 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Coding for Human and Machine Vision: A Scalable Image Coding Approach
Jan 09, 2020
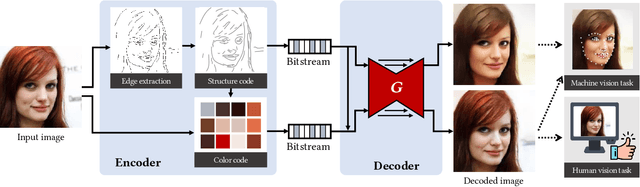

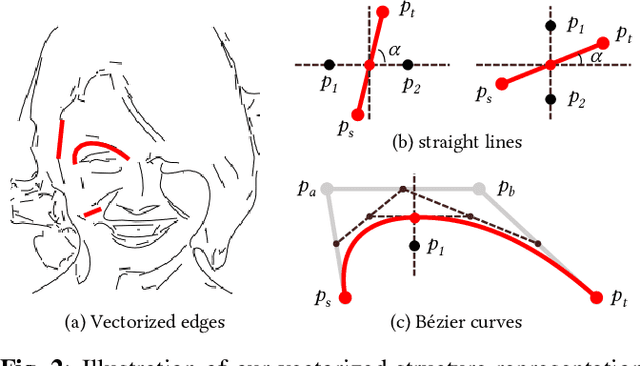

The past decades have witnessed the rapid development of image and video coding techniques in the era of big data. However, the signal fidelity-driven coding pipeline design limits the capability of the existing image/video coding frameworks to fulfill the needs of both machine and human vision. In this paper, we come up with a novel image coding framework by leveraging both the compressive and the generative models, to support machine vision and human perception tasks jointly. Given an input image, the feature analysis is first applied, and then the generative model is employed to perform image reconstruction with features and additional reference pixels, in which compact edge maps are extracted in this work to connect both kinds of vision in a scalable way. The compact edge map serves as the basic layer for machine vision tasks, and the reference pixels act as a sort of enhanced layer to guarantee signal fidelity for human vision. By introducing advanced generative models, we train a flexible network to reconstruct images from compact feature representations and the reference pixels. Experimental results demonstrate the superiority of our framework in both human visual quality and facial landmark detection, which provide useful evidence on the emerging standardization efforts on MPEG VCM (Video Coding for Machine).
Exploiting Motion Information from Unlabeled Videos for Static Image Action Recognition
Dec 01, 2019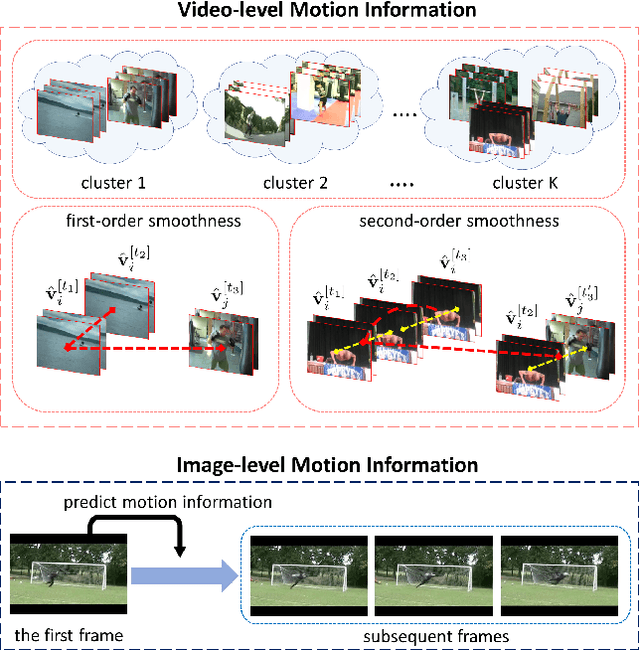
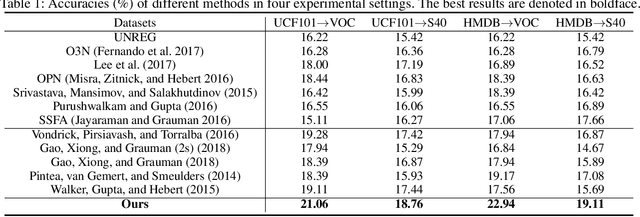
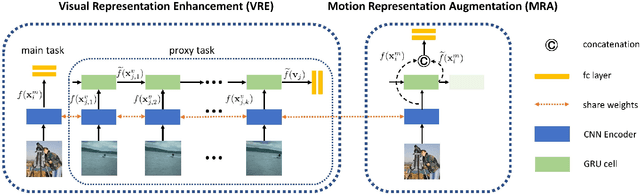
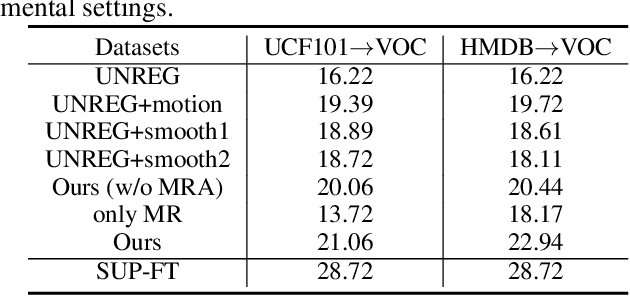
Static image action recognition, which aims to recognize action based on a single image, usually relies on expensive human labeling effort such as adequate labeled action images and large-scale labeled image dataset. In contrast, abundant unlabeled videos can be economically obtained. Therefore, several works have explored using unlabeled videos to facilitate image action recognition, which can be categorized into the following two groups: (a) enhance visual representations of action images with a designed proxy task on unlabeled videos, which falls into the scope of self-supervised learning; (b) generate auxiliary representations for action images with the generator learned from unlabeled videos. In this paper, we integrate the above two strategies in a unified framework, which consists of Visual Representation Enhancement (VRE) module and Motion Representation Augmentation (MRA) module. Specifically, the VRE module includes a proxy task which imposes pseudo motion label constraint and temporal coherence constraint on unlabeled videos, while the MRA module could predict the motion information of a static action image by exploiting unlabeled videos. We demonstrate the superiority of our framework based on four benchmark human action datasets with limited labeled data.
Single-Modal Entropy based Active Learning for Visual Question Answering
Oct 21, 2021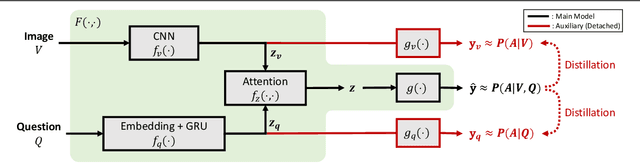
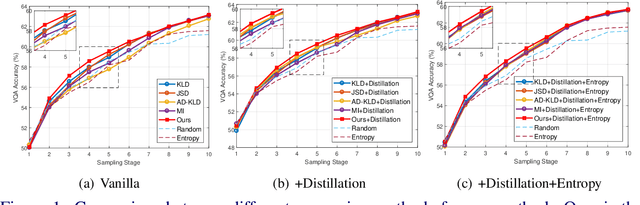
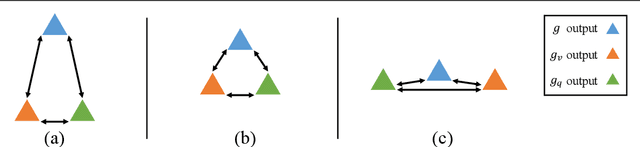
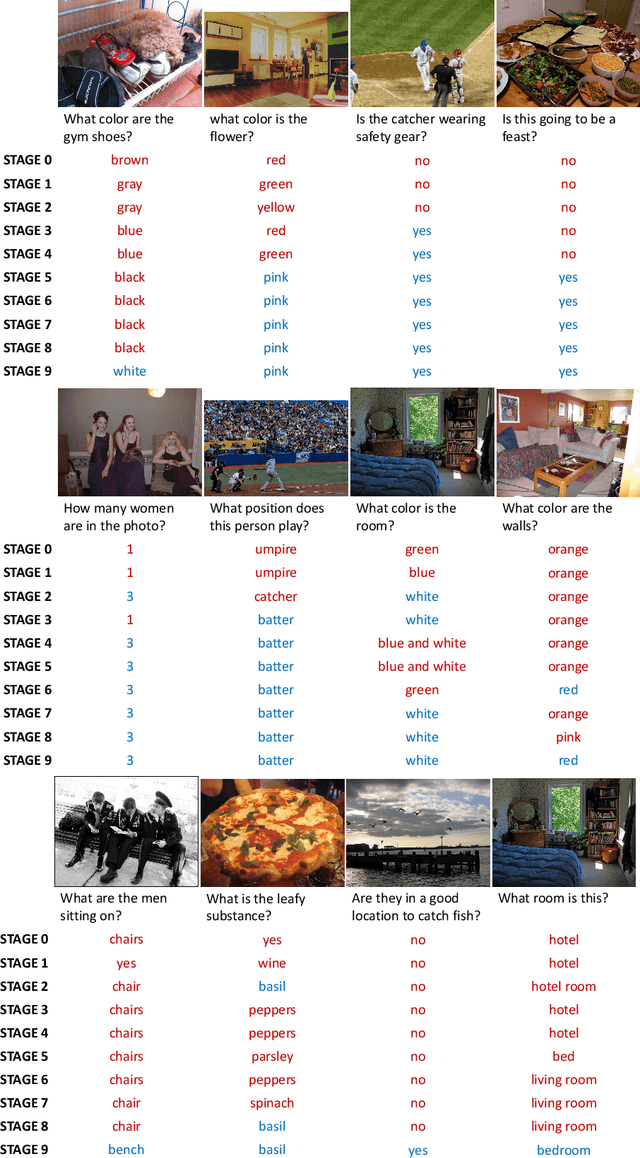
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
ML4ML: Automated Invariance Testing for Machine Learning Models
Sep 27, 2021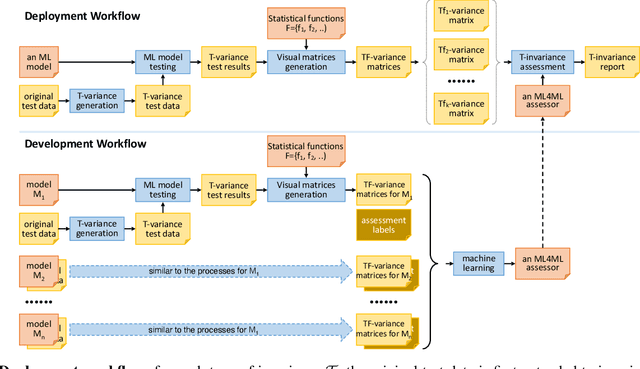

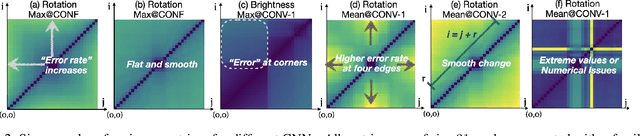

In machine learning workflows, determining invariance qualities of a model is a common testing procedure. In this paper, we propose an automatic testing framework that is applicable to a variety of invariance qualities. We draw an analogy between invariance testing and medical image analysis and propose to use variance matrices as ``imagery'' testing data. This enables us to employ machine learning techniques for analysing such ``imagery'' testing data automatically, hence facilitating ML4ML (machine learning for machine learning). We demonstrate the effectiveness and feasibility of the proposed framework by developing ML4ML models (assessors) for determining rotation-, brightness-, and size-variances of a collection of neural networks. Our testing results show that the trained ML4ML assessors can perform such analytical tasks with sufficient accuracy.
Geometrically Adaptive Dictionary Attack on Face Recognition
Nov 08, 2021CNN-based face recognition models have brought remarkable performance improvement, but they are vulnerable to adversarial perturbations. Recent studies have shown that adversaries can fool the models even if they can only access the models' hard-label output. However, since many queries are needed to find imperceptible adversarial noise, reducing the number of queries is crucial for these attacks. In this paper, we point out two limitations of existing decision-based black-box attacks. We observe that they waste queries for background noise optimization, and they do not take advantage of adversarial perturbations generated for other images. We exploit 3D face alignment to overcome these limitations and propose a general strategy for query-efficient black-box attacks on face recognition named Geometrically Adaptive Dictionary Attack (GADA). Our core idea is to create an adversarial perturbation in the UV texture map and project it onto the face in the image. It greatly improves query efficiency by limiting the perturbation search space to the facial area and effectively recycling previous perturbations. We apply the GADA strategy to two existing attack methods and show overwhelming performance improvement in the experiments on the LFW and CPLFW datasets. Furthermore, we also present a novel attack strategy that can circumvent query similarity-based stateful detection that identifies the process of query-based black-box attacks.
EvoBA: An Evolution Strategy as a Strong Baseline forBlack-Box Adversarial Attacks
Jul 12, 2021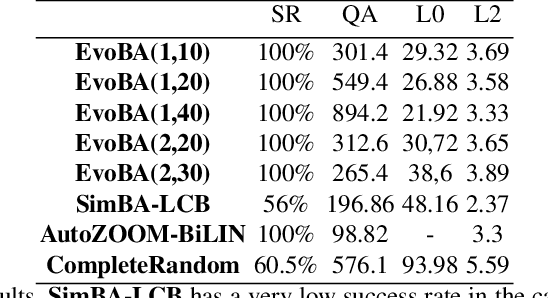
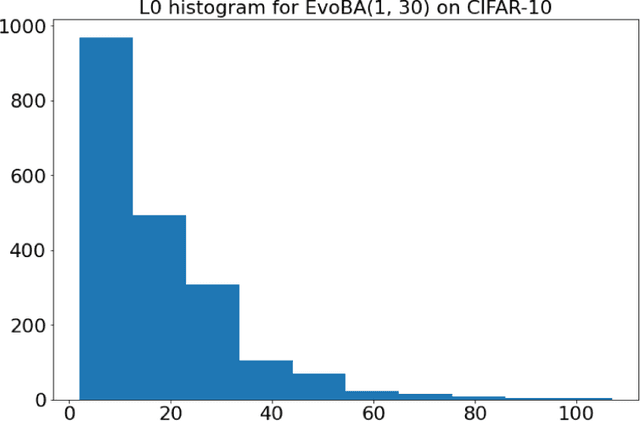
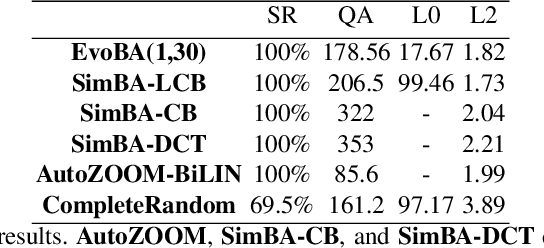
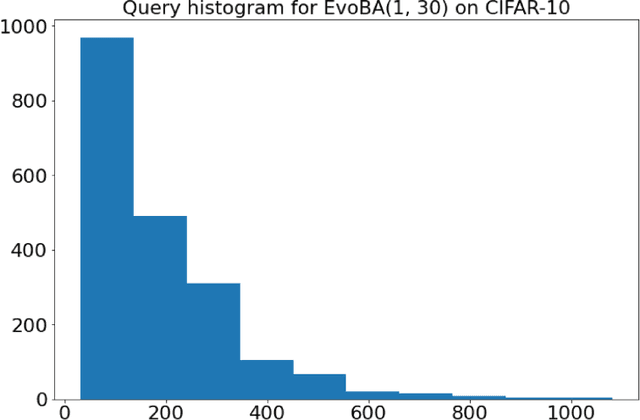
Recent work has shown how easily white-box adversarial attacks can be applied to state-of-the-art image classifiers. However, real-life scenarios resemble more the black-box adversarial conditions, lacking transparency and usually imposing natural, hard constraints on the query budget. We propose $\textbf{EvoBA}$, a black-box adversarial attack based on a surprisingly simple evolutionary search strategy. $\textbf{EvoBA}$ is query-efficient, minimizes $L_0$ adversarial perturbations, and does not require any form of training. $\textbf{EvoBA}$ shows efficiency and efficacy through results that are in line with much more complex state-of-the-art black-box attacks such as $\textbf{AutoZOOM}$. It is more query-efficient than $\textbf{SimBA}$, a simple and powerful baseline black-box attack, and has a similar level of complexity. Therefore, we propose it both as a new strong baseline for black-box adversarial attacks and as a fast and general tool for gaining empirical insight into how robust image classifiers are with respect to $L_0$ adversarial perturbations. There exist fast and reliable $L_2$ black-box attacks, such as $\textbf{SimBA}$, and $L_{\infty}$ black-box attacks, such as $\textbf{DeepSearch}$. We propose $\textbf{EvoBA}$ as a query-efficient $L_0$ black-box adversarial attack which, together with the aforementioned methods, can serve as a generic tool to assess the empirical robustness of image classifiers. The main advantages of such methods are that they run fast, are query-efficient, and can easily be integrated in image classifiers development pipelines. While our attack minimises the $L_0$ adversarial perturbation, we also report $L_2$, and notice that we compare favorably to the state-of-the-art $L_2$ black-box attack, $\textbf{AutoZOOM}$, and of the $L_2$ strong baseline, $\textbf{SimBA}$.
Meta-Learning Sparse Implicit Neural Representations
Oct 27, 2021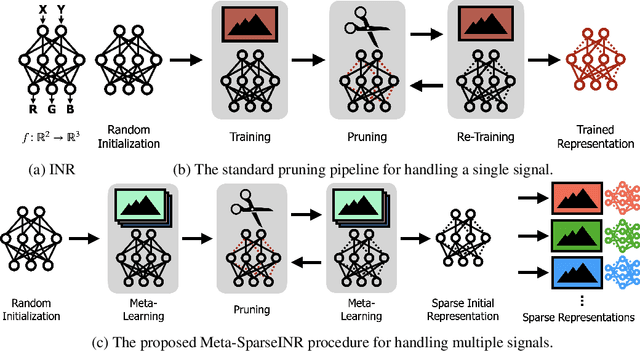

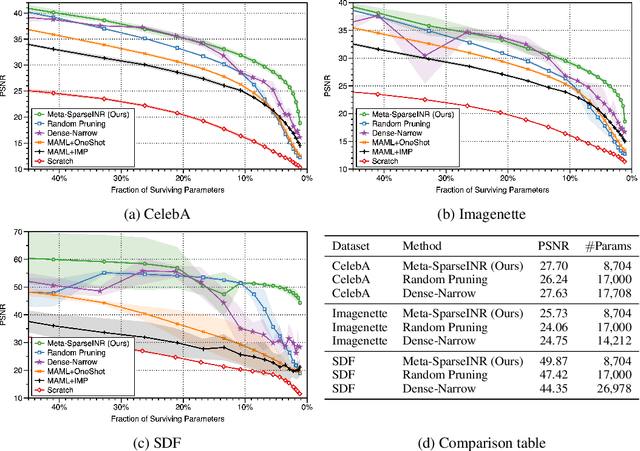
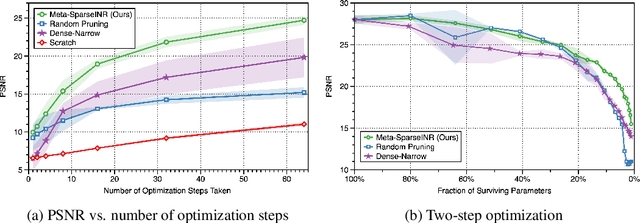
Implicit neural representations are a promising new avenue of representing general signals by learning a continuous function that, parameterized as a neural network, maps the domain of a signal to its codomain; the mapping from spatial coordinates of an image to its pixel values, for example. Being capable of conveying fine details in a high dimensional signal, unboundedly of its domain, implicit neural representations ensure many advantages over conventional discrete representations. However, the current approach is difficult to scale for a large number of signals or a data set, since learning a neural representation -- which is parameter heavy by itself -- for each signal individually requires a lot of memory and computations. To address this issue, we propose to leverage a meta-learning approach in combination with network compression under a sparsity constraint, such that it renders a well-initialized sparse parameterization that evolves quickly to represent a set of unseen signals in the subsequent training. We empirically demonstrate that meta-learned sparse neural representations achieve a much smaller loss than dense meta-learned models with the same number of parameters, when trained to fit each signal using the same number of optimization steps.
A Review of Machine Learning Techniques for Applied Eye Fundus and Tongue Digital Image Processing with Diabetes Management System
Dec 30, 2020Diabetes is a global epidemic and it is increasing at an alarming rate. The International Diabetes Federation (IDF) projected that the total number of people with diabetes globally may increase by 48%, from 425 million (year 2017) to 629 million (year 2045). Moreover, diabetes had caused millions of deaths and the number is increasing drastically. Therefore, this paper addresses the background of diabetes and its complications. In addition, this paper investigates innovative applications and past researches in the areas of diabetes management system with applied eye fundus and tongue digital images. Different types of existing applied eye fundus and tongue digital image processing with diabetes management systems in the market and state-of-the-art machine learning techniques from previous literature have been reviewed. The implication of this paper is to have an overview in diabetic research and what new machine learning techniques can be proposed in solving this global epidemic.
B-line Detection in Lung Ultrasound Videos: Cartesian vs Polar Representation
Jul 26, 2021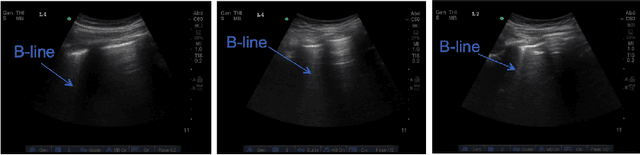

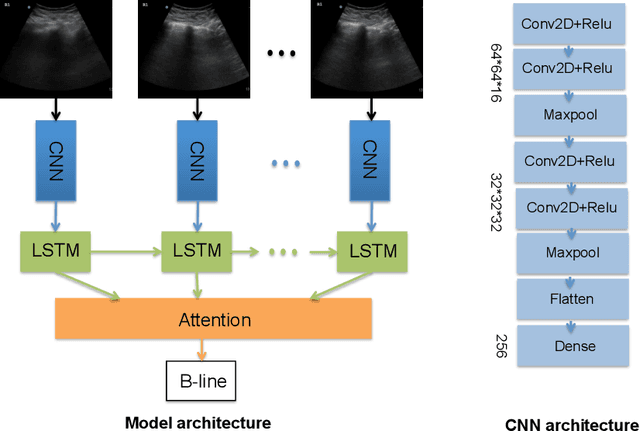
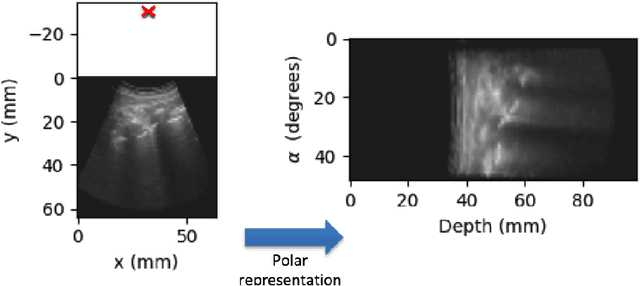
Lung ultrasound (LUS) imaging is becoming popular in the intensive care units (ICU) for assessing lung abnormalities such as the appearance of B-line artefacts as a result of severe dengue. These artefacts appear in the LUS images and disappear quickly, making their manual detection very challenging. They also extend radially following the propagation of the sound waves. As a result, we hypothesize that a polar representation may be more adequate for automatic image analysis of these images. This paper presents an attention-based Convolutional+LSTM model to automatically detect B-lines in LUS videos, comparing performance when image data is taken in Cartesian and polar representations. Results indicate that the proposed framework with polar representation achieves competitive performance compared to the Cartesian representation for B-line classification and that attention mechanism can provide better localization.
Boundary Guided Context Aggregation for Semantic Segmentation
Oct 27, 2021
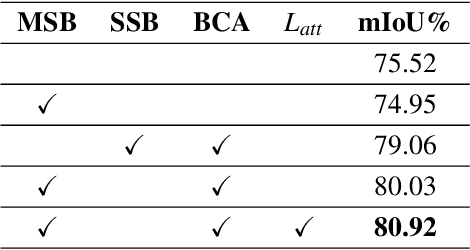
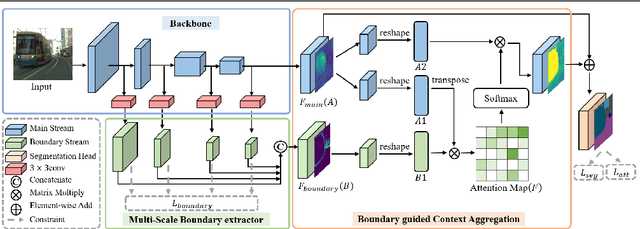

The recent studies on semantic segmentation are starting to notice the significance of the boundary information, where most approaches see boundaries as the supplement of semantic details. However, simply combing boundaries and the mainstream features cannot ensure a holistic improvement of semantics modeling. In contrast to the previous studies, we exploit boundary as a significant guidance for context aggregation to promote the overall semantic understanding of an image. To this end, we propose a Boundary guided Context Aggregation Network (BCANet), where a Multi-Scale Boundary extractor (MSB) borrowing the backbone features at multiple scales is specifically designed for accurate boundary detection. Based on which, a Boundary guided Context Aggregation module (BCA) improved from Non-local network is further proposed to capture long-range dependencies between the pixels in the boundary regions and the ones inside the objects. By aggregating the context information along the boundaries, the inner pixels of the same category achieve mutual gains and therefore the intra-class consistency is enhanced. We conduct extensive experiments on the Cityscapes and ADE20K databases, and comparable results are achieved with the state-of-the-art methods, clearly demonstrating the effectiveness of the proposed one.