 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
Nov 15, 2021
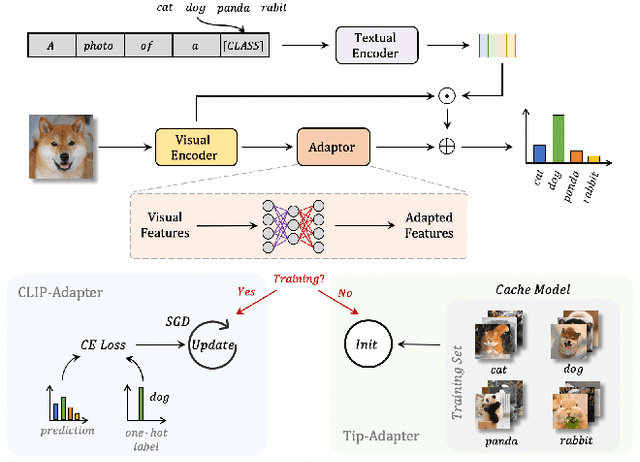

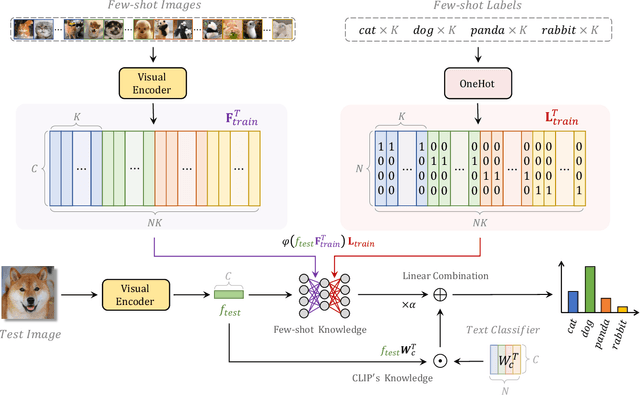

Contrastive Vision-Language Pre-training, known as CLIP, has provided a new paradigm for learning visual representations by using large-scale contrastive image-text pairs. It shows impressive performance on zero-shot knowledge transfer to downstream tasks. To further enhance CLIP's few-shot capability, CLIP-Adapter proposed to fine-tune a lightweight residual feature adapter and significantly improves the performance for few-shot classification. However, such a process still needs extra training and computational resources. In this paper, we propose \textbf{T}raining-Free CL\textbf{IP}-\textbf{Adapter} (\textbf{Tip-Adapter}), which not only inherits CLIP's training-free advantage but also performs comparably or even better than CLIP-Adapter. Tip-Adapter does not require any back propagation for training the adapter, but creates the weights by a key-value cache model constructed from the few-shot training set. In this non-parametric manner, Tip-Adapter acquires well-performed adapter weights without any training, which is both efficient and effective. Moreover, the performance of Tip-Adapter can be further boosted by fine-tuning such properly initialized adapter for only a few epochs with super-fast convergence speed. We conduct extensive experiments of few-shot classification on ImageNet and other 10 datasets to demonstrate the superiority of proposed Tip-Adapter. The code will be released at \url{https://github.com/gaopengcuhk/Tip-Adapter}.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 17, 2021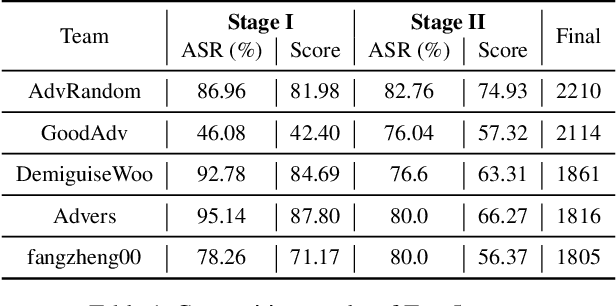
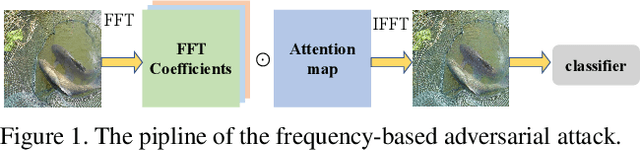
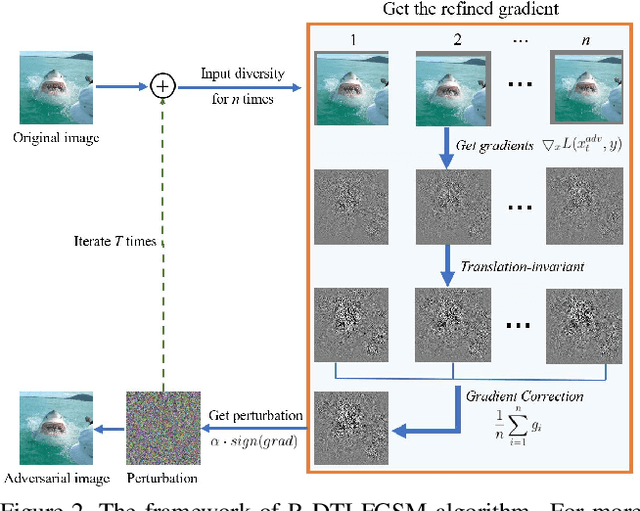
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Microscopy Image Restoration with Deep Wiener-Kolmogorov filters
Dec 25, 2019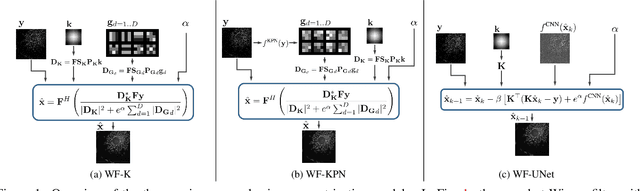
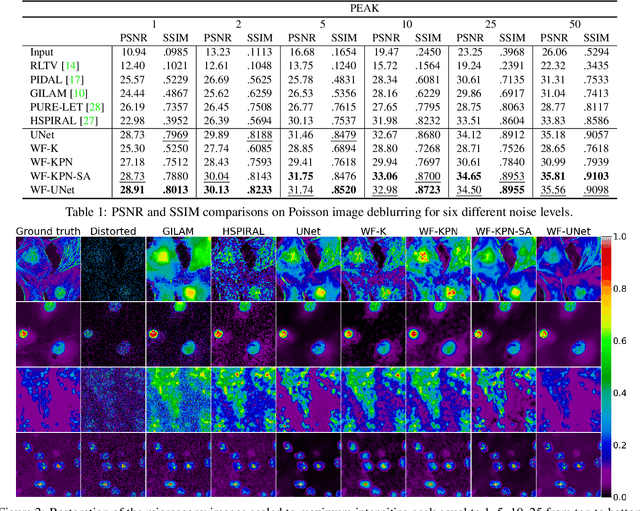
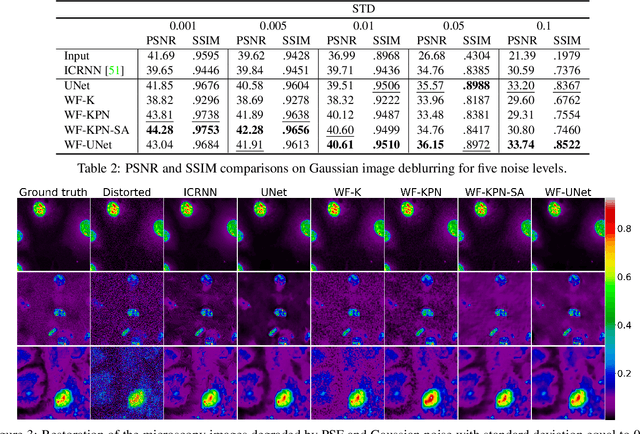
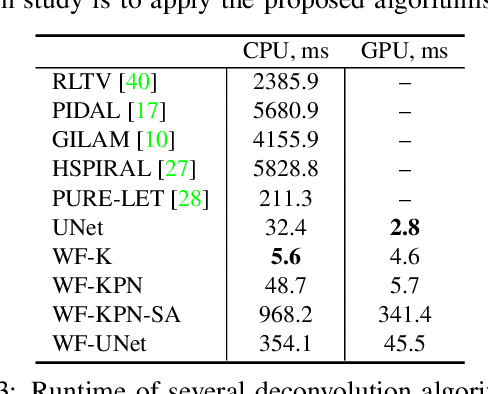
Microscopy is a powerful visualization tool in biology, enabling the study of cells, tissues, and the fundamental biological processes. Yet, the observed images of the objects at the micro-scale suffer from two major inherent distortions: the blur caused by the diffraction of light, and the background noise caused by the imperfections of the imaging detectors. The latter is especially severe in fluorescence and in confocal microscopes, which are known for operating at the low photon count with the Poisson noise statistics. Restoration of such images is usually accomplished by image deconvolution, with the nature of the noise statistics taken into account, and by solving an optimization problem given some prior information about the underlying data (i.e., regularization). In this work, we propose a unifying framework of algorithms for Poisson image deblurring and denoising. The algorithms are based on deep learning techniques for the design of learnable regularizers paired with an appropriate optimization scheme. Our extensive experimentation line showcases that the proposed approach achieves superior quality of image reconstruction and beats the solutions that rely on deep learning or on the optimization schemes alone. Moreover, several implementations of the proposed framework demonstrate competitive performance at a low computational complexity, which is of high importance for real-time imaging applications.
SO-Pose: Exploiting Self-Occlusion for Direct 6D Pose Estimation
Aug 18, 2021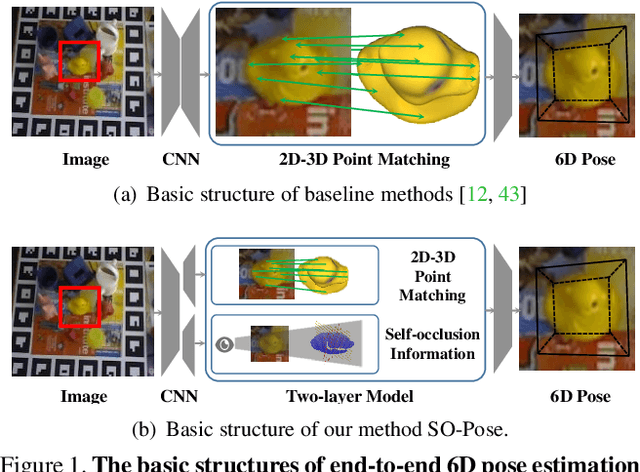
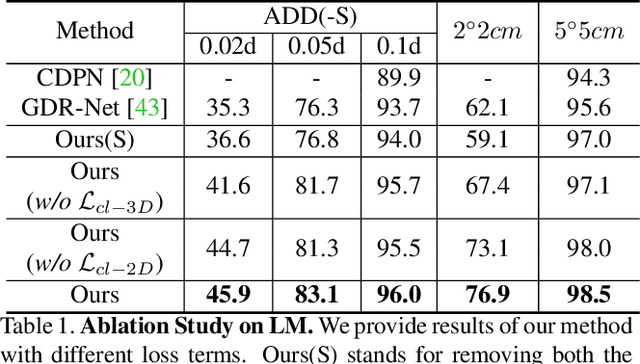
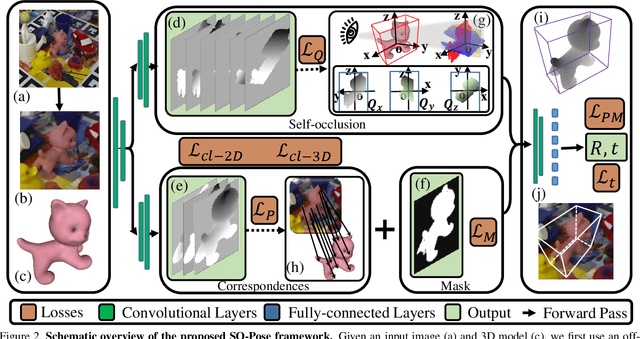
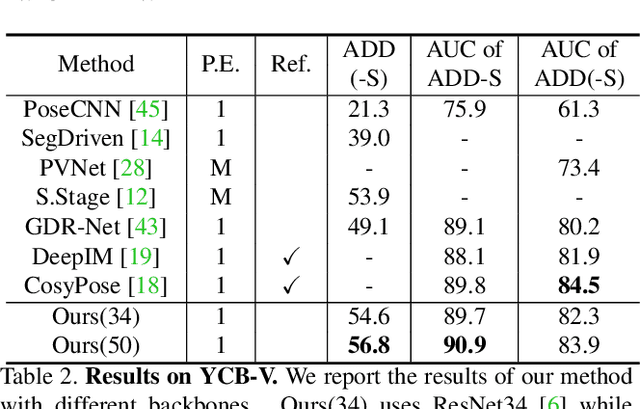
Directly regressing all 6 degrees-of-freedom (6DoF) for the object pose (e.g. the 3D rotation and translation) in a cluttered environment from a single RGB image is a challenging problem. While end-to-end methods have recently demonstrated promising results at high efficiency, they are still inferior when compared with elaborate P$n$P/RANSAC-based approaches in terms of pose accuracy. In this work, we address this shortcoming by means of a novel reasoning about self-occlusion, in order to establish a two-layer representation for 3D objects which considerably enhances the accuracy of end-to-end 6D pose estimation. Our framework, named SO-Pose, takes a single RGB image as input and respectively generates 2D-3D correspondences as well as self-occlusion information harnessing a shared encoder and two separate decoders. Both outputs are then fused to directly regress the 6DoF pose parameters. Incorporating cross-layer consistencies that align correspondences, self-occlusion and 6D pose, we can further improve accuracy and robustness, surpassing or rivaling all other state-of-the-art approaches on various challenging datasets.
Resolution Switchable Networks for Runtime Efficient Image Recognition
Jul 19, 2020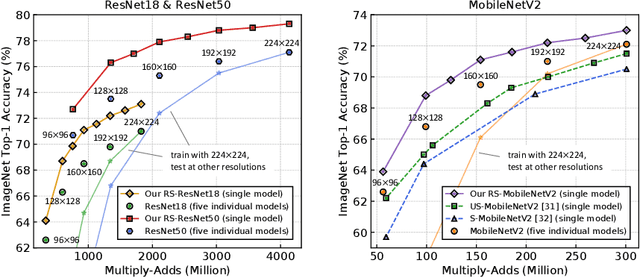
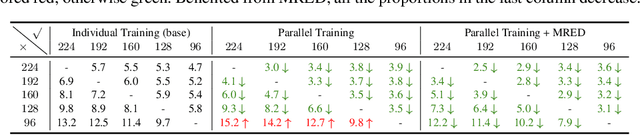
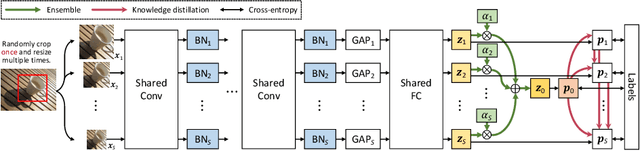
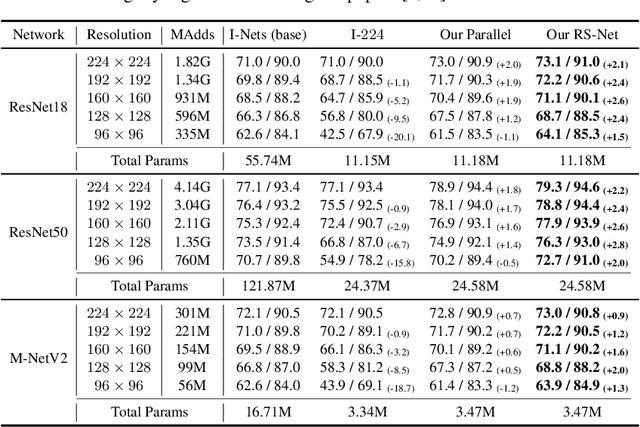
We propose a general method to train a single convolutional neural network which is capable of switching image resolutions at inference. Thus the running speed can be selected to meet various computational resource limits. Networks trained with the proposed method are named Resolution Switchable Networks (RS-Nets). The basic training framework shares network parameters for handling images which differ in resolution, yet keeps separate batch normalization layers. Though it is parameter-efficient in design, it leads to inconsistent accuracy variations at different resolutions, for which we provide a detailed analysis from the aspect of the train-test recognition discrepancy. A multi-resolution ensemble distillation is further designed, where a teacher is learnt on the fly as a weighted ensemble over resolutions. Thanks to the ensemble and knowledge distillation, RS-Nets enjoy accuracy improvements at a wide range of resolutions compared with individually trained models. Extensive experiments on the ImageNet dataset are provided, and we additionally consider quantization problems. Code and models are available at https://github.com/yikaiw/RS-Nets.
Algorithm Selection for Image Quality Assessment
Aug 19, 2019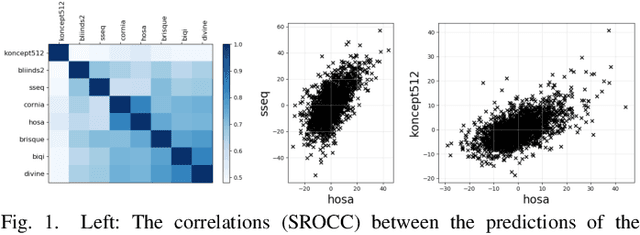
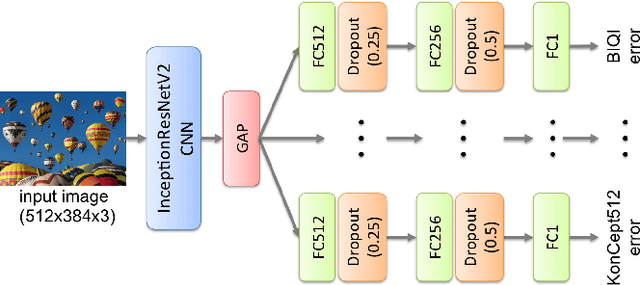
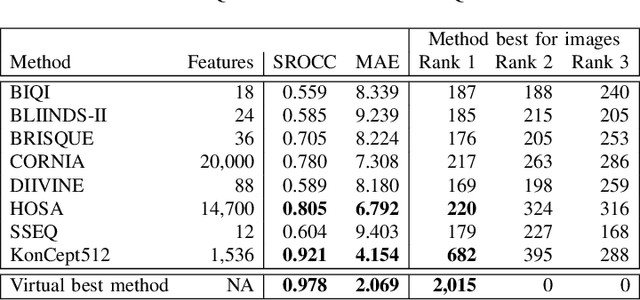
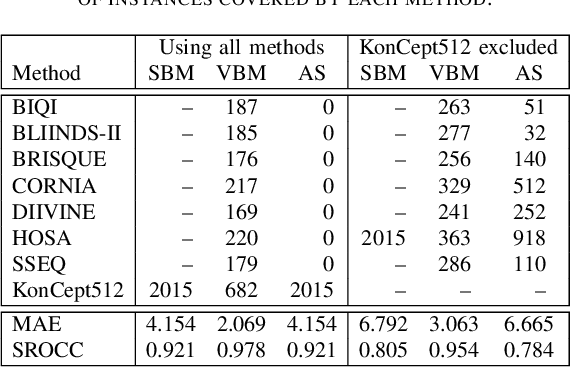
Subjective perceptual image quality can be assessed in lab studies by human observers. Objective image quality assessment (IQA) refers to algorithms for estimation of the mean subjective quality ratings. Many such methods have been proposed, both for blind IQA in which no original reference image is available as well as for the full-reference case. We compared 8 state-of-the-art algorithms for blind IQA and showed that an oracle, able to predict the best performing method for any given input image, yields a hybrid method that could outperform even the best single existing method by a large margin. In this contribution we address the research question whether established methods to learn such an oracle can improve blind IQA. We applied AutoFolio, a state-of-the-art system that trains an algorithm selector to choose a well-performing algorithm for a given instance. We also trained deep neural networks to predict the best method. Our results did not give a positive answer, algorithm selection did not yield a significant improvement over the single best method. Looking into the results in depth, we observed that the noise in images may have played a role in why our trained classifiers could not predict the oracle. This motivates the consideration of noisiness in IQA methods, a property that has so far not been observed and that opens up several interesting new research questions and applications.
Style Generator Inversion for Image Enhancement and Animation
Jun 05, 2019
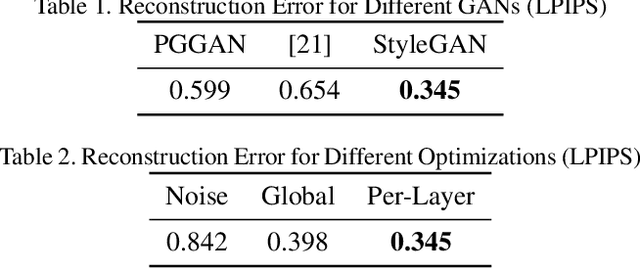


One of the main motivations for training high quality image generative models is their potential use as tools for image manipulation. Recently, generative adversarial networks (GANs) have been able to generate images of remarkable quality. Unfortunately, adversarially-trained unconditional generator networks have not been successful as image priors. One of the main requirements for a network to act as a generative image prior, is being able to generate every possible image from the target distribution. Adversarial learning often experiences mode-collapse, which manifests in generators that cannot generate some modes of the target distribution. Another requirement often not satisfied is invertibility i.e. having an efficient way of finding a valid input latent code given a required output image. In this work, we show that differently from earlier GANs, the very recently proposed style-generators are quite easy to invert. We use this important observation to propose style generators as general purpose image priors. We show that style generators outperform other GANs as well as Deep Image Prior as priors for image enhancement tasks. The latent space spanned by style-generators satisfies linear identity-pose relations. The latent space linearity, combined with invertibility, allows us to animate still facial images without supervision. Extensive experiments are performed to support the main contributions of this paper.
Dual Prototypical Contrastive Learning for Few-shot Semantic Segmentation
Nov 09, 2021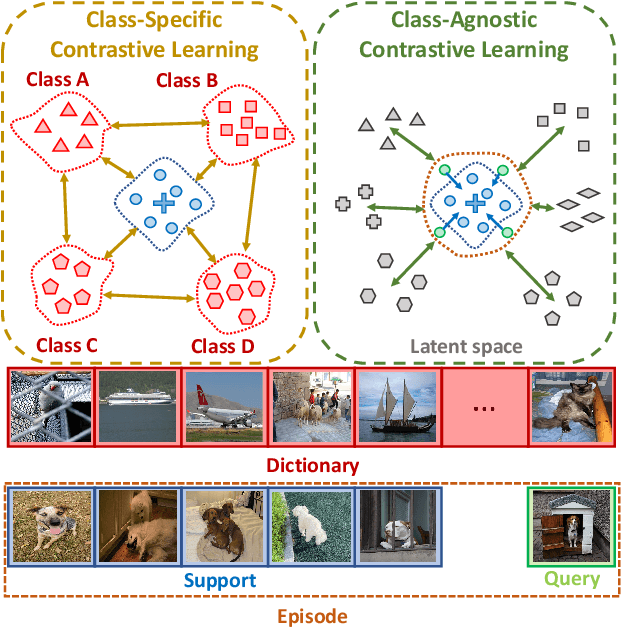
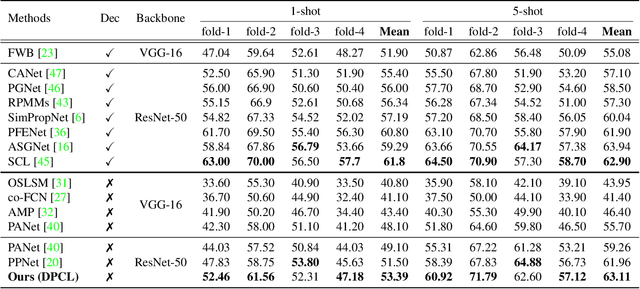
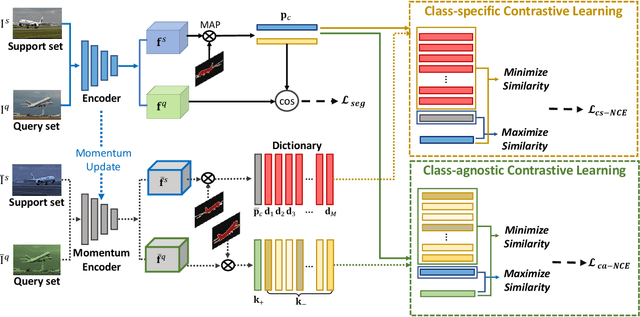

We address the problem of few-shot semantic segmentation (FSS), which aims to segment novel class objects in a target image with a few annotated samples. Though recent advances have been made by incorporating prototype-based metric learning, existing methods still show limited performance under extreme intra-class object variations and semantically similar inter-class objects due to their poor feature representation. To tackle this problem, we propose a dual prototypical contrastive learning approach tailored to the FSS task to capture the representative semanticfeatures effectively. The main idea is to encourage the prototypes more discriminative by increasing inter-class distance while reducing intra-class distance in prototype feature space. To this end, we first present a class-specific contrastive loss with a dynamic prototype dictionary that stores the class-aware prototypes during training, thus enabling the same class prototypes similar and the different class prototypes to be dissimilar. Furthermore, we introduce a class-agnostic contrastive loss to enhance the generalization ability to unseen classes by compressing the feature distribution of semantic class within each episode. We demonstrate that the proposed dual prototypical contrastive learning approach outperforms state-of-the-art FSS methods on PASCAL-5i and COCO-20i datasets. The code is available at:https://github.com/kwonjunn01/DPCL1.
Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities
May 03, 2020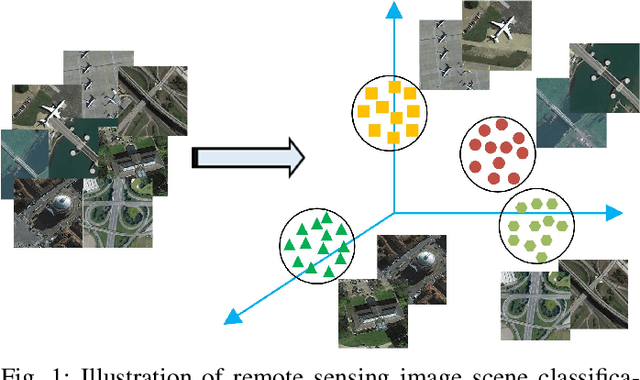
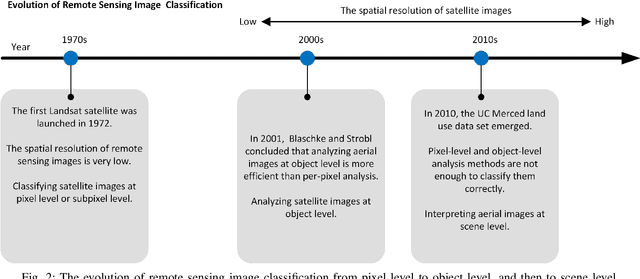
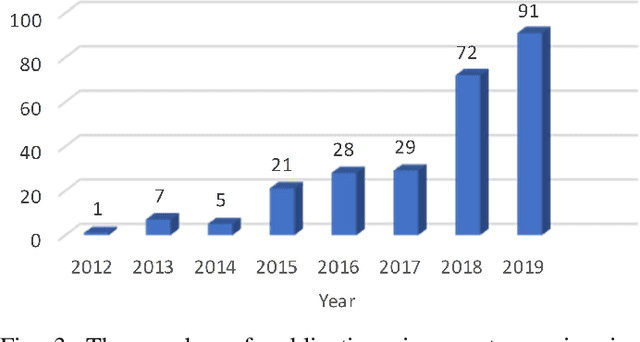
Remote sensing image scene classification, which aims at labeling remote sensing images with a set of semantic categories based on their contents, has broad applications in a range of fields. Propelled by the powerful feature learning capabilities of deep neural networks, remote sensing image scene classification driven by deep learning has drawn remarkable attention and achieved significant breakthroughs. However, to the best of our knowledge, a comprehensive review of recent achievements regarding deep learning for scene classification of remote sensing images is still lacking. Considering the rapid evolution of this field, this paper provides a systematic survey of deep learning methods for remote sensing image scene classification by covering more than 140 papers. To be specific, we discuss the main challenges of scene classification and survey (1) Autoencoder-based scene classification methods, (2) Convolutional Neural Network-based scene classification methods, and (3) Generative Adversarial Network-based scene classification methods. In addition, we introduce the benchmarks used for scene classification and summarize the performance of more than two dozens of representative algorithms on three commonly-used benchmark data sets. Finally, we discuss the promising opportunities for further research.
Model Watermarking for Image Processing Networks
Feb 25, 2020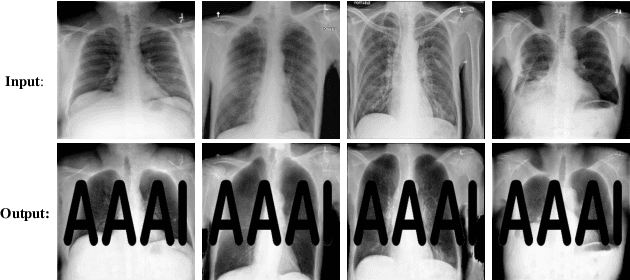
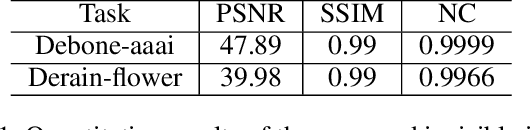
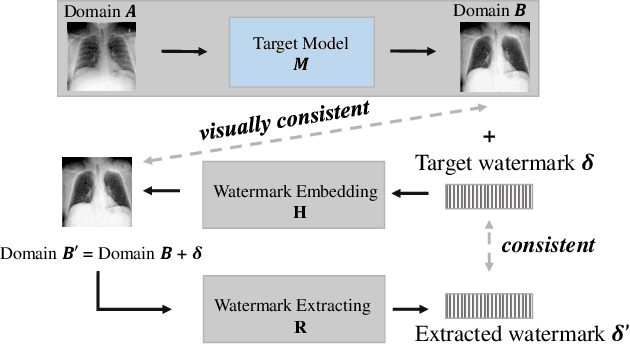
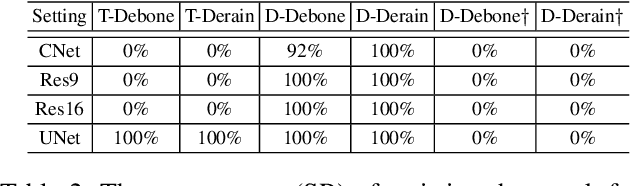
Deep learning has achieved tremendous success in numerous industrial applications. As training a good model often needs massive high-quality data and computation resources, the learned models often have significant business values. However, these valuable deep models are exposed to a huge risk of infringements. For example, if the attacker has the full information of one target model including the network structure and weights, the model can be easily finetuned on new datasets. Even if the attacker can only access the output of the target model, he/she can still train another similar surrogate model by generating a large scale of input-output training pairs. How to protect the intellectual property of deep models is a very important but seriously under-researched problem. There are a few recent attempts at classification network protection only. In this paper, we propose the first model watermarking framework for protecting image processing models. To achieve this goal, we leverage the spatial invisible watermarking mechanism. Specifically, given a black-box target model, a unified and invisible watermark is hidden into its outputs, which can be regarded as a special task-agnostic barrier. In this way, when the attacker trains one surrogate model by using the input-output pairs of the target model, the hidden watermark will be learned and extracted afterward. To enable watermarks from binary bits to high-resolution images, both traditional and deep spatial invisible watermarking mechanism are considered. Experiments demonstrate the robustness of the proposed watermarking mechanism, which can resist surrogate models learned with different network structures and objective functions. Besides deep models, the proposed method is also easy to be extended to protect data and traditional image processing algorithms.