 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Adaptive Monte Carlo Denoising and Super-Resolution
Aug 16, 2021

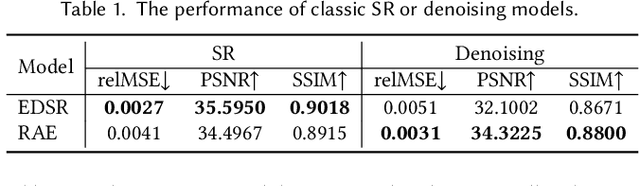
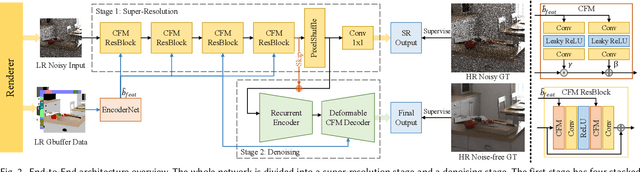
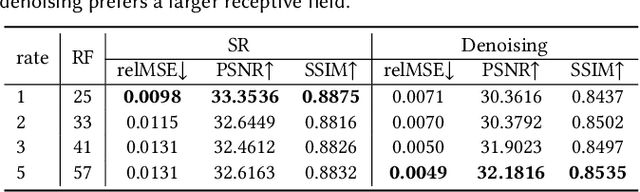
The classic Monte Carlo path tracing can achieve high quality rendering at the cost of heavy computation. Recent works make use of deep neural networks to accelerate this process, by improving either low-resolution or fewer-sample rendering with super-resolution or denoising neural networks in post-processing. However, denoising and super-resolution have only been considered separately in previous work. We show in this work that Monte Carlo path tracing can be further accelerated by joint super-resolution and denoising (SRD) in post-processing. This new type of joint filtering allows only a low-resolution and fewer-sample (thus noisy) image to be rendered by path tracing, which is then fed into a deep neural network to produce a high-resolution and clean image. The main contribution of this work is a new end-to-end network architecture, specifically designed for the SRD task. It contains two cascaded stages with shared components. We discover that denoising and super-resolution require very different receptive fields, a key insight that leads to the introduction of deformable convolution into the network design. Extensive experiments show that the proposed method outperforms previous methods and their variants adopted for the SRD task.
Temporal Knowledge Propagation for Image-to-Video Person Re-identification
Aug 11, 2019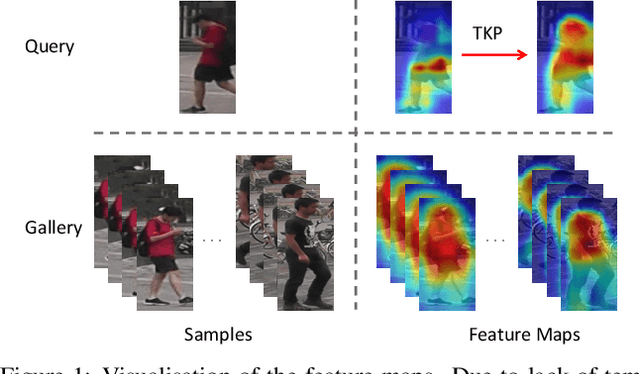
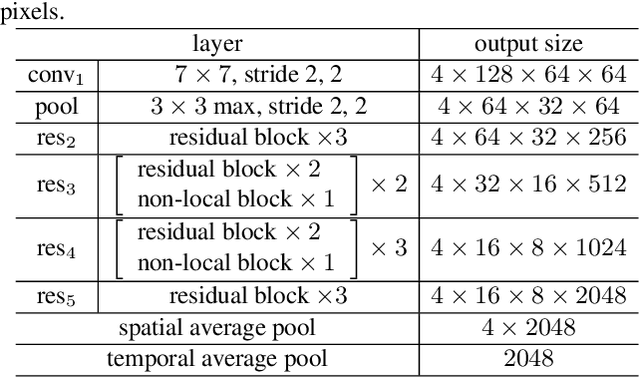
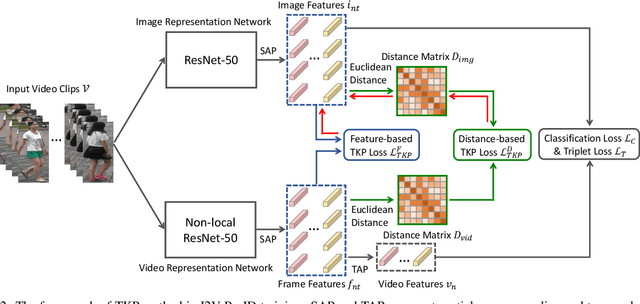
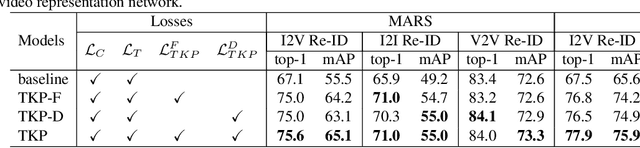
In many scenarios of Person Re-identification (Re-ID), the gallery set consists of lots of surveillance videos and the query is just an image, thus Re-ID has to be conducted between image and videos. Compared with videos, still person images lack temporal information. Besides, the information asymmetry between image and video features increases the difficulty in matching images and videos. To solve this problem, we propose a novel Temporal Knowledge Propagation (TKP) method which propagates the temporal knowledge learned by the video representation network to the image representation network. Specifically, given the input videos, we enforce the image representation network to fit the outputs of video representation network in a shared feature space. With back propagation, temporal knowledge can be transferred to enhance the image features and the information asymmetry problem can be alleviated. With additional classification and integrated triplet losses, our model can learn expressive and discriminative image and video features for image-to-video re-identification. Extensive experiments demonstrate the effectiveness of our method and the overall results on two widely used datasets surpass the state-of-the-art methods by a large margin.
Online Multi-Granularity Distillation for GAN Compression
Aug 16, 2021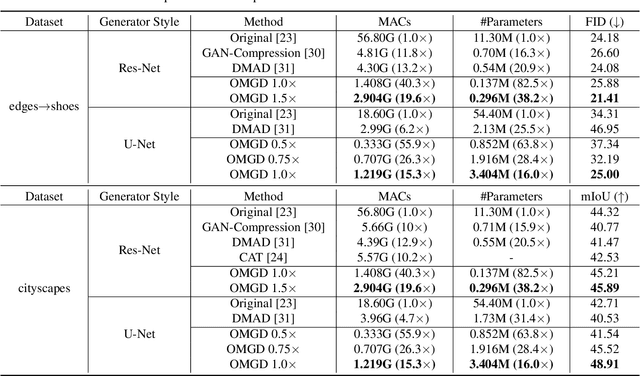
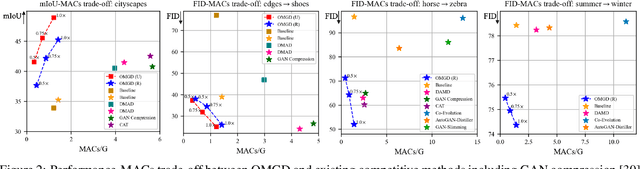
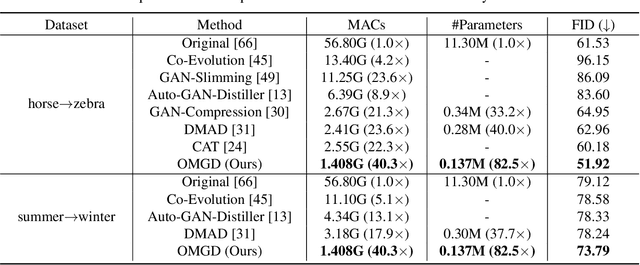
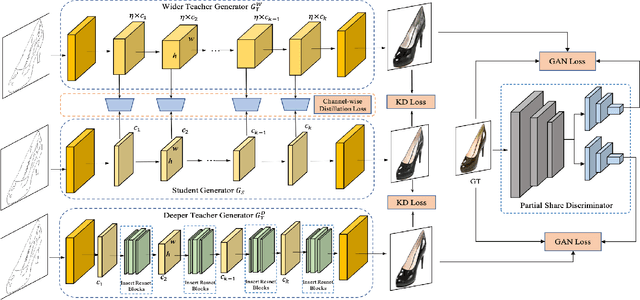
Generative Adversarial Networks (GANs) have witnessed prevailing success in yielding outstanding images, however, they are burdensome to deploy on resource-constrained devices due to ponderous computational costs and hulking memory usage. Although recent efforts on compressing GANs have acquired remarkable results, they still exist potential model redundancies and can be further compressed. To solve this issue, we propose a novel online multi-granularity distillation (OMGD) scheme to obtain lightweight GANs, which contributes to generating high-fidelity images with low computational demands. We offer the first attempt to popularize single-stage online distillation for GAN-oriented compression, where the progressively promoted teacher generator helps to refine the discriminator-free based student generator. Complementary teacher generators and network layers provide comprehensive and multi-granularity concepts to enhance visual fidelity from diverse dimensions. Experimental results on four benchmark datasets demonstrate that OMGD successes to compress 40x MACs and 82.5X parameters on Pix2Pix and CycleGAN, without loss of image quality. It reveals that OMGD provides a feasible solution for the deployment of real-time image translation on resource-constrained devices. Our code and models are made public at: https://github.com/bytedance/OMGD.
Image-on-Scalar Regression via Deep Neural Networks
Jun 17, 2020
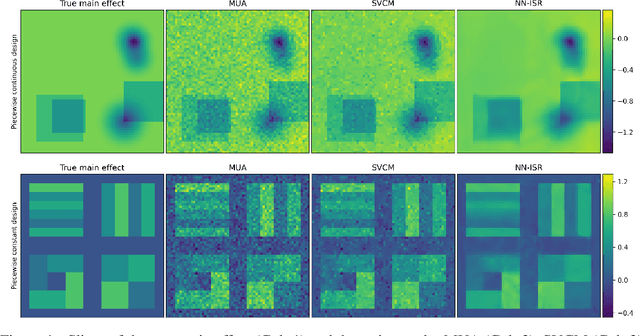
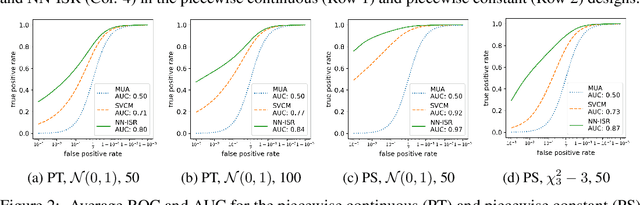
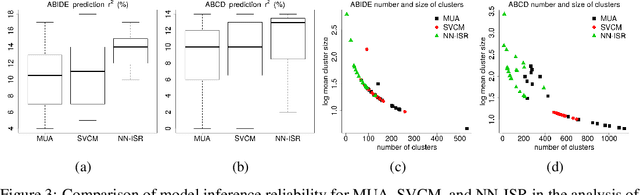
A research topic of central interest in neuroimaging analysis is to study the associations between the massive imaging data and a set of covariates. This problem is challenging, due to the ultrahigh dimensionality, the high and heterogeneous level of noise, and the limited sample size of the imaging data. To address those challenges, we develop a novel image-on-scalar regression model, where the spatially-varying coefficients and the individual spatial effects are all constructed through deep neural networks (DNN). Compared with the existing solutions, our method is much more flexible in capturing the complex patterns among the brain signals, of which the noise level and the spatial smoothness appear to be heterogeneous across different brain regions. We develop a hybrid stochastic gradient descent estimation algorithm, and derive the asymptotic properties when the number of voxels grows much faster than the sample size. We show that the new method outperforms the existing ones through both extensive simulations and two neuroimaging data examples.
NuI-Go: Recursive Non-Local Encoder-Decoder Network for Retinal Image Non-Uniform Illumination Removal
Aug 07, 2020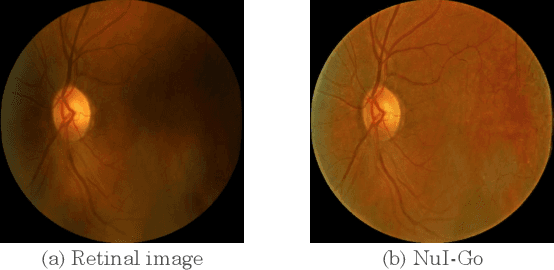
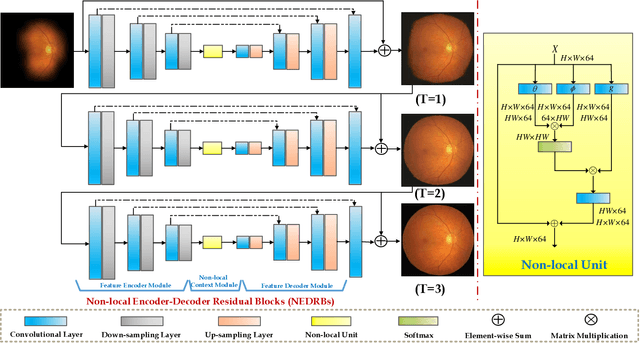

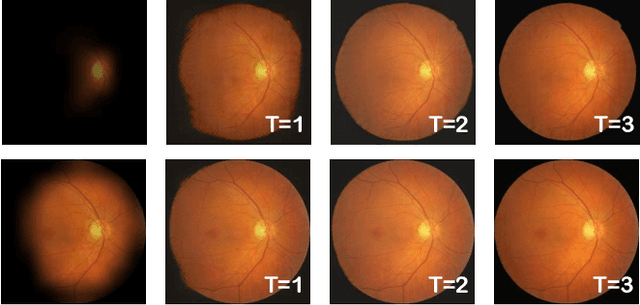
Retinal images have been widely used by clinicians for early diagnosis of ocular diseases. However, the quality of retinal images is often clinically unsatisfactory due to eye lesions and imperfect imaging process. One of the most challenging quality degradation issues in retinal images is non-uniform which hinders the pathological information and further impairs the diagnosis of ophthalmologists and computer-aided analysis.To address this issue, we propose a non-uniform illumination removal network for retinal image, called NuI-Go, which consists of three Recursive Non-local Encoder-Decoder Residual Blocks (NEDRBs) for enhancing the degraded retinal images in a progressive manner. Each NEDRB contains a feature encoder module that captures the hierarchical feature representations, a non-local context module that models the context information, and a feature decoder module that recovers the details and spatial dimension. Additionally, the symmetric skip-connections between the encoder module and the decoder module provide long-range information compensation and reuse. Extensive experiments demonstrate that the proposed method can effectively remove the non-uniform illumination on retinal images while well preserving the image details and color. We further demonstrate the advantages of the proposed method for improving the accuracy of retinal vessel segmentation.
Informative Image Captioning with External Sources of Information
Jun 20, 2019
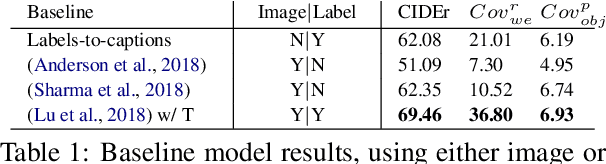
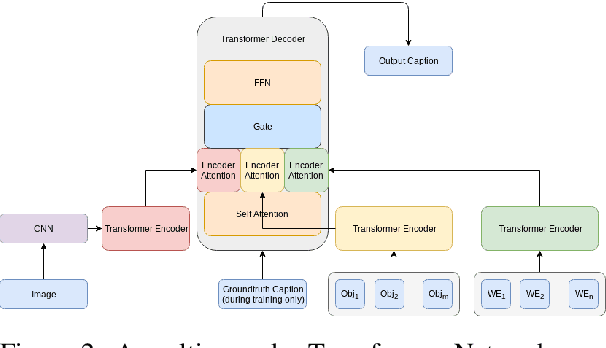
An image caption should fluently present the essential information in a given image, including informative, fine-grained entity mentions and the manner in which these entities interact. However, current captioning models are usually trained to generate captions that only contain common object names, thus falling short on an important "informativeness" dimension. We present a mechanism for integrating image information together with fine-grained labels (assumed to be generated by some upstream models) into a caption that describes the image in a fluent and informative manner. We introduce a multimodal, multi-encoder model based on Transformer that ingests both image features and multiple sources of entity labels. We demonstrate that we can learn to control the appearance of these entity labels in the output, resulting in captions that are both fluent and informative.
M5Product: A Multi-modal Pretraining Benchmark for E-commercial Product Downstream Tasks
Sep 09, 2021
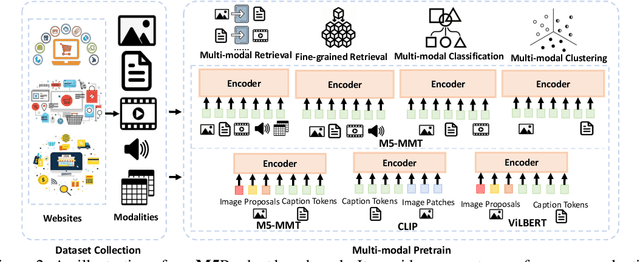
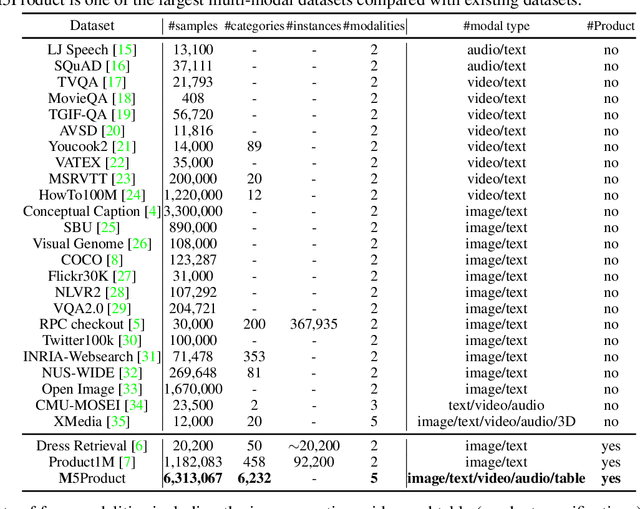
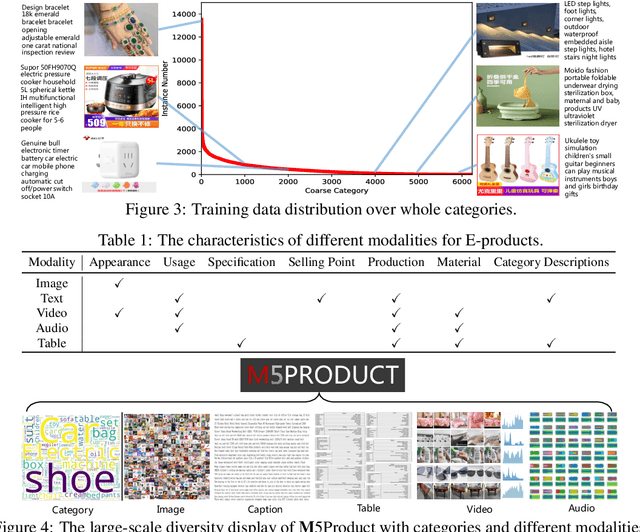
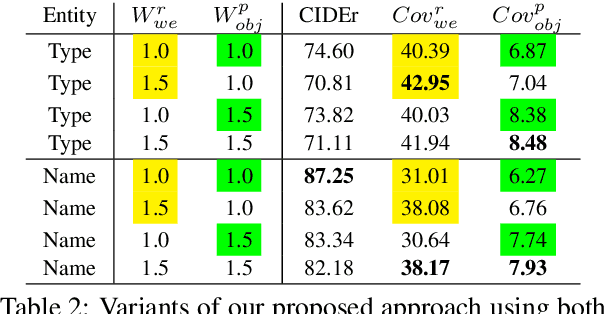
In this paper, we aim to advance the research of multi-modal pre-training on E-commerce and subsequently contribute a large-scale dataset, named M5Product, which consists of over 6 million multimodal pairs, covering more than 6,000 categories and 5,000 attributes. Generally, existing multi-modal datasets are either limited in scale or modality diversity. Differently, our M5Product is featured from the following aspects. First, the M5Product dataset is 500 times larger than the public multimodal dataset with the same number of modalities and nearly twice larger compared with the largest available text-image cross-modal dataset. Second, the dataset contains rich information of multiple modalities including image, text, table, video and audio, in which each modality can capture different views of semantic information (e.g. category, attributes, affordance, brand, preference) and complements the other. Third, to better accommodate with real-world problems, a few portion of M5Product contains incomplete modality pairs and noises while having the long-tailed distribution, which aligns well with real-world scenarios. Finally, we provide a baseline model M5-MMT that makes the first attempt to integrate the different modality configuration into an unified model for feature fusion to address the great challenge for semantic alignment. We also evaluate various multi-model pre-training state-of-the-arts for benchmarking their capabilities in learning from unlabeled data under the different number of modalities on the M5Product dataset. We conduct extensive experiments on four downstream tasks and provide some interesting findings on these modalities. Our dataset and related code are available at https://xiaodongsuper.github.io/M5Product_dataset.
TextAdaIN: Fine-Grained AdaIN for Robust Text Recognition
May 09, 2021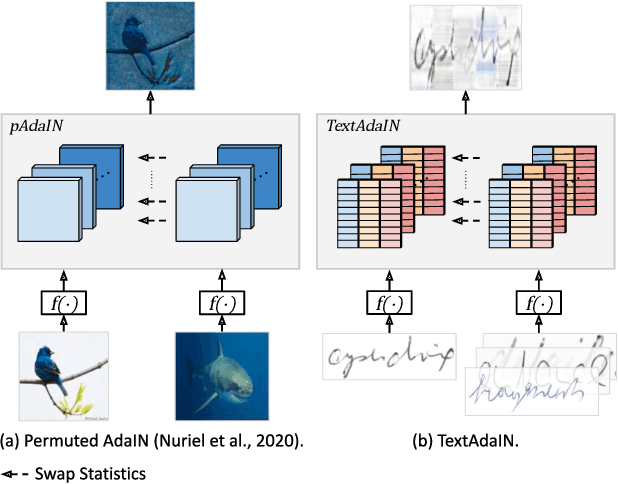
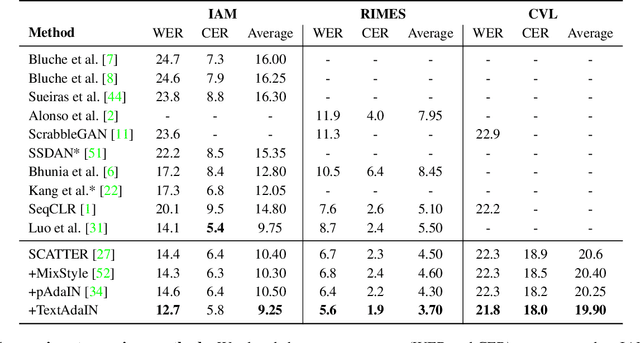

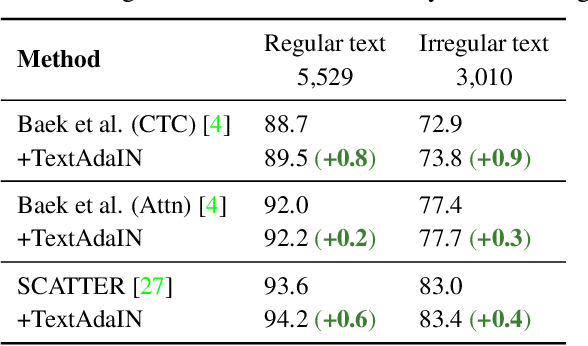
Leveraging the characteristics of convolutional layers, image classifiers are extremely effective. However, recent works have exposed that in many cases they immoderately rely on global image statistics that are easy to manipulate while preserving image semantics. In text recognition, we reveal that it is rather the local image statistics which the networks overly depend on. Motivated by this, we suggest an approach to regulate the reliance on local statistics that improves overall text recognition performance. Our method, termed TextAdaIN, creates local distortions in the feature map which prevent the network from overfitting to the local statistics. It does so by deliberately mismatching fine-grained feature statistics between samples in a mini-batch. Despite TextAdaIN's simplicity, extensive experiments show its effectiveness compared to other, more complicated methods. TextAdaIN achieves state-of-the-art results on standard handwritten text recognition benchmarks. Additionally, it generalizes to multiple architectures and to the domain of scene text recognition. Furthermore, we demonstrate that integrating TextAdaIN improves robustness towards image corruptions.
Image Captioning with Unseen Objects
Jul 31, 2019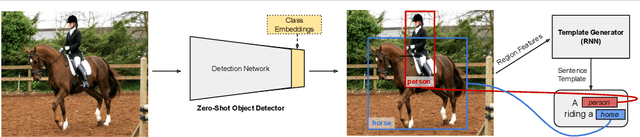

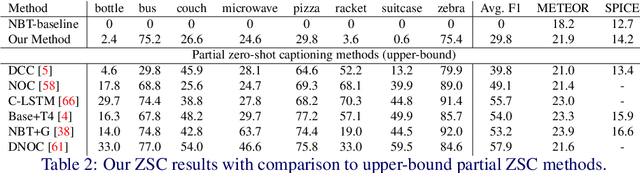

Image caption generation is a long standing and challenging problem at the intersection of computer vision and natural language processing. A number of recently proposed approaches utilize a fully supervised object recognition model within the captioning approach. Such models, however, tend to generate sentences which only consist of objects predicted by the recognition models, excluding instances of the classes without labelled training examples. In this paper, we propose a new challenging scenario that targets the image captioning problem in a fully zero-shot learning setting, where the goal is to be able to generate captions of test images containing objects that are not seen during training. The proposed approach jointly uses a novel zero-shot object detection model and a template-based sentence generator. Our experiments show promising results on the COCO dataset.
Copy and Paste method based on Pose for Re-identification
Jul 23, 2021


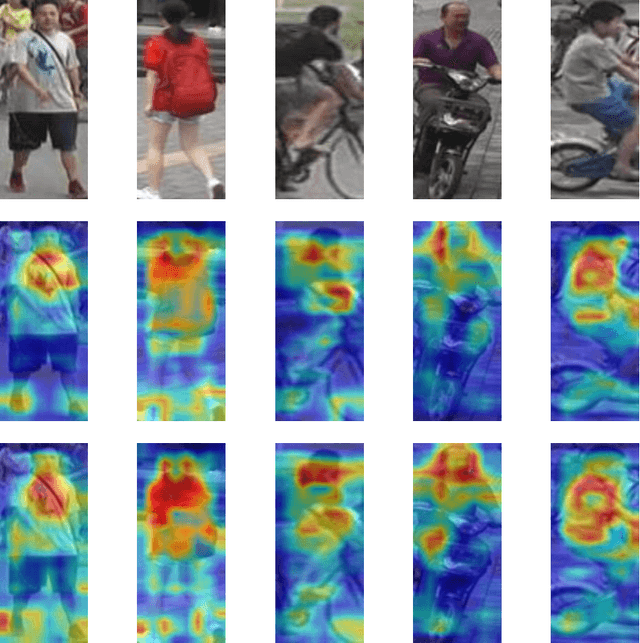
Re-identification (ReID) aims at matching objects in surveillance cameras with different viewpoints. It's developing very fast, but there is no processing method for the ReID task in multiple scenarios at this stage. However, this dose happen all the time in real life, such as the security scenarios. This paper explores a new scenario of Re-identification, which differs in perspective, background, and pose(walking or cycling). Obviously, ordinary ReID processing methods cannot handle this scenario well. As we all know, the best way to deal with that it is to introduce image datasets in this scanario, But this one is very expensive. To solve this problem, this paper proposes a simple and effective way to generate images in some new scenario, which is named Copy and Paste method based on Pose(CPP). The CPP is a method based on key point detection, using copy and paste, to composite a new semantic image dataset in two different semantic image datasets. Such as, we can use pedestrians and bicycles to generate some images that shows the same person rides on different bicycles. The CPP is suitable for ReID tasks in new scenarios and it outperforms state-of-the-art on the original datasets in original ReID tasks. Specifically, it can also have better generalization performance for third-party public datasets. Code and Datasets which composited by the CPP will be available in the future.