 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Chest ImaGenome Dataset for Clinical Reasoning
Jul 31, 2021
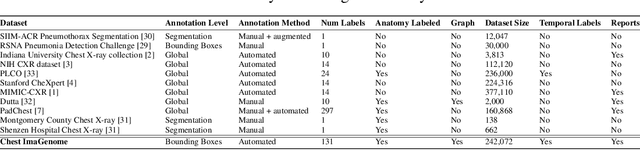
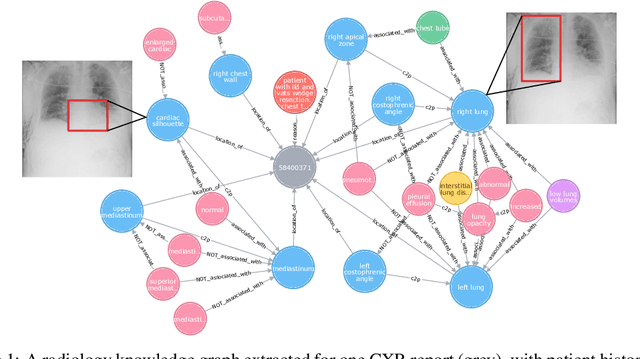
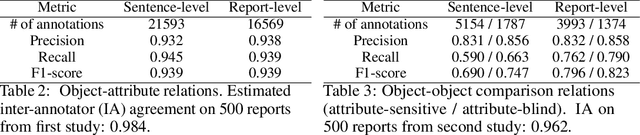

Despite the progress in automatic detection of radiologic findings from chest X-ray (CXR) images in recent years, a quantitative evaluation of the explainability of these models is hampered by the lack of locally labeled datasets for different findings. With the exception of a few expert-labeled small-scale datasets for specific findings, such as pneumonia and pneumothorax, most of the CXR deep learning models to date are trained on global "weak" labels extracted from text reports, or trained via a joint image and unstructured text learning strategy. Inspired by the Visual Genome effort in the computer vision community, we constructed the first Chest ImaGenome dataset with a scene graph data structure to describe $242,072$ images. Local annotations are automatically produced using a joint rule-based natural language processing (NLP) and atlas-based bounding box detection pipeline. Through a radiologist constructed CXR ontology, the annotations for each CXR are connected as an anatomy-centered scene graph, useful for image-level reasoning and multimodal fusion applications. Overall, we provide: i) $1,256$ combinations of relation annotations between $29$ CXR anatomical locations (objects with bounding box coordinates) and their attributes, structured as a scene graph per image, ii) over $670,000$ localized comparison relations (for improved, worsened, or no change) between the anatomical locations across sequential exams, as well as ii) a manually annotated gold standard scene graph dataset from $500$ unique patients.
Style Generator Inversion for Image Enhancement and Animation
Jun 05, 2019
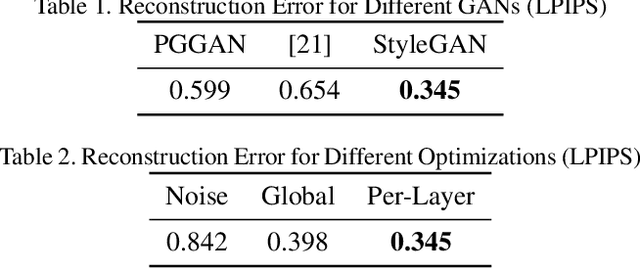


One of the main motivations for training high quality image generative models is their potential use as tools for image manipulation. Recently, generative adversarial networks (GANs) have been able to generate images of remarkable quality. Unfortunately, adversarially-trained unconditional generator networks have not been successful as image priors. One of the main requirements for a network to act as a generative image prior, is being able to generate every possible image from the target distribution. Adversarial learning often experiences mode-collapse, which manifests in generators that cannot generate some modes of the target distribution. Another requirement often not satisfied is invertibility i.e. having an efficient way of finding a valid input latent code given a required output image. In this work, we show that differently from earlier GANs, the very recently proposed style-generators are quite easy to invert. We use this important observation to propose style generators as general purpose image priors. We show that style generators outperform other GANs as well as Deep Image Prior as priors for image enhancement tasks. The latent space spanned by style-generators satisfies linear identity-pose relations. The latent space linearity, combined with invertibility, allows us to animate still facial images without supervision. Extensive experiments are performed to support the main contributions of this paper.
Learning Statistical Representation with Joint Deep Embedded Clustering
Sep 11, 2021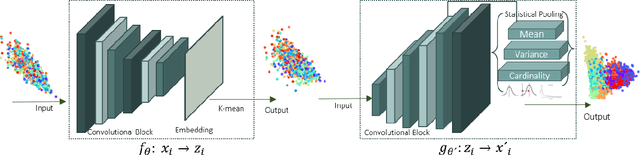
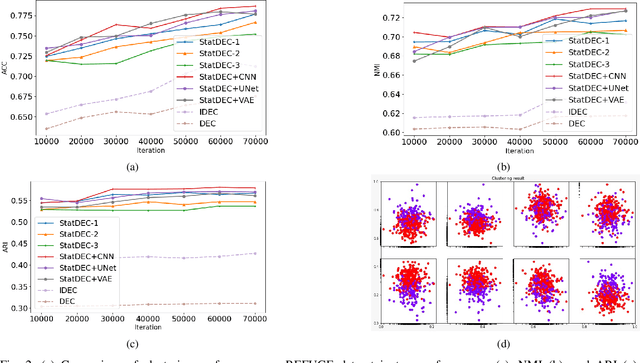
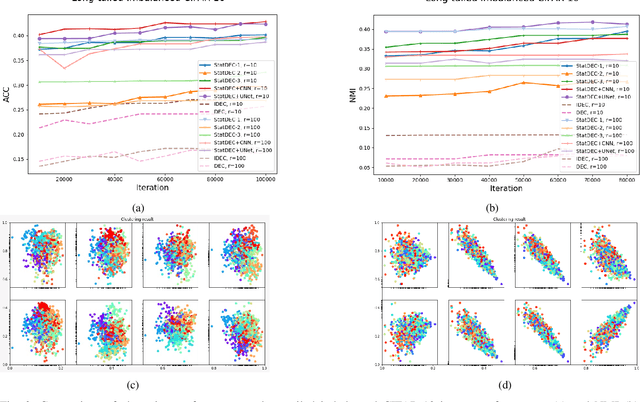
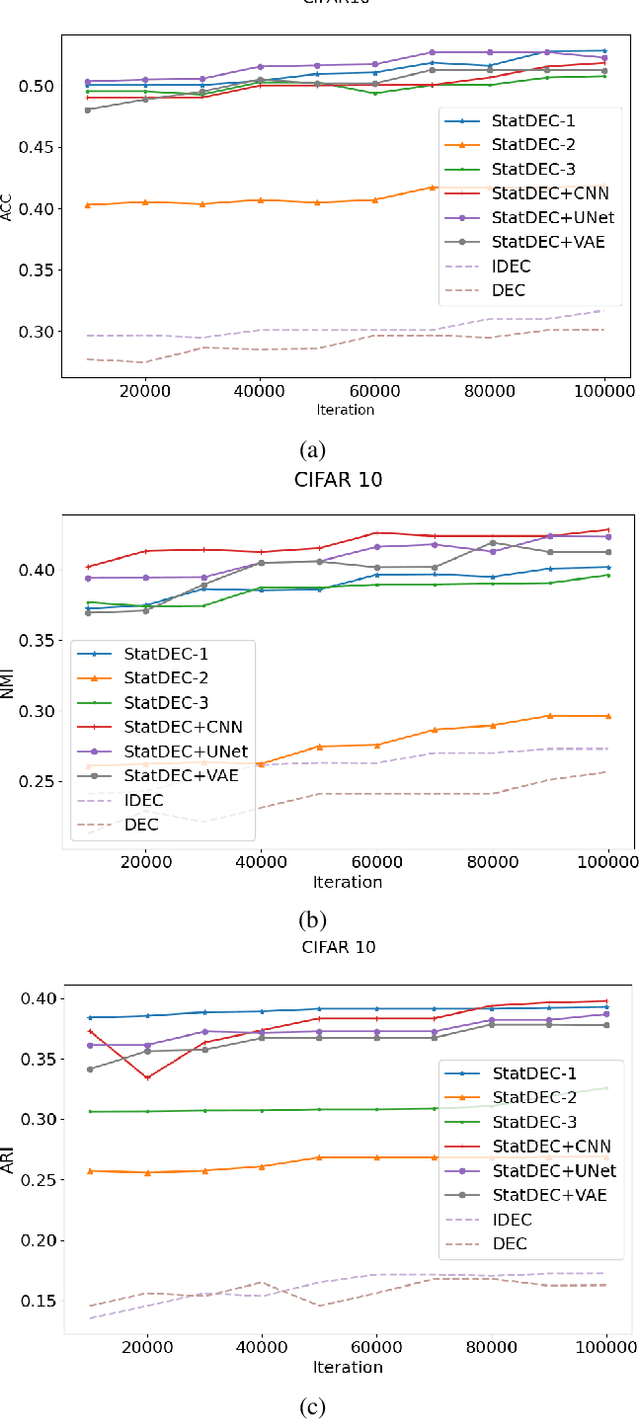
One of the most promising approaches for unsupervised learning is combining deep representation learning and deep clustering. Some recent works propose to simultaneously learn representation using deep neural networks and perform clustering by defining a clustering loss on top of embedded features. However, these approaches are sensitive to imbalanced data and out-of-distribution samples. Hence, these methods optimize clustering by pushing data close to randomly initialized cluster centers. This is problematic when the number of instances varies largely in different classes or a cluster with few samples has less chance to be assigned a good centroid. To overcome these limitations, we introduce StatDEC, a new unsupervised framework for joint statistical representation learning and clustering. StatDEC simultaneously trains two deep learning models, a deep statistics network that captures the data distribution, and a deep clustering network that learns embedded features and performs clustering by explicitly defining a clustering loss. Specifically, the clustering network and representation network both take advantage of our proposed statistics pooling layer that represents mean, variance, and cardinality to handle the out-of-distribution samples as well as a class imbalance. Our experiments show that using these representations, one can considerably improve results on imbalanced image clustering across a variety of image datasets. Moreover, the learned representations generalize well when transferred to the out-of-distribution dataset.
EvDistill: Asynchronous Events to End-task Learning via Bidirectional Reconstruction-guided Cross-modal Knowledge Distillation
Nov 24, 2021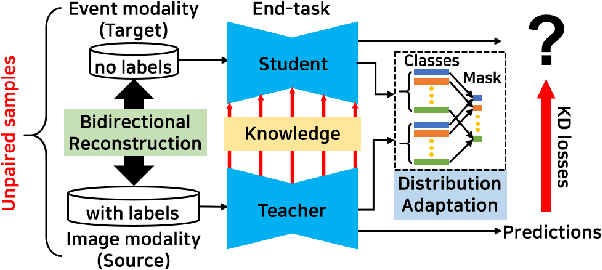
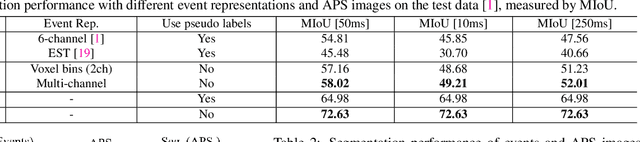
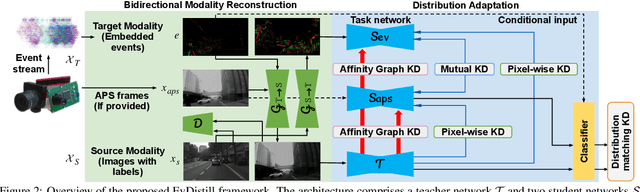

Event cameras sense per-pixel intensity changes and produce asynchronous event streams with high dynamic range and less motion blur, showing advantages over conventional cameras. A hurdle of training event-based models is the lack of large qualitative labeled data. Prior works learning end-tasks mostly rely on labeled or pseudo-labeled datasets obtained from the active pixel sensor (APS) frames; however, such datasets' quality is far from rivaling those based on the canonical images. In this paper, we propose a novel approach, called \textbf{EvDistill}, to learn a student network on the unlabeled and unpaired event data (target modality) via knowledge distillation (KD) from a teacher network trained with large-scale, labeled image data (source modality). To enable KD across the unpaired modalities, we first propose a bidirectional modality reconstruction (BMR) module to bridge both modalities and simultaneously exploit them to distill knowledge via the crafted pairs, causing no extra computation in the inference. The BMR is improved by the end-tasks and KD losses in an end-to-end manner. Second, we leverage the structural similarities of both modalities and adapt the knowledge by matching their distributions. Moreover, as most prior feature KD methods are uni-modality and less applicable to our problem, we propose to leverage an affinity graph KD loss to boost the distillation. Our extensive experiments on semantic segmentation and object recognition demonstrate that EvDistill achieves significantly better results than the prior works and KD with only events and APS frames.
Semantic Image Search for Robotic Applications
Apr 02, 2020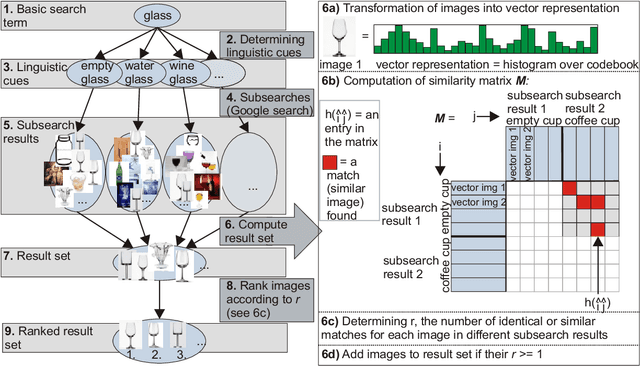
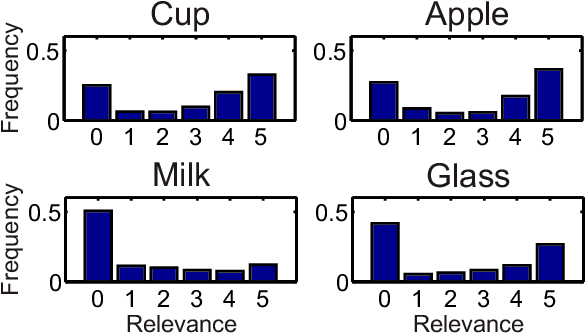
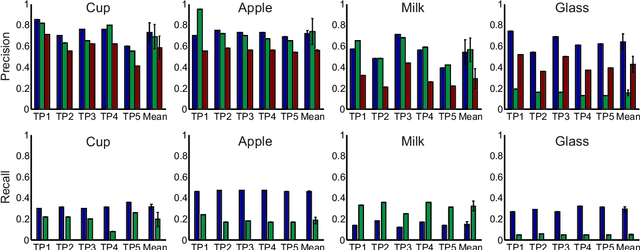

Generalization in robotics is one of the most important problems. New generalization approaches use internet databases in order to solve new tasks. Modern search engines can return a large amount of information according to a query within milliseconds. However, not all of the returned information is task relevant, partly due to the problem of polysemes. Here we specifically address the problem of object generalization by using image search. We suggest a bi-modal solution, combining visual and textual information, based on the observation that humans use additional linguistic cues to demarcate intended word meaning. We evaluate the quality of our approach by comparing it to human labelled data and find that, on average, our approach leads to improved results in comparison to Google searches, and that it can treat the problem of polysemes.
CRD-CGAN: Category-Consistent and Relativistic Constraints for Diverse Text-to-Image Generation
Jul 28, 2021
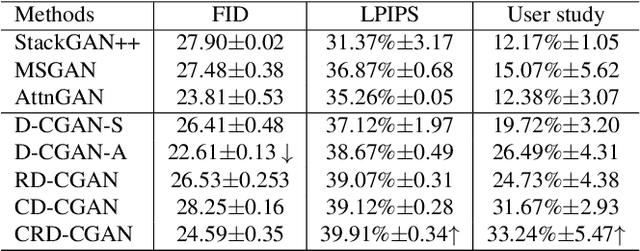

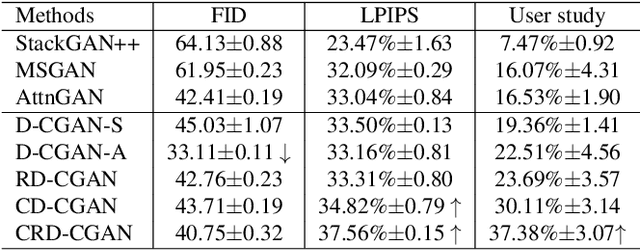
Generating photo-realistic images from a text description is a challenging problem in computer vision. Previous works have shown promising performance to generate synthetic images conditional on text by Generative Adversarial Networks (GANs). In this paper, we focus on the category-consistent and relativistic diverse constraints to optimize the diversity of synthetic images. Based on those constraints, a category-consistent and relativistic diverse conditional GAN (CRD-CGAN) is proposed to synthesize $K$ photo-realistic images simultaneously. We use the attention loss and diversity loss to improve the sensitivity of the GAN to word attention and noises. Then, we employ the relativistic conditional loss to estimate the probability of relatively real or fake for synthetic images, which can improve the performance of basic conditional loss. Finally, we introduce a category-consistent loss to alleviate the over-category issues between K synthetic images. We evaluate our approach using the Birds-200-2011, Oxford-102 flower and MSCOCO 2014 datasets, and the extensive experiments demonstrate superiority of the proposed method in comparison with state-of-the-art methods in terms of photorealistic and diversity of the generated synthetic images.
Precise Object Placement with Pose Distance Estimations for Different Objects and Grippers
Oct 03, 2021



This paper introduces a novel approach for the grasping and precise placement of various known rigid objects using multiple grippers within highly cluttered scenes. Using a single depth image of the scene, our method estimates multiple 6D object poses together with an object class, a pose distance for object pose estimation, and a pose distance from a target pose for object placement for each automatically obtained grasp pose with a single forward pass of a neural network. By incorporating model knowledge into the system, our approach has higher success rates for grasping than state-of-the-art model-free approaches. Furthermore, our method chooses grasps that result in significantly more precise object placements than prior model-based work.
Single Image Deraining: From Model-Based to Data-Driven and Beyond
Dec 27, 2019

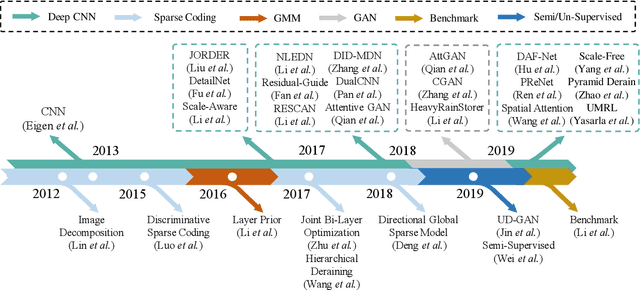
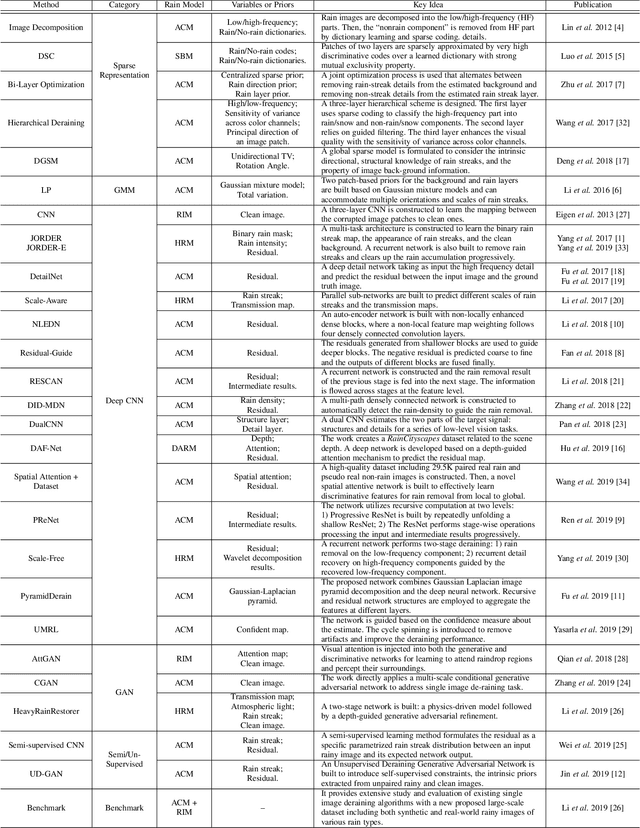
The goal of single-image deraining is to restore the rain-free background scenes of an image degraded by rain streaks and rain accumulation. The early single-image deraining methods employ a cost function, where various priors are developed to represent the properties of rain and background layers. Since 2017, single-image deraining methods step into a deep-learning era, and exploit various types of networks, i.e. convolutional neural networks, recurrent neural networks, generative adversarial networks, etc., demonstrating impressive performance. Given the current rapid development, in this paper, we provide a comprehensive survey of deraining methods over the last decade. We summarize the rain appearance models, and discuss two categories of deraining approaches: model-based and data-driven approaches. For the former, we organize the literature based on their basic models and priors. For the latter, we discuss developed ideas related to architectures, constraints, loss functions, and training datasets. We present milestones of single-image deraining methods, review a broad selection of previous works in different categories, and provide insights on the historical development route from the model-based to data-driven methods. We also summarize performance comparisons quantitatively and qualitatively. Beyond discussing the technicality of deraining methods, we also discuss the future directions.
Reducing Spatial Labeling Redundancy for Semi-supervised Crowd Counting
Aug 06, 2021

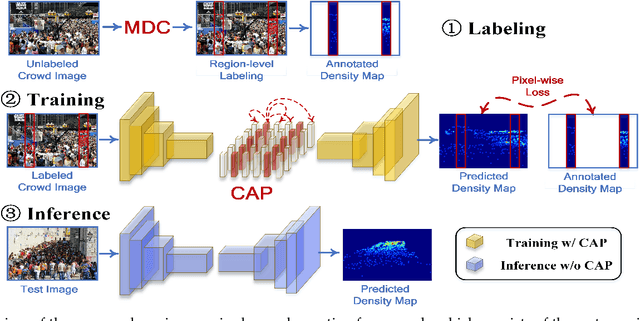

Labeling is onerous for crowd counting as it should annotate each individual in crowd images. Recently, several methods have been proposed for semi-supervised crowd counting to reduce the labeling efforts. Given a limited labeling budget, they typically select a few crowd images and densely label all individuals in each of them. Despite the promising results, we argue the None-or-All labeling strategy is suboptimal as the densely labeled individuals in each crowd image usually appear similar while the massive unlabeled crowd images may contain entirely diverse individuals. To this end, we propose to break the labeling chain of previous methods and make the first attempt to reduce spatial labeling redundancy for semi-supervised crowd counting. First, instead of annotating all the regions in each crowd image, we propose to annotate the representative ones only. We analyze the region representativeness from both vertical and horizontal directions, and formulate them as cluster centers of Gaussian Mixture Models. Additionally, to leverage the rich unlabeled regions, we exploit the similarities among individuals in each crowd image to directly supervise the unlabeled regions via feature propagation instead of the error-prone label propagation employed in the previous methods. In this way, we can transfer the original spatial labeling redundancy caused by individual similarities to effective supervision signals on the unlabeled regions. Extensive experiments on the widely-used benchmarks demonstrate that our method can outperform previous best approaches by a large margin.
Deep Clustering for Mars Rover image datasets
Nov 12, 2019In this paper, we build autoencoders to learn a latent space from unlabeled image datasets obtained from the Mars rover. Then, once the latent feature space has been learnt, we use k-means to cluster the data. We test the performance of the algorithm on a smaller labeled dataset, and report good accuracy and concordance with the ground truth labels. This is the first attempt to use deep learning based unsupervised algorithms to cluster Mars Rover images. This algorithm can be used to augment human annotations for such datasets (which are time consuming) and speed up the generation of ground truth labels for Mars Rover image data, and potentially other planetary and space images.