 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Early-exit deep neural networks for distorted images: providing an efficient edge offloading
Aug 20, 2021
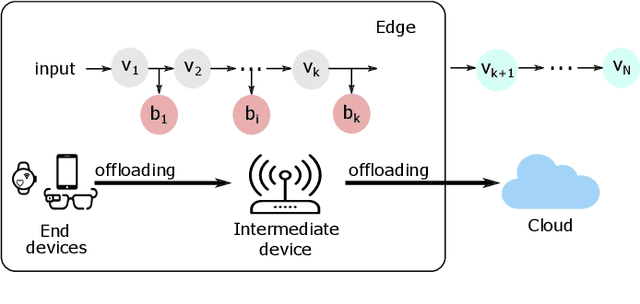
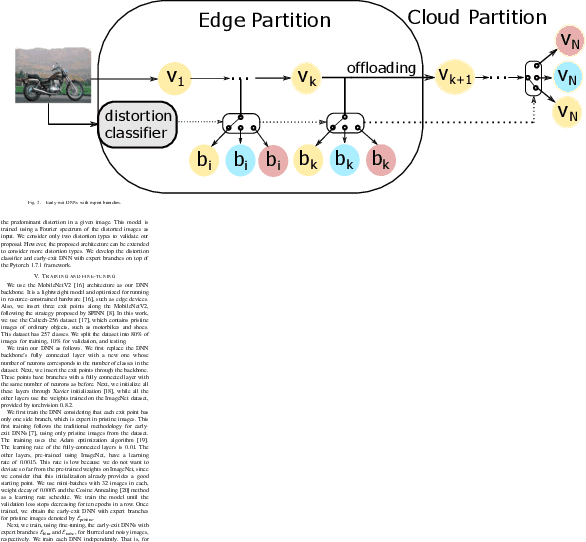
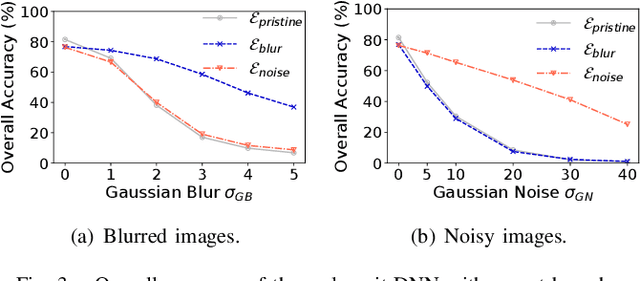
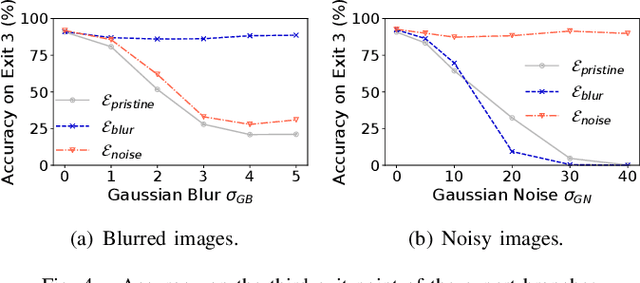
Edge offloading for deep neural networks (DNNs) can be adaptive to the input's complexity by using early-exit DNNs. These DNNs have side branches throughout their architecture, allowing the inference to end earlier in the edge. The branches estimate the accuracy for a given input. If this estimated accuracy reaches a threshold, the inference ends on the edge. Otherwise, the edge offloads the inference to the cloud to process the remaining DNN layers. However, DNNs for image classification deals with distorted images, which negatively impact the branches' estimated accuracy. Consequently, the edge offloads more inferences to the cloud. This work introduces expert side branches trained on a particular distortion type to improve robustness against image distortion. The edge detects the distortion type and selects appropriate expert branches to perform the inference. This approach increases the estimated accuracy on the edge, improving the offloading decisions. We validate our proposal in a realistic scenario, in which the edge offloads DNN inference to Amazon EC2 instances.
Combining chest X-rays and EHR data using machine learning to diagnose acute respiratory failure
Aug 27, 2021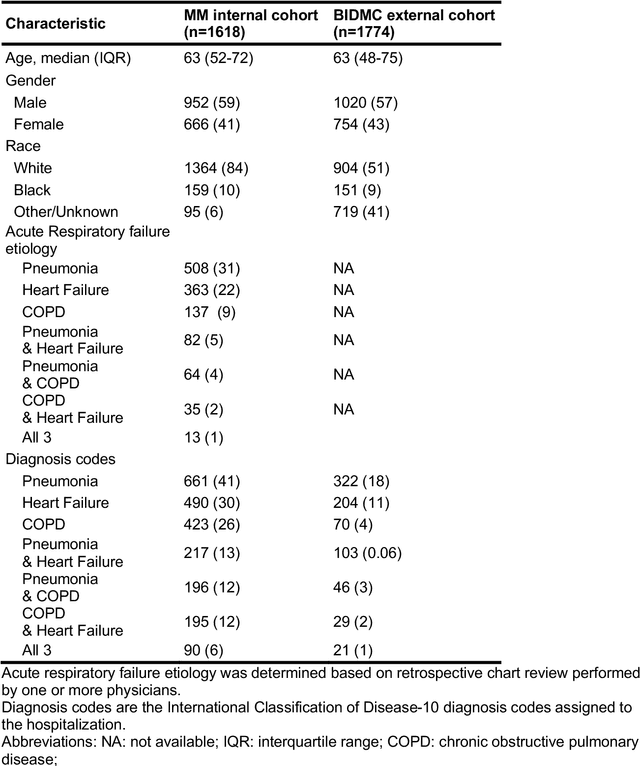
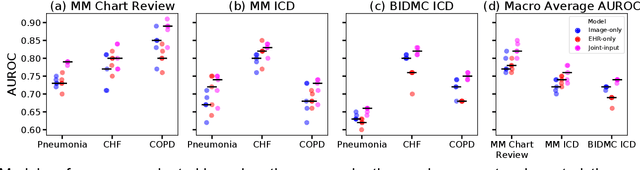
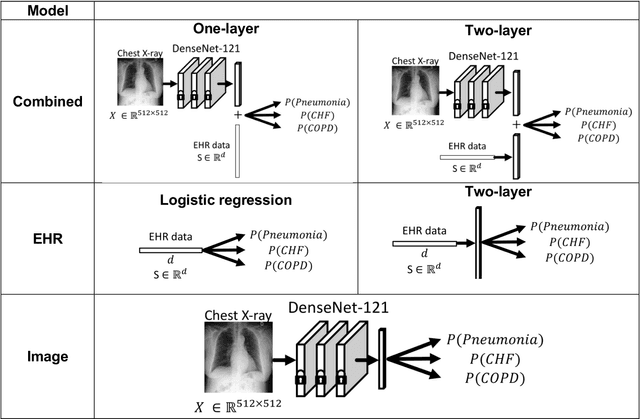
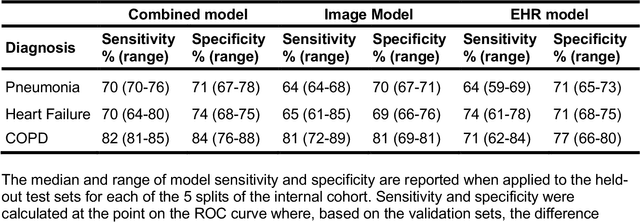
When patients develop acute respiratory failure, accurately identifying the underlying etiology is essential for determining the best treatment, but it can be challenging to differentiate between common diagnoses in clinical practice. Machine learning models could improve medical diagnosis by augmenting clinical decision making and play a role in the diagnostic evaluation of patients with acute respiratory failure. While machine learning models have been developed to identify common findings on chest radiographs (e.g. pneumonia), augmenting these approaches by also analyzing clinically relevant data from the electronic health record (EHR) could aid in the diagnosis of acute respiratory failure. Machine learning models were trained to predict the cause of acute respiratory failure (pneumonia, heart failure, and/or COPD) using chest radiographs and EHR data from patients within an internal cohort using diagnoses based on physician chart review. Models were also tested on patients in an external cohort using discharge diagnosis codes. A model combining chest radiographs and EHR data outperformed models based on each modality alone for pneumonia and COPD. For pneumonia, the combined model AUROC was 0.79 (0.78-0.79), image model AUROC was 0.73 (0.72-0.75), and EHR model AUROC was 0.73 (0.70-0.76); for COPD, combined: 0.89 (0.83-0.91), image: 0.85 (0.77-0.89), and EHR: 0.80 (0.76-0.84); for heart failure, combined: 0.80 (0.77-0.84), image: 0.77 (0.71-0.81), and EHR: 0.80 (0.75-0.82). In the external cohort, performance was consistent for heart failure and COPD, but declined slightly for pneumonia. Overall, machine learning models combing chest radiographs and EHR data can accurately differentiate between common causes of acute respiratory failure. Further work is needed to determine whether these models could aid clinicians in the diagnosis of acute respiratory failure in clinical settings.
RegNet: Learning the Optimization of Direct Image-to-Image Pose Registration
Dec 26, 2018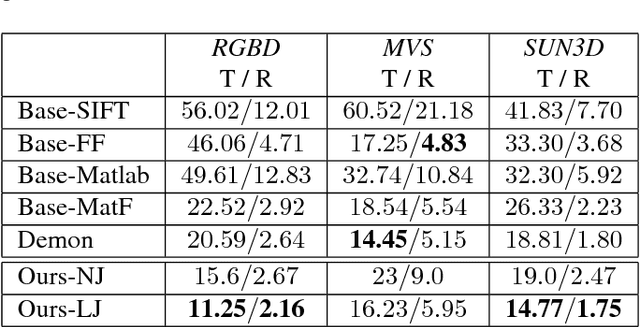
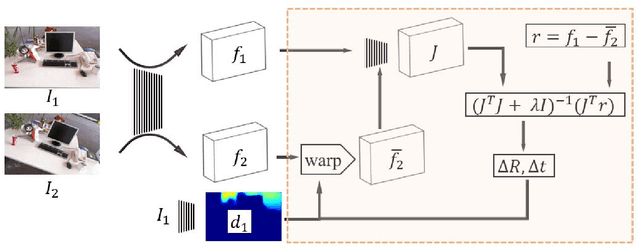

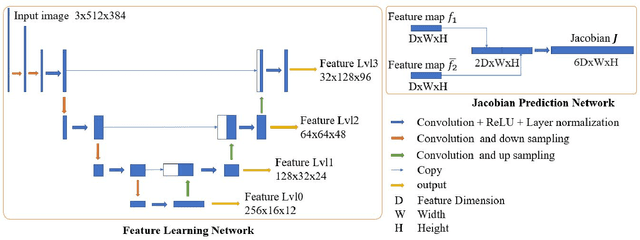
Direct image-to-image alignment that relies on the optimization of photometric error metrics suffers from limited convergence range and sensitivity to lighting conditions. Deep learning approaches has been applied to address this problem by learning better feature representations using convolutional neural networks, yet still require a good initialization. In this paper, we demonstrate that the inaccurate numerical Jacobian limits the convergence range which could be improved greatly using learned approaches. Based on this observation, we propose a novel end-to-end network, RegNet, to learn the optimization of image-to-image pose registration. By jointly learning feature representation for each pixel and partial derivatives that replace handcrafted ones (e.g., numerical differentiation) in the optimization step, the neural network facilitates end-to-end optimization. The energy landscape is constrained on both the feature representation and the learned Jacobian, hence providing more flexibility for the optimization as a consequence leads to more robust and faster convergence. In a series of experiments, including a broad ablation study, we demonstrate that RegNet is able to converge for large-baseline image pairs with fewer iterations.
Which Design Decisions in AI-enabled Mobile Applications Contribute to Greener AI?
Sep 28, 2021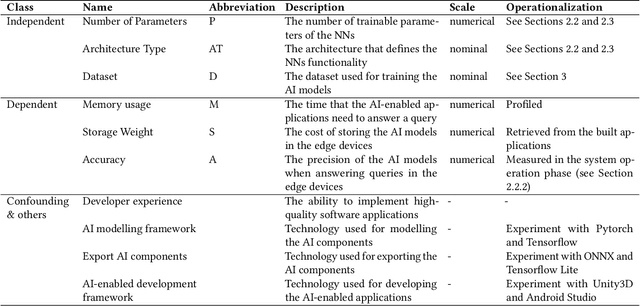
Background: The construction, evolution and usage of complex artificial intelligence (AI) models demand expensive computational resources. While currently available high-performance computing environments support well this complexity, the deployment of AI models in mobile devices, which is an increasing trend, is challenging. Mobile applications consist of environments with low computational resources and hence imply limitations in the design decisions during the AI-enabled software engineering lifecycle that balance the trade-off between the accuracy and the complexity of the mobile applications. Objective: Our objective is to systematically assess the trade-off between accuracy and complexity when deploying complex AI models (e.g. neural networks) to mobile devices, which have an implicit resource limitation. We aim to cover (i) the impact of the design decisions on the achievement of high-accuracy and low resource-consumption implementations; and (ii) the validation of profiling tools for systematically promoting greener AI. Method: This confirmatory registered report consists of a plan to conduct an empirical study to quantify the implications of the design decisions on AI-enabled applications performance and to report experiences of the end-to-end AI-enabled software engineering lifecycle. Concretely, we will implement both image-based and language-based neural networks in mobile applications to solve multiple image classification and text classification problems on different benchmark datasets. Overall, we plan to model the accuracy and complexity of AI-enabled applications in operation with respect to their design decisions and will provide tools for allowing practitioners to gain consciousness of the quantitative relationship between the design decisions and the green characteristics of study.
Jointly Trained Image and Video Generation using Residual Vectors
Dec 17, 2019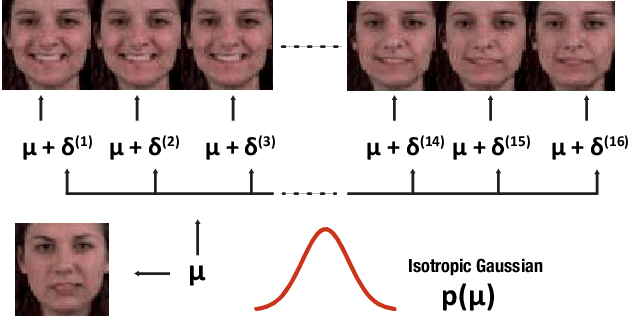
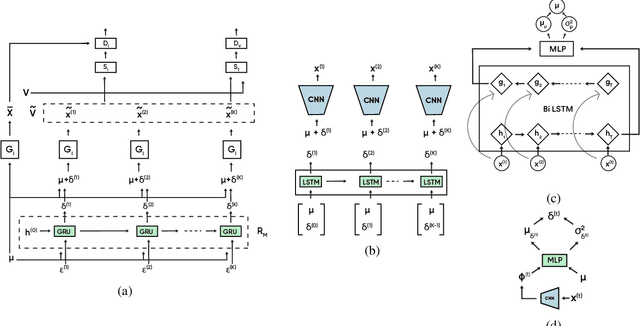
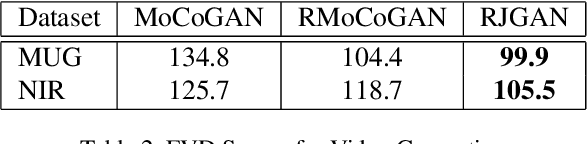

In this work, we propose a modeling technique for jointly training image and video generation models by simultaneously learning to map latent variables with a fixed prior onto real images and interpolate over images to generate videos. The proposed approach models the variations in representations using residual vectors encoding the change at each time step over a summary vector for the entire video. We utilize the technique to jointly train an image generation model with a fixed prior along with a video generation model lacking constraints such as disentanglement. The joint training enables the image generator to exploit temporal information while the video generation model learns to flexibly share information across frames. Moreover, experimental results verify our approach's compatibility with pre-training on videos or images and training on datasets containing a mixture of both. A comprehensive set of quantitative and qualitative evaluations reveal the improvements in sample quality and diversity over both video generation and image generation baselines. We further demonstrate the technique's capabilities of exploiting similarity in features across frames by applying it to a model based on decomposing the video into motion and content. The proposed model allows minor variations in content across frames while maintaining the temporal dependence through latent vectors encoding the pose or motion features.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision
Aug 12, 2021



The abundance and richness of Internet photos of landmarks and cities has led to significant progress in 3D vision over the past two decades, including automated 3D reconstructions of the world's landmarks from tourist photos. However, a major source of information available for these 3D-augmented collections---namely language, e.g., from image captions---has been virtually untapped. In this work, we present WikiScenes, a new, large-scale dataset of landmark photo collections that contains descriptive text in the form of captions and hierarchical category names. WikiScenes forms a new testbed for multimodal reasoning involving images, text, and 3D geometry. We demonstrate the utility of WikiScenes for learning semantic concepts over images and 3D models. Our weakly-supervised framework connects images, 3D structure, and semantics---utilizing the strong constraints provided by 3D geometry---to associate semantic concepts to image pixels and 3D points.
Variable Rate Deep Image Compression with Modulated Autoencoder
Dec 11, 2019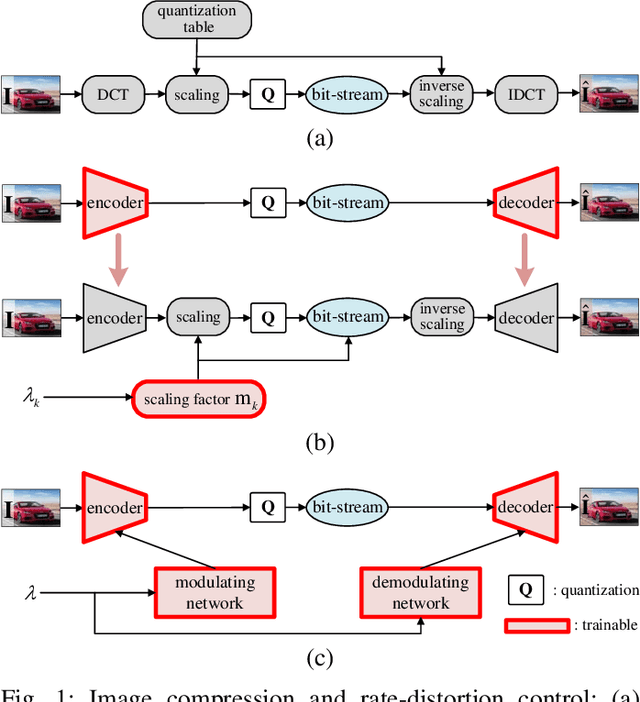
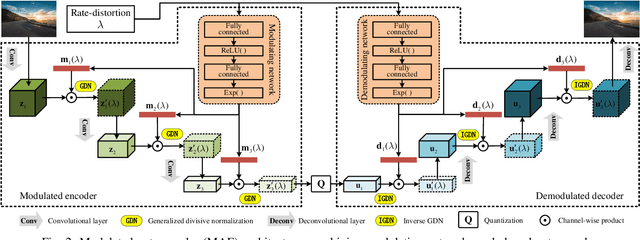
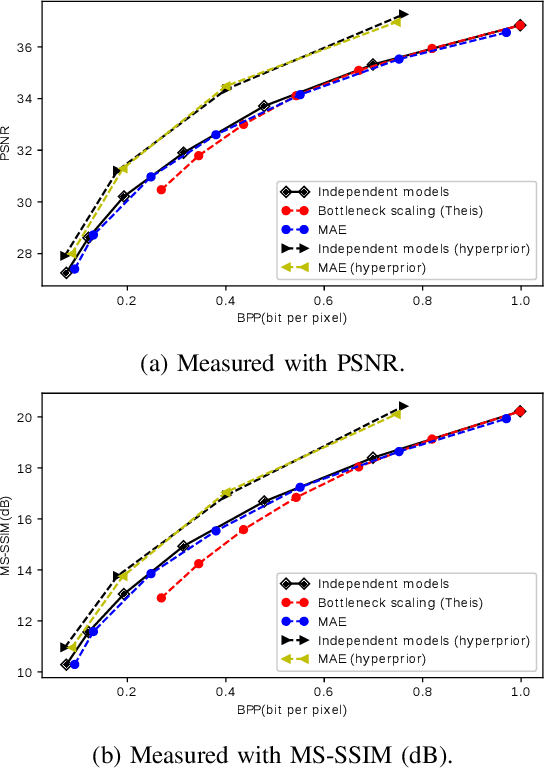
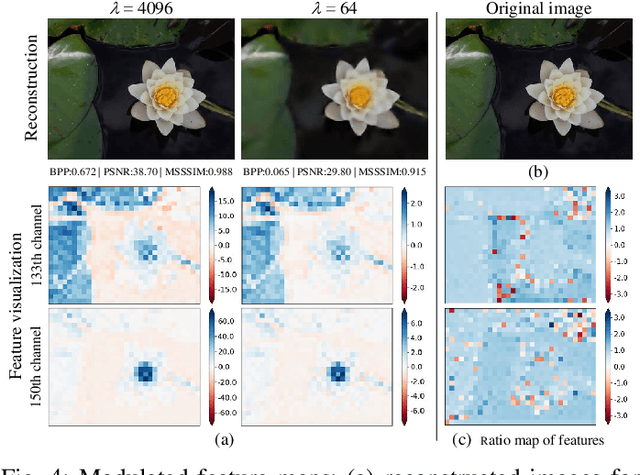
Variable rate is a requirement for flexible and adaptable image and video compression. However, deep image compression methods are optimized for a single fixed rate-distortion tradeoff. While this can be addressed by training multiple models for different tradeoffs, the memory requirements increase proportionally to the number of models. Scaling the bottleneck representation of a shared autoencoder can provide variable rate compression with a single shared autoencoder. However, the R-D performance using this simple mechanism degrades in low bitrates, and also shrinks the effective range of bit rates. Addressing these limitations, we formulate the problem of variable rate-distortion optimization for deep image compression, and propose modulated autoencoders (MAEs), where the representations of a shared autoencoder are adapted to the specific rate-distortion tradeoff via a modulation network. Jointly training this modulated autoencoder and modulation network provides an effective way to navigate the R-D operational curve. Our experiments show that the proposed method can achieve almost the same R-D performance of independent models with significantly fewer parameters.
View Blind-spot as Inpainting: Self-Supervised Denoising with Mask Guided Residual Convolution
Sep 10, 2021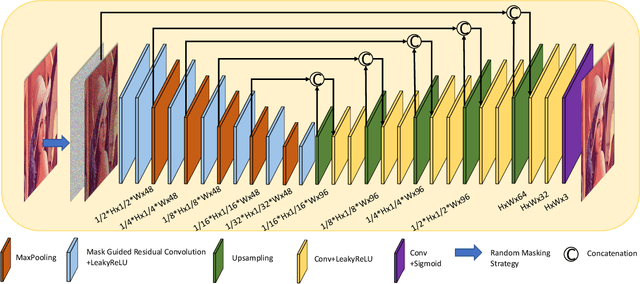
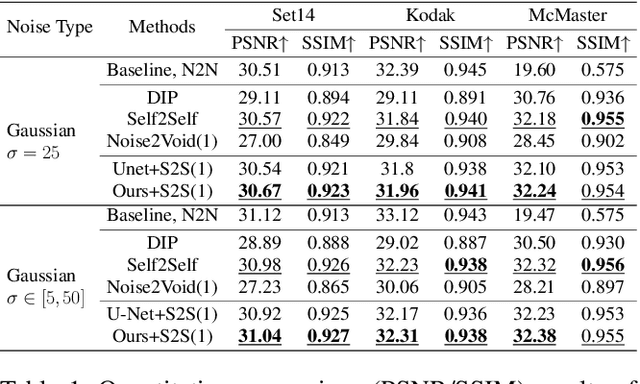
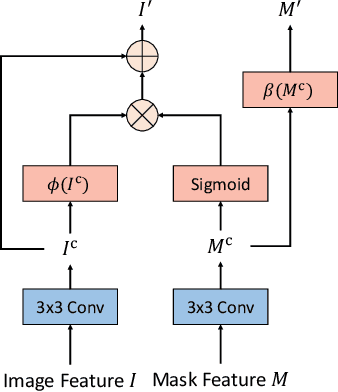
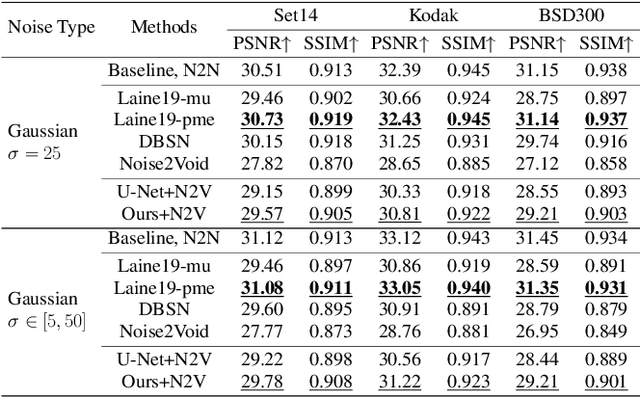
In recent years, self-supervised denoising methods have shown impressive performance, which circumvent painstaking collection procedure of noisy-clean image pairs in supervised denoising methods and boost denoising applicability in real world. One of well-known self-supervised denoising strategies is the blind-spot training scheme. However, a few works attempt to improve blind-spot based self-denoiser in the aspect of network architecture. In this paper, we take an intuitive view of blind-spot strategy and consider its process of using neighbor pixels to predict manipulated pixels as an inpainting process. Therefore, we propose a novel Mask Guided Residual Convolution (MGRConv) into common convolutional neural networks, e.g. U-Net, to promote blind-spot based denoising. Our MGRConv can be regarded as soft partial convolution and find a trade-off among partial convolution, learnable attention maps, and gated convolution. It enables dynamic mask learning with appropriate mask constrain. Different from partial convolution and gated convolution, it provides moderate freedom for network learning. It also avoids leveraging external learnable parameters for mask activation, unlike learnable attention maps. The experiments show that our proposed plug-and-play MGRConv can assist blind-spot based denoising network to reach promising results on both existing single-image based and dataset-based methods.
Cross-modal Attention for MRI and Ultrasound Volume Registration
Jul 12, 2021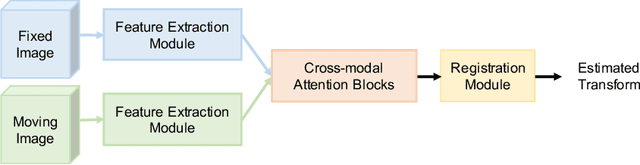
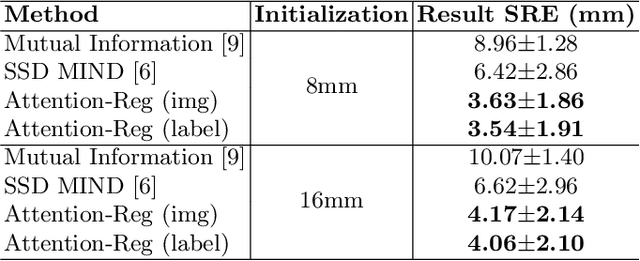
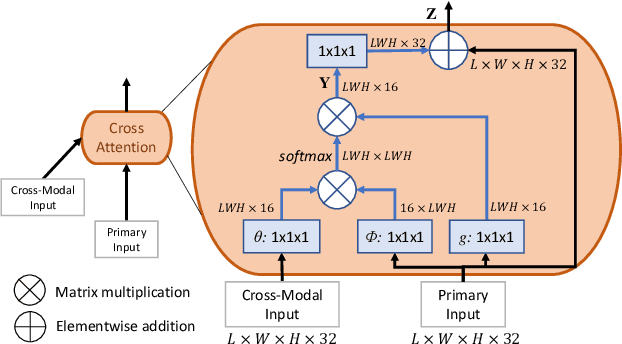
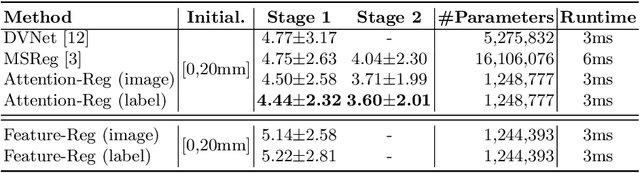
Prostate cancer biopsy benefits from accurate fusion of transrectal ultrasound (TRUS) and magnetic resonance (MR) images. In the past few years, convolutional neural networks (CNNs) have been proved powerful in extracting image features crucial for image registration. However, challenging applications and recent advances in computer vision suggest that CNNs are quite limited in its ability to understand spatial correspondence between features, a task in which the self-attention mechanism excels. This paper aims to develop a self-attention mechanism specifically for cross-modal image registration. Our proposed cross-modal attention block effectively maps each of the features in one volume to all features in the corresponding volume. Our experimental results demonstrate that a CNN network designed with the cross-modal attention block embedded outperforms an advanced CNN network 10 times of its size. We also incorporated visualization techniques to improve the interpretability of our network. The source code of our work is available at https://github.com/DIAL-RPI/Attention-Reg .
Convolutional Neural Network (CNN) vs Visual Transformer (ViT) for Digital Holography
Aug 20, 2021
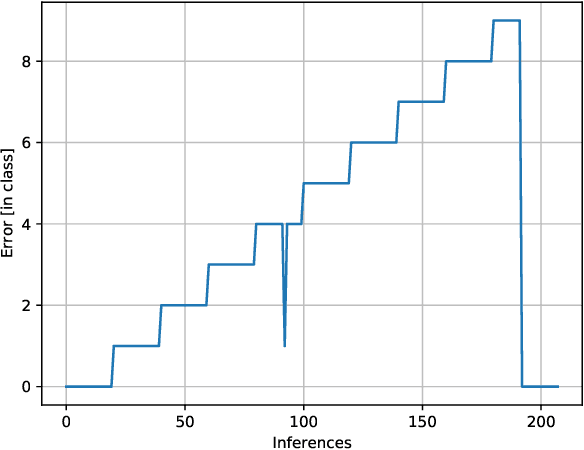
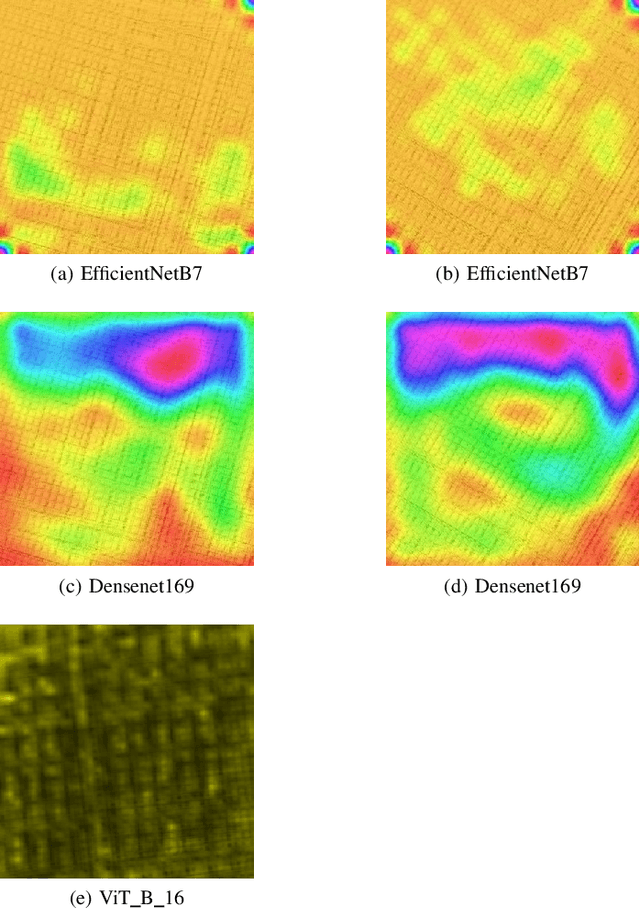

In Digital Holography (DH), it is crucial to extract the object distance from a hologram in order to reconstruct its amplitude and phase. This step is called auto-focusing and it is conventionally solved by first reconstructing a stack of images and then by sharpening each reconstructed image using a focus metric such as entropy or variance. The distance corresponding to the sharpest image is considered the focal position. This approach, while effective, is computationally demanding and time-consuming. In this paper, the determination of the distance is performed by Deep Learning (DL). Two deep learning (DL) architectures are compared: Convolutional Neural Network (CNN)and Visual transformer (ViT). ViT and CNN are used to cope with the problem of auto-focusing as a classification problem. Compared to a first attempt [11] in which the distance between two consecutive classes was 100{\mu}m, our proposal allows us to drastically reduce this distance to 1{\mu}m. Moreover, ViT reaches similar accuracy and is more robust than CNN.