 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Land Cover Image Classification
Jan 17, 2024
Land Cover (LC) image classification has become increasingly significant in understanding environmental changes, urban planning, and disaster management. However, traditional LC methods are often labor-intensive and prone to human error. This paper explores state-of-the-art deep learning models for enhanced accuracy and efficiency in LC analysis. We compare convolutional neural networks (CNN) against transformer-based methods, showcasing their applications and advantages in LC studies. We used EuroSAT, a patch-based LC classification data set based on Sentinel-2 satellite images and achieved state-of-the-art results using current transformer models.
Offline Deep Model Predictive Control (MPC) for Visual Navigation
Feb 07, 2024In this paper, we propose a new visual navigation method based on a single RGB perspective camera. Using the Visual Teach & Repeat (VT&R) methodology, the robot acquires a visual trajectory consisting of multiple subgoal images in the teaching step. In the repeat step, we propose two network architectures, namely ViewNet and VelocityNet. The combination of the two networks allows the robot to follow the visual trajectory. ViewNet is trained to generate a future image based on the current view and the velocity command. The generated future image is combined with the subgoal image for training VelocityNet. We develop an offline Model Predictive Control (MPC) policy within VelocityNet with the dual goals of (1) reducing the difference between current and subgoal images and (2) ensuring smooth trajectories by mitigating velocity discontinuities. Offline training conserves computational resources, making it a more suitable option for scenarios with limited computational capabilities, such as embedded systems. We validate our experiments in a simulation environment, demonstrating that our model can effectively minimize the metric error between real and played trajectories.
SHMC-Net: A Mask-guided Feature Fusion Network for Sperm Head Morphology Classification
Feb 07, 2024Male infertility accounts for about one-third of global infertility cases. Manual assessment of sperm abnormalities through head morphology analysis encounters issues of observer variability and diagnostic discrepancies among experts. Its alternative, Computer-Assisted Semen Analysis (CASA), suffers from low-quality sperm images, small datasets, and noisy class labels. We propose a new approach for sperm head morphology classification, called SHMC-Net, which uses segmentation masks of sperm heads to guide the morphology classification of sperm images. SHMC-Net generates reliable segmentation masks using image priors, refines object boundaries with an efficient graph-based method, and trains an image network with sperm head crops and a mask network with the corresponding masks. In the intermediate stages of the networks, image and mask features are fused with a fusion scheme to better learn morphological features. To handle noisy class labels and regularize training on small datasets, SHMC-Net applies Soft Mixup to combine mixup augmentation and a loss function. We achieve state-of-the-art results on SCIAN and HuSHeM datasets, outperforming methods that use additional pre-training or costly ensembling techniques.
KTVIC: A Vietnamese Image Captioning Dataset on the Life Domain
Jan 16, 2024Image captioning is a crucial task with applications in a wide range of domains, including healthcare and education. Despite extensive research on English image captioning datasets, the availability of such datasets for Vietnamese remains limited, with only two existing datasets. In this study, we introduce KTVIC, a comprehensive Vietnamese Image Captioning dataset focused on the life domain, covering a wide range of daily activities. This dataset comprises 4,327 images and 21,635 Vietnamese captions, serving as a valuable resource for advancing image captioning in the Vietnamese language. We conduct experiments using various deep neural networks as the baselines on our dataset, evaluating them using the standard image captioning metrics, including BLEU, METEOR, CIDEr, and ROUGE. Our findings underscore the effectiveness of the proposed dataset and its potential contributions to the field of image captioning in the Vietnamese context.
Learning to Produce Semi-dense Correspondences for Visual Localization
Feb 13, 2024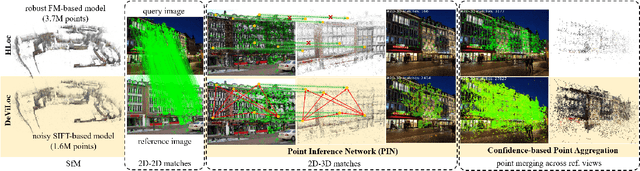
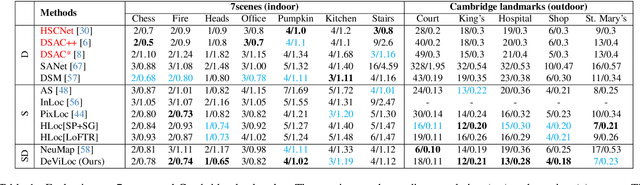
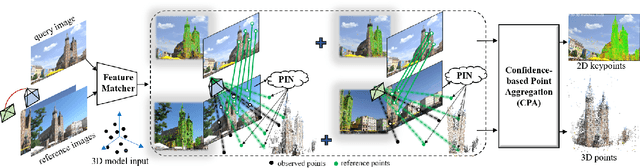
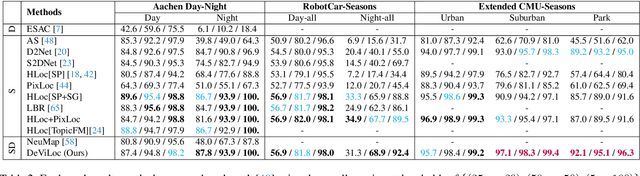
This study addresses the challenge of performing visual localization in demanding conditions such as night-time scenarios, adverse weather, and seasonal changes. While many prior studies have focused on improving image-matching performance to facilitate reliable dense keypoint matching between images, existing methods often heavily rely on predefined feature points on a reconstructed 3D model. Consequently, they tend to overlook unobserved keypoints during the matching process. Therefore, dense keypoint matches are not fully exploited, leading to a notable reduction in accuracy, particularly in noisy scenes. To tackle this issue, we propose a novel localization method that extracts reliable semi-dense 2D-3D matching points based on dense keypoint matches. This approach involves regressing semi-dense 2D keypoints into 3D scene coordinates using a point inference network. The network utilizes both geometric and visual cues to effectively infer 3D coordinates for unobserved keypoints from the observed ones. The abundance of matching information significantly enhances the accuracy of camera pose estimation, even in scenarios involving noisy or sparse 3D models. Comprehensive evaluations demonstrate that the proposed method outperforms other methods in challenging scenes and achieves competitive results in large-scale visual localization benchmarks. The code will be available.
Score-based generative models break the curse of dimensionality in learning a family of sub-Gaussian probability distributions
Feb 12, 2024While score-based generative models (SGMs) have achieved remarkable success in enormous image generation tasks, their mathematical foundations are still limited. In this paper, we analyze the approximation and generalization of SGMs in learning a family of sub-Gaussian probability distributions. We introduce a notion of complexity for probability distributions in terms of their relative density with respect to the standard Gaussian measure. We prove that if the log-relative density can be locally approximated by a neural network whose parameters can be suitably bounded, then the distribution generated by empirical score matching approximates the target distribution in total variation with a dimension-independent rate. We illustrate our theory through examples, which include certain mixtures of Gaussians. An essential ingredient of our proof is to derive a dimension-free deep neural network approximation rate for the true score function associated with the forward process, which is interesting in its own right.
EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss
Feb 07, 2024We present EfficientViT-SAM, a new family of accelerated segment anything models. We retain SAM's lightweight prompt encoder and mask decoder while replacing the heavy image encoder with EfficientViT. For the training, we begin with the knowledge distillation from the SAM-ViT-H image encoder to EfficientViT. Subsequently, we conduct end-to-end training on the SA-1B dataset. Benefiting from EfficientViT's efficiency and capacity, EfficientViT-SAM delivers 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing performance. Our code and pre-trained models are released at https://github.com/mit-han-lab/efficientvit.
EmoGen: Emotional Image Content Generation with Text-to-Image Diffusion Models
Jan 09, 2024Recent years have witnessed remarkable progress in image generation task, where users can create visually astonishing images with high-quality. However, existing text-to-image diffusion models are proficient in generating concrete concepts (dogs) but encounter challenges with more abstract ones (emotions). Several efforts have been made to modify image emotions with color and style adjustments, facing limitations in effectively conveying emotions with fixed image contents. In this work, we introduce Emotional Image Content Generation (EICG), a new task to generate semantic-clear and emotion-faithful images given emotion categories. Specifically, we propose an emotion space and construct a mapping network to align it with the powerful Contrastive Language-Image Pre-training (CLIP) space, providing a concrete interpretation of abstract emotions. Attribute loss and emotion confidence are further proposed to ensure the semantic diversity and emotion fidelity of the generated images. Our method outperforms the state-of-the-art text-to-image approaches both quantitatively and qualitatively, where we derive three custom metrics, i.e., emotion accuracy, semantic clarity and semantic diversity. In addition to generation, our method can help emotion understanding and inspire emotional art design.
Sheet Music Transformer: End-To-End Optical Music Recognition Beyond Monophonic Transcription
Feb 12, 2024State-of-the-art end-to-end Optical Music Recognition (OMR) has, to date, primarily been carried out using monophonic transcription techniques to handle complex score layouts, such as polyphony, often by resorting to simplifications or specific adaptations. Despite their efficacy, these approaches imply challenges related to scalability and limitations. This paper presents the Sheet Music Transformer, the first end-to-end OMR model designed to transcribe complex musical scores without relying solely on monophonic strategies. Our model employs a Transformer-based image-to-sequence framework that predicts score transcriptions in a standard digital music encoding format from input images. Our model has been tested on two polyphonic music datasets and has proven capable of handling these intricate music structures effectively. The experimental outcomes not only indicate the competence of the model, but also show that it is better than the state-of-the-art methods, thus contributing to advancements in end-to-end OMR transcription.
Kitchen Food Waste Image Segmentation and Classification for Compost Nutrients Estimation
Jan 26, 2024The escalating global concern over extensive food wastage necessitates innovative solutions to foster a net-zero lifestyle and reduce emissions. The LILA home composter presents a convenient means of recycling kitchen scraps and daily food waste into nutrient-rich, high-quality compost. To capture the nutritional information of the produced compost, we have created and annotated a large high-resolution image dataset of kitchen food waste with segmentation masks of 19 nutrition-rich categories. Leveraging this dataset, we benchmarked four state-of-the-art semantic segmentation models on food waste segmentation, contributing to the assessment of compost quality of Nitrogen, Phosphorus, or Potassium. The experiments demonstrate promising results of using segmentation models to discern food waste produced in our daily lives. Based on the experiments, SegFormer, utilizing MIT-B5 backbone, yields the best performance with a mean Intersection over Union (mIoU) of 67.09. Class-based results are also provided to facilitate further analysis of different food waste classes.