 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Monocular DepthEstimation with Internal Feature Fusion
Oct 18, 2021
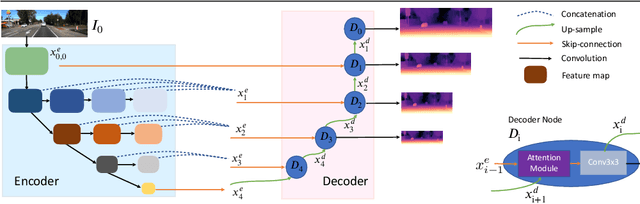
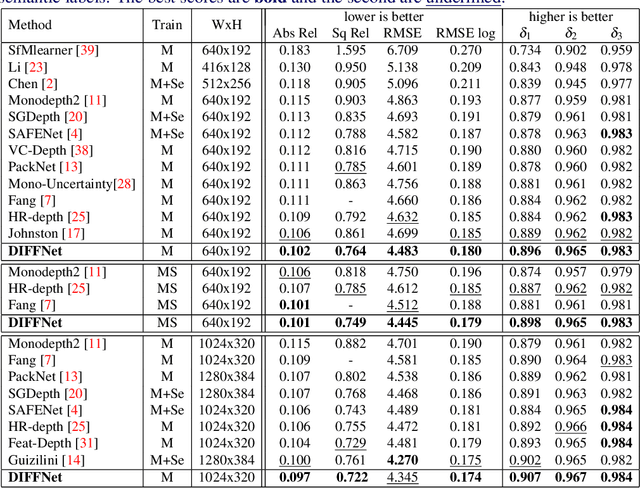

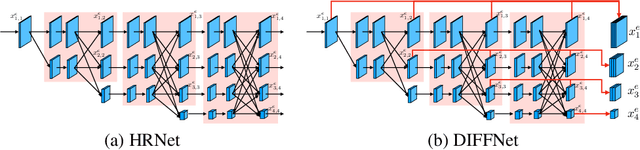
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.
Color Image Enhancement Method Based on Weighted Image Guided Filtering
Dec 24, 2018A novel color image enhancement method is proposed based on Retinex to enhance color images under non-uniform illumination or poor visibility conditions. Different from the conventional Retinex algorithms, the Weighted Guided Image Filter is used as a surround function instead of the Gaussian filter to estimate the background illumination, which can overcome the drawbacks of local blur and halo artifact that may appear by Gaussian filter. To avoid color distortion, the image is converted to the HSI color model, and only the intensity channel is enhanced. Then a linear color restoration algorithm is adopted to convert the enhanced intensity image back to the RGB color model, which ensures the hue is constant and undistorted. Experimental results show that the proposed method is effective to enhance both color and gray images with low exposure and non-uniform illumination, resulting in better visual quality than traditional method. At the same time, the objective evaluation indicators are also superior to the conventional methods. In addition, the efficiency of the proposed method is also improved thanks to the linear color restoration algorithm.
A generative adversarial approach to facilitate archival-quality histopathologic diagnoses from frozen tissue sections
Aug 24, 2021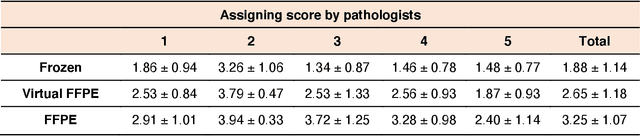
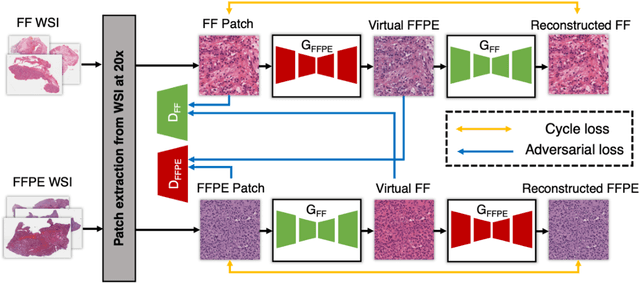
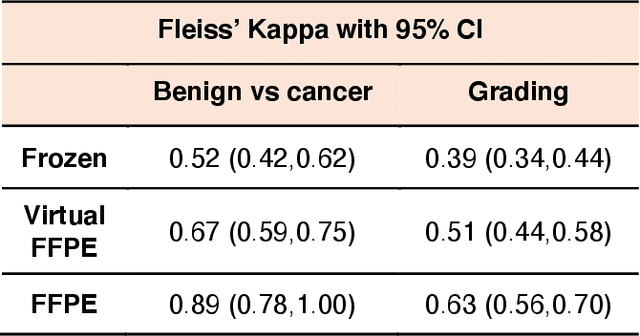
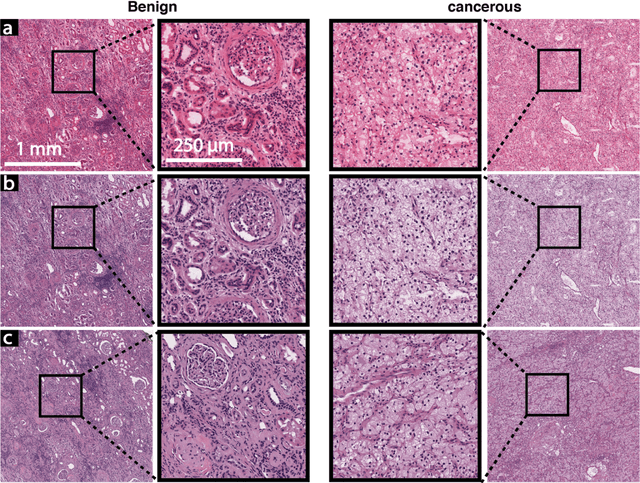
In clinical diagnostics and research involving histopathology, formalin fixed paraffin embedded (FFPE) tissue is almost universally favored for its superb image quality. However, tissue processing time (more than 24 hours) can slow decision-making. In contrast, fresh frozen (FF) processing (less than 1 hour) can yield rapid information but diagnostic accuracy is suboptimal due to lack of clearing, morphologic deformation and more frequent artifacts. Here, we bridge this gap using artificial intelligence. We synthesize FFPE-like images ,virtual FFPE, from FF images using a generative adversarial network (GAN) from 98 paired kidney samples derived from 40 patients. Five board-certified pathologists evaluated the results in a blinded test. Image quality of the virtual FFPE data was assessed to be high and showed a close resemblance to real FFPE images. Clinical assessments of disease on the virtual FFPE images showed a higher inter-observer agreement compared to FF images. The nearly instantaneously generated virtual FFPE images can not only reduce time to information but can facilitate more precise diagnosis from routine FF images without extraneous costs and effort.
Speech Synthesis from Text and Ultrasound Tongue Image-based Articulatory Input
Jul 05, 2021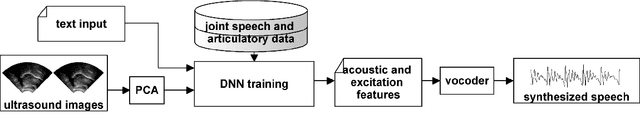
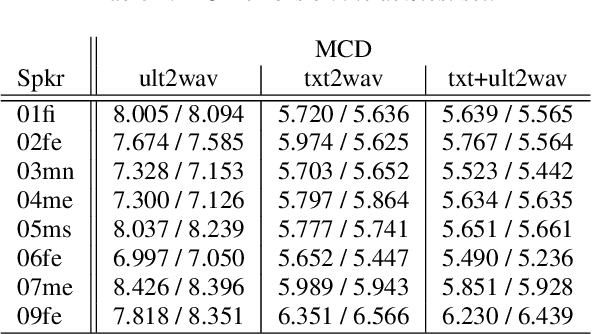
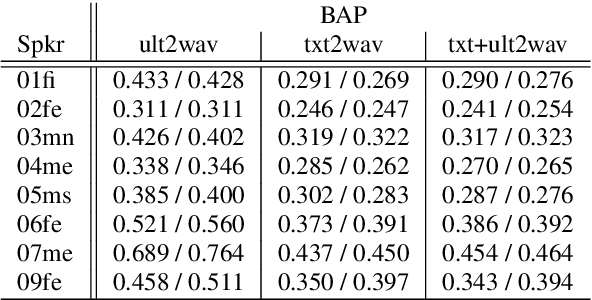
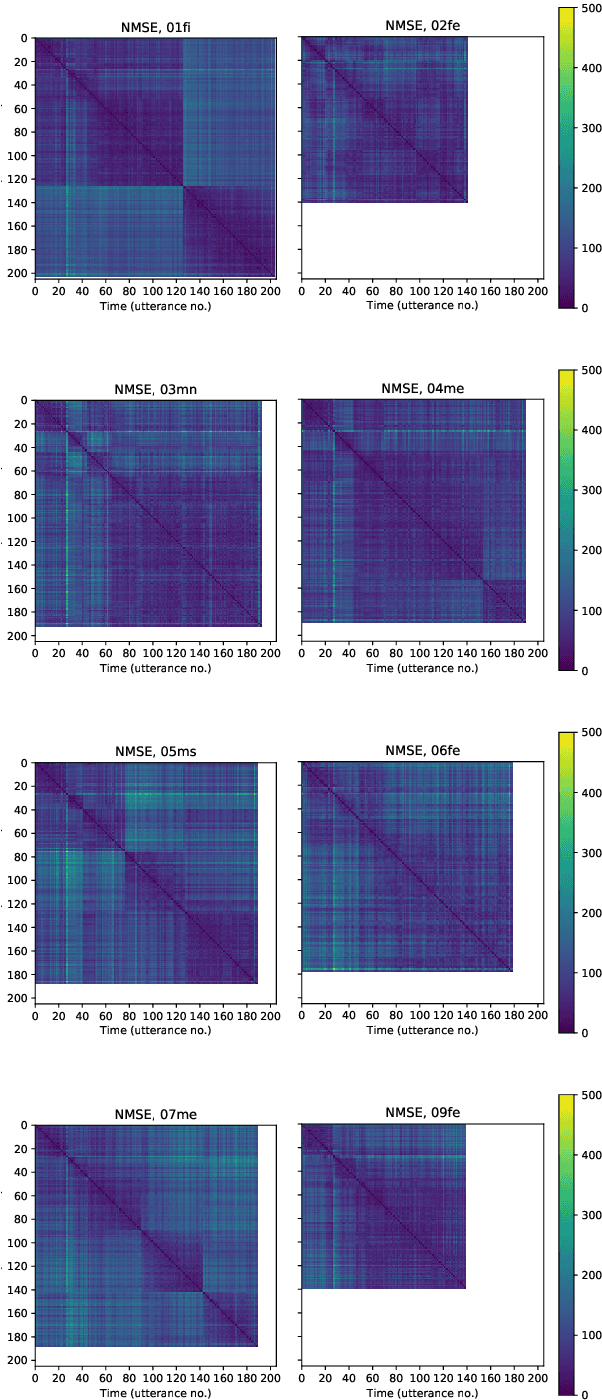
Articulatory information has been shown to be effective in improving the performance of HMM-based and DNN-based text-to-speech synthesis. Speech synthesis research focuses traditionally on text-to-speech conversion, when the input is text or an estimated linguistic representation, and the target is synthesized speech. However, a research field that has risen in the last decade is articulation-to-speech synthesis (with a target application of a Silent Speech Interface, SSI), when the goal is to synthesize speech from some representation of the movement of the articulatory organs. In this paper, we extend traditional (vocoder-based) DNN-TTS with articulatory input, estimated from ultrasound tongue images. We compare text-only, ultrasound-only, and combined inputs. Using data from eight speakers, we show that that the combined text and articulatory input can have advantages in limited-data scenarios, namely, it may increase the naturalness of synthesized speech compared to single text input. Besides, we analyze the ultrasound tongue recordings of several speakers, and show that misalignments in the ultrasound transducer positioning can have a negative effect on the final synthesis performance.
Sibling Neural Estimators: Improving Iterative Image Decoding with Gradient Communication
Nov 20, 2019
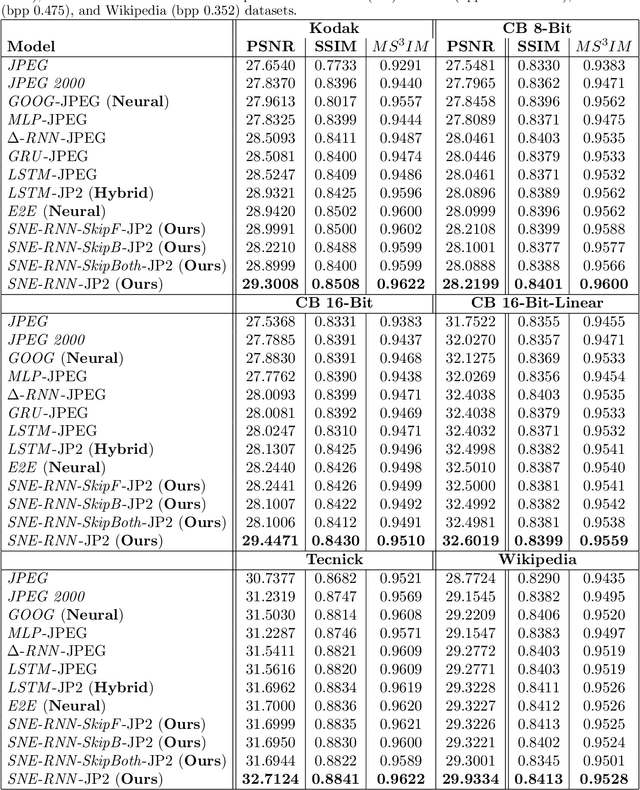
For lossy image compression, we develop a neural-based system which learns a nonlinear estimator for decoding from quantized representations. The system links two recurrent networks that \help" each other reconstruct same target image patches using complementary portions of spatial context that communicate via gradient signals. This dual agent system builds upon prior work that proposed the iterative refinement algorithm for recurrent neural network (RNN)based decoding which improved image reconstruction compared to standard decoding techniques. Our approach, which works with any encoder, neural or non-neural, This system progressively reduces image patch reconstruction error over a fixed number of steps. Experiment with variants of RNN memory cells, with and without future information, find that our model consistently creates lower distortion images of higher perceptual quality compared to other approaches. Specifically, on the Kodak Lossless True Color Image Suite, we observe as much as a 1:64 decibel (dB) gain over JPEG, a 1:46 dB gain over JPEG 2000, a 1:34 dB gain over the GOOG neural baseline, 0:36 over E2E (a modern competitive neural compression model), and 0:37 over a single iterative neural decoder.
Medical Image Registration Using Deep Neural Networks: A Comprehensive Review
Feb 09, 2020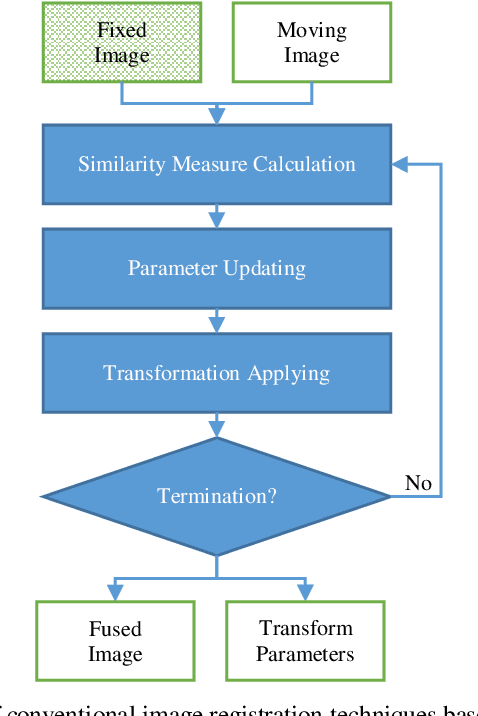
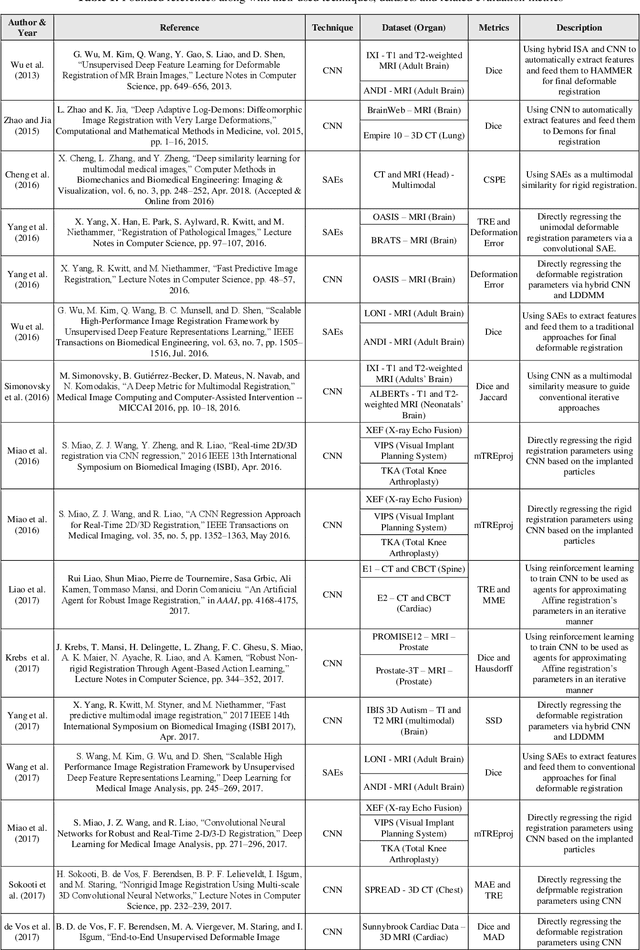
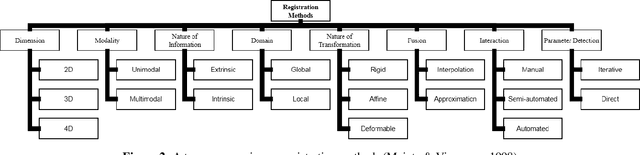
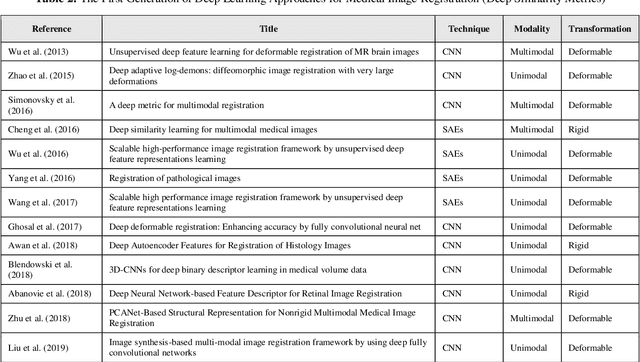
Image-guided interventions are saving the lives of a large number of patients where the image registration problem should indeed be considered as the most complex and complicated issue to be tackled. On the other hand, the recently huge progress in the field of machine learning made by the possibility of implementing deep neural networks on the contemporary many-core GPUs opened up a promising window to challenge with many medical applications, where the registration is not an exception. In this paper, a comprehensive review on the state-of-the-art literature known as medical image registration using deep neural networks is presented. The review is systematic and encompasses all the related works previously published in the field. Key concepts, statistical analysis from different points of view, confiding challenges, novelties and main contributions, key-enabling techniques, future directions and prospective trends all are discussed and surveyed in details in this comprehensive review. This review allows a deep understanding and insight for the readers active in the field who are investigating the state-of-the-art and seeking to contribute the future literature.
Fast-Slow Transformer for Visually Grounding Speech
Sep 16, 2021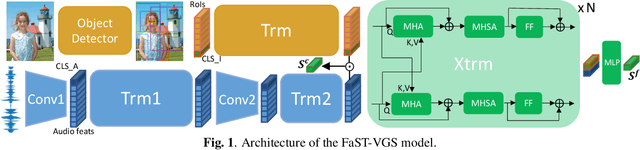
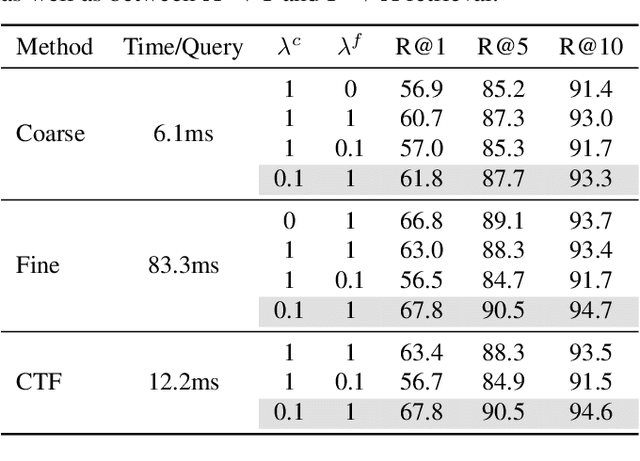
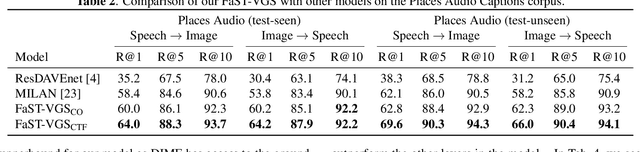
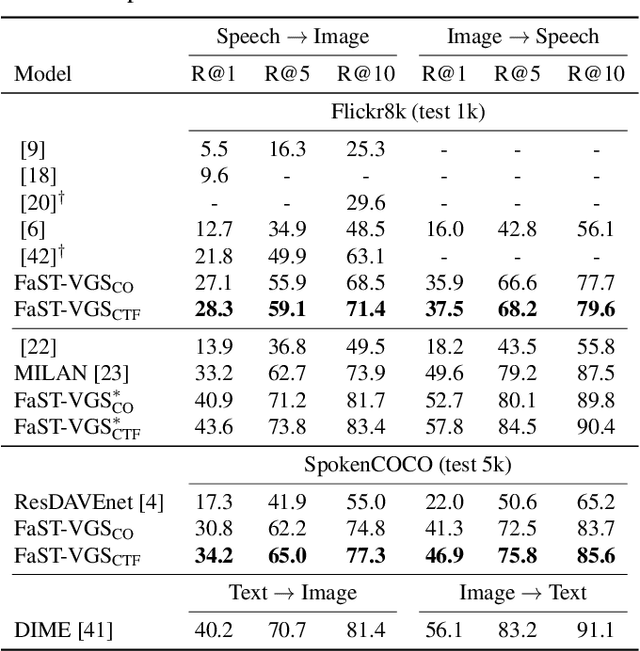
We present Fast-Slow Transformer for Visually Grounding Speech, or FaST-VGS. FaST-VGS is a Transformer-based model for learning the associations between raw speech waveforms and visual images. The model unifies dual-encoder and cross-attention architectures into a single model, reaping the superior retrieval speed of the former along with the accuracy of the latter. FaST-VGS achieves state-of-the-art speech-image retrieval accuracy on benchmark datasets, and its learned representations exhibit strong performance on the ZeroSpeech 2021 phonetic and semantic tasks.
SwinBERT: End-to-End Transformers with Sparse Attention for Video Captioning
Nov 25, 2021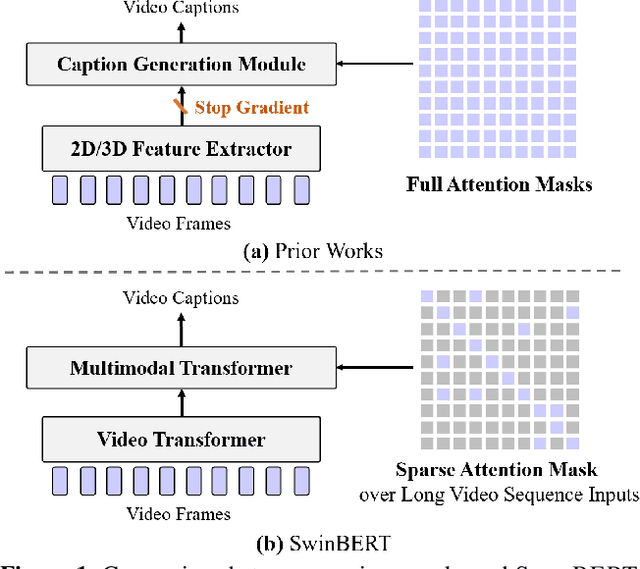

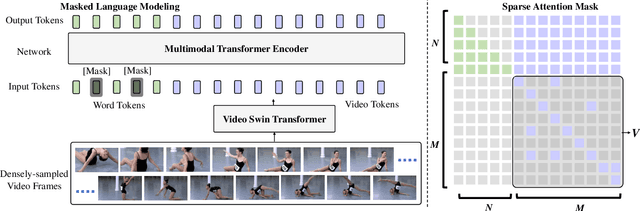
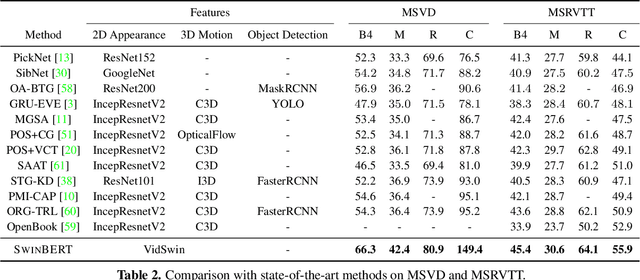
The canonical approach to video captioning dictates a caption generation model to learn from offline-extracted dense video features. These feature extractors usually operate on video frames sampled at a fixed frame rate and are often trained on image/video understanding tasks, without adaption to video captioning data. In this work, we present SwinBERT, an end-to-end transformer-based model for video captioning, which takes video frame patches directly as inputs, and outputs a natural language description. Instead of leveraging multiple 2D/3D feature extractors, our method adopts a video transformer to encode spatial-temporal representations that can adapt to variable lengths of video input without dedicated design for different frame rates. Based on this model architecture, we show that video captioning can benefit significantly from more densely sampled video frames as opposed to previous successes with sparsely sampled video frames for video-and-language understanding tasks (e.g., video question answering). Moreover, to avoid the inherent redundancy in consecutive video frames, we propose adaptively learning a sparse attention mask and optimizing it for task-specific performance improvement through better long-range video sequence modeling. Through extensive experiments on 5 video captioning datasets, we show that SwinBERT achieves across-the-board performance improvements over previous methods, often by a large margin. The learned sparse attention masks in addition push the limit to new state of the arts, and can be transferred between different video lengths and between different datasets.
Fully Automated Image De-fencing using Conditional Generative Adversarial Networks
Aug 19, 2019
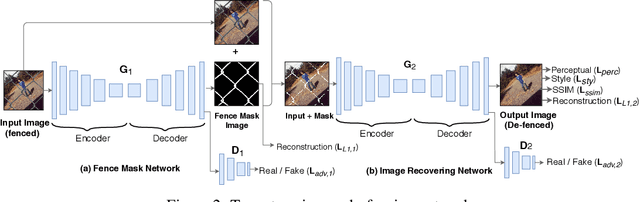
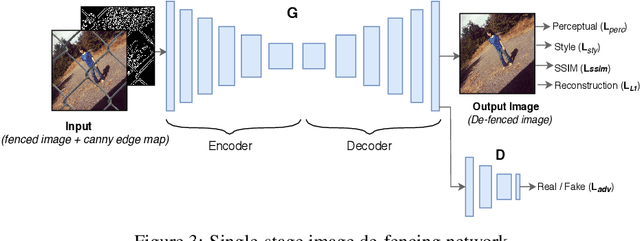

Image de-fencing is one of the important aspects of recreational photography in which the objective is to remove the fence texture present in an image and generate an aesthetically pleasing version of the same image without the fence texture. In this paper, we aim to develop an automated and effective technique for fence removal and image reconstruction using conditional Generative Adversarial Networks (cGANs). These networks have been successfully applied in several domains of Computer Vision focusing on image generation and rendering. Our initial approach is based on a two-stage architecture involving two cGANs that generate the fence mask and the inpainted image, respectively. Training of these networks is carried out independently and, during evaluation, the input image is passed through the two generators in succession to obtain the de-fenced image. The results obtained from this approach are satisfactory, but the response time is long since the image has to pass through two sets of convolution layers. To reduce the response time, we propose a second approach involving only a single cGAN architecture that is trained using the ground-truth of fenced de-fenced image pairs along with the edge map of the fenced image produced by the Canny Filter. Incorporation of the edge map helps the network to precisely detect the edges present in the input image, and also imparts it an ability to carry out high quality de-fencing in an efficient manner, even in the presence of a fewer number of layers as compared to the two-stage network. Qualitative and quantitative experimental results reported in the manuscript reveal that the de-fenced images generated by the single-stage de-fencing network have similar visual quality to those produced by the two-stage network. Comparative performance analysis also emphasizes the effectiveness of our approach over state-of-the-art image de-fencing techniques.
The power of pictures: using ML assisted image generation to engage the crowd in complex socioscientific problems
Oct 15, 2020
Human-computer image generation using Generative Adversarial Networks (GANs) is becoming a well-established methodology for casual entertainment and open artistic exploration. Here, we take the interaction a step further by weaving in carefully structured design elements to transform the activity of ML-assisted imaged generation into a catalyst for large-scale popular dialogue on complex socioscientific problems such as the United Nations Sustainable Development Goals (SDGs) and as a gateway for public participation in research.