 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention Aware Wavelet-based Detection of Morphed Face Images
Jul 22, 2021
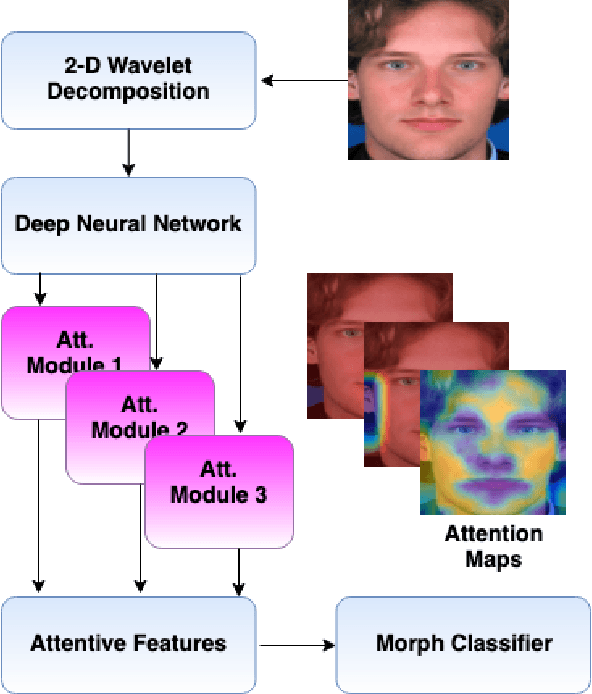
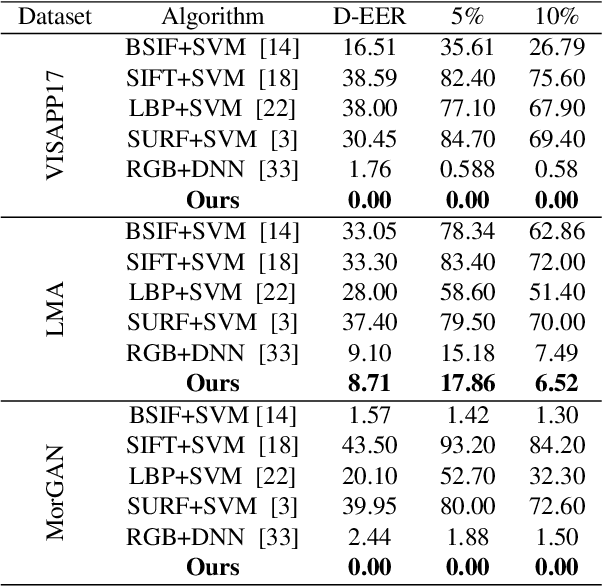
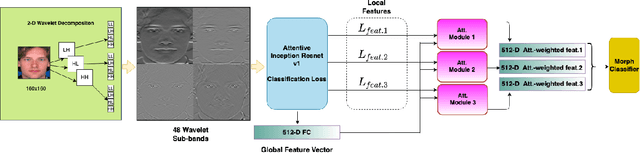
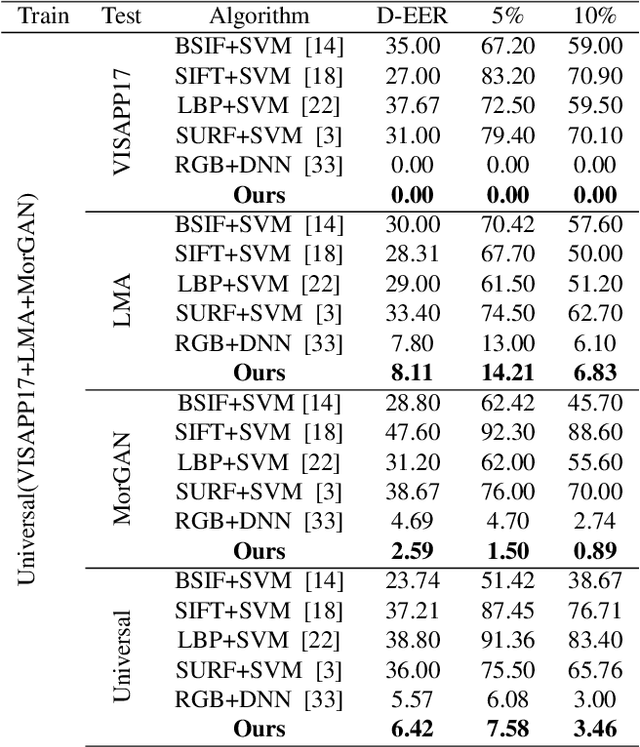
Morphed images have exploited loopholes in the face recognition checkpoints, e.g., Credential Authentication Technology (CAT), used by Transportation Security Administration (TSA), which is a non-trivial security concern. To overcome the risks incurred due to morphed presentations, we propose a wavelet-based morph detection methodology which adopts an end-to-end trainable soft attention mechanism . Our attention-based deep neural network (DNN) focuses on the salient Regions of Interest (ROI) which have the most spatial support for morph detector decision function, i.e, morph class binary softmax output. A retrospective of morph synthesizing procedure aids us to speculate the ROI as regions around facial landmarks , particularly for the case of landmark-based morphing techniques. Moreover, our attention-based DNN is adapted to the wavelet space, where inputs of the network are coarse-to-fine spectral representations, 48 stacked wavelet sub-bands to be exact. We evaluate performance of the proposed framework using three datasets, VISAPP17, LMA, and MorGAN. In addition, as attention maps can be a robust indicator whether a probe image under investigation is genuine or counterfeit, we analyze the estimated attention maps for both a bona fide image and its corresponding morphed image. Finally, we present an ablation study on the efficacy of utilizing attention mechanism for the sake of morph detection.
Co-Evolutionary Compression for Unpaired Image Translation
Jul 25, 2019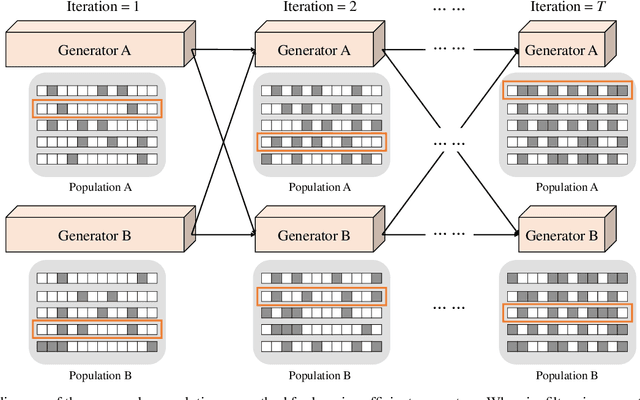
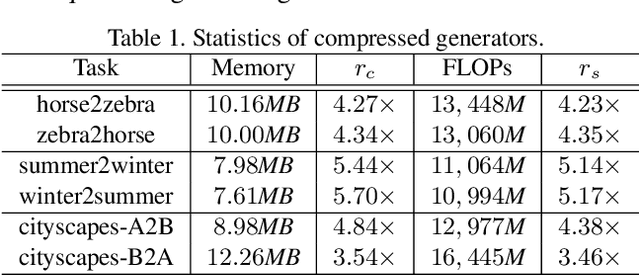

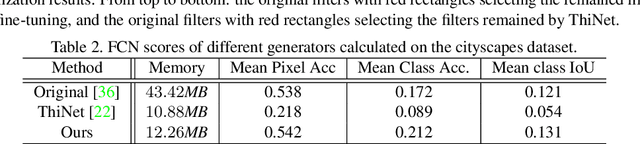
Generative adversarial networks (GANs) have been successfully used for considerable computer vision tasks, especially the image-to-image translation. However, generators in these networks are of complicated architectures with large number of parameters and huge computational complexities. Existing methods are mainly designed for compressing and speeding-up deep neural networks in the classification task, and cannot be directly applied on GANs for image translation, due to their different objectives and training procedures. To this end, we develop a novel co-evolutionary approach for reducing their memory usage and FLOPs simultaneously. In practice, generators for two image domains are encoded as two populations and synergistically optimized for investigating the most important convolution filters iteratively. Fitness of each individual is calculated using the number of parameters, a discriminator-aware regularization, and the cycle consistency. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of the proposed method for obtaining compact and effective generators.
Learning Anchored Unsigned Distance Functions with Gradient Direction Alignment for Single-view Garment Reconstruction
Aug 19, 2021
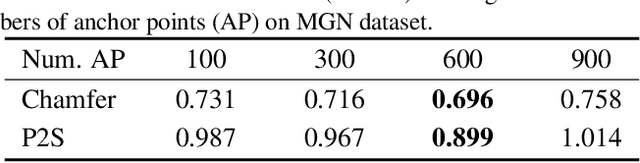
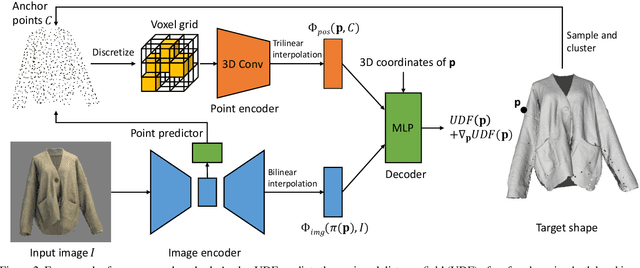
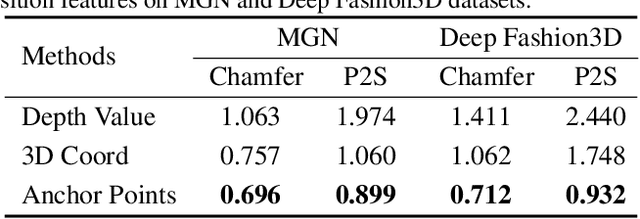
While single-view 3D reconstruction has made significant progress benefiting from deep shape representations in recent years, garment reconstruction is still not solved well due to open surfaces, diverse topologies and complex geometric details. In this paper, we propose a novel learnable Anchored Unsigned Distance Function (AnchorUDF) representation for 3D garment reconstruction from a single image. AnchorUDF represents 3D shapes by predicting unsigned distance fields (UDFs) to enable open garment surface modeling at arbitrary resolution. To capture diverse garment topologies, AnchorUDF not only computes pixel-aligned local image features of query points, but also leverages a set of anchor points located around the surface to enrich 3D position features for query points, which provides stronger 3D space context for the distance function. Furthermore, in order to obtain more accurate point projection direction at inference, we explicitly align the spatial gradient direction of AnchorUDF with the ground-truth direction to the surface during training. Extensive experiments on two public 3D garment datasets, i.e., MGN and Deep Fashion3D, demonstrate that AnchorUDF achieves the state-of-the-art performance on single-view garment reconstruction.
Image-to-Image Translation via Group-wise Deep Whitening and Coloring Transformation
Dec 24, 2018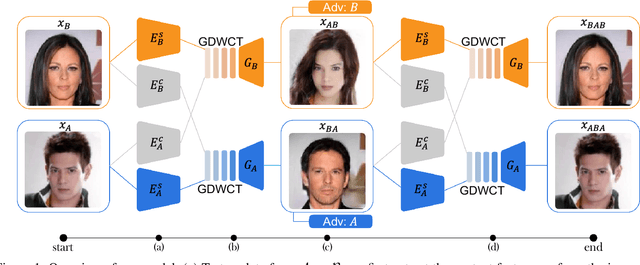
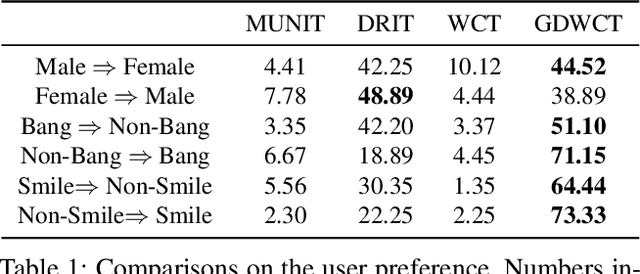
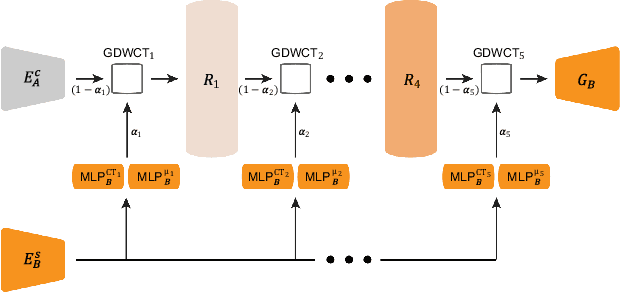
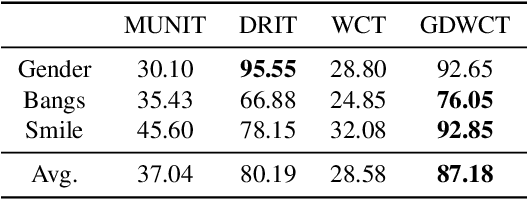
Unsupervised image translation is an active area powered by the advanced generative adversarial networks. Recently introduced models, such as DRIT or MUNIT, utilize a separate encoder in extracting the content and the style of image to successfully incorporate the multimodal nature of image translation. The existing methods, however, overlooks the role that the correlation between feature pairs plays in the overall style. The correlation between feature pairs on top of the mean and the variance of features, are important statistics that define the style of an image. In this regard, we propose an end-to-end framework tailored for image translation that leverages the covariance statistics by whitening the content of an input image followed by coloring to match the covariance statistics with an exemplar. The proposed group-wise deep whitening and coloring (GDWTC) algorithm is motivated by an earlier work of whitening and coloring transformation (WTC), but is augmented to be trained in an end-to-end manner, and with largely reduced computation costs. Our extensive qualitative and quantitative experiments demonstrate that the proposed GDWTC is fast, both in training and inference, and highly effective in reflecting the style of an exemplar.
Single Image Deraining: From Model-Based to Data-Driven and Beyond
Dec 27, 2019

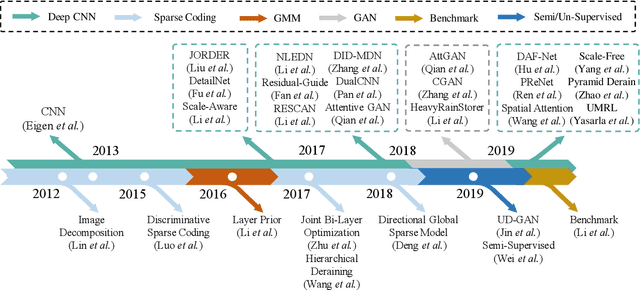
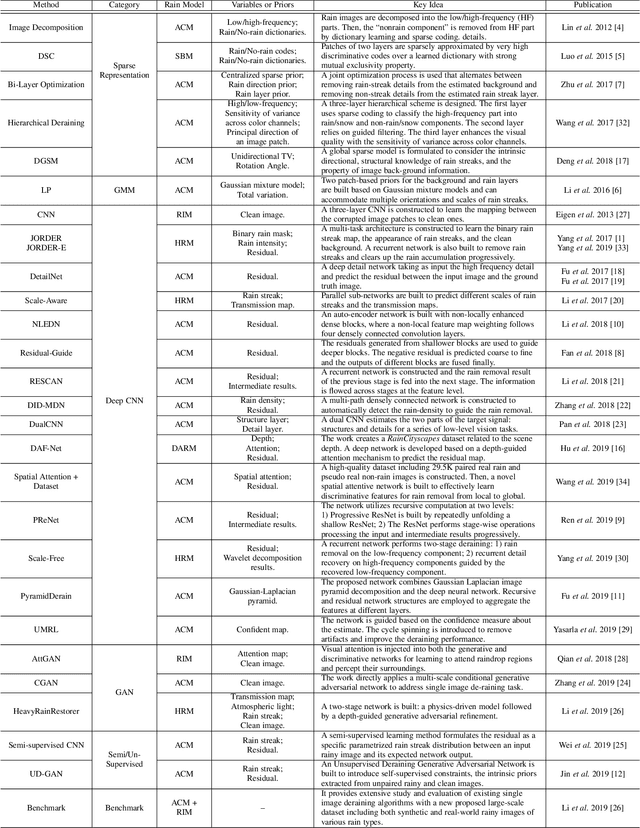
The goal of single-image deraining is to restore the rain-free background scenes of an image degraded by rain streaks and rain accumulation. The early single-image deraining methods employ a cost function, where various priors are developed to represent the properties of rain and background layers. Since 2017, single-image deraining methods step into a deep-learning era, and exploit various types of networks, i.e. convolutional neural networks, recurrent neural networks, generative adversarial networks, etc., demonstrating impressive performance. Given the current rapid development, in this paper, we provide a comprehensive survey of deraining methods over the last decade. We summarize the rain appearance models, and discuss two categories of deraining approaches: model-based and data-driven approaches. For the former, we organize the literature based on their basic models and priors. For the latter, we discuss developed ideas related to architectures, constraints, loss functions, and training datasets. We present milestones of single-image deraining methods, review a broad selection of previous works in different categories, and provide insights on the historical development route from the model-based to data-driven methods. We also summarize performance comparisons quantitatively and qualitatively. Beyond discussing the technicality of deraining methods, we also discuss the future directions.
Unified 3D Mesh Recovery of Humans and Animals by Learning Animal Exercise
Nov 03, 2021
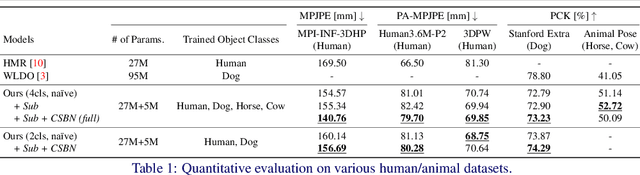
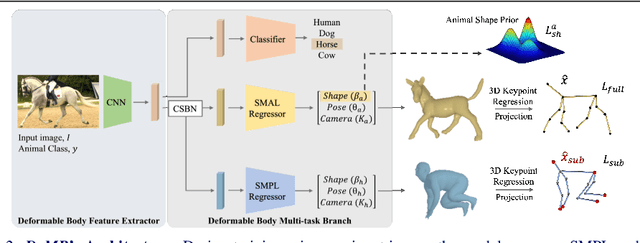

We propose an end-to-end unified 3D mesh recovery of humans and quadruped animals trained in a weakly-supervised way. Unlike recent work focusing on a single target class only, we aim to recover 3D mesh of broader classes with a single multi-task model. However, there exists no dataset that can directly enable multi-task learning due to the absence of both human and animal annotations for a single object, e.g., a human image does not have animal pose annotations; thus, we have to devise a new way to exploit heterogeneous datasets. To make the unstable disjoint multi-task learning jointly trainable, we propose to exploit the morphological similarity between humans and animals, motivated by animal exercise where humans imitate animal poses. We realize the morphological similarity by semantic correspondences, called sub-keypoint, which enables joint training of human and animal mesh regression branches. Besides, we propose class-sensitive regularization methods to avoid a mean-shape bias and to improve the distinctiveness across multi-classes. Our method performs favorably against recent uni-modal models on various human and animal datasets while being far more compact.
Deep Clustering for Mars Rover image datasets
Nov 12, 2019In this paper, we build autoencoders to learn a latent space from unlabeled image datasets obtained from the Mars rover. Then, once the latent feature space has been learnt, we use k-means to cluster the data. We test the performance of the algorithm on a smaller labeled dataset, and report good accuracy and concordance with the ground truth labels. This is the first attempt to use deep learning based unsupervised algorithms to cluster Mars Rover images. This algorithm can be used to augment human annotations for such datasets (which are time consuming) and speed up the generation of ground truth labels for Mars Rover image data, and potentially other planetary and space images.
Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
Nov 15, 2021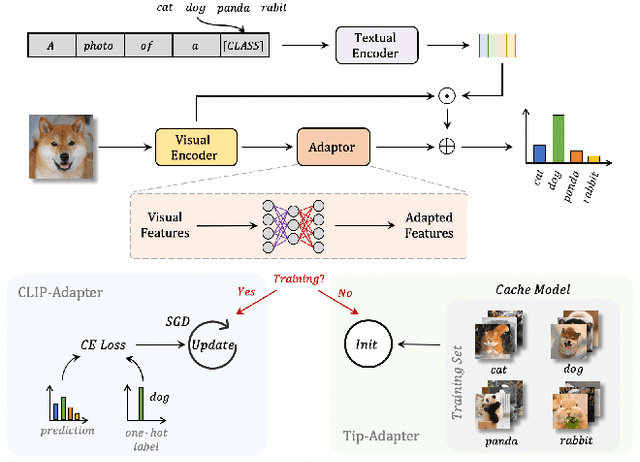

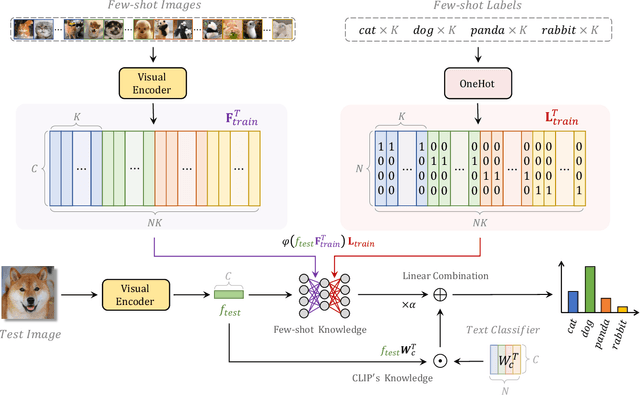

Contrastive Vision-Language Pre-training, known as CLIP, has provided a new paradigm for learning visual representations by using large-scale contrastive image-text pairs. It shows impressive performance on zero-shot knowledge transfer to downstream tasks. To further enhance CLIP's few-shot capability, CLIP-Adapter proposed to fine-tune a lightweight residual feature adapter and significantly improves the performance for few-shot classification. However, such a process still needs extra training and computational resources. In this paper, we propose \textbf{T}raining-Free CL\textbf{IP}-\textbf{Adapter} (\textbf{Tip-Adapter}), which not only inherits CLIP's training-free advantage but also performs comparably or even better than CLIP-Adapter. Tip-Adapter does not require any back propagation for training the adapter, but creates the weights by a key-value cache model constructed from the few-shot training set. In this non-parametric manner, Tip-Adapter acquires well-performed adapter weights without any training, which is both efficient and effective. Moreover, the performance of Tip-Adapter can be further boosted by fine-tuning such properly initialized adapter for only a few epochs with super-fast convergence speed. We conduct extensive experiments of few-shot classification on ImageNet and other 10 datasets to demonstrate the superiority of proposed Tip-Adapter. The code will be released at \url{https://github.com/gaopengcuhk/Tip-Adapter}.
An animated picture says at least a thousand words: Selecting Gif-based Replies in Multimodal Dialog
Sep 29, 2021
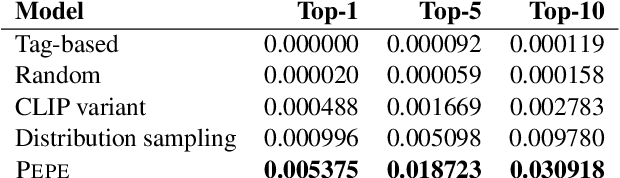
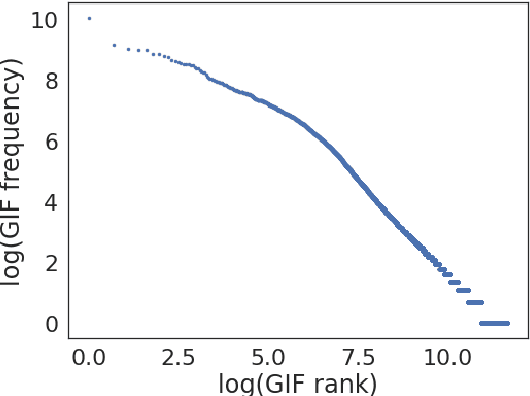

Online conversations include more than just text. Increasingly, image-based responses such as memes and animated gifs serve as culturally recognized and often humorous responses in conversation. However, while NLP has broadened to multimodal models, conversational dialog systems have largely focused only on generating text replies. Here, we introduce a new dataset of 1.56M text-gif conversation turns and introduce a new multimodal conversational model Pepe the King Prawn for selecting gif-based replies. We demonstrate that our model produces relevant and high-quality gif responses and, in a large randomized control trial of multiple models replying to real users, we show that our model replies with gifs that are significantly better received by the community.
Foreground-aware Image Inpainting
Jan 18, 2019
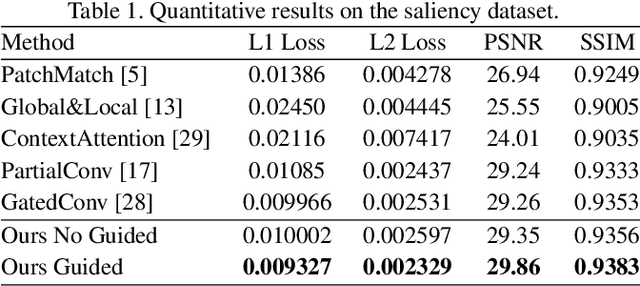
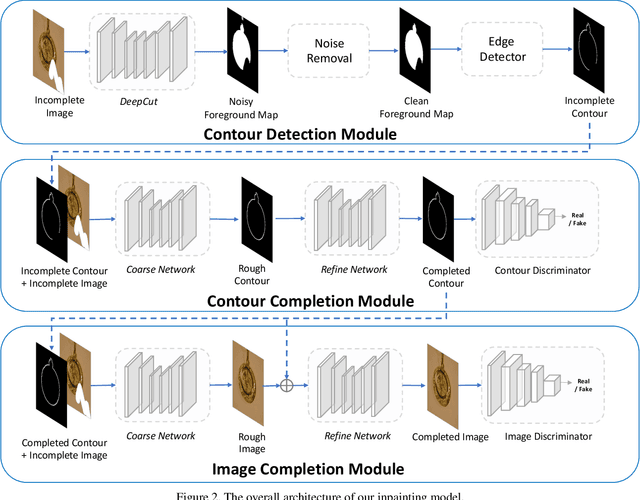

Existing image inpainting methods typically fill holes by borrowing information from surrounding image regions. They often produce unsatisfactory results when the holes overlap with or touch foreground objects due to lack of information about the actual extent of foreground and background regions within the holes. These scenarios, however, are very important in practice, especially for applications such as distracting object removal. To address the problem, we propose a foreground-aware image inpainting system that explicitly disentangles structure inference and content completion. Specifically, our model learns to predict the foreground contour first, and then inpaints the missing region using the predicted contour as guidance. We show that by this disentanglement, the contour completion model predicts reasonable contours of objects, and further substantially improves the performance of image inpainting. Experiments show that our method significantly outperforms existing methods and achieves superior inpainting results on challenging cases with complex compositions.