 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature Generation for Long-tail Classification
Nov 10, 2021
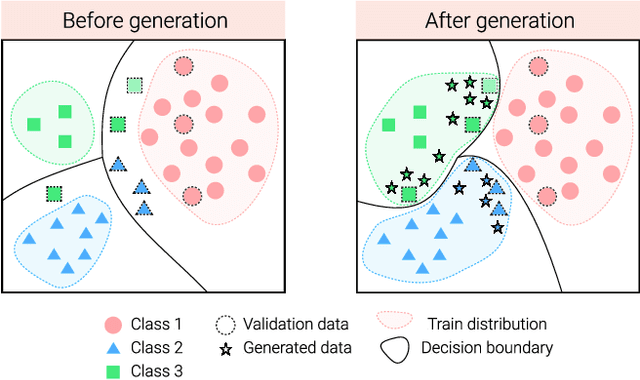
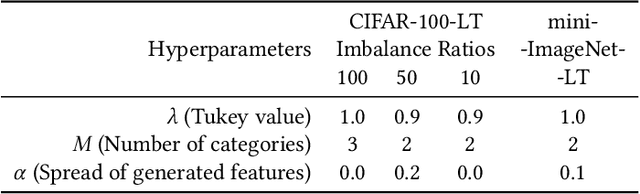
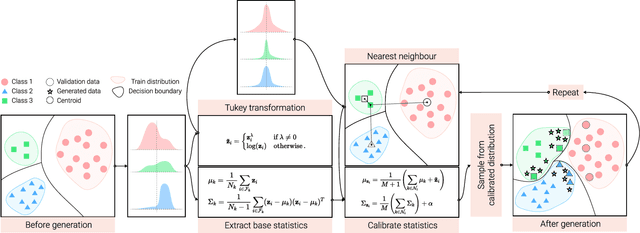
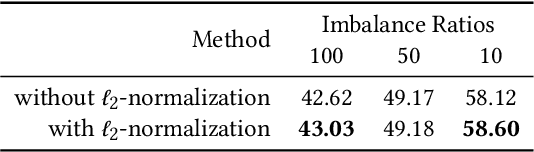
The visual world naturally exhibits an imbalance in the number of object or scene instances resulting in a \emph{long-tailed distribution}. This imbalance poses significant challenges for classification models based on deep learning. Oversampling instances of the tail classes attempts to solve this imbalance. However, the limited visual diversity results in a network with poor representation ability. A simple counter to this is decoupling the representation and classifier networks and using oversampling only to train the classifier. In this paper, instead of repeatedly re-sampling the same image (and thereby features), we explore a direction that attempts to generate meaningful features by estimating the tail category's distribution. Inspired by ideas from recent work on few-shot learning, we create calibrated distributions to sample additional features that are subsequently used to train the classifier. Through several experiments on the CIFAR-100-LT (long-tail) dataset with varying imbalance factors and on mini-ImageNet-LT (long-tail), we show the efficacy of our approach and establish a new state-of-the-art. We also present a qualitative analysis of generated features using t-SNE visualizations and analyze the nearest neighbors used to calibrate the tail class distributions. Our code is available at https://github.com/rahulvigneswaran/TailCalibX.
Keys to Accurate Feature Extraction Using Residual Spiking Neural Networks
Nov 10, 2021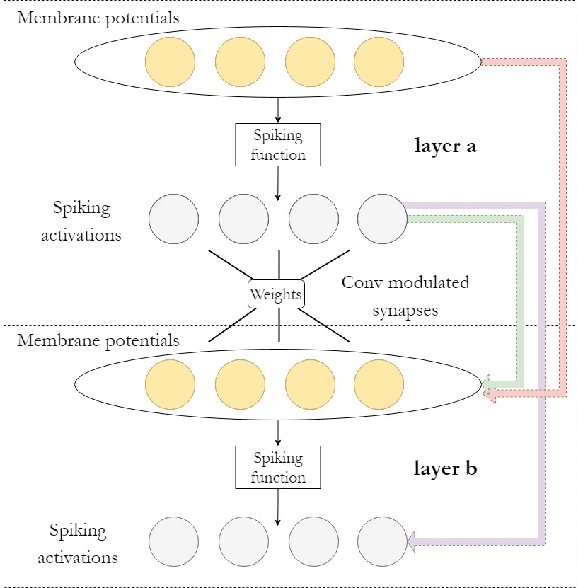
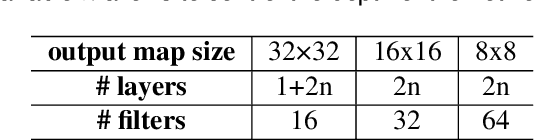
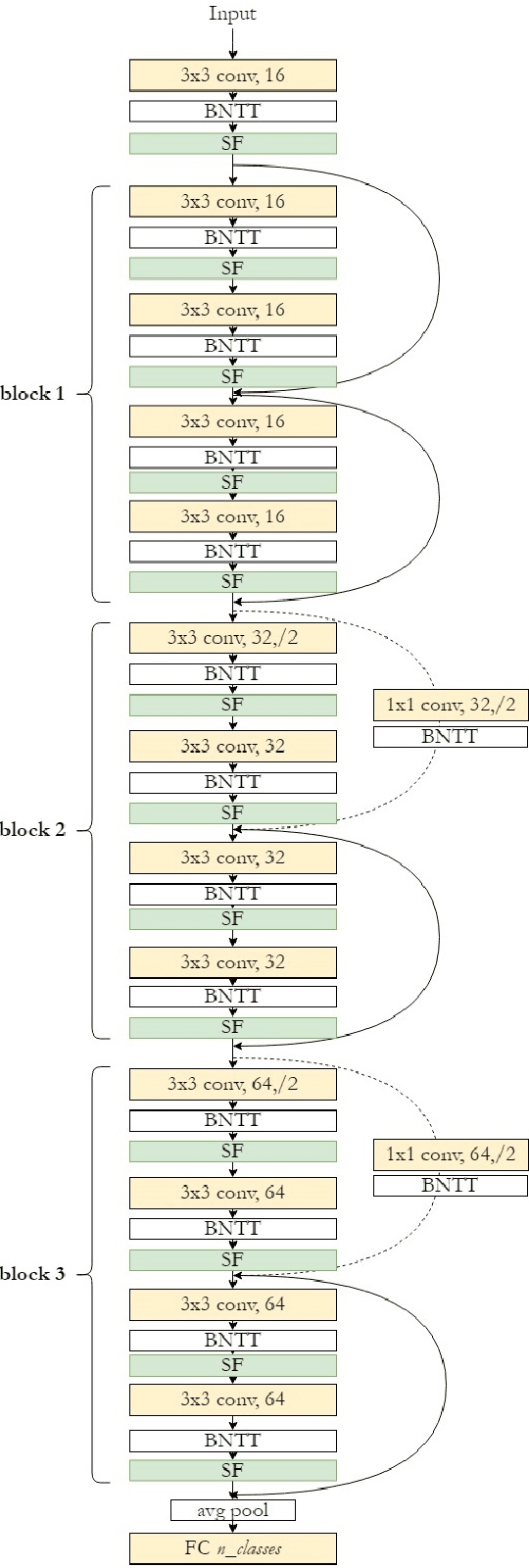

Spiking neural networks (SNNs) have become an interesting alternative to conventional artificial neural networks (ANN) thanks to their temporal processing capabilities and their low-SWaP (Size, Weight, and Power) and energy efficient implementations in neuromorphic hardware. However the challenges involved in training SNNs have limited their performance in terms of accuracy and thus their applications. Improving learning algorithms and neural architectures for a more accurate feature extraction is therefore one of the current priorities in SNN research. In this paper we present a study on the key components of modern spiking architectures. We empirically compare different techniques in image classification datasets taken from the best performing networks. We design a spiking version of the successful residual network (ResNet) architecture and test different components and training strategies on it. Our results provide a state of the art guide to SNN design, which allows to make informed choices when trying to build the optimal visual feature extractor. Finally, our network outperforms previous SNN architectures in CIFAR-10 (94.1%) and CIFAR-100 (74.5%) datasets and matches the state of the art in DVS-CIFAR10 (71.3%), with less parameters than the previous state of the art and without the need for ANN-SNN conversion. Code available at https://github.com/VicenteAlex/Spiking_ResNet.
Online Multi-Granularity Distillation for GAN Compression
Aug 26, 2021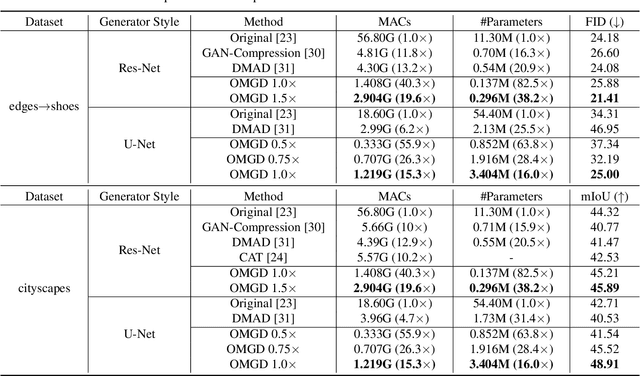
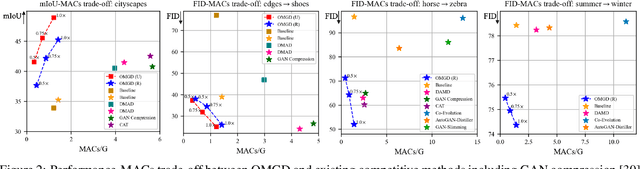
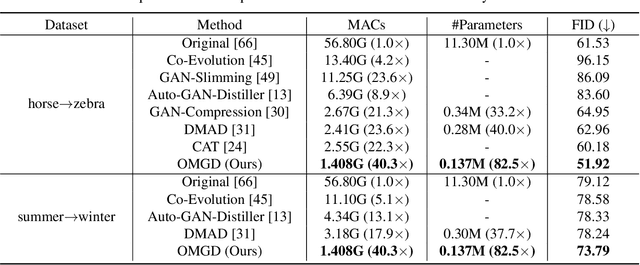
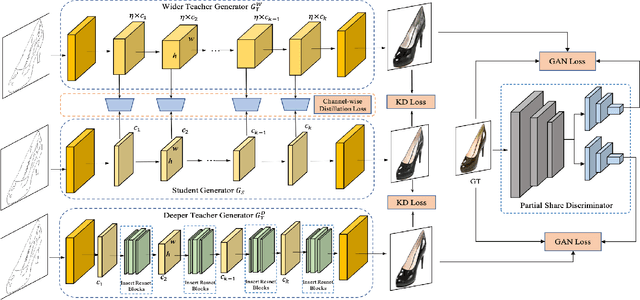
Generative Adversarial Networks (GANs) have witnessed prevailing success in yielding outstanding images, however, they are burdensome to deploy on resource-constrained devices due to ponderous computational costs and hulking memory usage. Although recent efforts on compressing GANs have acquired remarkable results, they still exist potential model redundancies and can be further compressed. To solve this issue, we propose a novel online multi-granularity distillation (OMGD) scheme to obtain lightweight GANs, which contributes to generating high-fidelity images with low computational demands. We offer the first attempt to popularize single-stage online distillation for GAN-oriented compression, where the progressively promoted teacher generator helps to refine the discriminator-free based student generator. Complementary teacher generators and network layers provide comprehensive and multi-granularity concepts to enhance visual fidelity from diverse dimensions. Experimental results on four benchmark datasets demonstrate that OMGD successes to compress 40x MACs and 82.5X parameters on Pix2Pix and CycleGAN, without loss of image quality. It reveals that OMGD provides a feasible solution for the deployment of real-time image translation on resource-constrained devices. Our code and models are made public at: https://github.com/bytedance/OMGD.
Harmonic Unpaired Image-to-image Translation
Feb 26, 2019
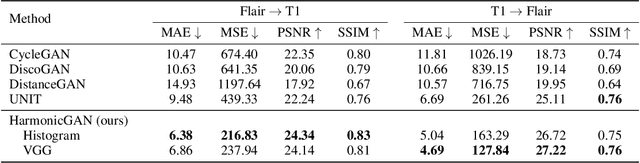
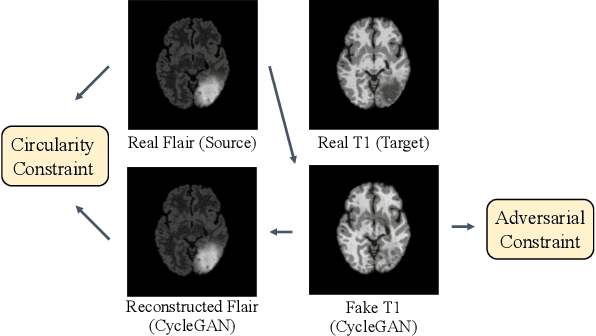
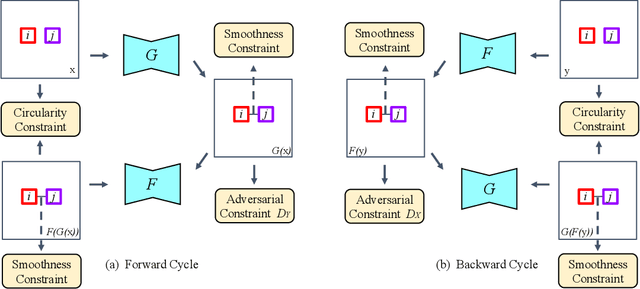
The recent direction of unpaired image-to-image translation is on one hand very exciting as it alleviates the big burden in obtaining label-intensive pixel-to-pixel supervision, but it is on the other hand not fully satisfactory due to the presence of artifacts and degenerated transformations. In this paper, we take a manifold view of the problem by introducing a smoothness term over the sample graph to attain harmonic functions to enforce consistent mappings during the translation. We develop HarmonicGAN to learn bi-directional translations between the source and the target domains. With the help of similarity-consistency, the inherent self-consistency property of samples can be maintained. Distance metrics defined on two types of features including histogram and CNN are exploited. Under an identical problem setting as CycleGAN, without additional manual inputs and only at a small training-time cost, HarmonicGAN demonstrates a significant qualitative and quantitative improvement over the state of the art, as well as improved interpretability. We show experimental results in a number of applications including medical imaging, object transfiguration, and semantic labeling. We outperform the competing methods in all tasks, and for a medical imaging task in particular our method turns CycleGAN from a failure to a success, halving the mean-squared error, and generating images that radiologists prefer over competing methods in 95% of cases.
Differential Morph Face Detection using Discriminative Wavelet Sub-bands
Jun 24, 2021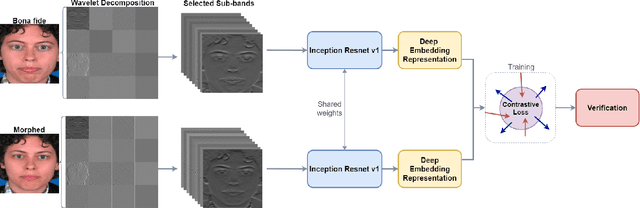
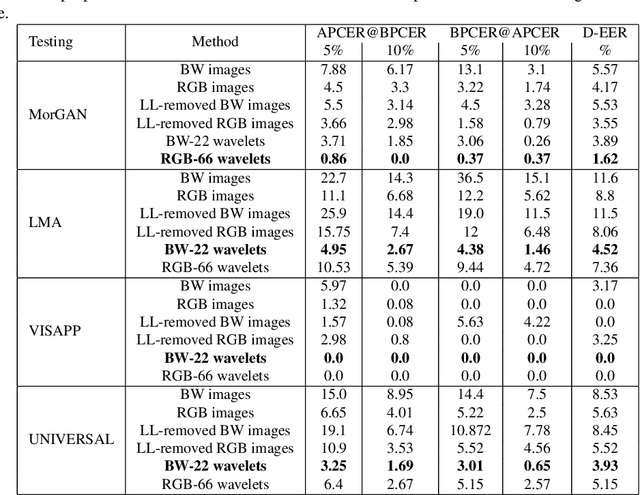
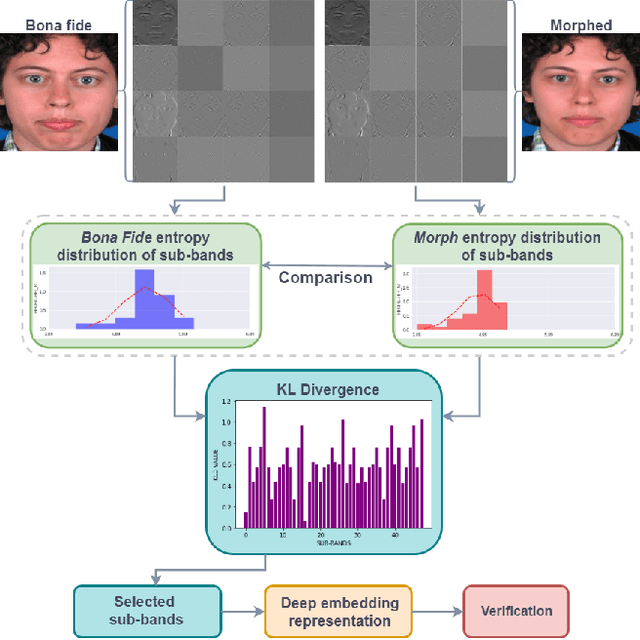
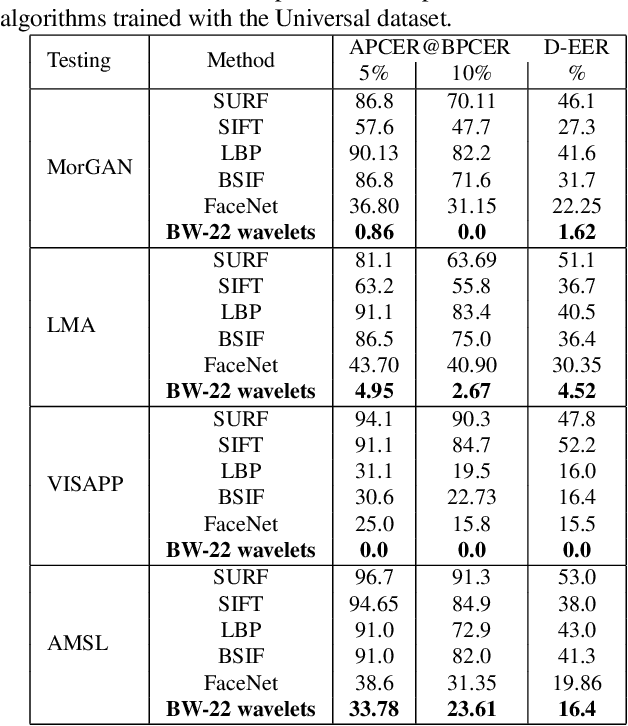
Face recognition systems are extremely vulnerable to morphing attacks, in which a morphed facial reference image can be successfully verified as two or more distinct identities. In this paper, we propose a morph attack detection algorithm that leverages an undecimated 2D Discrete Wavelet Transform (DWT) for identifying morphed face images. The core of our framework is that artifacts resulting from the morphing process that are not discernible in the image domain can be more easily identified in the spatial frequency domain. A discriminative wavelet sub-band can accentuate the disparity between a real and a morphed image. To this end, multi-level DWT is applied to all images, yielding 48 mid and high-frequency sub-bands each. The entropy distributions for each sub-band are calculated separately for both bona fide and morph images. For some of the sub-bands, there is a marked difference between the entropy of the sub-band in a bona fide image and the identical sub-band's entropy in a morphed image. Consequently, we employ Kullback-Liebler Divergence (KLD) to exploit these differences and isolate the sub-bands that are the most discriminative. We measure how discriminative a sub-band is by its KLD value and the 22 sub-bands with the highest KLD values are chosen for network training. Then, we train a deep Siamese neural network using these 22 selected sub-bands for differential morph attack detection. We examine the efficacy of discriminative wavelet sub-bands for morph attack detection and show that a deep neural network trained on these sub-bands can accurately identify morph imagery.
* CVPR Biometrics Workshop 2021
Learning Anchored Unsigned Distance Functions with Gradient Direction Alignment for Single-view Garment Reconstruction
Aug 19, 2021
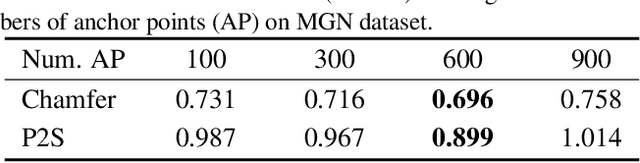
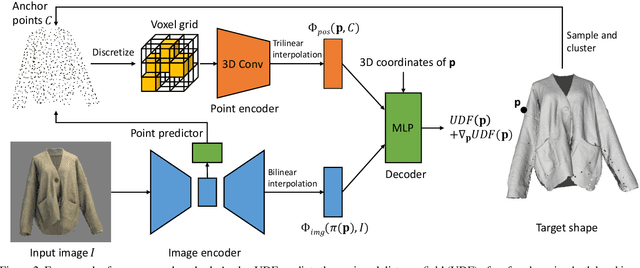
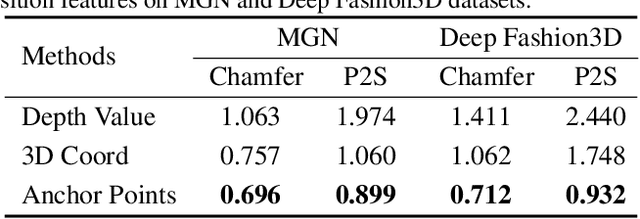
While single-view 3D reconstruction has made significant progress benefiting from deep shape representations in recent years, garment reconstruction is still not solved well due to open surfaces, diverse topologies and complex geometric details. In this paper, we propose a novel learnable Anchored Unsigned Distance Function (AnchorUDF) representation for 3D garment reconstruction from a single image. AnchorUDF represents 3D shapes by predicting unsigned distance fields (UDFs) to enable open garment surface modeling at arbitrary resolution. To capture diverse garment topologies, AnchorUDF not only computes pixel-aligned local image features of query points, but also leverages a set of anchor points located around the surface to enrich 3D position features for query points, which provides stronger 3D space context for the distance function. Furthermore, in order to obtain more accurate point projection direction at inference, we explicitly align the spatial gradient direction of AnchorUDF with the ground-truth direction to the surface during training. Extensive experiments on two public 3D garment datasets, i.e., MGN and Deep Fashion3D, demonstrate that AnchorUDF achieves the state-of-the-art performance on single-view garment reconstruction.
Unsupervised Learning of Compositional Energy Concepts
Nov 04, 2021
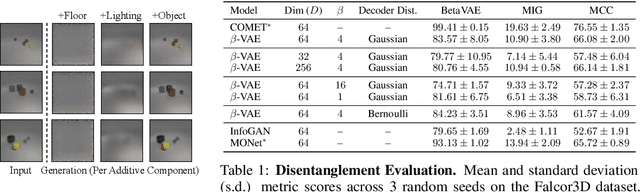
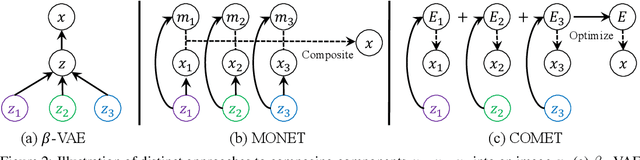
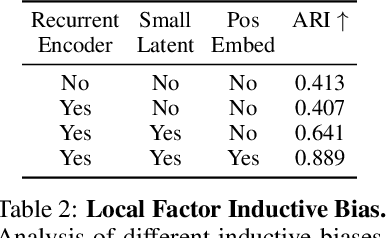
Humans are able to rapidly understand scenes by utilizing concepts extracted from prior experience. Such concepts are diverse, and include global scene descriptors, such as the weather or lighting, as well as local scene descriptors, such as the color or size of a particular object. So far, unsupervised discovery of concepts has focused on either modeling the global scene-level or the local object-level factors of variation, but not both. In this work, we propose COMET, which discovers and represents concepts as separate energy functions, enabling us to represent both global concepts as well as objects under a unified framework. COMET discovers energy functions through recomposing the input image, which we find captures independent factors without additional supervision. Sample generation in COMET is formulated as an optimization process on underlying energy functions, enabling us to generate images with permuted and composed concepts. Finally, discovered visual concepts in COMET generalize well, enabling us to compose concepts between separate modalities of images as well as with other concepts discovered by a separate instance of COMET trained on a different dataset. Code and data available at https://energy-based-model.github.io/comet/.
NENet: Monocular Depth Estimation via Neural Ensembles
Nov 16, 2021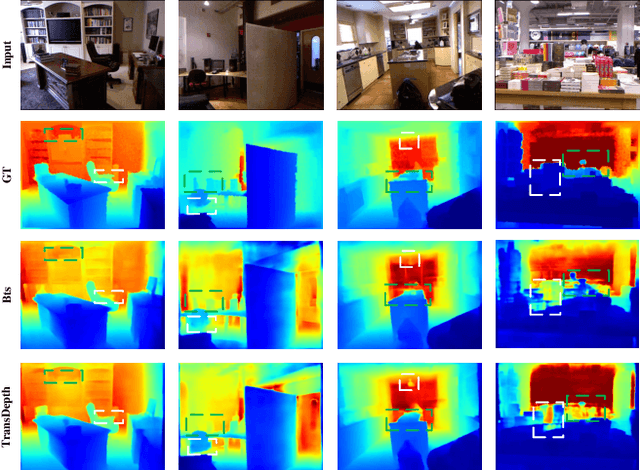
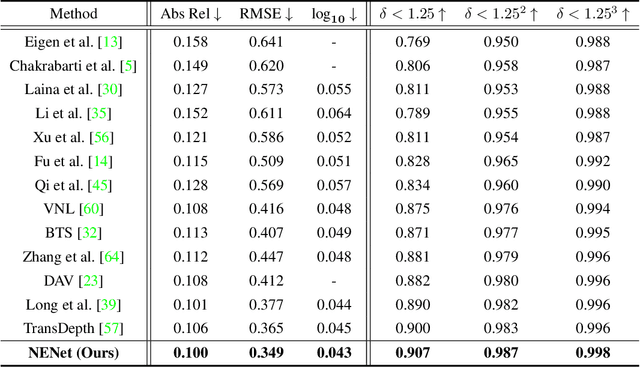
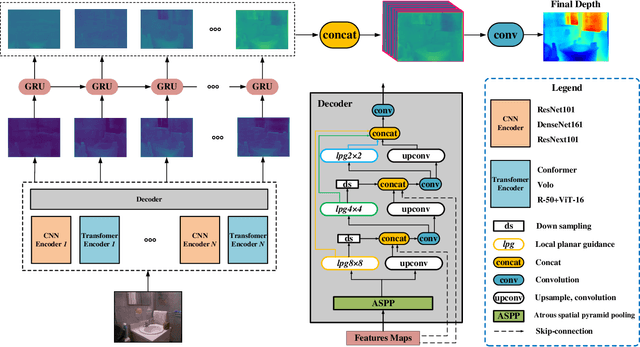
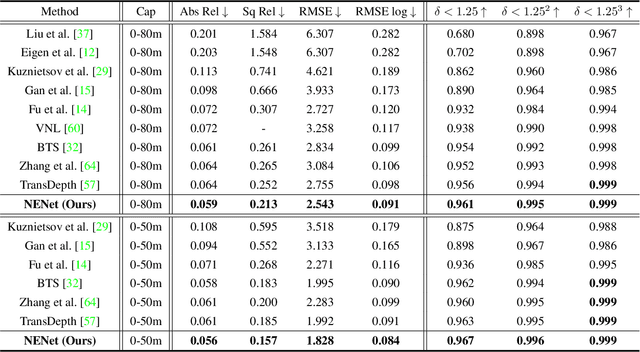
Depth estimation is getting a widespread popularity in the computer vision community, and it is still quite difficult to recover an accurate depth map using only one single RGB image. In this work, we observe a phenomenon that existing methods tend to exhibit asymmetric errors, which might open up a new direction for accurate and robust depth estimation. We carefully investigate into the phenomenon, and construct a two-level ensemble scheme, NENet, to integrate multiple predictions from diverse base predictors. The NENet forms a more reliable depth estimator, which substantially boosts the performance over base predictors. Notably, this is the first attempt to introduce ensemble learning and evaluate its utility for monocular depth estimation to the best of our knowledge. Extensive experiments demonstrate that the proposed NENet achieves better results than previous state-of-the-art approaches on the NYU-Depth-v2 and KITTI datasets. In particular, our method improves previous state-of-the-art methods from 0.365 to 0.349 on the metric RMSE on the NYU dataset. To validate the generalizability across cameras, we directly apply the models trained on the NYU dataset to the SUN RGB-D dataset without any fine-tuning, and achieve the superior results, which indicate its strong generalizability. The source code and trained models will be publicly available upon the acceptance.
Temporal Aware Deep Reinforcement Learning
Sep 05, 2021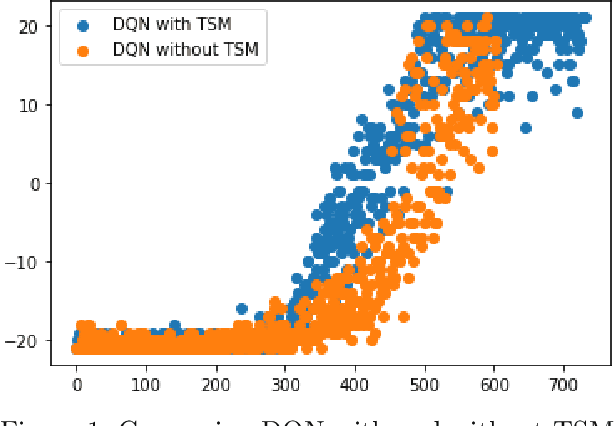
The function approximators employed by traditional image based Deep Reinforcement Learning (DRL) algorithms usually lack a temporal learning component and instead focus on learning the spatial component. We propose a technique wherein both temporal as well as spatial components are jointly learned. Our tested was tested with a generic DQN and it outperformed it in terms of maximum rewards as well as sample complexity. This algorithm has implications in the robotics as well as sequential decision making domains.
3D Object Detection Method Based on YOLO and K-Means for Image and Point Clouds
Apr 21, 2020



Lidar based 3D object detection and classification tasks are essential for autonomous driving(AD). A lidar sensor can provide the 3D point cloud data reconstruction of the surrounding environment. However, real time detection in 3D point clouds still needs a strong algorithmic. This paper proposes a 3D object detection method based on point cloud and image which consists of there parts.(1)Lidar-camera calibration and undistorted image transformation. (2)YOLO-based detection and PointCloud extraction, (3)K-means based point cloud segmentation and detection experiment test and evaluation in depth image. In our research, camera can capture the image to make the Real-time 2D object detection by using YOLO, we transfer the bounding box to node whose function is making 3d object detection on point cloud data from Lidar. By comparing whether 2D coordinate transferred from the 3D point is in the object bounding box or not can achieve High-speed 3D object recognition function in GPU. The accuracy and precision get imporved after k-means clustering in point cloud. The speed of our detection method is a advantage faster than PointNet.