 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conditional Generation of Synthetic Geospatial Images from Pixel-level and Feature-level Inputs
Sep 11, 2021
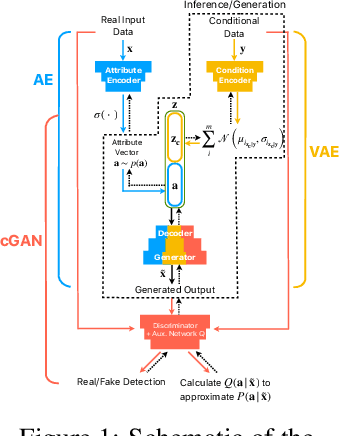
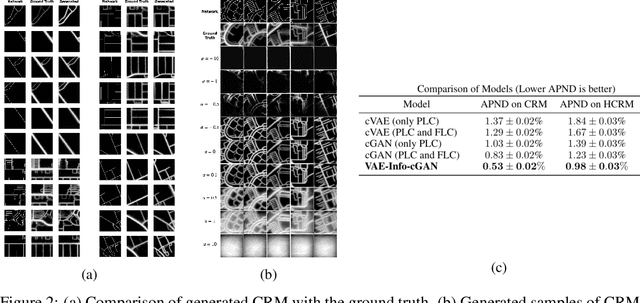
Training robust supervised deep learning models for many geospatial applications of computer vision is difficult due to dearth of class-balanced and diverse training data. Conversely, obtaining enough training data for many applications is financially prohibitive or may be infeasible, especially when the application involves modeling rare or extreme events. Synthetically generating data (and labels) using a generative model that can sample from a target distribution and exploit the multi-scale nature of images can be an inexpensive solution to address scarcity of labeled data. Towards this goal, we present a deep conditional generative model, called VAE-Info-cGAN, that combines a Variational Autoencoder (VAE) with a conditional Information Maximizing Generative Adversarial Network (InfoGAN), for synthesizing semantically rich images simultaneously conditioned on a pixel-level condition (PLC) and a macroscopic feature-level condition (FLC). Dimensionally, the PLC can only vary in the channel dimension from the synthesized image and is meant to be a task-specific input. The FLC is modeled as an attribute vector in the latent space of the generated image which controls the contributions of various characteristic attributes germane to the target distribution. Experiments on a GPS trajectories dataset show that the proposed model can accurately generate various forms of spatiotemporal aggregates across different geographic locations while conditioned only on a raster representation of the road network. The primary intended application of the VAE-Info-cGAN is synthetic data (and label) generation for targeted data augmentation for computer vision-based modeling of problems relevant to geospatial analysis and remote sensing.
Agriculture-Vision: A Large Aerial Image Database for Agricultural Pattern Analysis
Jan 05, 2020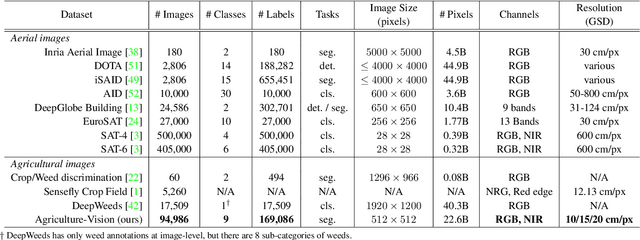


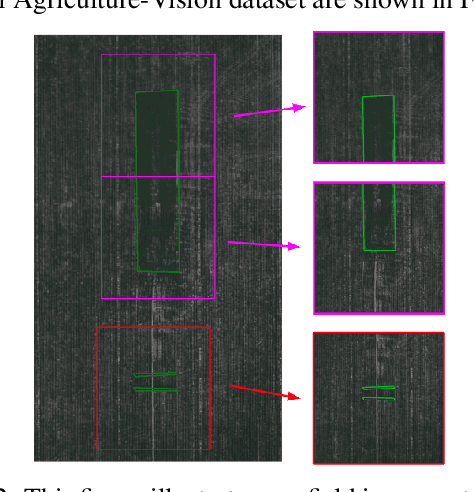
The success of deep learning in visual recognition tasks has driven advancements in multiple fields of research. Particularly, increasing attention has been drawn towards its application in agriculture. Nevertheless, while visual pattern recognition on farmlands carries enormous economic values, little progress has been made to merge computer vision and crop sciences due to the lack of suitable agricultural image datasets. Meanwhile, problems in agriculture also pose new challenges in computer vision. For example, semantic segmentation of aerial farmland images requires inference over extremely large-size images with extreme annotation sparsity. These challenges are not present in most of the common object datasets, and we show that they are more challenging than many other aerial image datasets. To encourage research in computer vision for agriculture, we present Agriculture-Vision: a large-scale aerial farmland image dataset for semantic segmentation of agricultural patterns. We collected 94,986 high-quality aerial images from 3,432 farmlands across the US, where each image consists of RGB and Near-infrared (NIR) channels with resolution as high as 10 cm per pixel. We annotate nine types of field anomaly patterns that are most important to farmers. As a pilot study of aerial agricultural semantic segmentation, we perform comprehensive experiments using popular semantic segmentation models; we also propose an effective model designed for aerial agricultural pattern recognition. Our experiments demonstrate several challenges Agriculture-Vision poses to both the computer vision and agriculture communities. Future versions of this dataset will include even more aerial images, anomaly patterns and image channels. More information at https://www.agriculture-vision.com.
StyleAugment: Learning Texture De-biased Representations by Style Augmentation without Pre-defined Textures
Aug 24, 2021
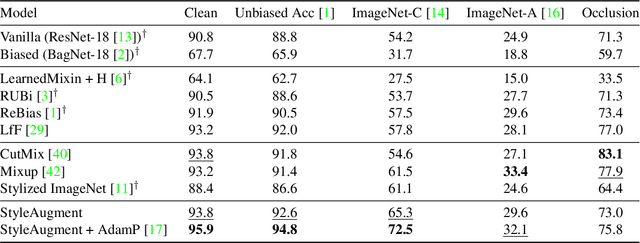


Recent powerful vision classifiers are biased towards textures, while shape information is overlooked by the models. A simple attempt by augmenting training images using the artistic style transfer method, called Stylized ImageNet, can reduce the texture bias. However, Stylized ImageNet approach has two drawbacks in fidelity and diversity. First, the generated images show low image quality due to the significant semantic gap betweeen natural images and artistic paintings. Also, Stylized ImageNet training samples are pre-computed before training, resulting in showing the lack of diversity for each sample. We propose a StyleAugment by augmenting styles from the mini-batch. StyleAugment does not rely on the pre-defined style references, but generates augmented images on-the-fly by natural images in the mini-batch for the references. Hence, StyleAugment let the model observe abundant confounding cues for each image by on-the-fly the augmentation strategy, while the augmented images are more realistic than artistic style transferred images. We validate the effectiveness of StyleAugment in the ImageNet dataset with robustness benchmarks, such as texture de-biased accuracy, corruption robustness, natural adversarial samples, and occlusion robustness. StyleAugment shows better generalization performances than previous unsupervised de-biasing methods and state-of-the-art data augmentation methods in our experiments.
Deep Convolutional Generative Modeling for Artificial Microstructure Development of Aluminum-Silicon Alloy
Sep 06, 2021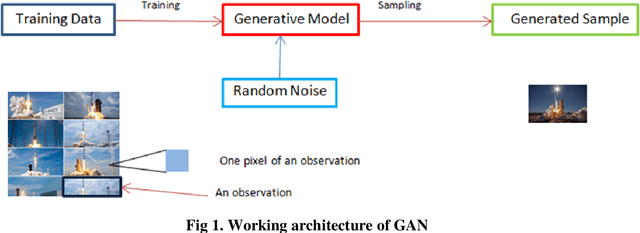
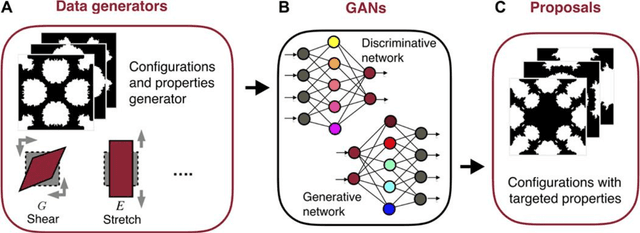

Machine learning which is a sub-domain of an Artificial Intelligence which is finding various applications in manufacturing and material science sectors. In the present study, Deep Generative Modeling which a type of unsupervised machine learning technique has been adapted for the constructing the artificial microstructure of Aluminium-Silicon alloy. Deep Generative Adversarial Networks has been used for developing the artificial microstructure of the given microstructure image dataset. The results obtained showed that the developed models had learnt to replicate the lining near the certain images of the microstructures.
Known Operator Learning and Hybrid Machine Learning in Medical Imaging --- A Review of the Past, the Present, and the Future
Aug 10, 2021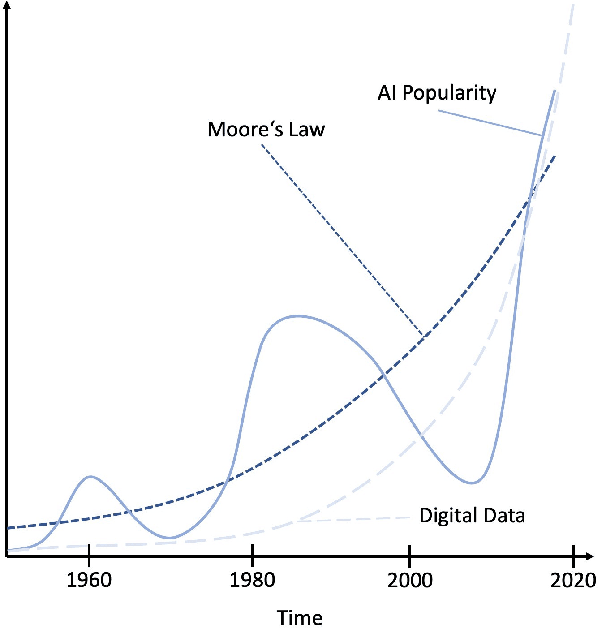
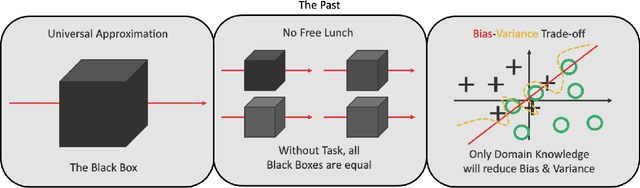
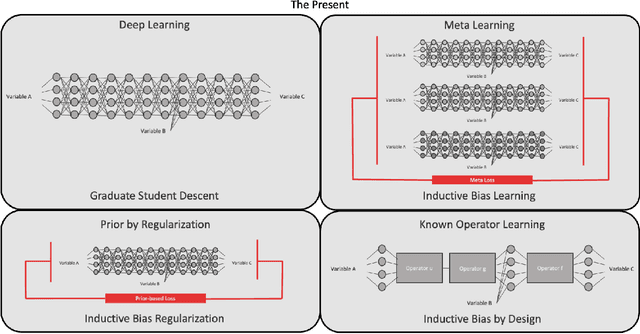
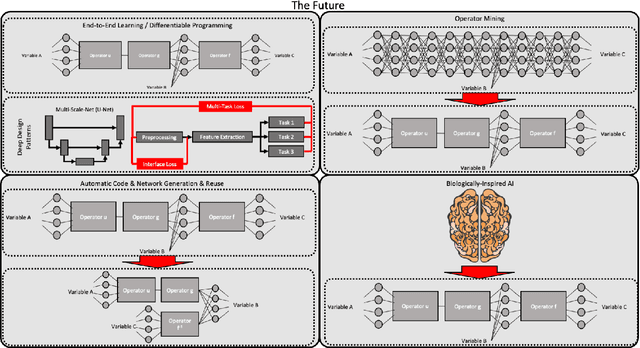
In this article, we perform a review of the state-of-the-art of hybrid machine learning in medical imaging. We start with a short summary of the general developments of the past in machine learning and how general and specialized approaches have been in competition in the past decades. A particular focus will be the theoretical and experimental evidence pro and contra hybrid modelling. Next, we inspect several new developments regarding hybrid machine learning with a particular focus on so-called known operator learning and how hybrid approaches gain more and more momentum across essentially all applications in medical imaging and medical image analysis. As we will point out by numerous examples, hybrid models are taking over in image reconstruction and analysis. Even domains such as physical simulation and scanner and acquisition design are being addressed using machine learning grey box modelling approaches. Towards the end of the article, we will investigate a few future directions and point out relevant areas in which hybrid modelling, meta learning, and other domains will likely be able to drive the state-of-the-art ahead.
DRÆM -- A discriminatively trained reconstruction embedding for surface anomaly detection
Aug 17, 2021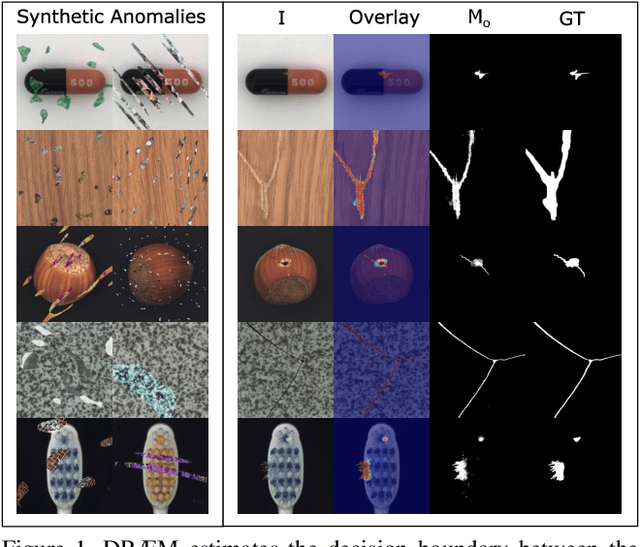
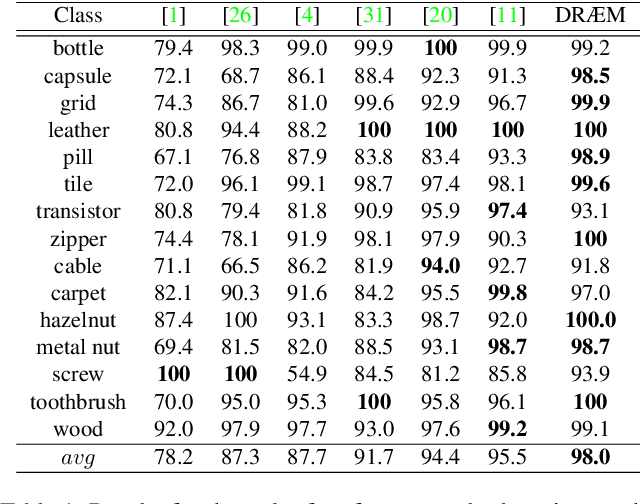
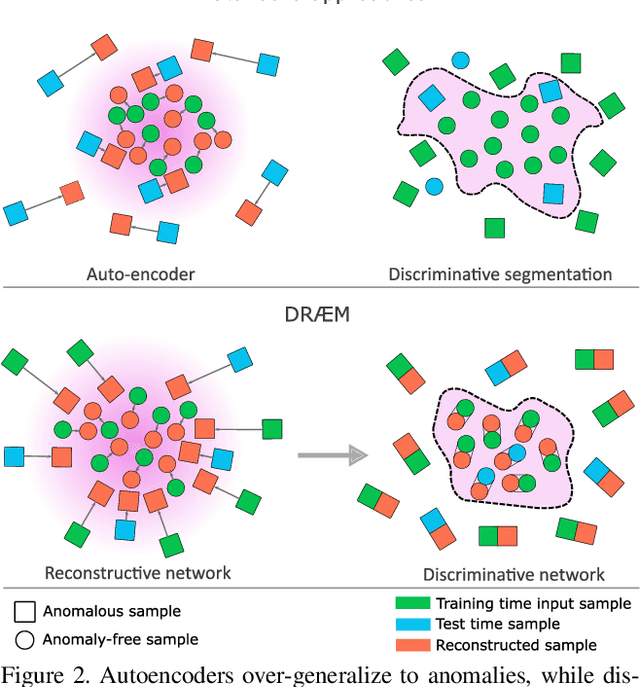
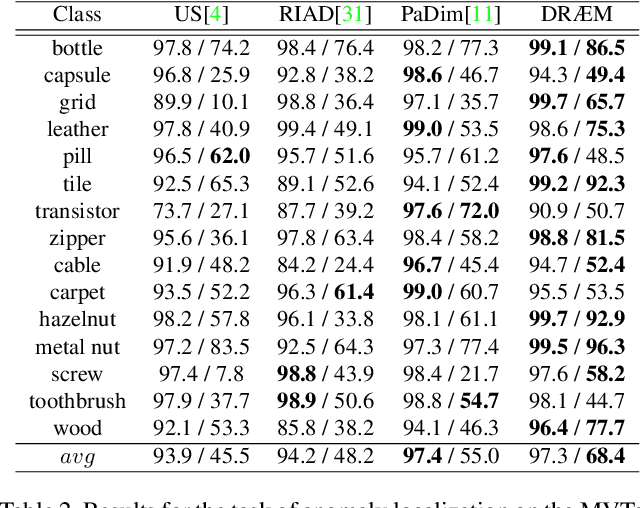
Visual surface anomaly detection aims to detect local image regions that significantly deviate from normal appearance. Recent surface anomaly detection methods rely on generative models to accurately reconstruct the normal areas and to fail on anomalies. These methods are trained only on anomaly-free images, and often require hand-crafted post-processing steps to localize the anomalies, which prohibits optimizing the feature extraction for maximal detection capability. In addition to reconstructive approach, we cast surface anomaly detection primarily as a discriminative problem and propose a discriminatively trained reconstruction anomaly embedding model (DRAEM). The proposed method learns a joint representation of an anomalous image and its anomaly-free reconstruction, while simultaneously learning a decision boundary between normal and anomalous examples. The method enables direct anomaly localization without the need for additional complicated post-processing of the network output and can be trained using simple and general anomaly simulations. On the challenging MVTec anomaly detection dataset, DRAEM outperforms the current state-of-the-art unsupervised methods by a large margin and even delivers detection performance close to the fully-supervised methods on the widely used DAGM surface-defect detection dataset, while substantially outperforming them in localization accuracy.
CAR-Net: Unsupervised Co-Attention Guided Registration Network for Joint Registration and Structure Learning
Jun 11, 2021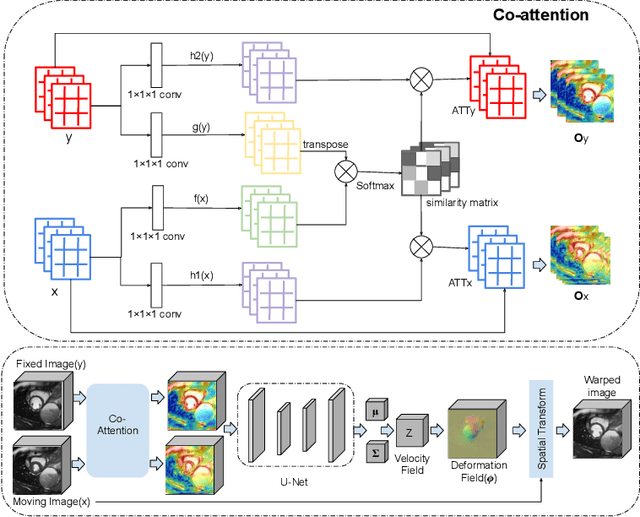
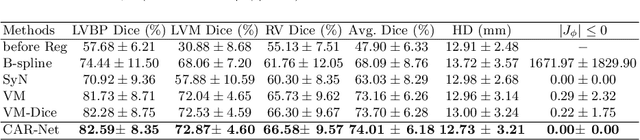
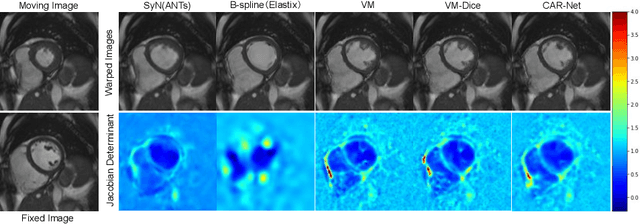
Image registration is a fundamental building block for various applications in medical image analysis. To better explore the correlation between the fixed and moving images and improve registration performance, we propose a novel deep learning network, Co-Attention guided Registration Network (CAR-Net). CAR-Net employs a co-attention block to learn a new representation of the inputs, which drives the registration of the fixed and moving images. Experiments on UK Biobank cardiac cine-magnetic resonance image data demonstrate that CAR-Net obtains higher registration accuracy and smoother deformation fields than state-of-the-art unsupervised registration methods, while achieving comparable or better registration performance than corresponding weakly-supervised variants. In addition, our approach can provide critical structural information of the input fixed and moving images simultaneously in a completely unsupervised manner.
IPG-Net: Image Pyramid Guidance Network for Object Detection
Dec 05, 2019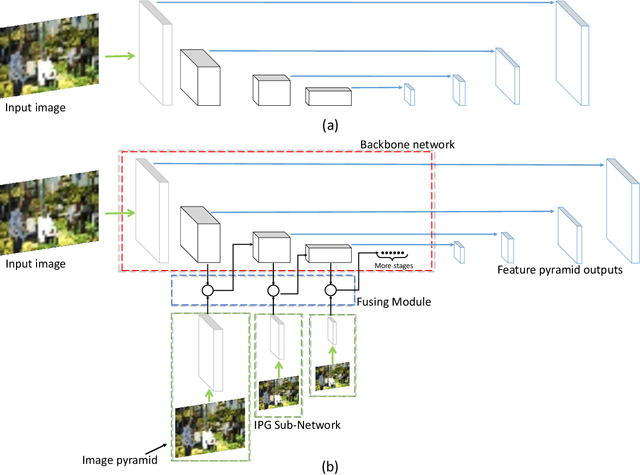
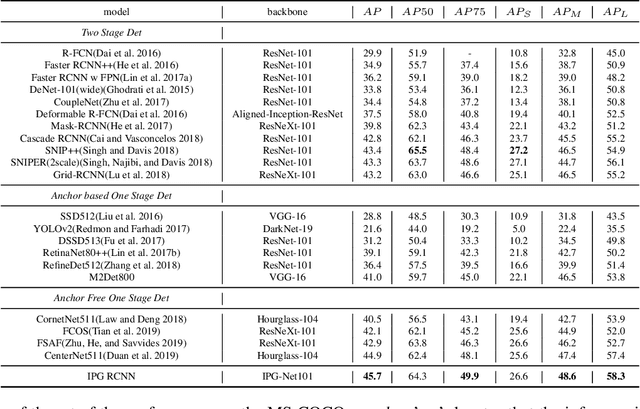
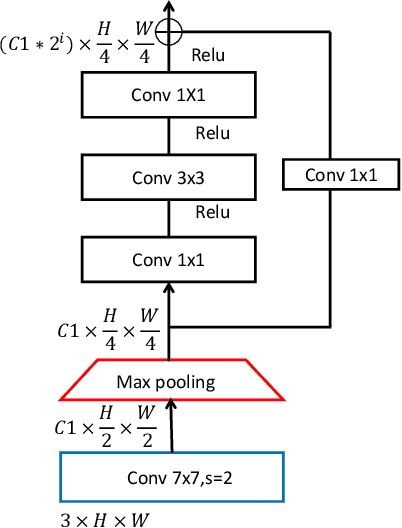
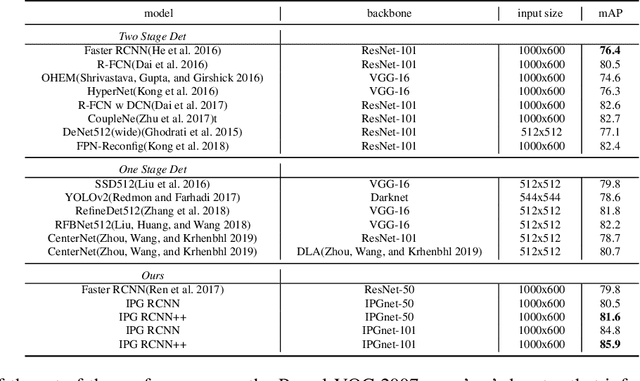
For Convolutional Neural Network based object detection, there is a typical dilemma: the spatial information is well kept in the shallow layers which unfortunately do not have enough semantic information, while the deep layers have high semantic concept but lost a lot of spatial information, resulting in serious information imbalance. To acquire enough semantic information for shallow layers, Feature Pyramid Networks (FPN) is used to build a top-down propagated path. In this paper, except for top-down combining of information for shallow layers, we propose a novel network called Image Pyramid Guidance Network(IPG-Net) to make sure both the spatial information and semantic information are abundant for each layer. Our IPG-Net has three main parts: the image pyramid guidance sub-network, the ResNet based backbone network and the fusing module. The image pyramid guidance sub-network supplies spatial information to each scale's feature to solve the information imbalance problem. This sub-network promise even in the deepest stage of the ResNet, there is enough spatial information for bounding box regression and classification. Furthermore, we designed an effective fusing module to fuse the features from the image pyramid and features from the feature pyramid. We have tried to apply this novel network to both one stage and two stage models, state of the art results are obtained on the most popular benchmark data sets, i.e. MS COCO and Pascal VOC.
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 13, 2021
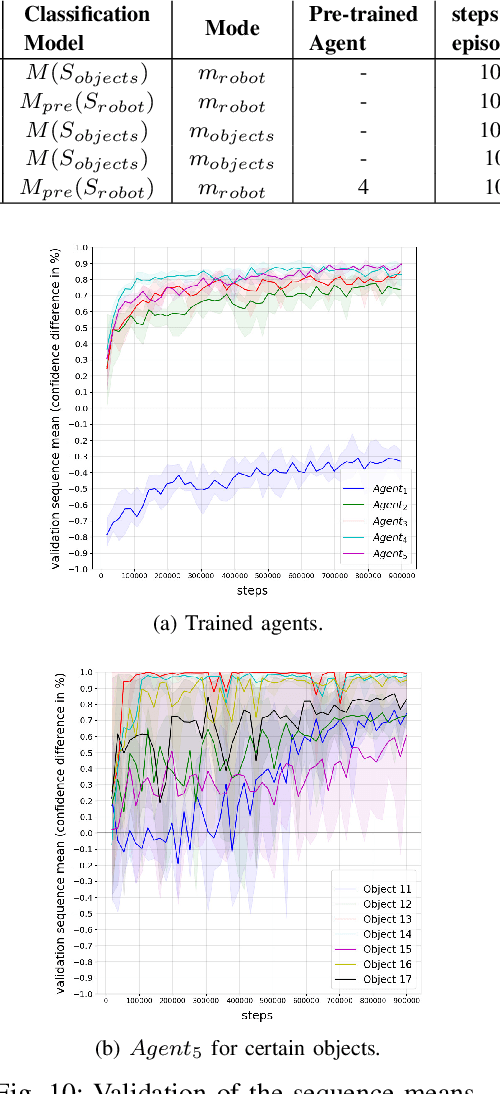
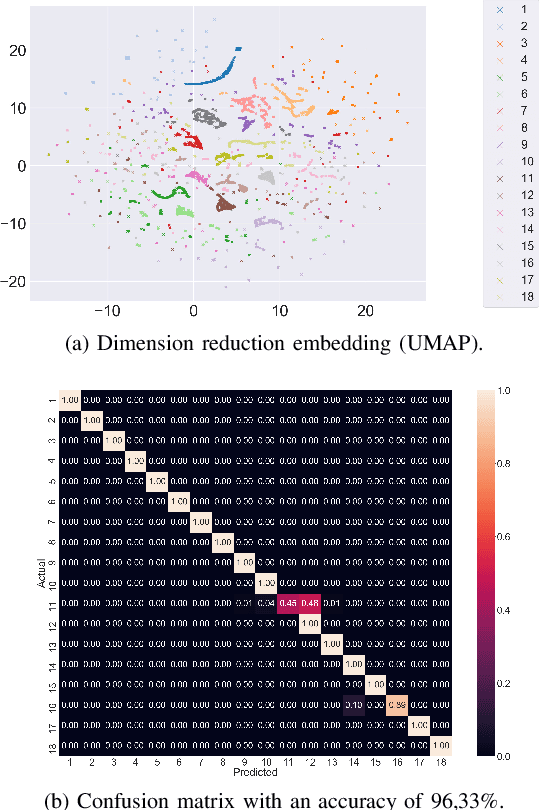
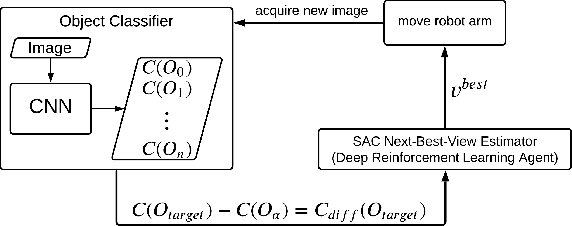
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The $\textit{next-best-view}$ problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility under $\href{https://github.com/ckorbach/nbv_rl}{\text{this https link}}$.
3D Human Shape Reconstruction from a Polarization Image
Jul 17, 2020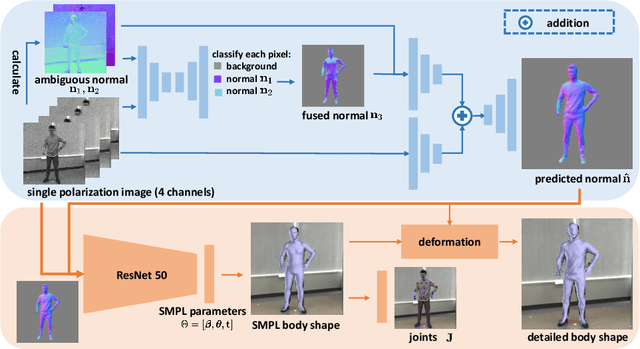
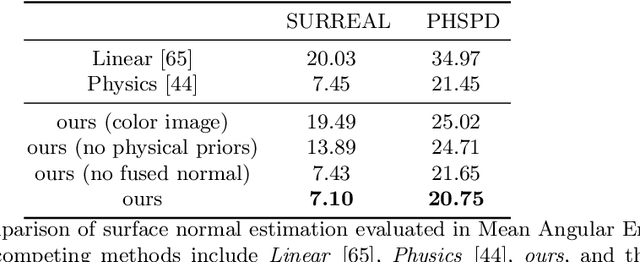


This paper tackles the problem of estimating 3D body shape of clothed humans from single polarized 2D images, i.e. polarization images. Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing surface normal of the objects of interest. Inspired by the recent advances in human shape estimation from single color images, in this paper, we attempt at estimating human body shapes by leveraging the geometric cues from single polarization images. A dedicated two-stage deep learning approach, SfP, is proposed: given a polarization image, stage one aims at inferring the fined-detailed body surface normal; stage two gears to reconstruct the 3D body shape of clothing details. Empirical evaluations on a synthetic dataset (SURREAL) as well as a real-world dataset (PHSPD) demonstrate the qualitative and quantitative performance of our approach in estimating human poses and shapes. This indicates polarization camera is a promising alternative to the more conventional color or depth imaging for human shape estimation. Further, normal maps inferred from polarization imaging play a significant role in accurately recovering the body shapes of clothed people.