 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CoCo DistillNet: a Cross-layer Correlation Distillation Network for Pathological Gastric Cancer Segmentation
Aug 27, 2021

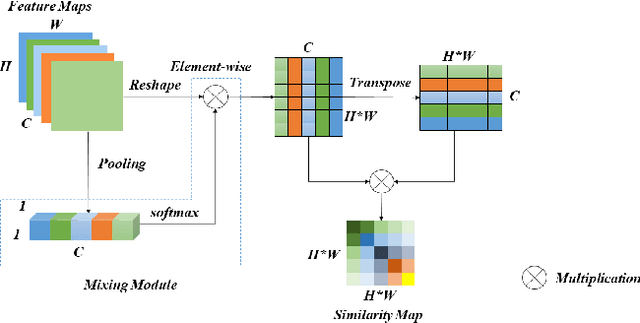

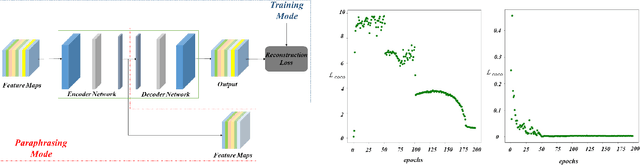
In recent years, deep convolutional neural networks have made significant advances in pathology image segmentation. However, pathology image segmentation encounters with a dilemma in which the higher-performance networks generally require more computational resources and storage. This phenomenon limits the employment of high-accuracy networks in real scenes due to the inherent high-resolution of pathological images. To tackle this problem, we propose CoCo DistillNet, a novel Cross-layer Correlation (CoCo) knowledge distillation network for pathological gastric cancer segmentation. Knowledge distillation, a general technique which aims at improving the performance of a compact network through knowledge transfer from a cumbersome network. Concretely, our CoCo DistillNet models the correlations of channel-mixed spatial similarity between different layers and then transfers this knowledge from a pre-trained cumbersome teacher network to a non-trained compact student network. In addition, we also utilize the adversarial learning strategy to further prompt the distilling procedure which is called Adversarial Distillation (AD). Furthermore, to stabilize our training procedure, we make the use of the unsupervised Paraphraser Module (PM) to boost the knowledge paraphrase in the teacher network. As a result, extensive experiments conducted on the Gastric Cancer Segmentation Dataset demonstrate the prominent ability of CoCo DistillNet which achieves state-of-the-art performance.
SyMetric: Measuring the Quality of Learnt Hamiltonian Dynamics Inferred from Vision
Nov 10, 2021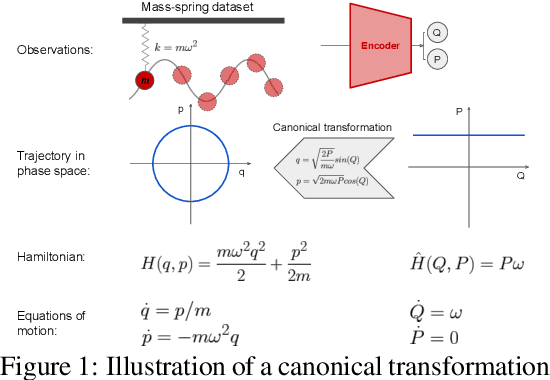

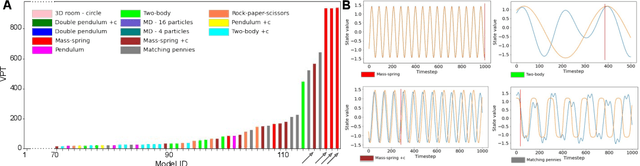
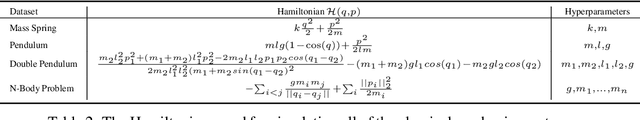
A recently proposed class of models attempts to learn latent dynamics from high-dimensional observations, like images, using priors informed by Hamiltonian mechanics. While these models have important potential applications in areas like robotics or autonomous driving, there is currently no good way to evaluate their performance: existing methods primarily rely on image reconstruction quality, which does not always reflect the quality of the learnt latent dynamics. In this work, we empirically highlight the problems with the existing measures and develop a set of new measures, including a binary indicator of whether the underlying Hamiltonian dynamics have been faithfully captured, which we call Symplecticity Metric or SyMetric. Our measures take advantage of the known properties of Hamiltonian dynamics and are more discriminative of the model's ability to capture the underlying dynamics than reconstruction error. Using SyMetric, we identify a set of architectural choices that significantly improve the performance of a previously proposed model for inferring latent dynamics from pixels, the Hamiltonian Generative Network (HGN). Unlike the original HGN, the new HGN++ is able to discover an interpretable phase space with physically meaningful latents on some datasets. Furthermore, it is stable for significantly longer rollouts on a diverse range of 13 datasets, producing rollouts of essentially infinite length both forward and backwards in time with no degradation in quality on a subset of the datasets.
Text-to-image synthesis method evaluation based on visual patterns
Oct 31, 2019
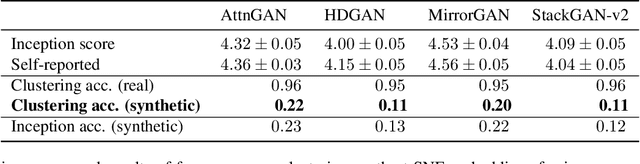
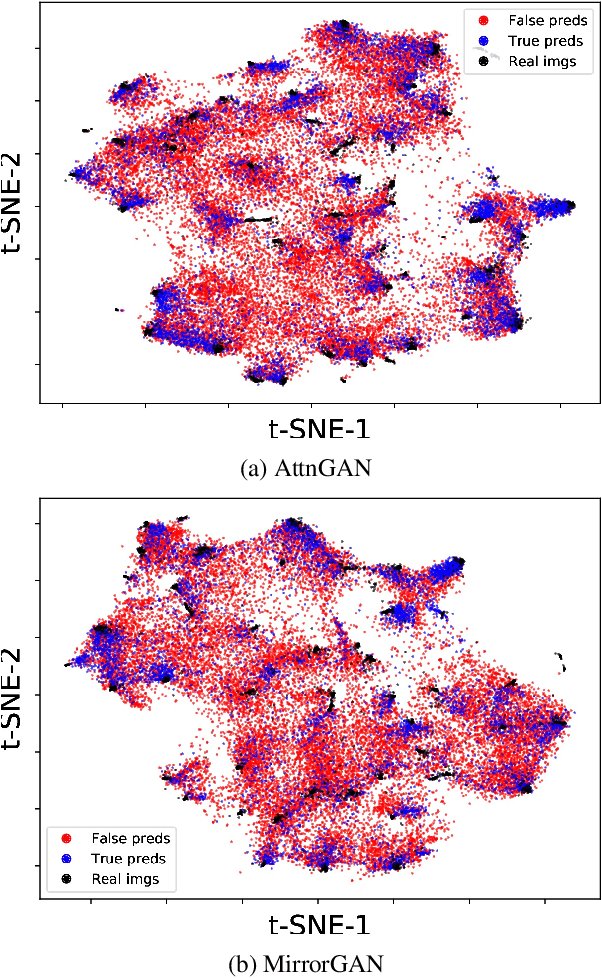
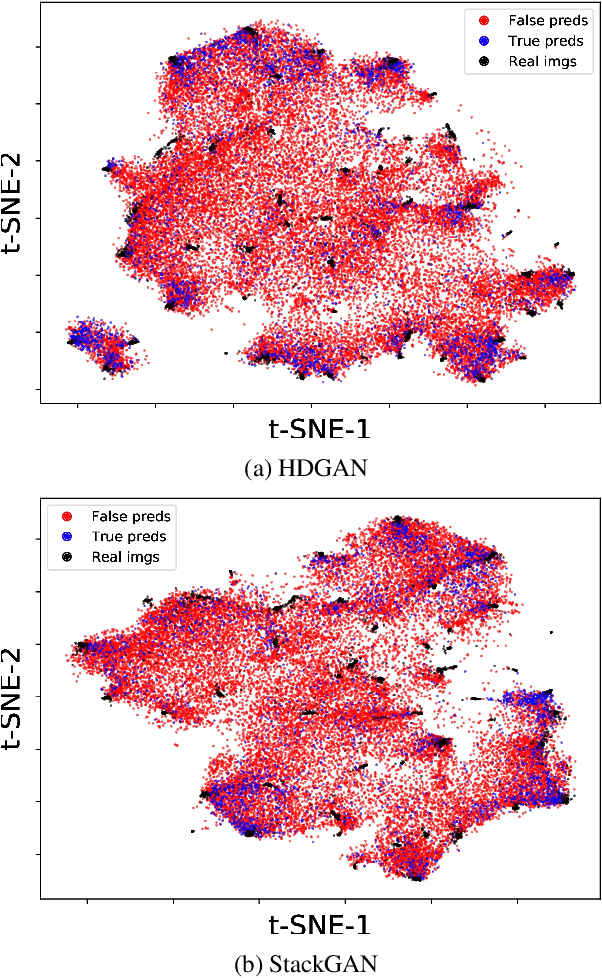
A commonly used evaluation metric for text-to-image synthesis is the Inception score (IS) \cite{inceptionscore}, which has been shown to be a quality metric that correlates well with human judgment. However, IS does not reveal properties of the generated images indicating the ability of a text-to-image synthesis method to correctly convey semantics of the input text descriptions. In this paper, we introduce an evaluation metric and a visual evaluation method allowing for the simultaneous estimation of the realism, variety and semantic accuracy of generated images. The proposed method uses a pre-trained Inception network \cite{inceptionnet} to produce high dimensional representations for both real and generated images. These image representations are then visualized in a $2$-dimensional feature space defined by the t-distributed Stochastic Neighbor Embedding (t-SNE) \cite{tsne}. Visual concepts are determined by clustering the real image representations, and are subsequently used to evaluate the similarity of the generated images to the real ones by classifying them to the closest visual concept. The resulting classification accuracy is shown to be a effective gauge for the semantic accuracy of text-to-image synthesis methods.
Anomaly Detection of Defect using Energy of Point Pattern Features within Random Finite Set Framework
Aug 27, 2021
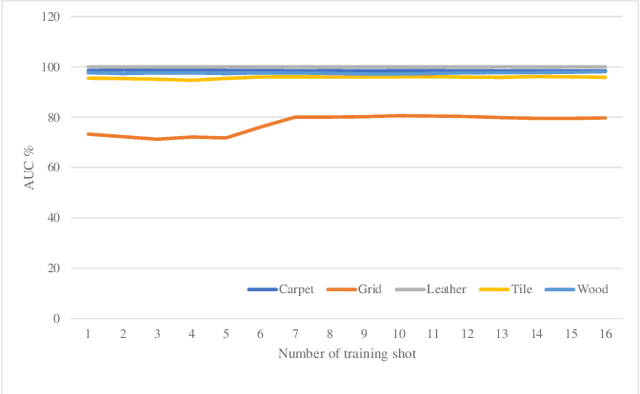
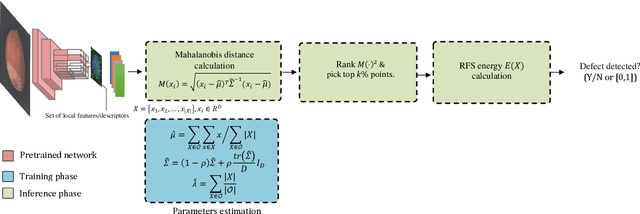

In this paper, we propose an efficient approach for industrial defect detection that is modeled based on anomaly detection using point pattern data. Most recent works use \textit{global features} for feature extraction to summarize image content. However, global features are not robust against lighting and viewpoint changes and do not describe the image's geometrical information to be fully utilized in the manufacturing industry. To the best of our knowledge, we are the first to propose using transfer learning of local/point pattern features to overcome these limitations and capture geometrical information of the image regions. We model these local/point pattern features as a random finite set (RFS). In addition we propose RFS energy, in contrast to RFS likelihood as anomaly score. The similarity distribution of point pattern features of the normal sample has been modeled as a multivariate Gaussian. Parameters learning of the proposed RFS energy does not require any heavy computation. We evaluate the proposed approach on the MVTec AD dataset, a multi-object defect detection dataset. Experimental results show the outstanding performance of our proposed approach compared to the state-of-the-art methods, and the proposed RFS energy outperforms the state-of-the-art in the few shot learning settings.
Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation
Sep 25, 2021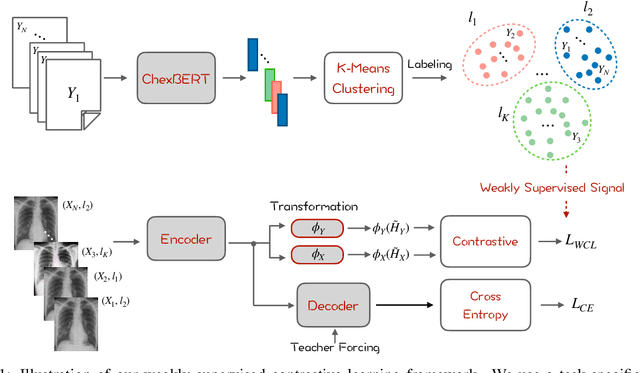
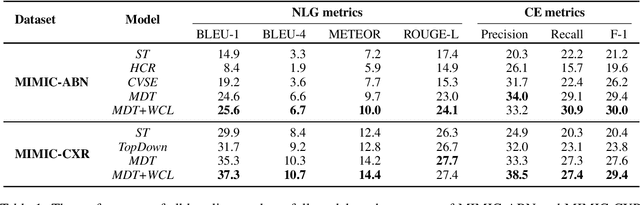
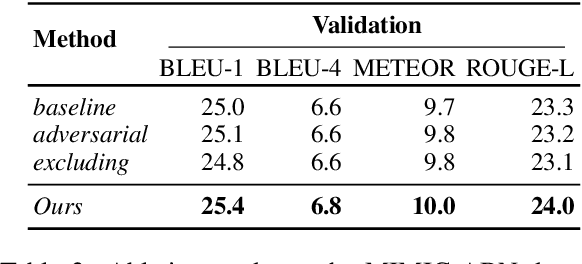
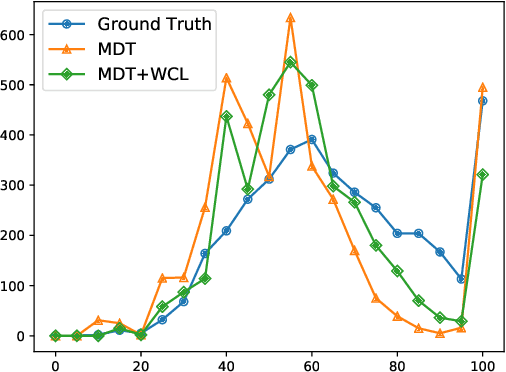
Radiology report generation aims at generating descriptive text from radiology images automatically, which may present an opportunity to improve radiology reporting and interpretation. A typical setting consists of training encoder-decoder models on image-report pairs with a cross entropy loss, which struggles to generate informative sentences for clinical diagnoses since normal findings dominate the datasets. To tackle this challenge and encourage more clinically-accurate text outputs, we propose a novel weakly supervised contrastive loss for medical report generation. Experimental results demonstrate that our method benefits from contrasting target reports with incorrect but semantically-close ones. It outperforms previous work on both clinical correctness and text generation metrics for two public benchmarks.
Representing Prior Knowledge Using Randomly, Weighted Feature Networks for Visual Relationship Detection
Nov 20, 2021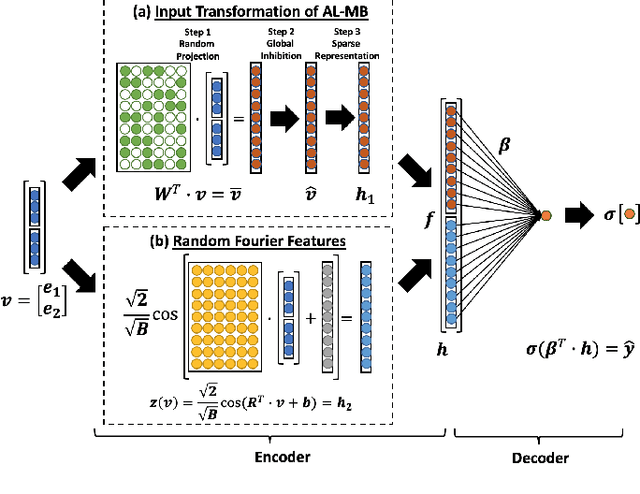
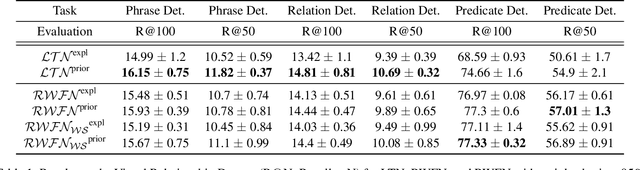
The single-hidden-layer Randomly Weighted Feature Network (RWFN) introduced by Hong and Pavlic (2021) was developed as an alternative to neural tensor network approaches for relational learning tasks. Its relatively small footprint combined with the use of two randomized input projections -- an insect-brain-inspired input representation and random Fourier features -- allow it to achieve rich expressiveness for relational learning with relatively low training cost. In particular, when Hong and Pavlic compared RWFN to Logic Tensor Networks (LTNs) for Semantic Image Interpretation (SII) tasks to extract structured semantic descriptions from images, they showed that the RWFN integration of the two hidden, randomized representations better captures relationships among inputs with a faster training process even though it uses far fewer learnable parameters. In this paper, we use RWFNs to perform Visual Relationship Detection (VRD) tasks, which are more challenging SII tasks. A zero-shot learning approach is used with RWFN that can exploit similarities with other seen relationships and background knowledge -- expressed with logical constraints between subjects, relations, and objects -- to achieve the ability to predict triples that do not appear in the training set. The experiments on the Visual Relationship Dataset to compare the performance between RWFNs and LTNs, one of the leading Statistical Relational Learning frameworks, show that RWFNs outperform LTNs for the predicate-detection task while using fewer number of adaptable parameters (1:56 ratio). Furthermore, background knowledge represented by RWFNs can be used to alleviate the incompleteness of training sets even though the space complexity of RWFNs is much smaller than LTNs (1:27 ratio).
Exploring Data Aggregation and Transformations to Generalize across Visual Domains
Aug 20, 2021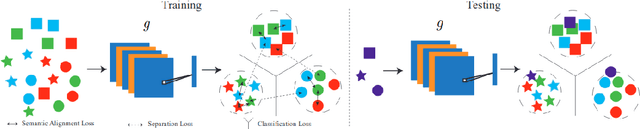

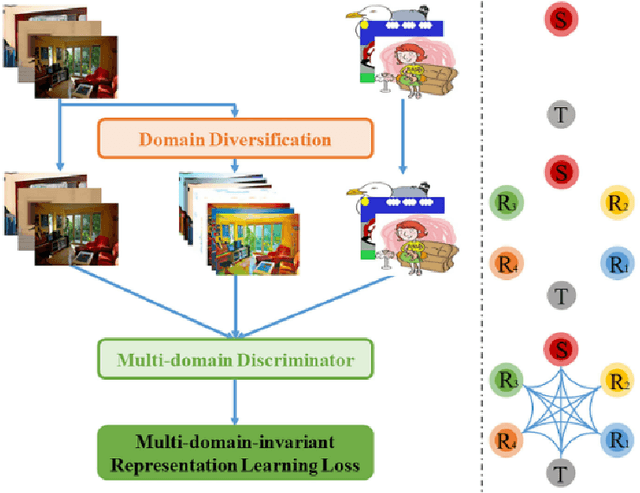

Computer vision has flourished in recent years thanks to Deep Learning advancements, fast and scalable hardware solutions and large availability of structured image data. Convolutional Neural Networks trained on supervised tasks with backpropagation learn to extract meaningful representations from raw pixels automatically, and surpass shallow methods in image understanding. Though convenient, data-driven feature learning is prone to dataset bias: a network learns its parameters from training signals alone, and will usually perform poorly if train and test distribution differ. To alleviate this problem, research on Domain Generalization (DG), Domain Adaptation (DA) and their variations is increasing. This thesis contributes to these research topics by presenting novel and effective ways to solve the dataset bias problem in its various settings. We propose new frameworks for Domain Generalization and Domain Adaptation which make use of feature aggregation strategies and visual transformations via data-augmentation and multi-task integration of self-supervision. We also design an algorithm that adapts an object detection model to any out of distribution sample at test time. With through experimentation, we show how our proposed solutions outperform competitive state-of-the-art approaches in established DG and DA benchmarks.
Iris Recognition Based on SIFT Features
Oct 30, 2021Biometric methods based on iris images are believed to allow very high accuracy, and there has been an explosion of interest in iris biometrics in recent years. In this paper, we use the Scale Invariant Feature Transformation (SIFT) for recognition using iris images. Contrarily to traditional iris recognition systems, the SIFT approach does not rely on the transformation of the iris pattern to polar coordinates or on highly accurate segmentation, allowing less constrained image acquisition conditions. We extract characteristic SIFT feature points in scale space and perform matching based on the texture information around the feature points using the SIFT operator. Experiments are done using the BioSec multimodal database, which includes 3,200 iris images from 200 individuals acquired in two different sessions. We contribute with the analysis of the influence of different SIFT parameters on the recognition performance. We also show the complementarity between the SIFT approach and a popular matching approach based on transformation to polar coordinates and Log-Gabor wavelets. The combination of the two approaches achieves significantly better performance than either of the individual schemes, with a performance improvement of 24% in the Equal Error Rate.
Dynamic Differential-Privacy Preserving SGD
Oct 30, 2021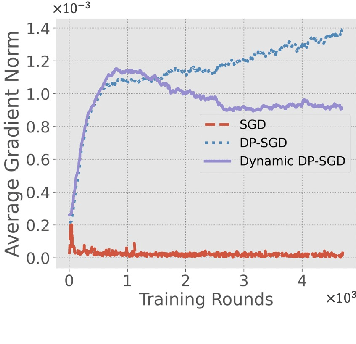
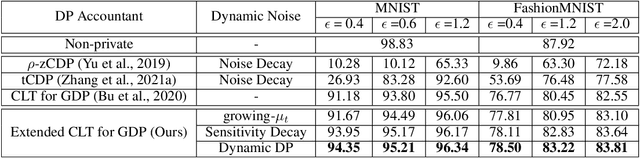
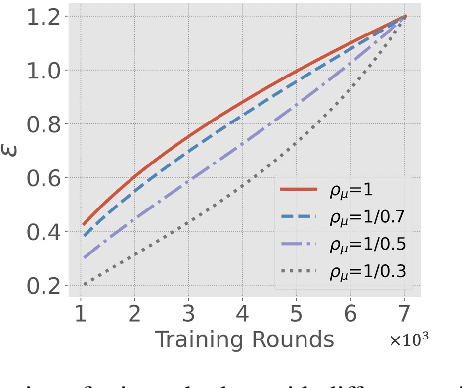
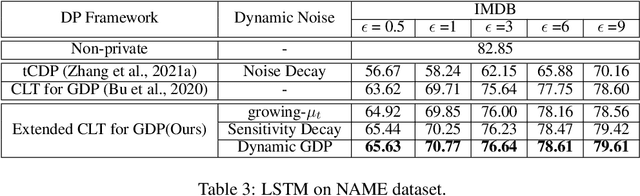
Differentially-Private Stochastic Gradient Descent (DP-SGD) prevents training-data privacy breaches by adding noise to the clipped gradient during SGD training to satisfy the differential privacy (DP) definition. On the other hand, the same clipping operation and additive noise across training steps results in unstable updates and even a ramp-up period, which significantly reduces the model's accuracy. In this paper, we extend the Gaussian DP central limit theorem to calibrate the clipping value and the noise power for each individual step separately. We, therefore, are able to propose the dynamic DP-SGD, which has a lower privacy cost than the DP-SGD during updates until they achieve the same target privacy budget at a target number of updates. Dynamic DP-SGD, in particular, improves model accuracy without sacrificing privacy by gradually lowering both clipping value and noise power while adhering to a total privacy budget constraint. Extensive experiments on a variety of deep learning tasks, including image classification, natural language processing, and federated learning, show that the proposed dynamic DP-SGD algorithm stabilizes updates and, as a result, significantly improves model accuracy in the strong privacy protection region when compared to DP-SGD.
FBNet: Feature Balance Network for Urban-Scene Segmentation
Nov 05, 2021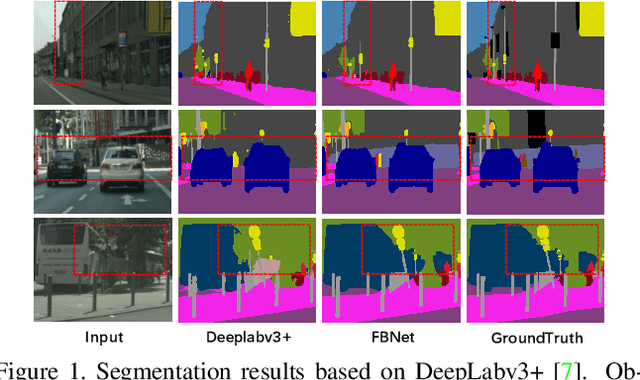


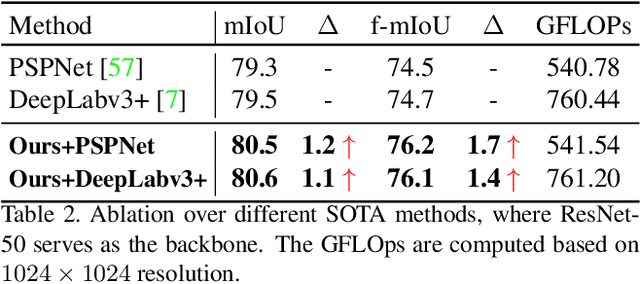
Image segmentation in the urban scene has recently attracted much attention due to its success in autonomous driving systems. However, the poor performance of concerned foreground targets, e.g., traffic lights and poles, still limits its further practical applications. In urban scenes, foreground targets are always concealed in their surrounding stuff because of the special camera position and 3D perspective projection. What's worse, it exacerbates the unbalance between foreground and background classes in high-level features due to the continuous expansion of the reception field. We call it Feature Camouflage. In this paper, we present a novel add-on module, named Feature Balance Network (FBNet), to eliminate the feature camouflage in urban-scene segmentation. FBNet consists of two key components, i.e., Block-wise BCE(BwBCE) and Dual Feature Modulator(DFM). BwBCE serves as an auxiliary loss to ensure uniform gradients for foreground classes and their surroundings during backpropagation. At the same time, DFM intends to enhance the deep representation of foreground classes in high-level features adaptively under the supervision of BwBCE. These two modules facilitate each other as a whole to ease feature camouflage effectively. Our proposed method achieves a new state-of-the-art segmentation performance on two challenging urban-scene benchmarks, i.e., Cityscapes and BDD100K. Code will be released for reproduction.