 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 13, 2021
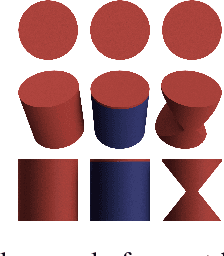
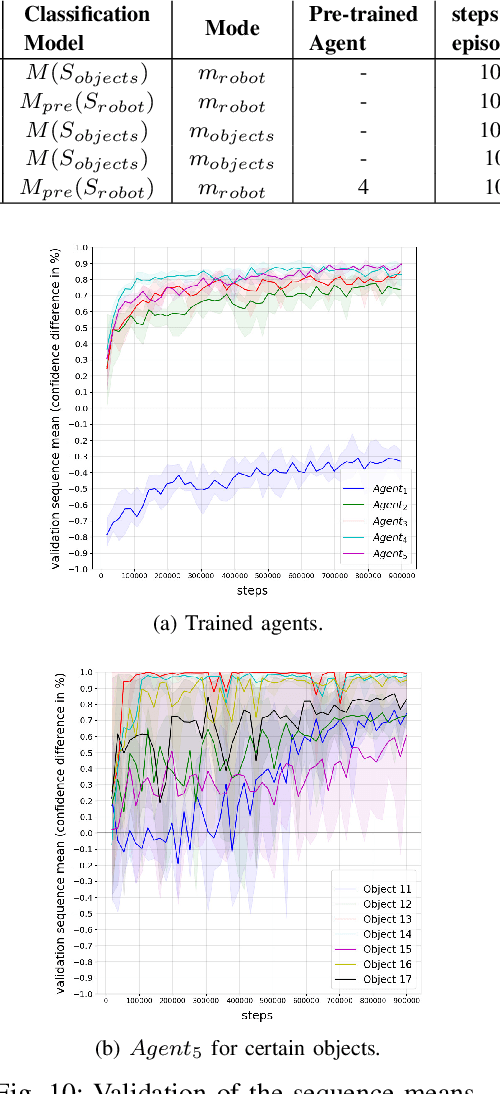
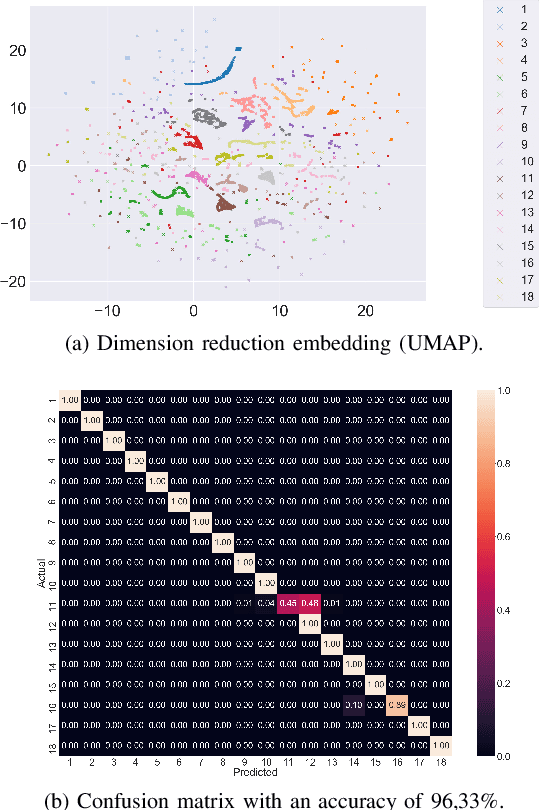
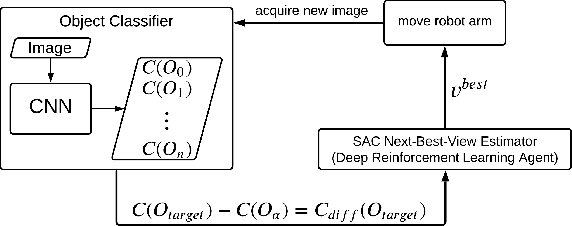
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The $\textit{next-best-view}$ problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility under $\href{https://github.com/ckorbach/nbv_rl}{\text{this https link}}$.
Conditional Generation of Synthetic Geospatial Images from Pixel-level and Feature-level Inputs
Sep 11, 2021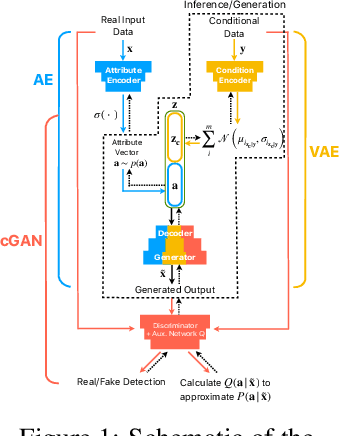
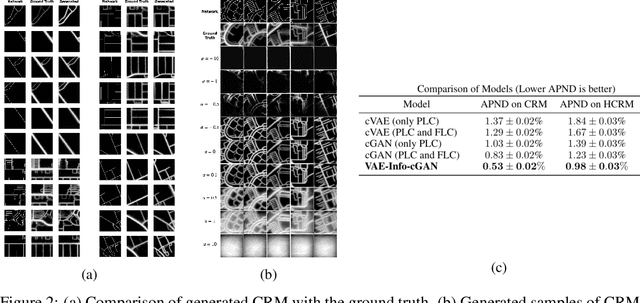
Training robust supervised deep learning models for many geospatial applications of computer vision is difficult due to dearth of class-balanced and diverse training data. Conversely, obtaining enough training data for many applications is financially prohibitive or may be infeasible, especially when the application involves modeling rare or extreme events. Synthetically generating data (and labels) using a generative model that can sample from a target distribution and exploit the multi-scale nature of images can be an inexpensive solution to address scarcity of labeled data. Towards this goal, we present a deep conditional generative model, called VAE-Info-cGAN, that combines a Variational Autoencoder (VAE) with a conditional Information Maximizing Generative Adversarial Network (InfoGAN), for synthesizing semantically rich images simultaneously conditioned on a pixel-level condition (PLC) and a macroscopic feature-level condition (FLC). Dimensionally, the PLC can only vary in the channel dimension from the synthesized image and is meant to be a task-specific input. The FLC is modeled as an attribute vector in the latent space of the generated image which controls the contributions of various characteristic attributes germane to the target distribution. Experiments on a GPS trajectories dataset show that the proposed model can accurately generate various forms of spatiotemporal aggregates across different geographic locations while conditioned only on a raster representation of the road network. The primary intended application of the VAE-Info-cGAN is synthetic data (and label) generation for targeted data augmentation for computer vision-based modeling of problems relevant to geospatial analysis and remote sensing.
BINet: a binary inpainting network for deep patch-based image compression
Dec 11, 2019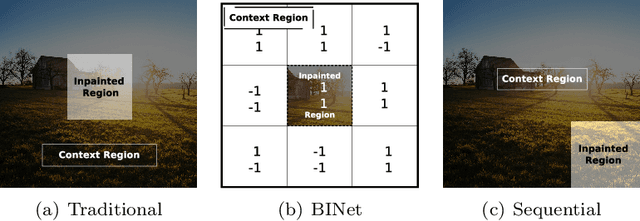

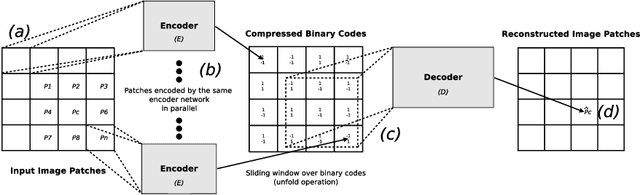

Recent deep learning models outperform standard lossy image compression codecs. However, applying these models on a patch-by-patch basis requires that each image patch be encoded and decoded independently. The influence from adjacent patches is therefore lost, leading to block artefacts at low bitrates. We propose the Binary Inpainting Network (BINet), an autoencoder framework which incorporates binary inpainting to reinstate interdependencies between adjacent patches, for improved patch-based compression of still images. When decoding a patch, BINet additionally uses the binarised encodings from surrounding patches to guide its reconstruction. In contrast to sequential inpainting methods where patches are decoded based on previons reconstructions, BINet operates directly on the binary codes of surrounding patches without access to the original or reconstructed image data. Encoding and decoding can therefore be performed in parallel. We demonstrate that BINet improves the compression quality of a competitive deep image codec across a range of compression levels.
Self-supervised Dynamic CT Perfusion Image Denoising with Deep Neural Networks
May 19, 2020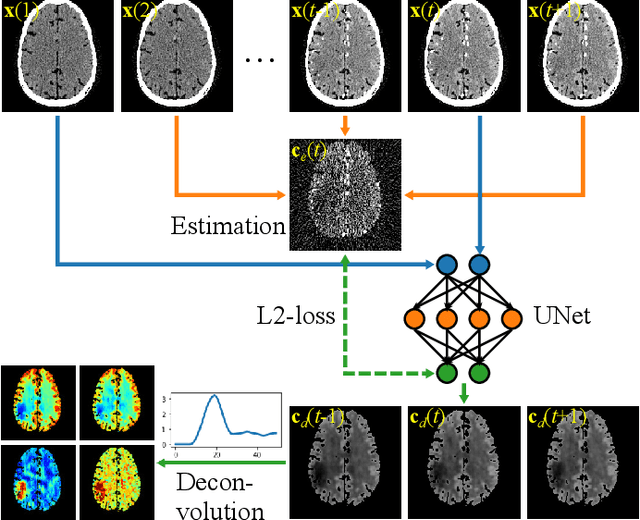
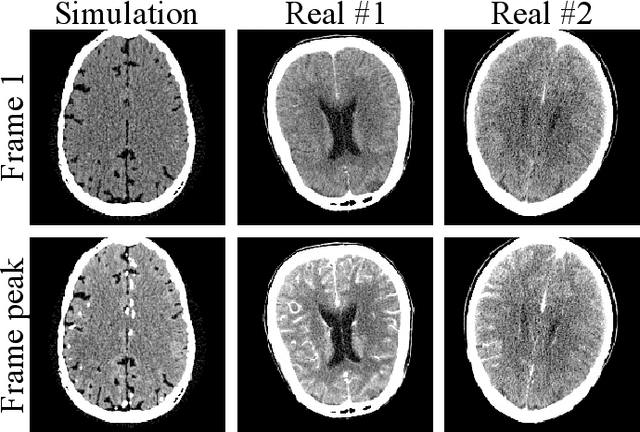
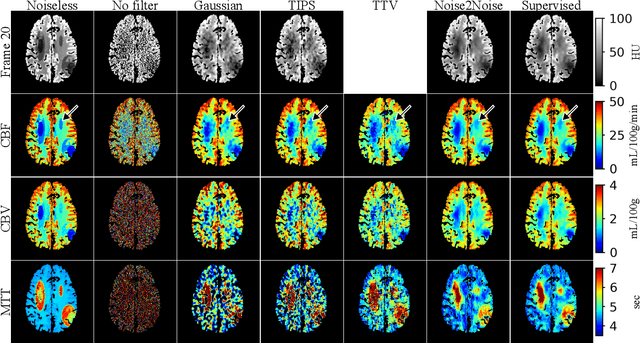
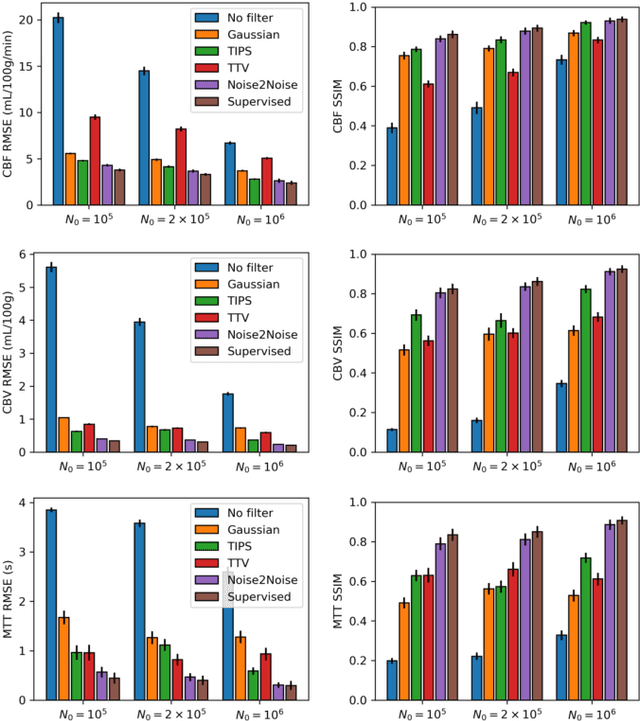
Dynamic computed tomography perfusion (CTP) imaging is a promising approach for acute ischemic stroke diagnosis and evaluation. Hemodynamic parametric maps of cerebral parenchyma are calculated from repeated CT scans of the first pass of iodinated contrast through the brain. It is necessary to reduce the dose of CTP for routine applications due to the high radiation exposure from the repeated scans, where image denoising is necessary to achieve a reliable diagnosis. In this paper, we proposed a self-supervised deep learning method for CTP denoising, which did not require any high-dose reference images for training. The network was trained by mapping each frame of CTP to an estimation from its adjacent frames. Because the noise in the source and target was independent, this approach could effectively remove the noise. Being free from high-dose training images granted the proposed method easier adaptation to different scanning protocols. The method was validated on both simulation and a public real dataset. The proposed method achieved improved image quality compared to conventional denoising methods. On the real data, the proposed method also had improved spatial resolution and contrast-to-noise ratio compared to supervised learning which was trained on the simulation data
Inferring the Class Conditional Response Map for Weakly Supervised Semantic Segmentation
Oct 27, 2021
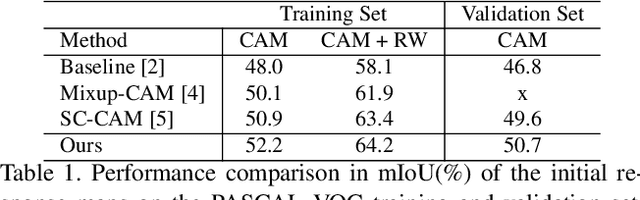

Image-level weakly supervised semantic segmentation (WSSS) relies on class activation maps (CAMs) for pseudo labels generation. As CAMs only highlight the most discriminative regions of objects, the generated pseudo labels are usually unsatisfactory to serve directly as supervision. To solve this, most existing approaches follow a multi-training pipeline to refine CAMs for better pseudo-labels, which includes: 1) re-training the classification model to generate CAMs; 2) post-processing CAMs to obtain pseudo labels; and 3) training a semantic segmentation model with the obtained pseudo labels. However, this multi-training pipeline requires complicated adjustment and additional time. To address this, we propose a class-conditional inference strategy and an activation aware mask refinement loss function to generate better pseudo labels without re-training the classifier. The class conditional inference-time approach is presented to separately and iteratively reveal the classification network's hidden object activation to generate more complete response maps. Further, our activation aware mask refinement loss function introduces a novel way to exploit saliency maps during segmentation training and refine the foreground object masks without suppressing background objects. Our method achieves superior WSSS results without requiring re-training of the classifier.
A model of semantic completion in generative episodic memory
Nov 26, 2021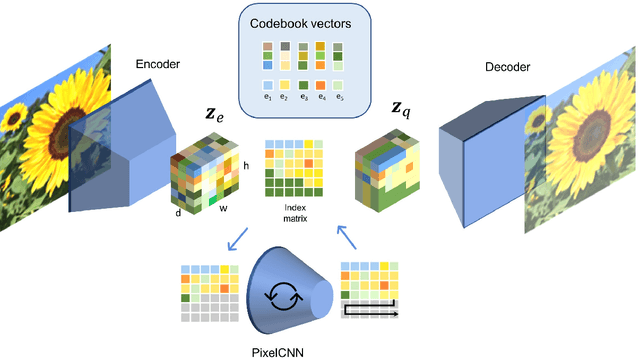
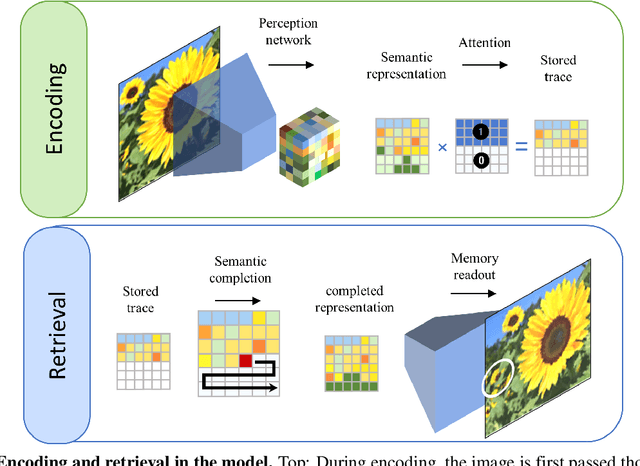
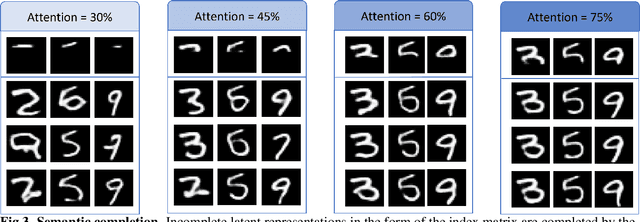
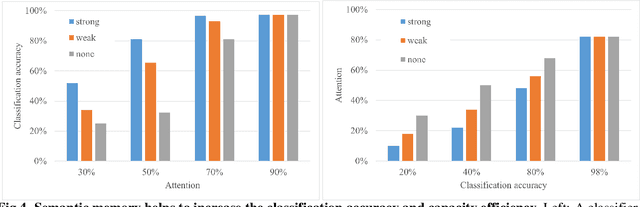
Many different studies have suggested that episodic memory is a generative process, but most computational models adopt a storage view. In this work, we propose a computational model for generative episodic memory. It is based on the central hypothesis that the hippocampus stores and retrieves selected aspects of an episode as a memory trace, which is necessarily incomplete. At recall, the neocortex reasonably fills in the missing information based on general semantic information in a process we call semantic completion. As episodes we use images of digits (MNIST) augmented by different backgrounds representing context. Our model is based on a VQ-VAE which generates a compressed latent representation in form of an index matrix, which still has some spatial resolution. We assume that attention selects some part of the index matrix while others are discarded, this then represents the gist of the episode and is stored as a memory trace. At recall the missing parts are filled in by a PixelCNN, modeling semantic completion, and the completed index matrix is then decoded into a full image by the VQ-VAE. The model is able to complete missing parts of a memory trace in a semantically plausible way up to the point where it can generate plausible images from scratch. Due to the combinatorics in the index matrix, the model generalizes well to images not trained on. Compression as well as semantic completion contribute to a strong reduction in memory requirements and robustness to noise. Finally we also model an episodic memory experiment and can reproduce that semantically congruent contexts are always recalled better than incongruent ones, high attention levels improve memory accuracy in both cases, and contexts that are not remembered correctly are more often remembered semantically congruently than completely wrong.
Per-Pixel Lung Thickness and Lung Capacity Estimation on Chest X-Rays using Convolutional Neural Networks
Oct 27, 2021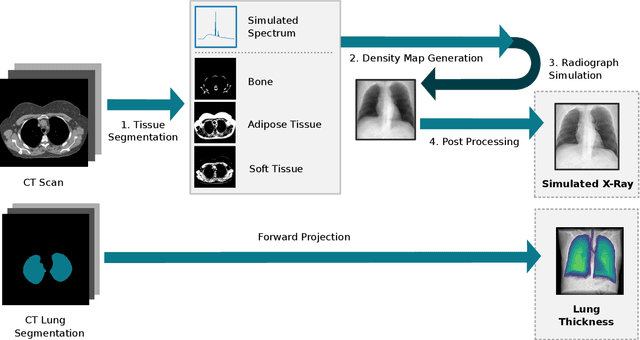
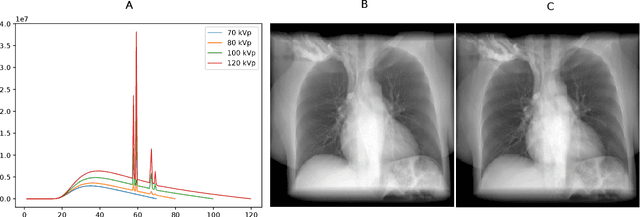
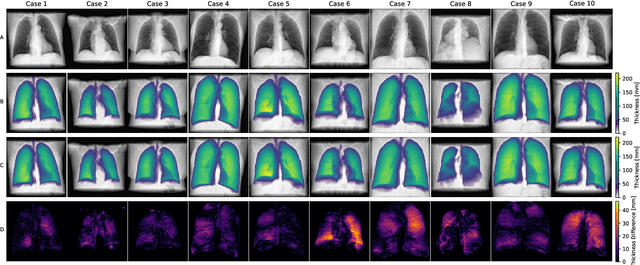
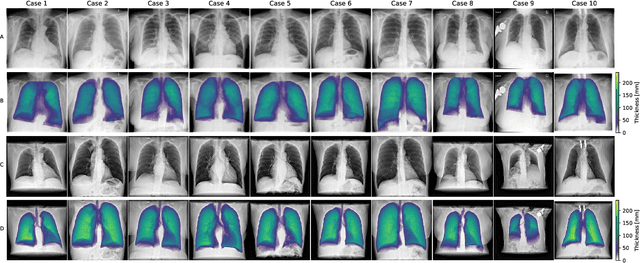
Estimating the lung depth on x-ray images could provide both an accurate opportunistic lung volume estimation during clinical routine and improve image contrast in modern structural chest imaging techniques like x-ray dark-field imaging. We present a method based on a convolutional neural network that allows a per-pixel lung thickness estimation and subsequent total lung capacity estimation. The network was trained and validated using 5250 simulated radiographs generated from 525 real CT scans. Furthermore, we are able to infer the model trained with simulation data on real radiographs. For 35 patients, quantitative and qualitative evaluation was performed on standard clinical radiographs. The ground-truth for each patient's total lung volume was defined based on the patients' corresponding CT scan. The mean-absolute error between the estimated lung volume on the 35 real radiographs and groundtruth volume was 0.73 liter. Additionally, we predicted the lung thicknesses on a synthetic dataset of 131 radiographs, where the mean-absolute error was 0.27 liter. The results show, that it is possible to transfer the knowledge obtained in a simulation model to real x-ray images.
Split then Refine: Stacked Attention-guided ResUNets for Blind Single Image Visible Watermark Removal
Dec 13, 2020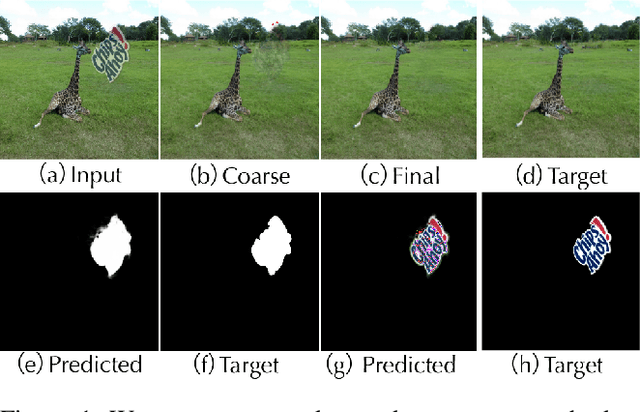
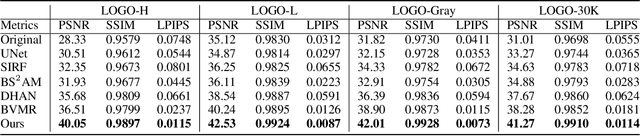
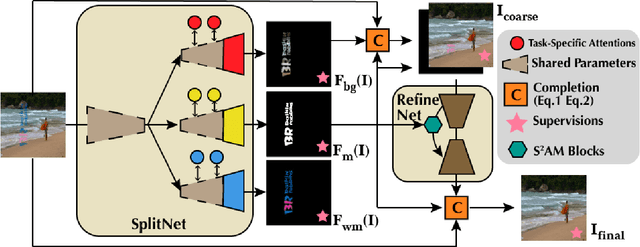

Digital watermark is a commonly used technique to protect the copyright of medias. Simultaneously, to increase the robustness of watermark, attacking technique, such as watermark removal, also gets the attention from the community. Previous watermark removal methods require to gain the watermark location from users or train a multi-task network to recover the background indiscriminately. However, when jointly learning, the network performs better on watermark detection than recovering the texture. Inspired by this observation and to erase the visible watermarks blindly, we propose a novel two-stage framework with a stacked attention-guided ResUNets to simulate the process of detection, removal and refinement. In the first stage, we design a multi-task network called SplitNet. It learns the basis features for three sub-tasks altogether while the task-specific features separately use multiple channel attentions. Then, with the predicted mask and coarser restored image, we design RefineNet to smooth the watermarked region with a mask-guided spatial attention. Besides network structure, the proposed algorithm also combines multiple perceptual losses for better quality both visually and numerically. We extensively evaluate our algorithm over four different datasets under various settings and the experiments show that our approach outperforms other state-of-the-art methods by a large margin. The code is available at http://github.com/vinthony/deep-blind-watermark-removal.
3D Human Shape Reconstruction from a Polarization Image
Jul 17, 2020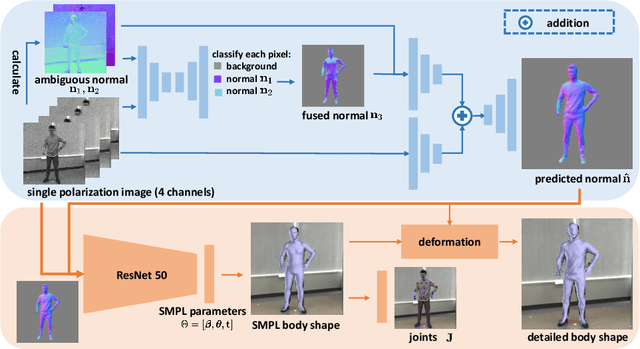
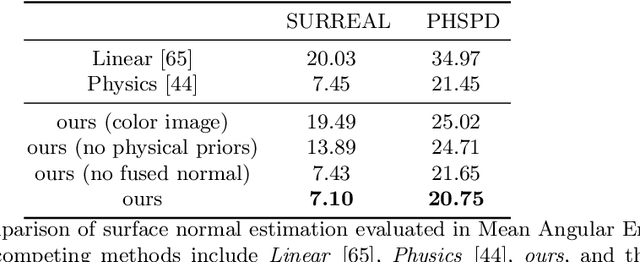


This paper tackles the problem of estimating 3D body shape of clothed humans from single polarized 2D images, i.e. polarization images. Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing surface normal of the objects of interest. Inspired by the recent advances in human shape estimation from single color images, in this paper, we attempt at estimating human body shapes by leveraging the geometric cues from single polarization images. A dedicated two-stage deep learning approach, SfP, is proposed: given a polarization image, stage one aims at inferring the fined-detailed body surface normal; stage two gears to reconstruct the 3D body shape of clothing details. Empirical evaluations on a synthetic dataset (SURREAL) as well as a real-world dataset (PHSPD) demonstrate the qualitative and quantitative performance of our approach in estimating human poses and shapes. This indicates polarization camera is a promising alternative to the more conventional color or depth imaging for human shape estimation. Further, normal maps inferred from polarization imaging play a significant role in accurately recovering the body shapes of clothed people.
StyleAugment: Learning Texture De-biased Representations by Style Augmentation without Pre-defined Textures
Aug 24, 2021
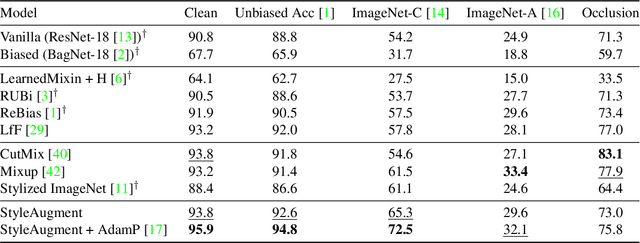


Recent powerful vision classifiers are biased towards textures, while shape information is overlooked by the models. A simple attempt by augmenting training images using the artistic style transfer method, called Stylized ImageNet, can reduce the texture bias. However, Stylized ImageNet approach has two drawbacks in fidelity and diversity. First, the generated images show low image quality due to the significant semantic gap betweeen natural images and artistic paintings. Also, Stylized ImageNet training samples are pre-computed before training, resulting in showing the lack of diversity for each sample. We propose a StyleAugment by augmenting styles from the mini-batch. StyleAugment does not rely on the pre-defined style references, but generates augmented images on-the-fly by natural images in the mini-batch for the references. Hence, StyleAugment let the model observe abundant confounding cues for each image by on-the-fly the augmentation strategy, while the augmented images are more realistic than artistic style transferred images. We validate the effectiveness of StyleAugment in the ImageNet dataset with robustness benchmarks, such as texture de-biased accuracy, corruption robustness, natural adversarial samples, and occlusion robustness. StyleAugment shows better generalization performances than previous unsupervised de-biasing methods and state-of-the-art data augmentation methods in our experiments.