 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VISIR: Visual and Semantic Image Label Refinement
Sep 02, 2019


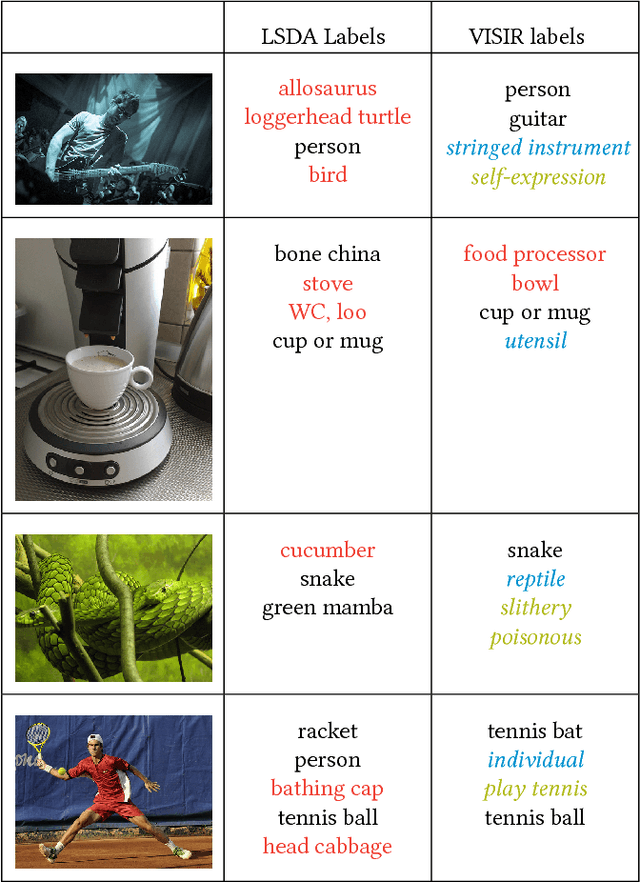
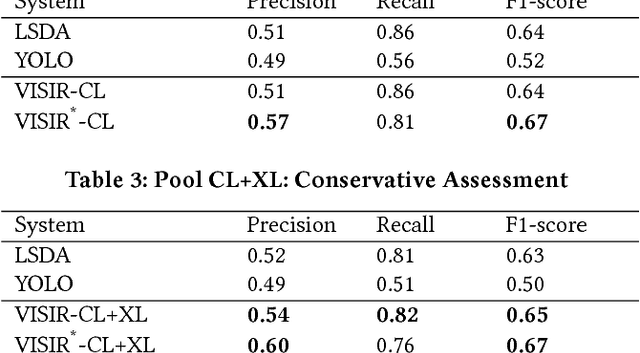
The social media explosion has populated the Internet with a wealth of images. There are two existing paradigms for image retrieval: 1) content-based image retrieval (CBIR), which has traditionally used visual features for similarity search (e.g., SIFT features), and 2) tag-based image retrieval (TBIR), which has relied on user tagging (e.g., Flickr tags). CBIR now gains semantic expressiveness by advances in deep-learning-based detection of visual labels. TBIR benefits from query-and-click logs to automatically infer more informative labels. However, learning-based tagging still yields noisy labels and is restricted to concrete objects, missing out on generalizations and abstractions. Click-based tagging is limited to terms that appear in the textual context of an image or in queries that lead to a click. This paper addresses the above limitations by semantically refining and expanding the labels suggested by learning-based object detection. We consider the semantic coherence between the labels for different objects, leverage lexical and commonsense knowledge, and cast the label assignment into a constrained optimization problem solved by an integer linear program. Experiments show that our method, called VISIR, improves the quality of the state-of-the-art visual labeling tools like LSDA and YOLO.
* Published in WSDM 2018
Kinship Verification Based on Cross-Generation Feature Interaction Learning
Sep 07, 2021
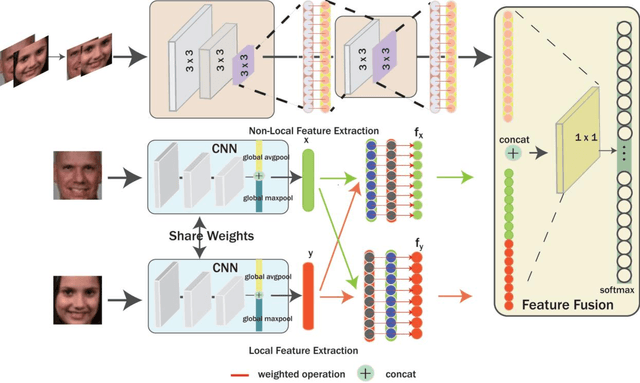
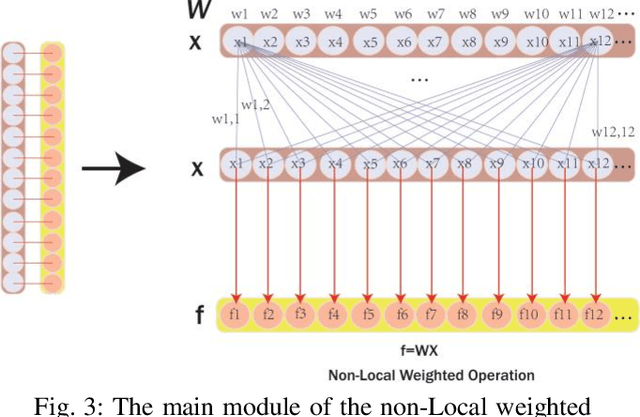
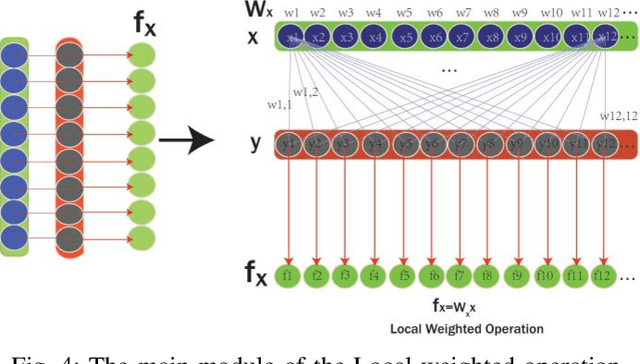
Kinship verification from facial images has been recognized as an emerging yet challenging technique in many potential computer vision applications. In this paper, we propose a novel cross-generation feature interaction learning (CFIL) framework for robust kinship verification. Particularly, an effective collaborative weighting strategy is constructed to explore the characteristics of cross-generation relations by corporately extracting features of both parents and children image pairs. Specifically, we take parents and children as a whole to extract the expressive local and non-local features. Different from the traditional works measuring similarity by distance, we interpolate the similarity calculations as the interior auxiliary weights into the deep CNN architecture to learn the whole and natural features. These similarity weights not only involve corresponding single points but also excavate the multiple relationships cross points, where local and non-local features are calculated by using these two kinds of distance measurements. Importantly, instead of separately conducting similarity computation and feature extraction, we integrate similarity learning and feature extraction into one unified learning process. The integrated representations deduced from local and non-local features can comprehensively express the informative semantics embedded in images and preserve abundant correlation knowledge from image pairs. Extensive experiments demonstrate the efficiency and superiority of the proposed model compared to some state-of-the-art kinship verification methods.
TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions
Nov 29, 2021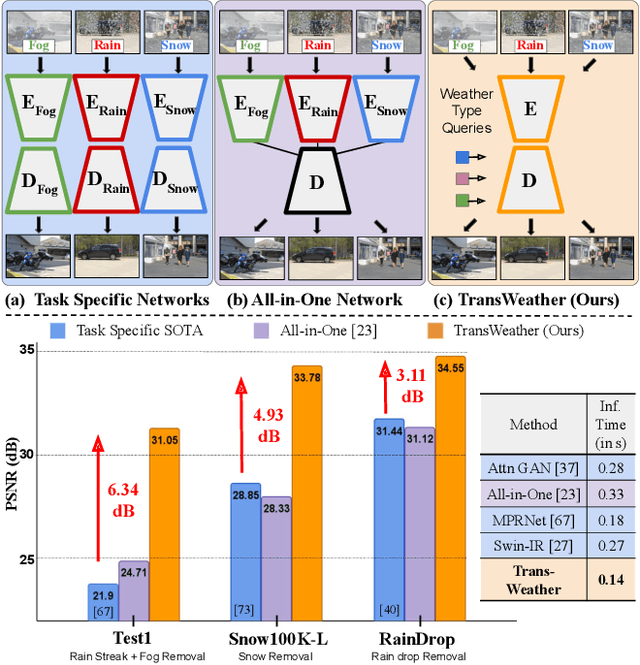
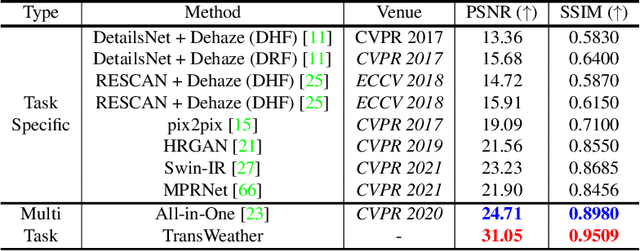
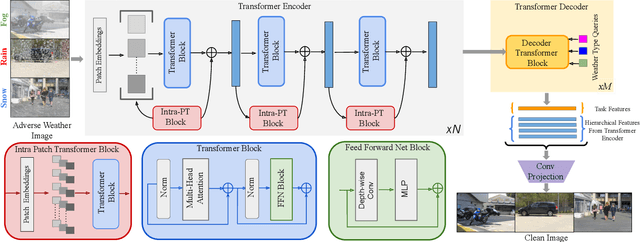
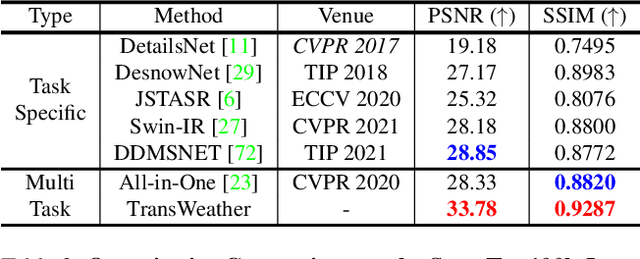
Removing adverse weather conditions like rain, fog, and snow from images is an important problem in many applications. Most methods proposed in the literature have been designed to deal with just removing one type of degradation. Recently, a CNN-based method using neural architecture search (All-in-One) was proposed to remove all the weather conditions at once. However, it has a large number of parameters as it uses multiple encoders to cater to each weather removal task and still has scope for improvement in its performance. In this work, we focus on developing an efficient solution for the all adverse weather removal problem. To this end, we propose TransWeather, a transformer-based end-to-end model with just a single encoder and a decoder that can restore an image degraded by any weather condition. Specifically, we utilize a novel transformer encoder using intra-patch transformer blocks to enhance attention inside the patches to effectively remove smaller weather degradations. We also introduce a transformer decoder with learnable weather type embeddings to adjust to the weather degradation at hand. TransWeather achieves significant improvements across multiple test datasets over both All-in-One network as well as methods fine-tuned for specific tasks. In particular, TransWeather pushes the current state-of-the-art by +6.34 PSNR on the Test1 (rain+fog) dataset, +4.93 PSNR on the SnowTest100K-L dataset and +3.11 PSNR on the RainDrop test dataset. TransWeather is also validated on real world test images and found to be more effective than previous methods. Implementation code and pre-trained weights can be accessed at https://github.com/jeya-maria-jose/TransWeather .
Unpaired Image Captioning via Scene Graph Alignments
Apr 04, 2019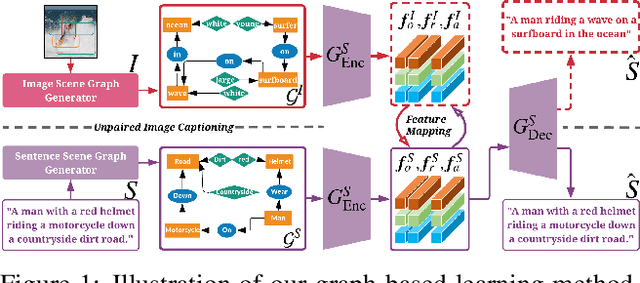
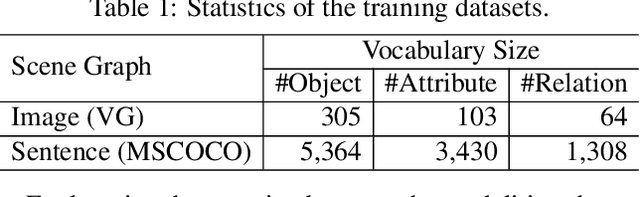
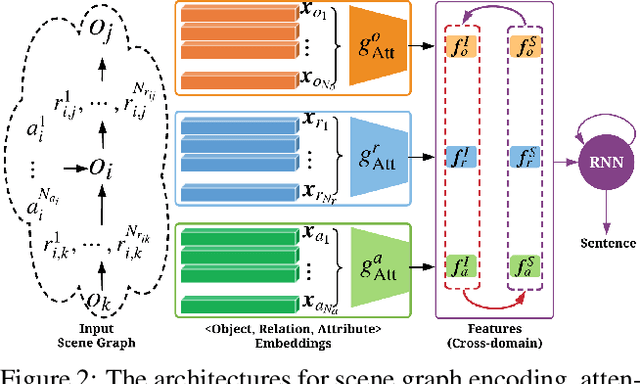
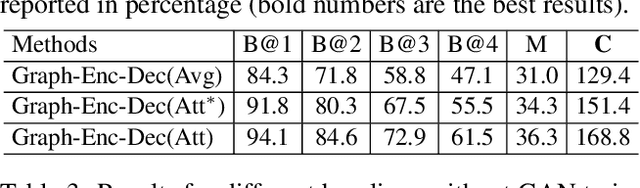
Most of the existing deep learning based image captioning methods are fully-supervised models, which require large-scale paired image-caption datasets. However, getting large scale image-caption paired data is labor-intensive and time-consuming. In this paper, we present a scene graph based approach for unpaired image captioning. Our framework comprises an image scene graph generator, a sentence scene graph generator, a scene graph encoder, and a sentence decoder. Specifically, we first train the scene graph encoder and the sentence decoder on the text modality. To align the scene graphs between images and sentences, we propose an unsupervised feature alignment method that maps the scene graph features from the image modality to the sentence modality without any paired data. Experimental results show that our proposed model can generate quite promising results without using any image-caption training pairs, outperforming existing methods by a wide margin.
Adaptive Convolutions with Per-pixel Dynamic Filter Atom
Aug 17, 2021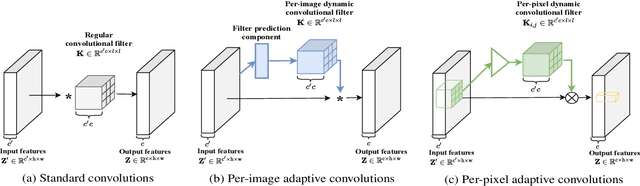

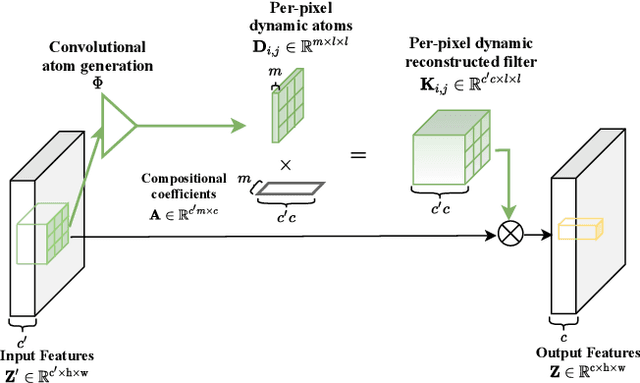

Applying feature dependent network weights have been proved to be effective in many fields. However, in practice, restricted by the enormous size of model parameters and memory footprints, scalable and versatile dynamic convolutions with per-pixel adapted filters are yet to be fully explored. In this paper, we address this challenge by decomposing filters, adapted to each spatial position, over dynamic filter atoms generated by a light-weight network from local features. Adaptive receptive fields can be supported by further representing each filter atom over sets of pre-fixed multi-scale bases. As plug-and-play replacements to convolutional layers, the introduced adaptive convolutions with per-pixel dynamic atoms enable explicit modeling of intra-image variance, while avoiding heavy computation, parameters, and memory cost. Our method preserves the appealing properties of conventional convolutions as being translation-equivariant and parametrically efficient. We present experiments to show that, the proposed method delivers comparable or even better performance across tasks, and are particularly effective on handling tasks with significant intra-image variance.
Leveraging Auxiliary Tasks with Affinity Learning for Weakly Supervised Semantic Segmentation
Jul 27, 2021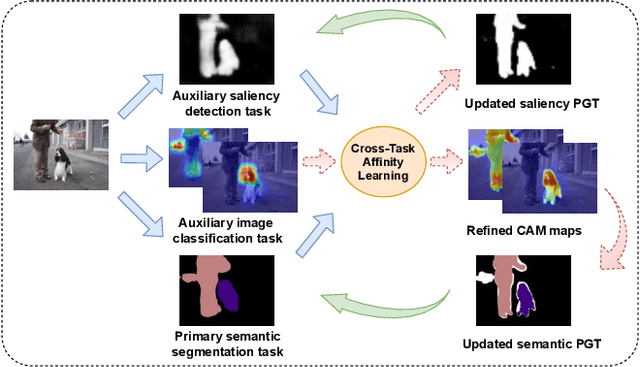
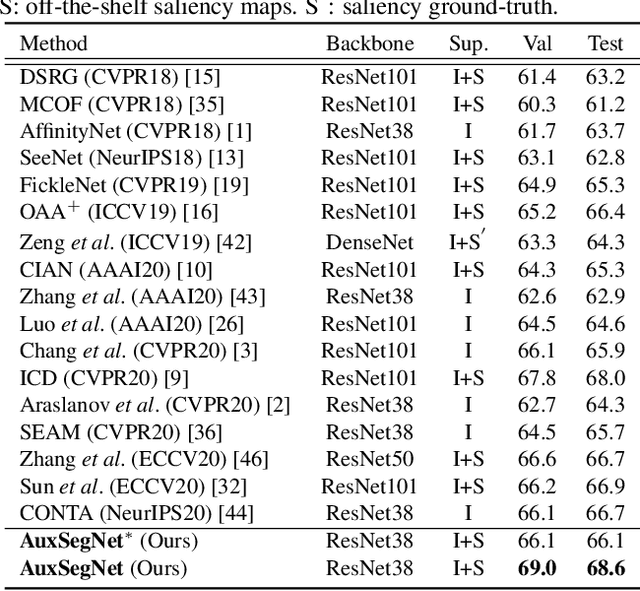
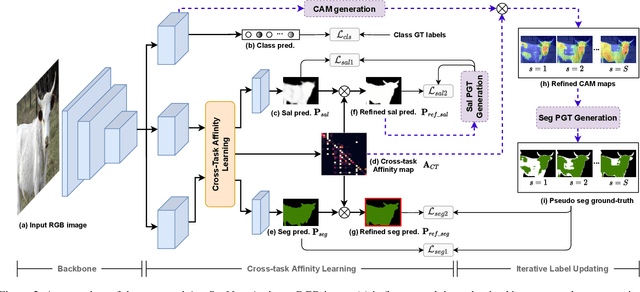

Semantic segmentation is a challenging task in the absence of densely labelled data. Only relying on class activation maps (CAM) with image-level labels provides deficient segmentation supervision. Prior works thus consider pre-trained models to produce coarse saliency maps to guide the generation of pseudo segmentation labels. However, the commonly used off-line heuristic generation process cannot fully exploit the benefits of these coarse saliency maps. Motivated by the significant inter-task correlation, we propose a novel weakly supervised multi-task framework termed as AuxSegNet, to leverage saliency detection and multi-label image classification as auxiliary tasks to improve the primary task of semantic segmentation using only image-level ground-truth labels. Inspired by their similar structured semantics, we also propose to learn a cross-task global pixel-level affinity map from the saliency and segmentation representations. The learned cross-task affinity can be used to refine saliency predictions and propagate CAM maps to provide improved pseudo labels for both tasks. The mutual boost between pseudo label updating and cross-task affinity learning enables iterative improvements on segmentation performance. Extensive experiments demonstrate the effectiveness of the proposed auxiliary learning network structure and the cross-task affinity learning method. The proposed approach achieves state-of-the-art weakly supervised segmentation performance on the challenging PASCAL VOC 2012 and MS COCO benchmarks.
LULC Segmentation of RGB Satellite Image Using FCN-8
Aug 24, 2020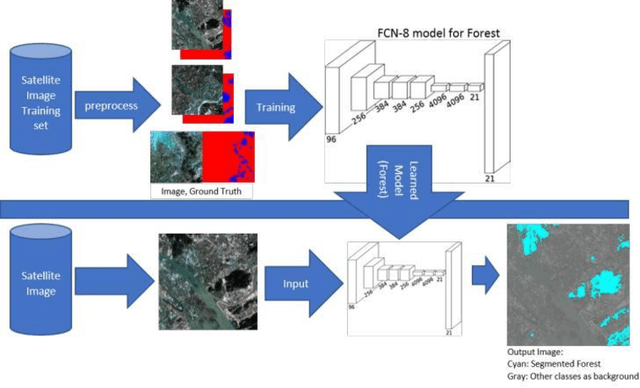


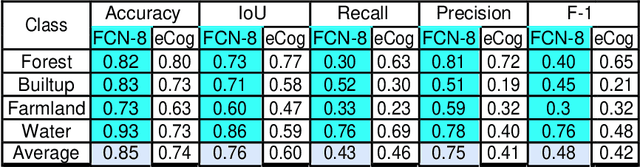
This work presents use of Fully Convolutional Network (FCN-8) for semantic segmentation of high-resolution RGB earth surface satel-lite images into land use land cover (LULC) categories. Specically, we propose a non-overlapping grid-based approach to train a Fully Convo-lutional Network (FCN-8) with vgg-16 weights to segment satellite im-ages into four (forest, built-up, farmland and water) classes. The FCN-8 semantically projects the discriminating features in lower resolution learned by the encoder onto the pixel space in higher resolution to get a dense classi cation. We experimented the proposed system with Gaofen-2 image dataset, that contains 150 images of over 60 di erent cities in china. For comparison, we used available ground-truth along with images segmented using a widely used commeriial GIS software called eCogni-tion. With the proposed non-overlapping grid-based approach, FCN-8 obtains signi cantly improved performance, than the eCognition soft-ware. Our model achieves average accuracy of 91.0% and average Inter-section over Union (IoU) of 0.84. In contrast, eCognitions average accu-racy is 74.0% and IoU is 0.60. This paper also reports a detail analysis of errors occurred at the LULC boundary.
Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
Nov 15, 2021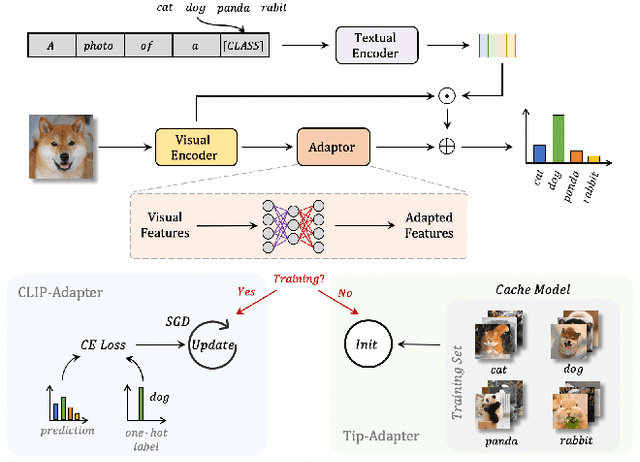

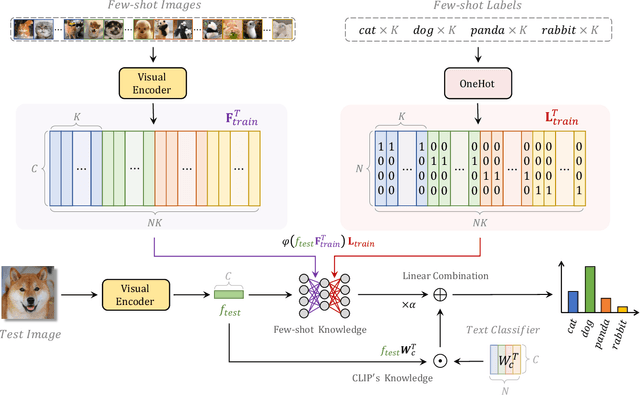

Contrastive Vision-Language Pre-training, known as CLIP, has provided a new paradigm for learning visual representations by using large-scale contrastive image-text pairs. It shows impressive performance on zero-shot knowledge transfer to downstream tasks. To further enhance CLIP's few-shot capability, CLIP-Adapter proposed to fine-tune a lightweight residual feature adapter and significantly improves the performance for few-shot classification. However, such a process still needs extra training and computational resources. In this paper, we propose \textbf{T}raining-Free CL\textbf{IP}-\textbf{Adapter} (\textbf{Tip-Adapter}), which not only inherits CLIP's training-free advantage but also performs comparably or even better than CLIP-Adapter. Tip-Adapter does not require any back propagation for training the adapter, but creates the weights by a key-value cache model constructed from the few-shot training set. In this non-parametric manner, Tip-Adapter acquires well-performed adapter weights without any training, which is both efficient and effective. Moreover, the performance of Tip-Adapter can be further boosted by fine-tuning such properly initialized adapter for only a few epochs with super-fast convergence speed. We conduct extensive experiments of few-shot classification on ImageNet and other 10 datasets to demonstrate the superiority of proposed Tip-Adapter. The code will be released at \url{https://github.com/gaopengcuhk/Tip-Adapter}.
Support Vector Machine for Handwritten Character Recognition
Sep 07, 2021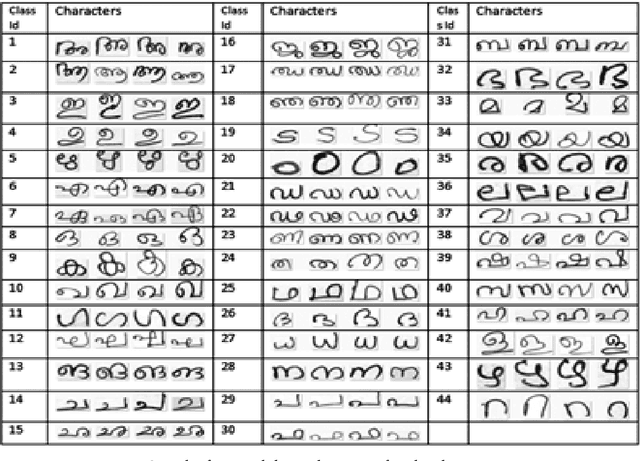
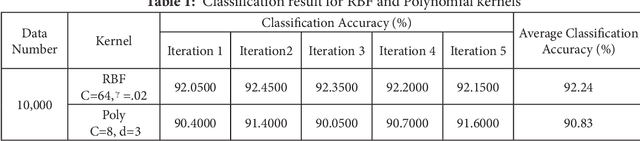
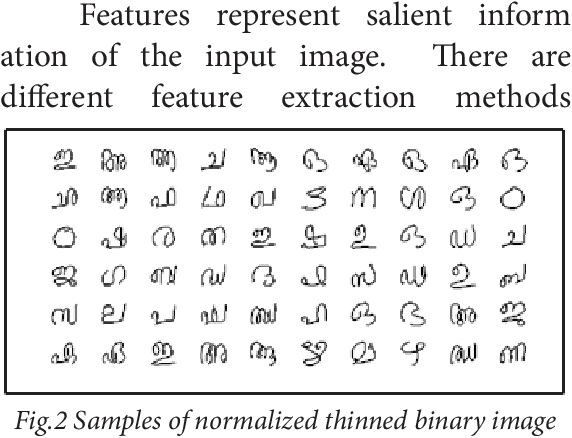
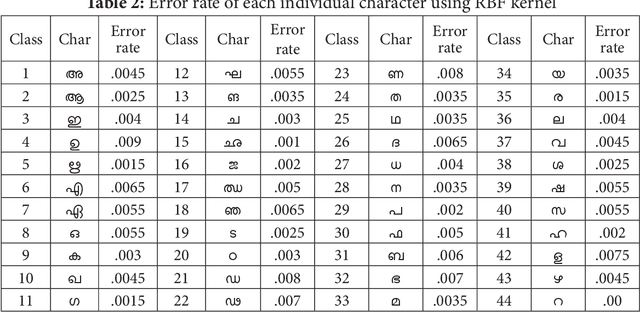
Handwriting recognition has been one of the most fascinating and challenging research areas in field of image processing and pattern recognition. It contributes enormously to the improvement of automation process. In this paper, a system for recognition of unconstrained handwritten Malayalam characters is proposed. A database of 10,000 character samples of 44 basic Malayalam characters is used in this work. A discriminate feature set of 64 local and 4 global features are used to train and test SVM classifier and achieved 92.24% accuracy
Discriminative Region Proposal Adversarial Networks for High-Quality Image-to-Image Translation
Aug 06, 2018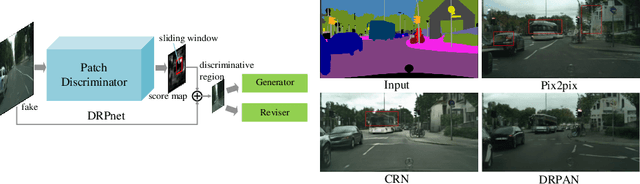
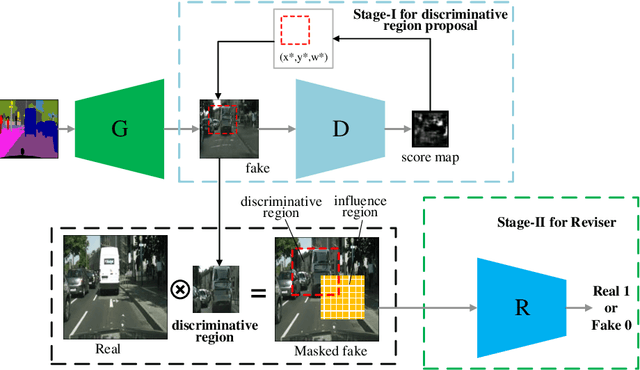
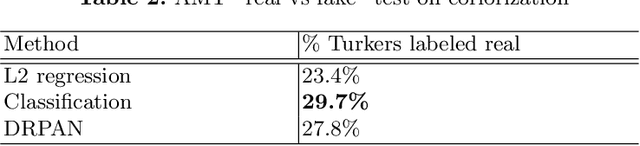
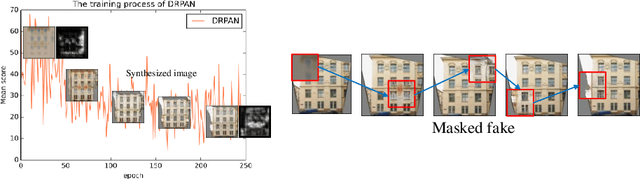
Image-to-image translation has been made much progress with embracing Generative Adversarial Networks (GANs). However, it's still very challenging for translation tasks that require high quality, especially at high-resolution and photorealism. In this paper, we present Discriminative Region Proposal Adversarial Networks (DRPAN) for high-quality image-to-image translation. We decompose the procedure of image-to-image translation task into three iterated steps, first is to generate an image with global structure but some local artifacts (via GAN), second is using our DRPnet to propose the most fake region from the generated image, and third is to implement "image inpainting" on the most fake region for more realistic result through a reviser, so that the system (DRPAN) can be gradually optimized to synthesize images with more attention on the most artifact local part. Experiments on a variety of image-to-image translation tasks and datasets validate that our method outperforms state-of-the-arts for producing high-quality translation results in terms of both human perceptual studies and automatic quantitative measures.