 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Validate on Sim, Detect on Real -- Model Selection for Domain Randomization
Dec 01, 2021
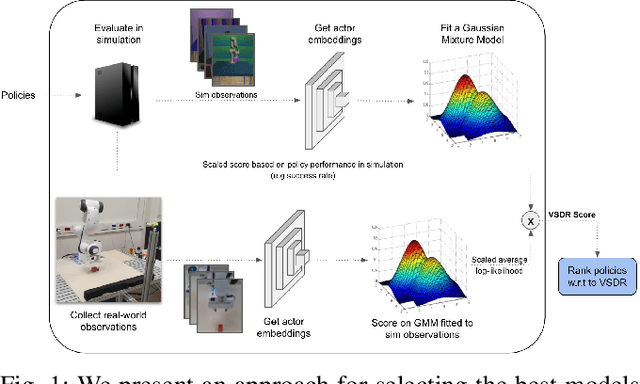
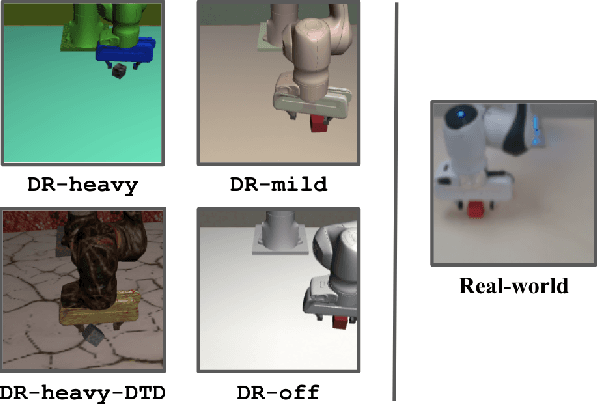
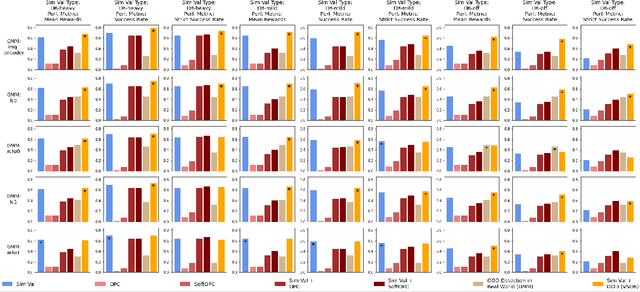
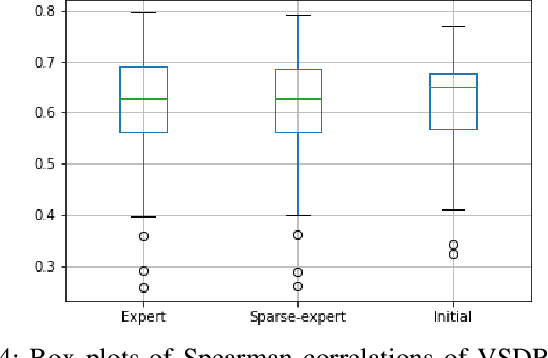
A practical approach to learning robot skills, often termed sim2real, is to train control policies in simulation and then deploy them on a real robot. Popular techniques to improve the sim2real transfer build on domain randomization (DR): Training the policy on a diverse set of randomly generated domains with the hope of better generalization to the real world. Due to the large number of hyper-parameters in both the policy learning and DR algorithms, one often ends up with a large number of trained models, where choosing the best model among them demands costly evaluation on the real robot. In this work we ask: Can we rank the policies without running them in the real world? Our main idea is that a predefined set of real world data can be used to evaluate all policies, using out-of-distribution detection (OOD) techniques. In a sense, this approach can be seen as a "unit test" to evaluate policies before any real world execution. However, we find that by itself, the OOD score can be inaccurate and very sensitive to the particular OOD method. Our main contribution is a simple-yet-effective policy score that combines OOD with an evaluation in simulation. We show that our score - VSDR - can significantly improve the accuracy of policy ranking without requiring additional real world data. We evaluate the effectiveness of VSDR on sim2real transfer in a robotic grasping task with image inputs. We extensively evaluate different DR parameters and OOD methods, and show that VSDR improves policy selection across the board. More importantly, our method achieves significantly better ranking, and uses significantly less data compared to baselines.
Do Vision Transformers See Like Convolutional Neural Networks?
Aug 19, 2021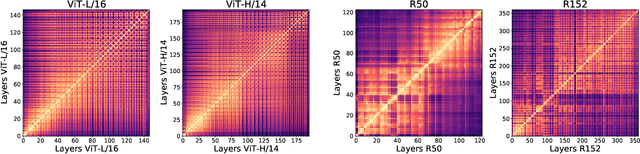
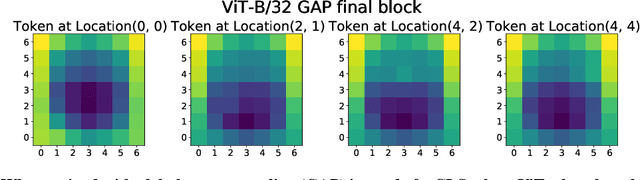
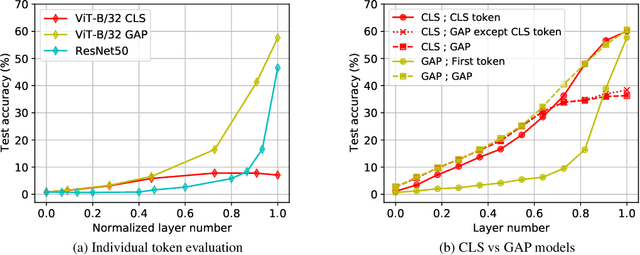
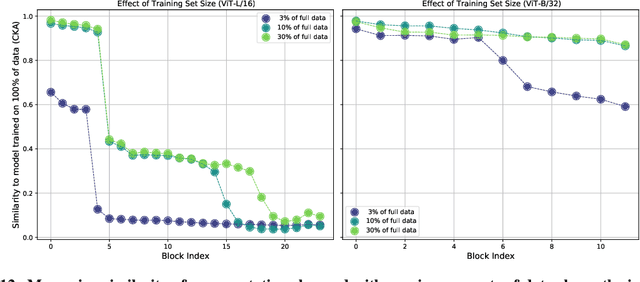
Convolutional neural networks (CNNs) have so far been the de-facto model for visual data. Recent work has shown that (Vision) Transformer models (ViT) can achieve comparable or even superior performance on image classification tasks. This raises a central question: how are Vision Transformers solving these tasks? Are they acting like convolutional networks, or learning entirely different visual representations? Analyzing the internal representation structure of ViTs and CNNs on image classification benchmarks, we find striking differences between the two architectures, such as ViT having more uniform representations across all layers. We explore how these differences arise, finding crucial roles played by self-attention, which enables early aggregation of global information, and ViT residual connections, which strongly propagate features from lower to higher layers. We study the ramifications for spatial localization, demonstrating ViTs successfully preserve input spatial information, with noticeable effects from different classification methods. Finally, we study the effect of (pretraining) dataset scale on intermediate features and transfer learning, and conclude with a discussion on connections to new architectures such as the MLP-Mixer.
Recognizing Vector Graphics without Rasterization
Nov 05, 2021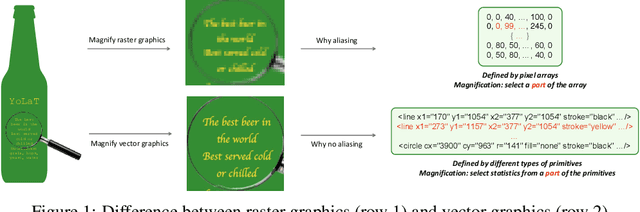
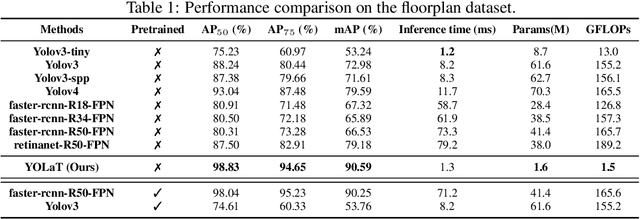
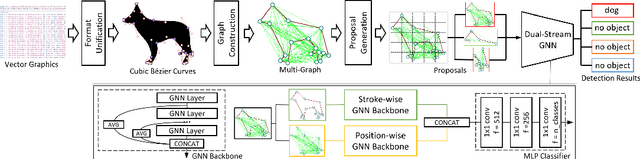
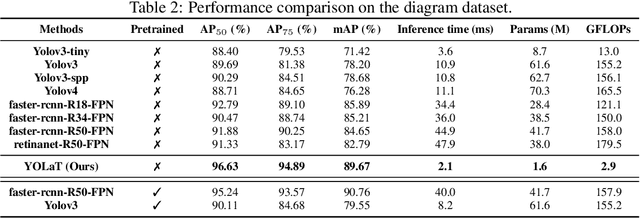
In this paper, we consider a different data format for images: vector graphics. In contrast to raster graphics which are widely used in image recognition, vector graphics can be scaled up or down into any resolution without aliasing or information loss, due to the analytic representation of the primitives in the document. Furthermore, vector graphics are able to give extra structural information on how low-level elements group together to form high level shapes or structures. These merits of graphic vectors have not been fully leveraged in existing methods. To explore this data format, we target on the fundamental recognition tasks: object localization and classification. We propose an efficient CNN-free pipeline that does not render the graphic into pixels (i.e. rasterization), and takes textual document of the vector graphics as input, called YOLaT (You Only Look at Text). YOLaT builds multi-graphs to model the structural and spatial information in vector graphics, and a dual-stream graph neural network is proposed to detect objects from the graph. Our experiments show that by directly operating on vector graphics, YOLaT out-performs raster-graphic based object detection baselines in terms of both average precision and efficiency.
Low-Rank and Total Variation Regularization and Its Application to Image Recovery
Mar 12, 2020
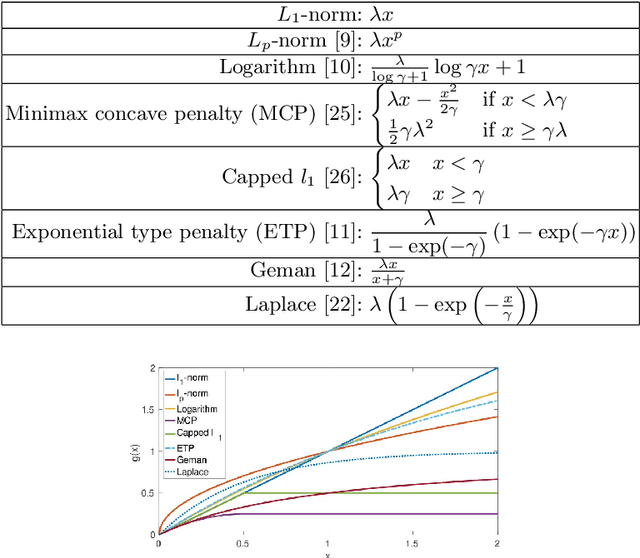
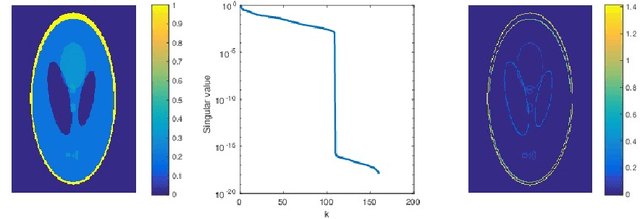
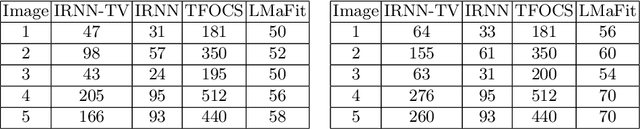
In this paper, we study the problem of image recovery from given partial (corrupted) observations. Recovering an image using a low-rank model has been an active research area in data analysis and machine learning. But often, images are not only of low-rank but they also exhibit sparsity in a transformed space. In this work, we propose a new problem formulation in such a way that we seek to recover an image that is of low-rank and has sparsity in a transformed domain. We further discuss various non-convex non-smooth surrogates of the rank function, leading to a relaxed problem. Then, we present an efficient iterative scheme to solve the relaxed problem that essentially employs the (weighted) singular value thresholding at each iteration. Furthermore, we discuss the convergence properties of the proposed iterative method. We perform extensive experiments, showing that the proposed algorithm outperforms state-of-the-art methodologies in recovering images.
Deep Two-Stream Video Inference for Human Body Pose and Shape Estimation
Oct 22, 2021
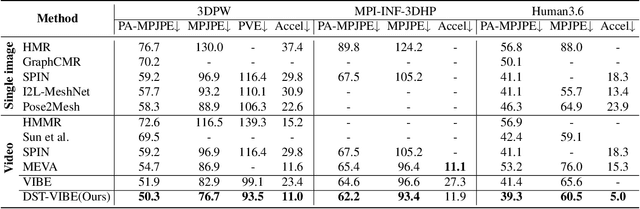
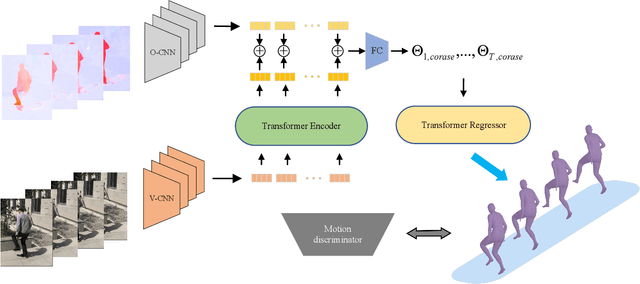

Several video-based 3D pose and shape estimation algorithms have been proposed to resolve the temporal inconsistency of single-image-based methods. However it still remains challenging to have stable and accurate reconstruction. In this paper, we propose a new framework Deep Two-Stream Video Inference for Human Body Pose and Shape Estimation (DTS-VIBE), to generate 3D human pose and mesh from RGB videos. We reformulate the task as a multi-modality problem that fuses RGB and optical flow for more reliable estimation. In order to fully utilize both sensory modalities (RGB or optical flow), we train a two-stream temporal network based on transformer to predict SMPL parameters. The supplementary modality, optical flow, helps to maintain temporal consistency by leveraging motion knowledge between two consecutive frames. The proposed algorithm is extensively evaluated on the Human3.6 and 3DPW datasets. The experimental results show that it outperforms other state-of-the-art methods by a significant margin.
Scientific Image Tampering Detection Based On Noise Inconsistencies: A Method And Datasets
Jan 21, 2020
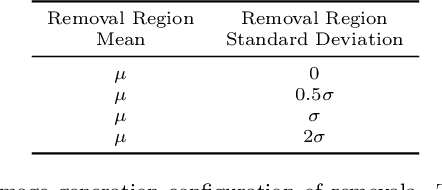

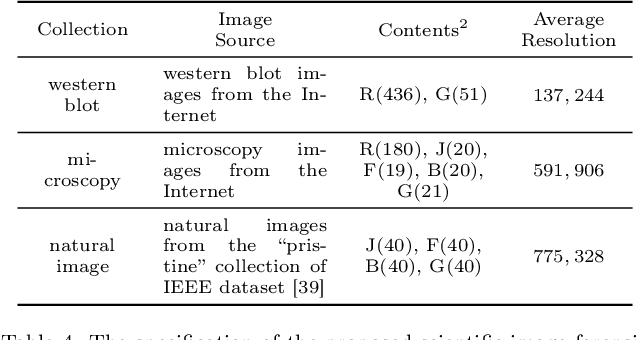
Scientific image tampering is a problem that affects not only authors but also the general perception of the research community. Although previous researchers have developed methods to identify tampering in natural images, these methods may not thrive under the scientific setting as scientific images have different statistics, format, quality, and intentions. Therefore, we propose a scientific-image specific tampering detection method based on noise inconsistencies, which is capable of learning and generalizing to different fields of science. We train and test our method on a new dataset of manipulated western blot and microscopy imagery, which aims at emulating problematic images in science. The test results show that our method can detect various types of image manipulation in different scenarios robustly, and it outperforms existing general-purpose image tampering detection schemes. We discuss applications beyond these two types of images and suggest next steps for making detection of problematic images a systematic step in peer review and science in general.
iFAN: Image-Instance Full Alignment Networks for Adaptive Object Detection
Mar 09, 2020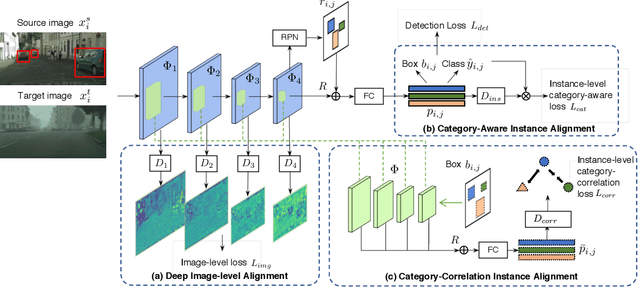
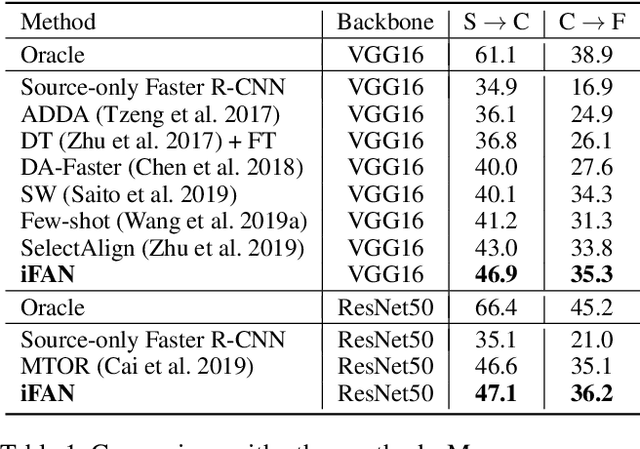
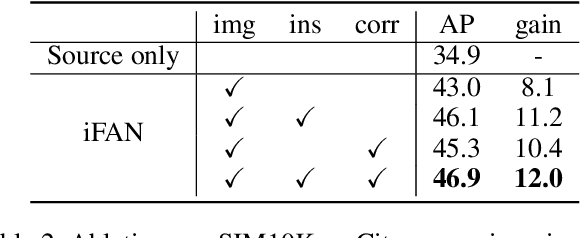

Training an object detector on a data-rich domain and applying it to a data-poor one with limited performance drop is highly attractive in industry, because it saves huge annotation cost. Recent research on unsupervised domain adaptive object detection has verified that aligning data distributions between source and target images through adversarial learning is very useful. The key is when, where and how to use it to achieve best practice. We propose Image-Instance Full Alignment Networks (iFAN) to tackle this problem by precisely aligning feature distributions on both image and instance levels: 1) Image-level alignment: multi-scale features are roughly aligned by training adversarial domain classifiers in a hierarchically-nested fashion. 2) Full instance-level alignment: deep semantic information and elaborate instance representations are fully exploited to establish a strong relationship among categories and domains. Establishing these correlations is formulated as a metric learning problem by carefully constructing instance pairs. Above-mentioned adaptations can be integrated into an object detector (e.g. Faster RCNN), resulting in an end-to-end trainable framework where multiple alignments can work collaboratively in a coarse-tofine manner. In two domain adaptation tasks: synthetic-to-real (SIM10K->Cityscapes) and normal-to-foggy weather (Cityscapes->Foggy Cityscapes), iFAN outperforms the state-of-the-art methods with a boost of 10%+ AP over the source-only baseline.
Inference via Sparse Coding in a Hierarchical Vision Model
Aug 03, 2021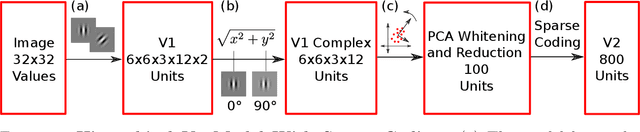


Sparse coding has been incorporated in models of the visual cortex for its computational advantages and connection to biology. But how the level of sparsity contributes to performance on visual tasks is not well understood. In this work, sparse coding has been integrated into an existing hierarchical V2 model (Hosoya and Hyv\"arinen, 2015), but replacing the Independent Component Analysis (ICA) with an explicit sparse coding in which the degree of sparsity can be controlled. After training, the sparse coding basis functions with a higher degree of sparsity resembled qualitatively different structures, such as curves and corners. The contributions of the models were assessed with image classification tasks, including object classification, and tasks associated with mid-level vision including figure-ground classification, texture classification, and angle prediction between two line stimuli. In addition, the models were assessed in comparison to a texture sensitivity measure that has been reported in V2 (Freeman et al., 2013), and a deleted-region inference task. The results from the experiments show that while sparse coding performed worse than ICA at classifying images, only sparse coding was able to better match the texture sensitivity level of V2 and infer deleted image regions, both by increasing the degree of sparsity in sparse coding. Higher degrees of sparsity allowed for inference over larger deleted image regions. The mechanism that allows for this inference capability in sparse coding is described here.
Attention Aware Wavelet-based Detection of Morphed Face Images
Jul 22, 2021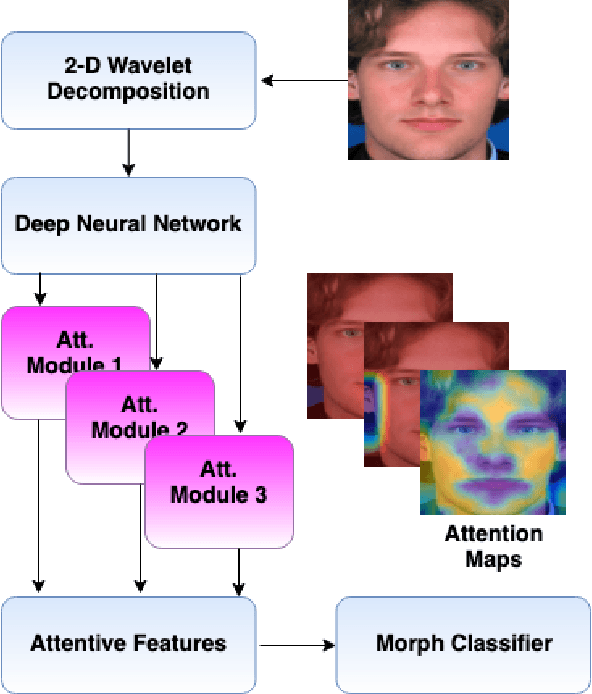
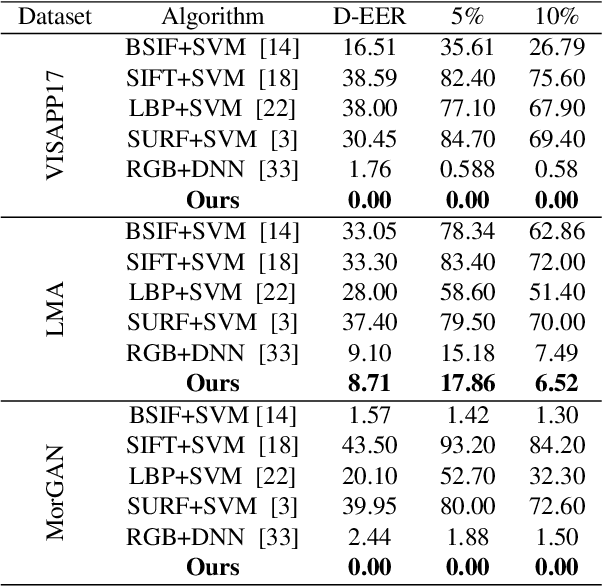
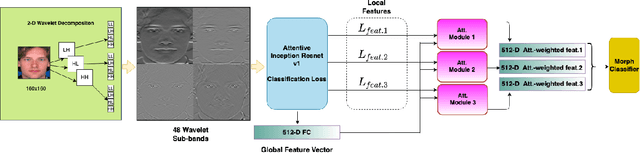
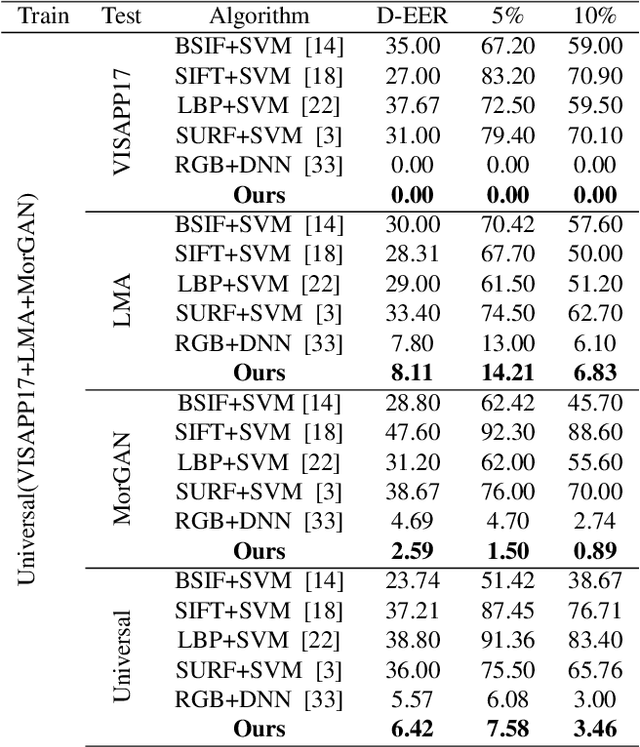
Morphed images have exploited loopholes in the face recognition checkpoints, e.g., Credential Authentication Technology (CAT), used by Transportation Security Administration (TSA), which is a non-trivial security concern. To overcome the risks incurred due to morphed presentations, we propose a wavelet-based morph detection methodology which adopts an end-to-end trainable soft attention mechanism . Our attention-based deep neural network (DNN) focuses on the salient Regions of Interest (ROI) which have the most spatial support for morph detector decision function, i.e, morph class binary softmax output. A retrospective of morph synthesizing procedure aids us to speculate the ROI as regions around facial landmarks , particularly for the case of landmark-based morphing techniques. Moreover, our attention-based DNN is adapted to the wavelet space, where inputs of the network are coarse-to-fine spectral representations, 48 stacked wavelet sub-bands to be exact. We evaluate performance of the proposed framework using three datasets, VISAPP17, LMA, and MorGAN. In addition, as attention maps can be a robust indicator whether a probe image under investigation is genuine or counterfeit, we analyze the estimated attention maps for both a bona fide image and its corresponding morphed image. Finally, we present an ablation study on the efficacy of utilizing attention mechanism for the sake of morph detection.
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Aug 30, 2018
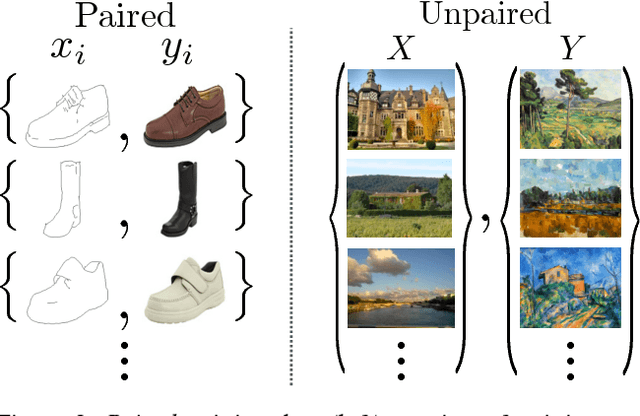
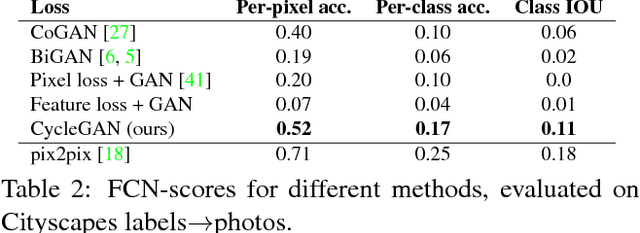
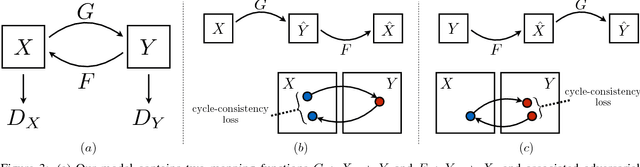
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain $X$ to a target domain $Y$ in the absence of paired examples. Our goal is to learn a mapping $G: X \rightarrow Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$ using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping $F: Y \rightarrow X$ and introduce a cycle consistency loss to push $F(G(X)) \approx X$ (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach.