognition of images. In this research, we propose to integrate RNN as an additional layer in designing image recognition's models. Moreover, we develop End-to-End Ensemble Multi-models that are able to learn experts' predictions from several models. Besides, we extend training strategy and softmax pruning which overall leads our designs to perform comparably to top models on several datasets. The source code of the methods provided in this article is available in https://github.com/leonlha/e2e-3m and http://nguyenhuuphong.me.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 17, 2021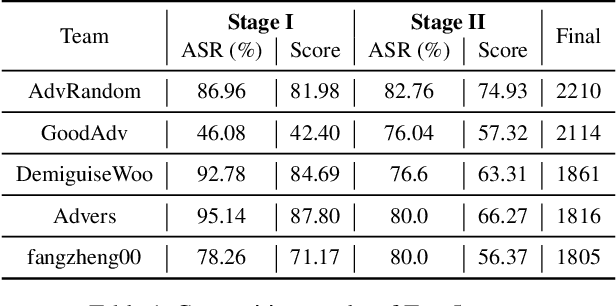
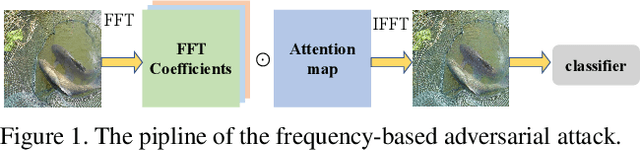
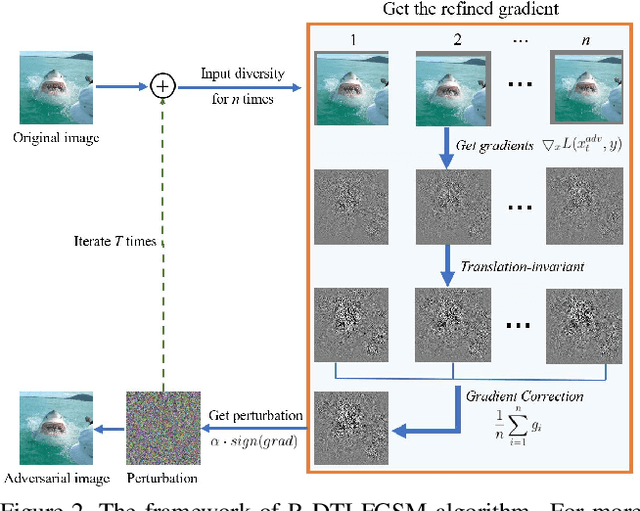
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Disrupting Deepfakes: Adversarial Attacks Against Conditional Image Translation Networks and Facial Manipulation Systems
Mar 06, 2020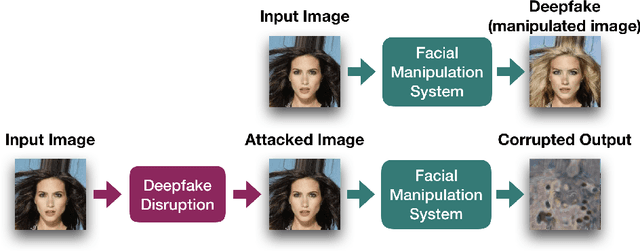
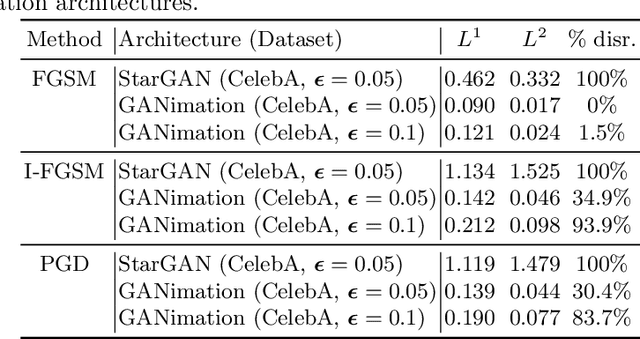

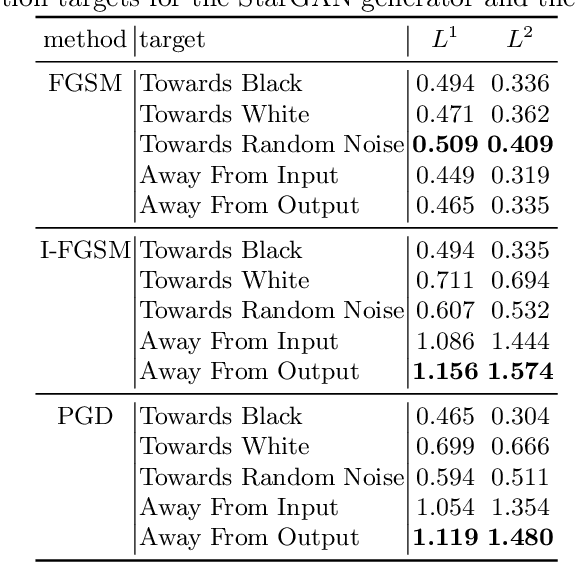
Face modification systems using deep learning have become increasingly powerful and accessible. Given images of a person's face, such systems can generate new images of that same person under different expressions and poses. Some systems can also modify targeted attributes such as hair color or age. This type of manipulated images and video have been coined Deepfakes. In order to prevent a malicious user from generating modified images of a person without their consent we tackle the new problem of generating adversarial attacks against such image translation systems, which disrupt the resulting output image. We call this problem disrupting deepfakes. Most image translation architectures are generative models conditioned on an attribute (e.g. put a smile on this person's face). We are first to propose and successfully apply (1) class transferable adversarial attacks that generalize to different classes, which means that the attacker does not need to have knowledge about the conditioning class, and (2) adversarial training for generative adversarial networks (GANs) as a first step towards robust image translation networks. Finally, in gray-box scenarios, blurring can mount a successful defense against disruption. We present a spread-spectrum adversarial attack, which evades blur defenses.