 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CoCo DistillNet: a Cross-layer Correlation Distillation Network for Pathological Gastric Cancer Segmentation
Aug 27, 2021

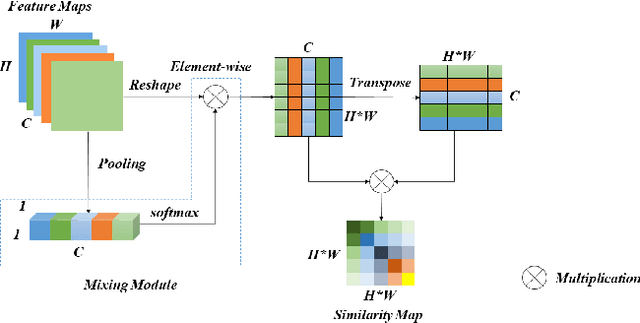

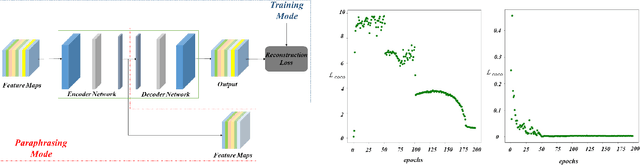
In recent years, deep convolutional neural networks have made significant advances in pathology image segmentation. However, pathology image segmentation encounters with a dilemma in which the higher-performance networks generally require more computational resources and storage. This phenomenon limits the employment of high-accuracy networks in real scenes due to the inherent high-resolution of pathological images. To tackle this problem, we propose CoCo DistillNet, a novel Cross-layer Correlation (CoCo) knowledge distillation network for pathological gastric cancer segmentation. Knowledge distillation, a general technique which aims at improving the performance of a compact network through knowledge transfer from a cumbersome network. Concretely, our CoCo DistillNet models the correlations of channel-mixed spatial similarity between different layers and then transfers this knowledge from a pre-trained cumbersome teacher network to a non-trained compact student network. In addition, we also utilize the adversarial learning strategy to further prompt the distilling procedure which is called Adversarial Distillation (AD). Furthermore, to stabilize our training procedure, we make the use of the unsupervised Paraphraser Module (PM) to boost the knowledge paraphrase in the teacher network. As a result, extensive experiments conducted on the Gastric Cancer Segmentation Dataset demonstrate the prominent ability of CoCo DistillNet which achieves state-of-the-art performance.
Anomaly Detection of Defect using Energy of Point Pattern Features within Random Finite Set Framework
Aug 27, 2021
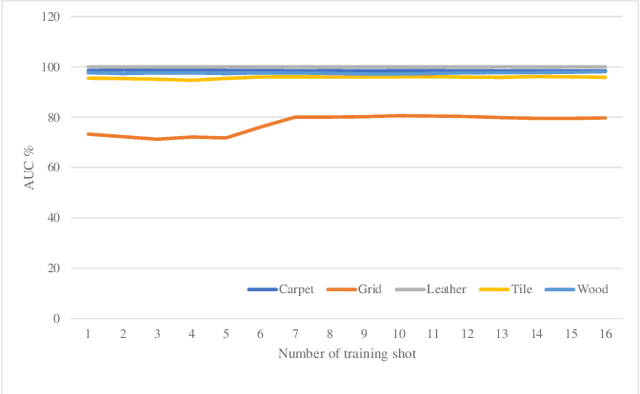
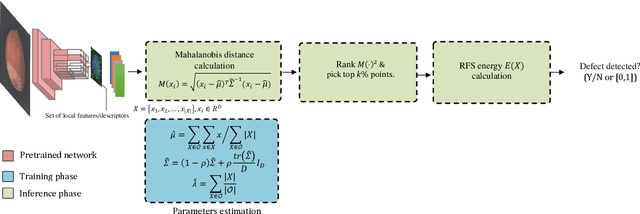

In this paper, we propose an efficient approach for industrial defect detection that is modeled based on anomaly detection using point pattern data. Most recent works use \textit{global features} for feature extraction to summarize image content. However, global features are not robust against lighting and viewpoint changes and do not describe the image's geometrical information to be fully utilized in the manufacturing industry. To the best of our knowledge, we are the first to propose using transfer learning of local/point pattern features to overcome these limitations and capture geometrical information of the image regions. We model these local/point pattern features as a random finite set (RFS). In addition we propose RFS energy, in contrast to RFS likelihood as anomaly score. The similarity distribution of point pattern features of the normal sample has been modeled as a multivariate Gaussian. Parameters learning of the proposed RFS energy does not require any heavy computation. We evaluate the proposed approach on the MVTec AD dataset, a multi-object defect detection dataset. Experimental results show the outstanding performance of our proposed approach compared to the state-of-the-art methods, and the proposed RFS energy outperforms the state-of-the-art in the few shot learning settings.
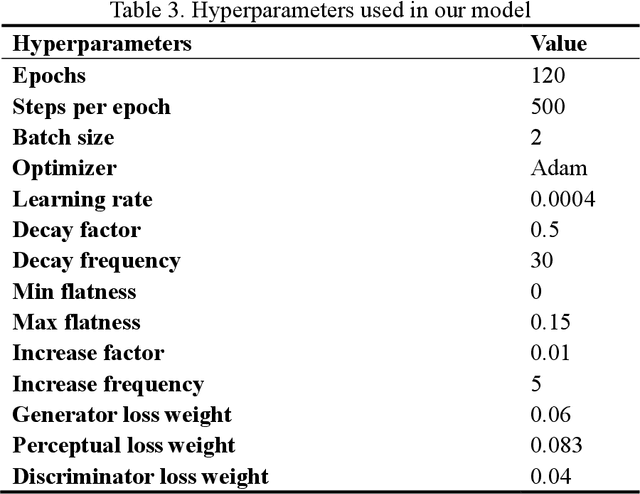
FCCDN: Feature Constraint Network for VHR Image Change Detection
May 23, 2021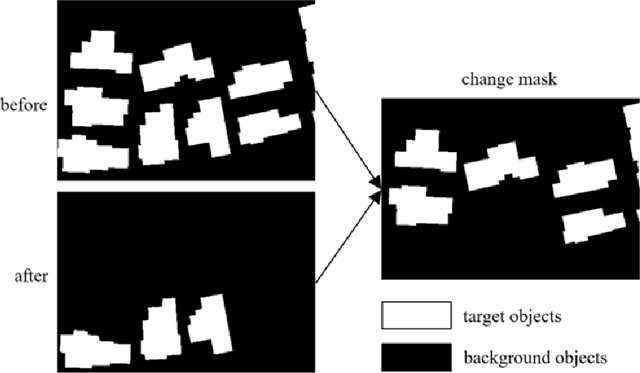

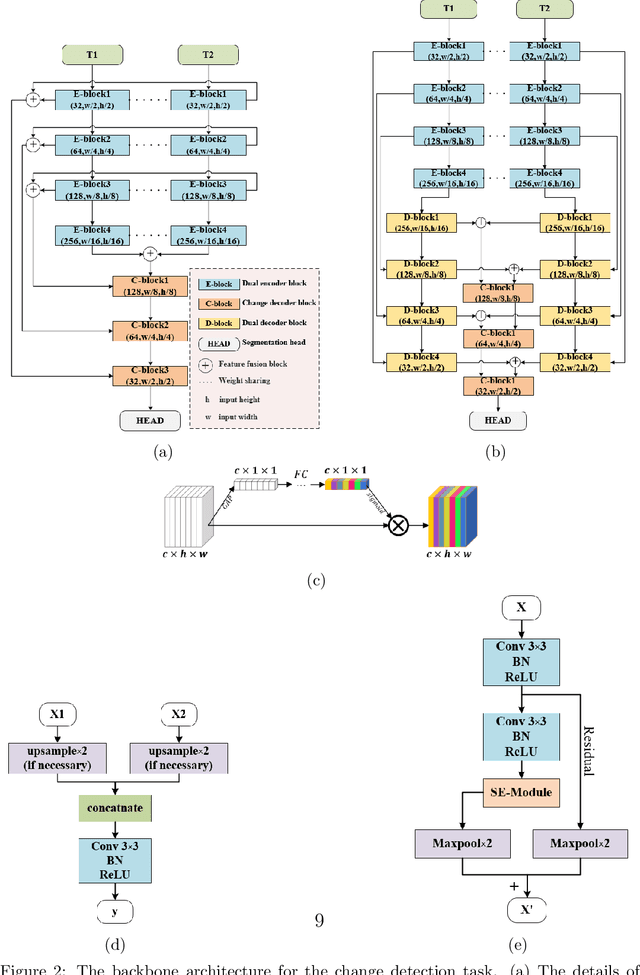
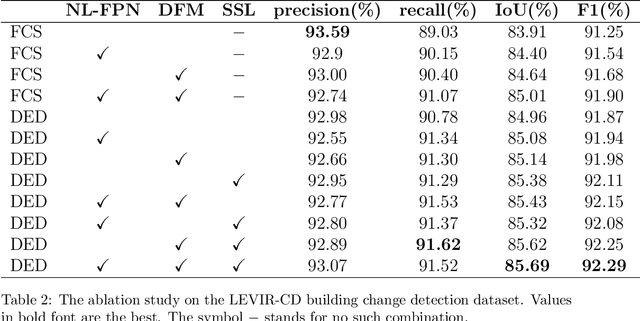
Change detection is the process of identifying pixel-wise differences of bi-temporal co-registered images. It is of great significance to Earth observation. Recently, with the emerging of deep learning (DL), deep convolutional neural networks (CNNs) based methods have shown their power and feasibility in the field of change detection. However, there is still a lack of effective supervision for change feature learning. In this work, a feature constraint change detection network (FCCDN) is proposed. We constrain features both on bi-temporal feature extraction and feature fusion. More specifically, we propose a dual encoder-decoder network backbone for the change detection task. At the center of the backbone, we design a non-local feature pyramid network to extract and fuse multi-scale features. To fuse bi-temporal features in a robust way, we build a dense connection-based feature fusion module. Moreover, a self-supervised learning-based strategy is proposed to constrain feature learning. Based on FCCDN, we achieve state-of-the-art performance on two building change detection datasets (LEVIR-CD and WHU). On the LEVIR-CD dataset, we achieve IoU of 0.8569 and F1 score of 0.9229. On the WHU dataset, we achieve IoU of 0.8820 and F1 score of 0.9373. Moreover, we, for the first time, achieve the acquire of accurate bi-temporal semantic segmentation results without using semantic segmentation labels. It is vital for the application of change detection because it saves the cost of labeling.
Multi-scale super-resolution generation of low-resolution scanned pathological images
May 15, 2021

Digital pathology slide is easy to store and manage, convenient to browse and transmit. However, because of the high-resolution scan for example 40 times magnification(40X) during the digitization, the file size of each whole slide image exceeds 1Gigabyte, which eventually leads to huge storage capacity and very slow network transmission. We design a strategy to scan slides with low resolution (5X) and a super-resolution method is proposed to restore the image details when in diagnosis. The method is based on a multi-scale generative adversarial network, which sequentially generate three high-resolution images such as 10X, 20X and 40X. The perceived loss, generator loss of the generated images and real images are compared on three image resolutions, and a discriminator is used to evaluate the difference of highest-resolution generated image and real image. A dataset consisting of 100,000 pathological images from 10 types of human tissues is performed for training and testing the network. The generated images have high peak-signal-to-noise-ratio (PSNR) and structural-similarity-index (SSIM). The PSNR of 10X to 40X image are 24.16, 22.27 and 20.44, and the SSIM are 0.845, 0.680 and 0.512, which are better than other super-resolution networks such as DBPN, ESPCN, RDN, EDSR and MDSR. Moreover, visual inspections show that the generated high-resolution images by our network have enough details for diagnosis, good color reproduction and close to real images, while other five networks are severely blurred, local deformation or miss important details. Moreover, no significant differences can be found on pathological diagnosis based on the generated and real images. The proposed multi-scale network can generate good high-resolution pathological images, and will provide a low-cost storage (about 15MB/image on 5X), faster image sharing method for digital pathology.
Exploring Data Aggregation and Transformations to Generalize across Visual Domains
Aug 20, 2021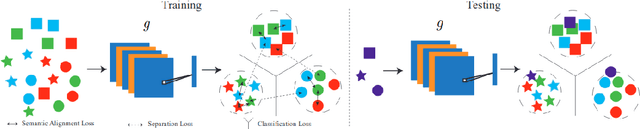

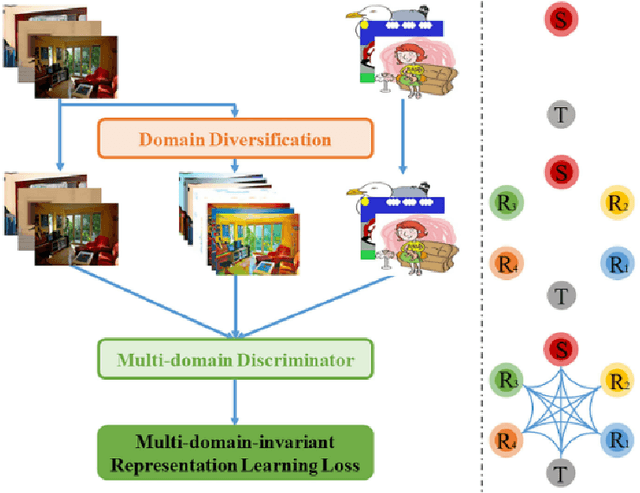

Computer vision has flourished in recent years thanks to Deep Learning advancements, fast and scalable hardware solutions and large availability of structured image data. Convolutional Neural Networks trained on supervised tasks with backpropagation learn to extract meaningful representations from raw pixels automatically, and surpass shallow methods in image understanding. Though convenient, data-driven feature learning is prone to dataset bias: a network learns its parameters from training signals alone, and will usually perform poorly if train and test distribution differ. To alleviate this problem, research on Domain Generalization (DG), Domain Adaptation (DA) and their variations is increasing. This thesis contributes to these research topics by presenting novel and effective ways to solve the dataset bias problem in its various settings. We propose new frameworks for Domain Generalization and Domain Adaptation which make use of feature aggregation strategies and visual transformations via data-augmentation and multi-task integration of self-supervision. We also design an algorithm that adapts an object detection model to any out of distribution sample at test time. With through experimentation, we show how our proposed solutions outperform competitive state-of-the-art approaches in established DG and DA benchmarks.
A Comprehensive Analysis of Weakly-Supervised Semantic Segmentation in Different Image Domains
Dec 24, 2019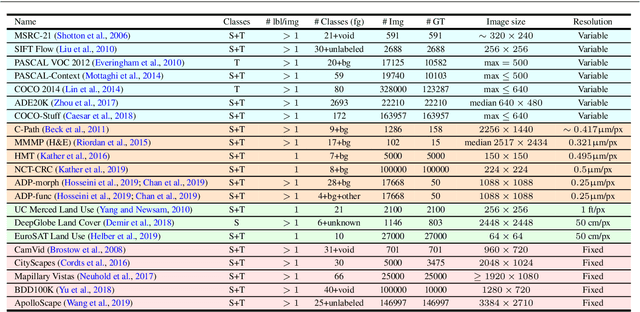
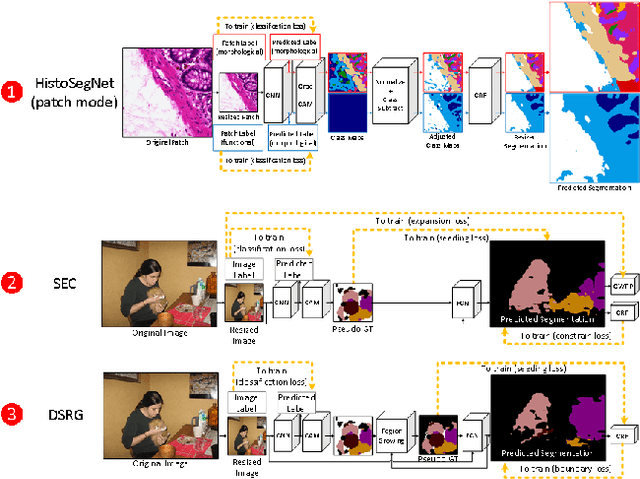
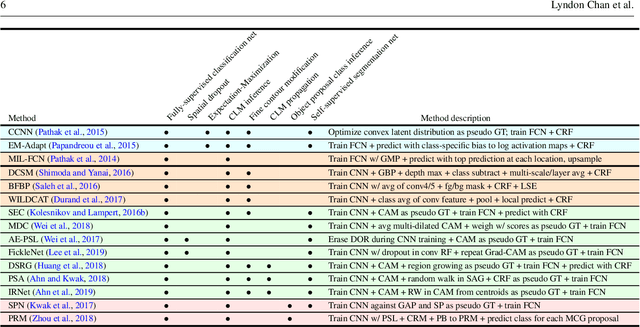
Recently proposed methods for weakly-supervised semantic segmentation have achieved impressive performance in predicting pixel classes despite being trained with only image labels which lack positional information. Because image annotations are cheaper and quicker to generate, weak supervision is more feasible for training segmentation algorithms in certain datasets. These methods have been predominantly developed on natural scene images and it is unclear whether they can be simply transferred to other domains with different characteristics, such as histopathology and satellite images, and still perform well. Little work has been conducted in the literature on applying weakly-supervised methods to these other image domains; it is unknown how to determine whether certain methods are more suitable for certain datasets, and how to determine the best method to use for a new dataset. This paper evaluates state-of-the-art weakly-supervised semantic segmentation methods on natural scene, histopathology, and satellite image datasets. We also analyze the compatibility of the methods for each dataset and present some principles for applying weakly-supervised semantic segmentation on an unseen image dataset.
Deviance Matrix Factorization
Oct 12, 2021
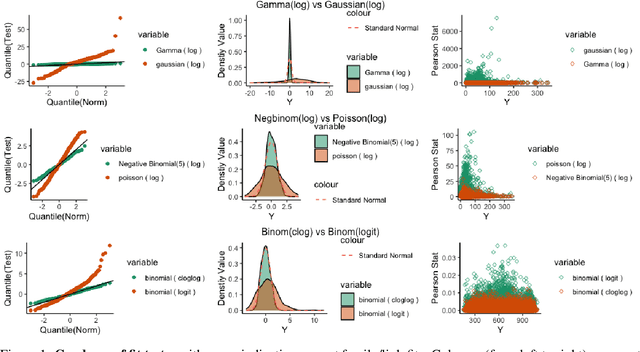
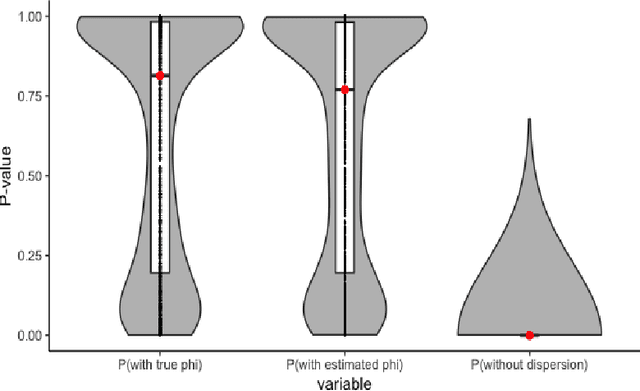

We investigate a general matrix factorization for deviance-based losses, extending the ubiquitous singular value decomposition beyond squared error loss. While similar approaches have been explored before, here we propose an efficient algorithm that is flexible enough to allow for structural zeros and entry weights. Moreover, we provide theoretical support for these decompositions by (i) showing strong consistency under a generalized linear model setup, (ii) checking the adequacy of a chosen exponential family via a generalized Hosmer-Lemeshow test, and (iii) determining the rank of the decomposition via a maximum eigenvalue gap method. To further support our findings, we conduct simulation studies to assess robustness to decomposition assumptions and extensive case studies using benchmark datasets from image face recognition, natural language processing, network analysis, and biomedical studies. Our theoretical and empirical results indicate that the proposed decomposition is more flexible, general, and can provide improved performance when compared to traditional methods.
Iterative Residual Image Deconvolution
Nov 04, 2018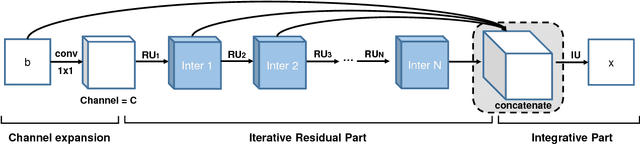
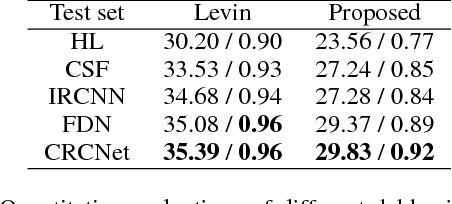

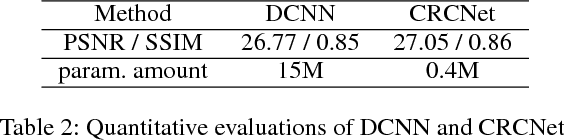
Image deblurring, a.k.a. image deconvolution, recovers a clear image from pixel superposition caused by blur degradation. Few deep convolutional neural networks (CNN) succeed in addressing this task. In this paper, we first demonstrate that the minimum-mean-square-error (MMSE) solution to image deblurring can be interestingly unfolded into a series of residual components. Based on this analysis, we propose a novel iterative residual deconvolution (IRD) algorithm. Further, IRD motivates us to take one step forward to design an explicable and effective CNN architecture for image deconvolution. Specifically, a sequence of residual CNN units are deployed, whose intermediate outputs are then concatenated and integrated, resulting in concatenated residual convolutional network (CRCNet). The experimental results demonstrate that proposed CRCNet not only achieves better quantitative metrics but also recovers more visually plausible texture details compared with state-of-the-art methods.
Webly Supervised Image Classification with Self-Contained Confidence
Aug 27, 2020
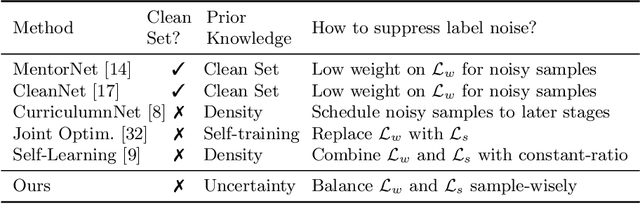
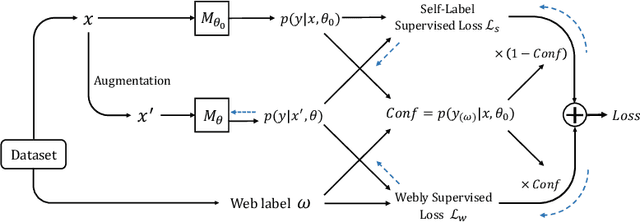
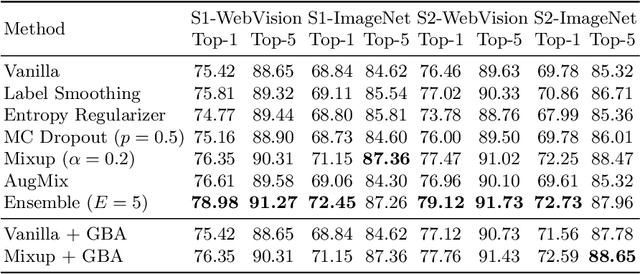
This paper focuses on webly supervised learning (WSL), where datasets are built by crawling samples from the Internet and directly using search queries as web labels. Although WSL benefits from fast and low-cost data collection, noises in web labels hinder better performance of the image classification model. To alleviate this problem, in recent works, self-label supervised loss $\mathcal{L}_s$ is utilized together with webly supervised loss $\mathcal{L}_w$. $\mathcal{L}_s$ relies on pseudo labels predicted by the model itself. Since the correctness of the web label or pseudo label is usually on a case-by-case basis for each web sample, it is desirable to adjust the balance between $\mathcal{L}_s$ and $\mathcal{L}_w$ on sample level. Inspired by the ability of Deep Neural Networks (DNNs) in confidence prediction, we introduce Self-Contained Confidence (SCC) by adapting model uncertainty for WSL setting, and use it to sample-wisely balance $\mathcal{L}_s$ and $\mathcal{L}_w$. Therefore, a simple yet effective WSL framework is proposed. A series of SCC-friendly regularization approaches are investigated, among which the proposed graph-enhanced mixup is the most effective method to provide high-quality confidence to enhance our framework. The proposed WSL framework has achieved the state-of-the-art results on two large-scale WSL datasets, WebVision-1000 and Food101-N. Code is available at https://github.com/bigvideoresearch/SCC.
MRI Image Reconstruction via Learning Optimization Using Neural ODEs
Jun 30, 2020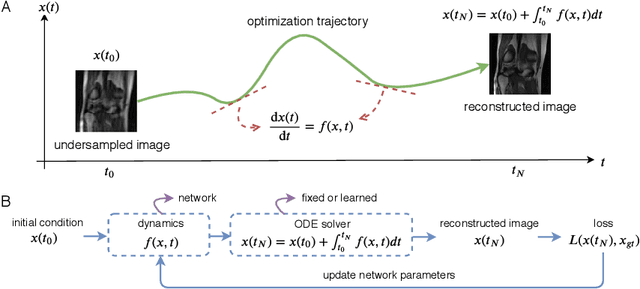
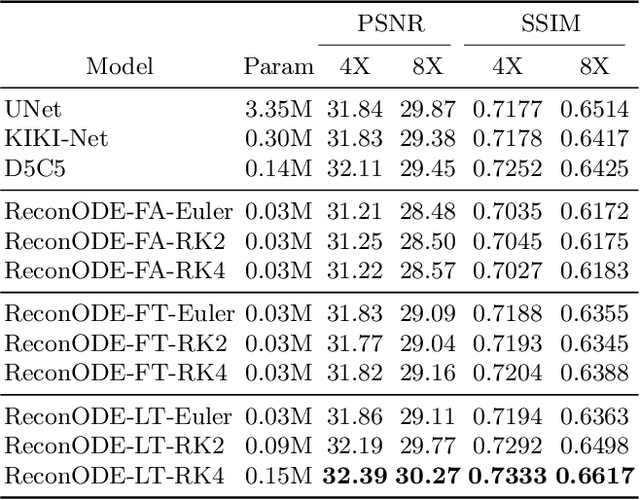
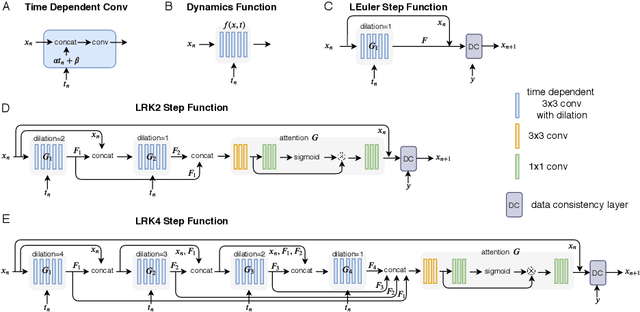
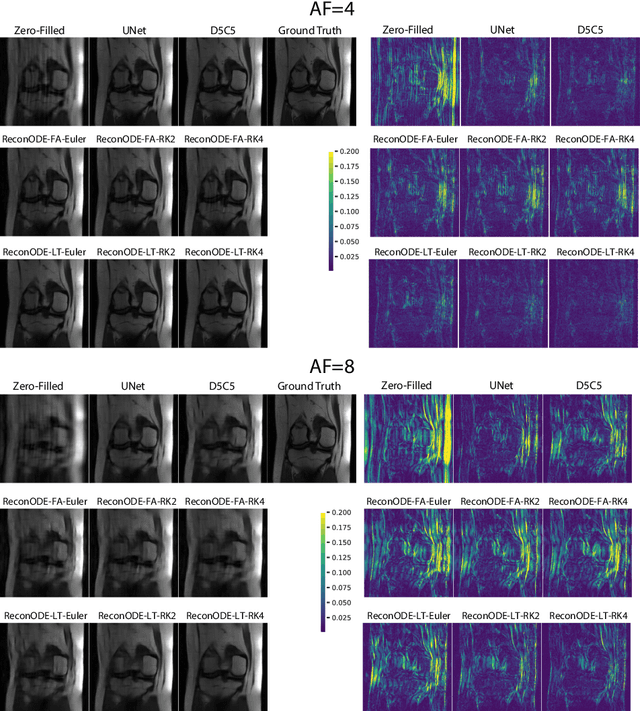
We propose to formulate MRI image reconstruction as an optimization problem and model the optimization trajectory as a dynamic process using ordinary differential equations (ODEs). We model the dynamics in ODE with a neural network and solve the desired ODE with the off-the-shelf (fixed) solver to obtain reconstructed images. We extend this model and incorporate the knowledge of off-the-shelf ODE solvers into the network design (learned solvers). We investigate several models based on three ODE solvers and compare models with fixed solvers and learned solvers. Our models achieve better reconstruction results and are more parameter efficient than other popular methods such as UNet and cascaded CNN. We introduce a new way of tackling the MRI reconstruction problem by modeling the continuous optimization dynamics using neural ODEs.