 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unifying Nonlocal Blocks for Neural Networks
Aug 13, 2021
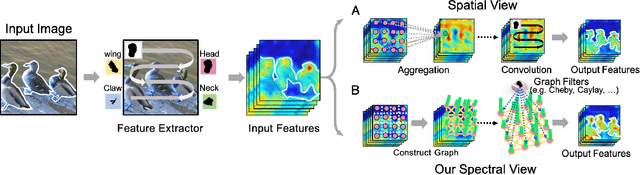

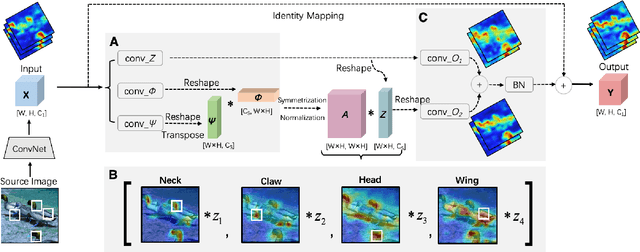
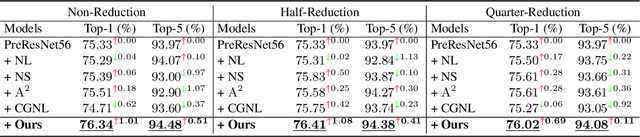
The nonlocal-based blocks are designed for capturing long-range spatial-temporal dependencies in computer vision tasks. Although having shown excellent performance, they still lack the mechanism to encode the rich, structured information among elements in an image or video. In this paper, to theoretically analyze the property of these nonlocal-based blocks, we provide a new perspective to interpret them, where we view them as a set of graph filters generated on a fully-connected graph. Specifically, when choosing the Chebyshev graph filter, a unified formulation can be derived for explaining and analyzing the existing nonlocal-based blocks (e.g., nonlocal block, nonlocal stage, double attention block). Furthermore, by concerning the property of spectral, we propose an efficient and robust spectral nonlocal block, which can be more robust and flexible to catch long-range dependencies when inserted into deep neural networks than the existing nonlocal blocks. Experimental results demonstrate the clear-cut improvements and practical applicabilities of our method on image classification, action recognition, semantic segmentation, and person re-identification tasks.
A Generalized Asymmetric Dual-front Model for Active Contours and Image Segmentation
Jun 14, 2020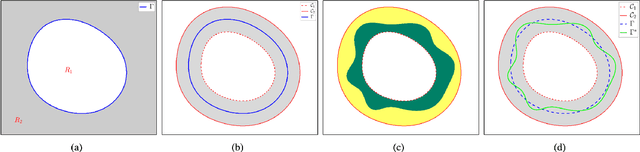
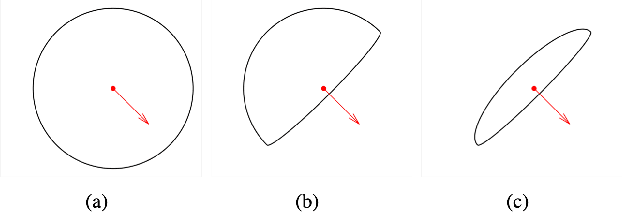
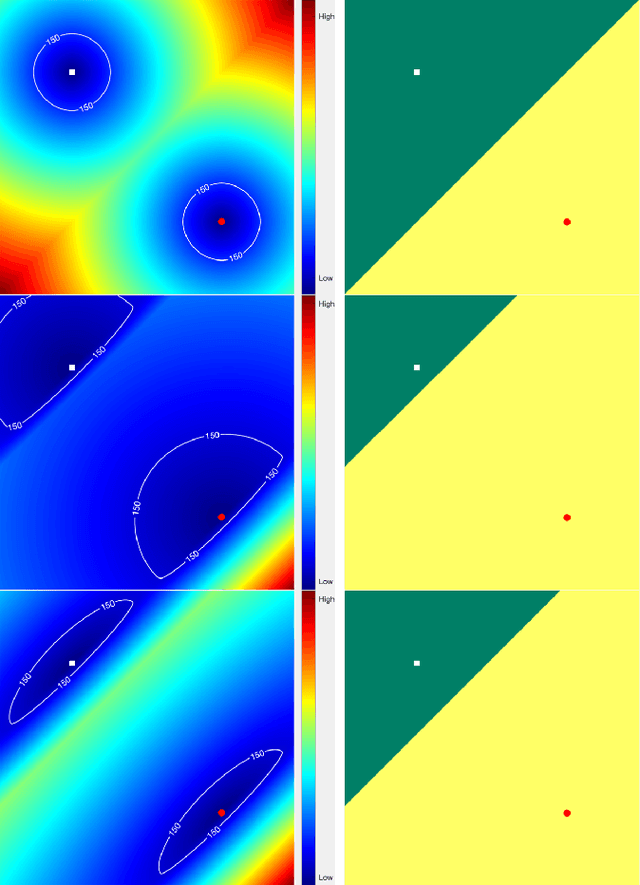

The geodesic distance-based dual-front curve evolution model is a powerful and efficient solution to the active contours and image segmentation issues. In its basic formulation, the dual-front model regards the meeting interfaces of two adjacent Voronoi regions as the evolving curves in the course of curve evolution. One of the most crucial ingredients for the construction of Voronoi regions or Voronoi diagram is the geodesic metrics and the corresponding geodesic distance. In this paper, we introduce a new type of geodesic metrics that encodes the edge-based anisotropy features, the region-based homogeneity penalization and asymmetric enhancement. In contrast to the original isotropic dual-front model, the use of the asymmetric enhancement can reduce the risk of shortcuts or leakage problems especially when the initial curves are far away from the target boundaries. Moreover, the proposed dual-front model can be applied for image segmentation in conjunction with various region-based homogeneity terms, whereas the original model only makes use of the piecewise constant case. The numerical experiments on both synthetic and real images show that the proposed model indeed achieves encouraging results.
Adapting Off-the-Shelf Source Segmenter for Target Medical Image Segmentation
Jun 23, 2021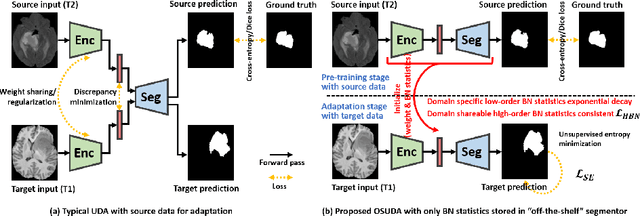
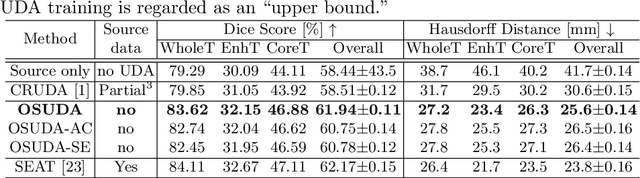
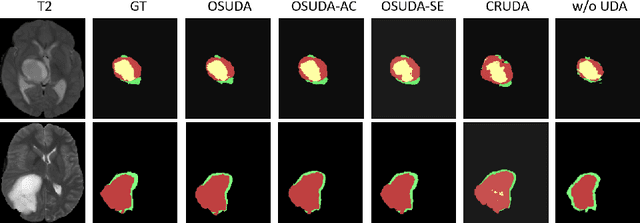
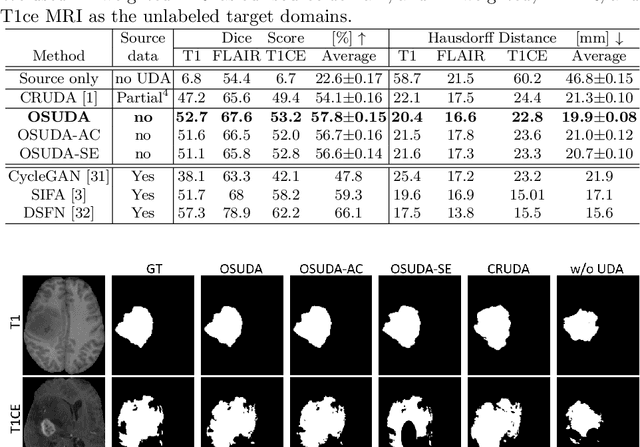
Unsupervised domain adaptation (UDA) aims to transfer knowledge learned from a labeled source domain to an unlabeled and unseen target domain, which is usually trained on data from both domains. Access to the source domain data at the adaptation stage, however, is often limited, due to data storage or privacy issues. To alleviate this, in this work, we target source free UDA for segmentation, and propose to adapt an ``off-the-shelf" segmentation model pre-trained in the source domain to the target domain, with an adaptive batch-wise normalization statistics adaptation framework. Specifically, the domain-specific low-order batch statistics, i.e., mean and variance, are gradually adapted with an exponential momentum decay scheme, while the consistency of domain shareable high-order batch statistics, i.e., scaling and shifting parameters, is explicitly enforced by our optimization objective. The transferability of each channel is adaptively measured first from which to balance the contribution of each channel. Moreover, the proposed source free UDA framework is orthogonal to unsupervised learning methods, e.g., self-entropy minimization, which can thus be simply added on top of our framework. Extensive experiments on the BraTS 2018 database show that our source free UDA framework outperformed existing source-relaxed UDA methods for the cross-subtype UDA segmentation task and yielded comparable results for the cross-modality UDA segmentation task, compared with a supervised UDA methods with the source data.
Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation
Sep 25, 2021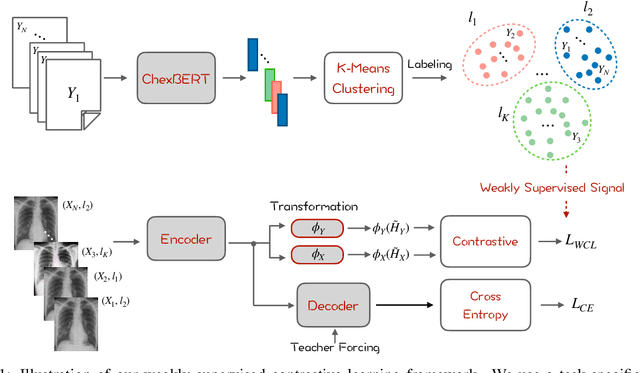
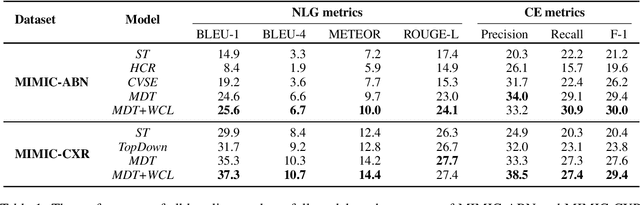
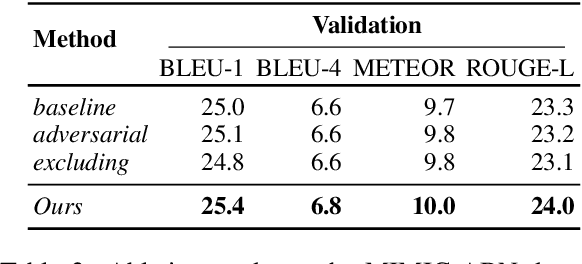
Radiology report generation aims at generating descriptive text from radiology images automatically, which may present an opportunity to improve radiology reporting and interpretation. A typical setting consists of training encoder-decoder models on image-report pairs with a cross entropy loss, which struggles to generate informative sentences for clinical diagnoses since normal findings dominate the datasets. To tackle this challenge and encourage more clinically-accurate text outputs, we propose a novel weakly supervised contrastive loss for medical report generation. Experimental results demonstrate that our method benefits from contrasting target reports with incorrect but semantically-close ones. It outperforms previous work on both clinical correctness and text generation metrics for two public benchmarks.
Spectral Analysis Network for Deep Representation Learning and Image Clustering
Sep 11, 2020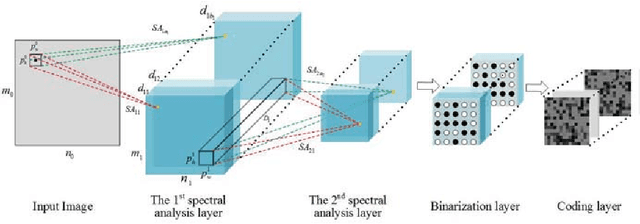
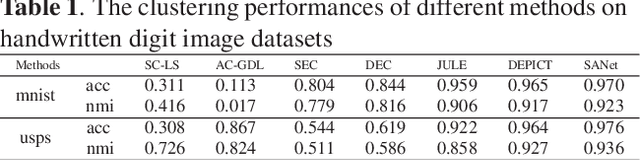

Deep representation learning is a crucial procedure in multimedia analysis and attracts increasing attention. Most of the popular techniques rely on convolutional neural network and require a large amount of labeled data in the training procedure. However, it is time consuming or even impossible to obtain the label information in some tasks due to cost limitation. Thus, it is necessary to develop unsupervised deep representation learning techniques. This paper proposes a new network structure for unsupervised deep representation learning based on spectral analysis, which is a popular technique with solid theory foundations. Compared with the existing spectral analysis methods, the proposed network structure has at least three advantages. Firstly, it can identify the local similarities among images in patch level and thus more robust against occlusion. Secondly, through multiple consecutive spectral analysis procedures, the proposed network can learn more clustering-friendly representations and is capable to reveal the deep correlations among data samples. Thirdly, it can elegantly integrate different spectral analysis procedures, so that each spectral analysis procedure can have their individual strengths in dealing with different data sample distributions. Extensive experimental results show the effectiveness of the proposed methods on various image clustering tasks.
Atlas-Based Segmentation of Intracochlear Anatomy in Metal Artifact Affected CT Images of the Ear with Co-trained Deep Neural Networks
Jul 09, 2021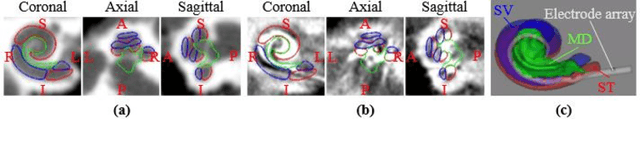
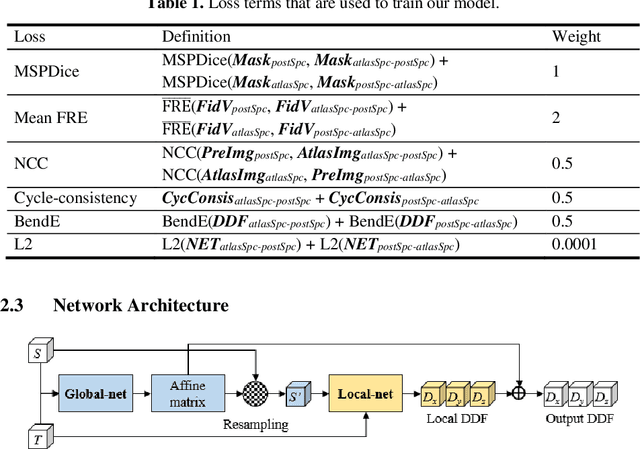
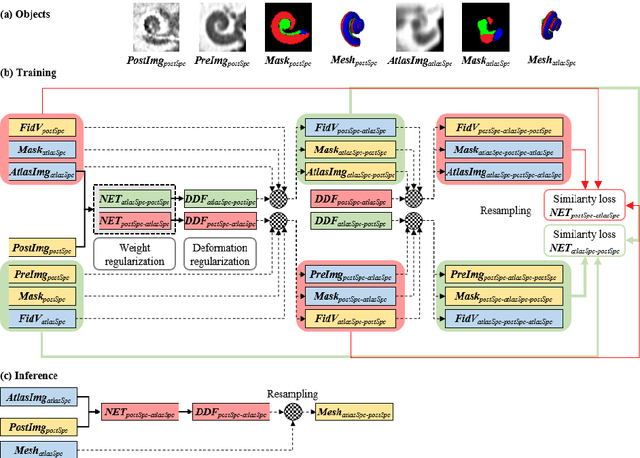
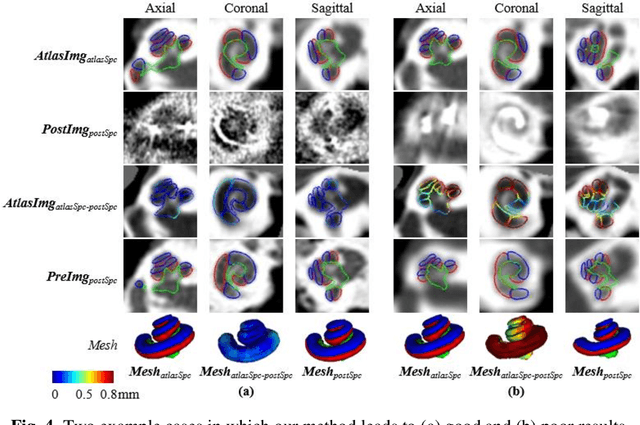
We propose an atlas-based method to segment the intracochlear anatomy (ICA) in the post-implantation CT (Post-CT) images of cochlear implant (CI) recipients that preserves the point-to-point correspondence between the meshes in the atlas and the segmented volumes. To solve this problem, which is challenging because of the strong artifacts produced by the implant, we use a pair of co-trained deep networks that generate dense deformation fields (DDFs) in opposite directions. One network is tasked with registering an atlas image to the Post-CT images and the other network is tasked with registering the Post-CT images to the atlas image. The networks are trained using loss functions based on voxel-wise labels, image content, fiducial registration error, and cycle-consistency constraint. The segmentation of the ICA in the Post-CT images is subsequently obtained by transferring the predefined segmentation meshes of the ICA in the atlas image to the Post-CT images using the corresponding DDFs generated by the trained registration networks. Our model can learn the underlying geometric features of the ICA even though they are obscured by the metal artifacts. We show that our end-to-end network produces results that are comparable to the current state of the art (SOTA) that relies on a two-steps approach that first uses conditional generative adversarial networks to synthesize artifact-free images from the Post-CT images and then uses an active shape model-based method to segment the ICA in the synthetic images. Our method requires a fraction of the time needed by the SOTA, which is important for end-user acceptance.
BINet: a binary inpainting network for deep patch-based image compression
Dec 11, 2019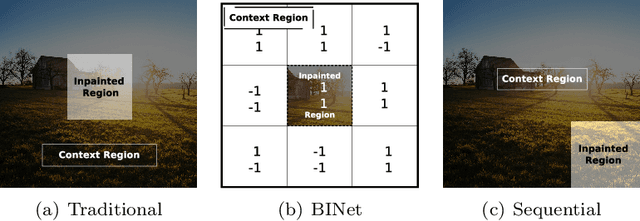

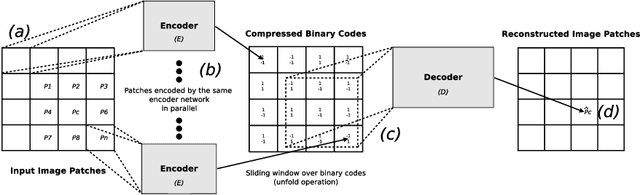

Recent deep learning models outperform standard lossy image compression codecs. However, applying these models on a patch-by-patch basis requires that each image patch be encoded and decoded independently. The influence from adjacent patches is therefore lost, leading to block artefacts at low bitrates. We propose the Binary Inpainting Network (BINet), an autoencoder framework which incorporates binary inpainting to reinstate interdependencies between adjacent patches, for improved patch-based compression of still images. When decoding a patch, BINet additionally uses the binarised encodings from surrounding patches to guide its reconstruction. In contrast to sequential inpainting methods where patches are decoded based on previons reconstructions, BINet operates directly on the binary codes of surrounding patches without access to the original or reconstructed image data. Encoding and decoding can therefore be performed in parallel. We demonstrate that BINet improves the compression quality of a competitive deep image codec across a range of compression levels.
Mastering Atari Games with Limited Data
Oct 30, 2021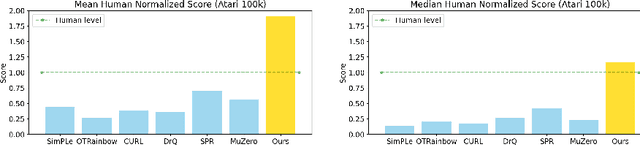
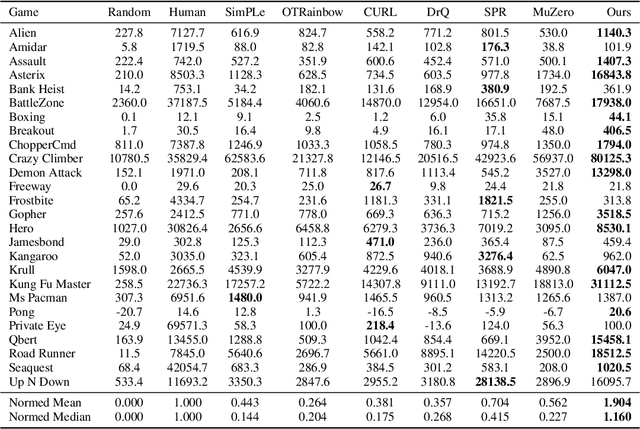
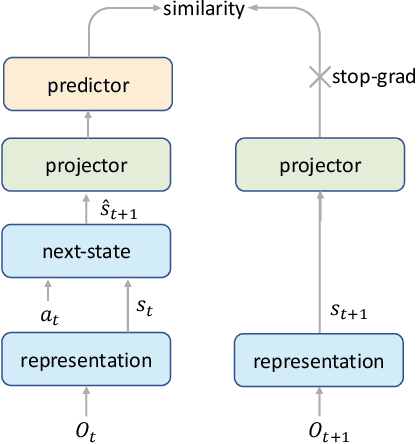

Reinforcement learning has achieved great success in many applications. However, sample efficiency remains a key challenge, with prominent methods requiring millions (or even billions) of environment steps to train. Recently, there has been significant progress in sample efficient image-based RL algorithms; however, consistent human-level performance on the Atari game benchmark remains an elusive goal. We propose a sample efficient model-based visual RL algorithm built on MuZero, which we name EfficientZero. Our method achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperforms the state SAC in some tasks on the DMControl 100k benchmark. This is the first time an algorithm achieves super-human performance on Atari games with such little data. EfficientZero's performance is also close to DQN's performance at 200 million frames while we consume 500 times less data. EfficientZero's low sample complexity and high performance can bring RL closer to real-world applicability. We implement our algorithm in an easy-to-understand manner and it is available at https://github.com/YeWR/EfficientZero. We hope it will accelerate the research of MCTS-based RL algorithms in the wider community.
SieveNet: A Unified Framework for Robust Image-Based Virtual Try-On
Jan 17, 2020
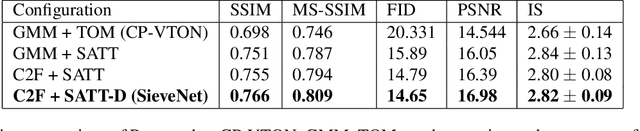
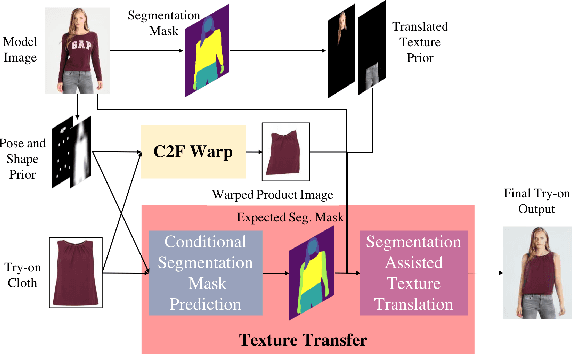
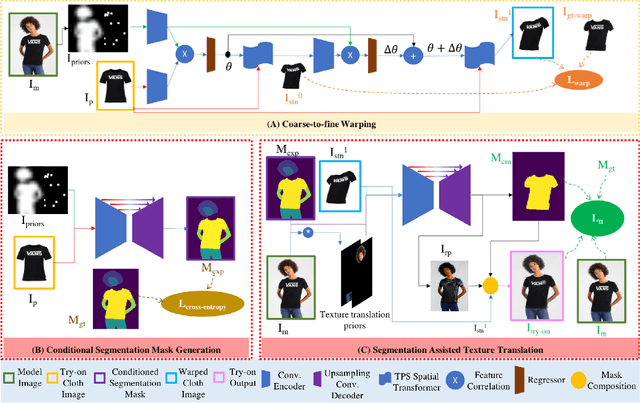
Image-based virtual try-on for fashion has gained considerable attention recently. The task requires trying on a clothing item on a target model image. An efficient framework for this is composed of two stages: (1) warping (transforming) the try-on cloth to align with the pose and shape of the target model, and (2) a texture transfer module to seamlessly integrate the warped try-on cloth onto the target model image. Existing methods suffer from artifacts and distortions in their try-on output. In this work, we present SieveNet, a framework for robust image-based virtual try-on. Firstly, we introduce a multi-stage coarse-to-fine warping network to better model fine-grained intricacies (while transforming the try-on cloth) and train it with a novel perceptual geometric matching loss. Next, we introduce a try-on cloth conditioned segmentation mask prior to improve the texture transfer network. Finally, we also introduce a dueling triplet loss strategy for training the texture translation network which further improves the quality of the generated try-on results. We present extensive qualitative and quantitative evaluations of each component of the proposed pipeline and show significant performance improvements against the current state-of-the-art method.
Multimodal Few-Shot Learning with Frozen Language Models
Jun 25, 2021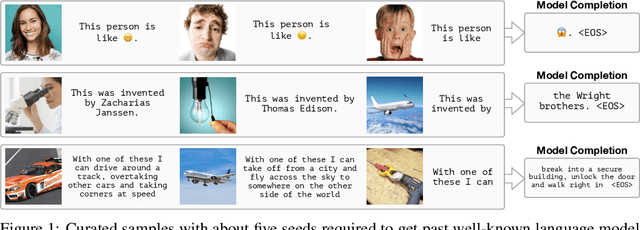
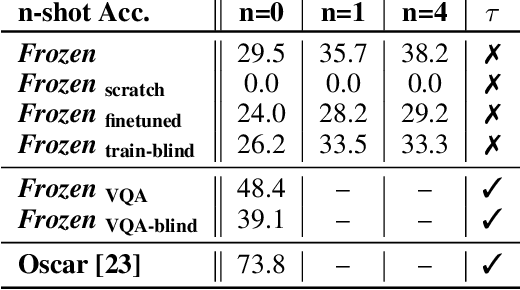
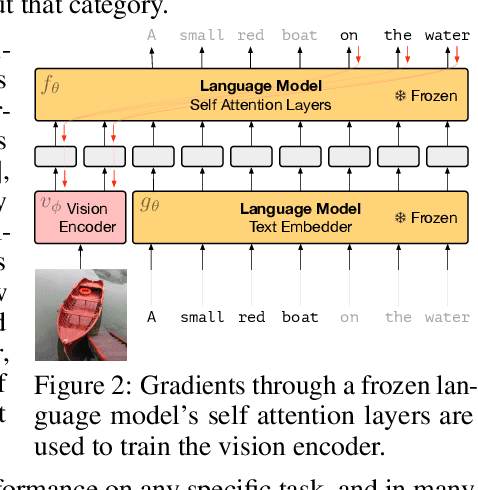
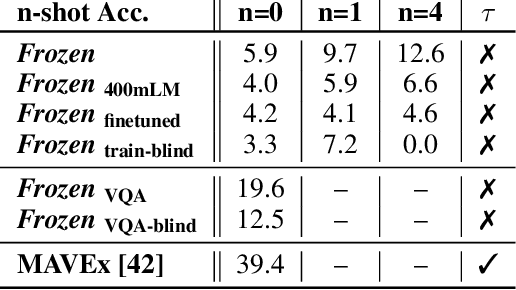
When trained at sufficient scale, auto-regressive language models exhibit the notable ability to learn a new language task after being prompted with just a few examples. Here, we present a simple, yet effective, approach for transferring this few-shot learning ability to a multimodal setting (vision and language). Using aligned image and caption data, we train a vision encoder to represent each image as a sequence of continuous embeddings, such that a pre-trained, frozen language model prompted with this prefix generates the appropriate caption. The resulting system is a multimodal few-shot learner, with the surprising ability to learn a variety of new tasks when conditioned on examples, represented as a sequence of multiple interleaved image and text embeddings. We demonstrate that it can rapidly learn words for new objects and novel visual categories, do visual question-answering with only a handful of examples, and make use of outside knowledge, by measuring a single model on a variety of established and new benchmarks.